
🔥 个人主页: 杨利杰YJlio
❄️ 个人专栏: 《Windows 疑难杂症与工单复盘案例库》 《Sysinternals实战教程》
《WINDOWS教程》 《Windows PowerShell 实战》 《IOS插件分析测试》
🌟 让复杂的事情更简单,让重复的工作自动化

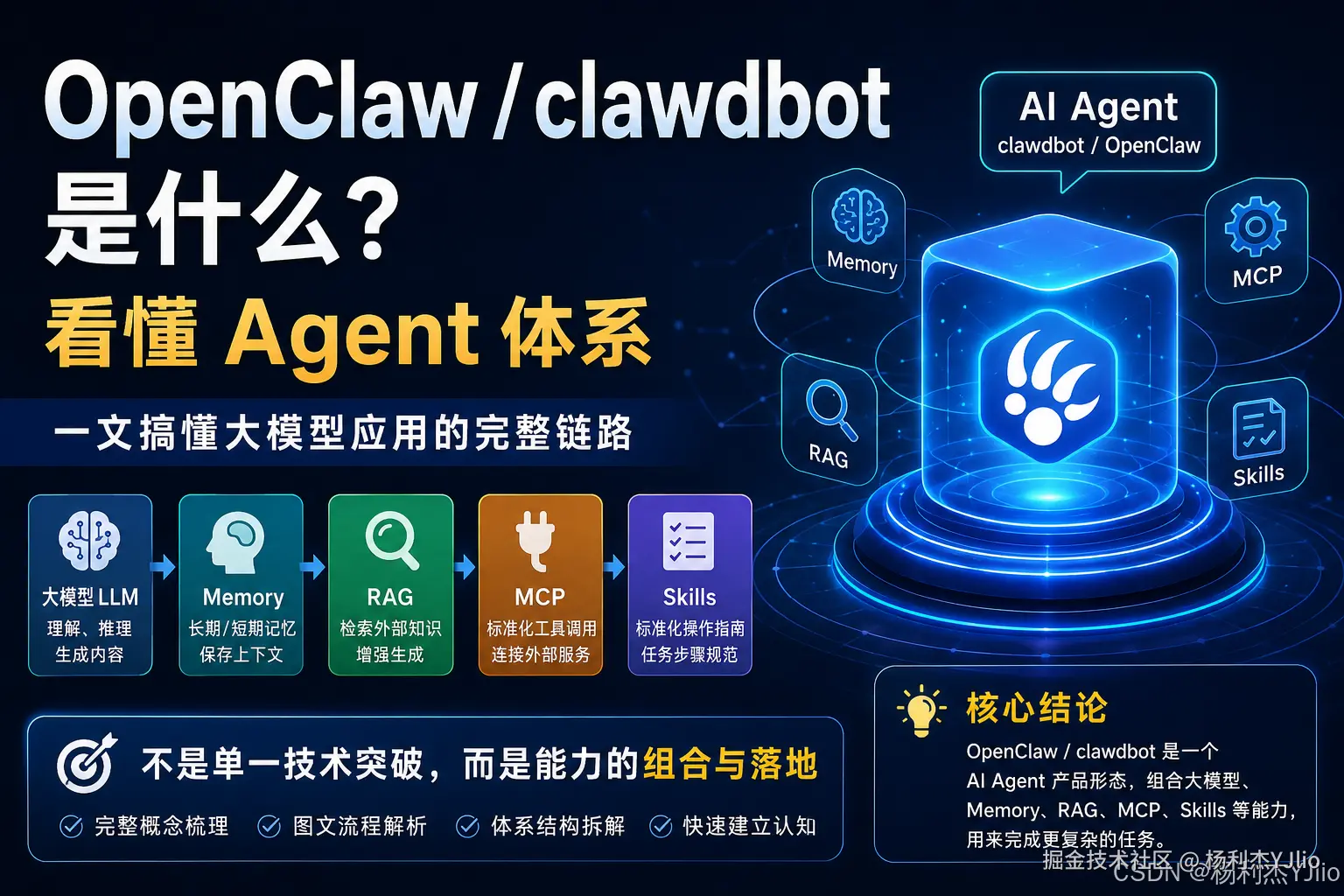
OpenClaw / clawdbot 是什么?看懂 Agent 体系

前言
最近很多人看到 OpenClaw、clawdbot、Skills、MCP、RAG、Memory、AI Agent 这些词时,会觉得它们都和 AI 应用有关,但又分不清它们到底是什么关系。
这篇文章按照视频里的图示逻辑重新拆开讲。先看整体关系,再看大模型、HTTP 请求、上下文窗口、Memory、RAG、工具调用、MCP、Skills,最后再回到 OpenClaw / clawdbot 到底应该放在哪一层理解。
先给结论:OpenClaw / clawdbot 更像一个 AI Agent 产品形态。它不是单独的新模型,也不是单独的 RAG、Memory、MCP 或 Skills,而是把这些能力组合起来,用来完成更复杂的任务。
一、整体关系:这些概念不是同一层
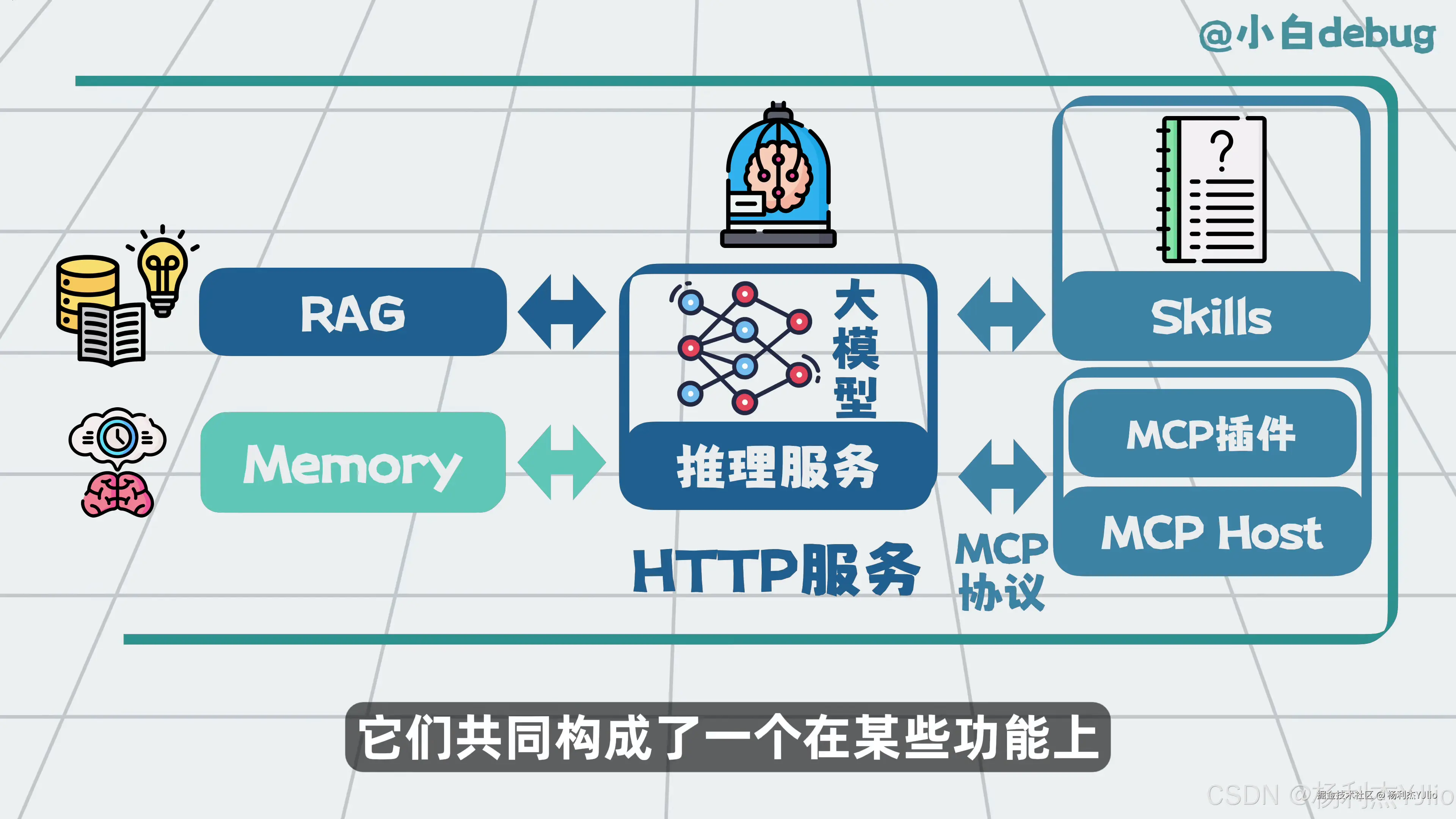
这张图是整篇文章的入口。图中把 Skills、RAG、LLM、MCP、Memory 放在同一个体系里,目的是说明这些概念不是同一层的东西。
LLM,也就是大模型,负责理解、推理和生成。Memory 负责记忆。RAG 负责从外部知识库检索资料。MCP 负责让模型按标准方式调用工具。Skills 负责告诉模型遇到任务时应该按什么步骤做。
所以这些概念不是互相替代的关系,而是组合关系。一个完整的 Agent 系统,往往会同时用到它们。
| 概念 | 主要作用 | 可以这样理解 |
|---|---|---|
