文章目录
- 一、前言
- 二、DeepSeekMath
- [3. 监督式微调(Supervised Fine-Tuning)](#3. 监督式微调(Supervised Fine-Tuning))
- [3.1. SFT数据整理(SFT Data Curation)](#3.1. SFT数据整理(SFT Data Curation))
- [3.2. DeepSeekMath-Instruct 7B 的训练与评估](#3.2. DeepSeekMath-Instruct 7B 的训练与评估)
-
- 问题1:总结一下
-
- [3.1 SFT 数据整理](#3.1 SFT 数据整理)
- [3.2 DeepSeekMath-Instruct 7B 的训练与评估](#3.2 DeepSeekMath-Instruct 7B 的训练与评估)
- 问题2:多格式指令微调?
-
- 三种格式具体是什么?
- [SFT 阶段具体怎么做的?](#SFT 阶段具体怎么做的?)
- [补充:SFT 和 RL 阶段的格式差异](#补充:SFT 和 RL 阶段的格式差异)
- 问题3:更直观的解释
-
- 一、三种格式长什么样?(看具体数据)
- [格式 1:CoT(思维链)------ 像写小作文](#格式 1:CoT(思维链)—— 像写小作文)
- [格式 2:PoT(程序思维)------ 像写代码](#格式 2:PoT(程序思维)—— 像写代码)
- [格式 3:Tool-Integrated(工具集成)------ 像边想边查计算器](#格式 3:Tool-Integrated(工具集成)—— 像边想边查计算器)
- [二、SFT 训练时到底在干什么?](#二、SFT 训练时到底在干什么?)
- 三、模型学完之后的效果
- 四、为什么叫"多格式"?为什么这样混合有效?
- [五、补充:SFT 和 RL 的区别](#五、补充:SFT 和 RL 的区别)
- [问题4:拼接成每段 4K tokens 的长文本不会被截断吗](#问题4:拼接成每段 4K tokens 的长文本不会被截断吗)
-
- 第一个问题:随机拼接会不会截断在问题中间?
- [做法 A:打包(Packing)+ 掩码隔离](#做法 A:打包(Packing)+ 掩码隔离)
- [做法 B:即使真的截断了,也没那么严重](#做法 B:即使真的截断了,也没那么严重)
- [但有个更关键的问题:Loss 计算](#但有个更关键的问题:Loss 计算)
- [第二个问题:为什么 RL 只练纯文字(CoT),不继续练代码和工具?](#第二个问题:为什么 RL 只练纯文字(CoT),不继续练代码和工具?)
- [1. Reward 信号越简单,RL 越稳定](#1. Reward 信号越简单,RL 越稳定)
- [2. 论文的核心目标是"数学推理",不是"工具使用"](#2. 论文的核心目标是"数学推理",不是"工具使用")
- [3. 统一范式实验的需要](#3. 统一范式实验的需要)
- [4. 代码/工具能力在 SFT 后已经够用了](#4. 代码/工具能力在 SFT 后已经够用了)
- 总结成一句话
一、前言
仅供参考,未经实验验证。
二、DeepSeekMath
论文标题: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
(DeepSeekMath:推动开放语言模型中数学推理的极限)
作者: Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y.K. Li, Y. Wu, Daya Guo
机构: DeepSeek-AI(主导)、清华大学、北京大学
发表时间: 2024年2月6日(arXiv:2402.03300)
GitHub: https://github.com/deepseek-ai/DeepSeek-Math
3. 监督式微调(Supervised Fine-Tuning)
3.1. SFT数据整理(SFT Data Curation)
We construct a mathematical instruction-tuning dataset covering English and Chinese problems from different mathematical fields and of varying complexity levels: problems are paired with solutions in chain-of-thought (CoT) (Wei et al., 2022), program-of-thought (PoT) (Chen et al., 2022; Gao et al., 2023), and tool-integrated reasoning format (Gou et al., 2023). The total number of training examples is 776K.
我们构建了一个涵盖不同数学领域、不同复杂程度的英语和中文问题的数学指令调优数据集:问题与链式思考(CoT)(Wei et al., 2022))、程序思考(PoT)(Chen et al., 2022; Gao et al., 2023))和工具集成推理格式(Gou et al., 2023)的解决方案配对。训练样本总数为776K。
-
English mathematical datasets: We annotate GSM8K and MATH problems with toolintegrated solutions, and adopt a subset of MathInstruct (Yue et al., 2023) along with the training set of Lila-OOD (Mishra et al., 2022) where problems are solved with CoT or PoT. Our English collection covers diverse fields of mathematics, e.g., algebra, probability, number theory, calculus, and geometry.
