本文主要记录如何分析Linux下的资源占用
top
在此之前,先熟悉下top命令
参考:
深入理解 Linux top 命令:从字段解读到性能诊断 - 知乎
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
top的使用方式 top -d number | top -bnp
参数 含义 -d number number代表秒数,表示top命令显示的页面更新一次的间隔 (default=5s) -b 以批次的方式执行top -n 与-b配合使用,表示需要进行几次top命令的输出结果 -p 指定特定的pid进程号进行观察 我们先直接top看看啥样的
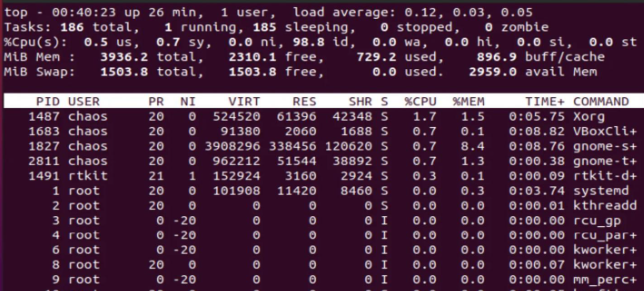
第一行系统总体信息
top - 00:40:23 up 26 min, 1 user, load average: 0.12, 0.03, 0.05从左往右的内容如下
- 当前时间:00:40:23
- 系统运行时间:已运行 26 分钟
- 当前登录用户数:1
- Load Average(平均负载):过去 1 分钟、5 分钟、15 分钟的系统平均负载,分别为 0.12、0.03 和 0.05,说明系统非常空闲。
第二行:任务信息(Tasks)
Tasks: 186 total, 1 running, 185 sleeping, 0 stopped, 0 zombie说明当前有 186 个任务,其中只有 1 个正在运行,其余都处于休眠状态,系统负载极低。
第三行:CPU 使用情况
%Cpu(s): 0.5 us, 0.7 sy, 0.0 ni, 98.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
字段 说明 us 用户空间占用 CPU 的百分比(业务逻辑) sy 内核空间占用 CPU 的百分比(系统调用) ni 调整 nice 值(进程优先级)所占用的 CPU id 空闲 CPU 时间 wa 等待 IO 的 CPU 时间(磁盘/网络等) hi 硬件中断消耗的 CPU 时间 si 软件中断消耗的 CPU 时间 st 被虚拟机偷走的 CPU 时间(在虚拟化环境中常见) 第四/五行:内存和交换空间使用
第四行是物理内存,第五行是Swap交换空间
MiB Mem : 3936.2 total, 2310.1 free, 729.2 used, 896.9 buff/cache MiB Swap: 1503.8 total, 1503.8 free, 0.0 used. 2959.0 avail Mem
指标 含义 free 空闲的内存 used 已使用内存 729MB buff/cache 用于缓存文件和块设备的内存为 896.9MB avail Mem 实际可供程序使用的内存 Swap 没有使用任何交换空间,系统内存压力为 0 剩余内容 进程列表(按 %CPU 排序)
最后的内容是每个进程的资源,字段内容说明如下
字段名 说明 PID 进程 ID 编号 USER 进程的持有用户 PR 进程运行的优先级,值越小优先级越高,会越早获得 CPU 的执行权 NI 进程的 nice 值,表示进程可被执行的优先级的修正数值 VIRT 进程使用的虚拟内存总大小,单位为 KB RES 进程使用的并且未被虚拟内存换出的物理内存大小(常驻内存),单位为 KB SHR 进程使用的共享内存大小,单位为 KB S 进程当前的运行状态:• D:不可中断的睡眠状态• R:运行中• S:休眠中• T:跟踪/停止• Z:僵死中(Zombie) %CPU 进程运行时 CPU 的占用比 %MEM 进程使用的内存占用比 TIME+ 进程占用的 CPU 总时长 COMMAND 正在运行的命令名称 以上就是简单认识下top的输出结果。
上面的是单核CPU,下面看看多核CPU的情况
第三至六行:CPU核心使用率
