一、引言
数据是信息系统的核心资产,其安全性、一致性与可恢复性直接关系到业务连续性保障能力。在金融、能源、政务等关键行业,一套科学、分层、可验证的备份恢复体系,是数据库运维工作的基础防线。
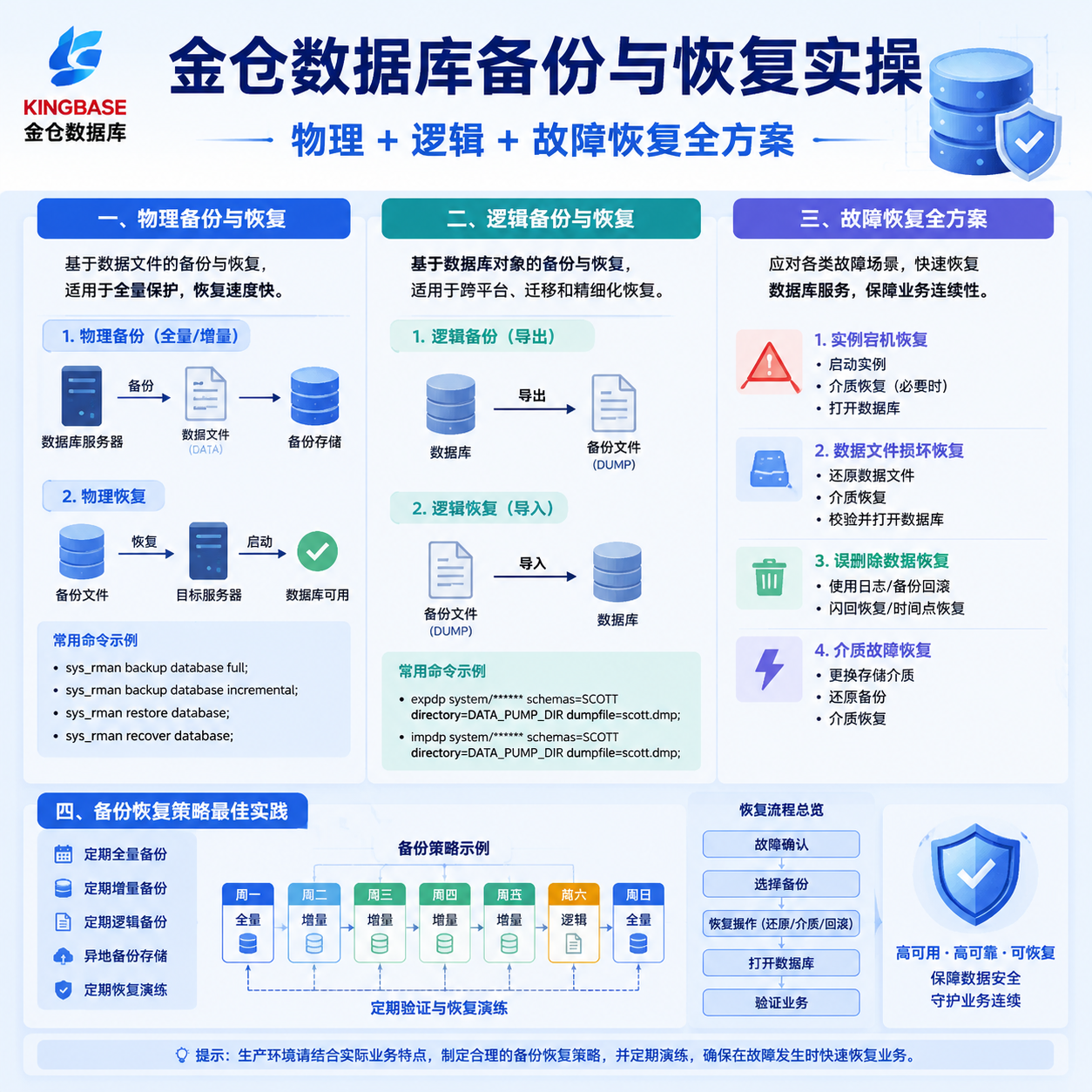
金仓数据库管理系统(KingbaseES)提供覆盖全场景需求的多维度备份恢复能力,主要包括物理备份、逻辑备份、增量备份与时间点恢复(PITR)四条技术路径。这些能力共同构成"全量+增量+日志"的三层防护模型,兼顾恢复速度、空间效率与时间精度,适配不同等级的业务连续性目标。
本文从一个技术专家的视角,结合实际运维场景,系统讲解金仓数据库的物理备份、逻辑备份与故障恢复方案,并提供完整的可执行代码案例。
二、环境准备与测试数据构建
2.1 环境说明
本文所有操作基于以下环境:
-
操作系统:CentOS 7.9 / 麒麟V10
-
数据库版本:金仓数据库管理系统 V9
-
数据目录:`/data/kingbase`
-
备份目录:`/backup/kingbase`
-
WAL归档目录:`/backup/wal`
2.2 创建测试数据库与表结构
首先,我们创建用于演示备份恢复的测试数据库和表结构。
连接数据库并创建测试库:
sql
-- 以system用户连接kingbase数据库
ksql -U system -d kingbase
-- 创建测试数据库
CREATE DATABASE testdb OWNER system ENCODING 'UTF8' LC_COLLATE='zh_CN.UTF-8' LC_CTYPE='zh_CN.UTF-8';创建业务表结构:
sql
-- 切换到testdb数据库
\c testdb
-- 创建客户表
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
contact_phone VARCHAR(20),
email VARCHAR(100),
register_date DATE DEFAULT CURRENT_DATE,
status SMALLINT DEFAULT 1,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建订单表
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER NOT NULL REFERENCES customers(customer_id),
order_no VARCHAR(32) NOT NULL UNIQUE,
order_amount DECIMAL(12,2) NOT NULL,
order_status SMALLINT DEFAULT 0,
order_date DATE DEFAULT CURRENT_DATE,
delivery_address TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建订单明细表
CREATE TABLE order_items (
item_id SERIAL PRIMARY KEY,
order_id INTEGER NOT NULL REFERENCES orders(order_id),
product_name VARCHAR(200) NOT NULL,
quantity INTEGER NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
total_price DECIMAL(12,2) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建产品目录表
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
product_code VARCHAR(32) NOT NULL UNIQUE,
product_name VARCHAR(200) NOT NULL,
category VARCHAR(50),
price DECIMAL(10,2) NOT NULL,
stock_quantity INTEGER DEFAULT 0,
status SMALLINT DEFAULT 1,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 为表添加索引
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
CREATE INDEX idx_orders_order_date ON orders(order_date);
CREATE INDEX idx_order_items_order_id ON order_items(order_id);
CREATE INDEX idx_products_category ON products(category);插入测试数据:
sql
-- 插入客户数据(100条)
