📚 本系列系统梳理了 Java 开发的详细知识点,从基础语法到工程实践层层递进,内容详实成体系,建议先收藏再慢慢阅读,方便日后随时回顾查阅。
前言
JVM 是 Java 程序运行的基石------理解它的内存结构、类加载机制和垃圾回收原理,不仅面试必考,更是排查线上 OOM、GC 停顿、类冲突等问题的前提。这篇文章把 JVM 最核心的三大块知识梳理清楚。
1. JVM 内存结构
JVM 把内存划分为几个区域,各司其职:
JVM 内存
线程共享
堆 (Heap)
新生代
Eden + S0 + S1
老年代
方法区 / 元空间
类信息、常量池、静态变量
线程私有
虚拟机栈
栈帧
程序计数器 (PC)
本地方法栈
1.1 堆(Heap)
存放所有对象实例和数组,是 GC 管理的主要区域。
java
Object obj = new Object(); // obj 引用在栈上,Object 实例在堆上
int[] arr = new int[100]; // 数组对象也在堆上堆分为两大区域:
-
新生代(Young Generation):新创建的对象在这里分配。又细分为 Eden 区和两个 Survivor 区(S0、S1)。大部分对象"朝生夕死",在新生代就被回收。
-
老年代(Old Generation):经过多次 GC 仍然存活的对象被晋升到这里。老年代的对象生命周期长,GC 频率低但耗时长。
对象分配流程:
new Object()
→ Eden 区分配
→ Eden 满了触发 Minor GC
→ 存活对象复制到 Survivor 区
→ 多次 GC 后仍存活(默认 15 次)
→ 晋升到老年代
→ 老年代满了触发 Major GC / Full GC
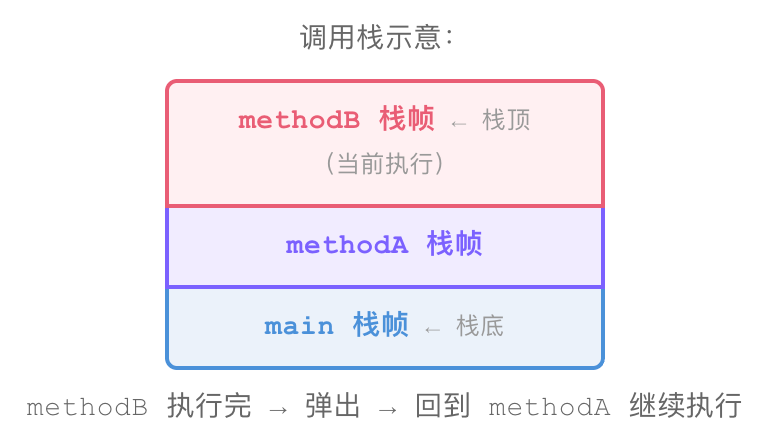
1.2 虚拟机栈(VM Stack)
每个线程一个栈,每调用一个方法就压入一个栈帧(Stack Frame):
java
public void methodA() {
int x = 10; // x 在 methodA 的栈帧中
methodB(x);
}
public void methodB(int y) {
String s = "hello"; // y 和 s 在 methodB 的栈帧中
}栈帧包含:
| 组成部分 | 内容 |
|---|---|
| 局部变量表 | 基本类型的值、对象引用 |
| 操作数栈 | 方法执行时的中间计算结果 |
| 动态链接 | 指向方法区中该方法的引用 |
| 返回地址 | 方法执行完后回到哪里继续执行 |
栈的两种异常:
java
// StackOverflowError:栈深度超限(通常是无限递归)
public void infinite() {
infinite(); // 每次调用压一个栈帧,最终溢出
}
// OutOfMemoryError:创建太多线程,每个线程都要分配栈空间1.3 程序计数器(PC Register)
每个线程一个,记录当前正在执行的字节码指令地址。是 JVM 中唯一不会 OOM 的区域。
1.4 方法区 / 元空间(Metaspace)
存储已加载的类信息、常量、静态变量、JIT 编译后的代码。
Java 7 及之前:方法区在 JVM 内存中(永久代 PermGen),大小有限,容易 OOM
Java 8 开始:改为元空间(Metaspace),使用本地内存(Native Memory),默认不限大小
java
// 元空间溢出场景:动态生成大量类(如 CGLIB 代理、大量 JSP)
// 报错:java.lang.OutOfMemoryError: Metaspace
// 调优:-XX:MaxMetaspaceSize=256m1.5 各区域 OOM 总结
| 区域 | 异常 | 常见原因 |
|---|---|---|
