OK,OK,大家好,欢迎大家来到大鹏 AI 教育,我是张大鹏。
前面几篇,我把开源项目 Presenton 的架构拆到了骨头,给 AI 配了代码地图,还亲手实测跑通了一整套 PPT 的生成。从这一篇开始,我换个方式跟大家同步:像产品发版一样,一个版本一个版本地讲清楚,我这一版到底做了什么,为什么是先做这些,下一步又打算干什么。
这一篇讲 v0.1.1 。这一版我没急着加新功能,而是干了一件更底层的事:把一个英文的开源项目,系统地改造成一个中文的、叫"如意课件"的产品雏形。 它分两条主线,一条是国际化,做到无遗留 ,一条是品牌化,彻底换成自己的。这两件事都不性感,但我把它们排在了所有新功能前面。为什么?这一篇就讲清楚。
一、我为什么先做这两件,而不是先堆功能
先说我的底牌。这个二开项目,最终目标不是再造一个 Gamma,而是把它改造成一个给中国老师用的 AI 课件工厂 。我的用户,是像我一样要天天备课、做讲义、录课的老师和知识博主。他们的课件,第一语言就是中文,他们认的,是一个有中文名字、中文界面的自家产品。
可我接手的 Presenton,是个彻头彻尾的英文开源项目:界面是英文的,幻灯片模板里写死了一堆英文,整个产品叫 Presenton,logo、桌面应用、对外链接,全是人家的。这种状态,既不能直接给学员用,也根本谈不上是"我的产品"。
所以国际化和品牌化,对我来说不是"锦上添花的功能",而是这个产品能不能用、算不算我的,这两个最底层的问题。
我打个上课的比方。这就像我要开一门面向中国学员的新课,再好的内容,我也得先把教室的牌子换成中文、把讲义模板和 PPT 母版全换成自家的样式,学员才坐得进来、才认得出这是大鹏的课。地基不中文化、不打上自己的烙印,上面盖什么都是给别人盖的。
