本文介绍如何使用AiEduLab.tech从零构建、训练音频分类模型。流程非常简单:拖拽积木搭建模型------下载训练数据------训练模型------进行预测。
一、该实验所需软硬件条件
1、浏览器支持WebGL2.0。若打开训练页面后端显示CPU:
①若您的计算机操作系统内置Edge浏览器,可直接使用Edge浏览器。若未开启WebGL加速,参考以下Chrome浏览器设置方法。
② 在Chrom中点击右上角"...",在弹出菜单中选择"设置",在打开的页面左侧列表选择"系统",将页面中"使用图形加速功能(如果可用)"选项设置为开启。
③若您使用Win7操作系统,应安装Chrome109(最后一个支持Win7的版本)后,在地址栏输入"chrome://flags"并打开,搜索"Override software rendering list"以及"WebGL Developer Features"并设置为打开状态。如果仍无法启用,则搜索WebGL并开启相关选项且更新您显卡的驱动再试。
2、使用核显、独立显卡均可。服务器不会收集我们的数据,也不会保存模型,所有算力均使用本地计算机算力。
二、音频分类方法
音频分类时有些使用原始波形,有些使用处理后的波形,它们各有优劣,但当前的主流还是把声音转换成更成熟的图像喂给模型。在本实验中,我们使用的是处理后的波形------将声音转化为梅尔谱图,而后用类似于手写数字分类的模型来学习分类任务。
1、模型构建中需要注意的问题:之前使用MNIST数据集进行文本分类时,图片为单通道28*28,所以输入为(None,28,28,1)。当前梅尔图谱页使用单通道,而图片大小需要根据数据管理器的设置来填写。例如采用以下设置:
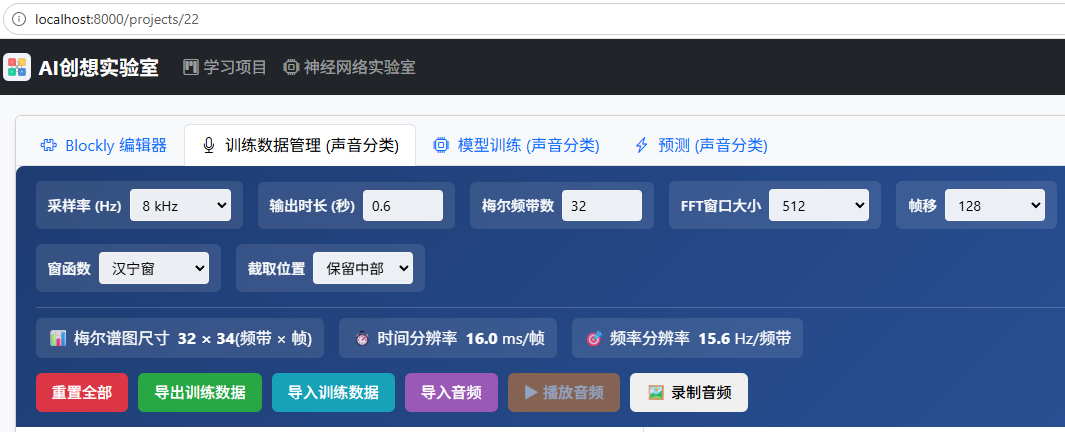
那么,输入应设置为(None,32,34,1),即在设置之后界面上所提示的32×34(频带×帧)的值。采样率、梅尔频带数、FFT大小、帧移等参数会直接影响最终梅尔谱图里声音细节保留多少------影响图片的大小:如果追求保留更多细节,那么生成的图片也会较大,训练速度也就会慢一些。
2、模型
使用类似之前MNIST手写数字分类的模型即可:

构建好模型之后,点击"导出XML"以供下次重新编辑模型,点击"导出训练模型"得到用于训练的JSON模型。
3、数据和清洗
为了便于初学者学习,我们使用公开数据集FSDD。在有条件的情况下,推荐更换为自己采集的数据集。
和图像分类相同的,首先配置维度:我们的模型是顺序模型------单输出头,所以数据维度只有一个,它含有10个标签。在数据管理器中右侧列表区域显示的是实际的梅尔谱图,而左侧预览区域显示的是着色之后的图片------人眼对彩色图片比灰度图更敏感,这使得我们易于观察梅尔谱图的差异。
如果我们需要观察原始音频,可以在"预测器"或"录制音频"工具导入(录制)它们进行观察。
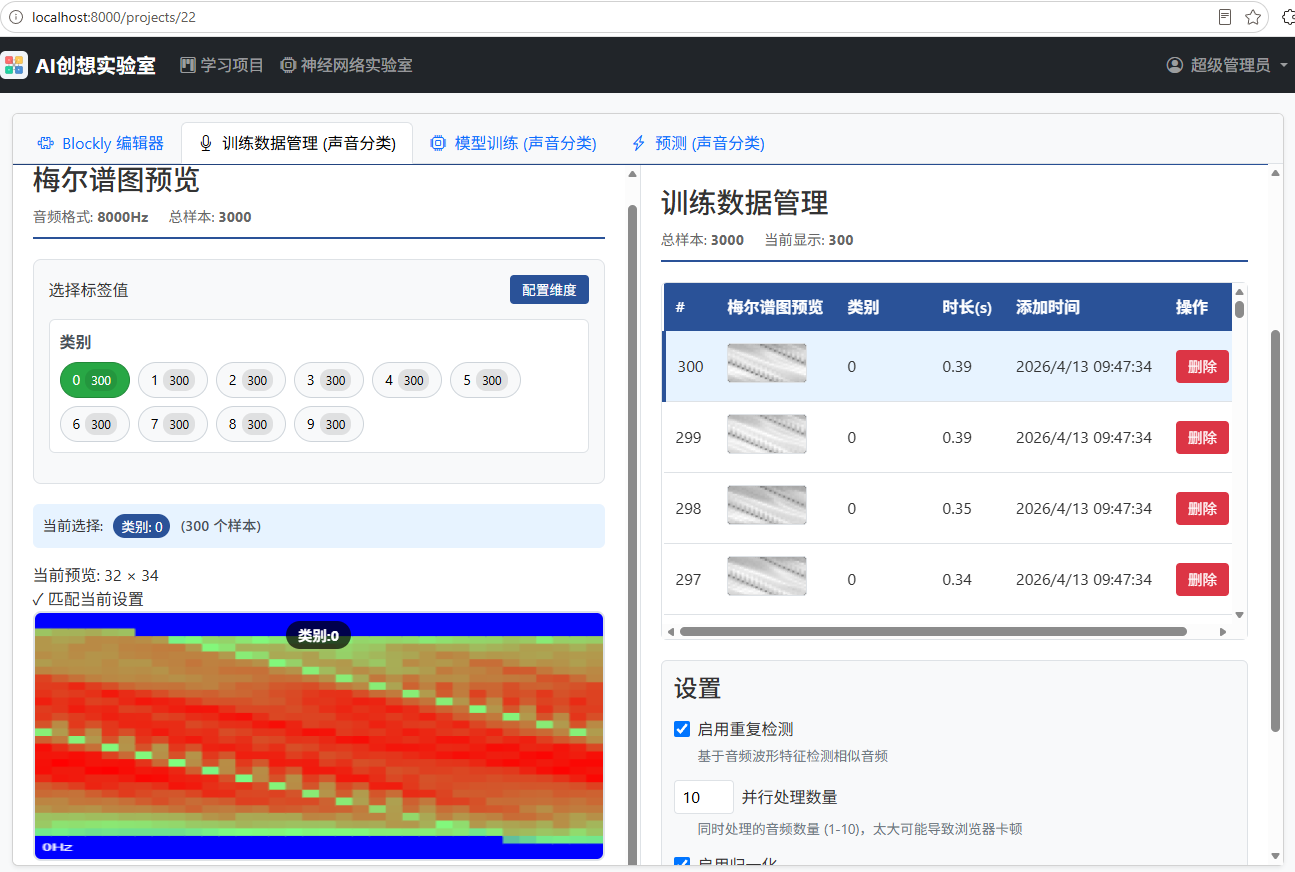
对于初学者,"设置"保持默认是最好的选择。得到样本之后,点击"导出训练数据"即可。
4、模型训练
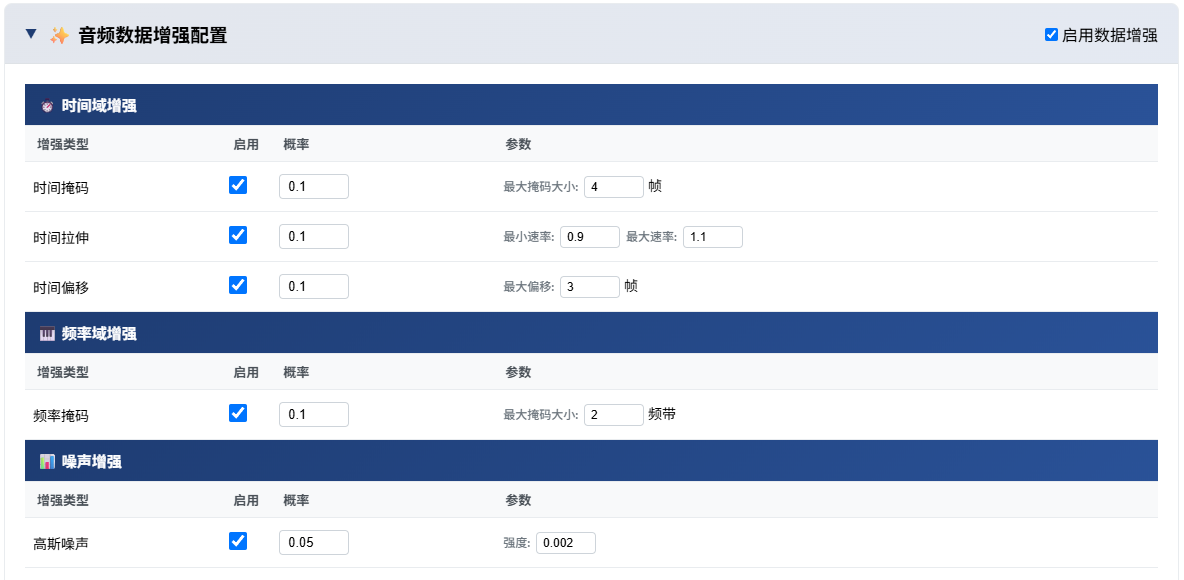
在模型训练器中,导入做好的JSON模型和训练数据,而后配置音频增强(如果你使用的数据中每个标签都达到几千那么可以不启用,但如果数据量和范例一样少,那么应该开启数据增强):