%Cpu0到%Cpu3表示你有 4个CPU核心 。每行的数据格式是us/sy,并有一个综合百分比。
us(用户空间):运行应用程序消耗的CPU。
sy(内核空间):运行内核代码消耗的CPU。后面的数字 (如
18、100、11、42)是总的CPU使用率。关键发现:
CPU 1 使用率达到了 100% ,其中
59.1%是用户程序,40.9%是内核。CPU 3 使用率为 42% ,其中
38.8%是用户程序,3.0%是内核。CPU 0 和 2 的使用率相对较低。
这说明有一个多线程程序(或几个程序)正在大量消耗CPU资源,主要集中在 CPU 1 和 CPU 3 上。
top命令显示的页面还可以输入以下按键执行相应的功能(注意大小写区分的)
快捷键 含义 M 按内存使用排序 P 按 CPU 使用率排序(默认) 1 显示所有 CPU 核心的使用情况 k 杀掉某个进程(输入 PID 后终止) h 帮助菜单 q 退出 top 更多待补充

load average
top命令里的平均负载 ,简单说就是在过去一段时间里,你的系统平均有多少个进程正在等待使用CPU。它通常显示为三个数字,比如你之前看到的
load average: 2.02, 1.83, 1.60。这三个数字分别代表过去1分钟、5分钟、15分钟的平均值。如何解读这三个数字?
1分钟负载:是当前最实时的"热度",如果这个数字长期很高,说明系统正在经历突发的高负载。
5分钟负载 :代表了中期的趋势。如果它比1分钟负载高,说明负载正在上升 ;如果比1分钟负载低,说明负载正在下降。
15分钟负载:反映了系统长期的"平均水位",可以帮你判断问题是暂时的波动还是常态。
如何判断负载是否"正常"?
关键规则 :平均负载的"健康值"取决于你的 CPU核心数。
理想状态 :负载 ≤ 核心数 × 0.7。表示系统非常轻松。
临界状态 :负载 ≈ 核心数。表示CPU刚好用满,是性能的甜点区。
过载状态 :负载 > 核心数 × 1.5 ~ 2。表示有进程在排队,系统响应可能会变慢。
在你之前的示例中,系统有 4个CPU核心 (
%Cpu0~%Cpu3),而平均负载是 2.02。
因为 2.02 < 4,说明总体负载没有超过CPU的总处理能力。
但负载已经超过了核心数的一半 (
4 x 0.7 = 2.8是理想上限),说明系统不算空闲,正处于中高负载状态,如果负载继续攀升,性能就可能会下降。一个常见的误解
平均负载不等于 CPU 使用率。
CPU使用率:反映的是CPU有多"忙"。
平均负载:反映的是有多少进程在等待使用CPU。
我们把CPU想象成一个收费站 ,进程是汽车。
CPU核心数 = 收费窗口的数量(你这里是2个)。
负载值 2.0 = 平均有2辆车停在收费站区域(要么在缴费,要么在排队)。
现在来验证你的推导:你说"分摊后每秒只有一个进程在使用CPU",这相当于在说"收费站平均只有1个窗口在工作"。
但在我们的排队模型里,负载是2.0意味着:
如果队列里没有车排队 :那说明2个窗口(CPU核心)都刚好在忙,各有1辆车在缴费。此时CPU利用率是100%,完全没有空闲。
如果队列里有车排队:那说明2个窗口不够用,有车在排队等待。此时CPU超负荷运行。
对于双核CPU,负载值在数值上等于核心数(2.0)时,意味着CPU资源恰好被用尽,利用率达到100%。这绝对不叫"空闲",而是"满载"的临界点。
实际上,一个CPU核心在一秒钟内,可以交替运行成百上千个进程。比如进程A运行1毫秒,然后切换给进程B运行1毫秒。
平均负载为2,说的是"在任意一个瞬间,平均有2个进程在等着用CPU",而不是"一秒钟内只有2个进程用过CPU"。如果一秒钟内只有2个进程,那CPU确实很闲,但这种情况负载会接近0,而不是2。
%CPU列
top或htop中%CPU这一列的含义,和你理解的可能有点不同。它的统计口径是:一个进程在采样周期内,消耗的所有 CPU 时间,占 单个 CPU 核心总处理能力的百分比。
核心概念:单核百分比
%CPU的 100% ,代表占满了 一个 CPU 核心。
