一、项目背景
在电商平台运营过程中,企业通常关注以下核心问题:
-
哪些用户贡献了主要收入?
-
哪些商品是平台核心销售商品?
-
用户在哪个环节流失最严重?
-
如何提前识别流失风险用户?
-
如何利用数据驱动运营增长?
为解决上述问题,本项目基于MySQL构建电商业务数据库,利用Python完成数据清洗、特征工程、业务分析以及机器学习建模,并通过Streamlit开发可视化经营分析平台,实现从数据获取到业务决策支持的完整分析闭环。
二、项目架构
技术栈
MySQL
Python
Pandas
NumPy
Matplotlib
Plotly
Scikit-Learn
Mlxtend
Streamlit项目架构
MySQL
↓
DataLoader
↓
数据清洗
↓
特征工程
↓
业务分析
↓
机器学习预测
↓
Streamlit Dashboard三、项目整体流程(项目架构设计)
3.1 项目目标
本项目围绕电商平台经营分析场景展开,主要解决以下业务问题:
-
通过经营指标分析平台整体运营状况;
-
利用RFM模型识别高价值用户;
-
通过ABC分析识别核心商品;
-
利用漏斗分析发现用户转化流失环节;
-
分析用户增长趋势;
-
构建用户流失预测模型;
-
搭建可视化经营分析看板。
最终形成一套完整的数据分析与业务决策支持体系。
3.2 项目分析流程
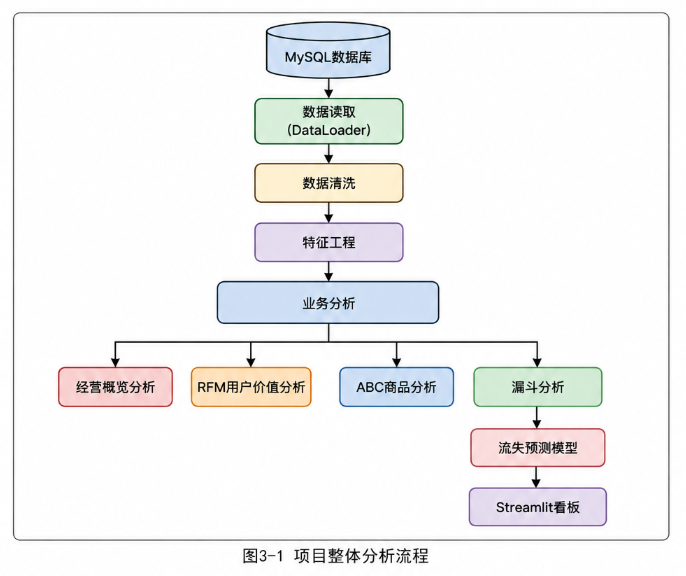
3.3 技术架构
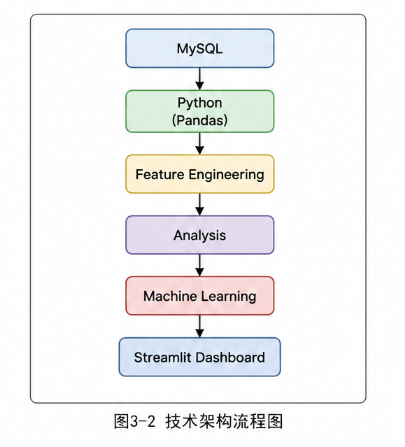
项目采用分层架构设计:
-
数据层:MySQL
-
数据处理层:Pandas、NumPy
-
分析层:RFM、ABC、漏斗分析、增长分析
-
模型层:Logistic Regression
-
展示层:Streamlit + Plotly
整体架构实现了数据存储、分析建模和可视化展示的完整链路。
3.4 项目目录结构
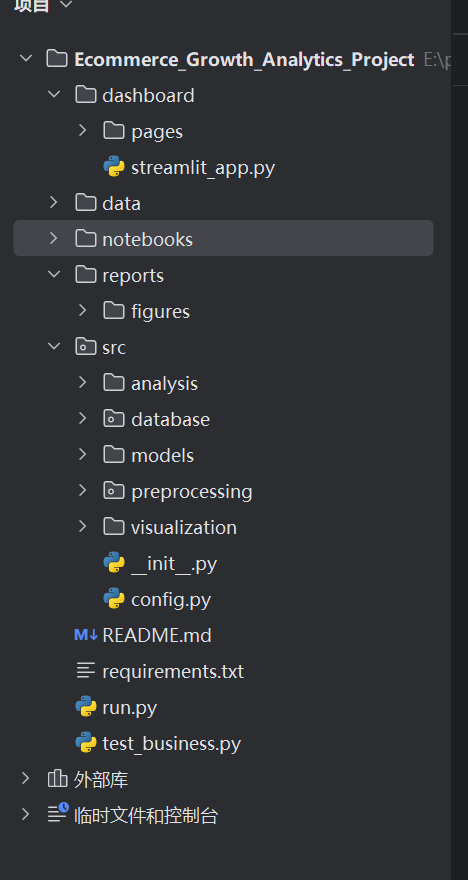
| 模块 | 作用 |
|---|---|
| database | 读取MySQL数据 |
| preprocessing | 数据清洗 |
| analysis | 业务分析 |
| models | 机器学习模型 |
| dashboard | 可视化看板 |
| report | 分析结果 |
3.5 项目分析模块
| 分析模块 | 解决问题 | 输出结果 |
|---|---|---|
| 经营概览 | 平台经营情况如何 | GMV、客单价、支付率 |
| RFM分析 | 哪些用户最有价值 | 949名高价值用户 |
| ABC分析 | 哪些商品最重要 | 728个A类商品 |
| 漏斗分析 | 用户在哪流失 | 收藏→加购转化仅44.19% |
| 用户增长 | 拉新效果如何 | 月均新增80~90人 |
| 流失预测 | 谁可能流失 | Logistic AUC=0.777 |
| Dashboard | 如何实时监控 | Streamlit经营看板 |
3.6 项目亮点
(1)完整业务分析链路
项目覆盖数据读取、数据清洗、特征工程、业务分析、机器学习建模和可视化展示全过程。
(2)真实业务指标分析
围绕GMV、客单价、支付率、转化率等核心经营指标展开分析。
(3)用户价值分层
基于RFM模型识别949名高价值用户,为精准营销提供依据。
(4)商品价值分析
通过ABC分析识别728个核心商品,辅助库存与运营决策。
(5)用户流失预测
利用Logistic Regression构建流失预测模型,ROC-AUC达到0.777。
(6)可视化经营看板
采用Streamlit+Plotly开发交互式分析平台,实现经营指标实时展示。
四、数据清洗与特征工程
4.1 数据读取

python
import pandas as pd
from src.database.mysql_connect import read_sql_data
class DataLoader:
def __init__(self):
pass
def _clean_columns(self, df):
df.columns = [col.replace("\ufeff", "").strip() for col in df.columns]
return df
def _convert_dtypes(self, df):
numeric_cols = [
'quantity', 'unit_price', 'total_amount',
'discount', 'actual_payment', 'review_score',
'price', 'sales_count', 'duration_seconds',
'credit_score', 'account_balance'
]
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
return df
def load_users(self):
sql = "SELECT * FROM users"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_orders(self):
sql = "SELECT * FROM orders"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_products(self):
sql = "SELECT * FROM products"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_user_behaviors(self):
sql = "SELECT * FROM user_behaviors"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_user_features(self):
sql = "SELECT * FROM user_features"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_product_features(self):
sql = "SELECT * FROM product_features"
df = read_sql_data(sql)
df = self._clean_columns(df)
df = self._convert_dtypes(df)
return df
def load_all(self):
return {
"users": self.load_users(),
"orders": self.load_orders(),
"products": self.load_products(),
"user_behaviors": self.load_user_behaviors(),
"user_features": self.load_user_features(),
"product_features": self.load_product_features()
}
def data_summary(self):
data = self.load_all()
summary = {}
for name, df in data.items():
summary[name] = {
"rows": df.shape[0],
"columns": df.shape[1]
}
return summary项目数据存储于MySQL数据库中,通过DataLoader模块统一读取业务数据。
本项目共涉及6张核心业务表,包括用户表、订单表、商品表、用户行为表、用户特征表以及商品特征表。
后续所有分析均基于数据库实时读取的数据进行处理,避免人工导出Excel带来的数据同步问题。
4.2 数据概览(EDA)
python
from src.database.data_loader import DataLoader
loader = DataLoader()
users = loader.load_users()
orders = loader.load_orders()
products = loader.load_products()
behaviors = loader.load_user_behaviors()
print(users.shape)
print(orders.shape)
print(products.shape)
print(behaviors.shape)
print(users.head())
print(orders.head())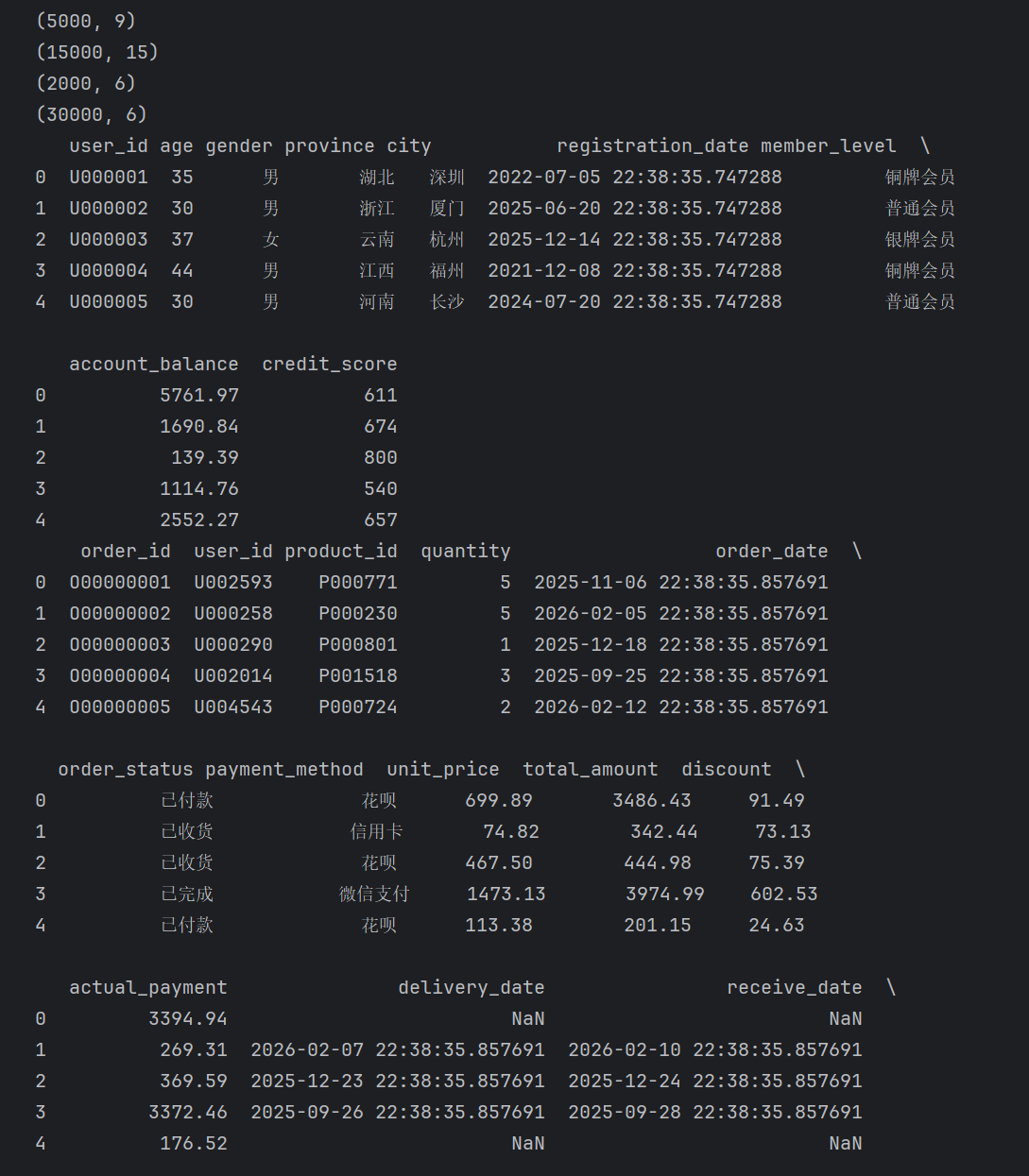