| LLM / 大模型 | 理解、推理、生成内容 | AI 的能力底座 |
| Memory | 保存和取回历史信息 | 让系统记住用户和任务背景 |
| RAG | 检索外部资料 | 让模型回答时有资料依据 |
| MCP | 标准化工具调用 | 让模型能连接外部工具 |
| Skills | 规定任务步骤和操作规范 | 让模型按流程做事 |
| AI Agent | 组合多种能力执行任务 | 从聊天走向执行 |
| OpenClaw / clawdbot | Agent 产品形态 | 把上述能力组织成可用产品 |
理解这套体系时,先不要急着问"谁取代谁"。更准确的问法是:它们分别负责哪一层,最后怎么组合成一个能执行任务的系统。
二、大模型只是能力来源,不等于完整应用

这张图讲的是大模型本身。视频里把大模型类比成一个模型文件,例如 gpt-4.bin、deepseek-v3.bin。这个说法不是在强调真实部署一定长这样,而是为了说明:模型本身只是能力来源。
用户平时使用 AI 产品时,不会直接打开这个模型文件。真正对外提供服务的是推理服务。用户把问题发给服务端,服务端调用模型推理,再把回答返回给用户。
因此,大模型只解决了一部分问题。它能理解和生成内容,但完整应用还要处理上下文、记忆、检索、工具调用、权限和执行环境。
三、HTTP 请求默认无状态,模型不会天然记住上文
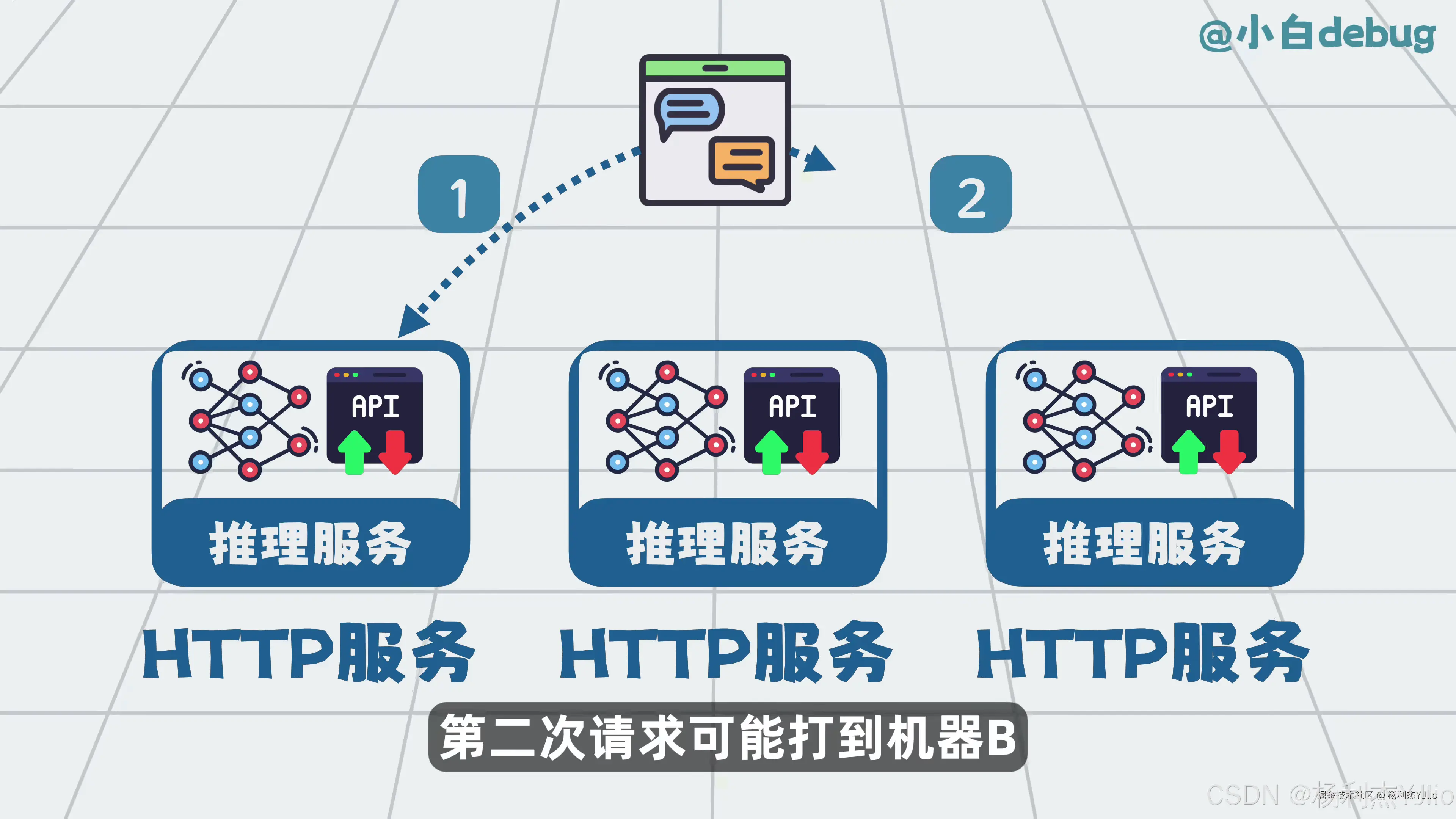
这张图对应 HTTP 推理服务。用户每次发起请求,服务端接收请求后调用模型,然后返回结果。
问题在于,HTTP 请求本身是一条一条来的。第一次请求可能被服务器 A 处理,第二次请求可能被服务器 B 处理。如果系统不额外保存历史,模型只会看到当前请求,不会自动知道前面聊过什么。
所以对话系统通常会把历史消息重新拼进当前请求里。用户继续提问时,系统会把前面的对话内容一起带给模型,让模型基于完整上下文继续回答。
四、上下文窗口有限,历史不能无限塞进去
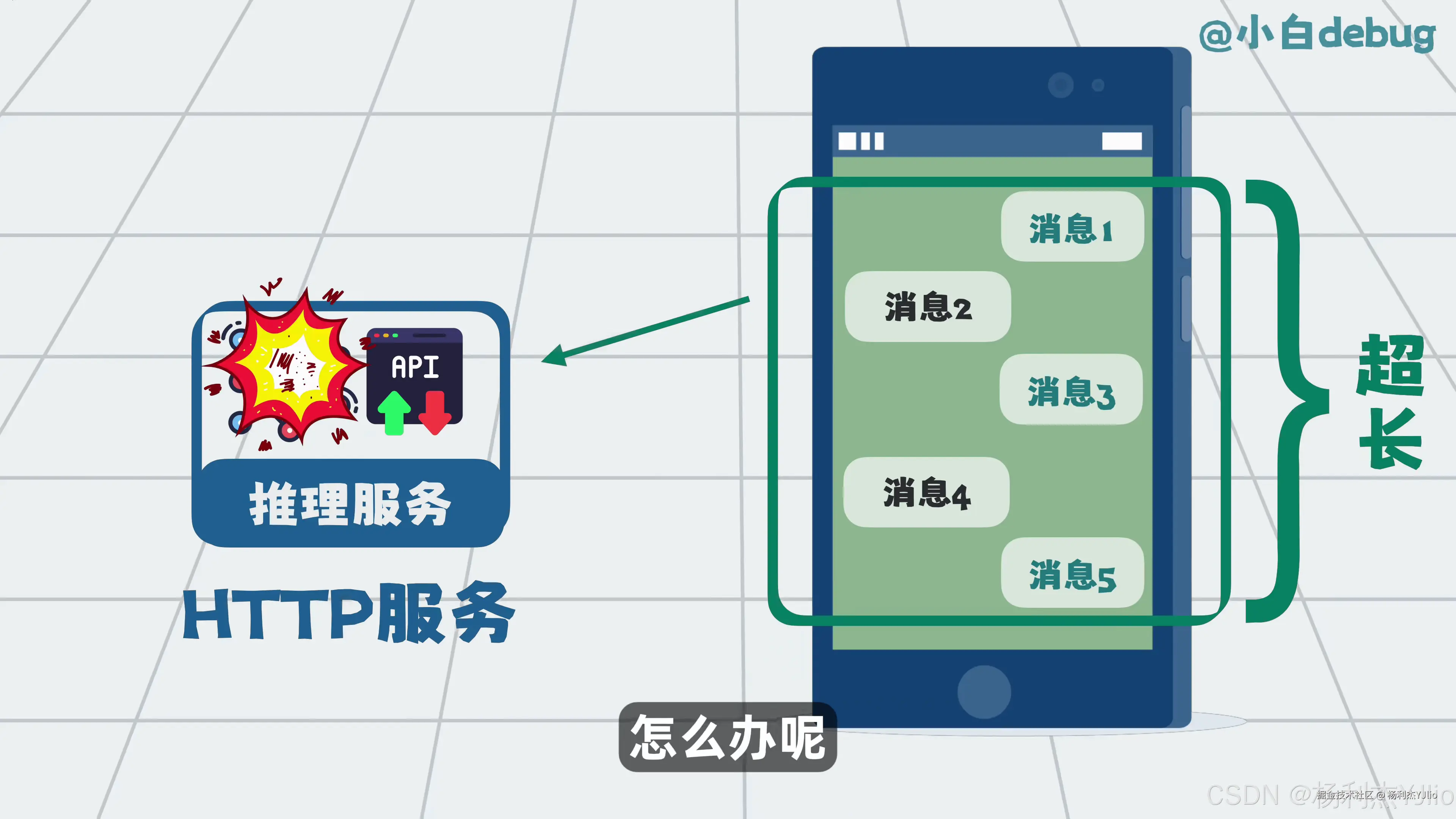