INSERT INTO customers (customer_name, contact_phone, email, register_date, status)
SELECT
'客户_' || generate_series(1,100),
'138' || LPAD(generate_series(1,100)::TEXT, 8, '0'),
'customer' || generate_series(1,100) || '@example.com',
CURRENT_DATE - (random() * 365)::INT,
(random() * 2)::INT + 1
FROM generate_series(1,100);
-- 插入产品数据(50条)
INSERT INTO products (product_code, product_name, category, price, stock_quantity, status)
SELECT
'PROD_' || LPAD(generate_series(1,50)::TEXT, 6, '0'),
'产品_' || generate_series(1,50),
CASE (random() * 4)::INT
WHEN 0 THEN '电子产品'
WHEN 1 THEN '家居用品'
WHEN 2 THEN '食品饮料'
WHEN 3 THEN '办公耗材'
ELSE '其他'
END,
(random() * 999 + 1)::DECIMAL(10,2),
(random() * 1000)::INT,
(random() * 2)::INT + 1
FROM generate_series(1,50);
-- 插入订单数据(500条)
INSERT INTO orders (customer_id, order_no, order_amount, order_status, order_date, delivery_address)
SELECT
(random() * 99 + 1)::INT,
'ORD_' || TO_CHAR(CURRENT_DATE, 'YYYYMMDD') || '_' || LPAD(generate_series(1,500)::TEXT, 6, '0'),
(random() * 9999 + 1)::DECIMAL(12,2),
(random() * 4)::INT,
CURRENT_DATE - (random() * 180)::INT,
'地址_' || generate_series(1,500)
FROM generate_series(1,500);
-- 插入订单明细数据(约1500条)
INSERT INTO order_items (order_id, product_name, quantity, unit_price, total_price)
SELECT
(random() * 499 + 1)::INT,
'商品_' || generate_series(1,1500),
(random() * 9 + 1)::INT,
(random() * 999 + 1)::DECIMAL(10,2),
((random() * 9 + 1) * (random() * 999 + 1))::DECIMAL(12,2)
FROM generate_series(1,1500);
-- 验证数据插入
SELECT 'customers' AS table_name, COUNT(*) AS row_count FROM customers
UNION ALL
SELECT 'products', COUNT(*) FROM products
UNION ALL
SELECT 'orders', COUNT(*) FROM orders
UNION ALL
SELECT 'order_items', COUNT(*) FROM order_items;三、物理备份实战
物理备份是构建基础恢复能力的起点,适用于对恢复速度要求严苛的生产环境。金仓数据库的物理备份通过`sys_basebackup`工具实现,能够在不中断业务的情况下获取数据库集群的一致性副本。
3.1 物理备份前置配置
在进行物理备份前,需要完成以下配置:
1. 启用备份权限插件(可选)
sql
-- 编辑kingbase.conf,添加shared_preload_libraries
shared_preload_libraries = 'backup_pri'
-- 重启数据库后创建扩展
CREATE EXTENSION backup_pri;
-- 启用备份权限功能
ALTER SYSTEM SET backup_pri.enable_backup_pri = on;
SELECT sys_reload_conf();
-- 为备份用户授予SYSBACKUP权限
CREATE USER backup_user WITH PASSWORD 'backup_pass';
ALTER USER backup_user SYSBACKUP;2. 配置归档模式(用于增量恢复)
