在分布式数据库架构中,数据一致性、持久性与系统性能构成了一个不可能三角。MongoDB 作为文档型 NoSQL 数据库的代表,通过读写关注(Read/Write Concern)机制,将 CAP 理论的权衡交还给开发者。读写关注并非简单的配置参数,而是决定系统数据可见性、持久化程度以及操作延迟的核心契约。
一、写关注(Write Concern):数据持久化的确认契约
写关注定义了 MongoDB 对写操作(Insert、Update、Delete)的确认(Acknowledgment)策略。它直接决定了数据何时被视为"已提交",以及主节点发生故障时数据丢失的风险概率。
1. 核心参数解析
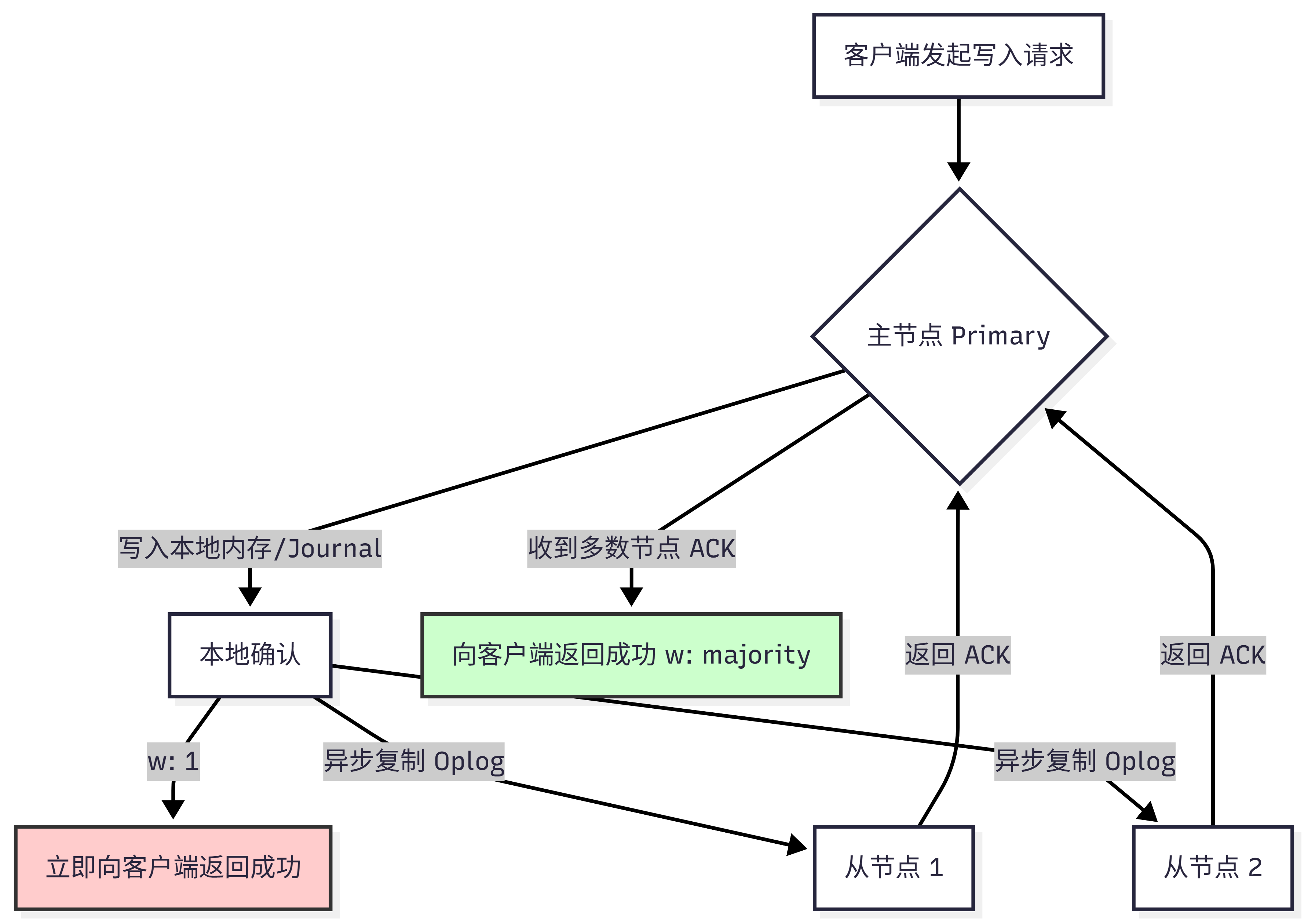
w: 1(默认):仅要求主节点(Primary)确认数据已写入内存。这是性能最高的配置,但如果主节点在数据复制到从节点前宕机且未能恢复,该数据将永久丢失。w: "majority":要求数据被写入到复制集中大多数有投票权的节点(Majority of voting members)后才返回成功。这从根本上消除了单点故障导致的数据丢失风险。j: true:要求主节点必须将数据写入 Journal(WAL 日志)并落盘后才返回确认。结合w: "majority"使用,可实现金融级的数据安全保障。wtimeout:等待多数节点确认的超时时间。必须合理设置,否则在网络抖动时可能导致写操作无限期挂起。
2. 多数派确认机制(Majority Acknowledgement)
写关注 w: "majority" 的底层逻辑依赖于 Oplog(操作日志)的复制。当客户端发起写入时,主节点先本地写入,随后异步将 Oplog 推送给从节点。只有当主节点收到来自多数节点的 ACK 后,才会向客户端返回成功。
3. 写关注数据流转机制
以下流程图展示了 w: "majority" 与 w: 1 在数据确认路径上的本质差异:
4. 生产环境避坑指南(写关注)
- 陷阱 :在核心业务(如订单、余额)中使用
w: 1以追求极致性能。 - 规避 :核心数据必须将
{ w: "majority", j: true }作为安全底线。虽然相比w: 1,w: "majority"会带来约 40%-60% 的吞吐量下降和更高的延迟,但它能消除 100% 的节点故障数据丢失风险。
二、读关注(Read Concern):数据可见性与隔离级别
读关注决定了读取操作能够看到何种状态的数据,是防止脏读、确保事务隔离性的关键。
1. 核心级别解析
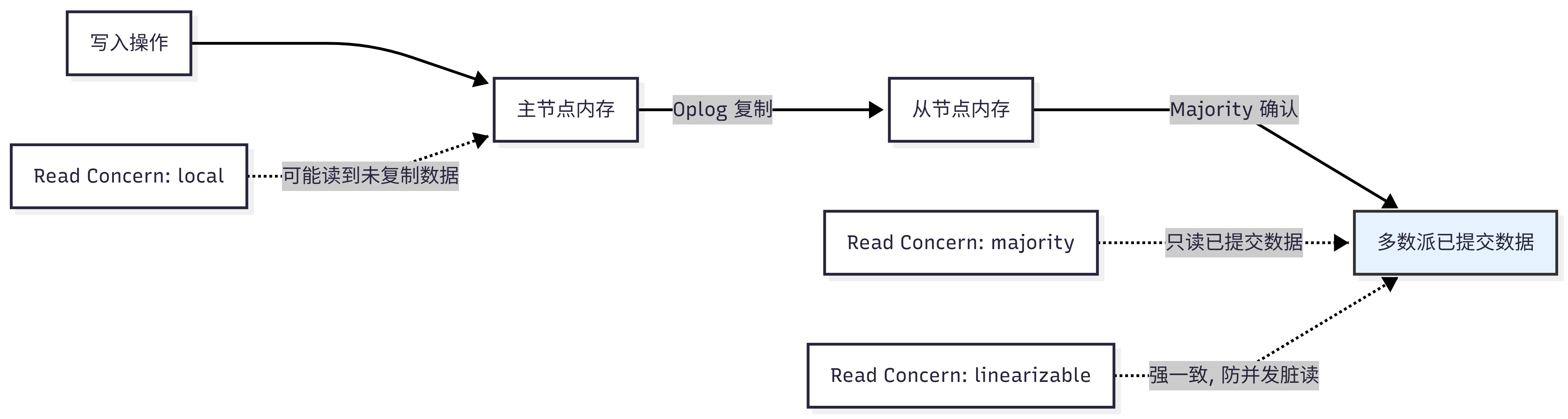
local:返回本地节点上最新的数据,不保证该数据是否已被多数节点复制。如果主节点发生回滚(Rollback),读到的数据可能是"孤儿数据"。majority:仅返回已被多数节点确认的数据。这保证了读取到的数据绝对不会因主节点故障而丢失,是因果一致性的基础。linearizable:最高隔离级别,保证读取到的是最新的、绝对真实的数据。即使并发写入,也能保证线性一致性。通常需配合{ maxTimeMS }使用,防止无限等待。snapshot:仅用于多文档事务中,保证事务内读取到一致的数据快照。
