最近成功实现了视频动作迁移到实机机器人身上(效果见最后一节),提取所用的仓库代码是GVHMR,然后开始重新学习单目视频中的人体动作恢复技术,起初我是从 GVHMR 的开源工程入手,希望弄清楚它如何从一段普通视频中恢复出人体在三维空间中的连续运动。但随着阅读过程推进,我发现如果只把 GVHMR 当成一个孤立项目去理解,反而容易忽略它背后的技术脉络。
更准确地说,GVHMR 并不是一个从零开始、端到端解决所有问题的单一模型。它更像是在 HMR2、WHAM、ViTPose、视觉里程计等已有模块和问题范式之上,进一步优化了"世界坐标系人体运动恢复"的表示方式。因此,这篇笔记不打算只讲 GVHMR,而是从几个相关工作之间的关系出发,梳理这条技术路线。
1. 这个方向到底在解决什么问题?
这类工作的目标可以简单理解为:
给定一段普通单目视频,恢复出视频中人的三维姿态、身体形状、连续动作,甚至恢复人在世界坐标系中的运动轨迹。
这里面其实有几个层次的问题。
第一层是"人在哪里"。这通常由目标检测或人体检测模型完成,比如 YOLO 这类模型会在每一帧中找到人体框,也就是 bbox。
第二层是"人的二维骨架是什么样"。这通常由 2D 姿态估计模型完成,比如 ViTPose 会估计肩、肘、腕、髋、膝、踝等 2D 关键点。
第三层是"人的三维身体是什么样"。这就进入 HMR,也就是 Human Mesh Recovery。它希望从图像中恢复出人体的三维姿态、形状和 mesh,常见输出形式是 SMPL 或 SMPL-X 参数。
第四层是"人在视频中如何连续运动"。这就要求模型不仅逐帧估计姿态,还要利用时序信息,让动作更平滑、更一致,减少抖动。
第五层是"人在真实世界坐标中如何运动"。这一步更难,因为视频中的运动既可能来自人体本身,也可能来自相机运动。如果相机在移动,画面中的人发生位移,并不一定意味着人真的在世界中这样移动。因此,world-grounded human motion recovery 需要尽可能恢复重力对齐、世界坐标一致的人体运动。
从这个角度看,HMR2、WHAM、GVHMR 分别处在这条链路的不同位置。
2. HMR2 / 4DHumans:强单帧人体重建与视频跟踪
项目地址:
HMR2 / 4DHumans:https://github.com/shubham-goel/4D-Humans
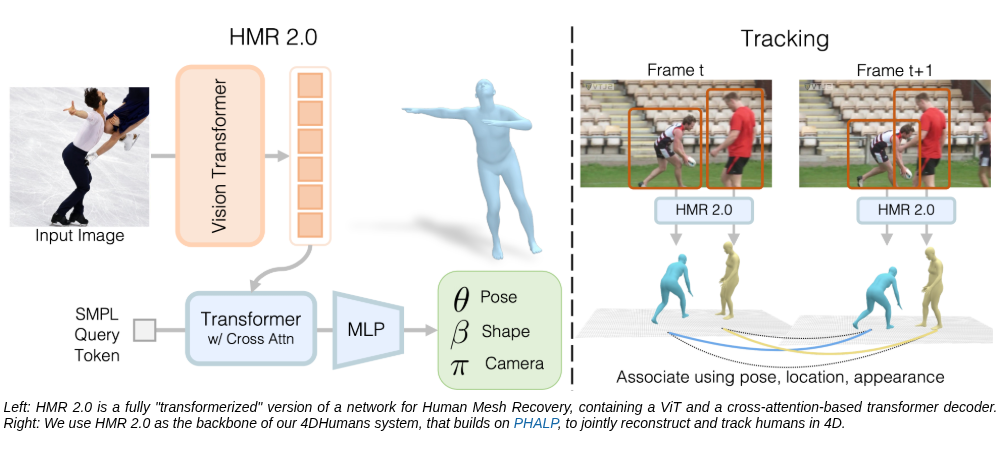
HMR2 的核心定位是 Human Mesh Recovery,也就是从单张图像中恢复人体三维 mesh。相比早期 HMR 方法,HMR2 的一个重要特点是"transformerized",即用 Vision Transformer 和 Transformer Decoder 来完成图像特征提取和 SMPL 参数回归。
简单来说,HMR2 做的是:
text
输入:单张人体图像
输出:SMPL pose、shape、camera 等参数HMR2 的价值在于,它是一个非常强的单帧人体三维重建模型。它可以处理很多异常姿态、复杂视角、部分遮挡等情况。在 4DHumans 中,HMR2 进一步作为基础模块,用于视频中的人体重建和跟踪。