| 堆 | OutOfMemoryError: Java heap space |
对象太多、内存泄漏 |
| 栈 | StackOverflowError |
无限递归、方法调用太深 |
| 栈 | OutOfMemoryError |
线程太多 |
| 元空间 | OutOfMemoryError: Metaspace |
动态生成大量类 |
| 直接内存 | OutOfMemoryError: Direct buffer memory |
NIO ByteBuffer.allocateDirect 过多 |
1.6 JVM 内存区域总结
| 区域 | 线程私有/共享 | 存放内容 | 生命周期 |
|---|---|---|---|
| 堆(Heap) | 共享 | 所有对象实例、数组 | JVM 启动到关闭 |
| 虚拟机栈(VM Stack) | 私有 | 局部变量(基本类型值、对象引用)、方法调用栈帧 | 随线程创建/销毁 |
| 程序计数器(PC Register) | 私有 | 当前执行的字节码指令地址 | 随线程创建/销毁 |
| 方法区 / 元空间(Metaspace) | 共享 | 类信息、常量、静态变量、JIT 编译代码 | JVM 启动到关闭 |
| 本地方法栈(Native Stack) | 私有 | native 方法(如 C/C++ 实现的 JNI 方法)的调用栈 | 随线程创建/销毁 |
一个变量到底存在哪,取决于它是什么:
| 变量类型 | 存放位置 | 示例 |
|---|---|---|
| 局部变量(基本类型) | 栈 | int x = 10; 方法内 |
| 局部变量(引用) | 栈上存引用,堆上存对象 | String s = "hi"; 方法内 |
| 实例变量 | 堆(跟随对象) | private String name; |
| 静态变量 | 方法区 / 元空间 | static int count; |
| 常量 | 方法区的常量池 | static final int MAX = 100; |
2. 类加载机制
2.1 类的生命周期
一个 .class 文件从被加载到内存,到被卸载,经历以下阶段:
加载 → 验证 → 准备 → 解析 → 初始化 → 使用 → 卸载
└─── 连接(Linking) ──┘| 阶段 | 做什么 | 通俗理解 |
|---|---|---|
| 加载 | 读取 .class 文件字节码,在内存中生成 Class 对象 | 把简历读进来 |
| 验证 | 校验字节码是否合法,防止恶意代码 | 查验简历真假 |
| 准备 | 为 static 变量分配内存,赋默认值(0 / null / false) | 先安排工位,名牌空着 |
| 解析 | 将符号引用替换为直接引用(内存地址) | 把"人名"换成"工位号" |
| 初始化 | 执行 static {} 和 static 变量的真正赋值 |
员工正式入职,开始干活 |
准备 vs 初始化是最容易混淆的,用一个例子说明:
java
public class Demo {
static int a = 10; // 准备阶段:a = 0(默认值)
// 初始化阶段:a = 10(真正赋值)
static final int B = 20; // 特殊:编译期常量,准备阶段直接就是 20,不用等初始化
static {
System.out.println("类初始化了"); // 初始化阶段才执行
}
}时间线:
准备阶段完成后: a = 0, B = 20
初始化阶段完成后:a = 10, B = 20, 打印"类初始化了"为什么要分两步? 因为 JVM 需要先给所有 static 变量分配好内存空间(准备),然后才能按代码顺序执行赋值和 static 代码块(初始化)。如果两步合一,可能出现 A 类的 static 变量引用 B 类,但 B 类还没分配内存的情况。
什么时候会触发类的初始化?
