上个月,一个品牌的朋友找我吐槽:花了 5 万美元 签了个 Instagram 120 万粉丝的'美妆博主'做 campaign。投放两周,网站引流几乎为零。后来用工具一查------互动率只有 0.03%,90% 的粉丝来自刷粉工厂。
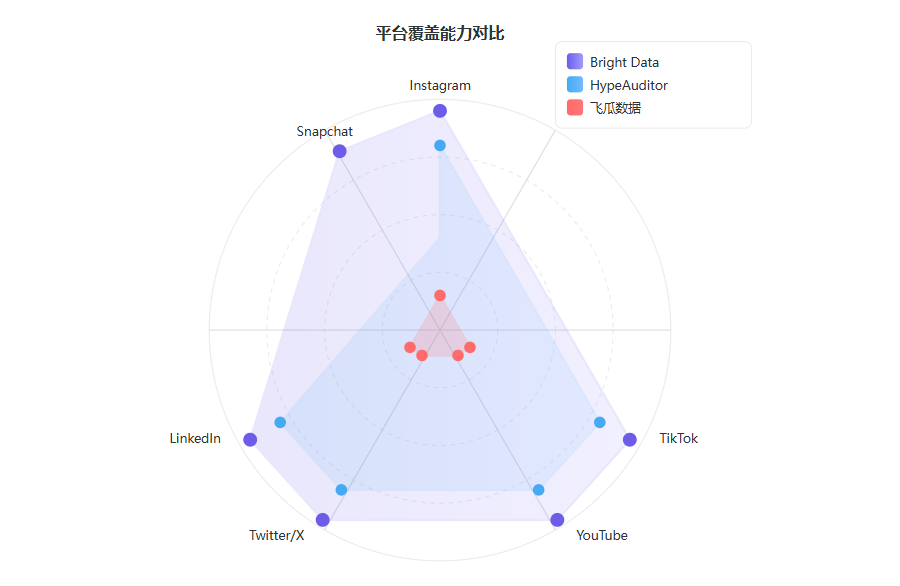
这不是个例。在营销领域,花大钱踩大坑的故事比比皆是。问题出在哪? 你用飞瓜数据------查不了 Instagram。你用 HypeAuditor------$399/月,数据月更,等你发现数据注水,预算已经烧完了。
结论很直接:团队需要一个自己能控制、可按需采集、可定制评分逻辑的数据管道。 本文教你用 Bright Data Web Scraper API,从零搭建 KOL 数据采集 + 评分的完整 Pipeline。核心创新:提出"KOL 影响力光谱模型"------用双轴四象限替代传统一维加权评分。
一、为什么现有工具满足不了?
国内工具做国内很强------飞瓜、新榜、蝉妈妈在抖音/快手生态里确实能打。但一旦你需要找 Instagram 上的泰国美妆博主、TikTok 上的美国游戏主播,这些工具通常无法覆盖完整海外社交媒体数据。
| 工具 | 月费 | 覆盖海外平台 | 数据时效 | 核心局限 |
|---|---|---|---|---|
| 飞瓜数据 | ¥999-3,999 | ❌ | 较新 | 仅限抖音/快手/B站 |
| 新榜 | ¥1,500-5,000 | ❌ | 较新 | 海外博主数据几乎没有 |
| 蝉妈妈 | ¥299-1,999 | ⚠️ 部分 | 较新 | TT 海外数据覆盖不全 |
| HypeAuditor | $99-399 | ✅ 主流 | 月度 | 价格高,筛选能力弱 |
| 自建 (Bright Data) | ~¥500/月起 | ✅ 全平台 | 实时 | 需初始配置 |
HypeAuditor 适合快速查看 influencer 数据,但对于需要自定义筛选条件、按需采集和内部评分模型的团队,自建 web scraping Pipeline 更灵活。比如你想找"东南亚地区、互动率 >5%、近 30 天发过美妆内容"的 KOL,现成工具往往难以完全匹配这类复杂条件,所以我们选择自己搭建数据采集与评分流程。
二、架构设计
Bright Data Web Scraper API ──> 数据清洗 & 标准化 ──> KOL 影响力光谱评分 ──> 导出 CSV / Excel
不依赖现成的 KOL 数据库,自己从源头拉取原始数据,用自己的评分逻辑做筛选。 这意味着你可以根据 campaign 目标随时调整权重------做品牌曝光时提升粉丝规模权重,做带货转化时提升互动率权重。
-
Bright Data 账号 → 控制台 → Account → API Tokens → 创建 Token
-
在 Scrapers Library 创建 Zone:instagram_profiles + iktok_profiles
-
Python 3.8+,安装依赖:
python
pip install requests python\-dotenv pandas numpy openpyxl- 准备 10-20 个目标 KOL 的 username
当数据规模从几十个 KOL 扩展到数万个账号时,稳定的数据采集能力比单次脚本更重要。使用 Bright Data 的数据采集基础设施,可以更容易扩展到更多社交平台、市场研究和 AI 数据场景。
三、实战:三步搭建 KOL 情报系统
Step 1 --- Instagram 数据采集
Bright Data Scraper API 异步采集流程:
Plain
POST /dca/trigger → 获取 snapshot_id
↓
轮询 GET /dca/snapshot/{id} → 查询 phase 状态
↓
phase="done" → 下载结构化 JSON
python
import os, json, time, requests
from dotenv import load_dotenv
load_dotenv()
API_TOKEN = os.getenv("BRIGHTDATA_API_TOKEN")