这张图展示的是"历史消息太长"的问题。把历史对话重新放进请求里,可以让模型理解上下文,但上下文窗口不是无限的。
对话越长,历史消息越多。如果全部塞进模型请求,最后会超过上下文窗口。超过以后,系统只能截断一部分内容,或者把历史压缩成摘要。
这也是为什么很多 AI 产品会引入 Memory。它的目的不是让模型文件永久改变,而是帮助系统管理哪些历史信息值得保留,哪些信息在当前任务里需要重新取出来。
五、Memory:长期记忆和短期记忆
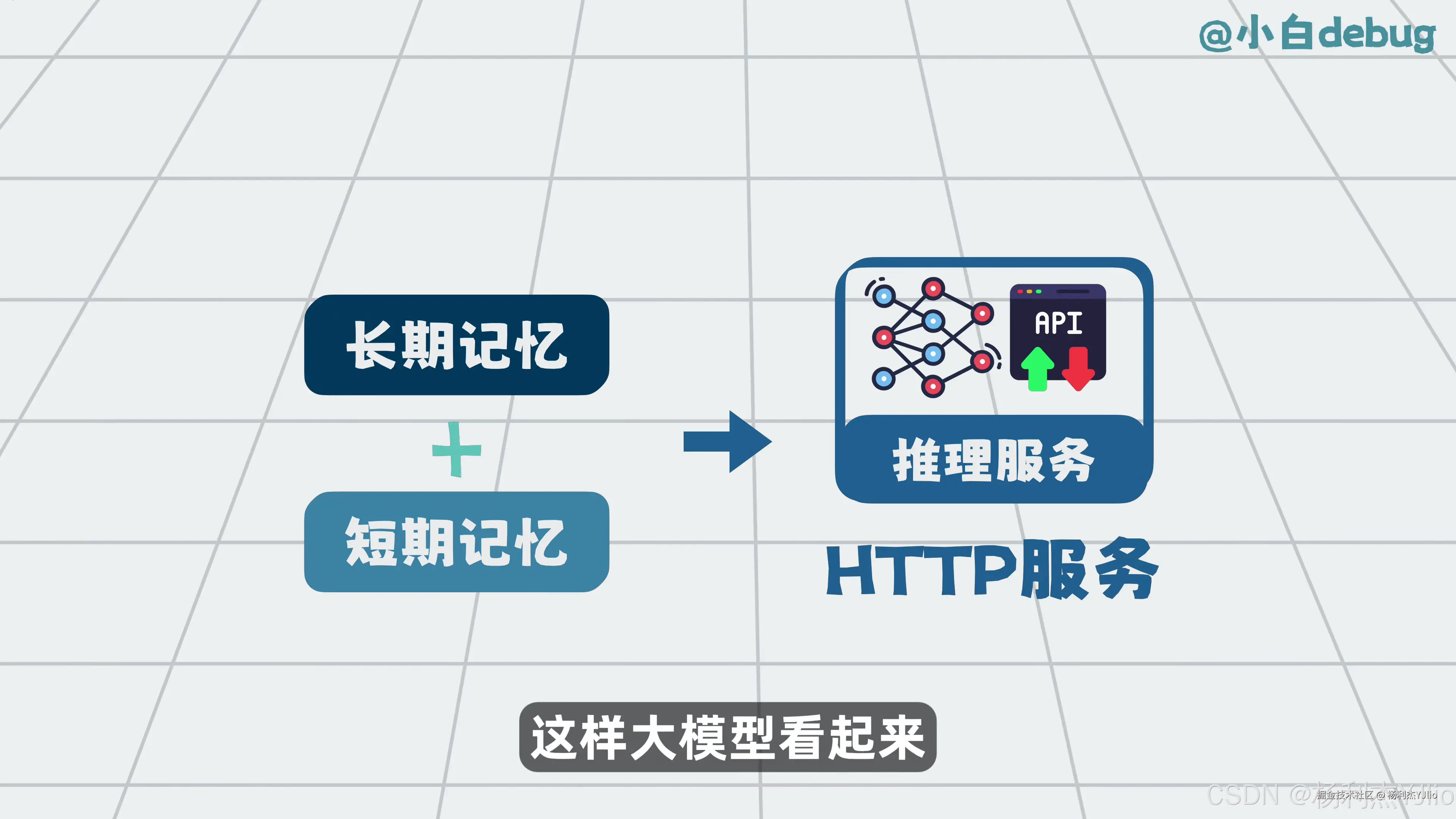
这张图对应 Memory,也就是记忆。图里把记忆分成长期记忆和短期记忆。
短期记忆通常和当前会话有关,比如刚才问了什么、任务做到哪一步、当前上下文里有哪些限制条件。长期记忆则更偏跨会话的信息,比如用户偏好、长期项目背景、经常使用的工作方式等。
Memory 的工作方式可以理解为:系统先保存一部分有价值的信息,需要时再把相关记忆取出来,放回当前请求上下文。模型看到这些信息后,才表现得像"记得"。
这里要注意,Memory 不等于模型训练。它通常不会改变模型参数,而是在推理前给模型补充上下文。
六、大模型知识固定,外部知识需要额外接入
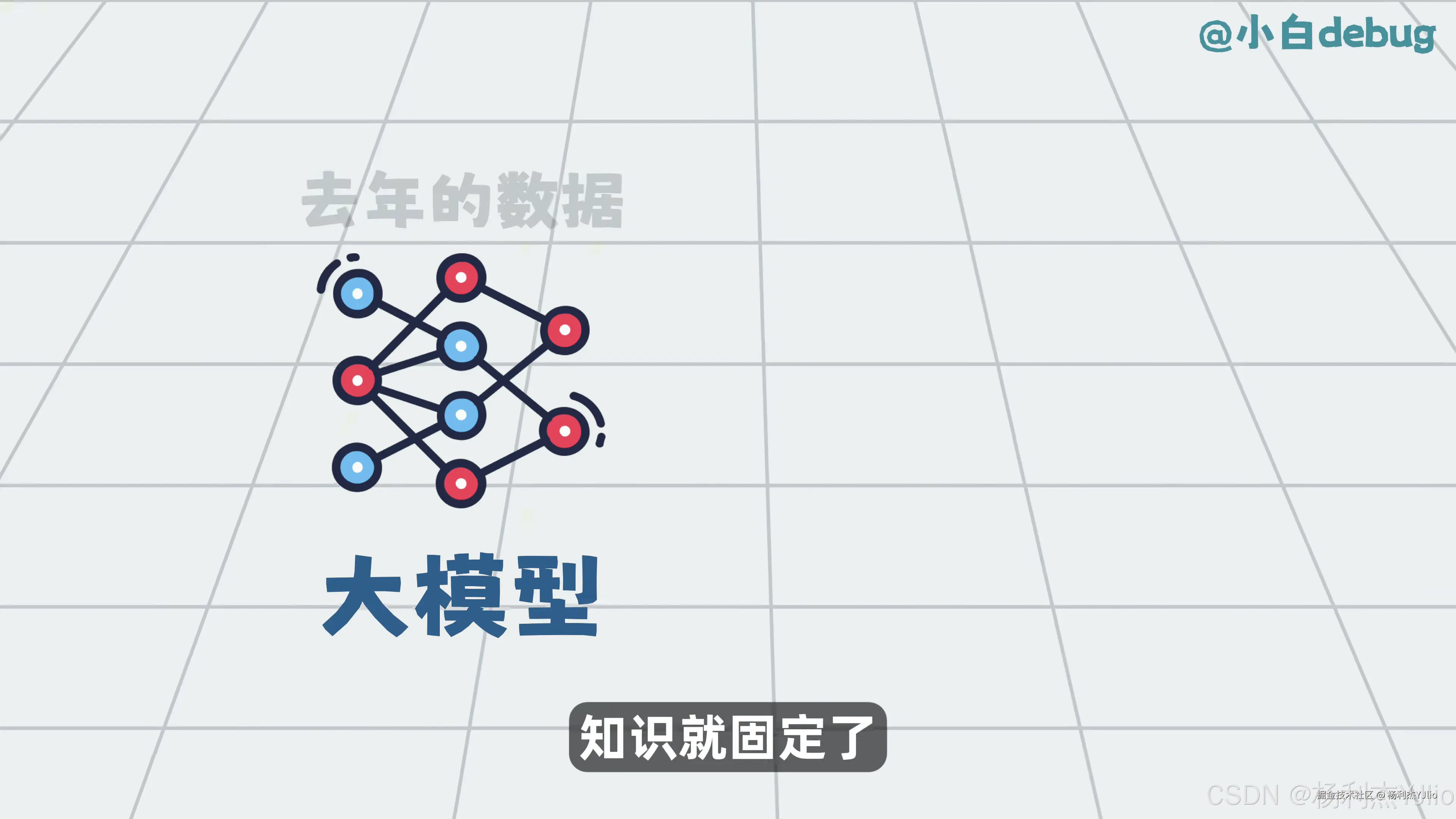
这张图讲的是大模型知识边界。画面里写着"去年的数据"和"知识就固定了",意思是:模型训练完成后,它内部的知识基本固定。
这类模型不一定知道公司最新制度、项目最新文档、数据库实时记录,也不一定知道本地文件里的内容。如果只靠模型原始知识,它可能回答不准。
尤其是在企业文档、内部系统、私有知识库、代码库、日志分析这些场景里,模型必须先拿到外部资料,才能基于资料回答。
七、外部知识库与检索服务
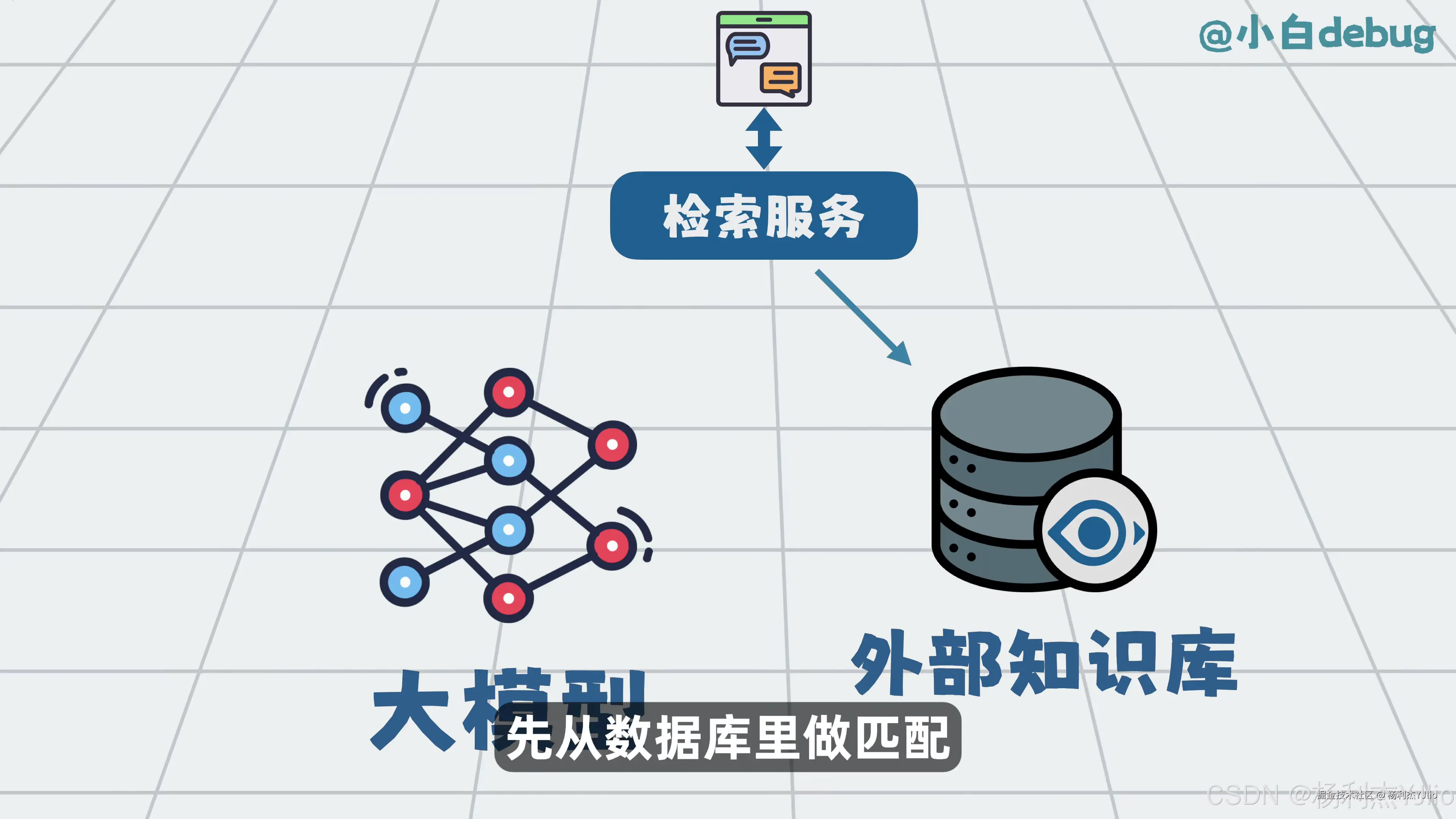
这张图对应外部知识库和检索服务。用户提出问题后,系统不是直接让模型凭空回答,而是先通过检索服务去外部知识库中查找相关内容。
