OK,OK,大家好,欢迎大家来到大鹏 AI 教育,我是张大鹏。
前面几篇,我把开源项目 Presenton 的架构拆到了骨头,也给 AI 配了一张代码地图。今天这篇,我不讲理论了,咱们动手实测。我从一句话开始,亲手把它跑到一套成稿,每一步真实发生了什么、屏幕上长什么样、背后是哪段代码在干活,我全摆给你看。 有图有真相,跑得通的地方我讲清楚,翻车的地方我也不藏。
我这次喂给它的就一句话:用一节课讲清楚什么是向量数据库,面向零基础学员,包含定义、工作原理、典型应用场景和上手建议。 你品,这就是一个老师备课时脑子里冒出来的最朴素的需求。
第一步:一句话起头
打开生成页,界面很干净,就一个大输入框,把我那句话填进去。
你注意看输入框上方那一行小字:Custom (deepseek-ai/DeepSeek-V4-Pro) 。这就是我这次用的模型,DeepSeek 的 V4。这里藏着我特别看重的一个设计,模型无关:我想换成别家的模型,不用改一行代码,改一个环境变量就行,这套抽象我在第一篇里专门拆过。这次我接的是国产模型,跑下来完全没问题。
填好,点"开始生成"。
第二步:它得先让你选个模板,才肯开工
这里有个我一开始没料到的行为:点完生成,它没有立刻开始写,而是先跳到一个"选择模板"的页面,你不选,它就一直等着。
第一次遇到我还愣了一下,以为卡住了。其实这是它的设计:内置了十几套模板,通用、现代、教育、报告、路演等等,每一套都是一组用 React 加 Zod Schema 写成的版式组件(这套结构化生成的玄机,也是第一篇的重点)。它要先知道你想要什么风格的版面,才好往里填内容。
我这次随手选了"通用"。先记住这个选择,后面翻车就翻在这。
第三步:先出大纲,而且是一个字一个字流式蹦出来的
选完模板,它干的第一件事不是埋头生成一整套 PPT,而是先给我出一份大纲。
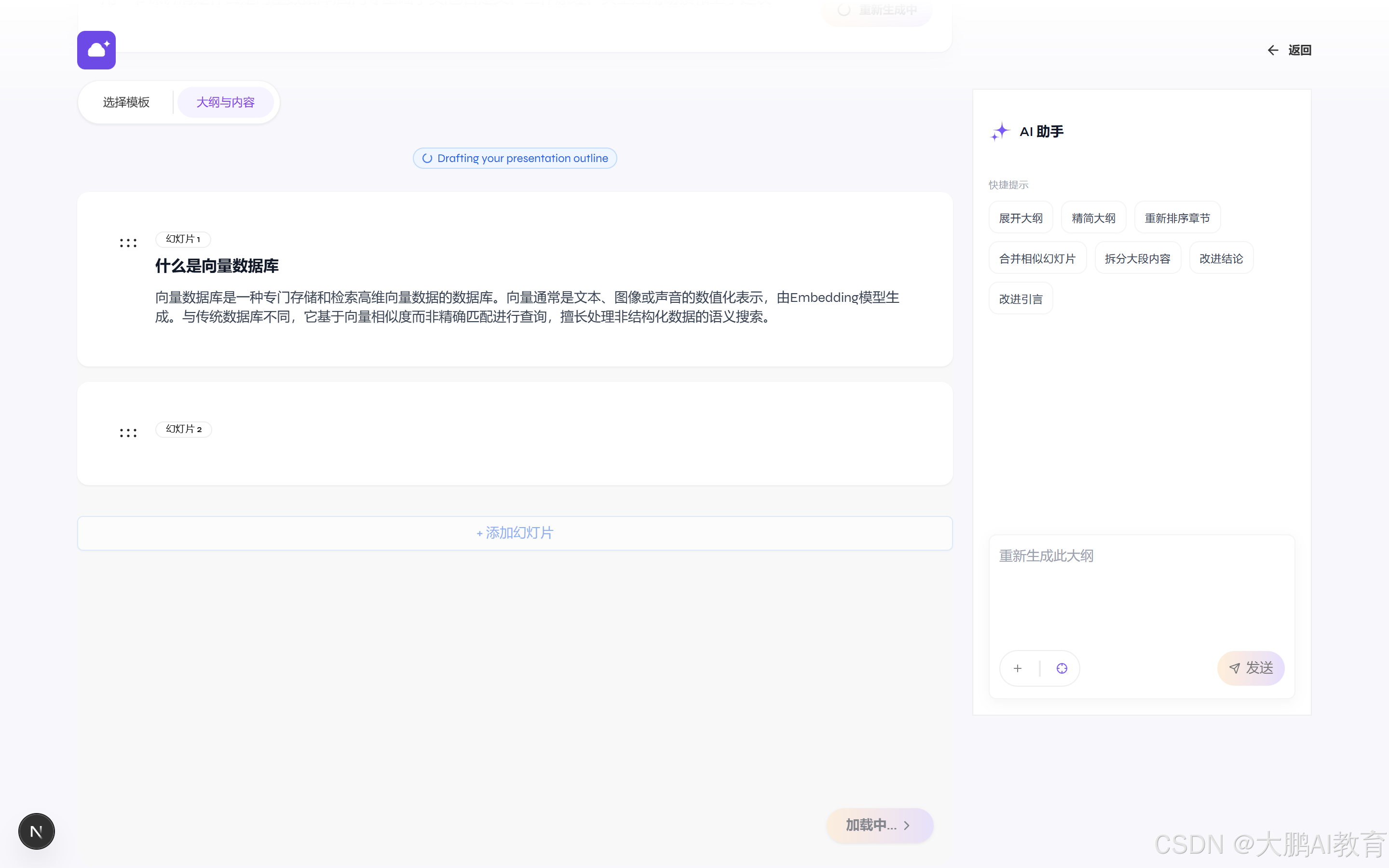