不过,HMR2 本身更偏向 camera-space 的人体恢复。也就是说,它主要告诉我们人在相机视角下是什么姿态、什么形状,而不是直接告诉我们人在真实世界坐标中如何运动。如果只是做单帧重建、视频中人体可视化、或者简单动作分析,HMR2 已经很有价值。但如果要得到稳定的世界坐标运动轨迹,它还不够。
3. WHAM:从视频恢复世界坐标人体运动
项目地址:
WHAM:https://github.com/yohanshin/WHAM
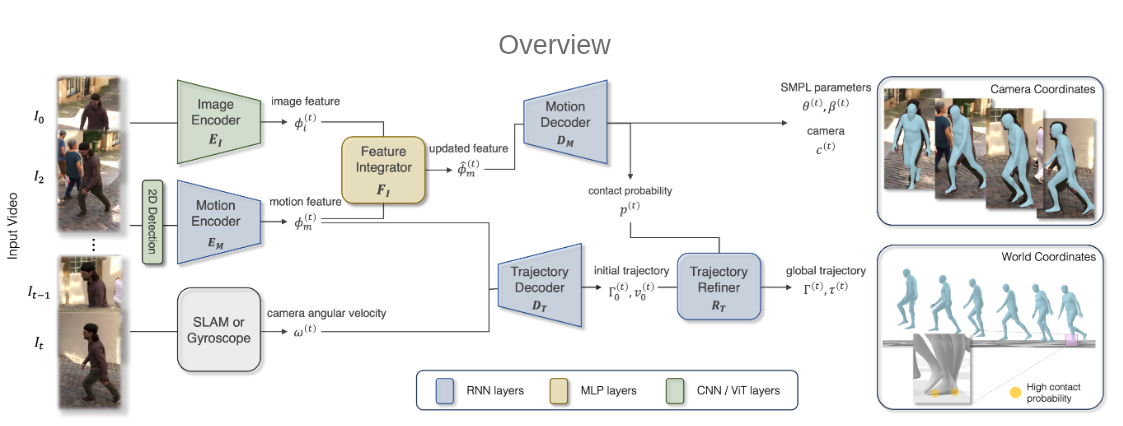
WHAM 的目标相比 HMR2 更进一步。它要从单目视频中恢复 world-grounded human motion,也就是世界坐标系下的人体三维运动。
WHAM 的输入不是单纯 RGB 图像,而是组合式输入:
text
2D keypoints
+ image features
+ camera angular velocity
→ 3D human motion in camera/world coordinates其中 2D keypoints 提供人体骨架随时间变化的信息;image features 提供图像中的密集视觉线索,比如身体朝向、遮挡、轮廓、形状等;camera angular velocity 则用于描述相机自身的旋转运动,帮助模型区分"人真的动了"和"相机在动"。
WHAM 的核心思路可以概括为三点。
第一,用 2D keypoints 序列学习 motion context。它通过大规模人体动作数据学习"二维骨架运动如何对应三维人体运动"。
第二,用图像特征补充关键点的不足。2D keypoints 太稀疏,无法完整表达身体朝向、遮挡关系、体型轮廓等信息,因此 WHAM 使用图像特征与 motion feature 融合。
第三,用相机角速度和脚底接触修正全局轨迹。WHAM 会估计 foot contact probability,并利用脚底接触信息减少 foot sliding,让世界坐标中的人体运动更合理。
因此,WHAM 可以看作是一个重要转折点:它不是只做人体 mesh recovery,而是开始系统性地处理"动态相机 + 世界坐标 + 人体运动"的问题。
4. DPVO:不是人体模型,而是相机运动估计
项目地址:
DPVO:https://github.com/princeton-vl/DPVO
在 WHAM 和 GVHMR 里都会出现 DPVO。初学时很容易把它误认为是人体动作恢复模型的一部分,但实际上它的角色不同。
DPVO 是 Deep Patch Visual Odometry,本质上是视觉里程计,用于估计相机在视频帧之间的相对运动。它关注的是"相机怎么动",而不是"人怎么动"。
可以这样理解:
text
YOLO / ViTPose / HMR2:
处理视频中的人。
DPVO:
处理拍摄视频的相机。如果相机是静态的,那么相邻帧之间的相机运动可以近似为单位变换;如果相机是动态的,则需要 DPVO 或类似 SLAM / VO 方法估计相机相对旋转。对于 world-grounded motion recovery 来说,相机运动信息非常重要,因为视频中的画面变化往往是人体运动和相机运动共同造成的。