英文数学数据集:我们使用工具集成解决方案标注 GSM8K 和 MATH 问题,并采用 MathInstruct (Yue et al., 2023) 的一个子集以及 Lila-OOD (Mishra et al., 2022) 的训练集,其中问题通过 CoT 或 PoT 解决。我们的英文集合涵盖了数学的各个领域,例如代数、概率、数论、微积分和几何。
-
Chinese mathematical datasets: We collect Chinese K-12 mathematical problems spanning 76 sub-topics such as linear equations, with solutions annotated in both CoT and toolintegrated reasoning format.
中文数学数据集:我们收集了中文K-12数学问题,涵盖76个子主题,如线性方程,并以CoT和工具集成推理格式注释了解决方案。
3.2. DeepSeekMath-Instruct 7B 的训练与评估
In this section, we introduce DeepSeekMath-Instruct 7B which undergoes mathematical instruction tuning based on DeepSeekMath-Base. Training examples are randomly concatenated until reaching a maximum context length of 4K tokens. We train the model for 500 steps with a batch size of 256 and a constant learning rate of 5e-5.
在本节中,我们将介绍 DeepSeekMath-Instruct 7B,它是在 DeepSeekMath-Base 的基础上进行数学指令微调得到的。训练样本被随机连接,直到达到 4K tokens 的最大上下文长度。我们以 256 的批量大小和 5e-5 的恒定学习率训练模型 500 步。
We evaluate models' mathematical performance both without and with tool use, on 4 quantitative reasoning benchmarks in English and Chinese. We benchmark our model against the leading models of the time:
我们评估了模型在英语和中文的4个定量推理基准上的数学性能,包括不使用工具和使用工具两种情况。我们将我们的模型与当时的领先模型进行了基准测试:
-
Closed-source models include: (1) the GPT family among which GPT-4 (OpenAI, 2023) and GPT-4 Code Interpreter 2 are the most capable ones, (2) Gemini Ultra and Pro (Anil et al., 2023), (3) Inflection-2 (Inflection AI, 2023), (4) Grok-1 3, as well as models recently released by Chinese companies including (5) Baichuan-3 4, (6) the latest GLM-4 5 from the GLM family (Du et al., 2022). These models are for general purposes, most of which have undergone a series of alignment procedures.
闭源模型包括:(1)GPT系列,其中GPT-4 (OpenAI, 2023) 和 GPT-4 Code Interpreter 2 是能力最强的模型;(2)Gemini Ultra 和 Pro (Anil et al., 2023);(3)Inflection-2 (Inflection AI, 2023);(4)Grok-1 3;以及最近中国公司发布的模型,包括(5)Baichuan-3 4;(6)来自GLM系列的最新GLM-4 5 (Du et al., 2022)。这些模型都是通用的,其中大多数都经过了一系列对齐程序。
-
Open-source models include: general models like (1) DeepSeek-LLM-Chat 67B (DeepSeek-AI, 2024), (2) Qwen 72B (Bai et al., 2023), (3) SeaLLM-v2 7B (Nguyen et al., 2023), and (4)
开源模型包括:通用模型,如(1)DeepSeek-LLM-Chat 67B (DeepSeekAI, 2024),(2)Qwen 72B (Bai et al., 2023),(3)SeaLLM-v2 7B (Nguyen et al., 2023),以及(4)
2https://openai.com/blog/chatgpt-plugins#code-interpreter
5https://open.bigmodel.cn/dev/api#glm-4
ChatGLM3 6B (ChatGLM3 Team, 2023), as well as models with enhancements in mathematics including (5) InternLM2-Math 20B 6 which builds on InternLM2 and underwent math training followed by instruction tuning, (6) Math-Shepherd-Mistral 7B which applys PPO training (Schulman et al., 2017) to Mistral 7B (Jiang et al., 2023) with a process-supervised reward model, (7) the WizardMath series (Luo et al., 2023) which improves mathematical reasoning in Mistral 7B and Llama-2 70B (Touvron et al., 2023) using evolve-instruct (i.e., a version of instruction tuning that uses AI-evolved instructions) and PPO training with training problems primarily sourced from GSM8K and MATH, (8) MetaMath 70B (Yu et al., 2023) which is Llama-2 70B fine-tuned on an augmented version of GSM8K and MATH, (9) ToRA 34B Gou et al. (2023) which is CodeLlama 34B fine-tuned to do tool-integrated mathematical reasoning, (10) MAmmoTH 70B (Yue et al., 2023) which is Llama-2 70B instruction-tuned on MathInstruct.