如果一个程序是单线程且一直在计算,在4核系统上,它的
%CPU最大值就是 100%。如果一个程序是多线程且能并行,比如开了4个线程同时满负荷计算,它的
%CPU可以达到 400%。所以,
%CPU的值可以超过 100%,上限是核心数 × 100%。一个容易混淆的地方:与平均负载无关
%CPU只反映进程消耗CPU时间的多少 ,不反映它排队等待的情况。
- 如果一个进程卡在I/O上,它几乎不消耗CPU时间,
%CPU会接近 0%。但它依然可能处于"不可中断睡眠"状态,导致系统平均负载(Load Average) 升高。这也是为什么会出现"CPU使用率看起来不高,但系统响应很慢"的原因------高负载可能源于I/O或锁等待,而非计算任务。
举例说明
场景 CPU核心数 %CPU显示实际含义 单线程死循环 4 100% 占满了1个核心,整体CPU使用率25% 4线程全速计算 4 400% 占满了全部4个核心,整体CPU使用率100% 进程卡在I/O 4 接近0% 几乎没用CPU,但可能在等待磁盘,导致负载升高
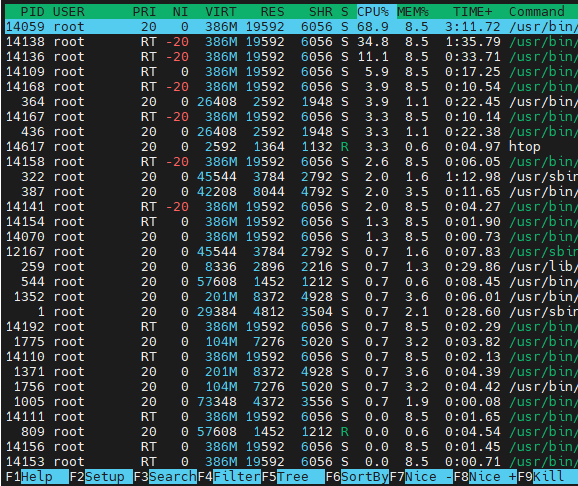
htop
htop是top命令的增强版,它提供了更友好的彩色界面、更直观的操作方式以及更丰富的交互功能,是分析系统负载和进程的更强大工具。✨ htop 的核心优势
相比传统的
top,htop主要有这几个优点:
彩色界面,一目了然:CPU、内存、Swap 的使用情况会用不同颜色的进度条和数字显示,非常直观。
支持鼠标操作:你可以直接用鼠标点击界面元素,比如点击列标题,就可以按该列排序,操作很方便。
更易用的进程管理 :无需记忆复杂的键盘命令,直接用功能键或鼠标点击就可以结束进程(
kill)、调整进程优先级(nice)。树形视图 :可以按
F5或t键,以树形结构展示进程的父子关系,方便你追溯程序的启动源头。进程筛选 :按
F4或/键,可以输入关键字,只显示匹配的进程,这在进程很多时定位特定程序非常方便。⌨️ 常用快捷键
如果你手上没有鼠标,或者在远程终端里操作,记住这几个快捷键会很有帮助:
快捷键 功能 说明 F1/h显示帮助 查看所有快捷键的完整列表 F2/S设置 可以调整显示风格、度量单位等 F3//搜索 高亮显示匹配的进程,可以用 F3跳到下一个F4/\过滤 只显示名称匹配的进程,输入关键字后实时过滤 F5/t树形视图 切换显示进程树,方便看清父子关系 F6排序 选择按哪一列排序(CPU、内存、PID 等),按 Enter确认F9/k结束进程 向选中的进程发送信号(默认为 SIGTERM)F10/q退出 退出 htopSpace(空格)标记进程 标记一个或多个进程,方便对它们执行批量操作 u显示特定用户进程 选择一个用户,只显示该用户拥有的进程 P按CPU使用率排序 快速找到最耗CPU的进程 M按内存使用率排序 快速找到最耗内存的进程 I按I/O使用率排序 找到读写磁盘最频繁的进程(如果内核支持) 🚀 安装 htop
如果你的系统还没有安装
htop,可以用下面的命令快速安装(根据你的发行版选择):bash
# Debian/Ubuntu sudo apt install htop # RHEL/CentOS/Fedora sudo yum install htop # 或使用 dnf install htop # OpenWrt (如果你在折腾路由器) opkg install htop总的来说,
htop是一个功能更强大、更友好的系统监控工具。学会使用它,可以让你快速定位系统资源消耗大户,是排查性能问题的得力助手。

分析CPU占用
在Linux下分析CPU占用,核心是使用
top或htop进行快速定位,然后根据情况使用pidstat、perf等工具进行深入分析。下面是一个由浅入深的实用指南。第一步:快速定位系统全局情况
当感觉系统变慢时,首先使用
top命令查看整体负载。
top第一步:全局概览------看整体压力
直接输入