在`kingbase.conf`中添加以下配置:
sql
archive_mode = on
archive_command = 'test ! -f /backup/wal/%f && cp %p /backup/wal/%f'
archive_timeout = 60
wal_level = replica
max_wal_senders = 103.2 执行物理备份
使用sys_basebackup进行在线物理备份:
bash
#!/bin/bash
# 物理备份脚本 - physical_backup.sh
# 定义变量
BACKUP_BASE="/backup/kingbase"
BACKUP_DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_DIR="${BACKUP_BASE}/base_${BACKUP_DATE}"
WAL_DIR="${BACKUP_BASE}/wal"
LOG_FILE="${BACKUP_BASE}/backup_${BACKUP_DATE}.log"
# 创建备份目录
mkdir -p ${BACKUP_DIR}
mkdir -p ${WAL_DIR}
# 执行物理备份
echo "=== 开始物理备份: $(date) ===" >> ${LOG_FILE}
sys_basebackup -U backup_user -h localhost -p 54321 \
-D ${BACKUP_DIR} \
-F plain \
-X stream \
-P \
-v \
-l "full_backup_${BACKUP_DATE}" \
>> ${LOG_FILE} 2>&1
# 检查备份结果
if [ $? -eq 0 ]; then
echo "物理备份成功完成: ${BACKUP_DIR}" >> ${LOG_FILE}
# 记录备份信息
echo "备份目录: ${BACKUP_DIR}" > ${BACKUP_DIR}/backup_info.txt
echo "备份时间: ${BACKUP_DATE}" >> ${BACKUP_DIR}/backup_info.txt
echo "备份标签: full_backup_${BACKUP_DATE}" >> ${BACKUP_DIR}/backup_info.txt
# 计算备份大小
du -sh ${BACKUP_DIR} >> ${BACKUP_DIR}/backup_info.txt
# 生成校验和
find ${BACKUP_DIR} -type f -exec sha256sum {} \; > ${BACKUP_DIR}/checksum.txt
else
echo "物理备份失败,请检查日志: ${LOG_FILE}" >> ${LOG_FILE}
exit 1
fi
echo "=== 物理备份结束: $(date) ===" >> ${LOG_FILE}3.3 物理备份参数说明
| 参数 | 说明 | 备注/注意事项 |
|---|---|---|
-U backup_user |
指定备份用户 | 该用户必须具备 SYSBACKUP 系统权限,否则无法执行全量备份。 |
-h localhost -p 54321 |
指定数据库地址与端口 | 金仓默认端口通常为54321,若是远程备份,需将localhost改为具体IP。 |
-D ${BACKUP_DIR} |
指定备份文件输出目录 | 重点:该目录必须为空,且数据库操作系统用户(如kingbase)对该目录拥有读写权限。 |
-F plain |
设置输出格式 | plain表示普通文本格式(SQL脚本),还原时最为灵活;也可选 tar或 custom。 |
-X stream |
WAL日志传输模式 | 启用流式传输预写日志(WAL),确保在备份期间产生的日志也能被归档,是实现PITR(时间点恢复)的关键。 |
-P |
显示进度 | 在备份过程中实时输出进度百分比,便于监控大库的备份状态。 |
-v |
详细输出模式 | 打印更详细的日志信息(Verbose),常用于排查备份失败的原因。 |
-l "Full Backup $(date +%F)" |
添加备份标签 | 为本次备份设置一个易于识别的描述信息(Label),方便后续在恢复时区分不同的备份集。 |
3.4 物理备份的恢复操作
物理恢复适用于整库级别的灾难恢复场景,恢复速度快,但需要停止数据库服务。
**物理恢复步骤:**
bash
#!/bin/bash
# 物理恢复脚本 - physical_restore.sh
# 定义变量
RESTORE_SOURCE="/backup/kingbase/base_20260101_000000" # 替换为实际备份路径
DATA_DIR="/data/kingbase"
BACKUP_DIR="/data/kingbase_backup_pre_restore"
# 1. 停止数据库服务
echo "正在停止数据库服务..."