| 触发 | 不触发 |
|---|---|
new 创建对象 |
访问 static final 编译期常量(准备阶段就有了) |
| 访问/修改 static 变量 | 子类访问父类 static 变量(只初始化父类) |
| 调用 static 方法 | Class.forName 传入 initialize=false |
Class.forName("类名") |
定义数组类型 Demo[] arr |
| main 方法所在的类 |
java
// 不会触发 Demo 初始化(B 是编译期常量,准备阶段就有了)
System.out.println(Demo.B); // 输出 20,不会打印"类初始化了"
// 会触发 Demo 初始化
System.out.println(Demo.a); // 先打印"类初始化了",再输出 102.2 双亲委派模型
什么是类加载器? JVM 不会一次性把所有 .class 文件都加载进内存,而是用到哪个类才加载哪个。负责加载的组件就是类加载器(ClassLoader)。
为什么有多个类加载器? 不同的类放在不同的位置,各司其职:
| 类加载器 | 加载什么 | 举例 |
|---|---|---|
| Bootstrap ClassLoader | Java 核心类库 | String、ArrayList、HashMap 等 java.* |
| Extension ClassLoader | JDK 扩展类库 | jre/lib/ext 目录下的类 |
| Application ClassLoader | 你写的代码和第三方依赖 | 你项目里的类、Maven 引入的 jar 包 |
| 自定义 ClassLoader | 特殊位置的类 | 从网络加载、热部署、插件系统 |
什么是双亲委派? 当需要加载一个类时,不是自己先加载,而是先问父类能不能加载。父类也先问父类的父类,一层层往上问,直到最顶层的 Bootstrap。谁能加载谁来,都不能加载才轮到自己。
text
你的代码用到 String 类,触发加载:
Application ClassLoader 收到请求
→ "我先不加载,问问我父类"
→ Extension ClassLoader 收到请求
→ "我也先不加载,问问我父类"
→ Bootstrap ClassLoader 收到请求
→ "String 在 rt.jar 里,我能加载!"
→ 加载完成,返回
你的代码用到 com.company.MyService 类:
Application ClassLoader 收到请求
→ 委派给 Extension ClassLoader
→ 委派给 Bootstrap ClassLoader
→ "不在我管的范围,加载不了"
→ Extension ClassLoader: "也不在我这,加载不了"
→ Application ClassLoader: "在 classpath 里找到了,我来加载"为什么要这么设计? 安全。假如有人写了一个恶意的 java.lang.String 类放在项目里,双亲委派会让 Bootstrap 优先加载 JDK 自带的 String,你写的假 String 永远不会被加载。保证了核心类不会被篡改。
java
// 验证类加载器层级
System.out.println(String.class.getClassLoader());
// null(Bootstrap 是 C++ 实现的,Java 中显示为 null)
System.out.println(MyService.class.getClassLoader());
// AppClassLoader(你的代码由 Application ClassLoader 加载)
System.out.println(MyService.class.getClassLoader().getParent());
// ExtClassLoader(Application 的父加载器是 Extension)
System.out.println(MyService.class.getClassLoader().getParent().getParent());
// null(Extension 的父加载器是 Bootstrap,显示为 null)2.3 为什么要双亲委派?
安全性 :防止用户自定义一个 java.lang.String 来替换核心类。无论谁请求加载 String,最终都会由 Bootstrap ClassLoader 加载 rt.jar 中的那个。
一致性 :保证同一个类在 JVM 中只被加载一次,所有代码用的是同一个 String.class。
2.4 打破双亲委派
某些场景需要打破双亲委派:
java
// 典型场景:
// 1. Tomcat:每个 Web 应用有自己的 ClassLoader,同名类互不影响
// 2. SPI 机制:Bootstrap ClassLoader 加载的接口需要加载 classpath 上的实现类
// 3. 热部署:抛弃旧 ClassLoader,创建新的来加载修改后的类
// 自定义 ClassLoader 示例
public class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] bytes = loadClassBytes(name); // 从自定义位置读取字节码
return defineClass(name, bytes, 0, bytes.length);
}
}3. 垃圾回收(GC)
3.1 如何判断对象是否可回收?