外部知识库可以是企业文档、网页资料、内部知识平台、代码仓库,也可以是数据库或向量库。检索服务负责从这些资料中找到与问题相关的部分。
检索到的内容会被放进模型上下文里,再交给模型生成回答。

这张图强调的是,外部资料不一定非得是向量数据库。传统数据库同样可以作为资料来源。
比如企业内部系统里的工单记录、资产信息、合同数据、运维日志,都可能存放在传统数据库中。AI 系统可以通过检索服务或接口查询这些数据,再把查询结果交给模型分析。
所以不要把 RAG 简单理解成"向量数据库"。向量检索只是常见实现方式之一,真正重要的是"回答前先检索资料"。
八、RAG:检索增强生成
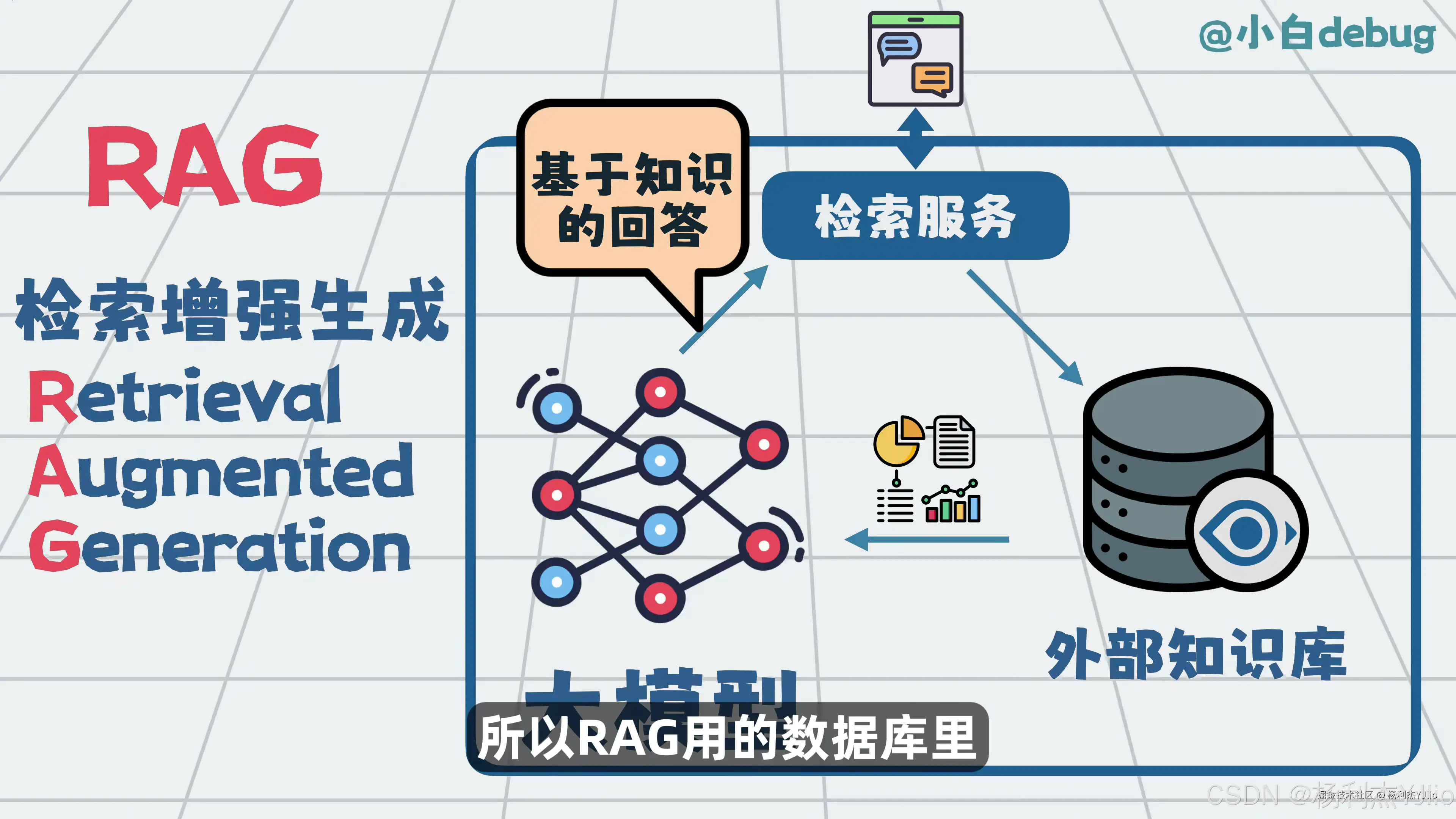
这张图正式对应 RAG。RAG 的英文是 Retrieval Augmented Generation,中文一般叫检索增强生成。
它的核心流程很清楚:用户提问后,系统先检索外部知识库,找到相关资料,然后把资料交给模型,模型再基于资料生成回答。
| 步骤 | 系统动作 | 目的 |
|---|---|---|
| 第一步 | 根据用户问题检索资料 | 找到可参考内容 |
| 第二步 | 把资料放入模型上下文 | 让模型看到外部知识 |
| 第三步 | 模型基于资料生成回答 | 减少凭空回答和知识过期问题 |
RAG 解决的是"模型如何获取外部知识"的问题。它不是记忆系统,也不是工具协议。
九、Memory 和 RAG 组合
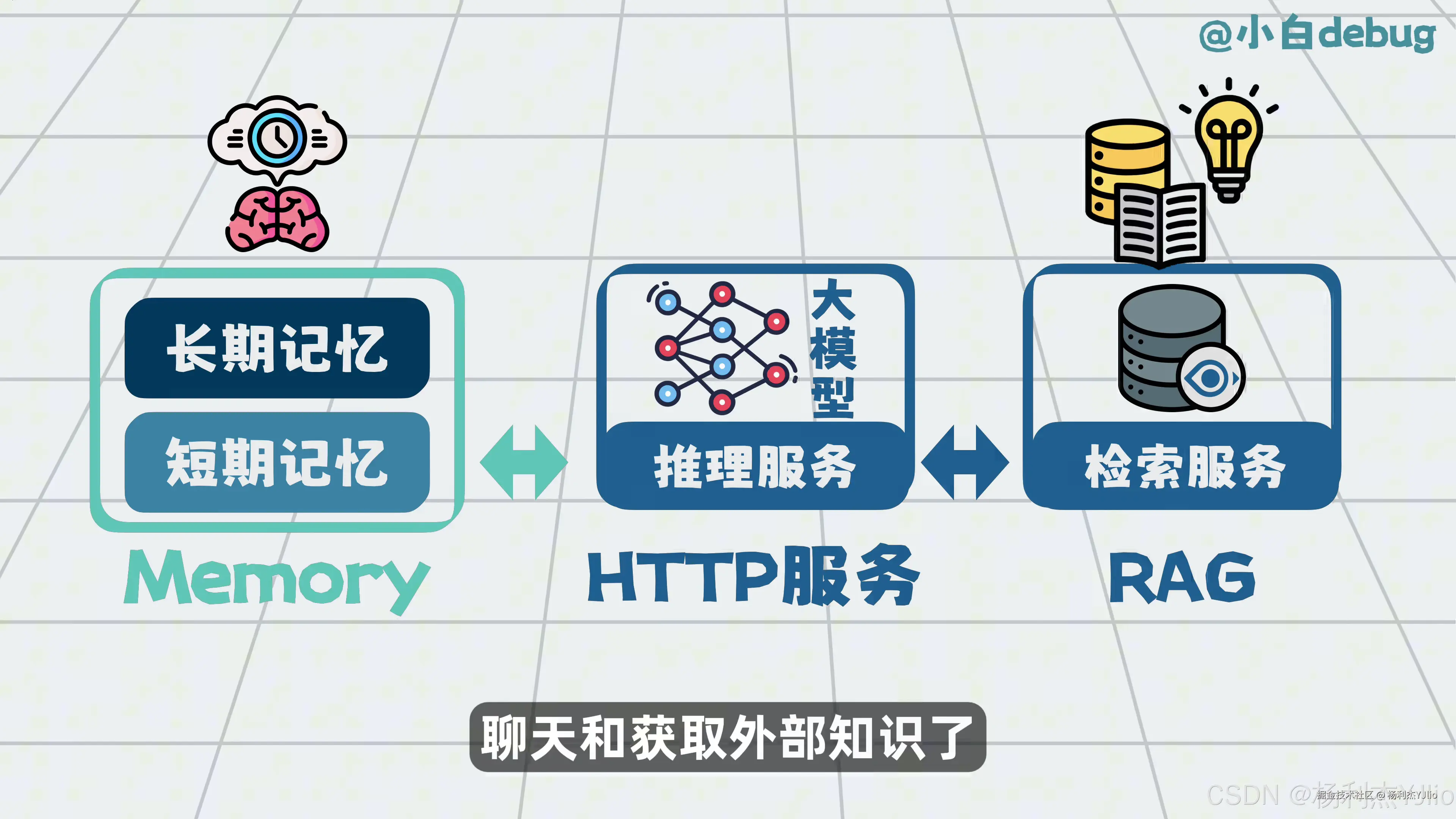
这张图把 Memory、RAG 和推理服务放在一起,说明它们可以同时进入模型上下文。
Memory 更关注用户历史和任务背景,例如用户偏好、当前会话进度、之前确认过的约束条件。RAG 更关注外部知识,例如文档、数据库、知识库、日志和接口数据。
| 对比项 | Memory | RAG |
|---|---|---|