ChatGLM3 6B NT0(ChatGLM3 团队,2023),以及在数学方面有所增强的模型,包括 (5) InternLM2-Math 20B 6,它基于 InternLM2 构建,并经过数学训练和指令调整,(6) Math-Shepherd-Mistral 7B,它将 PPO 训练(Schulman 等人,2017)应用于 Mistral 7B(Jiang 等人,2023),并采用过程监督奖励模型,(7) WizardMath 系列(Luo 等人,2023),它使用 evolve-instruct(即,使用 AI 进化的指令的指令调整版本)和 PPO 训练来改进 Mistral 7B 和 Llama-2 70B(Touvron 等人,2023)中的数学推理,训练问题主要来自 GSM8K 和 MATH,(8) MetaMath 70B(Yu 等人,2023),它是 Llama-2 70B 在 GSM8K 和 MATH 的增强版本上进行微调的模型,(9) ToRA 34B Gou 等人 (2023),它是 CodeLlama 34B 经过微调以进行工具集成数学推理的模型,(10) MAmmoTH 70B(Yue 等人,2023),它是 Llama-2 70B 在 MathInstruct 上进行指令调整的模型。
As shown in Table 5, under the evaluation setting where tool use is disallowed, DeepSeekMathInstruct 7B demonstrates strong performance of step-by-step reasoning. Notably, on the competition-level MATH dataset, our model surpasses all open-source models and the majority of proprietary models (e.g., Inflection-2 and Gemini Pro) by at least 9% absolute.
如表5所示,在禁止使用工具的评估设置下,DeepSeekMathInstruct 7B 在逐步推理方面表现出色。值得注意的是,在竞赛级别的MATH数据集上,我们的模型在至少9%的绝对值上超越了所有开源模型以及大多数专有模型(例如,Inflection-2和Gemini Pro)。
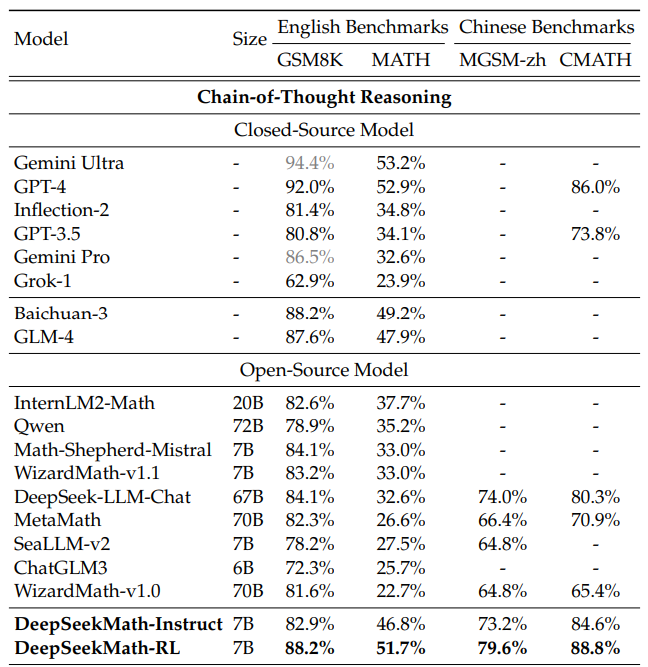
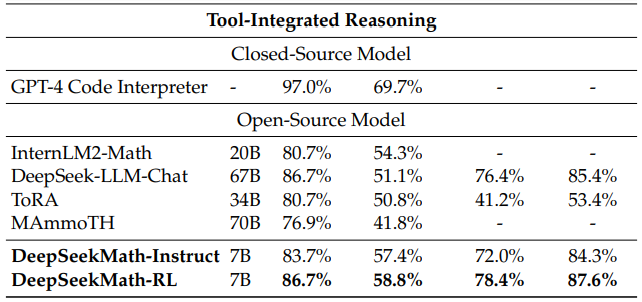
Table 5 | Performance of Open- and Closed-Source models with both Chain-of-Thought and Tool-Integrated Reasoning on English and Chinese Benchmarks. Scores in gray denote majority votes with 32 candidates; The others are Top1 scores. DeepSeekMath-RL 7B beats all open-source models from 7B to 70B, as well as the majority of closed-source models. Although DeepSeekMath-RL 7B is only further trained on chain-of-thought-format instruction tuning data of GSM8K and MATH, it improves over DeepSeekMath-Instruct 7B on all benchmarks.
