Ultralytics:解读RepConv模块
- 前言
- 相关介绍
-
-
- [Ultralytics 简介](#Ultralytics 简介)
-
- 前提条件
- 实验环境
- RepConv(RepVGG风格可重参数化卷积)
-
-
- 代码实现
- 功能
- 初始化参数
- 前向方法
- 融合机制详解
-
- [1. 融合原理](#1. 融合原理)
- [2. 关键函数](#2. 关键函数)
- 使用示例
- 流程示意图
- 代码解读
-
- [`init` 方法](#
__init__方法) - [`forward` 和 `forward_fuse`](#
forward和forward_fuse) - `_fuse_bn_tensor`
- `get_equivalent_kernel_bias`
- `fuse_convs`
- [`init` 方法](#
- 注意事项
- 优缺点
-
- 参考文献

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)
相关介绍
Ultralytics 简介
Ultralytics 基于多年的计算机视觉和人工智能基础研究,创建了最先进的 (SOTA) YOLO 模型。我们的模型不断更新性能和灵活性,快速、准确且易于使用。他们擅长对象检测、跟踪、实例分割、语义分割、图像分类和姿势估计任务。
前提条件
- 熟悉Python、Pytorch
实验环境
bash
Package Version
------------------------ ------------
Python 3.11.8
absl-py 2.4.0
accelerate 1.13.0
annotated-doc 0.0.4
anyio 4.13.0
calflops 0.3.2
certifi 2026.4.22
charset-normalizer 3.4.7
click 8.3.3
colorama 0.4.6
contourpy 1.3.3
cycler 0.12.1
filelock 3.29.0
flatbuffers 25.12.19
fonttools 4.62.1
fsspec 2026.4.0
grpcio 1.80.0
h11 0.16.0
hf-xet 1.5.0
httpcore 1.0.9
httpx 0.28.1
huggingface_hub 1.14.0
idna 3.15
Jinja2 3.1.6
kiwisolver 1.5.0
Markdown 3.10.2
markdown-it-py 4.2.0
MarkupSafe 3.0.3
matplotlib 3.10.9
mdurl 0.1.2
ml_dtypes 0.5.0
mpmath 1.3.0
networkx 3.6.1
numpy 1.26.4
nvidia-cublas-cu12 12.8.3.14
nvidia-cuda-cupti-cu12 12.8.57
nvidia-cuda-nvrtc-cu12 12.8.61
nvidia-cuda-runtime-cu12 12.8.57
nvidia-cudnn-cu12 9.7.1.26
nvidia-cufft-cu12 11.3.3.41
nvidia-cufile-cu12 1.13.0.11
nvidia-curand-cu12 10.3.9.55
nvidia-cusolver-cu12 11.7.2.55
nvidia-cusparse-cu12 12.5.7.53
nvidia-cusparselt-cu12 0.6.3
nvidia-nccl-cu12 2.26.2
nvidia-nvjitlink-cu12 12.8.61
nvidia-nvtx-cu12 12.8.55
onnx 1.19.0
onnxruntime-gpu 1.26.0
onnxslim 0.1.94
opencv-python 4.6.0.66
packaging 26.2
pillow 12.2.0
pip 24.0
polars 1.40.1
polars-runtime-32 1.40.1
protobuf 7.34.1
psutil 7.2.2
pycocotools 2.0.11
Pygments 2.20.0
pyparsing 3.3.2
python-dateutil 2.9.0.post0
PyYAML 6.0.3
regex 2026.5.9
requests 2.34.1
rich 15.0.0
safetensors 0.7.0
scipy 1.16.0
setuptools 65.5.0
shellingham 1.5.4
six 1.17.0
sympy 1.14.0
tabulate 0.10.0
tensorboard 2.20.0
tensorboard-data-server 0.7.2
tokenizers 0.22.2
torch 2.7.1+cu128
torchaudio 2.7.1+cu128
torchvision 0.22.1+cu128
tqdm 4.67.3
transformers 5.8.1
triton 3.3.1
typer 0.25.1
typing_extensions 4.15.0
ultralytics 8.4.58
ultralytics-thop 2.0.19
urllib3 2.7.0
Werkzeug 3.1.8RepConv(RepVGG风格可重参数化卷积)
RepConv 是 RepVGG 思想在 Ultralytics 中的实现,广泛应用于 RT-DETR 等模型。它在训练时采用 多分支结构 (3×3 卷积 + 1×1 卷积 + 恒等映射),在推理时通过 结构重参数化 融合为单个 3×3 卷积,从而实现 训练时高精度、推理时高效率 的完美平衡。
代码实现
python
import cv2
import math
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution module with batch normalization and activation.