systemctl stop kingbase
# 2. 备份当前数据目录(安全措施)
echo "备份当前数据目录..."
mv ${DATA_DIR} ${BACKUP_DIR}_$(date +%Y%m%d_%H%M%S)
# 3. 创建新的数据目录
mkdir -p ${DATA_DIR}
chown kingbase:kingbase ${DATA_DIR}
# 4. 恢复物理备份
echo "正在恢复物理备份..."
cp -a ${RESTORE_SOURCE}/* ${DATA_DIR}/
# 5. 恢复WAL日志(如有增量需要)
# cp -a /backup/wal/* ${DATA_DIR}/sys_wal/
# 6. 检查数据目录权限
chown -R kingbase:kingbase ${DATA_DIR}
# 7. 启动数据库
echo "正在启动数据库..."
systemctl start kingbase
# 8. 验证恢复结果
sleep 5
ksql -U system -d kingbase -c "SELECT sys_postmaster_start_time();"
ksql -U system -d testdb -c "SELECT COUNT(*) FROM customers;"
echo "物理恢复完成!"
四、逻辑备份实战
逻辑备份更适配开发测试、跨版本迁移、敏感数据脱敏等轻量级场景。金仓数据库的`sys_dump`工具支持丰富多样的逻辑备份功能,比如只备份指定的表结构、只备份表数据等。
4.1 sys_dump常用参数
这几个参数我是背下来的,因为出过几次事故。特别是-c和-C,用错了就是删库跑路的前奏。
| 参数 | 这玩意儿干嘛用 | 踩坑心得 |
|---|---|---|
-F c/d/p/t |
选输出格式 | 强烈建议用 -F c(自定义) 。以前爱用 -F p(纯文本),几百万的数据恢复慢得像蜗牛。用 c配合 -j并行恢复,速度快不是一个量级。 |
-f file |
指定输出文件 | 别光写文件名,写绝对路径!我有次脚本跑完找不到备份文件,结果是默认丢到执行用户的home目录里去了,查了半天。 |
-n schema |
只备份某个模式 | 救急神器。比如线上出毛病了,我只想把 trade_schema导出来,就用这个。别傻乎乎全库备份,浪费时间。 |
-t table |
只备份某张表 | 跟 -n搭配使用效果更佳。比如 -n trade_schema -t trade_order。注意:如果表有依赖,光导一张表可能会漏数据。 |
-a |
只要数据 | 俗称"裸数据"。做灰度验证的时候常用,表结构不动,只把生产数据导进来看看性能。 |
-s |
只要结构 | 搭新环境必备。先把表、索引建好,再想办法导数据。有时候用来比对开发和生产的表结构差异。 |
-c |
恢复前先删 | 高危操作! 恢复时加这个,它会先执行 DROP TABLE。除非你确定要覆盖,否则千万别乱加。我见过有人拿备份恢复测试库,结果把生产库干掉的(连错库了)。 |
-C |
带上建库语句 | 一般全库备份时会带。如果是单库恢复,且库还没建,得加这个。但如果库已经存在,加了反而会报错。 |
-j njobs |
开多线程干活 | 性能提升的关键!比如 -j 4,开4个核跑。但注意 :只有 -F d(目录格式)能用,而且别把CPU占满了,留点余地给别的进程。 |
-Z 0-9 |
压缩等级 | 默认是6。想速度快点就 -Z 1,想省磁盘就 -Z 9。但我一般不建议压太狠,因为解压和恢复也要消耗CPU,得不偿失。 |
4.2 全库逻辑备份
bash
#!/bin/bash
# 全库逻辑备份脚本 - logical_full_backup.sh
BACKUP_BASE="/backup/kingbase/logical"
BACKUP_DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_FILE="${BACKUP_BASE}/testdb_full_${BACKUP_DATE}.dump"