| 信息来源 | 用户历史、会话记录、任务背景 | 文档库、数据库、知识库、外部系统 |
| 主要用途 | 记住用户和任务上下文 | 检索外部资料 |
| 典型问题 | 你还记得我之前说过什么吗 | 资料库里有没有相关内容 |
| 是否改变模型本体 | 不改变 | 不改变 |
实际 Agent 系统里,系统可能先取 Memory,了解用户背景;再用 RAG 查外部资料;最后把两类信息一起交给大模型处理。
十、工具调用:模型要把回答变成动作
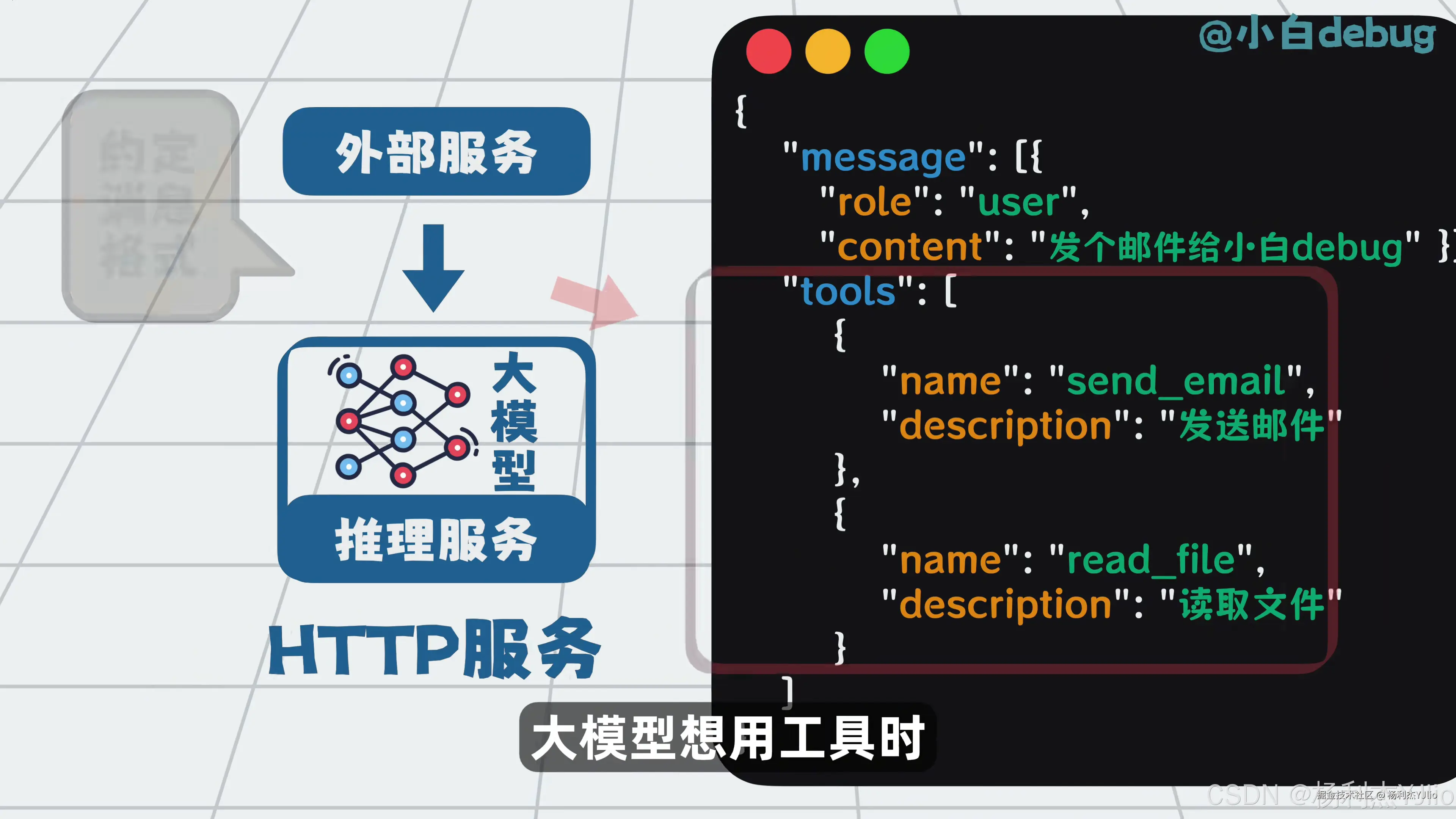
这张图讲的是工具调用。大模型有时不只是回答问题,还需要执行动作。例如发送邮件、读取文件、查询接口、操作系统、访问数据库、分析日志等。
模型本身不会直接去操作外部系统。它通常会生成一个结构化工具调用请求。图中展示的就是类似 JSON 的调用结构,里面包含工具名和参数。
比如模型判断当前任务需要发邮件,就会生成 send_email 之类的工具调用请求,并带上收件人、主题、正文等参数。真正执行动作的是外部工具或服务。
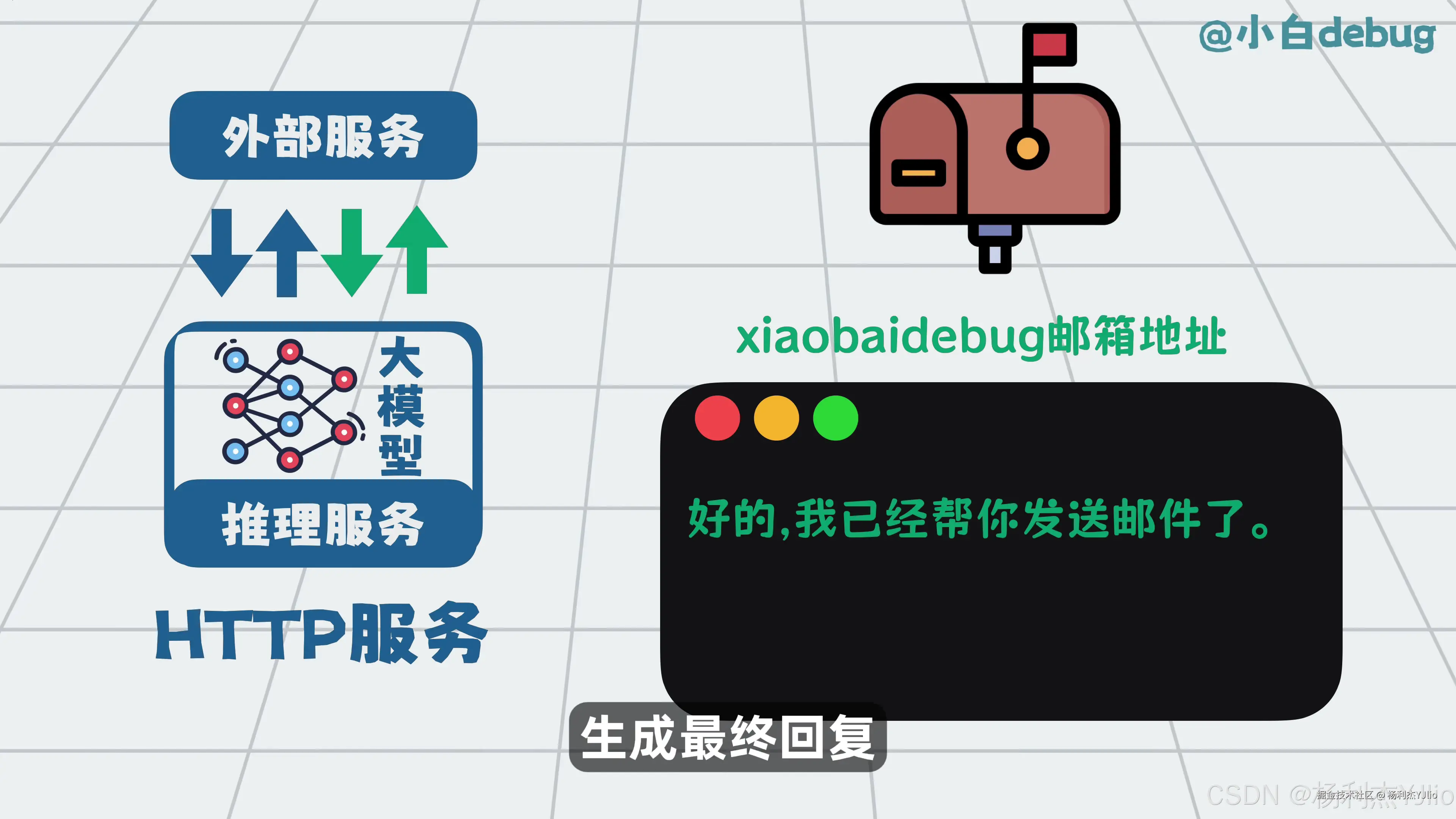
这张图对应工具执行后的返回流程。外部服务执行完成后,把结果返回给模型。模型再根据执行结果生成最终回复。
所以工具调用的分工是:模型负责判断该做什么,工具负责真正执行,执行结果再回到模型。这样 AI 才能从"说话"进一步变成"做事"。
十一、MCP Host:承接模型侧的工具调用
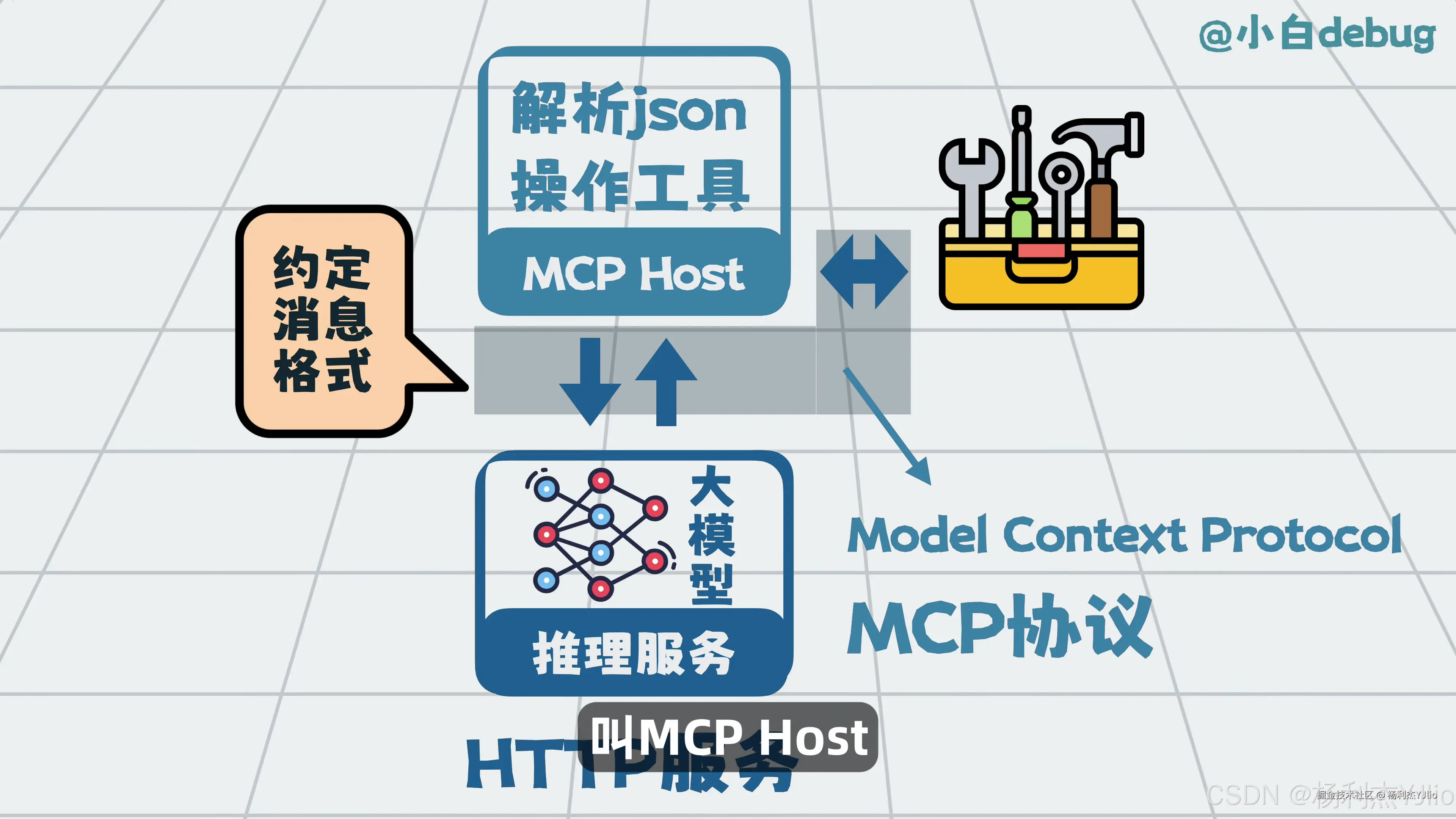
这张图讲的是 MCP Host。MCP 可以理解成一种标准化协议,用来规范模型和工具之间的通信方式。
当模型生成工具调用请求后,MCP Host 负责承接这些请求,并把它们按照 MCP 协议转给后面的工具系统。
MCP 的重点不是让模型本身变强,而是让模型调用工具的方式更统一、更容易扩展。
十二、MCP Client / Server / 插件