看这张图,幻灯片 1 已经出来了:什么是向量数据库,向量数据库是一种专门用来存储和检索高维向量数据的数据库,向量通常是文本、图像或声音的数值化表示,由 Embedding 模型生成...... 而且这些字是一个一个流式蹦出来的,不是憋半天一次性甩给你。
这对应的是流水线的第一阶段,代码在 servers/fastapi/utils/llm_calls/generate_presentation_outlines.py。我盯着后端日志,这一步打的是一个流式接口:
GET /api/v1/ppt/outlines/stream/{presentation_id} 200为什么先出大纲?这是它设计得聪明的地方:把"写一套 PPT"这个大任务,先拆成"列一个提纲"这个小任务,让你(或者将来让 AI 自己)在最便宜的环节先把方向定对。右边还有个 AI 助手,能展开大纲、精简大纲、重新排序章节,都是在大纲这一层做文章。
不过我也逮到一个小瑕疵:图里那行 Drafting your presentation outline 是英文的。我去翻了代码,这句状态文案是后端发过来的 ,前端按"服务端来的状态不强行翻译"的原则原样显示了。界面其余部分都是中文,就这一句露了英文。这种小地方,正是真跑一遍才抓得到的,我记进了优化清单。
第四步:大纲 → 选版面 → 逐页填充
大纲我看着没问题,点"生成演示文稿"。这下后端那条完整流水线才真正转起来。我盯着日志,先后打了这么两个接口:
POST /api/v1/ppt/presentation/prepare 200 # 前端把模板的 Schema 交给后端
GET /api/v1/ppt/presentation/stream/{id} 200 # 逐页生成开始中间发生的事,对应流水线的第二、第三阶段:
- 第二阶段,选版面 (
generate_presentation_structure.py):给大纲里的每一页,挑一个最合适的版式。注意,这一步只挑版面、不产文字。 - 第三阶段,逐页填充 (
generate_slide_content.py):按选定版式的 Schema,把每一页的内容填进去。
