PD 分离部署核心原理分析
一、为什么需要 PD 分离?
1.1 Prefill 和 Decode 的本质差异
大模型推理的两个阶段,在计算特性上完全是两个物种:
| 维度 |
Prefill(预填充) |
Decode(解码) |
| 计算模式 |
并行处理所有输入 Token |
串行逐个生成 Token |
| 计算类型 |
计算密集型(矩阵乘法) |
内存密集型(访存频繁) |
| GPU 利用率 |
~100%(近乎饱和) |
~1%(极度浪费) |
| 关键指标 |
TTFT(首 Token 延迟) |
TPOT(每 Token 时间) |
| 主要瓶颈 |
算力 FLOPs |
内存带宽 Memory Bandwidth |
| 批处理优化 |
大(可合并多请求) |
小(动态调整) |
| 加速手段 |
Tensor Core、量化 |
KV Cache 压缩、内存优化 |
1.2 速度差异惊人(实测数据)
测试条件:5 并发请求,输入 255 Token,生成 256 Token
- Prefill 阶段:0.2394 秒(5,325 tokens/s)
- Decode 阶段:32.8948 秒(38.76 tokens/s)
Decode 比 Prefill 慢 137 倍,占整体推理时间的 99%!
这就是核心矛盾:Prefill 吃算力、Decode 吃带宽,特性相反,放一起跑 GPU 资源永远在被浪费。
1.3 传统共置架构的三个问题
- 资源竞争:Prefill 请求会抢占 Decode 资源的 GPU 算力 → Decode 延迟尖峰 → 用户感知为输出"卡顿"(P99 延迟增加 78%+)
- 并行策略冲突:Prefill 适合张量并行(TP)降延迟,Decode 适合流水线并行(PP)提吞吐,共置架构无法同时满足
- 过度配置:为满足 SLO 被迫过度配置 GPU → 运营成本大幅上升
二、PD 分离的核心原理
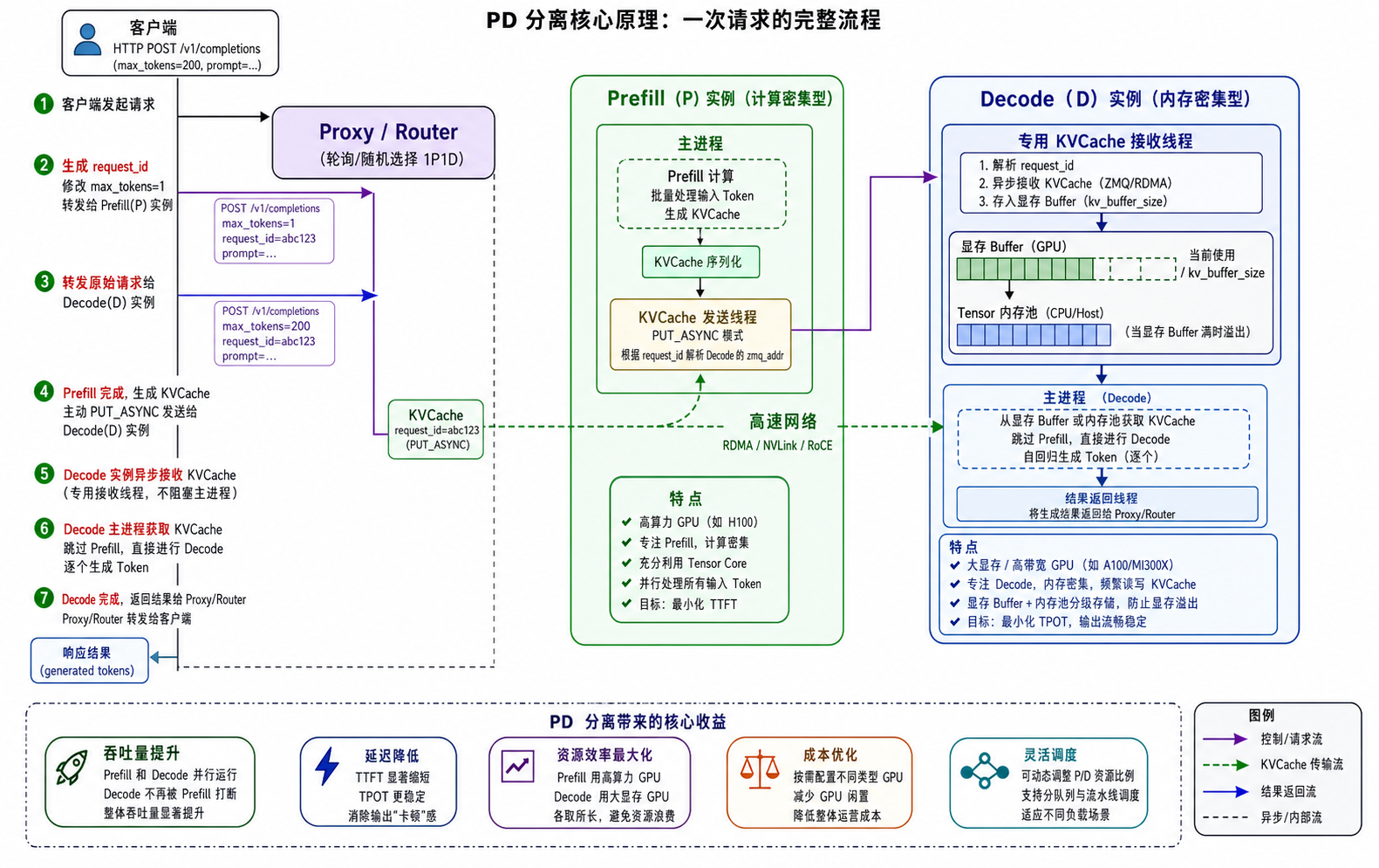
2.1 架构设计
传统共置架构:
请求 → [GPU: Prefill → Decode → Prefill → Decode → ...] → 响应
↑ 两个阶段争抢同一 GPU 资源,互相干扰
PD 分离架构:
请求 → [Prefill 节点组(高算力 GPU)] ── KV Cache 传输 ──→ [Decode 节点组(大显存 GPU)] → 响应
↑ 计算密集型 ↑ 高速网络(RDMA/NVLink) ↑ 内存密集型
↑ 并行处理所有 Token ↑ 传输中间状态 ↑ 逐个生成 Token
核心思想:将 Prefill 和 Decode 解耦,分配到不同类型的计算设备上执行,通过高速网络传输中间状态(KV Cache)。
2.2 关键实现机制
| 组件 |
说明 |
| Prefill 节点 |
高算力 GPU(如 H100),专注批量处理输入 Token,生成 KV Cache |
| Decode 节点 |
大显存/高带宽 GPU,专注自回归生成,频繁读写 KV Cache |
| KV Cache 传输 |
通过 RDMA / NVLink 高速传输中间状态,减少数据交换延迟 |
| 调度器 |
分队列管理 Prefill/Decode 流量,避免拥塞,动态分配资源比例 |