不过,DPVO 本身不是 WHAM 或 GVHMR 的创新点。它更像是一个成熟的外部视觉前端模块,为后续人体运动恢复提供相机运动线索。
5. GVHMR:在 WHAM 范式上优化世界坐标表示
项目地址:
GVHMR:https://github.com/zju3dv/GVHMR
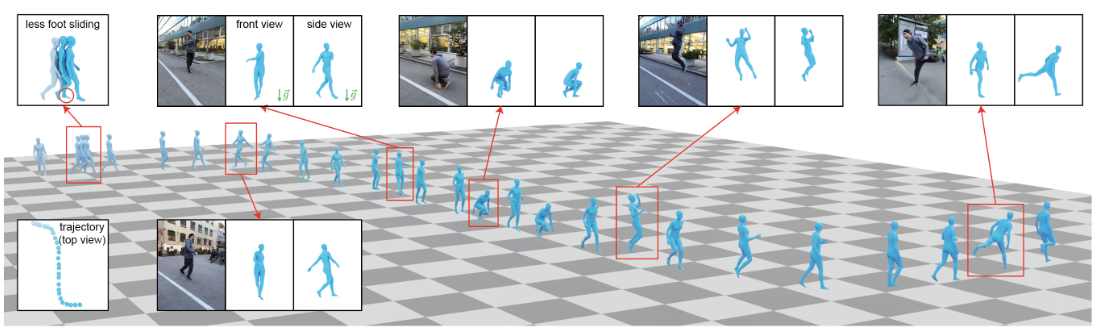
GVHMR 与 WHAM 的关系非常直接。可以认为,WHAM 建立了"2D keypoints + image features + camera motion + contact refinement → world-grounded human motion"的系统范式,而 GVHMR 则在这个范式上进一步思考:
世界坐标系的人体朝向,是否应该直接让网络去学?
GVHMR 认为,直接学习世界坐标下的人体全局朝向存在坐标定义歧义。只要重力方向一致,世界坐标系绕重力轴旋转多少都可以是合法坐标系。这会让网络学习变得不稳定,尤其在长序列中容易出现累积误差。
因此,GVHMR 提出了 Gravity-View 坐标系。这个坐标系由两个信息定义:
text
1. 重力方向;
2. 相机视线方向。在每一帧中,GV 坐标系都天然与重力对齐。模型不再直接预测世界坐标下的人体朝向,而是先预测人体在 GV 坐标系下的朝向,再利用相机相对旋转,把每一帧的 GV 坐标统一到同一个世界坐标系中。
一个更直观的例子
可以用一个生活中的例子来理解 GVHMR 的改进。
假设你在用手机拍一个人在操场上跑步:
- 如果你一边走一边拍,那么视频里的人既在动,你的相机也在动;
- 如果直接让模型去"猜这个人在世界坐标里朝哪个方向跑",就会很混乱,因为画面变化混合了两种运动。
WHAM 的做法类似于:
一边看人的动作,一边估计相机怎么转,然后一步步推算出人在世界里的轨迹。
而 GVHMR 的思路更像是:
先把每一帧都"摆正"------让画面里的重力方向始终朝下(就像你把手机画面自动旋转到正方向),再在这个统一的参考系里判断人朝哪走。
也就是说:
- 不直接在"乱动的世界坐标"里学习;
- 而是先建立一个"每一帧都对齐重力的局部坐标系"(GV坐标系);
- 再把这些局部结果拼回统一世界坐标。
这样做的好处是:
- 模型更容易学(因为坐标更稳定);
- 长视频不容易漂(减少累计误差);
- 人的朝向不会莫名其妙慢慢旋转。
从直观上讲:
text
WHAM:
递归预测 global orientation 和 root velocity,
逐帧往后 roll out,
长序列可能累积误差。
GVHMR:
每帧先在 Gravity-View 坐标系下预测人体朝向,
再通过相机相对旋转恢复统一世界坐标,
减少重力方向和全局朝向上的累积漂移。因此,GVHMR 的创新不是替换 YOLO、ViTPose、HMR2 或 DPVO,而是重新设计了世界系人体运动恢复中的坐标表示和时序建模方式。
6. 这些模块哪些是成熟组件,哪些是核心创新?