LOG_FILE="${BACKUP_BASE}/backup_${BACKUP_DATE}.log"
mkdir -p ${BACKUP_BASE}
echo "=== 开始全库逻辑备份: $(date) ===" >> ${LOG_FILE}
# 使用自定义格式进行全库备份(支持压缩和选择性恢复)
sys_dump -U system -h localhost -p 54321 \
-F c \
-b \
-v \
-Z 6 \
-f ${BACKUP_FILE} \
testdb >> ${LOG_FILE} 2>&1
if [ $? -eq 0 ]; then
echo "全库逻辑备份成功: ${BACKUP_FILE}" >> ${LOG_FILE}
ls -lh ${BACKUP_FILE} >> ${LOG_FILE}
else
echo "全库逻辑备份失败" >> ${LOG_FILE}
exit 1
fi
echo "=== 全库逻辑备份结束: $(date) ===" >> ${LOG_FILE}4.3 指定表的逻辑备份
sql
-- 备份单个表(仅结构+数据)
-- sys_dump -U system -h localhost -p 54321 -t customers -f /backup/customers.dump testdb
-- 备份多个表
-- sys_dump -U system -h localhost -p 54321 -t customers -t orders -t order_items -f /backup/business_tables.dump testdb
-- 只备份表结构(不包含数据)
-- sys_dump -U system -h localhost -p 54321 -t customers -s -f /backup/customers_schema.sql testdb
-- 只备份表数据(不包含结构)
-- sys_dump -U system -h localhost -p 54321 -t customers -a -f /backup/customers_data.sql testdb4.4 按模式备份
bash
#!/bin/bash
# 按模式备份 - logical_schema_backup.sh
BACKUP_BASE="/backup/kingbase/logical"
BACKUP_DATE=$(date +%Y%m%d_%H%M%S)
# 备份public模式
sys_dump -U system -h localhost -p 54321 \
-F d \
-j 4 \
-n public \
-f ${BACKUP_BASE}/public_schema_${BACKUP_DATE} \
testdb
echo "public模式备份完成: ${BACKUP_BASE}/public_schema_${BACKUP_DATE}"4.5 逻辑备份的恢复
逻辑恢复使用`sys_restore`工具,支持选择性恢复和并行恢复。
bash
#!/bin/bash
# 逻辑恢复脚本 - logical_restore.sh
BACKUP_FILE="/backup/kingbase/logical/testdb_full_20260101_000000.dump"
RESTORE_DB="testdb_restore"
# 1. 创建目标数据库(如需要)
ksql -U system -d kingbase -c "DROP DATABASE IF EXISTS ${RESTORE_DB};"
ksql -U system -d kingbase -c "CREATE DATABASE ${RESTORE_DB} OWNER system ENCODING 'UTF8';"
# 2. 执行恢复
echo "开始逻辑恢复..."