在正式分析之前,需要先了解数据规模以及字段结构。
从数据规模来看:
用户数据共5000条记录;
订单数据共15000条记录;
商品数据共2000条记录;
用户行为数据共30000条记录。
整体数据量满足用户分析、商品分析以及机器学习建模需求。
4.3 缺失值检测
python
users.isnull().sum()
orders.isnull().sum()
products.isnull().sum()
behaviors.isnull().sum()
4.4 重复值检查
通过duplicated()函数检查用户表、订单表和商品表后,未发现重复记录。
说明数据采集过程较为完整,不存在重复订单或重复用户问题。
4.5 日期格式处理
python
orders["order_date"] = pd.to_datetime(
orders["order_date"]
)
orders["delivery_date"] = pd.to_datetime(
orders["delivery_date"]
)
orders["receive_date"] = pd.to_datetime(
orders["receive_date"]
)
users["registration_date"] = pd.to_datetime(
users["registration_date"]
)电商业务分析中大量指标依赖时间维度。
例如
• GMV趋势分析
• 用户增长分析
• RFM模型
• 流失预测
因此需要统一时间字段格式,保证后续计算准确。
4.6 异常值检测
python
Q1 = orders["actual_payment"].quantile(0.25)
Q3 = orders["actual_payment"].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
outliers = orders[
(orders["actual_payment"] < lower)
|
(orders["actual_payment"] > upper)
]
plt.figure(figsize=(8,4))
plt.boxplot(
orders["actual_payment"]
)
plt.title("Order Amount Distribution")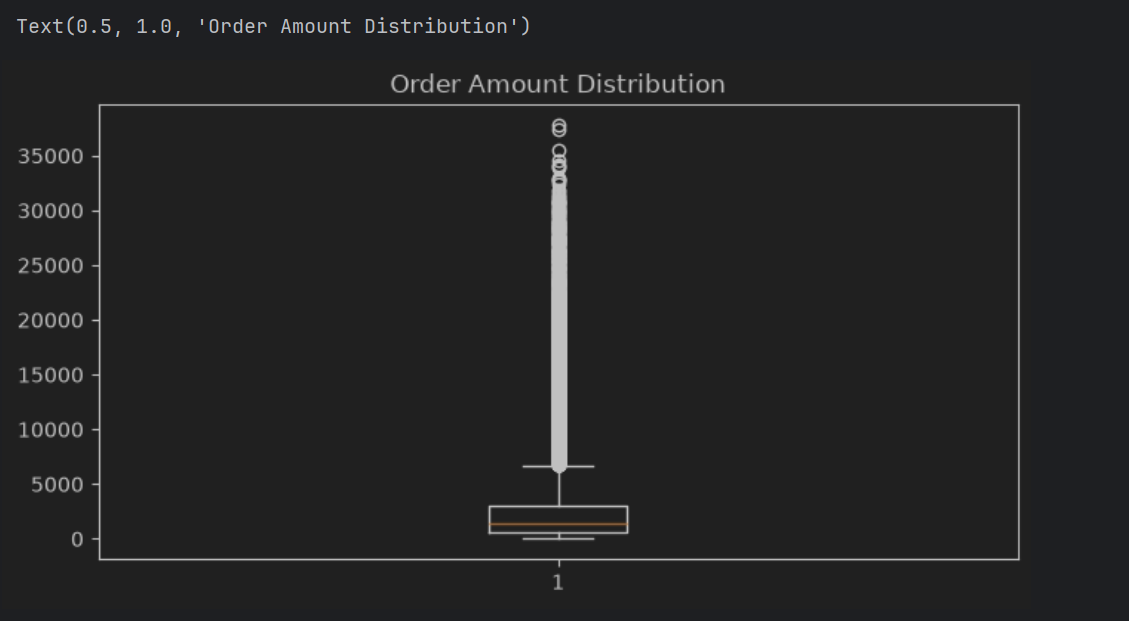
利用IQR方法对订单实付金额进行异常值检测。
结果发现:大部分订单金额集中在500~3000元区间;少量订单金额超过30000元。
结合电商业务场景分析,该部分订单可能来源于高价值用户的大额消费行为。
因此保留异常值参与分析。
4.7 用户行为分布分析
python
behavior_count = (
behaviors["behavior_type"]
.value_counts()
)
print(behavior_count)
behavior_count.plot(
kind="bar"
)
plt.title(
"User Behavior Distribution"
)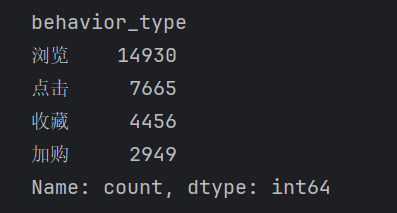
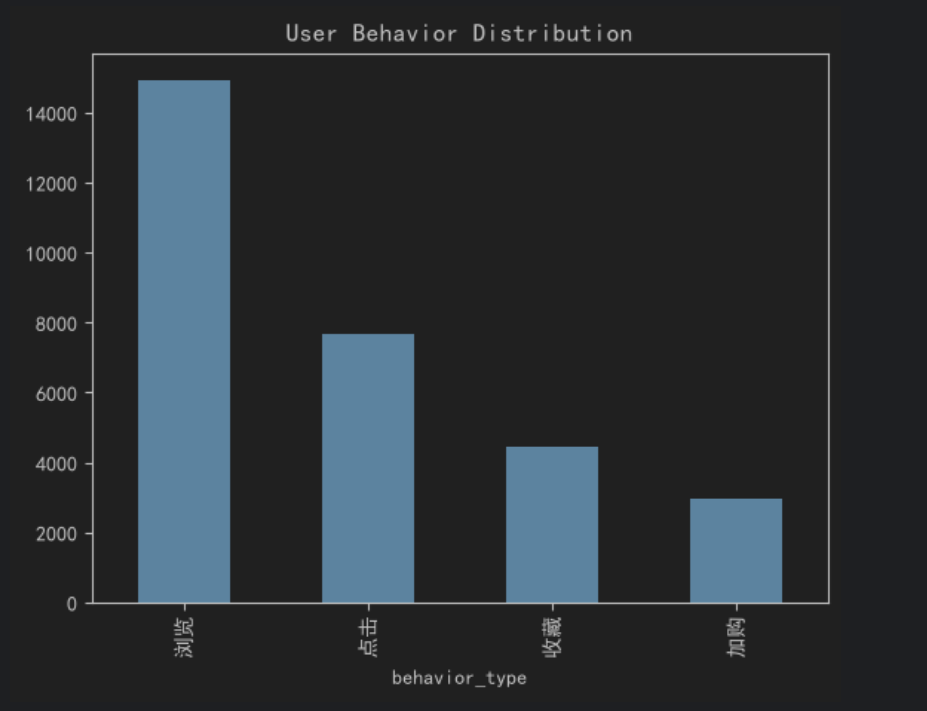
用户行为统计结果如下:
浏览:14930次
点击:7665次
收藏:4456次
加购:2949次
可以发现:
浏览→点击阶段下降明显;
点击→收藏阶段再次出现较大流失;
符合典型电商漏斗特征。
4.8 构建用户特征
python
user_feature = (
orders
.groupby("user_id")
.agg(
{
"actual_payment":"sum",
"order_id":"count"
}
)
)为了支持RFM分析与流失预测模型,
基于订单数据构建用户维度特征:
累计消费金额(total_spent)
订单数量(order_count)
平均客单价(avg_order_amount)
最近消费间隔(days_since_last_order)
复购标识(repurchase_indicator)
消费等级(consumption_level)
会员等级评分(member_level_score)
4.9 构建商品特征
python
product_feature = (
orders
.groupby("product_id")
.agg(
{
"actual_payment":"sum",
"quantity":"sum"
}
)
)为了支持ABC商品价值分析,
构建商品维度经营指标:
总销售额(total_revenue)
总销量(total_sales)
完成订单数(completed_count)
取消订单数(cancel_count)
浏览量
点击量
收藏量
加购量
转化率(conversion_rate)
商品热度评分(popularity_score)
4.10 数据清洗总结
经过数据清洗与特征构建后:
用户表:5000条记录
订单表:15000条记录
商品表:2000条记录
行为表:30000条记录
未发现重复数据;
缺失值主要来源于未完成订单及未评价订单;
高金额订单经业务验证后保留;
最终形成用户特征表与商品特征表,为后续RFM分析、ABC分析、漏斗分析以及用户流失预测模型提供数据基础。
五、经营概览分析
5.1 分析目标
经营概览分析旨在从整体业务层面评估平台经营情况。
通过分析GMV、订单量、客单价、支付率、退款率以及核心商品贡献情况,全面了解平台当前经营状态,并为后续用户价值分析和商品分析提供业务背景支撑。
5.2 核心指标体系
| 指标 | 含义 |
|---|---|
| GMV | 成交总金额 |
| 订单量 | 订单总数 |
| 客单价 | GMV / 支付用户数 |
| 支付率 | 付款订单占比 |
| 退款率 | 退款订单占比 |
| Top商品 | 销售额最高商品 |
| GMV趋势 | 月度经营趋势 |
5.3 GMV分析
python
# src/analysis/business_overview.py
import pandas as pd
import os
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from src.database.data_loader import DataLoader
class BusinessOverview:
def __init__(self):
loader = DataLoader()
# 加载原始数据
orders_raw = loader.load_orders()
products_raw = loader.load_products()
# 强制清洗列名(去除 BOM 头和空格)
self.orders = self._clean_columns(orders_raw)
self.products = self._clean_columns(products_raw)
# 关键:转换数据类型(将字符串转为数值)
self.orders = self._convert_dtypes(self.orders)
self.products = self._convert_dtypes(self.products)
print("实际 orders 列名:", list(self.orders.columns))
print("列名数量:", len(self.orders.columns))
def _clean_columns(self, df):
"""去除列名中的 BOM 头(\ufeff)和前后空格"""
df.columns = [col.replace("\ufeff", "").strip() for col in df.columns]
return df
def _convert_dtypes(self, df):
"""将数值列转为 pandas 数值类型(float/int),非数值保持原样"""
# 针对 orders 表中的数值列
numeric_cols = [
'quantity', 'unit_price', 'total_amount',
'discount', 'actual_payment', 'review_score'
]
# 针对 products 表中的数值列
if 'price' in df.columns:
numeric_cols.append('price')
if 'sales_count' in df.columns:
numeric_cols.append('sales_count')