从工程角度看,这类系统通常是组合式流水线,而不是一个模型从 RGB 视频直接端到端输出最终结果。一个典型流程可以抽象为:
text
输入视频
↓
人体检测与跟踪:找到人在哪里
↓
2D 姿态估计:得到人体关键点
↓
图像特征提取:得到高维视觉语义特征
↓
相机运动估计:估计相机相对旋转或角速度
↓
时序人体运动恢复网络:融合多种特征
↓
SMPL / SMPL-X 参数恢复
↓
相机系与世界系人体运动输出
↓
可视化与后处理其中,人体检测、2D 姿态估计、图像特征提取、相机运动估计,很多都可以使用成熟开源模型或已有预训练模型。这些模块很重要,但通常不是论文的核心创新。
真正的论文创新往往发生在几个地方:
第一,如何融合这些输入特征。比如 WHAM 中 motion feature 与 image feature 的融合。
第二,如何表示全局轨迹。比如 WHAM 的 trajectory decoder 和 contact-aware trajectory refinement。
第三,如何定义坐标系。比如 GVHMR 的 Gravity-View 坐标系。
第四,如何处理长序列。比如 GVHMR 使用相对 Transformer 和 RoPE,避免传统滑动窗口或自回归方式带来的长序列问题。
第五,如何减少物理不自然现象。比如 foot sliding、身体漂浮、轨迹抖动、重力方向不一致等。
7. 静态相机下,这些方法还有必要吗?
如果相机完全静止,那么 WHAM 和 GVHMR 中关于"相机运动解耦"的价值会下降。因为此时画面变化主要来自人体运动,而不是相机运动。
在这种情况下,如果只是想从固定机位视频中提取大致动作,早期的 HMR、视频 HMR、或者 HMR2 加简单时序处理,可能已经能满足一些需求。
但这并不意味着 WHAM 和 GVHMR 在静态相机下没有价值。因为即使相机静止,仍然存在几个问题:
text
1. 单帧估计容易抖动;
2. 三维深度和尺度仍有歧义;
3. root trajectory 仍然需要合理恢复;
4. 脚底接触和 foot sliding 仍然需要处理;
5. 人体运动最好仍然保持重力对齐;
6. 长序列动作仍然需要时序一致性。所以更准确的理解是:
text
静态相机:
普通方法可能够用;
WHAM/GVHMR 的必要性下降,但高质量时序和世界系输出仍有价值。
动态相机:
WHAM/GVHMR 的价值显著上升;
因为它们专门处理人体运动和相机运动耦合的问题。8. WHAM 和 GVHMR 的输入输出其实很接近
从使用者视角看,WHAM 和 GVHMR 的输入输出确实高度相似。
它们都大致是:
text
输入:
单目视频
人体 bbox
2D keypoints
image features
camera motion / camera rotation
输出:
camera-space human motion
world-grounded human motion
SMPL 或 SMPL-X pose / shape
root orientation / root translation
contact 或 stationary 信息区别不在于"输入输出完全不同",而在于中间如何建模。
WHAM 更像是:
text
2D motion context + image feature + camera angular velocity
→ RNN 递归预测 global trajectory
→ foot contact refinementGVHMR 更像是:
text
bbox + 2D keypoints + image feature + camera relative rotation
→ Relative Transformer
→ Gravity-View orientation
→ world-grounded trajectory recovery
→ stationary / IK post-processing因此,GVHMR 更像是对 WHAM 的世界坐标表示方式和长序列处理方式的进一步优化,而不是完全不同的问题定义。
9. 我的阶段性理解
这次学习后,我对这类工作的理解可以总结为几句话。
第一,单目人体动作恢复不是一个单模型问题,而是一个组合式系统问题。检测、关键点、图像特征、相机运动、人体参数模型、时序网络、接触后处理,每个模块都影响最终质量。
第二,HMR2 代表的是强单帧人体 mesh recovery 能力。它解决的是"单张图里的人是什么三维姿态"。
第三,WHAM 代表的是从 camera-space 走向 world-grounded 的关键一步。它把 2D keypoints、图像特征、相机角速度、脚底接触结合起来,尝试恢复世界坐标中的人体运动。
第四,GVHMR 的核心价值在于 Gravity-View 坐标系。它没有推翻 WHAM 的整体范式,而是在"全局运动如何表示"这个关键点上做了更稳定的设计。