还有个很现实的工程账:这种事越早做越省。 现在项目还小,把文本规整好、把品牌换干净,成本很低。等我后面把课程工作流、练习题、录课提词那一堆功能加上去了,再回头补翻译、改品牌,那就是个填不完的坑。先把地基浇好,后面盖楼才快。
二、国际化第一关:分清"内容语言"和"界面语言"
国际化最容易被想简单。很多人以为就是把英文换成中文,找一遍替换一遍。真动手我才发现,同一个界面里的文字,根本不是一种文字,它们该跟谁走,是不一样的。
举个最直白的例子:一个用户,完全可能把软件界面设成英文,却让 AI 生成一份中文 PPT。这时候界面上的按钮该是英文,可幻灯片里的标题、表头,必须是中文。
顺着这个判断,我把文本拆成了四类,每类的治法都不同:
- 类别一,AI 生成的正文 (标题、要点):跟内容语言走。
- 类别二,模板里写死的英文标签 (报告表头、致谢页、目录):它不经过数据、AI 管不到,导出永远是英文,这是最大的坑。它该跟内容语言走。
- 类别三,模板选择器的组别名称和描述 :属界面外壳,跟界面语言走。
- 类别四,藏在 Schema 里的英文描述和默认值 :会被打包进提示词,诱导模型输出英文甚至照抄默认值,这东西压根不该出现在成品里。
想清楚这个分类,我还顺手躲过一个大坑:原本担心要去改导出管线加多语言,风险很高。但当我把类别二的写死英文收编进数据 之后,导出拿到的本来就是中文了,这个高风险改动直接推迟掉了。想清楚再动手,省下来的往往是最难啃的那部分。