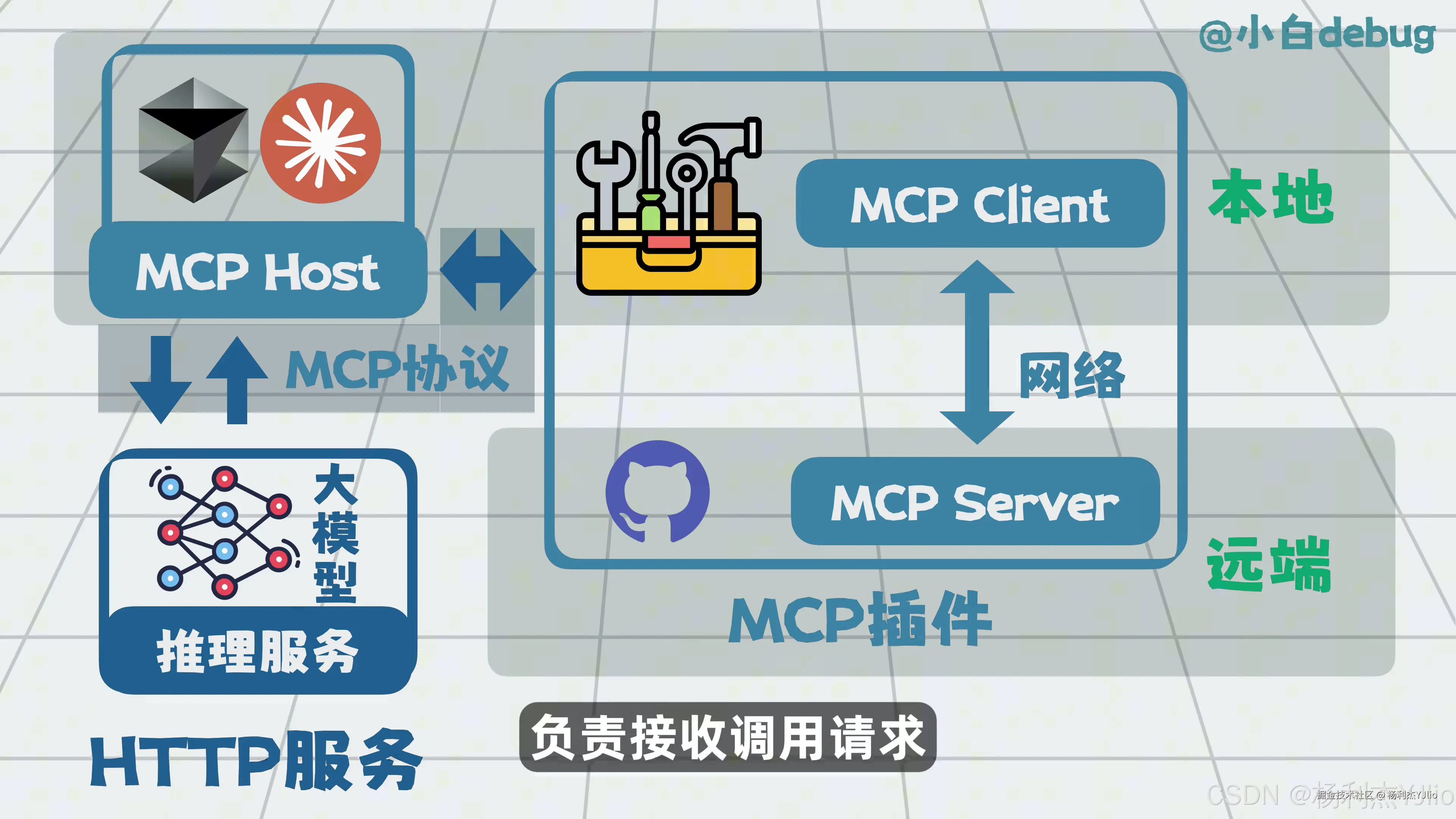
这张图对应 MCP 的本地、网络和远端插件结构。可以把 MCP 分成几个角色来看:
| 角色 | 作用 |
|---|---|
| MCP Host | 承接模型侧工具调用请求 |
| MCP Client | 按 MCP 协议发起连接和调用 |
| MCP Server | 暴露具体工具能力 |
| MCP 插件 | 连接文件、接口、数据库、浏览器等外部能力 |
有了 MCP,模型可以通过相对统一的方式连接不同工具,而不是每接一个工具就重新写一套调用规则。
十三、RAG、Memory、MCP 可以组合使用
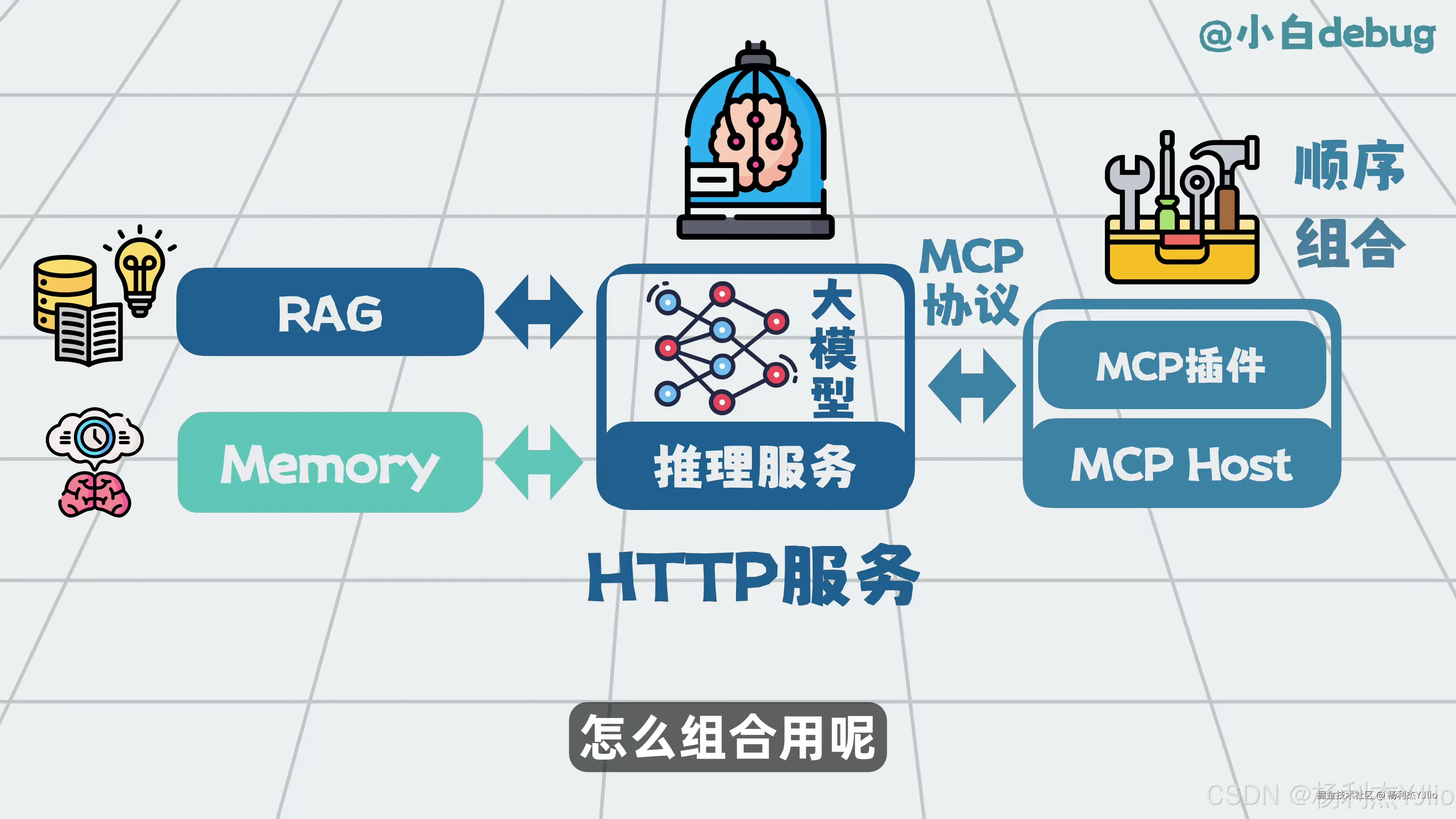
这张图讲的是 RAG、Memory、MCP 的组合。实际 Agent 系统里,这几类能力不会孤立存在。
例如用户让 AI 分析一个项目问题,系统可能先通过 Memory 取出用户的项目背景,再通过 RAG 检索相关文档,接着通过 MCP 调用工具读取文件或查询接口,最后由大模型整理分析结果。
这也是为什么现在很多 Agent 产品会同时提到这些概念。它们是同一套执行系统里的不同部件。
十四、Skills:结构化操作指南
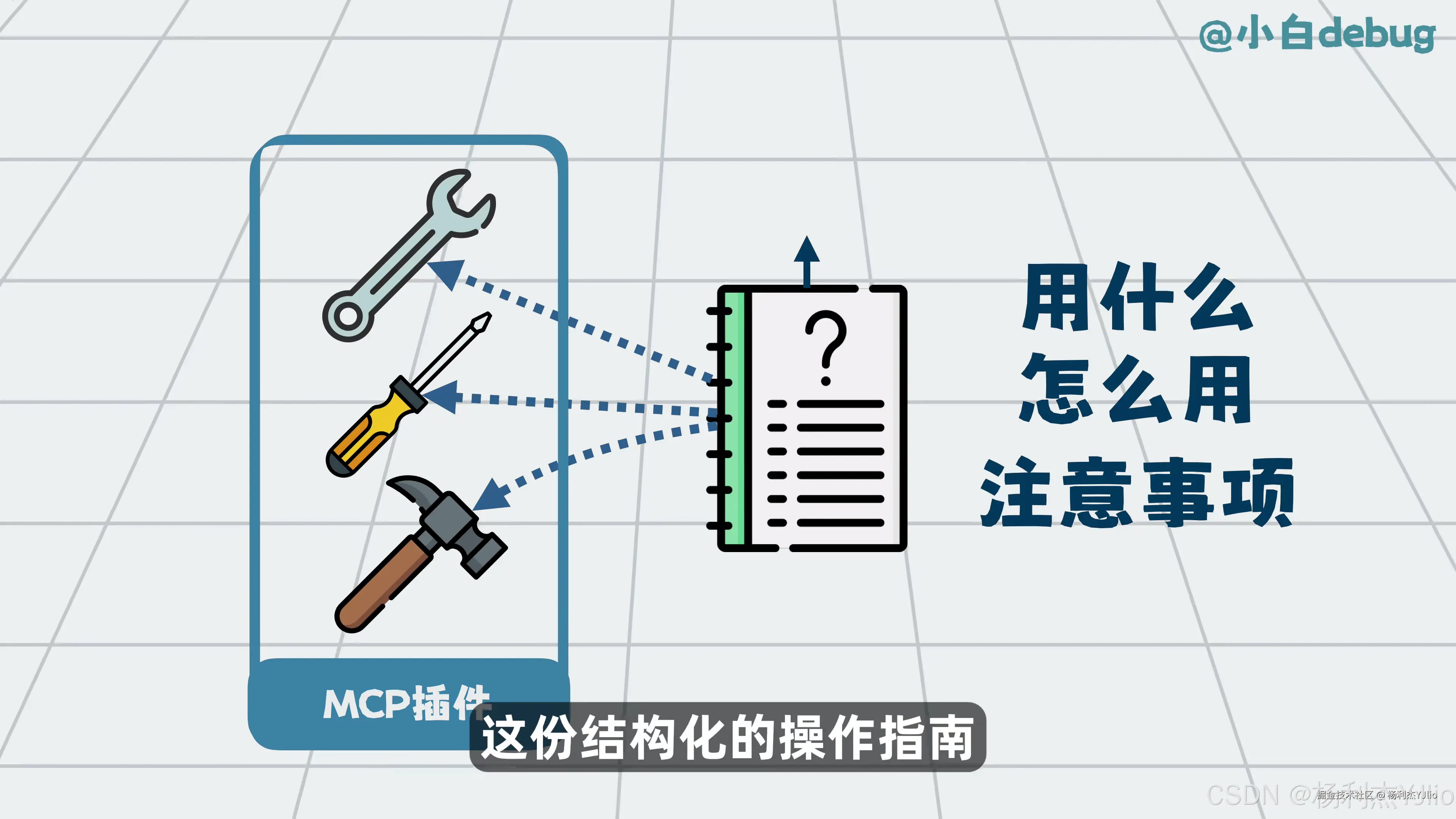
这张图对应 Skills。Skills 和 MCP 经常一起出现,但它们解决的问题不同。
MCP 负责"怎么调用工具"。Skills 负责"遇到任务应该按什么步骤做"。
可以把 Skills 理解成结构化操作指南。它会告诉模型:遇到某类任务时先做什么,再做什么,什么时候查资料,什么时候调用工具,什么时候停止。
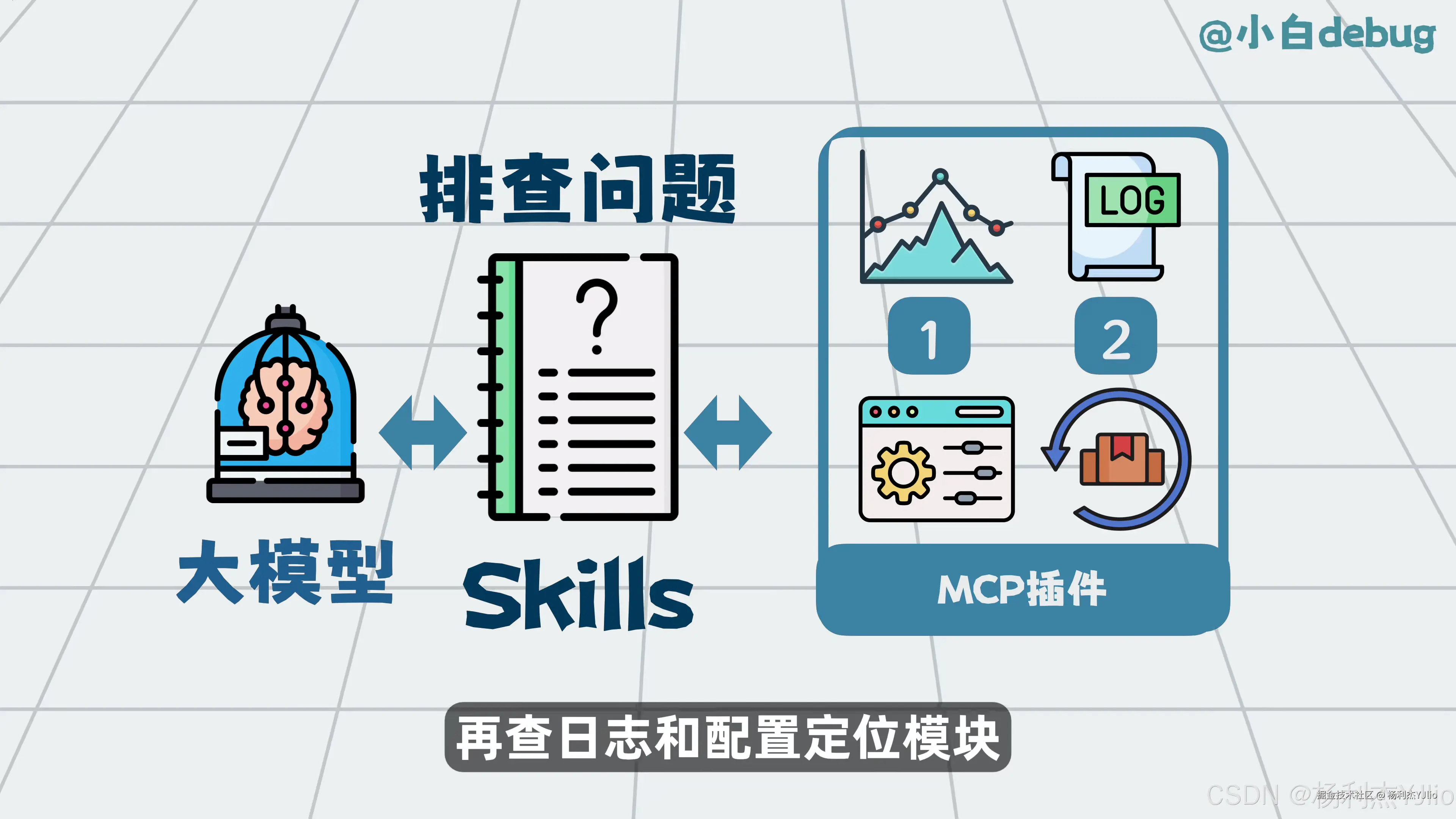
这张图用"排查问题"举例。排查问题不能只靠模型随便猜,而是应该按步骤执行。
例如先看日志,再看配置,再定位模块,必要时通过 MCP 插件读取文件、查询系统或调用接口。这样模型执行任务时才更稳定。