Attributes:
conv (nn.Conv2d): Convolutional layer.
bn (nn.BatchNorm2d): Batch normalization layer.
act (nn.Module): Activation function layer.
default_act (nn.Module): Default activation function (SiLU).
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given parameters.
Args:
c1 (int): Number of input channels.
c2 (int): Number of output channels.
k (int): Kernel size.
s (int): Stride.
p (int, optional): Padding.
g (int): Groups.
d (int): Dilation.
act (bool | nn.Module): Activation function.
"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Apply convolution and activation without batch normalization.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
return self.act(self.conv(x))
class RepConv(nn.Module):
"""RepConv module with training and deploy modes.
This module is used in RT-DETR and can fuse convolutions during inference for efficiency.
Attributes:
conv1 (Conv): 3x3 convolution.
conv2 (Conv): 1x1 convolution.
bn (nn.BatchNorm2d, optional): Batch normalization for identity branch.
act (nn.Module): Activation function.
default_act (nn.Module): Default activation function (SiLU).
References:
https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
"""Initialize RepConv module with given parameters.
Args:
c1 (int): Number of input channels.
c2 (int): Number of output channels.
k (int): Kernel size.
s (int): Stride.
p (int): Padding.
g (int): Groups.
d (int): Dilation.
act (bool | nn.Module): Activation function.
bn (bool): Use batch normalization for identity branch.
deploy (bool): Deploy mode for inference.
"""
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward pass for deploy mode.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
return self.act(self.conv(x))
def forward(self, x):
"""Forward pass for training mode.
Args:
x (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor.
"""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
"""Calculate equivalent kernel and bias by fusing convolutions.
Returns:
(torch.Tensor): Equivalent kernel
(torch.Tensor): Equivalent bias
"""
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
@staticmethod
def _pad_1x1_to_3x3_tensor(kernel1x1):
"""Pad a 1x1 kernel to 3x3 size.
Args:
kernel1x1 (torch.Tensor): 1x1 convolution kernel.
Returns:
(torch.Tensor): Padded 3x3 kernel.
"""
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
"""Fuse batch normalization with convolution weights.
Args:
branch (Conv | nn.BatchNorm2d | None): Branch to fuse.
Returns:
kernel (torch.Tensor): Fused kernel.
bias (torch.Tensor): Fused bias.
"""
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, "id_tensor"):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
"""Fuse convolutions for inference by creating a single equivalent convolution."""