GC 的核心问题:堆上有一堆对象,哪些还有用,哪些是垃圾?有两种判断方式。
方式一:引用计数法(JVM 不用,了解即可)
每个对象维护一个计数器,有人引用它就 +1,引用断了就 -1,减到 0 说明没人用了,可以回收:
java
Object a = new Object(); // 对象 A 被 a 引用,计数 = 1
Object b = a; // 对象 A 又被 b 引用,计数 = 2
a = null; // a 不再引用,计数 = 1
b = null; // b 不再引用,计数 = 0 → 可以回收听起来很简单,但有一个致命问题------循环引用:
java
class Node {
Node ref; // 指向另一个节点
}
Node a = new Node(); // 对象 A 计数 = 1(被变量 a 引用)
Node b = new Node(); // 对象 B 计数 = 1(被变量 b 引用)
a.ref = b; // 对象 B 计数 = 2(被变量 b + 对象 A 的 ref 引用)
b.ref = a; // 对象 A 计数 = 2(被变量 a + 对象 B 的 ref 引用)
a = null; // 对象 A 计数 = 1(还被对象 B 的 ref 引用着)
b = null; // 对象 B 计数 = 1(还被对象 A 的 ref 引用着)
// 两个对象计数都不为 0,无法回收
// 但实际上已经没有任何变量能访问到它们了------这就是内存泄漏所以 JVM 不用引用计数法,用下面这种。
方式二:可达性分析(JVM 实际使用)
思路很简单:从一组"肯定活着"的对象出发,沿着引用链往下找,能找到的就是活的,找不到的就是垃圾。
这组"肯定活着"的起点叫 GC Roots 。哪些对象有资格当 GC Roots?就是那些你的代码正在直接使用的东西:
| GC Root | 为什么肯定活着 | 举例 |
|---|---|---|
| 栈中的局部变量 | 方法正在执行,变量正在被用 | void foo() { List list = new ArrayList(); } 中的 list |
| static 变量 | 类活着它就活着 | static Map cache = new HashMap(); 中的 cache |
| 常量引用 | 不会变 | static final String NAME = "test"; 中的 "test" |
| synchronized 锁持有的对象 | 正在被锁着,不能回收 | synchronized(obj) 中的 obj |
用上面循环引用的例子走一遍可达性分析:
a = null; b = null; 之后:
从 GC Roots 出发(栈中的局部变量 a 和 b 都是 null 了)
→ 没有任何 GC Root 指向对象 A 或对象 B
→ 对象 A 和对象 B 都不可达
→ 都是垃圾,可以回收 ✅
引用计数法搞不定的循环引用,可达性分析轻松解决再看一个正常的例子:
java
void foo() {
List<String> list = new ArrayList<>(); // list 是 GC Root(栈中局部变量)
list.add("hello"); // "hello" 被 list 引用,可达
Map<String, List<String>> map = new HashMap<>();
map.put("key", list); // map 也是 GC Root
}
// foo() 执行完毕,list 和 map 从栈中弹出,不再是 GC Root
// → ArrayList、HashMap、"hello" 都不可达 → 全部可回收3.2 四种引用类型
GC 判断"能不能回收"时,不是只看"有没有引用",还要看引用的强度。Java 有四种引用,强度从高到低:
强引用(Strong Reference):日常写的代码都是强引用
java
Object obj = new Object(); // obj 就是强引用
// 只要 obj 还指着这个对象,GC 绝对不会回收它
// 哪怕内存不够了,宁可抛 OOM 也不回收强引用对象
obj = null; // 断开引用后才能被回收软引用(Soft Reference):内存够就留着,不够就回收
java
// 场景:图片缓存。图片占内存大,缓存着能加速,但内存不够时宁可丢掉缓存也别 OOM
SoftReference<byte[]> cache = new SoftReference<>(new byte[10 * 1024 * 1024]);
byte[] data = cache.get(); // 尝试获取
if (data != null) {
// 内存充足,缓存还在,直接用
} else {