第三阶段这里我得多说一句,因为它直接关系到中文课件做得正不正。我在代码里看到这么一段写给模型的硬规矩(就在 generate_slide_content.py 里):所有输出文本必须严格用目标语言,Schema 里那些英文的字段描述和默认值只是结构图纸,绝不许照抄进内容里。 这就是为什么我中文稿出来,表头、标签也都是中文,没有那种半中半洋的尴尬。这块加固,是我上个版本 v0.1.1 专门做的,下一篇细讲。
第五步:进编辑器,一套成稿摆在面前
逐页生成完,它自动把我带进了编辑器。一份 4 页的中文演示文稿,成了。
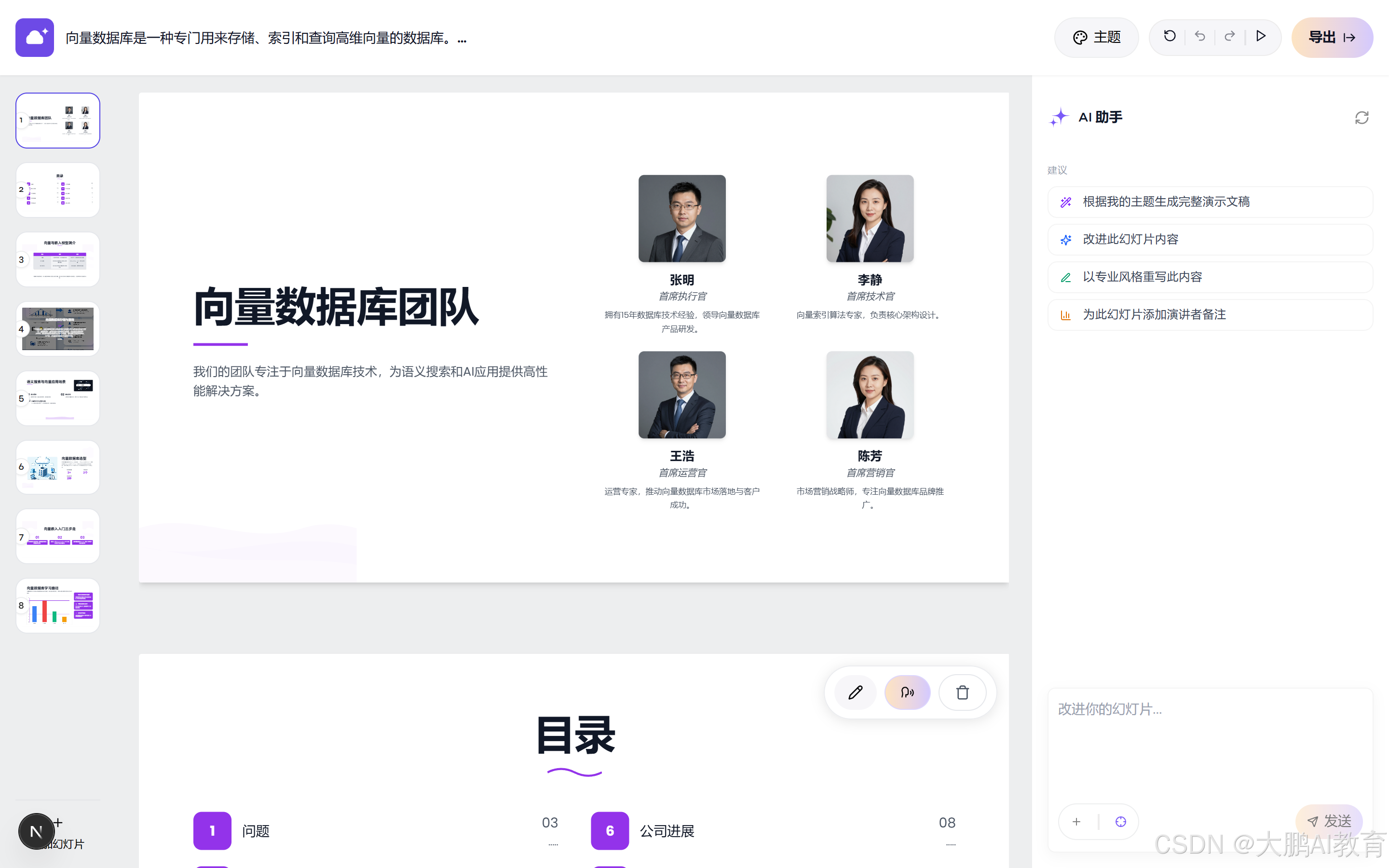
这个界面就很完整了:左边是每一页的缩略图,中间是当前页的所见即所得,右边是一个 AI 助手,能"根据主题生成完整演示文稿""改进幻灯片内容""以专业风格重写""加演讲者备注"。右上角还有主题切换和导出。从一句话,到这一屏,全程我就输入了一句话、选了一个模板、点了两次按钮。
实测翻车现场:通用模板把我的"课"做成了"商业路演"
好,说说翻车。看上面那张编辑器的截图,主视图那一页是什么?向量数据库团队,张明首席执行官,李静首席技术官...... 我让它讲一节"什么是向量数据库"的课,它给我编了一个公司团队页,后面目录里还有"公司进展"。
这是怎么回事?根子就在第二步我随手选的那个通用模板 。它的版式集是偏商业路演的,自带团队介绍、公司数据这类版面。于是第二阶段"选版面"的时候,就把我这份教学大纲,硬套进了一个商业 pitch 的结构里,第三阶段再一填充,就编出了一个不存在的团队。
内容是对的,结构跑偏了。 这件事给我两个很实在的提醒:
- 模板选择对结果的影响,比想象中大得多。 同样一句话,我要是选了"教育"模板,结构大概率就正经多了。
- 对我要做的课件产品 来说,光让用户自己选模板还不够,产品应该更主动地引导甚至替用户判断,一节课该用什么版面结构。这正是我后面要往"纯 AI 驱动"改造的发力点之一:让 AI 自己审一遍"这个结构配不配这节课",不对就重来。