if hasattr(self, "conv"):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(
in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True,
).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__("conv1")
self.__delattr__("conv2")
if hasattr(self, "nm"):
self.__delattr__("nm")
if hasattr(self, "bn"):
self.__delattr__("bn")
if hasattr(self, "id_tensor"):
self.__delattr__("id_tensor")功能
- 训练模式 :采用 三路并行结构 :
- 3×3 卷积(主分支)
- 1×1 卷积(旁路,用于跨通道特征融合)
- 恒等映射(identity,仅当输入输出通道相同且步长为 1 时存在,通过 BN 层实现)
- 三路输出相加后经过激活函数。
- 推理模式 :通过
fuse_convs()将三个分支合并为一个 等效的 3×3 卷积,此时无额外开销,速度与标准卷积相同。 - 核心优势:训练时增加模型容量和梯度多样性,提升精度;推理时无损融合,不增加延迟。
初始化参数
| 参数 | 类型 | 说明 |
|---|---|---|
c1 |
int | 输入通道数 |
c2 |
int | 输出通道数 |
k |
int | 卷积核大小(必须为 3) |
s |
int | 步长(默认 1) |
p |
int | 填充(必须为 1) |
g |
int | 分组数(默认 1) |
d |
int | 膨胀率(默认 1) |
act |
bool / nn.Module | 激活函数(与 Conv 一致) |
bn |
bool | 是否在恒等分支使用 BN(仅当 c2==c1 且 s==1 时生效) |
deploy |
bool | 是否直接进入部署模式(未使用,保留参数) |
assert k == 3 and p == 1强制核大小和填充,因为 RepVGG 设计假定 3×3 卷积。若需其他核大小,需修改代码。
前向方法
| 方法 | 流程 | 用途 |
|---|---|---|
forward(x) |
act(conv1(x) + conv2(x) + bn(x)) (若 bn 存在) |
训练阶段 |
forward_fuse(x) |
act(conv(x)) (融合后的单卷积) |
推理阶段(需先调用 fuse_convs()) |
融合机制详解
1. 融合原理
- 每个分支(3×3、1×1、identity)均包含卷积(或恒等)与 BN(如有)。通过数学推导,可将 卷积 + BN 合并为一个带偏置的卷积层。
- 1×1 卷积等价于一个特殊 3×3 卷积(中心填充),恒等映射等价于一个在中心位置为 1 的 3×3 卷积核(单位矩阵)。
- 三个分支的等效卷积核和偏置相加,得到最终的单卷积核。
2. 关键函数
_fuse_bn_tensor(branch):将分支中的卷积与 BN 融合,返回等效的(kernel, bias)。- 若分支是
Conv,则取其卷积权重和 BN 参数。 - 若分支是
BatchNorm2d(恒等分支),则构造一个单位 3×3 卷积核,并与 BN 参数融合。
- 若分支是
_pad_1x1_to_3x3_tensor(kernel1x1):将 1×1 核填充为 3×3(在四周各补一圈零)。get_equivalent_kernel_bias():分别计算三个分支的等效核与偏置,相加得到最终等效参数。fuse_convs():创建新的nn.Conv2d,用等效参数赋值,删除原分支,并将forward重定向为forward_fuse。
使用示例

python
if __name__ == '__main__':
# 1. 读取图像(请将路径改为您自己的图片)
img_path = "cat_640x640.png" # 或使用绝对路径
img_bgr = cv2.imread(img_path)
if img_bgr is None:
raise FileNotFoundError(f"图片 {img_path} 不存在!请检查路径。")
# 2. 转换为 RGB,并转为 PyTorch 张量 (H,W,C) -> (C,H,W) -> (1,C,H,W)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
img_tensor = torch.from_numpy(img_rgb).float().permute(2, 0, 1).unsqueeze(0)
# 3. 创建 RepConv 层:输入3通道,输出16通道,核3×3,步长2(下采样),无恒等分支
rep_layer = RepConv(c1=3, c2=16, k=3, s=2, p=1, g=1, act=True, bn=False)
# 重要:切换到 eval 模式,固定 BN 的 running_mean 和 running_var,确保融合前后统计量一致
rep_layer.eval()
# 4. 训练模式前向(未融合,三路分支)
with torch.no_grad():
out_train = rep_layer(img_tensor)
print("训练模式输出形状:", out_train.shape) # torch.Size([1, 16, 320, 320])
# 5. 融合分支(将 3x3、1x1 和 identity 合并为单个 3x3 卷积)
rep_layer.fuse_convs()
print("融合完成,conv1/conv2/bn 已删除,新 conv 已创建")
# 6. 推理模式前向(融合后的单卷积,必须使用 forward_fuse)
with torch.no_grad():
out_deploy = rep_layer.forward_fuse(img_tensor)
print("推理模式输出形状:", out_deploy.shape) # torch.Size([1, 16, 320, 320])