2.3 典型实现参考
- DistServe:创新性 KV Cache 传输机制 + 调度算法
- Mooncake:基于 RDMA 的高效 KV Cache 传输
- 百度智能云 HPN:4μs 端到端延迟,分队列调度,吞吐量提升 20%
三、PD 分离的性能优势
3.1 吞吐量提升
- Prefill 阶段独立跑在高算力 GPU 上,并行度拉满
- Decode 阶段在专用节点上持续运行,不再被 Prefill 打断
- 实测 :MoE 专家并行减半 + PD 分离 → 端到端性能提升 40%(文章2数据)
3.2 延迟降低
- TTFT 显著缩短:Prefill 请求不再被 Decode 任务阻塞
- TPOT 更稳定:Decode 阶段独占资源,输出更流畅,消除"卡顿"感
- 共置架构下 Prefill/Decode 混合时的 P99 延迟增加 78%+ → PD 分离后这个干扰被彻底消除
3.3 硬件利用率最大化
| 场景 |
传统共置 |
PD 分离 |
| Prefill GPU 利用率 |
~100%(但受 Decode 拖累) |
~100%(专注计算) |
| Decode GPU 利用率 |
~1%(算力严重浪费) |
更高(专注内存带宽) |
| 整体资源效率 |
低 |
高 |
| 成本 |
需过度配置 |
减少 GPU 闲置 |
3.4 灵活的资源调度
- 可根据工作负载动态调整 Prefill/Decode 资源比例
- 支持 Continuous Batching:迭代级调度,不等整批,流水线式处理
- 分队列管理 Prefill/Decode 流量,避免拥塞
四、实测性能数据汇总
4.1 Prefill vs Decode 速度对比
| 指标 |
Prefill |
Decode |
差异倍数 |
| 处理速度 |
5,325 tokens/s |
38.76 tokens/s |
137x |
| 耗时占比 |
~1% |
~99% |
--- |
| GPU 利用率 |
~100% |
~1% |
--- |
| 计算特性 |
算力密集 |
内存带宽受限 |
--- |
4.2 模型规模与硬件需求(文章2数据)
| 模型 |
参数 |
所需显存 |
H100 80G 卡数 |
显卡成本 |
| MiMo-V2.5 |
3,100 亿 |
~620 GB |
~8 张 |
~¥182 万 |
| MiMo-V2.5-Pro |
1 万亿 |
~2.0 TB |
~26 张 |
~¥592 万 |
| DeepSeek-V4-Pro |
1.6 万亿 |
~3.2 TB |
~40 张 |
~¥910 万 |
注意:以上为 FP16 完整精度估算。原生部署以 FP8/FP4 精度,实际显存减半/四分之三。
4.3 KV Cache 规模
MiMo-V2.5-Pro @ 100K 上下文:
| 场景 |
KV Cache 大小 |
| 单请求 / 纯 Full Attention |
~36 GB |
| 100 并发 / 纯 Full |
~3.6 TB |
KV Cache 公式:2 × layers × heads × head_dim × seq_len × precision_bytes
4.4 优化实践效果
| 优化手段 |
效果 |