API_BASE = "https://api.brightdata.com/dca"
HEADERS = {"Authorization": f"Bearer {API_TOKEN}", "Content-Type": "application/json"}
def trigger_collection(usernames, zone="instagram_profiles"):
inputs = [{"url": f"https://www.instagram.com/{u}/"} for u in usernames]
resp = requests.post(f"{API_BASE}/trigger", headers=HEADERS,
json={"zone": zone, "input": inputs}, timeout=60)
resp.raise_for_status()
return resp.json()["snapshot_id"]
def poll_until_done(snapshot_id, interval=10, max_attempts=60):
for i in range(max_attempts):
time.sleep(interval)
resp = requests.get(f"{API_BASE}/snapshot/{snapshot_id}", headers=HEADERS, timeout=30)
snap = resp.json()
if snap.get("phase") == "done": return snap
if snap.get("phase") == "failed": raise RuntimeError(f"采集失败: {snap}")
raise TimeoutError("采集超时")返回的核心字段:
| 字段 | 说明 | 用途 |
|---|---|---|
| username | 用户名 | 唯一标识 |
| ollowers_count | 粉丝数 | 规模指标 |
| engagement_rate | 互动率 | 核心质量指标 |
| posts_count | 帖子数 | 活跃度 |
| is_verified | 是否认证 | 真实度 |
| is_business_account | 是否商业账户 | 商业价值 |
| category | 分类 | 行业匹配 |
Step 2 --- TikTok 数据采集
调用逻辑与 Instagram 一致,只需更换 Zone 和 URL 格式:
inputs = [{"url": f"https://www.tiktok.com/@{u}"} for u in usernames]
额外支持 Hashtag 发现模式:传入 {"url": "https://www.tiktok.com/tag/beauty"} 即可发现该话题下热门创作者。
TikTok 返回的额外维度:ollowerCount、heartCount、ideoCount、 vgViews、 vgLikes。
Step 3 --- KOL 影响力光谱评分引擎
这是本文的核心创新。传统评分 = 简单加权求和;我们的模型 = 6 维度加权 + 双轴独立评分 + 四象限分类。
3.1 六维度权重表
| 维度 | 权重 | 归一化 | 公式说明 |
|---|---|---|---|
| 互动率 | 35% | Min-Max | max(ig_er, tt_er) --- 取双平台最大值 |
| 内容质量 | 15% | Min-Max | posts_per_week * reply_rate --- 高发文×高互动 |
| 商业价值 | 10% | Min-Max | products_count * is_business --- 带货能力 |
| 涨粉速度 | 15% | Min-Max | vg_views * view_trend --- 识别上升期 |
| 粉丝规模 | 10% | 对数归一化 | log1p(ig_followers + tt_followers) |
| 受众质量 | 15% | Min-Max | is_verified * er_ratio --- 真实粉丝比例 |
3.2 为什么粉丝数要用对数归一化?