# 7. 验证融合前后一致性(差异应接近于 0,通常 < 1e-4)
diff = torch.abs(out_train - out_deploy).max().item()
print(f"融合前后最大绝对差异: {diff:.6f}")
# 8. 可视化融合后的特征图(第一个通道)
feat_map = out_deploy[0, 0, :, :].cpu().numpy()
# 归一化到 0~255 便于显示
feat_map = (feat_map - feat_map.min()) / (feat_map.max() - feat_map.min() + 1e-8)
feat_map = (feat_map * 255).astype(np.uint8)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.title("Original Image")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(feat_map, cmap='gray')
plt.title("RepConv (Fused) - Channel 0")
plt.axis("off")
plt.tight_layout()
plt.savefig("repconv_output.png", dpi=150)
# 若有图形界面,可取消下面一行的注释以显示窗口
# plt.show()
print("可视化已保存为 repconv_output.png")输出示例:
训练模式输出形状: torch.Size([1, 16, 320, 320])
融合完成,conv1/conv2/bn 已删除,新 conv 已创建
推理模式输出形状: torch.Size([1, 16, 320, 320])
融合前后最大绝对差异: 0.000092
可视化已保存为 repconv_output.png流程示意图
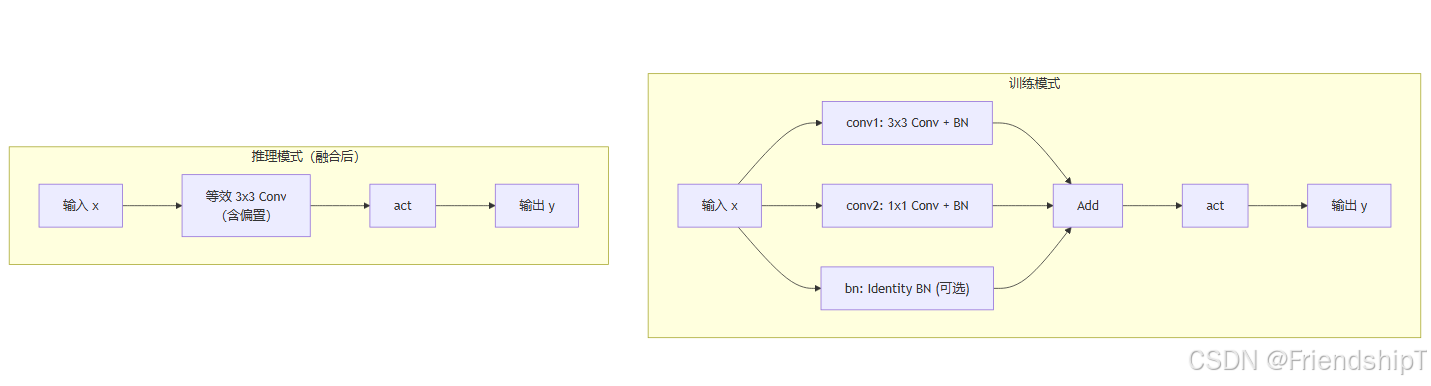
代码解读
__init__ 方法
- 强制
k==3和p==1,确保兼容 RepVGG 设计。 self.bn:仅当bn=True且c1==c2且s==1时创建,用于恒等映射。self.conv1:3×3 主卷积,无激活(act=False,但后续在forward中统一加)。self.conv2:1×1 卷积,其填充通过p - k//2计算(若p=1, k=3,则填充为1-1=0,即无填充),步长与主卷积一致。
forward 和 forward_fuse
forward:三路相加后激活;若bn为None,则id_out=0。forward_fuse:直接使用融合后的self.conv(需先调用fuse_convs)。
_fuse_bn_tensor
- 该函数将卷积和 BN 合并为等效卷积核与偏置,公式为:
kernel = conv.weight * gamma / sqrt(running_var + eps)bias = beta - running_mean * gamma / sqrt(running_var + eps)
- 当分支是 BN 时(恒等分支),构造一个单位矩阵卷积核,再进行同样的融合。
get_equivalent_kernel_bias
- 分别融合三个分支,将 1×1 核填充为 3×3,三者相加。
fuse_convs
- 创建新
nn.Conv2d(bias=True),用等效参数赋值并冻结梯度。 - 删除原分支,释放内存,并将
forward隐式替换为forward_fuse(因为后续调用self(x)时,self.forward仍指向原方法,但通常需手动将forward指向forward_fuse?代码未显式重定向,但在融合后仍可调用forward_fuse。然而在示例中,rep_layer(img_tensor)会调用forward(训练模式),这样会出错,因为原分支已删除。因此需在使用时注意:融合后应调用forward_fuse或重新定义forward。但官方实现中会动态修改forward,本代码未包含此操作,可能是一个小瑕疵。使用时需手动处理。我们可以在说明中提醒。
注意 :融合后直接调用
forward会因分支缺失而报错,需调用forward_fuse。为方便,可在fuse_convs末尾添加self.forward = self.forward_fuse,但原代码未做。故在使用时需注意。
注意事项
- 融合前后调用方法 :训练时使用
forward;融合后应使用forward_fuse,否则会因缺失conv1等属性而报错。可自行在fuse_convs末尾添加self.forward = self.forward_fuse。 - 恒等分支的条件 :只有当
c1==c2且s==1且bn=True时,恒等分支才生效。若条件不满足,则无恒等分支。 - 分组卷积 :
g参数同时作用于主卷积和 1×1 卷积,恒等分支的构造考虑了分组情况(input_dim = c1 // g)。 - 激活函数 :训练和推理共用一个
act,融合后仍保留激活。 - 部署模式 :参数
deploy当前未使用,可扩展为直接创建单卷积。 - 内存占用:训练时三路分支占用额外显存,但推理时仅单路。
优缺点
优点
- 训练精度高:多分支结构相当于隐式集成,提升模型表达能力。
- 推理零损耗:融合后与标准卷积速度一致,不增加任何额外计算。
- 即插即用 :可无缝替换普通
Conv,提升性能。 - 已被广泛验证:RepVGG 在 ImageNet 等任务上表现优异。
缺点
- 训练资源消耗大:三路分支增加约 2 倍计算和显存。
- 融合逻辑复杂:需处理 BN 融合、1×1 填充等,代码维护成本高。
- 灵活性受限:强制核大小为 3,难以适应特殊设计。
- 使用时需注意切换:融合后需调用不同 forward 方法,否则容易出错。
在 RT-DETR 和 YOLOv8 的某些变体中,RepConv 被用作骨干网络的基本构建块。建议训练时开启多分支,推理前调用 fuse_convs() 并切换至 forward_fuse,以兼顾精度与速度。
参考文献
1 https://docs.ultralytics.com/
2 https://github.com/ultralytics/ultralytics.git
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)