十五、大模型、Skills、MCP、插件的顺序

这张图把大模型、Skills、MCP 协议和 MCP 插件放到同一条链路里。
比较清晰的理解顺序是:大模型负责理解任务;Skills 提供操作步骤;MCP 协议负责标准化通信;MCP 插件连接具体工具。
| 环节 | 负责内容 |
|---|---|
| 大模型 | 理解用户意图,判断下一步 |
| Skills | 提供任务流程和注意事项 |
| MCP 协议 | 规范工具调用通信方式 |
| MCP 插件 | 执行具体工具能力 |
如果没有 Skills,模型可能知道可以调用工具,但不一定知道应该按什么顺序做。如果没有 MCP,Skills 里写了要调用工具,也缺少统一的执行通道。
十六、AI Agent:这些能力组合后的系统形态
AI Agent 的重点不是"模型会聊天",而是"系统能围绕任务持续推进"。它可以理解用户目标,拆解步骤,查资料,调用工具,拿到结果,再继续下一步。
从结构上看,Agent 通常不是单一能力,而是把大模型、Memory、RAG、MCP、Skills、插件和执行环境组合起来。大模型负责判断,Memory 和 RAG 负责补充上下文,MCP 和插件负责连接工具,Skills 负责给出操作流程。
所以 Agent 不是某一个单独工具,而是一组能力组合后的系统形态。本节不再重复插入整体架构图,避免和第一节重复。
十七、AI Agent 与 clawdbot
这张图把 clawdbot 放到了 AI Agent 的位置上,这是理解 OpenClaw / clawdbot 的关键。
OpenClaw / clawdbot 不是一个单独的新模型,也不是单独的 RAG、Memory、MCP 或 Skills。它更像一个把这些能力组织到一起的 Agent 产品。
它的重点在于:让用户通过自然语言提出任务,然后由系统结合大模型、记忆、外部知识、工具调用和执行环境,把任务一步步推进下去。