sys_restore -U system -h localhost -p 54321 \
-d ${RESTORE_DB} \
-v \
--clean \
--if-exists \
-j 4 \
${BACKUP_FILE}
if [ $? -eq 0 ]; then
echo "逻辑恢复成功"
# 3. 验证恢复
ksql -U system -d ${RESTORE_DB} -c "\dt"
ksql -U system -d ${RESTORE_DB} -c "SELECT COUNT(*) FROM customers;"
ksql -U system -d ${RESTORE_DB} -c "SELECT COUNT(*) FROM orders;"
# 4. 更新统计信息
ksql -U system -d ${RESTORE_DB} -c "ANALYZE;"
else
echo "逻辑恢复失败"
exit 1
fi4.6 指定表恢复
bash
# 从备份文件中只恢复特定表
sys_restore -U system -h localhost -p 54321 \
-d testdb \
-t customers \
-t orders \
--clean \
/backup/kingbase/logical/testdb_full_20260101_000000.dump
五、故障恢复方案
5.1 常见故障场景与恢复策略
这表是我们组出了几次事故后总结的血泪史。特别是那个DROP TABLE,真碰上了心都会跳到嗓子眼。
| 故障场景 | 怎么救(恢复策略) | 会不会丢数据(风险) |
|---|---|---|
| **表数据被误删(DELETE没加WHERE)** | 首选闪回查询 ,快!不行就上PITR (时间点恢复),实在不行用WalMiner挖日志。 | 看运气。闪回能精确到秒,基本不丢。PITR要看你备份策略,至少丢个几分钟是跑不掉的。 |
| **表被干掉了(DROP TABLE)** | 这就有点麻烦了。如果有逻辑备份(.sql文件),直接恢复那张表最快。没有的话,只能全库PITR,把整个库恢复到删表之前。 | 必丢。除非你刚好在删表前一秒做了备份。不然从上次备份到现在的增量数据,全得补。 |
| **库被删了(DROP DATABASE)** | 这种属于重大事故。别想了,直接掏最新的物理全备,连夜恢复吧。 | 取决于备份有多旧。每天一备就丢一天,每小时一备就丢一小时。这时候老板看你的眼神都是凉的。 |
| 数据文件损坏 | 先看能不能从备库顶上。不行就恢复物理备份,或者试试块修复工具。 | 大概率要丢。坏的那部分文件里的数据基本找不回来,只能指望备份了。 |
| **数据块损坏(坏块)** | 金仓自带块自动恢复(如果开了),或者把坏块所在的表导出来再导入。 | 可能丢一点点。通常只是一个页(8K)的数据,但如果是索引块还好,数据块就惨了。 |
5.2 方案一:闪回技术快速恢复
金仓数据库V9内置闪回能力,支持闪回查询和闪回表功能,适用于快速应对高频误操作场景。
闪回查询:
sql
-- 查看表在指定时间点的数据
SELECT * FROM customers AS OF TIMESTAMP '2026-01-01 14:30:00'
WHERE customer_id BETWEEN 1 AND 10;
-- 查看表在指定时间之前的数据
SELECT * FROM orders AS OF TIMESTAMP (CURRENT_TIMESTAMP - INTERVAL '10 minutes')
WHERE order_amount > 1000;闪回表恢复:
sql
-- 将表恢复到指定时间点
FLASHBACK TABLE customers TO TIMESTAMP '2026-01-01 14:30:00';
-- 将表恢复到指定时间点(带重命名旧表)
FLASHBACK TABLE orders TO TIMESTAMP '2026-01-01 14:30:00'
RENAME TO orders_bak_20260101;启用防误删保护:
sql
-- 开启库级防误删保护
ALTER DATABASE testdb SET enable_drop_protection = on;
-- 开启会话级防误删保护
SET enable_drop_protection = on;5.3 方案二:基于物理备份的PITR恢复
时间点恢复(PITR)是最完整的数据恢复方案,适用于需要恢复到特定历史时刻的场景。
恢复流程:
bash
#!/bin/bash
# PITR恢复脚本 - pitr_restore.sh
# 配置参数
BASE_BACKUP="/backup/kingbase/base_20260101_000000" # 全量备份路径
WAL_ARCHIVE="/backup/wal" # WAL归档目录
DATA_DIR="/data/kingbase"
RECOVER_TIME="2026-01-01 15:30:00" # 目标恢复时间点
# 1. 停止数据库
systemctl stop kingbase
# 2. 备份当前数据目录
mv ${DATA_DIR} ${DATA_DIR}_backup_$(date +%Y%m%d_%H%M%S)
# 3. 恢复全量备份
mkdir -p ${DATA_DIR}
cp -a ${BASE_BACKUP}/* ${DATA_DIR}/
chown -R kingbase:kingbase ${DATA_DIR}
# 4. 创建恢复信号文件
cat > ${DATA_DIR}/recovery.signal << EOF
# recovery.signal - 指示数据库进入恢复模式
EOF