表5 开源与闭源模型在英文和中文基准测试上的性能表现,测试方式同时包含思维链(Chain-of-Thought)和工具集成推理(Tool-Integrated Reasoning)。灰色分数表示使用32个候选结果进行多数投票(majority vote)的得分;其余分数为Top1得分(即单次输出的准确率)。DeepSeekMath-RL 7B 击败了所有参数规模从7B到70B的开源模型,以及大多数闭源模型。尽管 DeepSeekMath-RL 7B 仅使用 GSM8K 和 MATH 的思维链格式指令微调数据进行了进一步训练,但它在所有基准测试上均优于 DeepSeekMath-Instruct 7B。
This is true even for models that are substantially larger (e.g., Qwen 72B) or have been specifically enhanced through math-focused reinforcement learning (e.g., WizardMath-v1.1 7B). While DeepSeekMath-Instruct rivals the Chinese proprietary models GLM-4 and Baichuan-3 on MATH, it still underperforms GPT-4 and Gemini Ultra.
即使对于模型规模大得多(例如 Qwen 72B)或通过以数学为中心的强化学习(例如 WizardMath-v1.1 7B)进行了专门增强的模型,这也是成立的。尽管 DeepSeekMath-Instruct 在 MATH 基准测试上可以与中国的专有模型 GLM-4 和 Baichuan-3 相媲美,但其性能仍逊于 GPT-4 和 Gemini Ultra。
Under the evaluation setting where models are allowed to integrate natural language reasoning and program-based tool use for problem solving, DeepSeekMath-Instruct 7B approaches an accuracy of 60% on MATH, surpassing all existing open-source models. On the other benchmarks, our model is competitive with DeepSeek-LLM-Chat 67B, the prior state-of-the-art that is 10 times larger.
在允许模型整合自然语言推理和基于程序的工具使用进行问题求解的评估设置下,DeepSeekMath-Instruct 7B 在 MATH 数据集上达到了 60% 的准确率,超越了所有现有的开源模型。在其他基准测试中,我们的模型与之前的最先进模型 DeepSeek-LLM-Chat 67B 具有竞争力,而后者规模是我们的 10 倍。
问题1:总结一下
3.1 SFT 数据整理
- 数据规模 :共 776K 条训练样本
- 覆盖范围:英语和中文,涵盖不同数学领域(代数、概率、数论、微积分、几何等)和不同难度级别
- 三种推理格式 :
- CoT(思维链):逐步文字推导
- PoT(程序思维):用代码解决问题
- 工具集成推理:结合自然语言和外部工具(如 Python)
- 英文数据来源:GSM8K、MATH(带工具集成标注)、MathInstruct 子集、Lila-OOD
- 中文数据来源:K-12 数学问题,覆盖 76 个子主题(如线性方程)
3.2 DeepSeekMath-Instruct 7B 的训练与评估
训练设置
- 基于 DeepSeekMath-Base 7B 继续训练
- 样本随机拼接至 4K tokens 上下文
- 训练 500 步,batch size 256,学习率 5e-5
评估结果
| 测试设置 | 核心结论 |
|---|---|
| 禁用工具(纯 CoT 推理) | • MATH 竞赛级基准上超越所有开源模型 (7B~70B)和大多数闭源模型 (如 Gemini Pro、Inflection-2),领先幅度 ≥ 9% • 与国产闭源 GLM-4、Baichuan-3 相当,但仍略低于 GPT-4 和 Gemini Ultra |
| 允许工具使用(CoT + Python) | • MATH 准确率接近 60% ,再次超越所有开源模型 • 其他基准与 DeepSeek-LLM-Chat 67B(参数量大 10 倍)表现相当 |
关键亮点:一个仅 7B 参数的模型,通过高质量的数学预训练 + 多格式指令微调,在无工具推理场景下击败了参数量大 10 倍甚至数十倍的通用模型,以及专门做过数学强化学习的模型(如 WizardMath)。
问题2:多格式指令微调?