top并关注前 5 行:
load average(平均负载):判断系统整体是否"堵车"。
- 关键 :用
nproc命令查看核心数。如果负载长期 > 核心数 × 1.5,说明系统严重过载。
%Cpu(s)行:判断 CPU 时间花在了哪里。
us(用户空间)高:应用进程在大量计算。
sy(内核空间)高:程序在进行大量系统调用或内核操作。
wa(I/O 等待)高:瓶颈在磁盘或网络 I/O,CPU 在空等。
id(空闲)低:CPU 整体处于忙碌状态。第二步:定位进程------找到消耗大户
找到全局问题后,按下面的快捷键在进程列表里定位:
按
P键(大写) :进程按%CPU使用率从高到低排序。这是最常用的操作,能立刻看到谁在消耗 CPU。观察
%CPU列:
如果数值 > 100%,说明该进程是多线程的,占用了多个 CPU 核心。
如果数值接近 100% 或更高,这个进程就是主要的 CPU 消耗者。
按
M键(大写):进程按内存使用率排序,可辅助排查内存泄漏导致的性能问题。第三步:深入线程------找出进程内的"罪魁祸首"
定位到可疑进程(比如
PID 11336)后,需要分析它内部的线程。
显示进程内的线程 :在
top界面中,按H键(大写)切换到线程视图 。此时列表中的每一行代表一个线程,PID列会变成TID(线程 ID)。排序并观察 :再次按
P键,让线程按 CPU 使用率排序。关键判断:
如果有一个线程的
%CPU始终很高(如 80%~100%),通常是死循环 或计算密集的逻辑,需要优化代码。如果有很多线程的
%CPU都很低(如 1%~5%),但总和很高,则可能是大量上下文切换 或锁竞争导致。记住这个高 CPU 的线程 ID (
TID),它会成为后续排查的关键线索。切回进程视图 :按
H键可以切回默认的进程视图。第四步:追溯问题根源------结合日志和代码
拿到高 CPU 的
TID(线程 ID)后,可以配合日志做进一步分析:
查看进程状态 :按
f键进入字段管理,用空格选中WCHAN(等待通道)和COMMAND字段,然后按q退出。这能帮你看到线程当前在内核中卡在哪个函数上(如futex表示锁等待,sk_wait_data表示网络等待)。结合系统日志 :退出
top,用dmesg | grep <进程名>或journalctl查看内核日志,有时能捕获到内核抛出的异常(比如你之前遇到的段错误)。查看文件描述符 :对于疑似 I/O 问题的线程,可以使用
ls -l /proc/<PID>/fd/查看进程打开的文件,判断是否在频繁读写同一文件。
分析内存占用
在 Linux 中,初步分析内存占用 通常遵循一个思路:先看整体内存使用概况,再看哪些进程消耗了内存,最后判断是否有内存泄漏或缓存占用过高。
下面是一套实用的、仅用系统自带工具就能完成的初步分析方法。
第一步:全局概览------看整体内存状态
使用
free -h命令快速查看内存概况:
free -h输出示例:
total used free shared buff/cache available Mem: 7.6G 2.1G 1.2G 123M 4.3G 5.0G Swap: 2.0G 0.0K 2.0G关键列解读:
列名 含义 判断标准 total总物理内存 --- used已使用的内存(含缓存) 这个值高不一定有问题 free完全未使用的内存 如果接近 0,说明内存用得很满 buff/cache缓冲区 + 缓存 这是 Linux 为了提速而主动占用的,可以随时被回收,不用太担心 available应用程序实际可用的内存 这是最值得关注的值,如果这个值很小(如 < 10%),说明内存真的紧张 核心判断规则:
看
available而不是free,因为 Linux 会主动用空闲内存做缓存。如果
available持续很低,且Swap使用率在增长,说明物理内存确实不足。
第二步:定位进程------谁在吃内存
使用
ps或top找出内存占用最高的进程。方法一:
ps静态快照(推荐)