// 内存不足时 GC 回收了它,返回 null,需要重新加载
data = loadFromDisk();
}弱引用(Weak Reference):不管内存够不够,下次 GC 就回收
java
// 场景:WeakHashMap,key 被 GC 回收后,对应的 entry 自动删除,防止内存泄漏
WeakReference<Object> weak = new WeakReference<>(new Object());
weak.get(); // 能拿到(GC 还没来)
System.gc(); // 触发 GC
weak.get(); // null(GC 一来就被回收了)虚引用(Phantom Reference):最弱,get() 永远返回 null
java
// 场景:跟踪对象什么时候被回收了,做清理工作(比如释放堆外内存)
// 日常开发基本用不到,了解即可总结:
| 引用类型 | 类比 | GC 态度 | 典型场景 |
|---|---|---|---|
| 强引用 | 亲儿子 | 打死也不回收,宁可 OOM | 所有普通变量 |
| 软引用 | 家里亲戚 | 家里宽裕就住着,住不下了请你走 | 内存敏感的缓存 |
| 弱引用 | 临时访客 | 打扫卫生(GC)就清走 | WeakHashMap |
| 虚引用 | 监控探头 | 随时清走,只是通知你一声 | 跟踪回收状态 |
日常开发 99% 都是强引用,偶尔用软引用做缓存,弱引用和虚引用在框架源码里才会见到。
3.3 GC 算法
标记-清除(Mark-Sweep)
标记阶段:从 GC Roots 遍历,标记所有可达对象
清除阶段:回收未被标记的对象
优点:简单
缺点:产生内存碎片标记-复制(Copying)
将内存分为两半,每次只用一半
GC 时把存活对象复制到另一半,清空当前这半
优点:无碎片,分配快(指针碰撞)
缺点:可用内存减半
新生代使用此算法(Eden + S0 + S1 的设计就是优化版的复制算法)标记-整理(Mark-Compact)
标记阶段:同标记-清除
整理阶段:将存活对象向一端移动,清空边界以外的内存
优点:无碎片
缺点:移动对象开销大
老年代使用此算法3.4 分代回收策略
为什么要分代? 研究发现大部分对象"朝生夕死"(比如方法里的局部变量,方法执行完就没用了),少部分对象长期存活(比如缓存、连接池)。把它们分开管理,用不同的策略回收,效率更高。
堆被分成两大区域:
| 区域 | 占比 | 存放什么 | GC 频率 |
|---|---|---|---|
| 新生代(Young) | 约 1/3 | 新创建的对象 | 频繁,但每次很快 |
| 老年代(Old) | 约 2/3 | 长期存活的对象 | 很少,但每次很慢 |
新生代内部又分三块:
新生代(Young Generation)
┌──────────────┬───────┬───────┐
│ Eden │ S0 │ S1 │
│ (80%) │ (10%) │ (10%) │
└──────────────┴───────┴───────┘
新对象在这里诞生 两个 Survivor 区轮流使用用搬家来理解整个流程:
把 Eden 想象成一个临时宿舍,S0 和 S1 是两个小隔间,老年代是正式住所:
第一步:新对象在 Eden 出生
new Object() → 分配到 Eden 区
第二步:Eden 满了,触发 Minor GC
GC 检查 Eden 里所有对象:
还有人引用的(存活)→ 搬到 S0,年龄标记为 1
没人引用的(垃圾)→ 直接清除
Eden 清空
第三步:Eden 又满了,再次 Minor GC
GC 同时检查 Eden 和 S0:
存活的 → 全部搬到 S1,年龄 +1
垃圾 → 清除
Eden 和 S0 清空
第四步:Eden 又满了,再次 Minor GC
GC 同时检查 Eden 和 S1:
存活的 → 全部搬到 S0,年龄 +1
垃圾 → 清除
Eden 和 S1 清空
(S0 和 S1 就这样轮流交替,始终有一个是空的)
第五步:某个对象年龄达到 15(默认阈值)
说明这个对象经历了 15 次 GC 都没死 → 搬到老年代(正式住下)
第六步:老年代也满了
触发 Major GC / Full GC → 整个堆大扫除,耗时很长(程序会卡顿)为什么 Survivor 要两个轮流用? 这是标记-复制算法的核心------每次 GC 把存活对象复制到另一个 Survivor,然后把原来那个整块清空。这样不会产生内存碎片(不像标记-清除会留下"洞"),而且新生代大部分对象都是垃圾,真正需要复制的很少,所以速度很快。
用具体数字感受一下:
假设 Eden 每次 GC 有 100 个对象:
→ 大约 95 个是垃圾,直接清掉
→ 只有 5 个存活,复制到 Survivor