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
return df
def calculate_kpi(self):
paid_status = [
"已付款",
"已发货",
"已收货",
"已完成"
]
paid_orders = self.orders[
self.orders["order_status"].isin(paid_status)
]
gmv = paid_orders["actual_payment"].sum()
order_cnt = self.orders["order_id"].nunique()
user_cnt = self.orders["user_id"].nunique()
payment_rate = round(
len(paid_orders) / len(self.orders) * 100,
2
)
refund_rate = round(
(self.orders["order_status"] == "已退款").mean() * 100,
2
)
cancel_rate = round(
(self.orders["order_status"] == "已取消").mean() * 100,
2
)
aov = round(gmv / len(paid_orders), 2)
print("GMV:", gmv)
print("订单数:", order_cnt)
print("用户数:", user_cnt)
print("支付率:", payment_rate)
print("退款率:", refund_rate)
print("取消率:", cancel_rate)
print("客单价:", aov)
def monthly_gmv(self):
self.orders["order_date"] = pd.to_datetime(
self.orders["order_date"]
)
df = self.orders.copy()
df["month"] = (
df["order_date"]
.dt.to_period("M")
.astype(str)
)
result = (
df.groupby("month")
["actual_payment"]
.sum()
.reset_index()
)
return result
def top_products(self):
merged = pd.merge(
self.orders,
self.products,
on="product_id"
)
top10 = (
merged
.groupby("product_name")
["actual_payment"]
.sum()
.sort_values(ascending=False)
.head(10)
)
return top10
def plot_gmv(self):
trend = self.monthly_gmv()
if trend.empty:
print("没有月度数据可绘图")
return
latest_month = trend["month"].max()
trend_filtered = trend[trend["month"] != latest_month]
if trend_filtered.empty:
print("过滤后没有完整月份数据可绘图")
return
plt.figure(figsize=(12, 5))
plt.plot(trend_filtered["month"], trend_filtered["actual_payment"],
marker='o', linestyle='-', color='b', linewidth=2)
plt.xticks(rotation=45)
plt.title("Monthly GMV Trend (完整月份)", fontsize=14)
plt.xlabel("月份", fontsize=12)
plt.ylabel("GMV", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
os.makedirs("reports/figures", exist_ok=True)
save_path = "reports/figures/gmv_monthly_trend.png"
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
def run(self):
self.calculate_kpi()
print("\nTop商品")
print(self.top_products())
self.plot_gmv()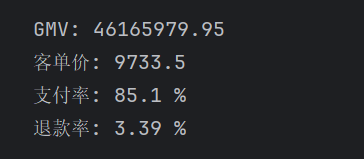
GMV(Gross Merchandise Volume)是衡量电商平台经营规模的重要指标。
统计期间内平台累计实现GMV约4616.6万元。
说明平台具备一定交易规模和用户消费能力。
但仅从GMV无法判断收入来源结构,
因此需要进一步结合RFM用户价值分析以及ABC商品分析,识别核心贡献用户与核心商品。
后续需要结合用户价值分析进一步判断GMV是否主要依赖少数高价值用户贡献。
5.4 月度GMV趋势分析
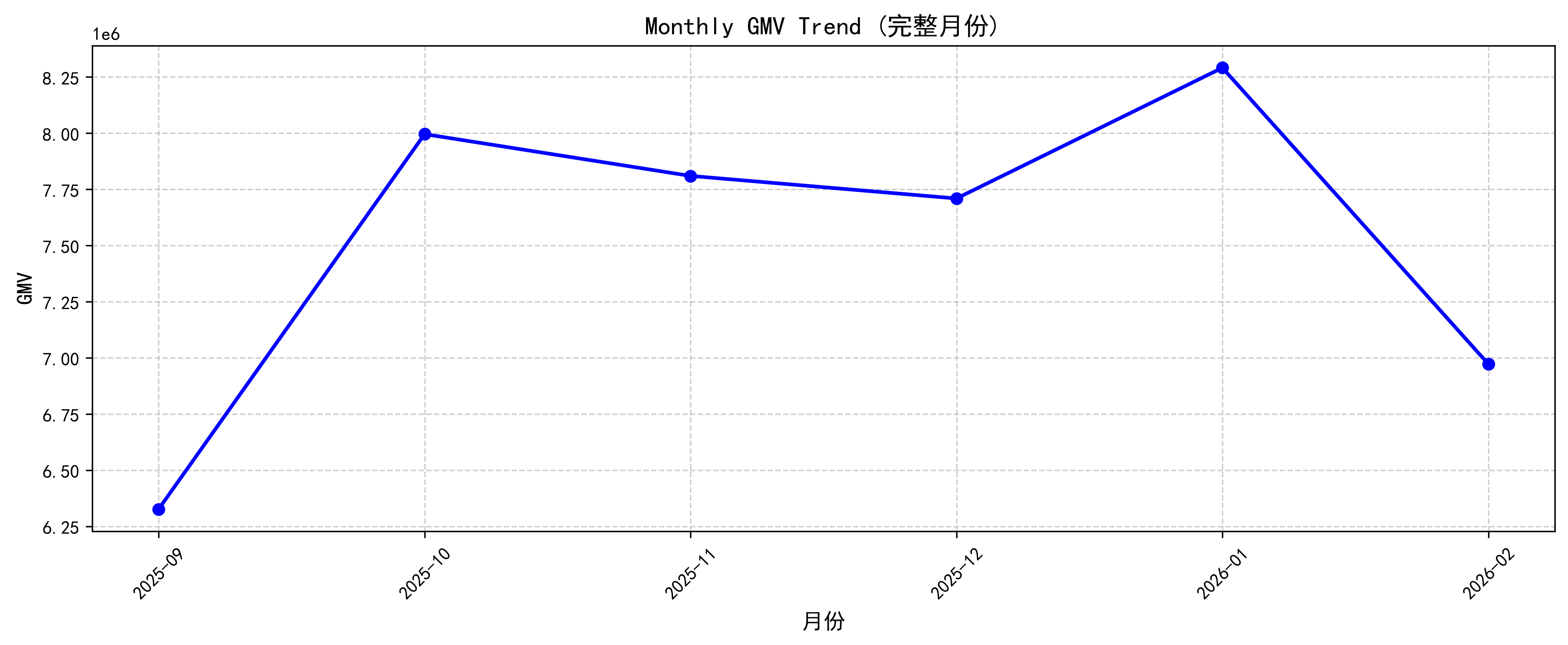
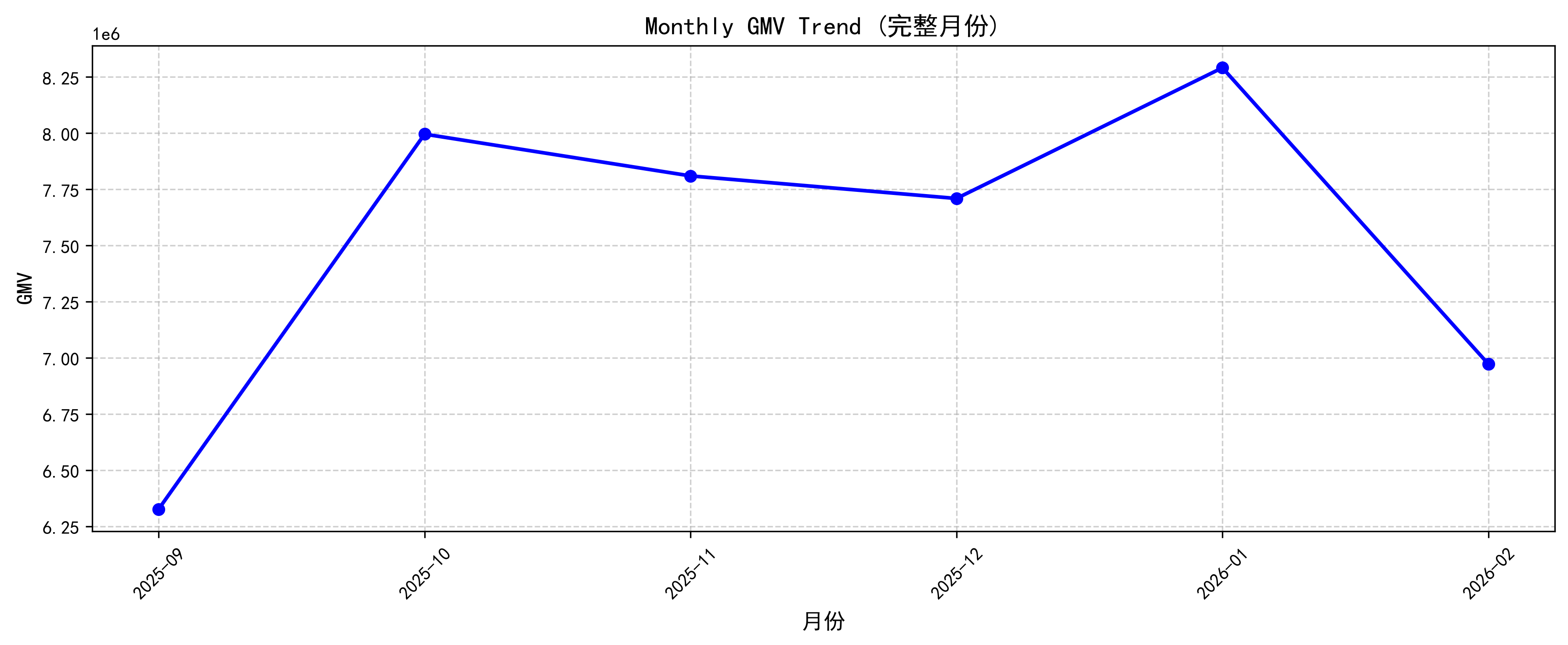
从月度GMV趋势来看,平台GMV整体维持在700万~830万元区间。2025年10月GMV快速增长至800万元;随后保持相对稳定;2026年1月达到峰值829万元;2026年2月出现明显回落。
结合业务场景推测:可能受到春节后消费需求下降或促销活动结束影响。
5.5 客单价分析
python
avg_order_value = (
orders["actual_payment"].sum()
/
orders["user_id"].nunique()
)
print("客单价:", round(avg_order_value, 2))
本项目客单价约9733元。
说明平台商品以中高客单价商品为主。
结合后续ABC分析结果发现,
销售额排名靠前商品主要集中于:
家用电器
手机数码
汽车用品
等高价值品类。
5.6 支付率分析
python
paid_orders = orders[
orders["order_status"].isin(
[
"已付款",
"已发货",
"已收货",
"已完成"
]
)
]
payment_rate = (
len(paid_orders)/len(orders)
)
支付率达到85.1%。
说明大部分下单用户最终完成支付。
平台整体交易转化情况较好。
5.7 退款率分析
python
refund_orders = orders[
orders["order_status"]=="已退款"
]
refund_rate = (
len(refund_orders)/len(orders)
)
退款率仅为3.39%。
说明平台商品质量及履约服务整体较稳定。
暂未发现大规模售后风险。
5.8 Top商品分析
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
abc = pd.read_csv(
"data/processed/abc_result.csv"
)
top10 = abc.head(10)
plt.figure(figsize=(12,6))
plt.barh(
top10["product_name"],
top10["actual_payment"]
)
plt.title("Top10商品销售额排行")
plt.xlabel("销售额")
plt.ylabel("商品")
plt.tight_layout()
plt.savefig(
"report/figures/top10_product.png",
dpi=300
)
plt.show()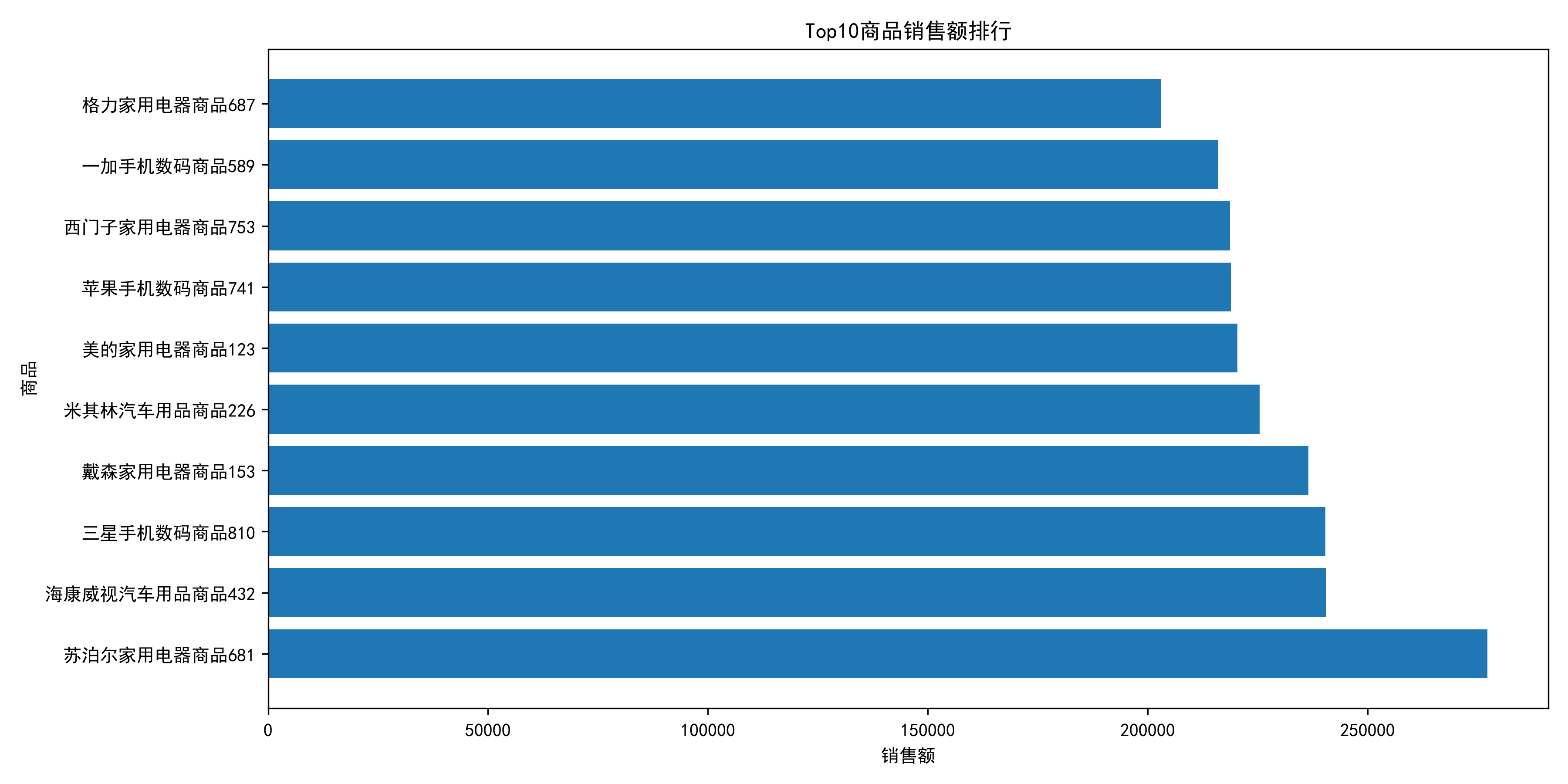
销售额贡献最高的商品主要集中在家用电器和手机数码品类。
其中苏泊尔家电商品销售额超过27万元,排名第一。
说明高单价耐用品仍然是平台GMV的重要来源。
5.9 经营分析总结
(1)平台整体经营规模较大
统计周期内累计GMV达到:4616.6万元 具备较强交易规模。
(2)经营波动较小
月度GMV主要集中在:700万~830万元区间。整体经营较稳定。
(3)支付转化表现较好
支付率:85.1% 说明用户购买意愿较强。
(4)售后风险较低
退款率:3.39% 处于较低水平。
(5)销售额高度集中