# 按内存使用率排序,显示前 10 个进程 ps aux --sort=-%mem | head -10输出示例:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1234 5.6 45.2 123456 987654 ? Ssl 10:00 5:23 /usr/bin/helper root 5678 0.1 8.3 45678 123456 ? S 10:01 0:12 /usr/sbin/sshd关键列解读:
列 含义 %MEM进程占物理内存(RSS)的百分比 VSZ虚拟内存大小(包括已交换、已映射的库等) RSS驻留物理内存大小(实际占用的物理内存) 重点关注
%MEM和RSS列,找出占比异常的进程。方法二:
top动态查看进入
top后按M键(大写),进程列表会按内存使用率从高到低排序。观察RES列(实际物理内存)和%MEM列。
第三步:判断内存是否泄漏
如果发现某个进程的内存占用持续增长且不回落,可能存在内存泄漏。
方法:监控进程内存变化
# 每 2 秒查看一次指定进程的内存占用 watch -n 2 "ps -p <PID> -o pid,vsz,rss,comm"
VSZ(虚拟内存)持续增长:可能存在虚拟内存泄漏(如映射了文件但未释放)。
RSS(物理内存)持续增长 :可能存在物理内存泄漏(如malloc了内存但未free)。一个更简单的观察方式:
在
top中记下可疑进程的RES值,等 5 分钟后再看,如果它持续增长且不回落,就值得深入排查。
第四步:区分"缓存占用"和"真实占用"
很多新手看到
free -h中used很高就担心内存不足,但实际上buff/cache是可回收的。如何确认内存是否真的紧张?
# 查看系统内存回收压力 cat /proc/meminfo | grep -E "^(MemTotal|MemFree|MemAvailable|Buffers|Cached|SwapTotal|SwapFree)"关键指标:
MemAvailable是系统估算的"可用于启动新应用的内存",这个值低才说明内存紧张。如果
SwapFree在持续减少,说明系统开始使用交换分区,物理内存已不足。
第五步:快速排查常见问题
现象 可能原因 排查方向 available很小物理内存不足 检查是否有大进程、内存泄漏 某个进程 %MEM异常高该进程有内存问题 用 pmap -x <PID>看内存映射详情buff/cache占用极高正常现象(Linux 缓存策略) 可用 sync && echo 3 > /proc/sys/vm/drop_caches手动清理缓存(仅测试用)Swap 使用率持续增长 物理内存不足,系统在换页 需要增加物理内存或优化应用 进程 VSZ远大于RSS进程分配了大量虚拟内存但未使用 可能是预留了内存池,不一定是问题
📋 核心命令速查表
使用场景 推荐命令 整体内存概况 free -h内存 TOP 进程 `ps aux --sort=-%mem 监控进程内存变化 watch -n 2 "ps -p <PID> -o pid,vsz,rss,comm"查看内存详细信息 cat /proc/meminfo查看进程内存映射 pmap -x <PID>统计进程内存总和 `ps aux
一句话总结 :用
free -h看整体(重点关注available),用ps aux --sort=-%mem找具体进程,通过watch监控变化趋势来判断是否存在内存泄漏。如果available持续偏低且 Swap 在增长,就需要考虑加内存或优化应用了。
分析flash占用
在 Linux 嵌入式设备(如你正在调试的智能家居设备)中,初步分析 Flash 占用,本质就是查看存储空间的使用情况 ,重点关注系统分区、应用和日志是否把空间占满。
💡 核心概念:Flash 在 Linux 下的"模样"
在嵌入式 Linux 中,Flash 通常被划分为多个分区,并挂载为不同的目录,最常见的包括:
根文件系统 (
/) :存放操作系统、库文件和应用程序(如你的helper)。/data 或 /userdata:存放用户数据和配置。
/tmp:通常挂载为内存文件系统 (tmpfs),重启后数据会丢失。
因此,分析 Flash 占用,其实就是分析这些挂载点的磁盘使用情况。
第一步:全局概览------查看各分区大小和使用率
使用
df -h命令查看所有已挂载分区的空间使用情况。
df -h输出示例:
Filesystem Size Used Avail Use% Mounted on /dev/root 2.3G 1.2G 1.0G 55% / devtmpfs 3.9G 0 3.9G 0% /dev tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/data 5.8G 4.2G 1.4G 76% /data重点关注:
Use%:已用百分比。如果这个值长期超过 85%,就需要关注了。
Mounted on:挂载点。重点关注/(根分区)和存放应用日志的分区(如/data或/var)。
Avail:剩余空间。如果接近 0,系统可能无法正常写入日志或保存配置。关键判断:
/分区满了:可能导致系统无法创建临时文件、无法启动新服务,甚至系统崩溃。
/data或/var分区满了 :可能导致应用无法写入日志、OTA 升级包无法下载,这在你的helper场景中尤其需要注意。
第二步:定位大文件------谁在吃空间?
找到空间紧张的分区(比如
/data)后,使用du命令深入分析该目录下的大文件。1. 查看当前目录下各子目录的大小
# 显示当前目录下每个子目录的大小,并按大小排序 du -sh * | sort -rh | head -10
du -sh *:统计当前目录下每个目录或文件的大小。
sort -rh:按大小从大到小排序,-r表示降序,-h表示识别人类可读单位(如 K、M、G)。
head -10:只显示最大的前 10 个。2. 递归查看特定目录(如
/data)
du -h /data --max-depth=1 | sort -rh | head -10这个命令会先找出
/data下的第一级子目录中,哪些占用空间最大。输出示例:
4.2G /data/logs 800M /data/app 120M /data/ota ...这里能清晰地看到,是日志目录 (
logs) 或 OTA 升级包目录占用了大量空间。
第三步:常见空间杀手及处理
在嵌入式设备中,空间通常被以下几类文件耗尽:
常见占用 典型路径 处理方法 应用日志文件 /var/log/、/data/log/检查日志大小,考虑日志轮替 ( logrotate) 或定期清理。OTA 升级包 /data/ota/、/tmp/OTA 成功后未删除的升级包;可以检查并清理。 Core Dump 文件 /tmp/、/data/core/由程序崩溃产生的调试文件,通常体积较大;可以清理。 临时文件 /tmp/、/var/tmp/系统或应用产生的临时文件;可以清理。 数据库文件 /data/db/如 SQLite 等数据库文件,需要检查是否有数据膨胀,可能需业务处理。
📋 核心命令速查表
场景 命令 查看所有分区空间 df -h查看当前目录下最大子目录 `du -sh * 查看指定目录深度1的最大子目录 `du -h /path --max-depth=1 查找大于100M的文件 find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null查找core dump文件 find / -name "core*" -type f -ls 2>/dev/null
✅ 总结
看整体 :用
df -h找出哪个分区快满了。找大文件 :用
du -sh * | sort -rh层层进入,定位到具体目录或文件。处理:根据文件类型(日志、升级包、core dump)决定是清理还是优化策略。