| PD 分离(MoE 专家并行减半) |
端到端性能 +40% |
| Prompt 裁剪 |
系统提示词减少 30% |
| Prefix Cache 复用 |
MiMo 线上命中率均值 90%+ |
| Continuous Batching |
vLLM/TGI 吞吐翻几倍的核心机制 |
| 百度 HPN 网络优化 |
4μs 端到端延迟,吞吐量提升 20% |
五、PD 分离的关键挑战与解决方案
5.1 资源动态分配
| 挑战 |
解决方案 |
| Prefill 和 Decode 对资源需求差异大 |
分队列调度,独立分配 GPU 计算单元与内存带宽 |
| 短请求阻塞长生成任务 |
动态批处理 + Continuous Batching |
5.2 内存管理
| 挑战 |
解决方案 |
| KV Cache 占显存大(单请求 36GB @100K ctx) |
分层存储:高频在 GPU 显存,低频移至主机内存/NVMe SSD |
| 动态请求导致显存碎片化 |
内存池(Memory Pool)+ PagedAttention(分页管理) |
| 分布式 KV Cache 传输延迟 |
RDMA 加速数据传输 |
5.3 低延迟 vs 高吞吐平衡
| 挑战 |
解决方案 |
| 用户对 TTFT 敏感 |
优先级调度:优先处理 Prefill 任务确保低 TTFT |
| Decode 需稳定输出 |
Decode 公平调度,保证 TPOT 稳定 |
| 端到端延迟 |
流水线并行,Prefill 与 Decode 任务重叠执行 |
5.4 分布式通信
| 挑战 |
解决方案 |
| 跨节点同步开销大 |
HPN(高性能网络),超低延迟(4μs)网络架构 |
| AlltoAll 通信瓶颈 |
KV Cache 分区,按 Token 位置分布,减少跨节点传输 |
5.5 工程落地
| 挑战 |
解决方案 |
| 框架支持不足(PyTorch 未原生支持) |
定制化推理引擎 |
| 异构硬件适配 |
硬件感知优化,不同 GPU 架构定制计算内核 |
六、部署方案建议
6.1 核心决策原则
| 维度 |
建议 |
| 模型规模 |
≥100B 参数强烈建议 PD 分离;<100B 视并发量决定 |
| 并发量 |
高并发(>50 并发)→ PD 分离收益大;低并发可暂缓 |
| 上下文长度 |
长上下文(>32K)→ KV Cache 压力大 → PD 分离价值高 |
| SLO 要求 |
对 TTFT 敏感(聊天/交互场景)→ 必须 PD 分离 |
| 成本敏感度 |
GPU 资源紧张 → PD 分离减少闲置,ROI 更高 |
6.2 推荐部署架构
┌─────────────────────────────────────┐
│ 全局调度器(Dispatcher) │
│ 分队列管理 + 动态资源分配 + 优先级调度 │
└──────┬──────────────────────┬────────┘
│ │
┌────────────▼──────────┐ ┌───────▼──────────────┐
│ Prefill 节点组 │ │ Decode 节点组 │
│ (计算密集型) │ │ (内存密集型) │
├───────────────────────┤ ├──────────────────────┤