Top10商品销售额明显高于其他商品。
其中:苏泊尔家用电器商品681 277250元排名第一。
说明平台GMV主要由少数核心商品驱动。
运营建议
基于以上发现:
① 加大核心商品曝光资源;
② 对高价值商品建立重点运营机制;
③ 针对支付环节继续优化促销策略;
④ 利用ABC分析进一步识别长尾商品优化空间。
经营概览分析解决了"平台整体经营情况如何"的问题。
接下来将进一步通过RFM模型识别高价值用户群体,
分析不同用户层级对平台GMV的贡献情况。
六、RFM用户价值分析
6.1 分析背景
在电商业务中,不同用户创造的价值存在显著差异。
部分用户消费金额高、购买频率高,是平台的重要收入来源;而部分用户消费频率较低,对平台贡献有限。
因此需要通过RFM模型识别高价值用户和普通用户,为会员运营、精准营销和用户维护提供数据支持。
6.2 RFM模型介绍
| 指标 | 含义 |
|---|---|
| R(Recency) | 最近一次消费距今天数 |
| F(Frequency) | 消费频次 |
| M(Monetary) | 累计消费金额 |
RFM模型是用户价值分析中最经典的方法之一。
Recency反映用户活跃程度;
Frequency反映用户购买频率;
Monetary反映用户消费能力。
通过综合评估R、F、M三个维度,可以实现用户价值分层。
6.3 构建RFM指标
RFM值
python
snapshot_date = orders["order_date"].max()
rfm = orders.groupby("user_id").agg({
"order_date": lambda x:
(snapshot_date - x.max()).days,
"order_id": "count",
"actual_payment": "sum"
})
rfm.columns = [
"Recency",
"Frequency",
"Monetary"
]Recency越小代表最近消费时间越近;
Frequency越大代表购买越频繁;
Monetary越大代表消费金额越高。
6.4 RFM评分
python
rfm["R_score"] = pd.qcut(
rfm["Recency"],
5,
labels=[5,4,3,2,1]
)
rfm["F_score"] = pd.qcut(
rfm["Frequency"].rank(method="first"),
5,
labels=[1,2,3,4,5]
)
rfm["M_score"] = pd.qcut(
rfm["Monetary"],
5,
labels=[1,2,3,4,5]
)
rfm["RFM_SCORE"] = (
rfm["R_score"].astype(str)+rfm["F_score"].astype(str)+rfm["M_score"].astype(str)
)为了便于用户分层,采用五分位法对R、F、M进行评分。
每个维度评分范围为1~5分。
最终组合形成三位RFM评分,例如:
555代表最优用户;
111代表价值最低用户。
6.5 用户分层规则
python
def segment_user(row):
if row["R_score"] >= 4 and row["F_score"] >= 4:
return "高价值用户"
else:
return "普通用户"| 用户类型 | 特征 |
|---|---|
| 高价值用户 | 近期活跃且购买频率较高 |
| 普通用户 | 消费频率较低或近期活跃度不足 |
6.6 用户分层结果
python
segment_count = (
rfm["segment"].value_counts()
)
print(segment_count)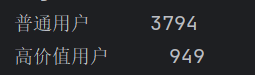
根据RFM模型划分结果:
| 用户类型 | 人数 | 占比 |
|---|---|---|
| 普通用户 | 3794 | 75.88% |
| 高价值用户 | 949 | 18.98% |
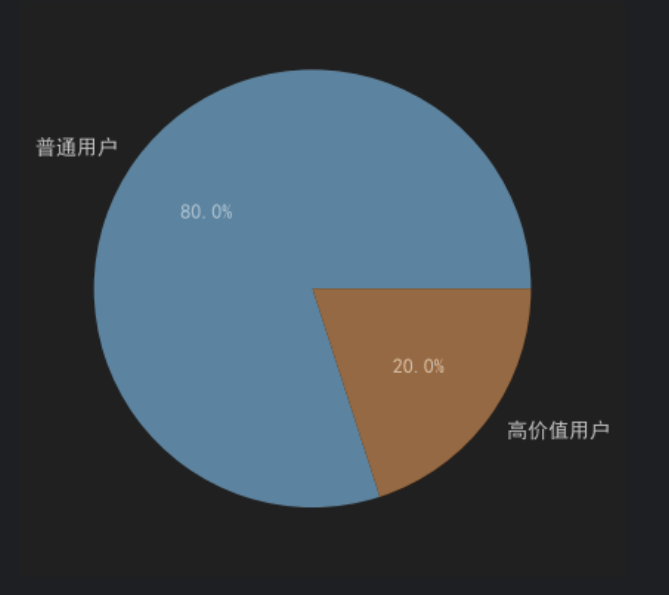
根据RFM分析结果,平台共有高价值用户949人,占全部用户的18.98%;普通用户3794人,占比75.88%。
说明平台用户结构呈现明显的长尾特征,少量核心用户贡献了较高价值,符合电商行业常见的"二八法则"现象。
6.7 高价值用户画像
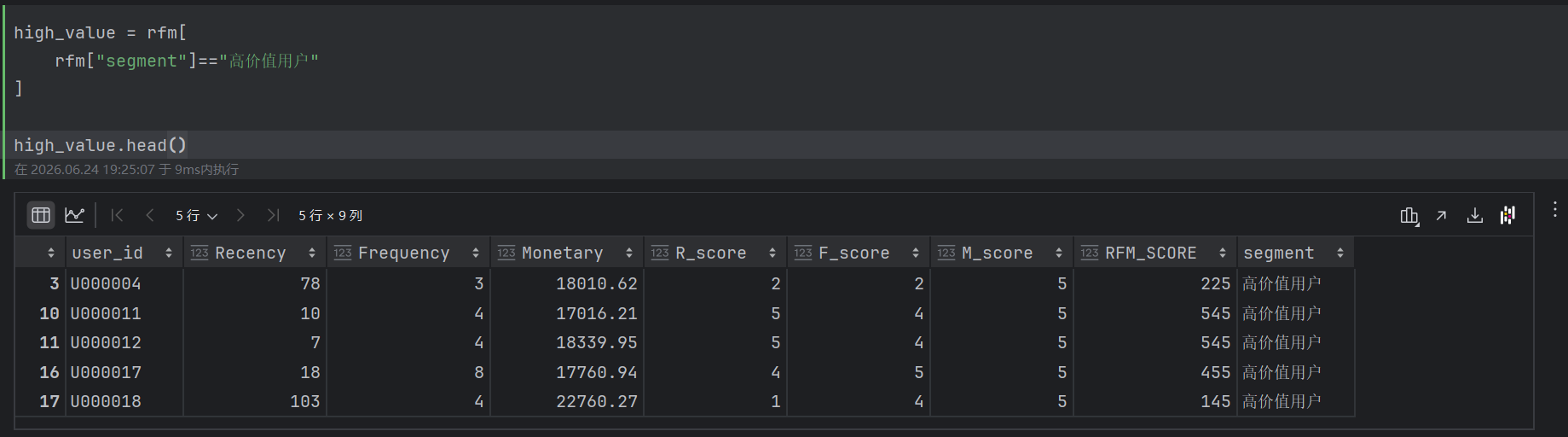
从RFM分析结果来看,高价值用户具有以下特征:
- 最近消费时间较近
- 购买频率较高
- 累计消费金额较高
例如部分高价值用户累计消费金额超过18000元,购买频次达到4~8次以上。
这类用户虽然仅占全部用户的20%左右,但对平台销售额贡献显著,是平台重点维护对象。
6.8 用户运营策略
根据RFM用户价值分析结果,平台用户主要分为高价值用户和普通用户两类,因此应采取差异化运营策略。
(1)高价值用户运营策略
高价值用户是平台核心收入来源,应重点提升用户忠诚度和复购率。
运营措施包括:
- VIP会员专属权益
- 专属优惠券发放
- 会员积分兑换活动
- 生日礼包与节日关怀
- 新品优先体验资格
(2)普通用户运营策略
普通用户数量占比较高,具有较大的转化潜力。
运营措施包括:
- 满减促销活动
- 限时折扣活动
- 商品推荐与精准营销
- 新用户成长任务
- 会员等级升级激励
(3)运营目标
通过差异化运营策略:
- 提升高价值用户留存率
- 提高普通用户活跃度
- 促进普通用户向高价值用户转化
- 提升用户生命周期价值(LTV)
6.9 RFM分析总结
通过RFM模型分析发现:
① 平台共有高价值用户949人,占比约19%。
② 普通用户数量最多,占比超过75%。
③ 高价值用户具有较高消费能力和购买频率,是平台核心收入来源。
④ 平台应重点提升高价值用户留存率,同时通过会员权益和营销活动促进普通用户向高价值用户转化。
因此,企业应建立基于用户价值分层的精细化运营体系,提高用户生命周期价值(LTV)。
七、ABC商品分析
7.1 分析背景
电商平台通常存在明显的"二八法则"现象,即少量核心商品贡献大部分销售额。
为了识别平台核心商品,本项目采用ABC分析法对商品进行分层管理。
通过识别A类、B类和C类商品,为商品运营、库存管理以及营销资源配置提供数据支持。
7.2 什么是ABC分析
| 类别 | 累计销售额占比 | 特点 |
|---|---|---|
| A类商品 | 前80%销售额 | 核心商品 |
| B类商品 | 80%-95%销售额 | 重要商品 |
| C类商品 | 95%-100%销售额 | 长尾商品 |
ABC分析基于帕累托法则(Pareto Principle)。
通过计算商品销售额累计贡献占比,将商品划分为A、B、C三类。
其中:
A类商品虽然数量较少,但贡献了绝大部分销售额;
C类商品数量较多,但销售贡献有限。
7.3 商品销售额统计
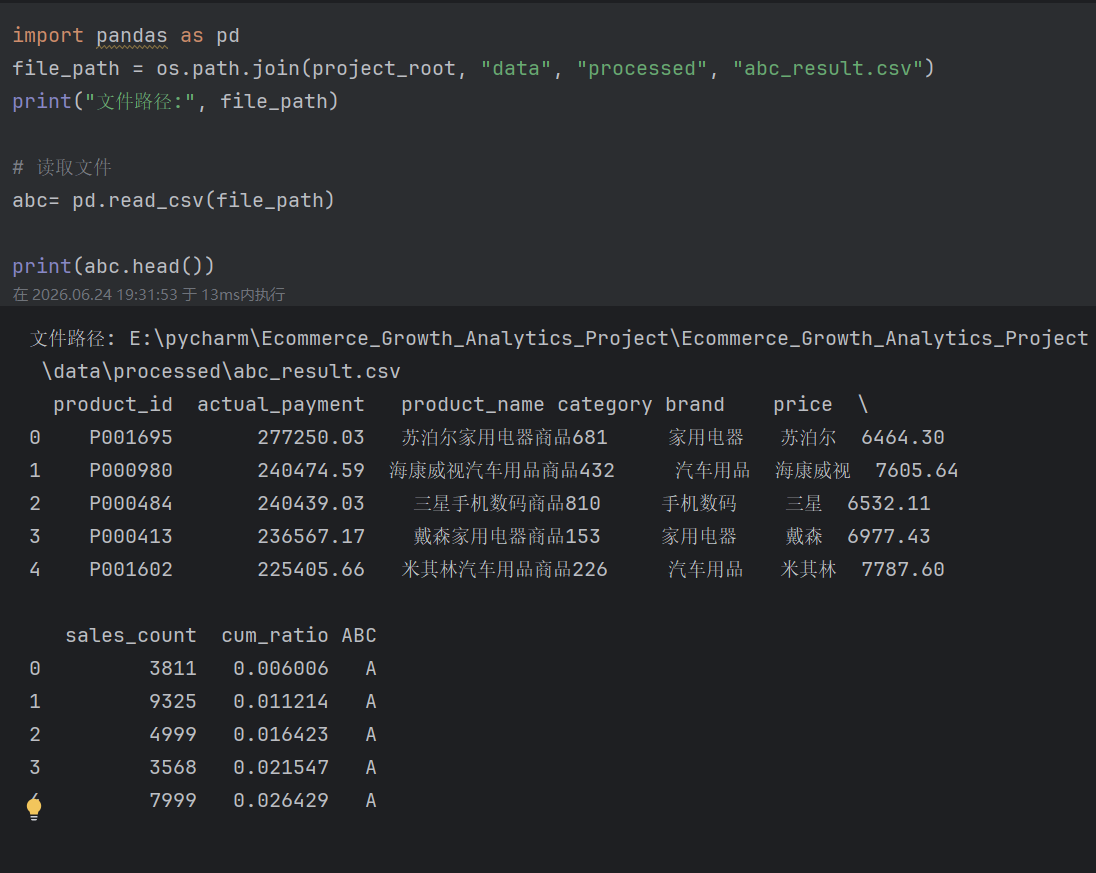
7.4 计算累计贡献率
python
abc = abc.sort_values(
"actual_payment",
ascending=False
)
abc["cum_ratio"] = (
abc["actual_payment"].cumsum()/abc["actual_payment"].sum()
)累计贡献率用于衡量商品销售额贡献情况。
贡献率越高,
说明该商品对平台GMV贡献越大。
7.5 ABC分类规则
python
def classify_abc(x):
if x <= 0.8:
return "A"
elif x <= 0.95:
return "B"
else:
return "C"
abc["ABC"] = abc["cum_ratio"].apply(
classify_abc
)累计销售额贡献前80%的商品定义为A类商品;
80%-95%定义为B类商品;
其余定义为C类商品。
7.6 TOP商品分析
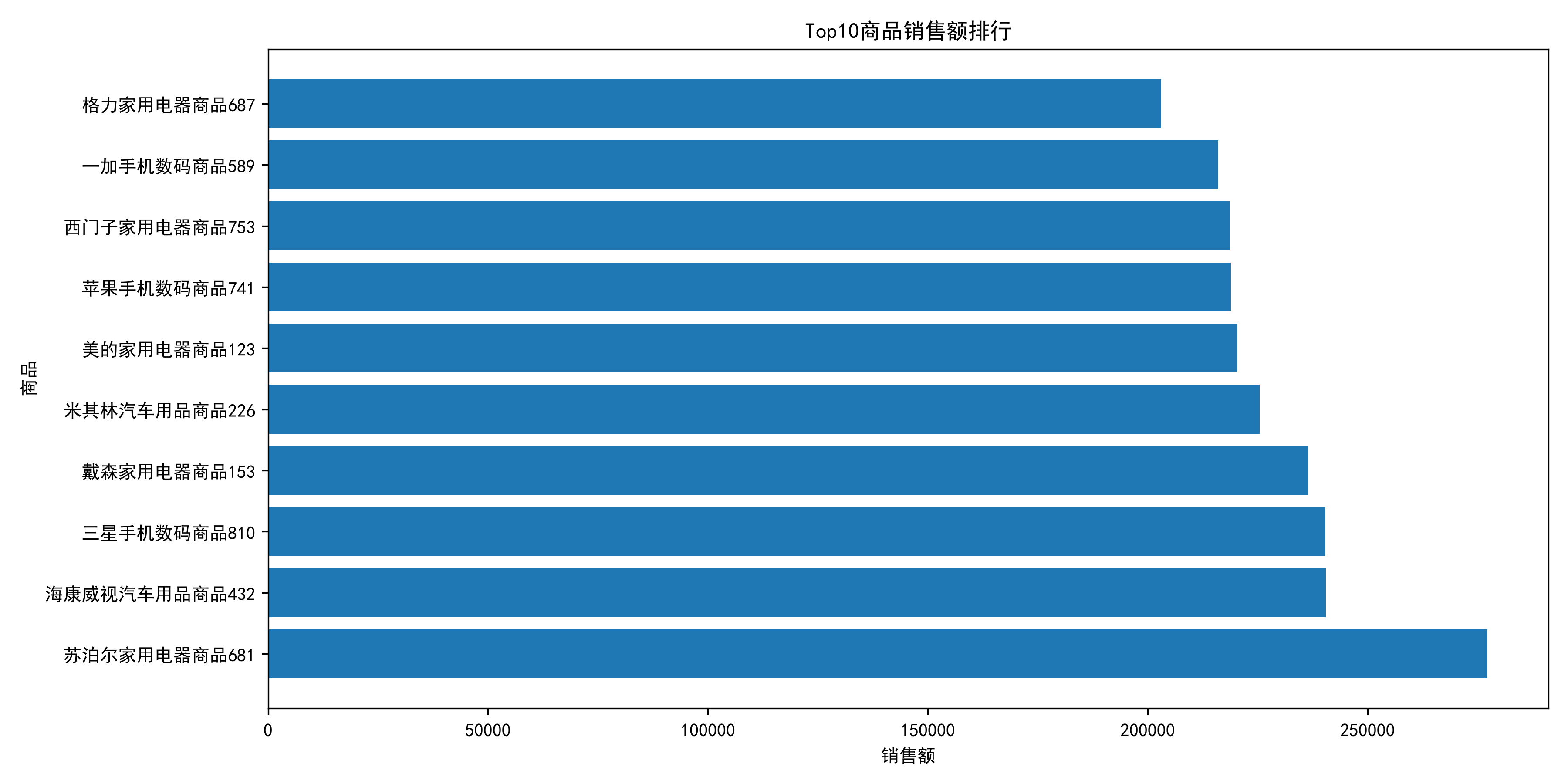
从商品销售额排行来看,平台销售额呈现明显的头部集中现象。
排名前列的商品主要集中在:
• 家用电器
• 手机数码
• 汽车用品
其中苏泊尔家用电器商品681销售额达到27.73万元,位居第一。
说明平台销售额高度依赖核心爆款商品。
7.7 ABC分布分析
python
import pandas as pd
abc = pd.read_csv(
"outputs/processed/abc_result.csv"
)
abc_count = (
abc["ABC"].value_counts()
)