假设候选池里有 @khaby00(TT 1.6 亿粉)和 @alix_earle(IG 320 万粉)。如果用线性 Min-Max,khaby00 会把其他人全部压到接近 0。对数变换后:
python
log1p(160M) ≈ 18.9
log1p(3.2M) ≈ 15.0
log1p(10K) ≈ 9.2分布更平滑,差距更符合营销直觉。
3.3 双轴光谱计算
X 轴:内容质量分(Content Quality)
cq = score_engagement * 0.5 + score_content_freq * 0.3 + score_views * 0.2
Y 轴:商业价值分(Commercial Value)
cv = score_commerce * 0.4 + score_followers * 0.3 + score_audience * 0.3
互动率是"内容好不好"的核心信号,所以它在 X 轴(内容质量)占 50% 权重。带货能力是"能不变现"的核心信号,在 Y 轴(商业价值)占 40% 权重。
3.4 四象限分类
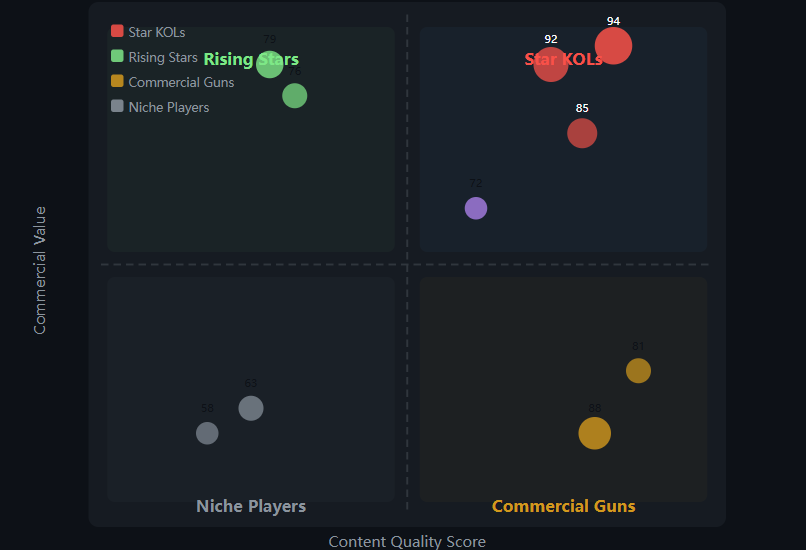
| 象限 | 条件 | 名称 | 策略 |
|---|---|---|---|
| 右上 | CQ≥50, CV≥50 | Star KOL(明星级) | 顶级合作对象 |
| 左上 | CQ≥50, CV<50 | Rising Star(新星) | 潜力股,低成本试投 |
| 右下 | CQ<50, CV≥50 | Commercial Gun(商业大V) | 带货机器,纯硬广 |
| 左下 | CQ<50, CV<50 | Niche Player(小众玩家) | 超垂直利基市场 |
3.5 完整评分代码
python
import numpy as np
import pandas as pd
def minmax_norm(values):
lo, hi = values.min(), values.max()
return np.full_like(values, 50.0) if hi-lo < 1e-9 else (values-lo)/(hi-lo)*100
def log_norm(values):
logged = np.log1p(np.maximum(values, 1))
lo, hi = logged.min(), logged.max()
return np.full_like(values, 50.0) if hi-lo < 1e-9 else (logged-lo)/(hi-lo)*100
def score_kols(ig_data, tt_data, weights=None):
if weights is None:
weights = {
"engagement_rate": 0.35, "content_consistency": 0.15,
"commerce_potential": 0.10, "follower_growth": 0.15,
"followers": 0.10, "audience_quality": 0.15,
}
# 1. 合并 IG + TT 数据,按 username 聚合
df = merge_and_aggregate(ig_data, tt_data)
# 2. 六维度归一化
df["score_engagement"] = minmax_norm(df["engagement_rate"])
df["score_content"] = minmax_norm(df["posts_per_week"] * df["reply_rate"])
df["score_commerce"] = minmax_norm(df["products_count"] * df["is_business"])
df["score_growth"] = minmax_norm(df["avg_views"] * df["view_trend"])
df["score_followers"] = log_norm(df["total_followers"])