│ GPU: H100 × N 张 │ │ GPU: H100 × M 张 │
│ 并行策略:张量并行(TP) │ │ 并行策略:流水线并行(PP)│
│ 精度:FP8/INT8 │ │ 精度:FP16(保持稳定) │
│ 优化:Tensor Core │ │ 优化:KV Cache 压缩 │
└───────────────────────┘ └──────────────────────┘
│ │
└────── RDMA/NVLink ───┘
KV Cache 传输
6.3 GPU 资源配置建议
场景:MiMo-V2.5-Pro 级别模型(1T 参数)
| 角色 |
GPU 需求 |
配置要点 |
| Prefill 节点 |
总 GPU 的 20-30% |
高算力 H100,张量并行,FP8 量化,批量处理 |
| Decode 节点 |
总 GPU 的 70-80% |
大显存 H100,流水线并行,KV Cache 优化 |
| 比例动态调整 |
根据实际负载 |
读密集型场景(长 Prompt 短输出)→ 增加 Prefill |
|
|
写密集型场景(短 Prompt 长输出)→ 增加 Decode |
6.4 分阶段部署路线
第一阶段:快速上线
| 步骤 |
内容 |
| 1 |
部署 vLLM + Continuous Batching(传统共置模式) |
| 2 |
启用 Prefix Cache 复用(system prompt 命中率 90%+) |
| 3 |
开启量化(FP8 部署,显存减半) |
| 4 |
Prompt 裁剪优化(目标减少 30%+) |
| 5 |
监控 TTFT/TPOT 基线数据 |
预期效果:不改变架构,仅靠上述优化可提升 2-3 倍吞吐量
第二阶段:PD 分离改造
| 步骤 |
内容 |
| 1 |
部署调度器(分队列管理 Prefill/Decode 流量) |
| 2 |
划分 Prefill 节点组(20-30% GPU,高算力) |
| 3 |
划分 Decode 节点组(70-80% GPU,大显存) |
| 4 |
搭建 RDMA/NVLink 高速传输通道 |
| 5 |
配置 KV Cache 高效传输机制 |
| 6 |
灰度切换部分流量验证 |
预期效果:端到端性能提升 40%+,TTFT 显著降低,TPOT 更稳定
第三阶段:精细化调优
| 步骤 |
内容 |
| 1 |
根据实际负载动态调整 Prefill/Decode 资源比例 |
| 2 |
分层存储 KV Cache(GPU 显存 → 主机内存 → NVMe SSD) |
| 3 |
集成 HPN 高性能网络(4μs 延迟目标) |
| 4 |
强化学习驱动的细粒度资源调度 |
| 5 |
持续 Benchmark 验证性能 |
6.5 关键技术选型建议
| 组件 |
推荐方案 |
备选方案 |
| 推理引擎 |
vLLM(原生支持 PagedAttention + Continuous Batching) |
TGI / TensorRT-LLM |
| KV Cache 传输 |
RDMA(RoCEv2 / InfiniBand) |
NVLink(单机内) |
| 调度器 |
自研(分队列 + 优先级调度) |
基于 Ray / Kubernetes |