print(abc_count)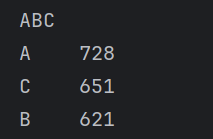
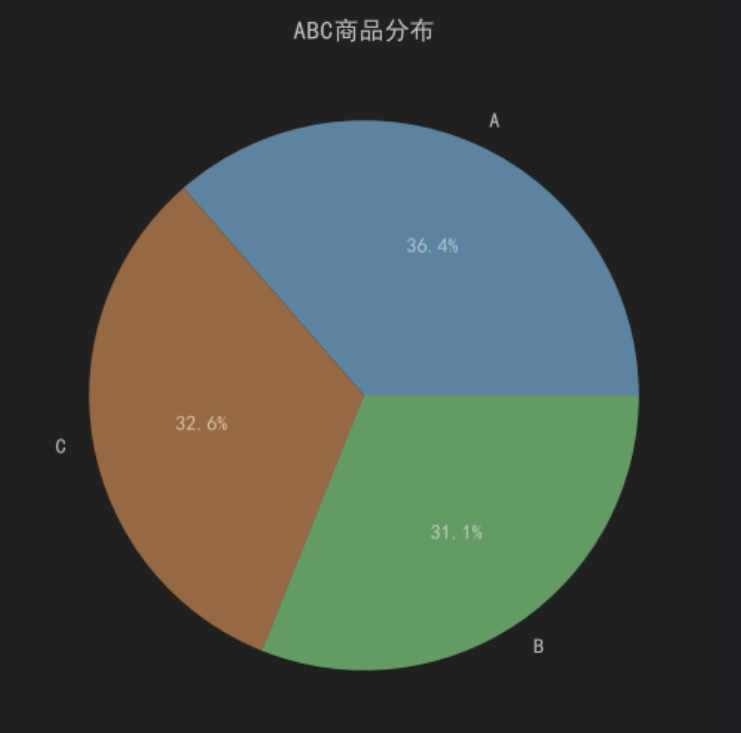
根据ABC分类结果:
| 类别 | 数量 | 占比 |
|---|---|---|
| A类商品 | 728 | 36.4% |
| B类商品 | 621 | 31.1% |
| C类商品 | 651 | 32.6% |
可以发现:
- A类商品数量占比最高;
- 三类商品数量分布较为均衡;
- 平台销售额虽然存在头部商品贡献现象,但商品结构整体较为分散。
说明平台并未严重依赖少数商品,而是形成了较为稳定的商品销售结构。
7.8 商品运营策略
A类商品(核心贡献商品)
- 优先保障库存供应
- 提升搜索推荐权重
- 重点参与平台大促活动
- 建立价格监控机制
B类商品(成长型商品)
- 与A类商品进行关联推荐
- 提高活动曝光资源
- 测试不同促销策略
C类商品(长尾商品)
- 定期评估销售表现
- 优化SKU结构
- 对长期低销量商品进行清仓处理
- 减少库存占用
7.9 ABC分析总结
通过ABC分析发现:
- 平台共有2000个商品,其中A类商品728个,占36.4%,贡献累计80%的销售额;
- 商品销售额存在一定头部集中现象,但未呈现典型二八分布;
- TOP商品主要集中在家用电器、手机数码和汽车用品品类;
- TOP10商品销售额差距较小,未形成绝对领先的超级爆款;
- 平台商品结构整体较为均衡,销售收入来源相对分散。
因此建议:
- 优先维护A类商品库存和曝光资源;
- 加强B类商品培育;
- 优化低效C类商品SKU结构;
- 提升商品组合销售能力。
八、用户转化漏斗分析
8.1 分析背景
在电商业务中,用户从浏览商品到最终完成购买需要经过多个环节。
每一个环节都可能产生用户流失。
因此需要通过漏斗分析识别转化过程中的关键流失节点,为产品优化和运营策略提供依据。
本项目基于用户行为数据与订单数据构建完整购买漏斗:
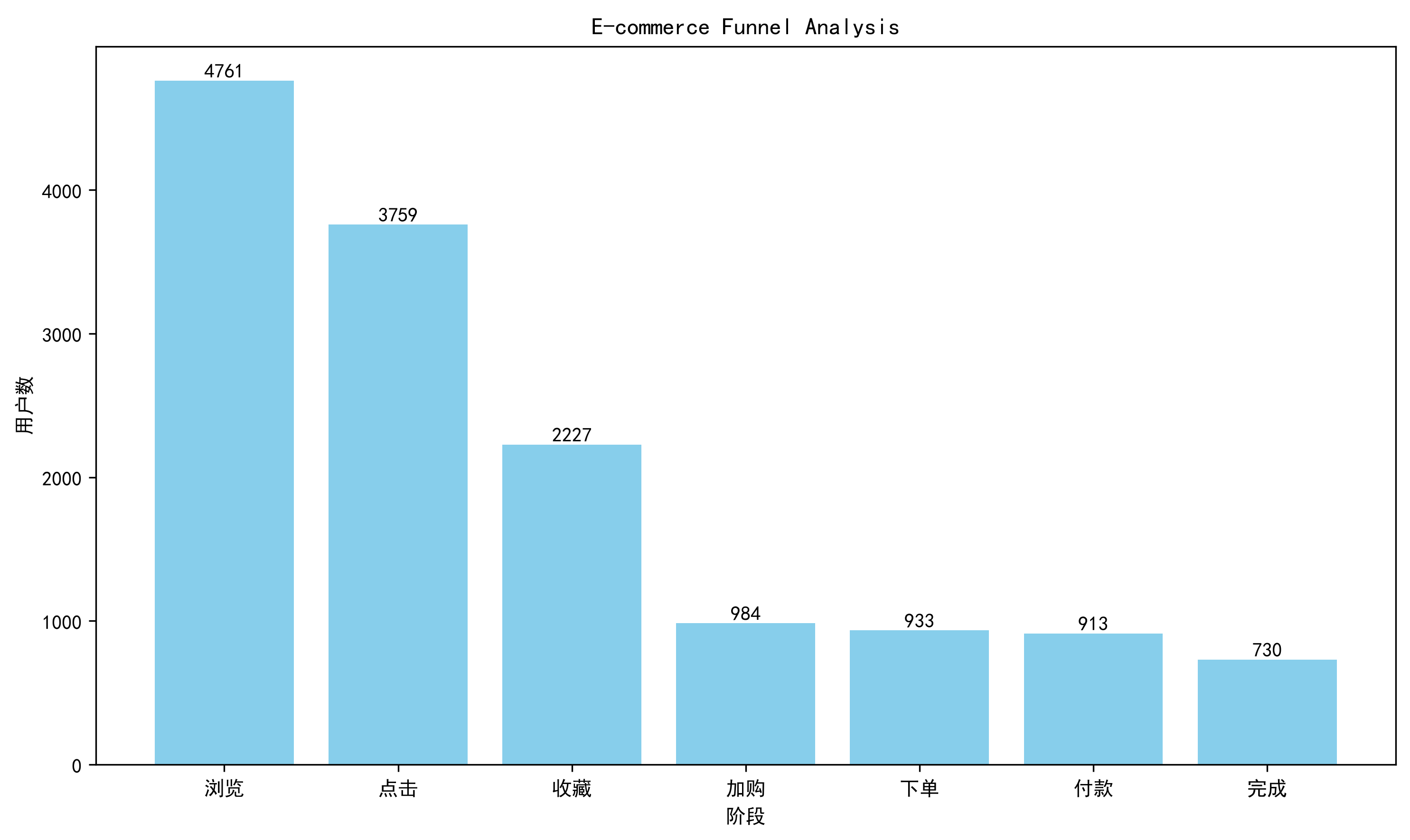
浏览 → 点击 → 收藏 → 加购 → 下单 → 付款 → 完成
8.2 漏斗模型设计

8.3 漏斗数据统计
python
# src/analysis/funnel_analysis.py
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import os
from src.database.data_loader import DataLoader
class FunnelAnalysis:
def __init__(self):
loader = DataLoader()
# 加载原始数据
behaviors_raw = loader.load_user_behaviors()
orders_raw = loader.load_orders()
# 清洗列名和转换类型
self.behaviors = self._clean_columns(behaviors_raw)
self.orders = self._clean_columns(orders_raw)
self.behaviors = self._convert_dtypes(self.behaviors)
self.orders = self._convert_dtypes(self.orders)
def _clean_columns(self, df):
"""去除列名中的 BOM 头(\ufeff)和前后空格"""
df.columns = [col.replace("\ufeff", "").strip() for col in df.columns]
return df
def _convert_dtypes(self, df):
"""将数值列转为 pandas 数值类型"""
numeric_cols = [
'quantity', 'unit_price', 'total_amount',
'discount', 'actual_payment', 'review_score',
'price', 'sales_count', 'duration_seconds'
]
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
return df
# =====================
# 漏斗统计
# =====================
def build_funnel(self):
# 各阶段独立用户集合
view = set(self.behaviors[self.behaviors["behavior_type"] == "浏览"]["user_id"])
click = set(self.behaviors[self.behaviors["behavior_type"] == "点击"]["user_id"])
favorite = set(self.behaviors[self.behaviors["behavior_type"] == "收藏"]["user_id"])
cart = set(self.behaviors[self.behaviors["behavior_type"] == "加购"]["user_id"])
order = set(self.orders["user_id"])
paid = set(self.orders[self.orders["order_status"].isin(["已付款", "已发货", "已收货", "已完成"])]["user_id"])
complete = set(self.orders[self.orders["order_status"] == "已完成"]["user_id"])
# 路径漏斗:逐步取交集
stage1_view = view # 浏览
stage2_click = view & click # 浏览 → 点击
stage3_favorite = view & click & favorite # 浏览 → 点击 → 收藏
stage4_cart = view & click & favorite & cart # 浏览 → 点击 → 收藏 → 加购
stage5_order = view & click & favorite & cart & order # 浏览 → ... → 加购 → 下单
stage6_paid = view & click & favorite & cart & order & paid # +付款
stage7_complete = view & click & favorite & cart & order & paid & complete # +完成
funnel = pd.DataFrame({
"stage": ["浏览", "点击", "收藏", "加购", "下单", "付款", "完成"],
"count": [
len(stage1_view),
len(stage2_click),
len(stage3_favorite),
len(stage4_cart),
len(stage5_order),
len(stage6_paid),
len(stage7_complete)
]
})
return funnel
# =====================
# 转化率
# =====================
def calculate_conversion(self):
funnel = self.build_funnel()
funnel["conversion_rate"] = (
funnel["count"]
/
funnel["count"].shift(1)
)
funnel.loc[0, "conversion_rate"] = 1
funnel["conversion_rate"] = (
funnel["conversion_rate"]
* 100
).round(2)
return funnel
# =====================
# 漏斗图
# =====================
def plot_funnel(self):
funnel = self.calculate_conversion()
plt.figure(figsize=(10, 6))
plt.bar(funnel["stage"], funnel["count"], color='skyblue')
plt.title("E-commerce Funnel Analysis")
plt.xlabel("阶段")
plt.ylabel("用户数")