另外两个小发现也一并记下:一是上面说的英文状态文案;二是它配图标用的是一个本地向量模型,第一次跑要从外网下模型、还走的 CPU,初始化很慢。我这台机器 GPU 很强,这种本地模型不该走 CPU,这笔账我记下了。
至于导出,它的设计很巧:用一个无头 Chromium 把你编辑器里看到的页面原样渲染、截图、再组装成 PPTX 或 PDF (代码在 services/export_task_service.py),所以导出的和你看到的像素级一致。我这次的环境没装那个导出运行时,导出没跑,这块我留到后面补上跑通了再给大家完整演示。
写在最后
实测下来,结论很清楚:它确实能做到"一句话生成一整套 PPT",而且全程是流式、分阶段、可干预的,国产模型也能稳稳跑通。 这已经比那种"让大模型直接吐一坨 HTML"的玩具强太多了。
但你也看到了,"能用"和"好用"、和我追求的"纯 AI 驱动"之间,还隔着一段路:结构会跑偏、个别文案没中文化、本地模型没用上 GPU。这些今天被我亲手跑出来的问题,就是我下一步要一个个去优化的清单。 真跑一遍的价值就在这,纸上看着挺好的流程,跑起来才知道哪儿硌脚。
下一篇,我讲讲怎么把这个开源项目,名正言顺地变成我自己的产品。我们下一篇见。
本文为真实实测:模型为 DeepSeek-V4-Pro(接国产 provider 硅基流动),生成主题为"向量数据库入门课",截图均取自本地实跑的真实界面。流程论断对照后端流水线代码核实:大纲 generate_presentation_outlines.py、选版面 generate_presentation_structure.py、逐页填充 generate_slide_content.py、导出 services/export_task_service.py;实测接口为 /presentation/create、/template/all、/outlines/stream、/presentation/prepare、/presentation/stream。