# 5. 配置恢复参数(在kingbase.conf或recovery.conf中)
cat > ${DATA_DIR}/kingbase.auto.conf << EOF
# PITR恢复配置
restore_command = 'cp ${WAL_ARCHIVE}/%f %p'
recovery_target_time = '${RECOVER_TIME}'
recovery_target_timeline = 'latest'
EOF
# 6. 启动数据库(自动进入恢复模式)
systemctl start kingbase
# 7. 监控恢复进度
tail -f /data/kingbase/logfile
echo "PITR恢复已启动,目标恢复时间: ${RECOVER_TIME}"5.4 方案三:数据块损坏应急恢复
当数据文件出现坏块时,金仓数据库提供多种应急恢复手段。
1. 使用`ignore_checksum_failure`抢救数据:
sql
-- 开启忽略校验和失败(当前会话)
SET ignore_checksum_failure = on;
-- 尝试读取数据(坏块数据可能丢失)
SELECT * FROM damaged_table;
-- 将可读数据导出到新表
CREATE TABLE damaged_table_recovered AS
SELECT * FROM damaged_table;
-- 关闭忽略选项
SET ignore_checksum_failure = off;2. 使用`zero_damaged_pages`强制读取:
sql
-- 开启损坏页面清零(谨慎使用)
SET zero_damaged_pages = on;
-- 读取数据(损坏页会被清零)
SELECT * FROM damaged_table;
-- 导出可恢复数据
COPY (SELECT * FROM damaged_table) TO '/backup/recovered_data.csv' CSV HEADER;
SET zero_damaged_pages = off;3. 使用物理备份恢复损坏表:
sql
-- 如果只有个别表损坏,可从备份中单独恢复
-- 1. 从备份中恢复特定表的数据文件
-- 2. 或者使用逻辑备份恢复特定表
-- 从逻辑备份恢复特定表
sys_restore -U system -d testdb -t damaged_table --clean /backup/logical/testdb_full.dump5.5 方案四:WalMiner日志解析恢复
当仅有逻辑备份或需要精细化恢复时,可使用WalMiner插件解析WAL日志,提取变更SQL。
sql
-- 1. 创建WalMiner扩展
CREATE EXTENSION IF NOT EXISTS walminer;
-- 2. 添加要解析的WAL文件
SELECT walminer.walminer_add_file('/backup/wal/0000000100000001000000A0');
-- 3. 执行解析
SELECT walminer.walminer_analyze();
-- 4. 查询解析结果(按事务查看)
SELECT * FROM walminer.walminer_contents
WHERE op_text LIKE '%DELETE%' OR op_text LIKE '%DROP%'
ORDER BY xid, ctid;
-- 5. 生成恢复SQL
-- 根据解析结果反向生成恢复语句
-- 对于DELETE操作,生成INSERT语句
-- 对于DROP TABLE,生成CREATE TABLE + INSERT语句
-- 6. 清理
SELECT walminer.walminer_stop();
六、备份策略设计与最佳实践
6.1 分级备份策略
这个策略是我们花了很多心思才定下来的。核心思想就是:钱得花在刀刃上,不能所有系统都按核心系统那个标准来,不然存储费和运维人力费能把预算烧穿。
| 业务级别 | 全量备份 | 增量备份 | WAL归档 | 保留周期 | 人话解读(为啥这么定) |
|---|---|---|---|---|---|
| 核心交易系统 (比如支付、下单) | 每天1次 (通常在凌晨业务低峰) | 每15分钟 (几乎实时了) | 实时 (落盘就传) | 7天 (多了也没用,恢复链太长) | 这是亲儿子。RPO(恢复点目标)必须压到15分钟以内。哪怕硬盘炸了,最多丢15分钟数据,老板还能接受。 |
| 重要业务系统 (比如报表、后台管理) | 每天1次 | 每小时 | 实时 | 30天 (合规要求) | 这是干儿子。丢一小时数据还能跟业务方解释清楚。保留30天主要是为了审计和对账,不是为了恢复。 |
| 一般业务系统 (比如日志、配置库) | 每周1次 (周末) | 每天1次 | 开启 (但不用实时同步) | 30天 | 这是路人。一周备一次全量,每天增量凑合。真出问题了,从上周日的备份恢复,补一天数据就行。 |
| 开发测试环境 | 按需 (发版前) | 不启用 (太浪费资源) | 可选 (基本关掉) | 按需 (用完就删) | 这是后娘养的。数据随便造,崩了直接重装。除非要测恢复流程,否则谁给这玩意儿做备份啊?纯粹浪费磁盘。 |
6.2 备份策略配置脚本
bash
#!/bin/bash
# 综合备份策略调度脚本 - backup_scheduler.sh
BACKUP_BASE="/backup/kingbase"
DATE=$(date +%Y%m%d)
DAY_OF_WEEK=$(date +%u)
# 每日增量备份(使用永久增量备份PIB)
incremental_backup() {
echo "执行增量备份..."