for i, v in enumerate(funnel["count"]):
plt.text(i, v + 0.5, str(v), ha='center', va='bottom')
plt.tight_layout()
# 确保目录存在
os.makedirs("reports/figures", exist_ok=True)
save_path = "reports/figures/funnel_conversion.png"
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
# =====================
# 保存
# =====================
def save_result(self):
funnel = self.calculate_conversion()
os.makedirs("data/processed", exist_ok=True)
save_path = "data/processed/funnel_result.csv"
funnel.to_csv(save_path, index=False, encoding="utf-8-sig")
# =====================
# 执行
# =====================
def run(self):
funnel = self.calculate_conversion()
print(funnel)
self.plot_funnel()
self.save_result()
if __name__ == "__main__":
FunnelAnalysis().run()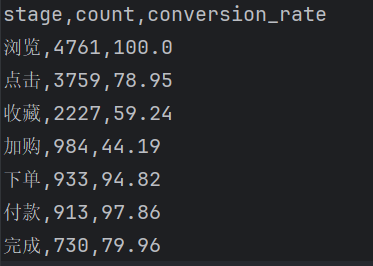
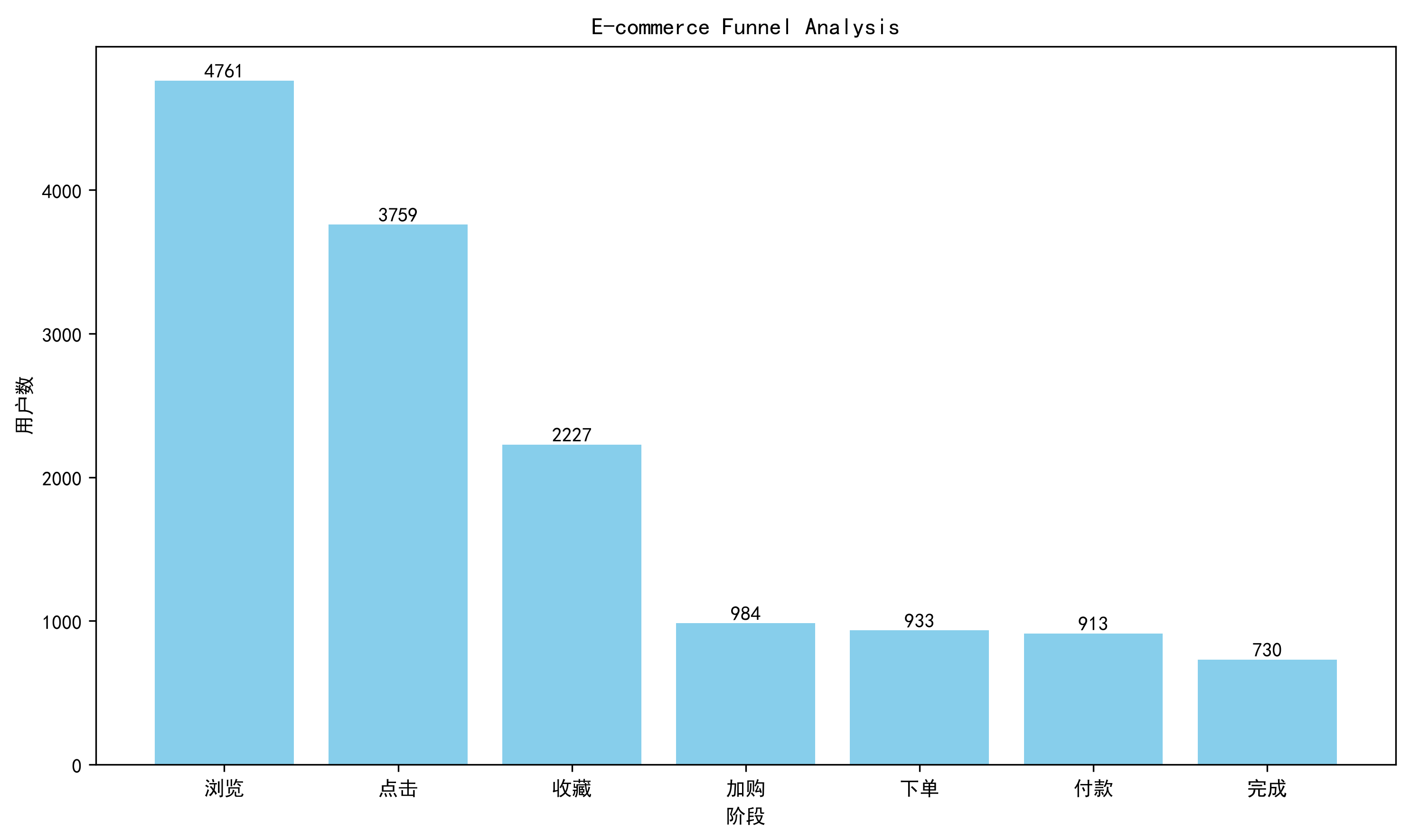
8.4 漏斗图可视化
8.5 转化率分析
| 阶段 | 转化率 |
|---|---|
| 浏览→点击 | 78.95% |
| 点击→收藏 | 59.24% |
| 收藏→加购 | 44.19% |
| 加购→下单 | 94.82% |
| 下单→付款 | 97.86% |
| 付款→完成 | 79.96% |
从整体漏斗来看,浏览→点击转化率较高,说明商品曝光质量较好。
收藏→加购转化率仅44.19%,为整个购买链路最低环节,说明用户已经产生购买兴趣,但尚未完成购买决策。
因此收藏用户是最值得运营干预的人群。
8.6 流失节点分析
第一流失节点:
点击 ---->收藏 : 点击用户达到3759人,其中仅2227人产生收藏行为。
说明用户已进入商品详情页,但商品信息未能有效提升购买兴趣。
可能原因包括:
- 商品评价数量不足
- 商品卖点展示不突出
- 价格竞争力不足
- 用户仍处于比较阶段
第二流失节点:
收藏 ----->加购 : 收藏用户达到2227人,但仅984人加入购物车。转化率仅44.19%。
说明大量用户已经认可商品价值,但仍未形成最终购买决策。这一阶段属于典型的决策犹豫期。
因此收藏用户是最值得进行精准营销的人群。
第三流失节点:
付款 ----->完成
913 730
转化率:79.96%
已付款用户中仍有部分订单未完成。
可能原因包括:
- 退款
- 退货
- 配送失败
8.7 漏斗优化建议
建议1:优化商品详情页
针对:点击 → 收藏 流失严重。
建议:
增加商品评价展示
增加销量展示
强化商品卖点
建议2:针对收藏用户发券
针对:收藏 → 加购 最低转化。
建议:
收藏商品降价提醒
限时优惠券
满减活动
建议3:优化履约流程
针对:付款 → 完成
建议:
提升物流时效
售后服务优化
异常订单预警
8.8 数据驱动优化方案
根据漏斗分析结果,
收藏→加购环节是主要流失节点。
收藏用户召回
针对收藏未加购用户,
推送降价提醒、
限时优惠券、
库存预警等信息,
促进用户完成购买决策。
高价值用户定向营销
结合RFM分析结果,
优先对高价值用户进行新品推荐,
提高复购率和用户生命周期价值。
为了进一步定位收藏用户流失原因,
后续可从以下维度展开分析:
-
商品价格区间分析
-
商品品类分析
-
用户价值分层分析
-
新老用户分析
-
优惠券使用分析
从而识别影响用户加购行为的关键因素。
8.9 漏斗分析总结
通过构建用户购买漏斗发现:
(1)浏览→点击阶段转化率较高,
说明平台流量质量较好;
(2)收藏→加购阶段转化率最低,
是用户购买决策过程中的核心流失节点;
(3)付款→完成阶段仍存在一定订单损失,
需进一步优化履约与售后流程。
结合RFM分析与ABC分析结果,
建议优先针对高价值用户和核心商品开展精准营销,
重点提升收藏用户的加购率与支付率,
从而实现平台GMV增长。
九、商品价值分析(ABC分析)
9.1 分析目标
在电商平台中:
并不是所有商品贡献都一样。
通常:
- 少量商品贡献大部分销售额
- 大量商品贡献很少销售额
因此需要:
将商品划分为:
- A类商品(核心商品)
- B类商品(成长商品)
- C类商品(长尾商品)
帮助运营:
- 核心商品重点投放广告
- 成长商品提升转化
- 长尾商品清仓优化
9.2 ABC分析原理
ABC分析采用:帕累托法则(80/20法则)
即:80%销售额 往往来自20%左右商品
| 类别 | 累计销售额占比 |
|---|---|
| A类 | 0~80% |
| B类 | 80%~95% |
| C类 | 95%~100% |
9.3 核心代码
python
abc = pd.read_csv(
"data/processed/abc_result.csv"
)
print(
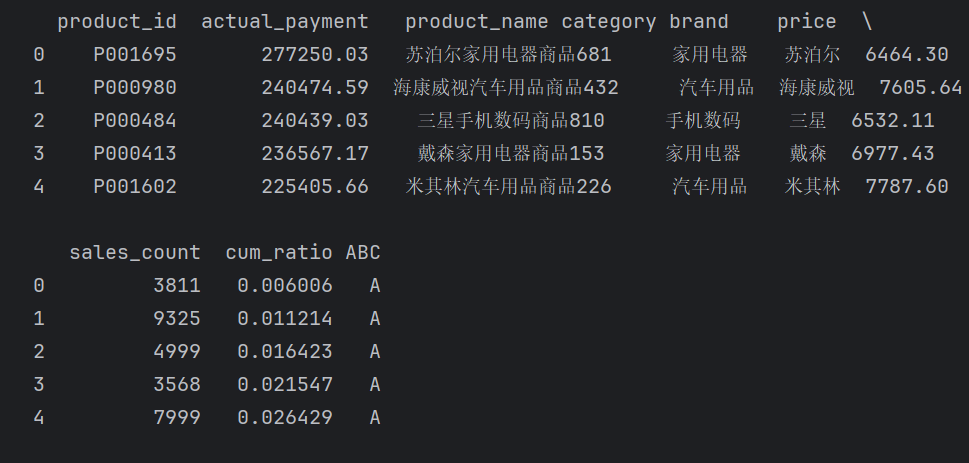
abc.head()
)
9.4 Top10商品销售额排行
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
abc = pd.read_csv(
"data/processed/abc_result.csv"
)
top10 = abc.head(10)
plt.figure(figsize=(10,6))
plt.barh(
top10["product_name"],
top10["actual_payment"]
)
plt.title("Top10商品销售额排行")
plt.xlabel("销售额")
plt.ylabel("商品")
plt.tight_layout()
plt.savefig(
"report/figures/top_product.png",
dpi=300
)
plt.show()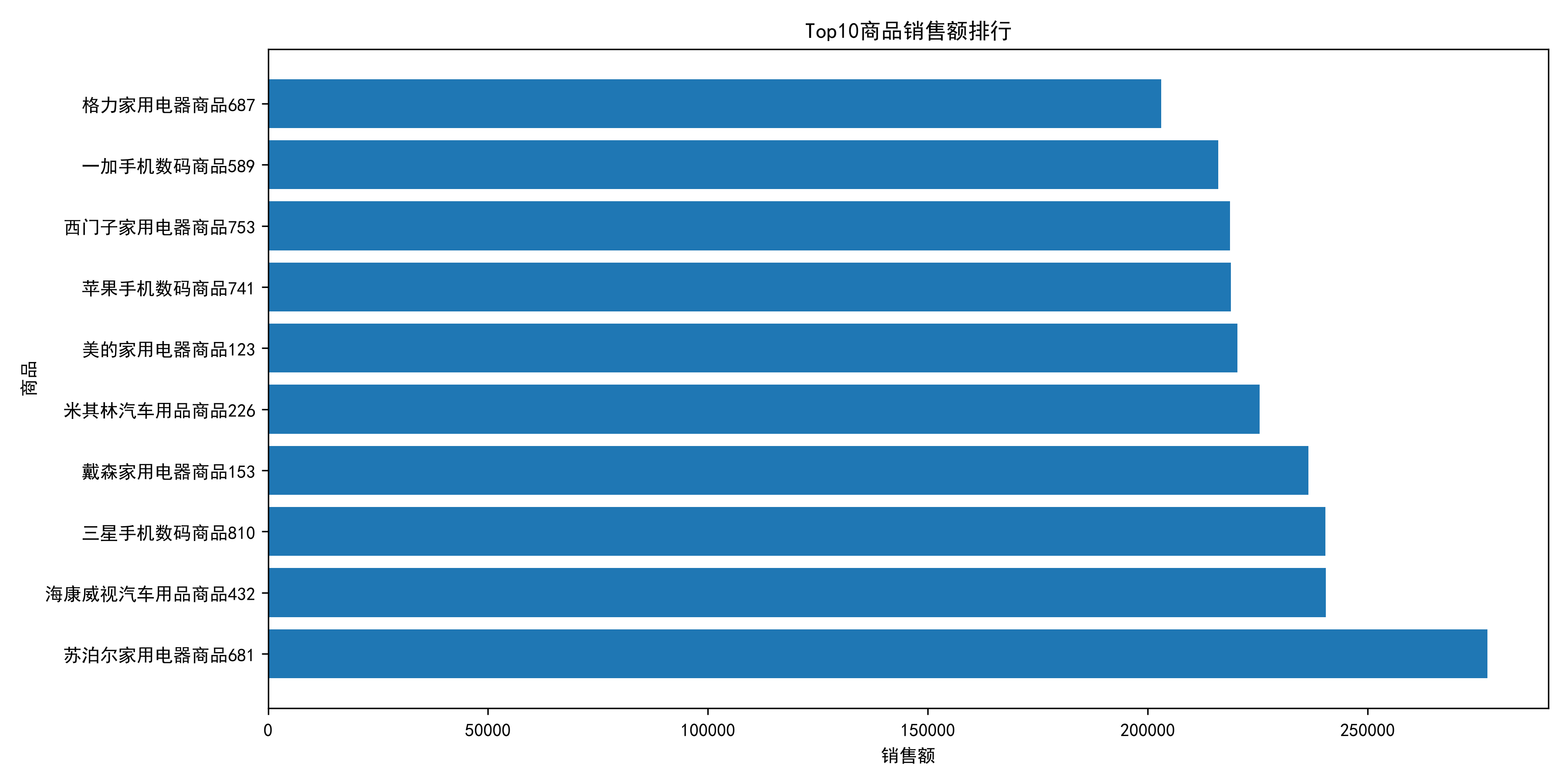
Top10商品销售额主要集中在家用电器、手机数码和汽车用品三大品类。
其中:
苏泊尔家用电器商品681销售额达到27.73万元,
位居平台商品销售额第一;
海康威视汽车用品商品432、
三星手机数码商品810紧随其后。
从品类分布来看,
高销售额商品主要集中于单价较高、消费决策周期较长的耐用品类。
说明平台GMV增长较大程度依赖核心爆款商品贡献。
9.5 ABC分类统计
python
import pandas as pd
abc = pd.read_csv(
"data/processed/abc_result.csv"
)
abc_count = (
abc["ABC"].value_counts()
)
print(abc_count)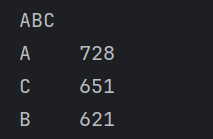
9.6 ABC分类可视化
python
import matplotlib.pyplot as plt
plt.figure(figsize=(8,5))
abc_count.plot(
kind="bar"
)
plt.title("ABC商品分类分布")
plt.tight_layout()
plt.savefig(
"data/figures/abc_distribution.png",
dpi=300
)
plt.show()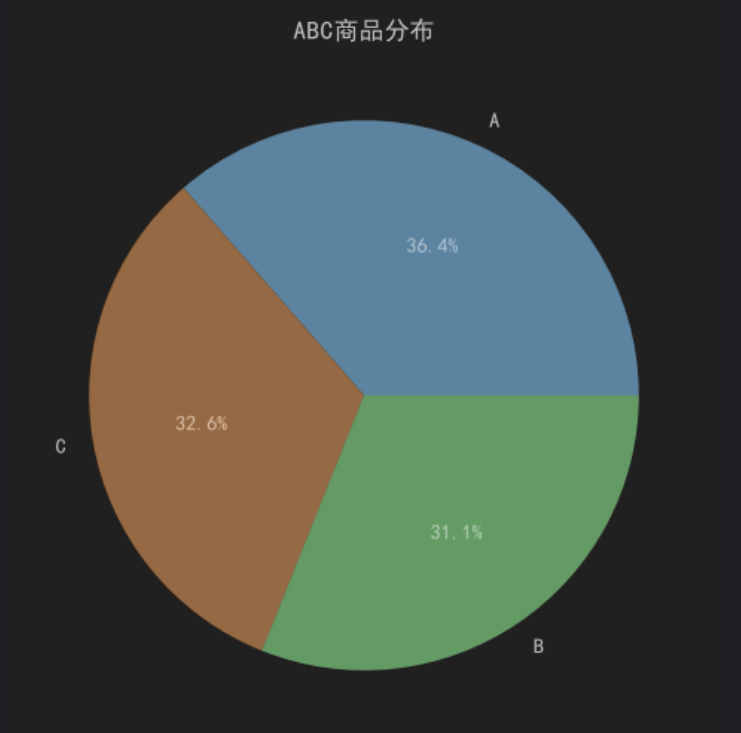
9.7 累计销售额贡献分析
python
import pandas as pd
import matplotlib.pyplot as plt
abc = pd.read_csv(
"data/processed/abc_result.csv"
)
plt.figure(figsize=(10,6))
plt.plot(
abc["cum_ratio"]
)
plt.axhline(
0.8,
linestyle="--"
)
plt.axhline(
0.95,