2. 读关注的数据可见性逻辑
不同的读关注级别决定了客户端能"看"到数据流的哪个阶段:
3. 生产环境避坑指南(读关注)
- 陷阱 :在读写分离架构中,对从节点使用
local读关注进行关键业务查询,导致主从切换时读到过期或已回滚的数据。 - 规避 :对于强一致性要求的查询,必须使用
majority读关注。仅在容忍短暂数据过期且对性能极度敏感的场景(如非关键的统计报表、用户会话缓存)下,才降级使用local。
三、读偏好(Read Preference):请求路由与负载均衡
读偏好控制的是客户端的读请求应该路由到副本集中的哪一个节点。它与读关注解决的是完全不同的问题:读关注决定"数据的状态",读偏好决定"去哪里读"。
1. 核心路由模式解析
primary(默认):所有读操作仅路由到主节点。保证强一致性,但主节点可能成为读瓶颈。secondaryPreferred:优先从从节点读取,如果从节点不可用(如副本集仅剩主节点),则自动回退到主节点。secondary:仅从从节点读取。如果所有从节点不可用,读取操作将报错。nearest:根据网络延迟,从拓扑中距离最近的节点读取(无论主从),最大限度减少网络延迟。primaryPreferred:优先从主节点读取,主节点不可用时降级到从节点。
2. 生产环境避坑指南(读偏好)
- 陷阱 :为了"分担主节点压力",盲目将核心业务查询设置为
secondaryPreferred。由于 MongoDB 的异步复制机制,从节点必然存在复制延迟,这会导致应用读到"过时数据",甚至引发非单调读取(Non-monotonic reads)。 - 规避 :不要单纯为了增加读容量而使用从节点读取。如果应用需要分担读负载,更好的策略是通过分片集群(Sharding)水平扩展。若必须使用
secondaryPreferred,务必配合"客户端会话(Client Session)"和因果一致性来保证单调读取。
四、性能与一致性的黄金平衡法则
在实际架构设计中,不存在完美的配置,只有最适合业务的权衡。以下是生产环境的数据敏感度矩阵与配置建议:
| 数据类型 | 丢失容忍度 | 过期容忍度 | 推荐写关注 (Write Concern) | 推荐读关注 (Read Concern) | 推荐读偏好 (Read Preference) | 性能影响评估 |
|---|---|---|---|---|---|---|
| 金融交易/订单 | 0% | 0% | { w: "majority", j: true } |
majority |
primary |
延迟增加 70-90%,吞吐量显著下降 |
| 核心业务数据 | < 0.01% | 5s | { w: "majority" } |
majority |
primary |
延迟增加 40-60%,推荐作为基线 |
| 用户会话/日志 | < 1% | 30s | { w: 1 } |
local |
secondaryPreferred |
基准性能,延迟最低 |