# 使用PIB方式,只备份变更的数据块
sys_basebackup -U backup_user -h localhost -p 54321 \
-D ${BACKUP_BASE}/inc_${DATE} \
-F plain -X stream -P -v \
-l "inc_backup_${DATE}"
}
# 每周全量备份(周日执行)
full_backup() {
echo "执行全量备份..."
sys_basebackup -U backup_user -h localhost -p 54321 \
-D ${BACKUP_BASE}/full_${DATE} \
-F plain -X stream -P -v \
-l "full_backup_${DATE}"
}
# 清理过期备份(保留30天)
cleanup_old_backups() {
echo "清理30天前的备份..."
find ${BACKUP_BASE}/full_* -type d -mtime +30 -exec rm -rf {} \;
find ${BACKUP_BASE}/inc_* -type d -mtime +7 -exec rm -rf {} \;
find ${BACKUP_BASE}/wal -type f -mtime +7 -delete
}
# 主流程
case $DAY_OF_WEEK in
7) # 周日执行全量备份
full_backup
;;
*) # 工作日执行增量备份
incremental_backup
;;
esac
# 执行逻辑备份(每周日同时执行)
if [ $DAY_OF_WEEK -eq 7 ]; then
sys_dump -U system -h localhost -p 54321 \
-F c -Z 6 -b -v \
-f ${BACKUP_BASE}/logical/testdb_full_${DATE}.dump \
testdb
fi
# 清理过期备份
cleanup_old_backups6.3 备份有效性验证
备份的最终价值在于可恢复。建议定期执行恢复验证:
bash
#!/bin/bash
# 备份验证脚本 - verify_backup.sh
BACKUP_FILE="/backup/kingbase/logical/testdb_full_20260101_000000.dump"
VERIFY_DB="verify_db"
# 1. 检查备份文件完整性
echo "检查备份文件完整性..."
file ${BACKUP_FILE}
if [ $? -ne 0 ]; then
echo "备份文件不存在或已损坏"
exit 1
fi
# 2. 尝试列出备份内容
echo "验证备份内容..."
sys_restore -l ${BACKUP_FILE} | head -20
# 3. 创建验证数据库
ksql -U system -d kingbase -c "DROP DATABASE IF EXISTS ${VERIFY_DB};"
ksql -U system -d kingbase -c "CREATE DATABASE ${VERIFY_DB};"
# 4. 执行恢复验证
echo "执行恢复验证..."
time sys_restore -U system -d ${VERIFY_DB} -j 4 ${BACKUP_FILE}
# 5. 验证数据完整性
echo "验证数据完整性..."
ksql -U system -d ${VERIFY_DB} -c "\dt"
ksql -U system -d ${VERIFY_DB} -c "SELECT COUNT(*) FROM customers;"
ksql -U system -d ${VERIFY_DB} -c "SELECT COUNT(*) FROM orders;"
# 6. 清理验证库
ksql -U system -d kingbase -c "DROP DATABASE ${VERIFY_DB};"
echo "备份验证完成!"七、总结
本文系统介绍了金仓数据库的物理备份、逻辑备份与故障恢复方案,涵盖了从环境准备、备份执行到故障恢复的完整实操流程。
核心要点总结如下:
-
物理备份:通过`sys_basebackup`实现整库级别的快速备份,适用于灾难恢复场景。配合WAL归档,可实现任意时间点的精确恢复。
-
逻辑备份:通过`sys_dump`和`sys_restore`实现细粒度的备份恢复,支持按表、按模式的选择性操作,适用于开发测试和跨版本迁移。
-
故障恢复:根据故障类型选择合适方案------闪回技术应对快速误操作,PITR应对时间点精确恢复,WalMiner应对精细化日志分析恢复。
-
备份策略:应建立"全量+增量+日志"的分层防护体系,并配套备份有效性验证机制,确保备份真正"可用、可恢复"。
正如本文开篇所言,一套兼顾RTO与RPO的备份恢复体系,不能仅依赖"能用",更要追求"可靠、可验证、可演进"。希望本文提供的实操案例能够帮助运维人员构建坚实的数据安全防线。