多格式指令微调 指的就是这个SFT监督微调吗?具体是怎么做的?
是的,"多格式指令微调"指的就是这里的 SFT(Supervised Fine-Tuning,监督微调)阶段。具体来说,就是在 SFT 阶段,训练数据中的"答案"部分不是单一格式,而是混合了三种不同的推理格式,让模型学会根据问题类型或提示要求,用不同方式输出解题过程。
三种格式具体是什么?
论文中明确提到的三种格式:
| 格式 | 全称 | 输出形式 | 适用场景 |
|---|---|---|---|
| CoT | Chain-of-Thought | 纯自然语言,逐步推导 | 不需要复杂计算,靠逻辑推理即可 |
| PoT | Program-of-Thought | 写 Python 代码来解题 | 需要精确计算、方程求解、迭代等 |
| Tool-Integrated | Tool-Integrated Reasoning | 自然语言 + 代码/工具调用交替 | 需要结合推理和外部工具(如计算器、Python) |
示例对比(解一道数学题):
-
CoT 格式:
设 x 为苹果的数量... 根据题意列出方程... 解得 x = 12... 所以答案是 12。
-
PoT 格式:
pythonapples = 24 oranges = apples / 2 total = apples + oranges print(total) -
Tool-Integrated 格式:
首先我们需要计算橙子的数量,调用 Python 执行
24 / 2 = 12,然后计算总数24 + 12 = 36。所以答案是 36。
SFT 阶段具体怎么做的?
1. 数据来源与格式分配
论文把不同来源的数据预先标注成不同格式,然后混合在一起:
- GSM8K 和 MATH :标注了 Tool-Integrated 格式(即带工具调用的解法)
- MathInstruct 子集 + Lila-OOD :包含 CoT 或 PoT 解法
- 中文 K-12 数据 :同时标注了 CoT 和 Tool-Integrated 两种格式
总共 776K 条样本。
2. 训练方式
论文 3.2 节的描述非常简洁:
Training examples are randomly concatenated until reaching a maximum context length of 4K tokens. We train the model for 500 steps with a batch size of 256 and a constant learning rate of 5e-5.
具体解读:
- 随机拼接:把多条样本(可能是 CoT、可能是 PoT、可能是 Tool-Integrated)随机组合,拼满 4K tokens 作为一个训练序列
- 统一训练:模型不区分格式类型,统一做 next-token prediction。它看到 CoT 样本就学习写文字推导,看到 PoT 样本就学习写代码,看到 Tool-Integrated 就学习交替使用文字和工具
- 训练量很小:只有 500 步 × 256 batch = 约 128K 个训练样本(远小于 776K,说明可能只遍历了部分数据,或者 776K 是拼接前的数量)
3. 为什么叫"多格式"?
关键就在于这 776K 条数据不是同一种"答案风格"。模型在 SFT 阶段同时学会了:
- 像人一样逐步思考(CoT)
- 像程序员一样写代码解题(PoT)
- 像使用工具一样,在推理过程中调用 Python(Tool-Integrated)
这使得模型在后续评估时,可以根据提示词选择不同模式:
- 提示"逐步解释" → 输出 CoT
- 提示"写 Python 解决" → 输出 PoT
- 提示"你可以使用工具" → 输出 Tool-Integrated
补充:SFT 和 RL 阶段的格式差异
值得注意的是,论文后面提到:
Although DeepSeekMath-RL 7B is only further trained on chain-of-thought-format instruction tuning data of GSM8K and MATH...
这说明:
- SFT 阶段 :用了 三种格式混合 的数据(CoT + PoT + Tool-Integrated)
- RL 阶段(GRPO) :只用了 CoT 格式 的 GSM8K 和 MATH 数据
也就是说,"多格式"是 SFT 阶段特有的设计,RL 阶段为了简化只保留了纯文字推理(CoT)进行强化学习。
问题3:更直观的解释
好,我用最直观的方式给你拆解。想象你正在训练一个学生解题,但这个学生要同时学会 三种不同的"答题风格"。
一、三种格式长什么样?(看具体数据)
假设题目是:
小明有 24 个苹果,橙子是苹果的一半,一共有多少个水果?
格式 1:CoT(思维链)------ 像写小作文
训练样本:
[问题] 小明有 24 个苹果,橙子是苹果的一半,一共有多少个水果?