| 跨地域多活读取 | 0% | 视网络延迟 | { w: "majority" } |
majority |
nearest |
降低跨区网络延迟,保障本地读取 |
动态治理策略 :
不要在生产环境中使用一成不变的配置。应建立完善的监控体系,当复制延迟(Replication Lag)超过 500ms 或 wtimeout 错误率超过 0.5% 时,系统应具备动态降级读关注至 local 或调整 wtimeout 的应急能力。
五、高频面试题
Q1:为什么 MongoDB 官方建议将 w: "majority" 作为生产环境的默认写关注?
答 :在分布式复制集中,主节点故障是常态。w: 1 仅保证主节点写入,若主节点在数据同步前宕机,新主节点选举后,未同步的数据将被回滚(Rollback),导致数据永久丢失。w: "majority" 确保了数据在多数节点落盘,从根本上消除了单点故障带来的数据丢失风险。虽然牺牲了部分性能,但换来了数据的绝对安全。
Q2:Read Concern majority 和 linearizable 有什么本质区别?在什么场景下必须用 linearizable?
答 :majority 保证读取到的数据是"已提交的"(不会丢失),但不保证它是"最新的"(可能读到旧版本)。而 linearizable 提供了强一致性保证,确保读取到的是操作发生时的最新真实状态。linearizable 仅适用于分布式锁、唯一性约束检查等绝对不能出现并发冲突的极端场景,因其需要额外的协调开销,延迟极高,不可滥用。
Q3:什么是因果一致性(Causal Consistency)?它需要怎样的读写关注与读偏好组合?
答 :因果一致性保证了逻辑上存在先后依赖的操作,在客户端观察到的结果也符合这一先后顺序。要实现因果一致性,必须在同一个客户端会话(Client Session)中,配合使用 Read Concern: majority、Write Concern: majority,并使用 Read Preference: secondaryPreferred。这是构建跨会话、跨节点数据逻辑连贯性的基础。
Q4:在读写分离架构中,使用 secondaryPreferred 读偏好时,如何避免从节点读到"脏数据"或"过期数据"?
答 :从节点的数据同步是异步的,必然存在复制延迟。如果业务对数据新鲜度有要求,不应盲目使用 secondaryPreferred。正确的做法是:对强一致性查询强制路由到主节点并使用 majority 读关注;对容忍延迟的查询使用 secondaryPreferred,并结合业务层的重试机制或缓存策略来弥补数据延迟。
Q5:设置了 w: "majority" 后,写入延迟显著增加,除了增加节点硬件资源,还有哪些优化手段?
答 :首先,检查复制集的网络拓扑,确保节点间网络延迟在合理范围(通常要求 < 200ms)。其次,合理设置 wtimeout,避免因个别慢节点导致整体写入阻塞。最后,进行业务分层,不要对所有操作都使用 majority,仅对核心交易链路开启强一致写,非核心链路(如埋点、日志)降级为 w: 1,通过架构分层来平衡整体系统的吞吐量。