这张图强调的是,clawdbot 不一定代表底层技术出现了绝对突破。它更像是把现有能力组合成了一个可用的产品形态。
这类产品的价值不能只看模型,还要看任务编排、工具接入、执行环境、权限控制、稳定性和安全边界。
十八、和 Manus 的相似点:远端执行环境
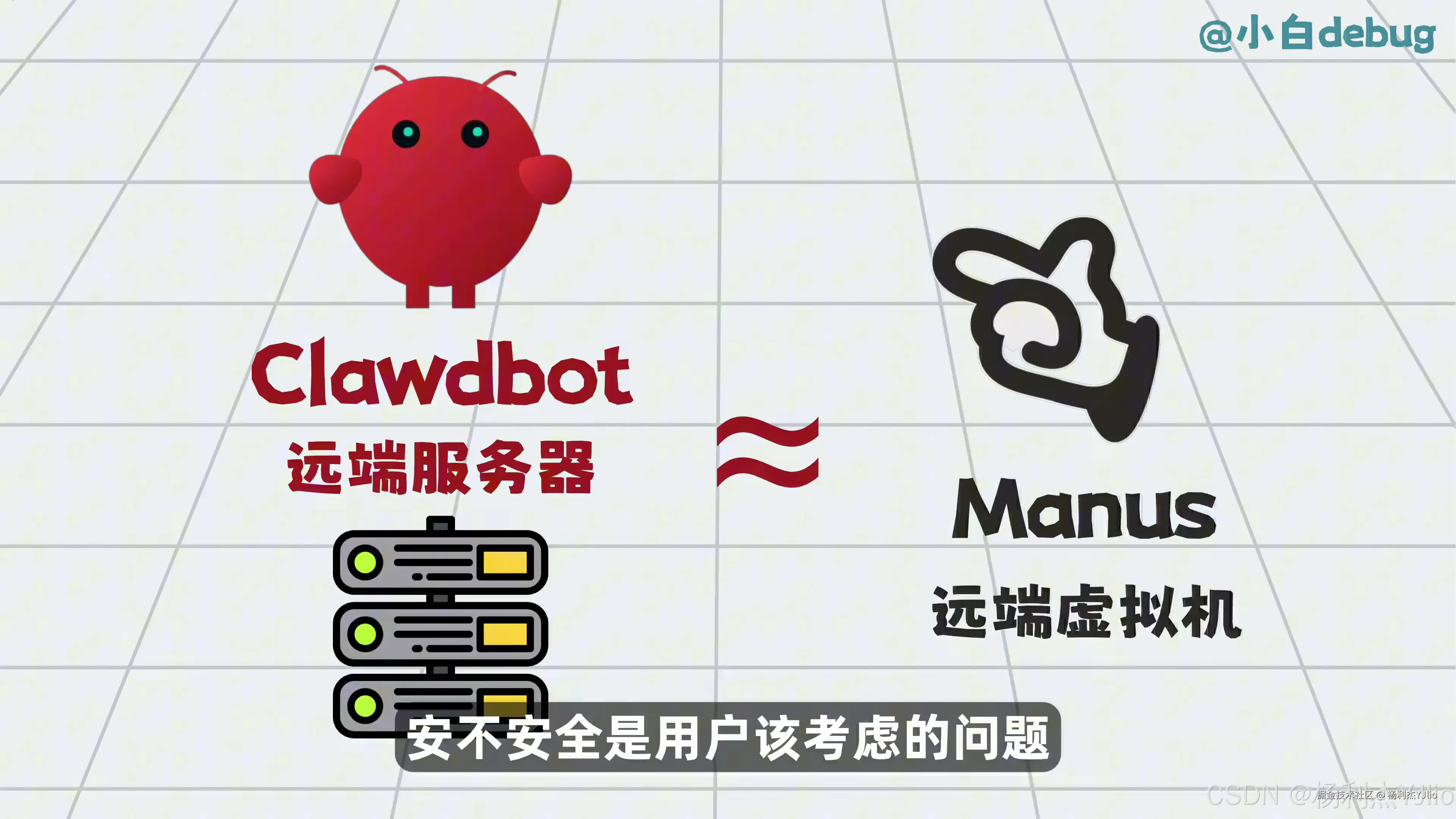
这张图把 clawdbot 和 Manus 做了类比。相似点在于,它们都涉及远端服务器或远端虚拟机式的执行环境。
远端执行环境的好处是,Agent 可以在隔离环境里访问网页、运行工具、处理文件、调用服务。用户不需要把所有执行能力都放在本地。
但这里必须关注安全问题。只要一个 Agent 能读取文件、访问系统、调用接口,就要考虑权限控制、数据隔离、日志审计和敏感信息保护。
十九、最后再压缩成一句话
把整套关系压缩一下,可以这样记:
| 概念 | 一句话理解 |
|---|---|
| 大模型 | 负责理解和生成 |
| Memory | 负责记住用户和任务背景 |
| RAG | 负责从外部资料中检索内容 |
| MCP | 负责标准化工具调用 |
| Skills | 负责规定任务步骤 |
| AI Agent | 负责把这些能力组合起来执行任务 |
| OpenClaw / clawdbot | 更像一个 Agent 产品形态 |
理解 OpenClaw / clawdbot,不要只盯着"它是不是新模型"。更准确的看法是:它把大模型、Memory、RAG、MCP、Skills、工具插件和执行环境组合起来,形成一个能够执行复杂任务的 Agent 系统。
真正需要评估的,也不是某一个概念听起来多新,而是这套组合是否稳定、是否可控、权限边界是否清楚、数据是否安全、任务执行效果是否可靠。
二十、视频结尾转发提示

如果只是想快速记忆,可以把这篇文章的关系记成一条线:大模型负责生成,Memory 负责记忆,RAG 负责查资料,MCP 负责调工具,Skills 负责定步骤,Agent 负责把这些能力组合起来做任务。