落地我分了三步:后端把"必须用目标语言、Schema 英文只是图纸别照抄"的规矩写死(这段约束就在 servers/fastapi/utils/llm_calls/generate_slide_content.py 里);把约 17 个模板里写死的英文标签收编进 Schema,改由 AI 按内容语言生成;模板选择器新建一个翻译命名空间,13 个内置组做简体、英文、繁体三语,繁体用台湾的习惯用词。
三、国际化第二关:把上百处漏网文案,一次扫干净
模板这关过了,还剩一堆边边角角的硬编码文案。这一步我做法不一样,我想专门讲讲,因为它正好是我这个系列一直在说的那件事:连开发本身,也交给 AI。
我没有一个文件一个文件手动翻。我把整个前端按翻译命名空间 切成互不重叠的几块,派了几个 AI 子代理并行去做 :核心生成流程一个、设置页一个、自定义模板一个、首次设置向导一个、模型配置一个。每个代理各管各的语言包文件,互不打架,我自己只做两件事:给它们划好不冲突的地盘,以及在它们交活后逐批审查、注册新命名空间、跑验证。 后面还补了一个专门的清扫代理,把登录页这种漏网的角落也收了,为此新增了 onboarding、ollama、codex、auth 这几个命名空间。
这套打法的好处是,几个代理同时干活,我从"一行行翻译的体力活"里抽身出来,只做我该做的判断和把关。 这就是把开发流程本身也变成 AI 驱动的一次真实演练。
但 AI 干活快,不等于能甩手不管。我发版前每一条都验过:
- 全量类型检查
tsc --noEmit零报错; - 写了个脚本逐个比对,17 个翻译命名空间,简体、英文、繁体三套键结构完全对齐,一个不差;
- 起前端实测三语切换,同一个页面,简、英、繁来回切,文案全部正确,繁体是地道的台湾用词,浏览器控制台零缺键警告。
下面这组图,就是同一个生成页在三种语言下的样子,从"生成"到 Generate 到"生成",从中文按钮到英文到繁体,是真能切的:
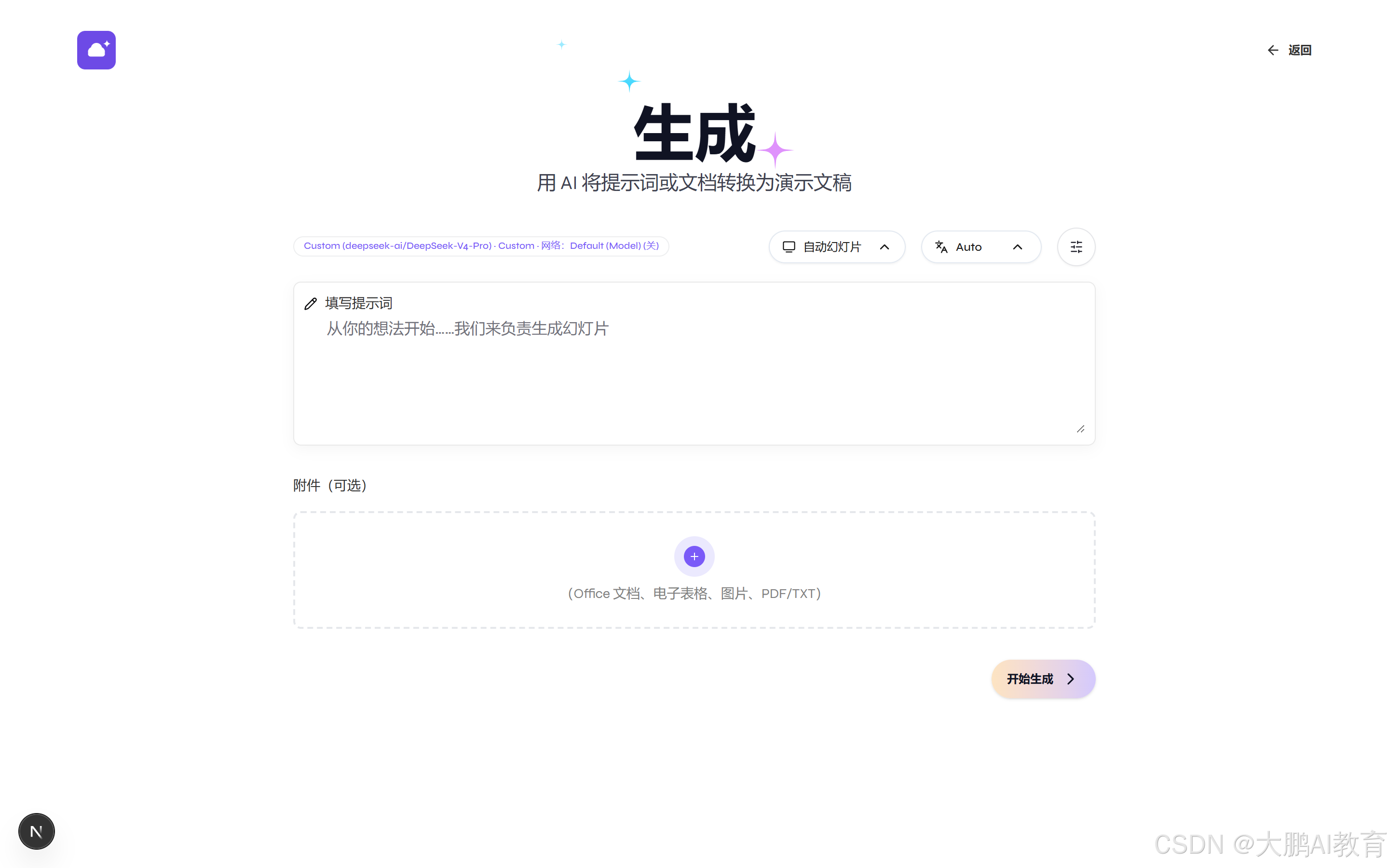
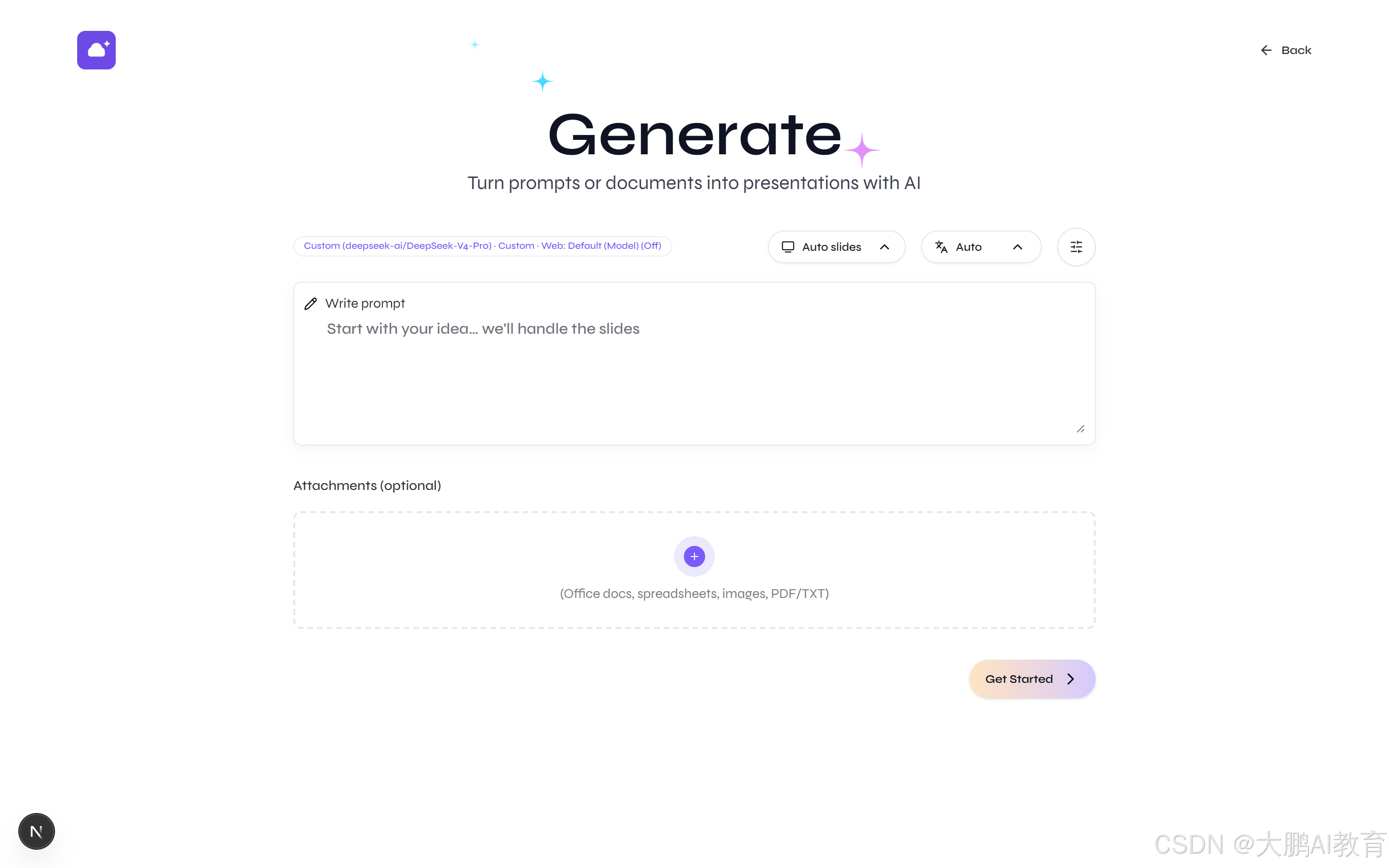
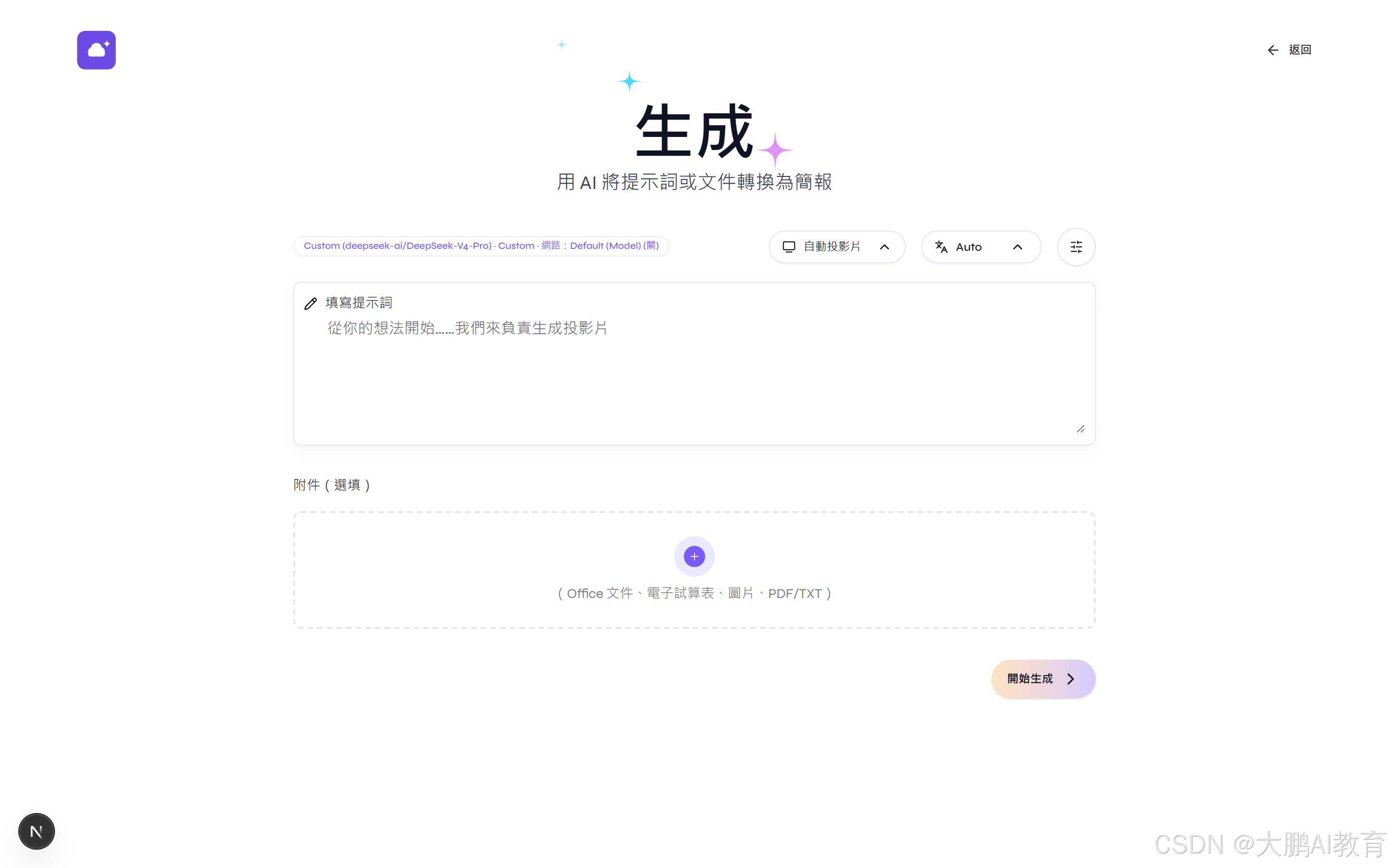
四、品牌化:从 Presenton,到"如意课件"
界面中文了,但产品还叫 Presenton。品牌化这条线,我分了六步,把它从里到外换成自己的:
- 前端所有用户可见的产品名,Presenton 换成"如意课件 / RuyiCourse"。
- 一套祥云方向的 logo,连同运行时资源全部落地。
- Electron 桌面壳的身份,应用标识改名,并把指向原作者的自动更新中和掉,免得我的桌面应用去检查人家的更新。
- 内部环境变量前缀 ,把那一类内部变量从
PRESENTON_改名成RUYICOURSE_。 - 域名和社交引用,对外链接换成我们自己的,移除掉指向原项目的帮助入口和社群入口。
- 模板样例里的联系方式,换成我们自己的。
这里我守了一条纪律,叫外科手术式改动 :只换该换的,绝不顺手去重构无关的代码。二开一个上万文件的大项目,最容易翻车的就是手痒,看哪儿不顺眼都想改,结果改出一堆新问题。改名就老老实实改名,别夹带私货。
五、顺手填的几个坑
做上面这些的过程里,我也撞见并修掉了几个真问题,一并记下:
- 开发时真实浏览器里,流式生成会卡。 排查下来是前端经 Next 的代理去连后端,那层代理把流式响应缓冲了、还对慢请求超时。我让开发模式下浏览器直连后端,绕开这层缓冲,大纲才能真正一个字一个字地流出来。