而后,配置学习率、批次大小等超参数,即可点击"开始训练"按钮开始训练模型,训练过程中关注训练损失---验证损失各自变化和相对大小关系,以判定模型训练效果;对于该实验也可以简单的观察acc和val_acc,如下图使用范例模型和数据在几轮训练之后就能看到明显效果:
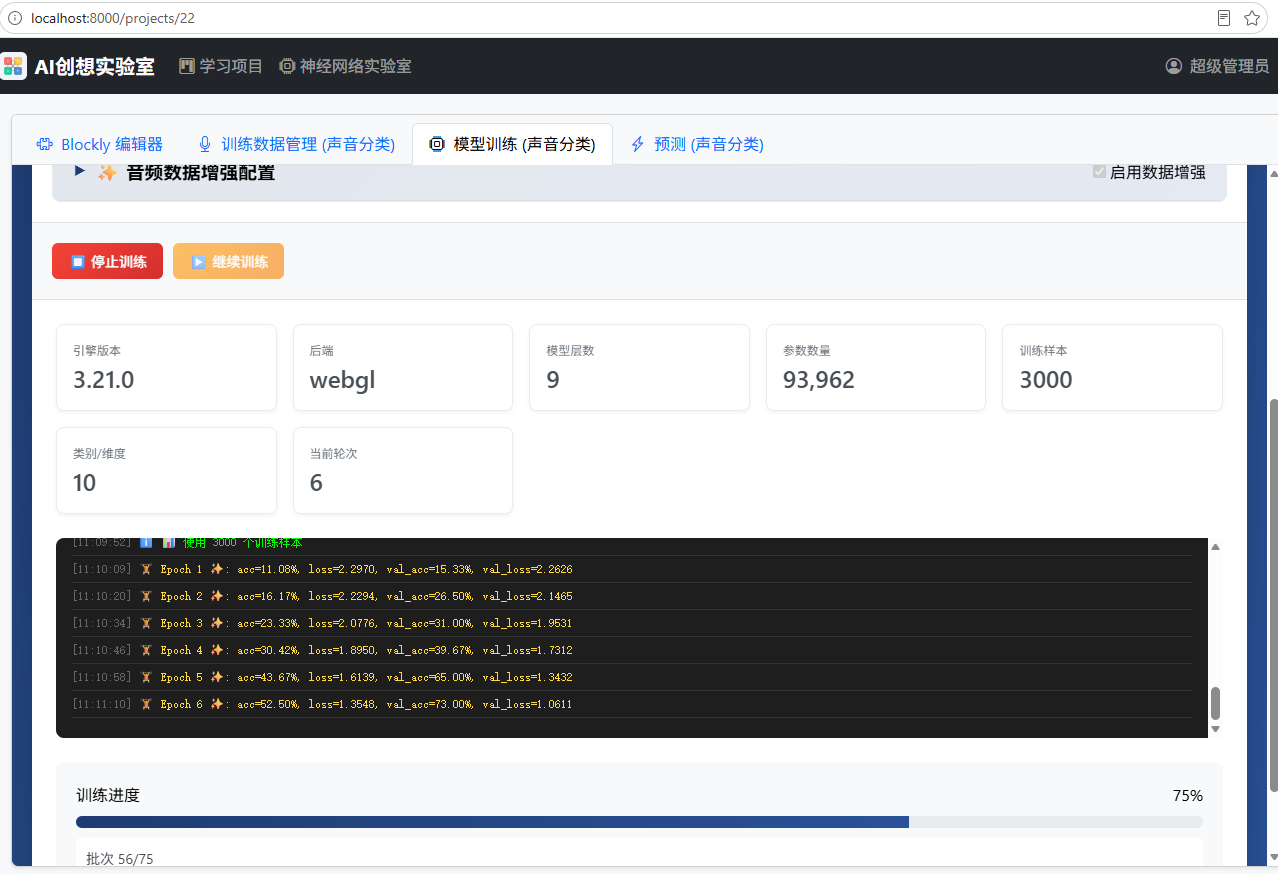
如果想要取得更好的训练效果,应增增加训练轮数直到模型表现出过拟合倾向停止训练、增加训练数据、增加模型容量。这些请自行验证。
5、预测------模型的使用
训练结束后,点击"导出已训练模型",然后把模型导入到预测器中。此时,可以选择录音或导入文件来进行预测,第一次预测耗时会较长,后续耗时应在几毫秒到几十毫秒之间:
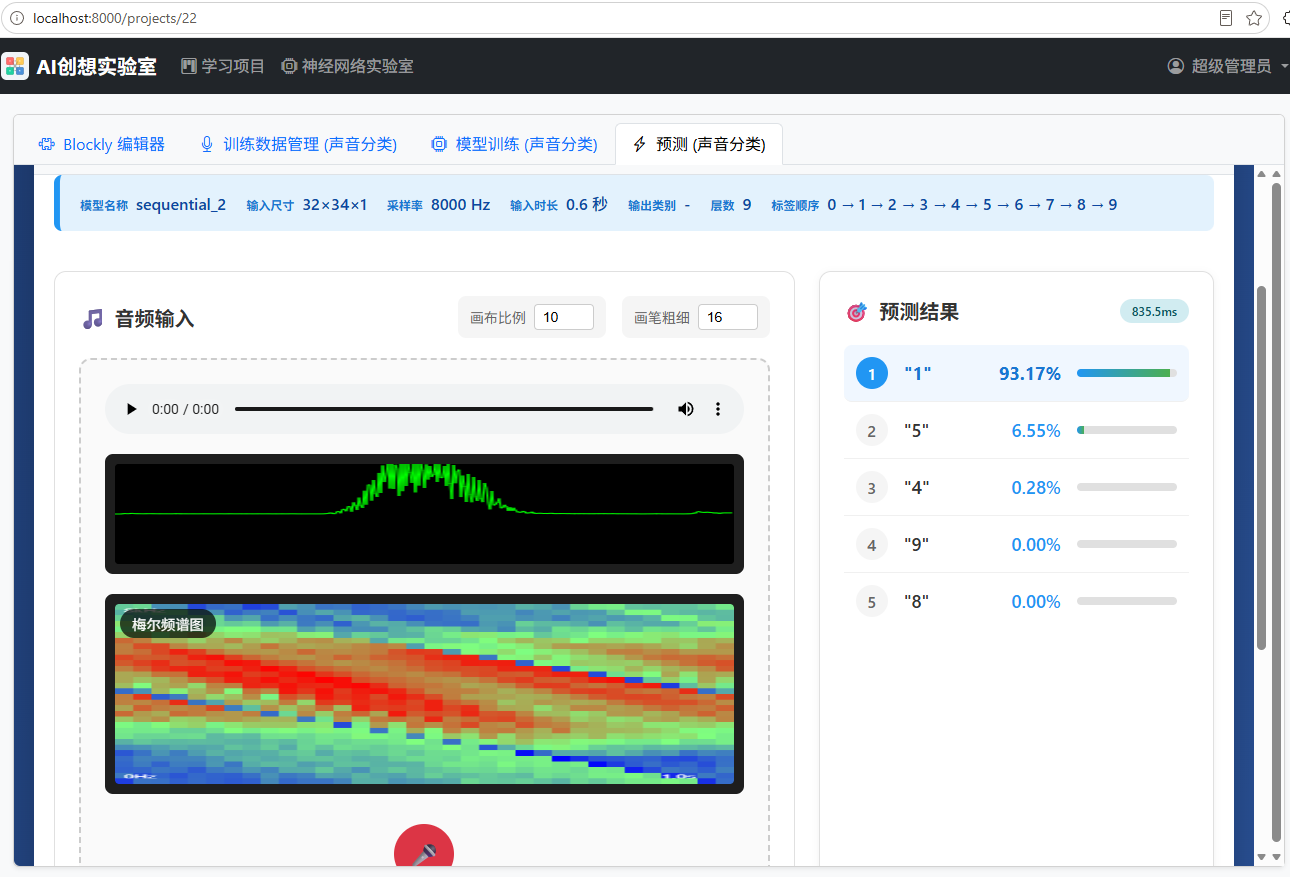
导出训练后的模型也可以用作移动端、嵌入式设备,可以将之前介绍过的手写数字识别的ESP32实验迁移到音频识别中。当然,我们也可以把导出的ONNX模型拿到其他平台进行使用。