[要求] 请逐步推理
[答案] 已知苹果有 24 个。
橙子是苹果的一半,所以橙子有 24 ÷ 2 = 12 个。
水果总数 = 苹果 + 橙子 = 24 + 12 = 36 个。
因此,答案是 36。模型学到的是:看到"逐步推理",就输出一段纯文字推导。
格式 2:PoT(程序思维)------ 像写代码
训练样本:
[问题] 小明有 24 个苹果,橙子是苹果的一半,一共有多少个水果?
[要求] 请写 Python 程序解决
[答案] ```python
apples = 24
oranges = apples // 2
total = apples + oranges
print(total)
# 输出:36模型学到的是:看到"写 Python",就输出一段可执行代码。
格式 3:Tool-Integrated(工具集成)------ 像边想边查计算器
训练样本:
[问题] 小明有 24 个苹果,橙子是苹果的一半,一共有多少个水果?
[要求] 你可以使用 Python 工具辅助计算
[答案] 首先,苹果数量是 24 个。
我需要计算橙子数量,调用 Python 执行 24 / 2 = 12。
然后计算总数,调用 Python 执行 24 + 12 = 36。
所以一共有 36 个水果。模型学到的是:看到"可以使用工具",就在文字推理中穿插代码调用。
二、SFT 训练时到底在干什么?
论文说把 776K 条这样的样本混合在一起,然后:
样本 1:一道 CoT 数学题(纯文字推导)
样本 2:一道 PoT 数学题(写代码)
样本 3:一道 Tool-Integrated 数学题(文字+代码)
样本 4:又是一道 CoT 题
样本 5:又是一道 PoT 题
...打乱顺序,随机拼接成每段 4K tokens 的长文本,然后让模型做**"预测下一个词"**的训练。
你可以想象成给学生发了一本 "混合练习题册":
- 第 1 题:用文字写步骤
- 第 2 题:写 Python 代码
- 第 3 题:边想边用计算器
- 第 4 题:又是文字步骤
- ...
学生(模型)做多了就发现规律:"哦,原来题目开头的'要求'决定了我要用什么格式回答!"
三、模型学完之后的效果
训练完成后,模型变成了一个**"多面手"**。你给它同样的数学题,但换不同的提示词,它就能切换模式:
| 你问它 | 它回答 |
|---|---|
| "请逐步推理" | 输出纯文字步骤(CoT 模式) |
| "请写 Python 解决" | 输出代码(PoT 模式) |
| "你可以使用 Python 工具" | 输出文字+代码混合(Tool 模式) |
关键就在于:模型在 SFT 阶段同时见过这三种"标准答案",所以学会了"看提示词选格式"。
四、为什么叫"多格式"?为什么这样混合有效?
如果不混合,只训练 CoT:
- 模型只会写小作文,你让它写代码,它可能乱写文字。
如果只训练 PoT:
- 模型只会写代码,你让它解释思路,它可能给你输出一段 Python。
混合训练的好处就像让厨师同时学中餐、西餐、日料:
- 看到客人点牛排 → 做西餐
- 看到客人点寿司 → 做日料
- 看到客人点炒饭 → 做中餐
模型学会了**"看指令选风格"**,而不是只会一种固定写法。
五、补充:SFT 和 RL 的区别
论文后面提到 RL 阶段(GRPO)只用了 CoT 格式的数据。这意味着:
- SFT 阶段(学基础):三种格式都学,让模型"什么都会"
- RL 阶段(强化提升):只拿 CoT 格式做强化学习,专门打磨"纯文字推理"的能力
就像:
- 先让学生同时学语文、数学、英语(SFT)
- 然后专门找语文老师给他开小灶,只练作文(RL)
这样最终模型在纯文字推理 上被强化到了极致,但因为它 SFT 阶段学过其他格式,所以基础能力还在,只是 RL 阶段没有继续练代码和工具而已。
问题4:拼接成每段 4K tokens 的长文本不会被截断吗
随机拼接成每段 4K tokens 的长文本,然后让模型做**"预测下一个词"**的训练。这样会不会刚好这4K tokens的长文本是被截断的,比如最后是一个不完整的问题。而且为什么RL只练纯文字推理,不继续练代码和工具,是后者比较简单,不用再练了吗?
你这两个问题都问到关键细节了,我逐个解释。
第一个问题:随机拼接会不会截断在问题中间?