→ 复制 5 个比整理 100 个快得多这也是为什么 Eden 占 80%、Survivor 各占 10% ------ 因为大部分对象活不过第一次 GC,Survivor 不需要太大。
3.5 主流垃圾回收器
| 回收器 | 算法 | 区域 | 特点 |
|---|---|---|---|
| Serial | 复制 / 标记-整理 | 新 / 老 | 单线程,STW,适合客户端 |
| Parallel (默认) | 复制 / 标记-整理 | 新 / 老 | 多线程并行,吞吐量优先 |
| CMS | 标记-清除 | 老 | 低延迟,已废弃(Java 14 移除) |
| G1(Java 9 默认) | 分区 + 复制 + 整理 | 全堆 | 可预测停顿,兼顾吞吐和延迟 |
| ZGC(Java 15+) | 着色指针 + 读屏障 | 全堆 | 停顿 < 1ms,适合大堆 |
| Shenandoah | Brooks 指针 | 全堆 | 类似 ZGC,Red Hat 主导 |
G1 核心思想

4. JVM 常用参数
4.1 内存设置
bash
# 堆大小
-Xms512m # 初始堆大小(建议和 Xmx 设为一样,避免动态扩缩)
-Xmx2g # 最大堆大小
# 新生代
-Xmn512m # 新生代大小
-XX:NewRatio=2 # 老年代 : 新生代 = 2 : 1(默认)
-XX:SurvivorRatio=8 # Eden : S0 : S1 = 8 : 1 : 1(默认)
# 元空间
-XX:MetaspaceSize=128m # 初始大小
-XX:MaxMetaspaceSize=256m # 最大大小
# 栈
-Xss256k # 每个线程的栈大小4.2 GC 选择
bash
-XX:+UseG1GC # 使用 G1(Java 9+ 默认)
-XX:+UseZGC # 使用 ZGC(Java 15+)
-XX:MaxGCPauseMillis=200 # G1 期望最大停顿时间4.3 GC 日志
bash
# Java 9+ 统一日志(推荐)
-Xlog:gc*:file=gc.log:time,uptime,level,tags
# 打印更详细的信息
-Xlog:gc+heap=debug:file=gc.log4.4 排查工具
bash
# 查看 JVM 进程
jps -l
# 查看堆内存使用
jmap -heap <pid>
# 导出堆快照(分析内存泄漏)
jmap -dump:format=b,file=heap.hprof <pid>
# 查看线程状态(排查死锁、CPU 飙高)
jstack <pid>
# 实时监控 GC 情况(每秒刷新)
jstat -gcutil <pid> 1000
# 可视化工具
# jconsole / jvisualvm(JDK 自带)
# Arthas(阿里开源,线上诊断神器)5. 常见 OOM 排查思路
OutOfMemoryError: Java heap space
→ jmap -dump 导出堆快照
→ 用 MAT 或 VisualVM 分析
→ 找到占用内存最大的对象
→ 检查是否有内存泄漏(长生命周期对象持有短生命周期对象的引用)
→ 常见原因:
- 集合不断添加不清理(Map 做缓存没有淘汰策略)
- 大查询一次性加载全部数据(应该分页)
- 静态集合持有大量对象
OutOfMemoryError: Metaspace
→ 检查是否动态生成大量类(CGLIB 代理、反射、脚本引擎)
→ 增大 -XX:MaxMetaspaceSize
StackOverflowError
→ 检查递归是否有终止条件
→ 考虑将递归改为迭代
→ 增大 -Xss(治标不治本)6. 小结
| 主题 | 关键要点 |
|---|---|
| 堆 | 所有对象实例在这里分配;分新生代(Eden + S0 + S1)和老年代 |
| 栈 | 线程私有,每个方法调用一个栈帧;存局部变量和引用 |
| 方法区/元空间 | 类信息、常量池、静态变量;Java 8 改为本地内存 |
| 类加载 | 加载 → 验证 → 准备 → 解析 → 初始化 |
| 双亲委派 | 先委派父加载器,保证核心类安全和唯一 |
| 可达性分析 | 从 GC Roots 出发,不可达即为垃圾 |
| GC 算法 | 标记-清除(碎片)、标记-复制(新生代)、标记-整理(老年代) |
| GC 回收器 | G1 是默认选择,ZGC 适合大堆低延迟场景 |
| 调优工具 | jmap(内存)、jstack(线程)、jstat(GC)、Arthas(线上诊断) |
下一篇预告:注解与反射------动态类信息获取与运行时行为修改
🎯 如果这篇文章对你有帮助,别忘了点赞、收藏、关注三连!关注我,让你在 Java 学习的道路上不迷路,持续为你带来成体系的 Java 干货~