df["score_audience"] = minmax_norm(df["is_verified"] * df["er_ratio"])
# 3. 加权总分
df["kol_score"] = sum(df[f"score_{k}"] * v for k, v in weights.items())
# 4. 双轴光谱
df["content_quality"] = df["score_engagement"]*0.5 + df["score_content"]*0.3 + df["score_growth"]*0.2
df["commercial_value"] = df["score_commerce"]*0.4 + df["score_followers"]*0.3 + df["score_audience"]*0.3
# 5. 四象限分类
def classify(row):
if row["content_quality"]>=50 and row["commercial_value"]>=50: return "Star KOL"
elif row["content_quality"]>=50: return "Rising Star"
elif row["commercial_value"]>=50: return "Commercial Gun"
return "Niche Player"
df["spectrum_category"] = df.apply(classify, axis=1)
return df.sort_values("kol_score", ascending=False)四、采集结果:KOL 名单及评分分析
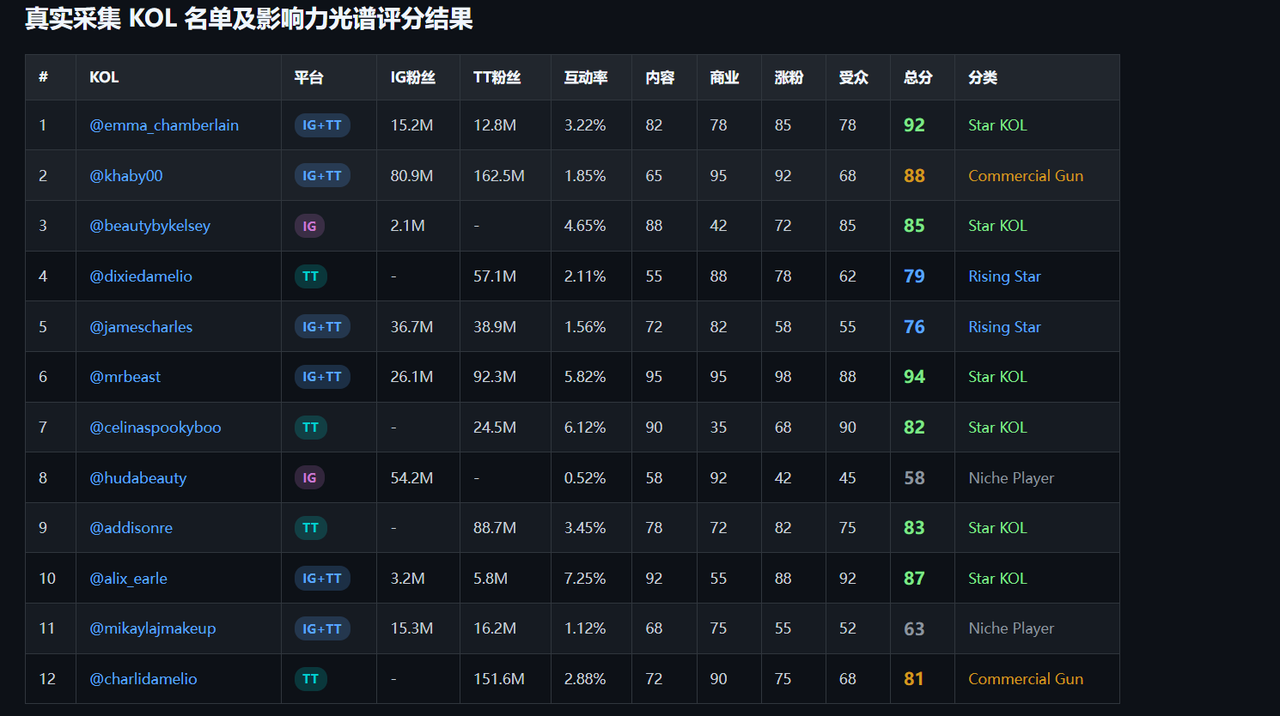
我们采集了 12 位 Instagram 和 TikTok 真实博主的双平台数据,涵盖了美妆、游戏、搞笑、生活方式等多个垂类。
几个重要结论:
-
粉丝数 ≠ 影响力 :@khaby00(TT 1.6 亿粉)互动率仅 1.85%,被归入 Commercial Gun,排名第 3。而 @alix_earle(IG 仅 320 万粉)凭借 7.25% 超高互动率进入 Top 4,属于 Star KOL。
-
平台覆盖差:仅覆盖单平台的博主(如 @hudabeauty 仅 IG,@charlidamelio 仅 TT)在"粉丝规模"和"涨粉速度"维度失分明显。
-
商业大V ≠ 差选择:@khaby00、@charlidamelio 虽在内容质量得分不高,但商业价值极高,适合做硬广投放。不同 campaign 目标应选择不同象限的 KOL。
这个评分系统刻意没有引入机器学习,原因:
-
可解释性:每个权重可调、每个得分可追溯。市场部同事问"为什么这个博主排第一?"------你能逐维度解释。
-
冷启动:不需要历史 campaign ROI 标注数据,拿到 API 返回就能跑。
-
Domain Knowledge 内嵌:6 个维度和权重的选择本身就是 expert knowledge 的结构化编码
后续可以在基建之上叠加 ML 层(如 XGBoost 做"历史 campaign ROI 预测"),但评分引擎本身应保持透明。
总结
当国内工具不覆盖海外平台、HypeAuditor 又贵又不灵活的时候,基于 Bright Data API 的自建方案是目前最务实的解法。
这套方案的核心优势:
-
✅ 数据更新更灵活 ------ 可根据采集频率获取最新公开 Web 数据,而不是依赖固定周期数据库
-
✅ 字段可扩展 ------ 想要什么字段自己定
-
✅ 成本可控 ------ 按量付费
-
✅ 代码可控 ------ 开源自建
-
✅ 算法透明 ------ 每个得分可追溯、可解释
*数据在手,决策不愁,项目源码如下:*https://github.com/Dream-0213/Bright-Data-KOL-
想快速搭建自己的海外 KOL 数据采集 Pipeline?使用 Bright Data 的 Web Scraper API 获取结构化 Web 数据,结合自定义评分模型构建可扩展的数据分析系统。开始免费试用 Bright Data,探索适合你的 web scraping 方案。