- 生成页顶上的模型徽章显示的型号是错的,图像开关也被错误关掉了。 根子是开发环境前端读了一份占位配置。我让它改读真实配置,徽章正确显示了在用的模型,图像生成也恢复了。
这些都不是大功能,但它们卡着真实可用性,不修,前面做的一切体验都打折。
六、接下来要做什么
国际化和品牌化这两块地基浇好了,楼才能往上盖。往后的方向很清楚:
- 课件工作流 ,这才是这个产品真正的差异点。普通 AI PPT 工具是"输入主题,生成 PPT,导出"三步;我要做的是课程项目、课程结构、讲稿、配图提示词、练习题、录课提词稿、发布文案一整条课程生产链,从"AI 做 PPT"升级成"AI 做课程"。
- 把实测跑出来的毛病一个个修掉。我上一篇实测时亲手跑出了几个真问题:通用模板会把一节"课"套成"商业路演"的结构、个别状态文案还是英文、配图标的本地模型没用上这台机器的 GPU。这些都进了我的优化清单。
- 补上推迟的导出多语言,再往商业化版本走,个人版、专业版、机构版。
所以这一版你别看它"只是国际化加改名",它是我把这个项目从一个英文开源工具,正式扭向"中国老师的 AI 课件工厂"、并打上自己烙印的关键一版 。地基不起眼,但楼是盖在它上面的。
这是 v0.1.1 的发版记录。下一篇,我们继续往上盖。我们下一篇见。
本文所有技术论断均对照 RuyiCourse v0.1.1 实际代码、git 提交与开发记录核实:后端语言约束见 servers/fastapi/utils/llm_calls/generate_slide_content.py;模板写死文本收编与模板选择器三语化见对应模板组件与 i18n 翻译命名空间;品牌化六步、开发流式直连与配置徽章修复,均对应仓库中相应提交。三语切换截图取自本地实跑界面。