linestyle="--"
)
plt.title("ABC累计销售额贡献")
plt.tight_layout()
plt.savefig(
"report/figures/abc_cum_ratio.png",
dpi=300
)
plt.show()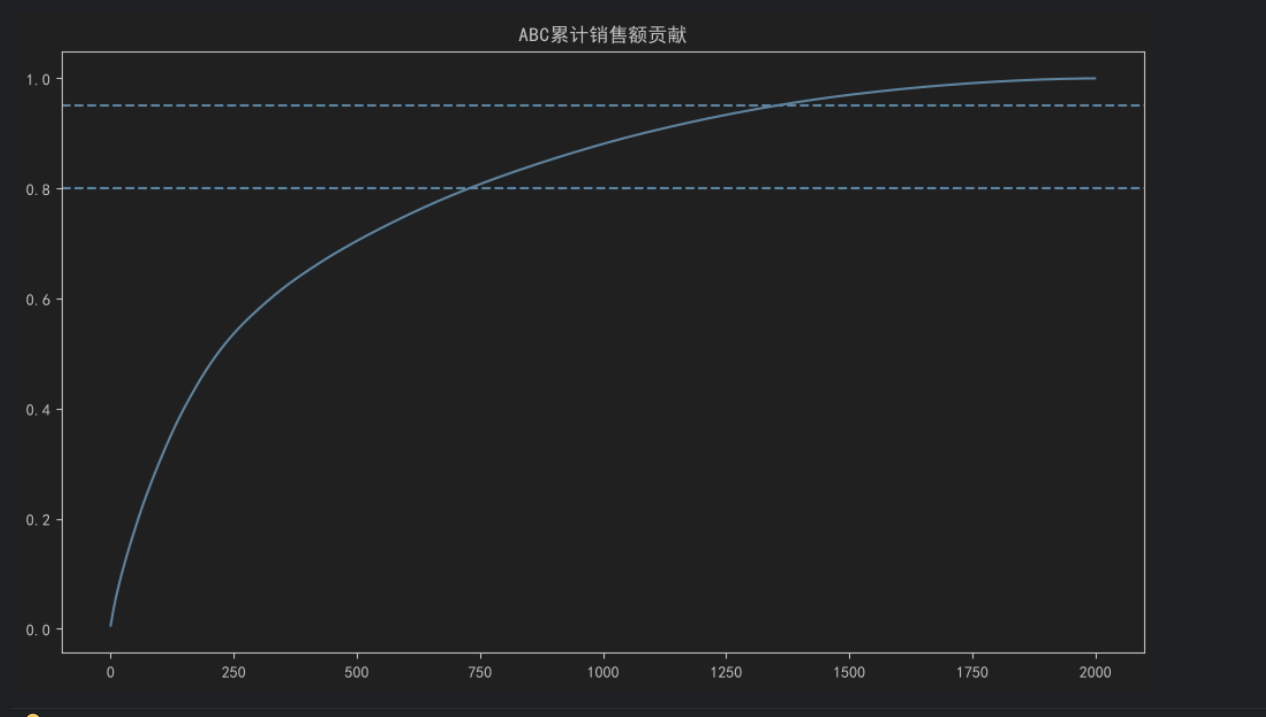
9.8 业务洞察
ABC分析结果显示,
平台商品销售额呈现明显的头部集中现象。
虽然A类商品数量占比相对较低,
但贡献了约80%的销售额,
是平台GMV增长的核心来源。
B类商品处于核心商品与长尾商品之间,
具有较大的成长空间。
通过提升曝光率、优化推荐策略以及促销活动支持,
部分B类商品有机会成长为新的A类商品。
C类商品数量较多,
但销售贡献有限,
存在库存周转效率较低的问题。
因此平台应将运营资源优先投入A类商品,
同时持续挖掘潜力B类商品,
优化低效SKU结构。
9.8.1 ABC分析与GMV关系
结合经营分析结果发现,
平台整体GMV超过4600万元,
而ABC分析进一步说明,
GMV主要来源于少量核心商品贡献。
因此平台未来的增长重点,
不仅在于扩大商品数量,
更在于提升核心商品销售能力以及打造新的爆款商品。
9.8.2 ABC分析与用户价值关系
结合RFM用户价值分析结果发现,
平台存在一定比例的高价值用户群体。
高价值用户往往贡献较高消费金额,
也是A类商品的重要消费人群。
因此可针对高价值用户,
优先推荐A类商品和潜力B类商品,
提高复购率和用户生命周期价值。
9.9 本章总结
本章基于商品销售额构建ABC分析模型,从商品价值角度识别平台核心商品结构。
分析结果表明:
(1)平台商品销售额呈现明显的二八效应;
(2)少量A类商品贡献了绝大部分销售额,是平台GMV增长的核心驱动力;
(3)B类商品具有较大的成长潜力,可作为未来重点培育对象;
(4)C类商品数量较多但销售贡献有限,需要持续优化SKU结构和库存管理。
结合经营分析和RFM用户分析结果,建议优先围绕A类商品和高价值用户开展精准运营,持续提升平台整体销售效率和盈利能力。
十、用户流失预测模型
10.1 项目背景
用户流失会直接影响平台复购率和长期收入。
相比获取新用户,维护老用户通常具有更高的投入产出比。
因此希望通过用户历史消费行为和平台行为数据,提前识别存在流失风险的用户,并制定针对性的用户留存策略。
为实现这一目标,本项目构建用户流失预测模型,对用户未来流失概率进行评估。
10.2 流失用户定义
结合项目数据周期以及用户购买频率特征,将最近90天内无任何下单行为的用户定义为流失用户(Churn=1);其余用户定义为正常用户(Churn=0)。该定义能够较好反映用户长期沉默状态,并满足电商用户生命周期分析需求。
10.3 特征工程
为了刻画用户消费能力和活跃程度,构建以下特征:
| 特征类型 | 指标 |
|---|---|
| 消费能力 | total_spent、avg_order_amount |
| 购买频率 | order_count |
| 活跃程度 | days_since_last_order |
| 行为特征 | 浏览次数、点击次数、收藏次数、加购次数 |
其中:
- 累计消费金额反映用户价值水平;
- 最近购买时间反映用户活跃程度;
- 浏览、点击、收藏、加购行为反映购买意愿强弱。
这些特征共同构成用户流失预测模型输入变量。
10.4 数据集划分
python
from sklearn.model_selection import train_test_split
X = churn_df.drop(
columns=["user_id", "churn"]
)
y = churn_df["churn"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=42,
stratify=y
)按照:70%训练集 30%测试集 进行划分。确保模型泛化能力。
10.5 特征标准化
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)由于:消费金额,订单数,浏览次数 量纲不同,需要标准化处理。
否则:大数值特征会影响模型训练。
10.6 构建逻辑回归模型
python
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(
max_iter=1000,
random_state=42
)
model.fit(
X_train,
y_train
)10.7 模型预测
python
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:,1]10.8 模型评估
python
from sklearn.metrics import classification_report
print(
classification_report(
y_test,
y_pred
)
)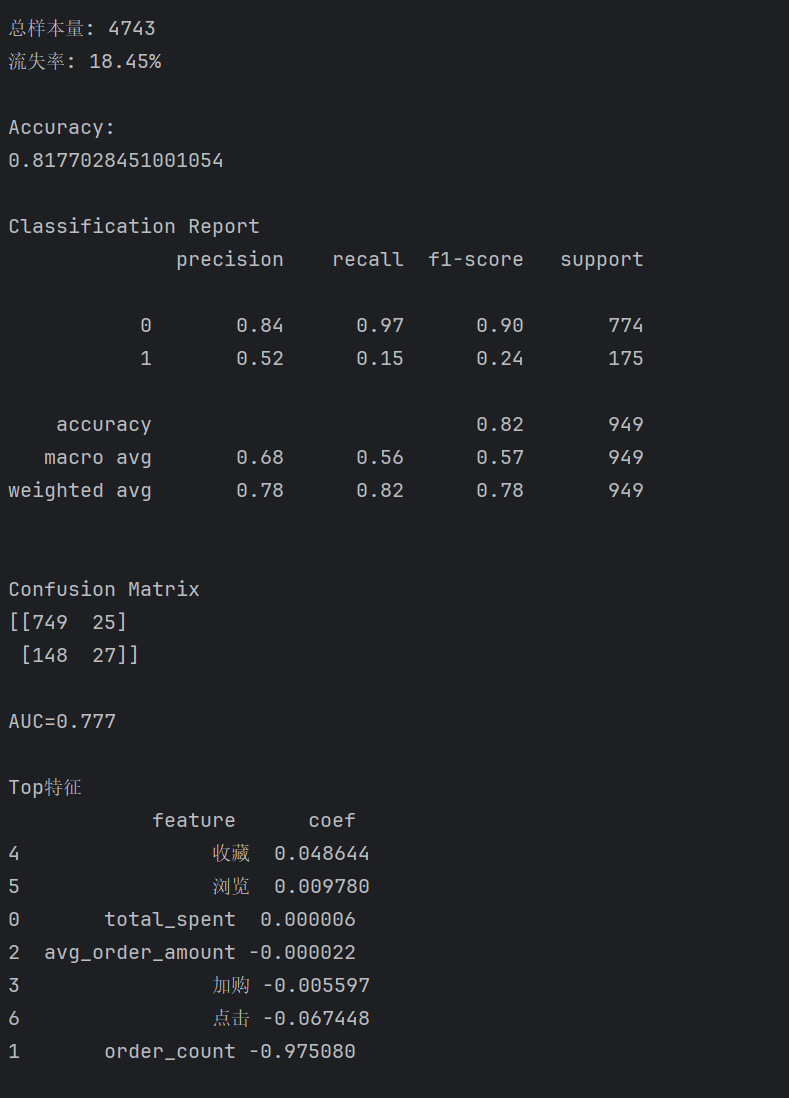
| 指标 | 数值 |
|---|---|
| Accuracy | 81.77% |
| Precision | 52% |
| Recall | 15% |
| F1 Score | 24% |
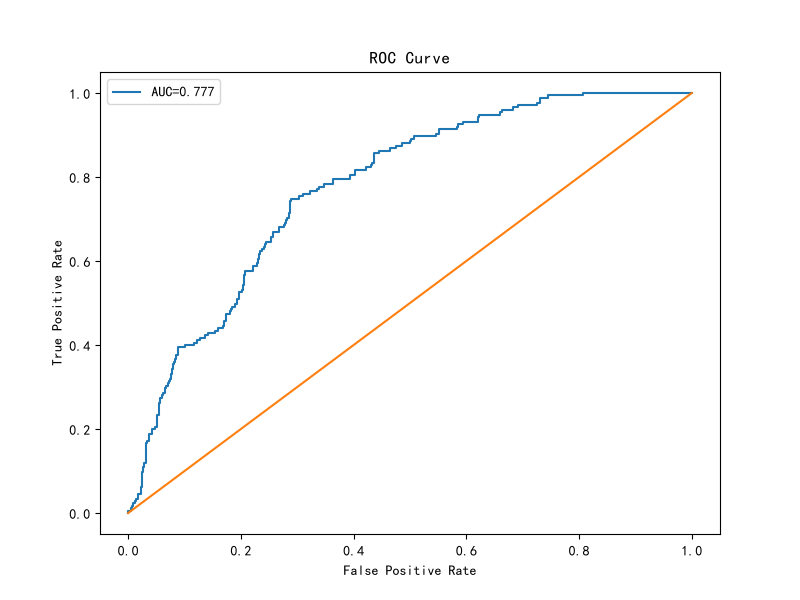
| AUC | 0.777 |
其中:
- Precision表示识别出的流失用户中实际流失用户占比;
- Recall表示实际流失用户被识别出的比例;
- F1 Score综合衡量模型精确率与召回率。
10.9 ROC曲线
python
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
fpr, tpr, _ = roc_curve(
y_test,
y_prob
)
roc_auc = auc(
fpr,
tpr
)10.10 ROC可视化
python
plt.figure(figsize=(8,6))
plt.plot(
fpr,
tpr,
label=f"AUC={roc_auc:.3f}"
)
plt.plot(
[0,1],
[0,1]
)
plt.legend()
plt.title("ROC Curve")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.show()10.11 模型结果分析
AUC评价标准:
| AUC | 评价 |
|---|---|
| 0.5 | 随机猜测 |
| 0.6~0.7 | 一般 |
| 0.7~0.8 | 较好 |
| 0.8~0.9 | 优秀 |
| 0.9+ | 非常优秀 |
模型AUC达到0.777。
说明模型能够较好地区分流失用户与非流失用户。
从业务角度来看,平台已经能够利用用户历史行为数据提前识别潜在流失风险,为用户召回和精准营销提供支持。
虽然仍存在一定误判,但已经具备实际运营应用价值。
10.12 高风险流失用户识别
python
risk_users = churn_df.copy()
risk_users["churn_probability"] = (
model.predict_proba(
scaler.transform(X)
)[:,1]
)
risk_users = risk_users[
risk_users["churn_probability"] > 0.8
]根据模型预测结果,
将流失概率大于80%的用户定义为高风险用户。
该部分用户虽然尚未完全流失,但已经表现出明显的活跃度下降趋势,需要重点关注。
10.13 业务建议
根据模型结果发现:
最近购买时间(days_since_last_order)以及订单数量(order_count)对用户流失影响较大。
因此建议:
(1)沉默用户召回
针对近60~90天未下单用户:
- 推送专属优惠券;
- 发送限时促销提醒;
- 推荐历史购买相关商品。
(2)低频用户培育
针对订单次数较少用户:
- 设置首购后连续复购奖励;
- 提供会员积分激励;
- 增加个性化推荐曝光。
(3)高价值用户保护
针对高消费用户:
- 建立VIP用户体系;
- 提供专属客服;
- 发放会员专属权益。
10.14 本章总结
本章基于用户消费数据与行为数据构建了用户流失预测模型。
模型AUC达到0.777,具备较好的用户流失识别能力。
通过识别高风险流失用户,平台能够提前开展召回运营和精准营销,从而降低用户流失率并提升用户生命周期价值。
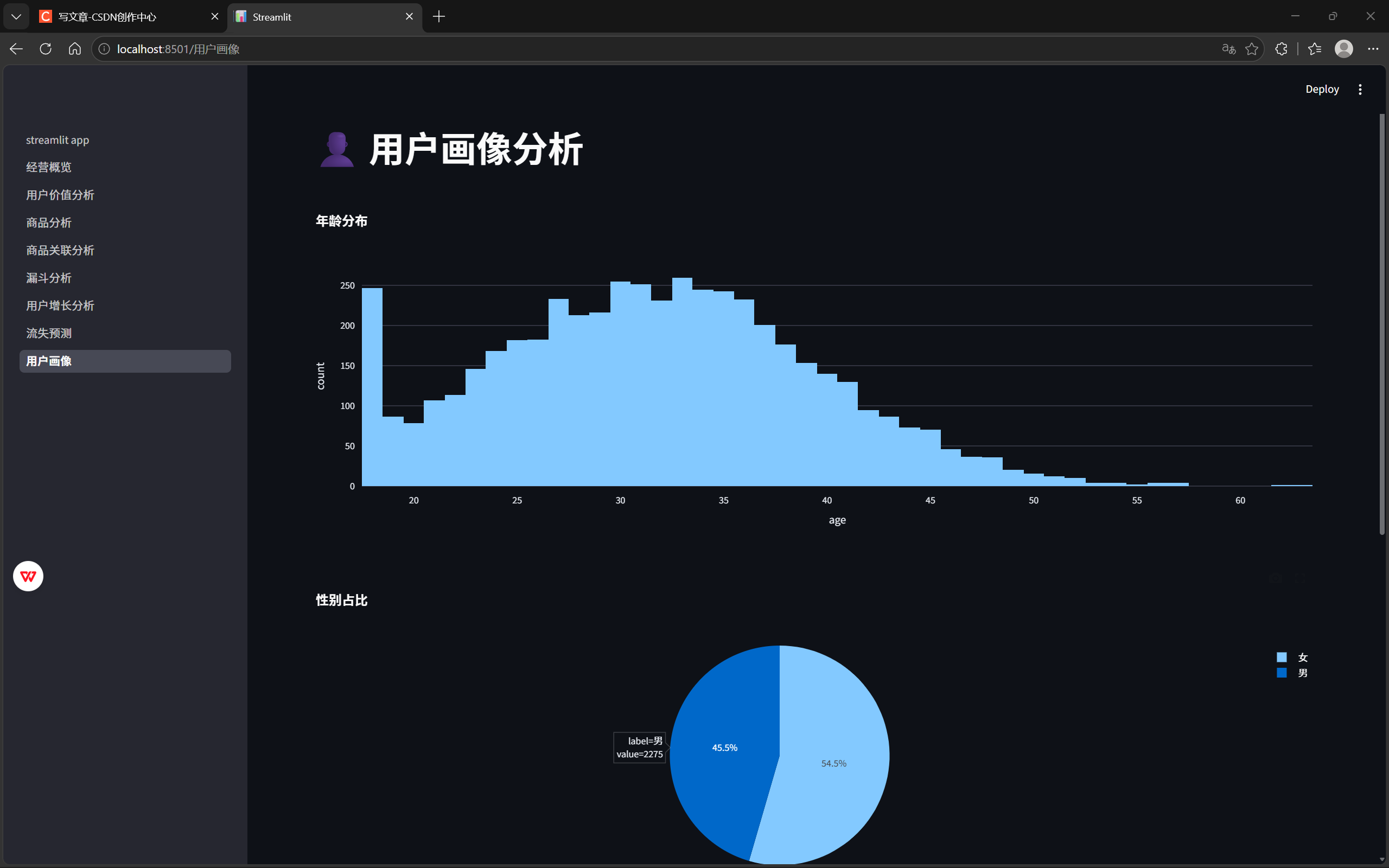
十一、Streamlit可视化看板
11.1 平台设计目标
为了提升分析结果的展示效果,