实际操作中,通常不会"硬截断"破坏样本。
论文里说的"randomly concatenated"在工程实现上一般有两种做法:
做法 A:打包(Packing)+ 掩码隔离
把多个完整样本用 EOS(结束符) 分隔,然后首尾相接拼进 4K tokens。比如:
[问题1]...[答案1]<EOS>[问题2]...[答案2]<EOS>[问题3]...[答案3]...如果拼到某个样本时刚好快满 4K,那就把这个完整样本放到下一个序列里,而不是从中间砍断。
同时,训练时会用 Attention Mask 或 Position IDs 让模型知道:
"虽然这些文本物理上连在一起,但
<EOS>前面和后面是两个互不相关的题目,前面题目的答案不能影响后面题目的推理。"
做法 B:即使真的截断了,也没那么严重
如果确实因为工程简化,在 4K 边界处把一个样本切成了两半,对 Decoder-only 模型(如 GPT、Llama)来说:
- 模型预训练时本来就见过无数不完整的网页片段(一个网页被切成多段,最后一段没头没尾)。
- 模型会学到:"这段文本到这里突然结束,说明这是一个片段的边界。"
- 只要截断是随机的、不是系统性地总在某个位置截断,模型依然能学到稳定的模式。
但有个更关键的问题:Loss 计算
SFT 训练通常只计算 答案部分 的 Loss,问题部分是不算 Loss 的(或者权重很低)。
如果多个样本硬拼在一起,必须确保模型知道"哪里是问题 A 的答案,哪里是问题 B 的答案",否则 Loss 会算乱。所以工程上一定会用 样本边界标记(如 EOS 或特殊分隔符)来处理,不会真的无脑乱拼。
第二个问题:为什么 RL 只练纯文字(CoT),不继续练代码和工具?
不是因为代码/工具"简单不用练",恰恰相反------是因为 RL 阶段练代码和工具太麻烦了,而且论文想集中火力突破最难的部分。
具体原因有几个:
1. Reward 信号越简单,RL 越稳定
RL 需要一个明确的分数来告诉模型"这个答案好,那个答案坏"。
| 格式 | Reward 怎么算? | 难度 |
|---|---|---|
| CoT(纯文字) | 提取最终数字,跟标准答案比对 → 对就是 1,错就是 0 | 极简 |
| PoT(写代码) | 需要把代码送进 Python 执行器运行 → 捕获输出 → 再比对 | 需要沙箱环境 |
| Tool-Integrated(工具调用) | 需要模拟或真实执行多次工具调用,中间步骤还要判断对错 | pipeline 极复杂 |
GRPO 本身每次要采样 一组(group) 答案(比如 8~16 个候选),如果每个候选都要执行 Python,那训练速度会慢几十倍,而且需要搭建安全的代码执行环境 (防止模型生成 rm -rf / 这种危险代码)。
2. 论文的核心目标是"数学推理",不是"工具使用"
看论文的标题和核心卖点:
"Pushing the Limits of Mathematical Reasoning"
竞赛级数学 benchmark(如 MATH)的最高难度题目 恰恰是纯逻辑推导 ,不是靠写代码暴力计算就能解决的。SFT 阶段已经让模型"学会了用工具",RL 阶段想把有限的算力用在提升思维链质量上------比如怎么更好地分解问题、怎么避免计算错误、怎么检查中间步骤。
换句话说:
- SFT:广撒网,学会三种生存技能(写作文、写代码、用工具)
- RL:集中资源,把最难的"写作文推理"练到顶尖水平
3. 统一范式实验的需要
论文后面用 GRPO 做了一大堆对比实验(在线 vs 离线、结果监督 vs 过程监督、单轮 vs 迭代)。如果同时引入代码和工具,变量太多,很难 cleanly 地证明"是 RL 算法本身带来的提升"。
只保留 CoT 这种最干净的形式,才能让实验结论更 solid。
4. 代码/工具能力在 SFT 后已经够用了
从表 5 的评估结果看,SFT 之后的 DeepSeekMath-Instruct 在"允许使用工具"的设置下已经很强了(MATH 接近 60%)。论文认为这部分能力已经满足需求,而纯 CoT 的 51.7% 还有提升空间,所以 RL 只追这个缺口。
总结成一句话
SFT 阶段是"通识教育",让模型多才多艺;RL 阶段是"高考冲刺",只练最容易出分、最需要突破、且最容易打分的科目(纯文字推理)。