| 量化 |
FP8(H100 原生支持) |
INT8 / INT4(需校准) |
| 监控 |
Prometheus + Grafana |
自研监控面板 |
6.6 成本估算参考
以 MiMo-V2.5-Pro 级别模型为例:
| 项目 |
共置架构 |
PD 分离 |
| GPU 总数 |
26 张 H100 |
26 张 H100(Prefill 6 + Decode 20) |
| GPU 成本 |
¥592 万 |
¥592 万(相同) |
| 网络成本 |
--- |
RDMA 交换机(约 ¥50-100 万) |
| 吞吐量(基准 1x) |
1x |
1.4x+ |
| 每 Token 成本 |
基准 |
降低约 30% |
| TCO(3 年) |
基准 |
降低约 20-25% |
核心结论:PD 分离的硬件投入增量主要是网络(RDMA),但 GPU 利用率提升带来的吞吐量增益,可使每 Token 成本降低约 30%,6-12 个月即可收回网络投入。
七、总结与关键结论
- PD 分离是必选项,不是可选项 --- Prefill 和 Decode 的计算特性差异(137 倍速度差)决定了共置架构永远无法高效利用 GPU 资源
- Decode 占推理时间的 99% --- 优化 Decode 阶段是性能提升的最大杠杆
- 实测收益明确 --- 端到端性能 +40%(MoE + PD 分离),吞吐量 +20%(调度优化)
- 分阶段落地最稳妥 --- 先上 vLLM + Continuous Batching + 量化 → 再改造 PD 分离 → 最后精细化调优
- 成本账算得过来 --- PD 分离的每 Token 成本降低约 30%,网络投入 6-12 个月收回
- 关键配套技术 --- Prefix Cache 复用(命中率 90%+)、Prompt 裁剪(-30%)、Continuous Batching(吞吐翻倍)、量化(显存减半)
附录:关键术语速查
| 术语 |
定义 |
| TTFT |
Time To First Token,首 Token 延迟,衡量 Prefill 阶段性能 |
| TPOT |
Time Per Output Token,每 Token 生成时间,衡量 Decode 阶段性能 |
| KV Cache |
Key-Value 缓存,存储 Attention 计算的中间状态,是 Decode 阶段的核心数据 |
| PagedAttention |
vLLM 的核心技术,将 KV Cache 分页管理,类比操作系统虚拟内存 |
| Continuous Batching |
迭代级调度,不等整批,每个请求完成后立即让出槽位 |
| Prefix Cache 复用 |
相同前缀的 KV Cache 跳过重复计算,直接复用 |
| MoE |
Mixture of Experts,混合专家模型,稀疏激活,每次只激活部分参数 |
| RDMA |
Remote Direct Memory Access,远程直接内存访问,低延迟高带宽网络技术 |
| HPN |
高性能网络,百度智能云的 4μs 端到端延迟网络架构 |
| SWA |
Sliding Window Attention,滑动注意力窗口,只看最近 K 个 token |