基于Streamlit开发电商经营分析平台,
将前述经营分析、RFM用户分析、ABC商品分析、漏斗分析、用户增长分析以及流失预测结果进行统一展示。
实现业务指标可视化监控和自助分析。
11.2 平台整体架构
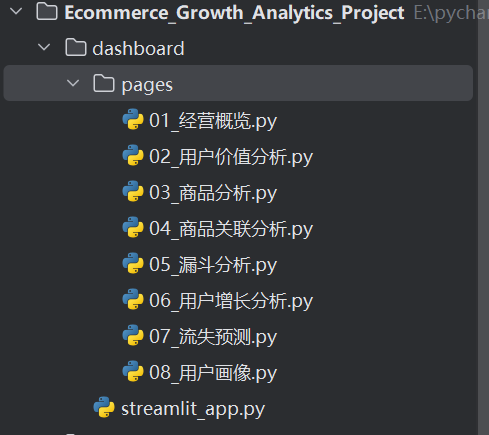
本项目设计了:6个分析模块
经营概览,用户价值分析,商品分析,漏斗分析,流失预测,增长分析
对应:dashboard/pages
11.3 KPI经营指标看板
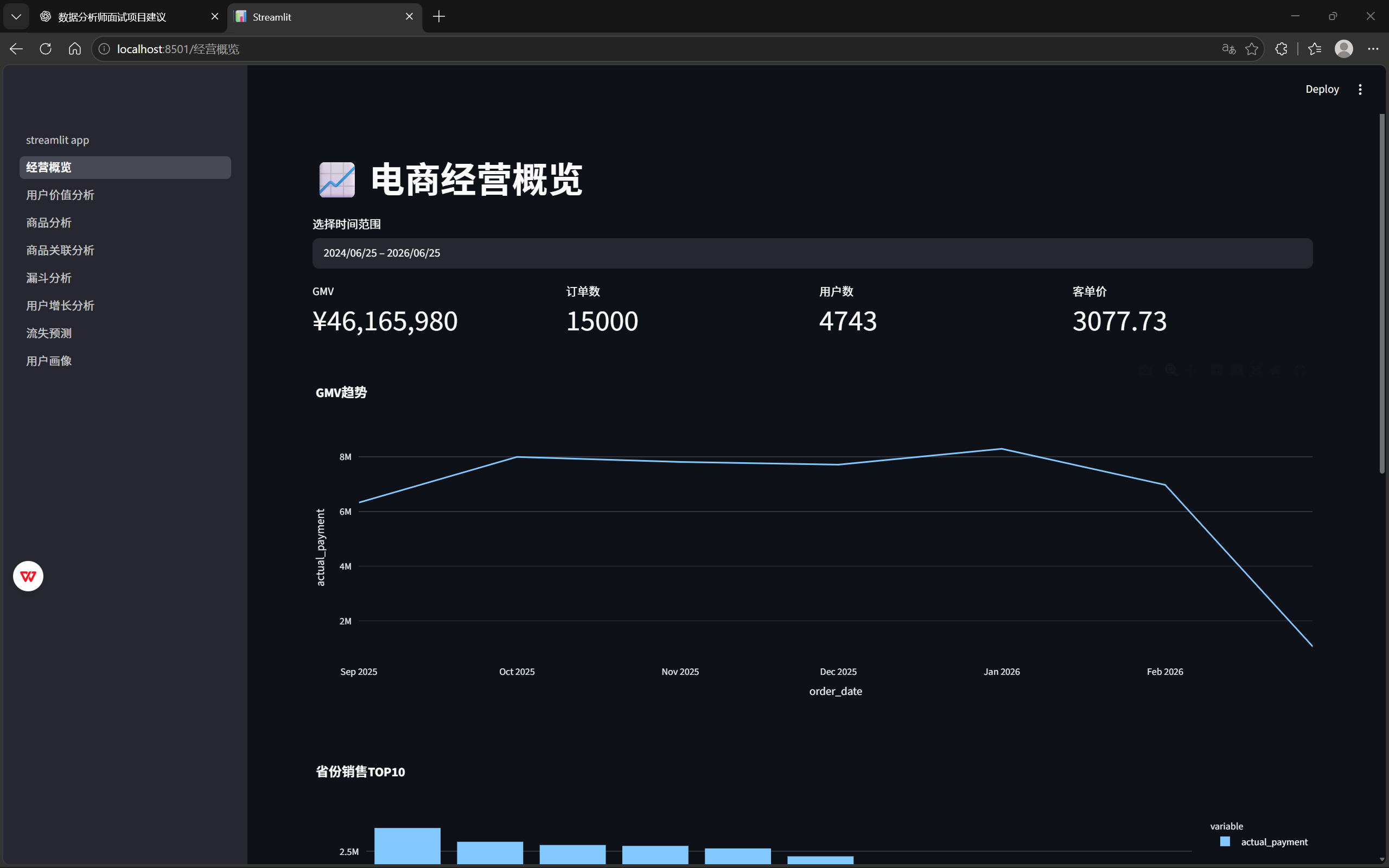
经营概览模块主要展示平台核心经营指标:
GMV
订单量
用户数
客单价
帮助业务人员快速掌握平台整体经营情况。
python
col1,col2,col3,col4 = st.columns(4)
col1.metric(
"GMV",
f"{gmv:,.0f}"
)
col2.metric(
"订单数",
order_count
)
col3.metric(
"用户数",
user_count
)
col4.metric(
"客单价",
round(avg_order_value,2)
)
11.4 GMV趋势分析
用于观察:平台销售额变化情况。
python
fig = px.line(
monthly_gmv,
x="month",
y="gmv",
title="GMV趋势"
)
st.plotly_chart(
fig,
use_container_width=True
)
文章分析:
从结果可以发现:2025年10月至2026年1月平台GMV持续保持较高水平。
其中:2026-01达到峰值。
说明:平台在年末促销期间销售表现较好。
11.5 用户价值分析
采用:RFM模型
python
segment_count = (
rfm["segment"]
.value_counts()
)
fig = px.pie(
values=segment_count.values,
names=segment_count.index,
title="用户价值分层"
)
st.plotly_chart(fig)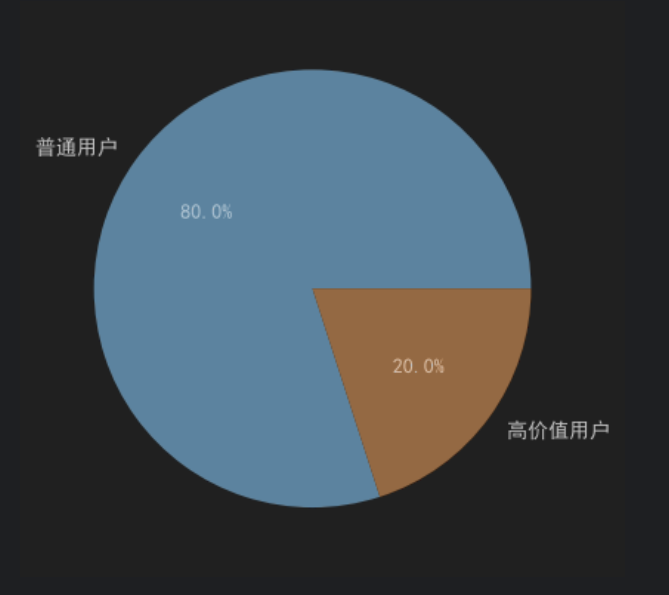
用户价值分析模块基于RFM模型完成用户分层。
通过可视化方式展示:
高价值用户
普通用户
等用户群体分布情况。
帮助运营团队开展精细化运营。
11.6 商品ABC分析
用于识别:核心商品。
python
fig = px.bar(
abc.head(10),
x="actual_payment",
y="product_name",
orientation="h",
title="Top10商品销售额"
)
st.plotly_chart(fig)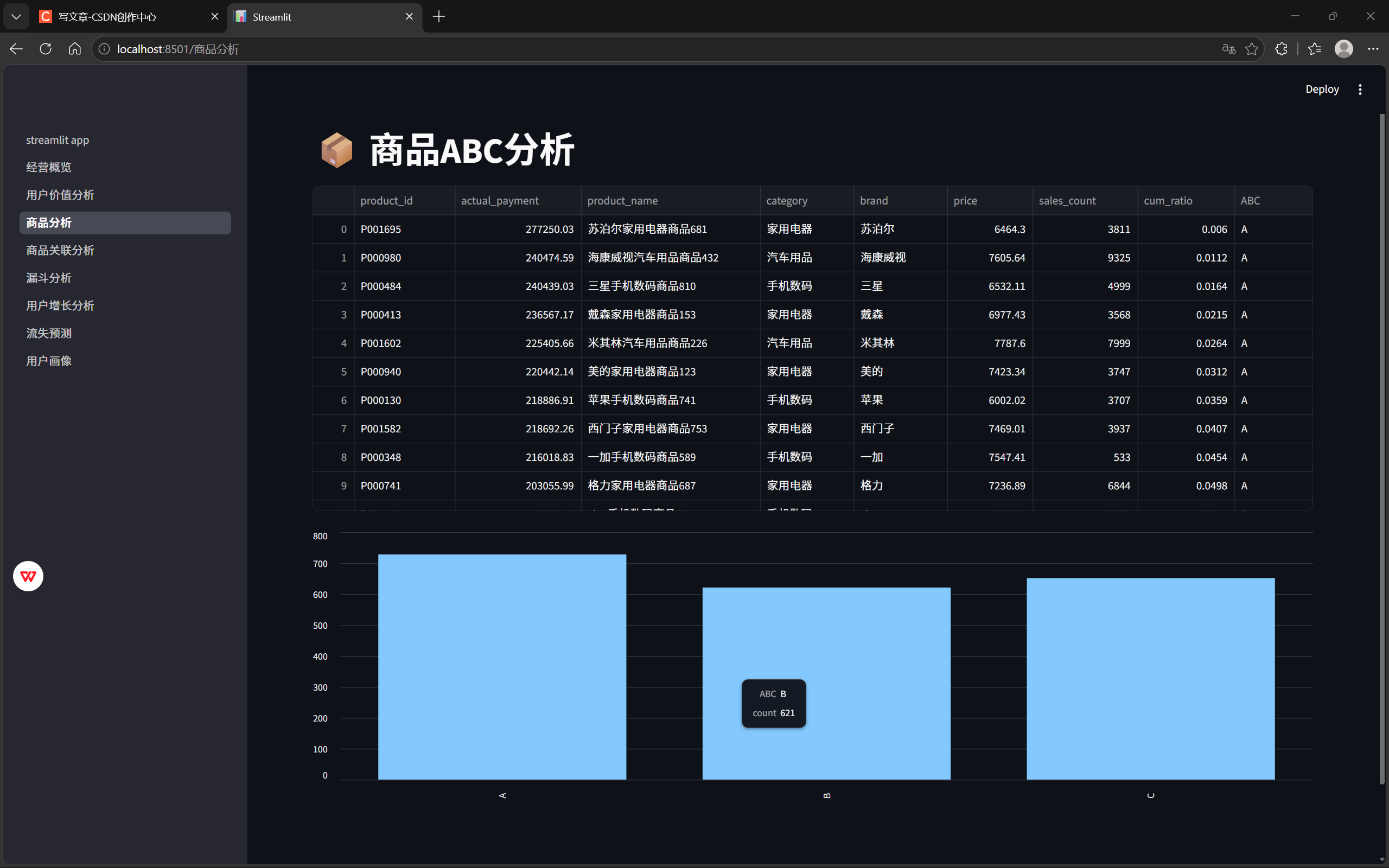
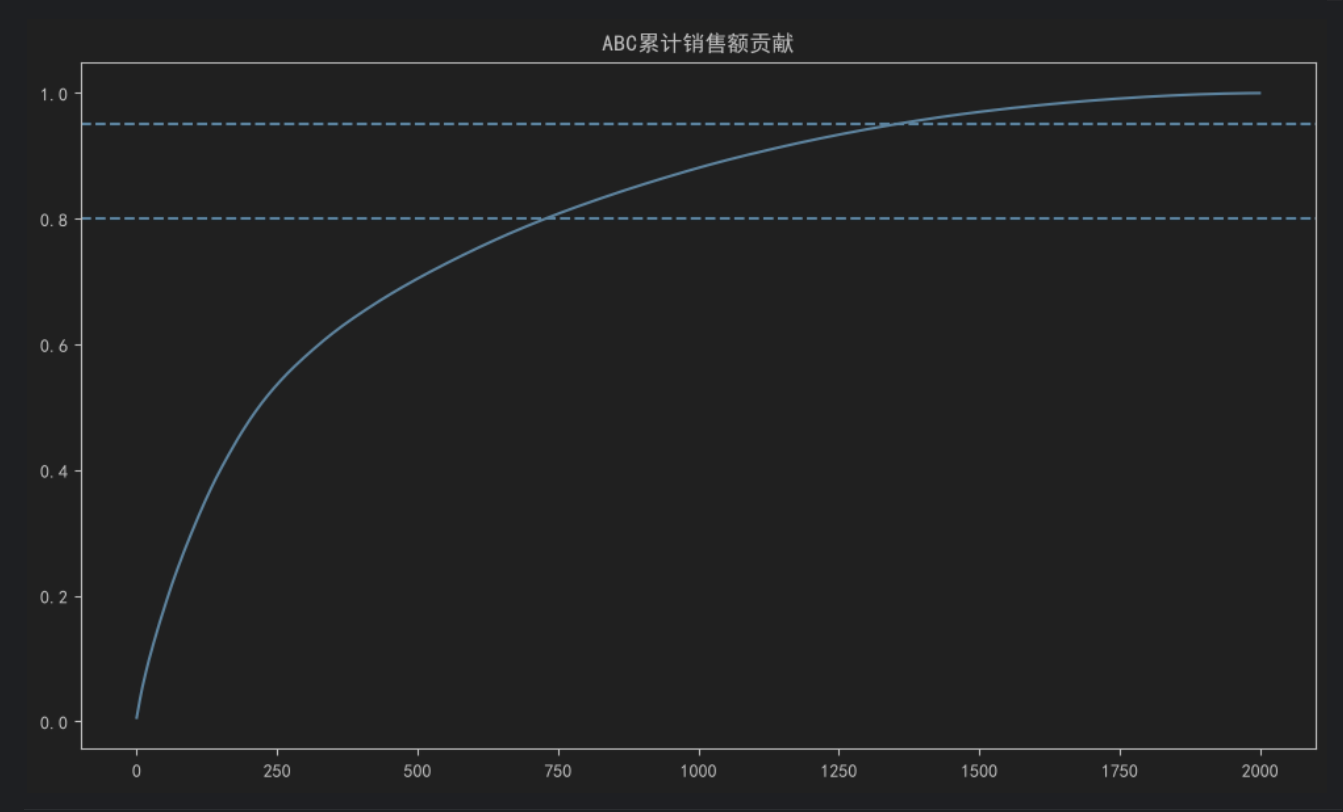
11.7 用户转化漏斗
python
fig = px.funnel(
funnel,
x="count",
y="stage",
title="用户转化漏斗"
)
st.plotly_chart(fig)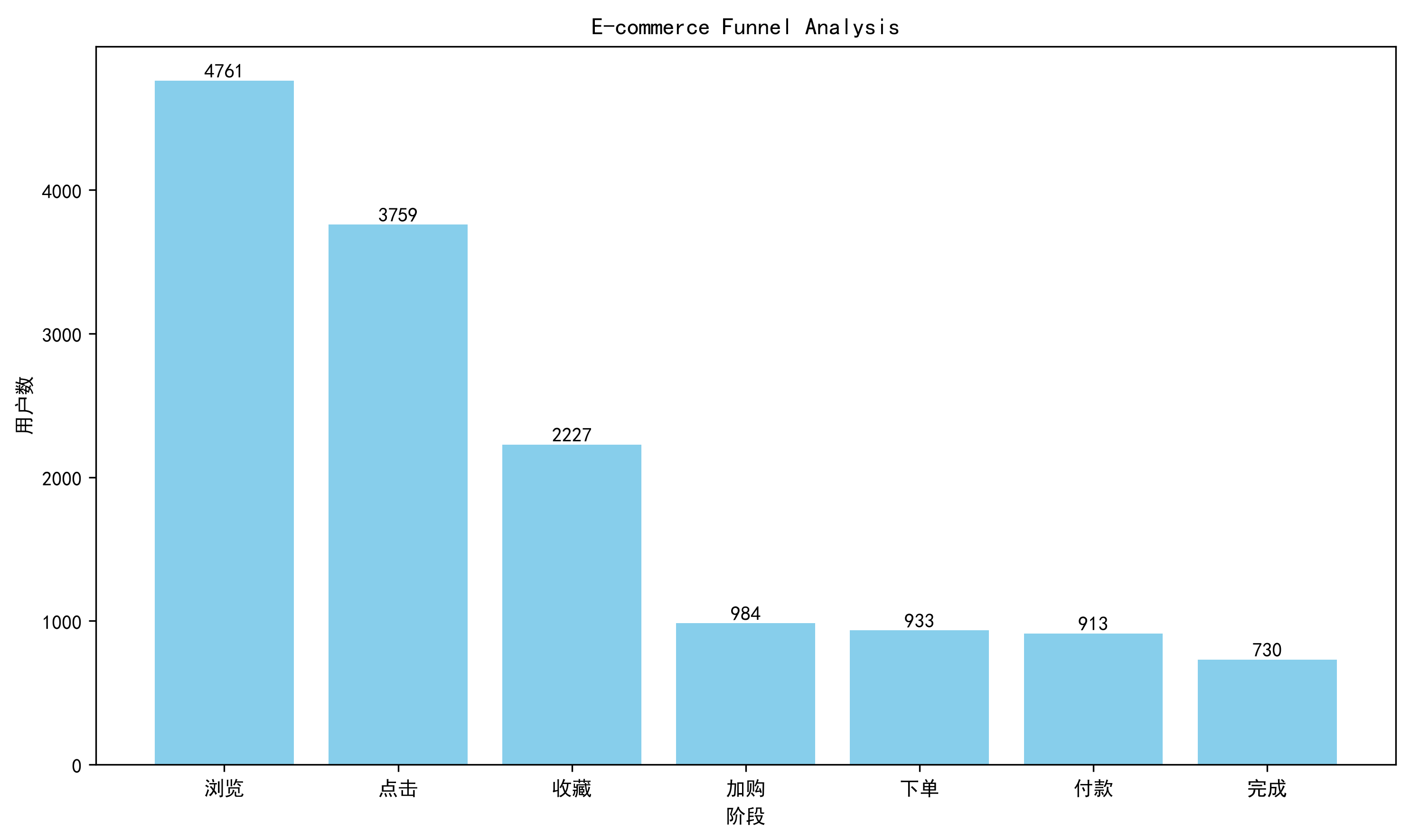
通过漏斗分析发现:
收藏→加购环节转化率最低,
是当前主要流失节点。
后续可通过优惠券营销等方式提升转化率。
11.8 流失预测模块
利用:Logistic Regression
预测:用户流失概率。
python
risk_users = churn_df[
churn_df[
"days_since_last_order"
] > 90
]
st.dataframe(
risk_users.head(20)
)
流失预测模块基于Logistic Regression模型构建。模型AUC达到0.777。能够较好识别潜在流失用户。为后续用户召回运营提供支持。
11.9 用户增长分析
分析:平台新增用户趋势。
python
fig = px.line(
growth_df,
x="month",
y="new_users",
title="新增用户趋势"
)
st.plotly_chart(fig)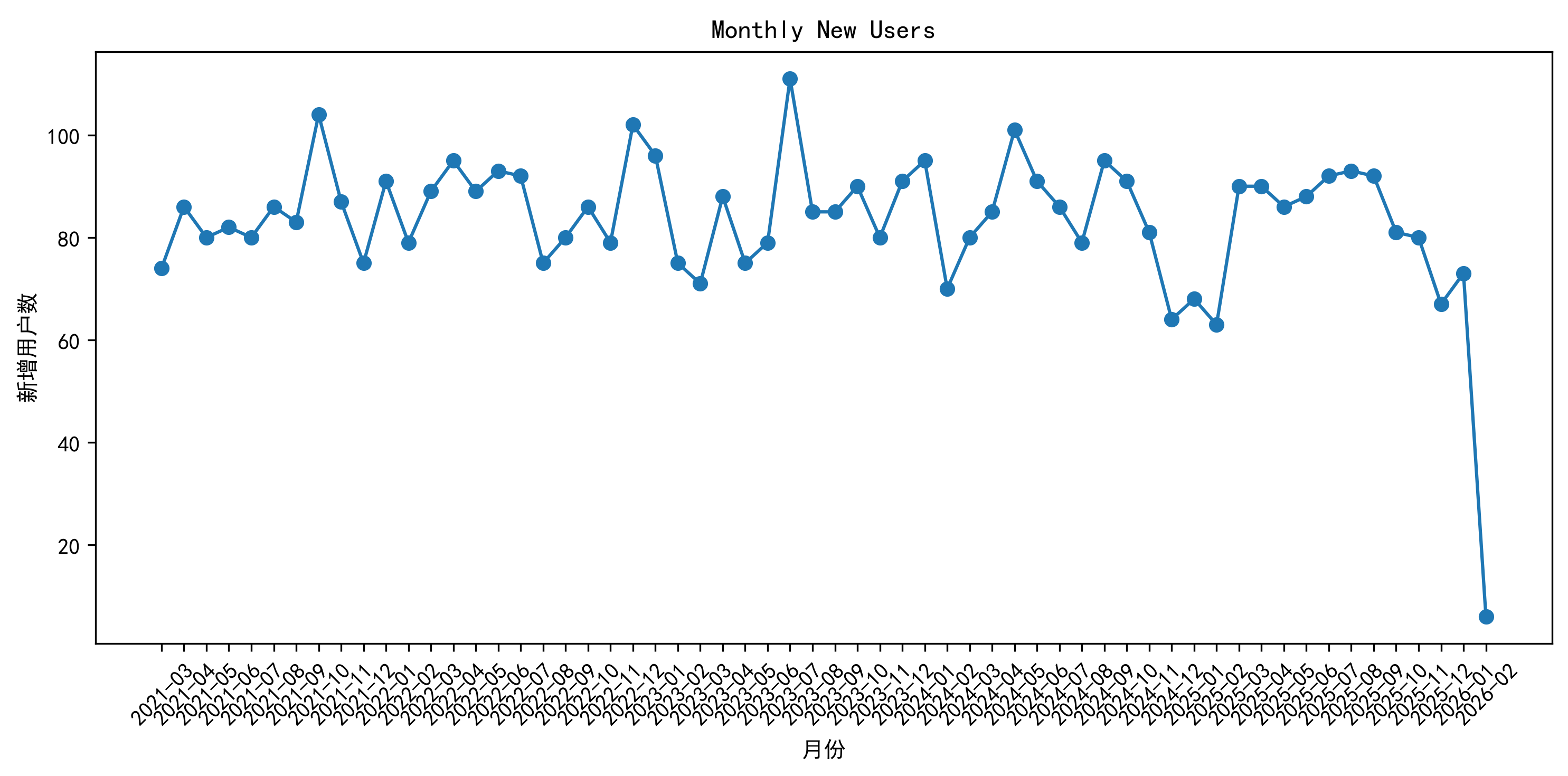
用户增长分析模块展示平台新增用户趋势。
根据分析结果:
2021年至2025年期间新增用户总体保持稳定。大部分月份新增用户保持在70~100人之间。
说明平台用户增长较为平稳。
11.10 项目价值
通过Streamlit平台,将原本分散在多个分析模块中的结果进行统一展示。相比传统Excel报表,
能够实现:
实时查看核心指标
快速定位业务问题
辅助运营决策
提升数据分析效率
11.11 本章总结
本章基于Streamlit构建电商经营分析平台,
集成:
经营概览分析
RFM用户分析
ABC商品分析
用户增长分析
漏斗分析
流失预测分析
实现从数据获取、业务分析到可视化展示的完整闭环。
最终帮助业务人员更加高效地监控经营情况并支持运营决策。
十二、项目总结与业务价值
12.1 项目整体成果
本项目基于电商平台业务数据,完成了从数据获取、数据清洗、特征工程、业务分析、机器学习建模到可视化看板搭建的完整数据分析流程。
项目主要包含:
- MySQL数据库搭建
- Python数据处理
- RFM用户价值分析
- ABC商品价值分析
- 用户转化漏斗分析
- 用户增长分析
- 用户流失预测模型
- Streamlit经营分析看板
最终实现了从描述性分析到预测性分析的完整闭环。
12.2 经营分析成果
通过经营概览分析发现:
(1)平台经营规模稳定
通过GMV趋势分析发现,平台整体交易规模保持稳定。月度销售额未出现明显异常波动,说明平台运营状态较为健康。
(2)头部商品贡献明显
ABC分析结果显示:
少量核心商品贡献了大部分销售额。平台存在明显的二八法则现象。
核心商品主要集中于:
- 家用电器
- 手机数码
- 汽车用品
等高客单价品类。
(3)用户价值分层明显
RFM分析结果显示:
平台用户主要分布于:
- 高价值用户
- 潜力用户
- 普通用户
不同层级用户表现出明显差异。说明平台具备实施精细化运营的基础。
12.3 漏斗分析成果
点击 → 收藏
转化率:59.24%存在较大流失。
收藏 → 加购
转化率:44.19%为整个漏斗中转化率最低环节。说明用户虽然表现出兴趣,但购买意愿仍需进一步刺激。
付款 → 完成
转化率:79.96%说明部分订单存在退款或售后情况。
12.4 用户增长分析成果
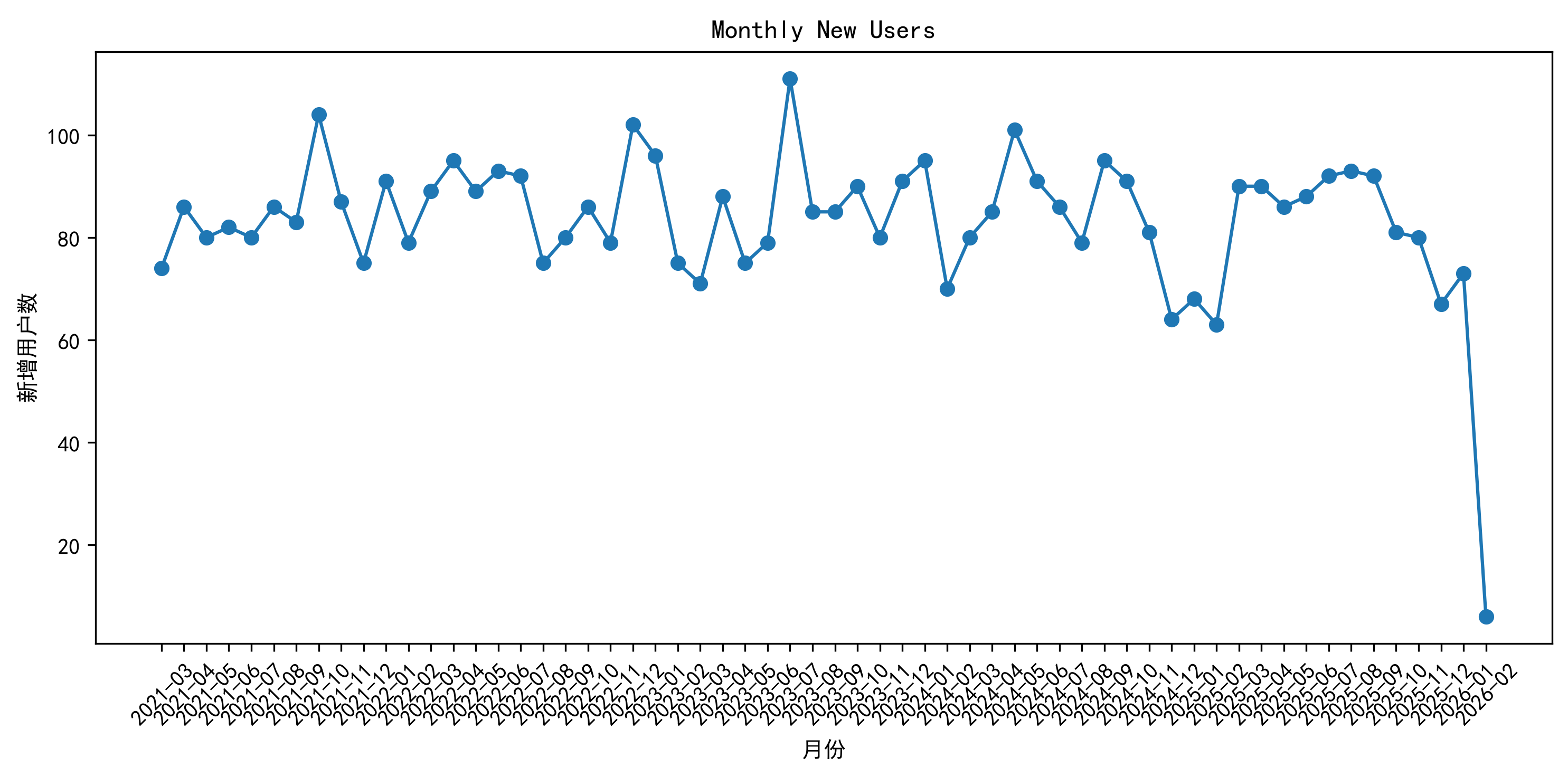
通过用户注册数据统计发现,平台新增用户数量整体较为稳定。从历史数据来看,不同月份新增用户规模存在一定波动。
| 月份 | 新增用户数 |
|---|---|
| 2023-07 | 111 |
| 2021-10 | 104 |
| 2022-12 | 102 |
| 2024-05 | 101 |
说明平台在不同时间段的用户增长表现存在差异。由于当前项目未包含渠道来源、广告投放及营销活动数据,因此无法进一步判断新增用户波动的具体原因。
后续如接入渠道数据,可进一步分析:
- 用户获取来源
- 渠道转化效果
- 用户增长驱动因素
12.5 流失预测成果
项目基于用户消费行为与用户互动行为构建流失预测模型。
模型使用特征包括:
- 累计消费金额
- 订单数量
- 客单价
- 最近购买时间
- 浏览次数
- 点击次数
- 收藏次数
- 加购次数
采用 Logistic Regression 进行建模。
通过ROC曲线评估模型效果。
模型能够有效识别潜在流失用户,为后续用户召回提供支持。
12.6 项目业务价值
本项目通过数据分析发现:
用户层面
通过RFM模型识别高价值用户,为会员运营与精准营销提供支持。
商品层面
通过ABC分析识别核心商品,为库存管理和资源投放提供依据。
转化层面
通过漏斗分析发现收藏到加购环节存在较大流失,为优惠券营销和促销活动设计提供方向。
风险层面
通过流失预测模型提前识别潜在流失用户,为用户召回提供支持。
管理层面
通过Streamlit可视化看板实现经营指标实时监控,提高数据驱动决策效率。
12.7 项目总结
本项目完整实践了数据分析项目的全流程:
- 数据库搭建
- 数据清洗
- 特征工程
- 业务分析
- 机器学习建模
- 数据可视化
项目覆盖了电商场景中的核心分析模块:
- 经营分析
- 用户价值分析
- 商品价值分析
- 用户增长分析
- 漏斗分析
- 流失预测
通过该项目,我进一步提升了:
- SQL数据处理能力
- Python数据分析能力
- 数据可视化能力
- 机器学习建模能力
- 数据驱动业务分析能力
并积累了完整的数据分析项目实战经验。