第五,成熟开源组件和论文独门创新要分开看。YOLO、ViTPose、HMR2、DPVO 这类模块是强大的前端能力;WHAM 和 GVHMR 的研究贡献更多体现在时序建模、轨迹恢复、坐标表示和物理合理性约束上。
第六,如果只是固定机位下粗略提取动作,早期方法或者 HMR2 可能已经能满足部分需求;但如果希望得到更稳定、更自然、更接近世界坐标的人体运动,尤其是动态相机视频,那么 WHAM 和 GVHMR 这类方法就更有研究价值。
10. 结语
最开始我只是想运行 GVHMR,并理解它的输出。但真正梳理后发现,GVHMR 背后串起的是一条完整技术脉络:
text
2D人体检测与关键点
→ 单帧三维人体重建
→ 视频时序人体恢复
→ 动态相机下的世界坐标运动恢复
→ 重力对齐与长序列稳定性优化如果只看最终仓库,很容易把这些模块混在一起。但从论文脉络看,每个模块都有自己的角色:有些是成熟工具,有些是基础模型,有些是系统集成,有些才是核心创新。
这也是我觉得这类视觉系统值得学习的地方:真正有效的系统往往不是单点突破,而是在成熟模块之上,找到一个关键表示、关键约束或关键接口,让整条流水线的结果变得更稳定、更可信。
11. 以 GVHMR 为例:从自拍视频中提取机器人可用的人体动作
前面更多是在梳理 HMR2、WHAM、GVHMR 之间的技术脉络。接下来回到我的实际目标:能不能把自己拍摄的一段真人动作视频,转换成后续人形机器人动作重定向和模仿跟踪学习可以使用的数据。
这里我就以 GVHMR 为例,完整走了一遍从自拍视频到人体动作数据的提取流程。选择 GVHMR 的原因也很直接:它恢复的不只是相机视角下"看起来贴合图像"的人体 mesh,而是更强调重力方向一致、带全局轨迹的 world-grounded human motion。对于人形机器人来说,重力方向、root trajectory、身体朝向和脚底接触关系都会影响后续训练效果。如果这些信息本身不稳定,后面的 retargeting 和 policy learning 会非常难调。
工程流程概览
GVHMR 的 demo pipeline 可以理解成一条"视频到人体运动参数"的流水线。它并不是一个单独的大模型直接吃原始视频,而是先把视频拆解成多个中间观测,再由 GVHMR 的时序网络恢复动作。
整体流程如下:
text
输入视频
-> 视频重编码与统一读取
-> YOLOv8 人体检测与跟踪
-> ViTPose 2D 关键点检测
-> HMR2 / 4D-Humans 图像特征提取
-> SimpleVO / DPVO 相机旋转估计
-> GVHMR 时序网络预测
-> SMPL-X / SMPL 人体模型解析
-> 相机系结果与世界系结果可视化
-> 导出后续机器人训练使用的数据其中每一步的作用都比较明确:
- YOLOv8 负责找到并持续跟踪视频中的人;
- ViTPose 负责提取 2D 骨架关键点;
- HMR2 提供更高层的图像人体特征;
- SimpleVO 或 DPVO 提供相机相对旋转信息;
- GVHMR 主网络根据这些信息恢复相机系和世界系人体动作;
- SMPL-X / SMPL 模型负责把网络输出的姿态参数转换成可视化 mesh 和关节轨迹。
如果视频是固定机位拍摄,可以直接使用静态相机选项:
bash
python tools/demo/demo.py --video=docs/example_video/record_test_fixed.mp4 -s这里的 -s 表示跳过视觉里程计,把相机看作静止。对于我们自己采集机器人训练数据来说,这通常是更稳妥的方式。固定机位可以减少相机运动估计误差,让恢复出来的全局人体轨迹更稳定。
自己拍摄视频时遇到的一个细节
在实际使用中,我先录制了一段真人舞蹈动作视频,然后用 GVHMR 进行动作提取。这里遇到过一个很典型的问题:手机拍摄的视频在播放器里看起来是竖屏正常方向,但进入 GVHMR 后,输出的 0_input_video.mp4 却旋转了 90 度,最后世界系人体也横在地面上。
原因是很多手机视频并不会真的把像素存成竖屏,而是把真实帧存成横屏,再通过视频 metadata 里的 rotate=90 告诉播放器"播放时旋转显示"。GVHMR demo 在内部会逐帧读取并重新编码视频,如果这一步没有正确处理旋转 metadata,后续所有模型看到的就是横着的人。
解决办法是先用 ffmpeg 把旋转信息烘焙进真实像素,再输入 GVHMR:
bash
ffmpeg -y -noautorotate -i docs/example_video/record_test.mp4 \
-vf "transpose=clock" \
-metadata:s:v:0 rotate=0 \
-c:v libx264 -crf 18 -preset medium -pix_fmt yuv420p \
-c:a copy docs/example_video/record_test_fixed.mp4处理后再运行 GVHMR,输出的世界系动作方向就正常了。这个细节也提醒我们:从视频到机器人动作,中间任何一个坐标系处理错误,都会在最终动作中被放大。
GVHMR 的输出结果
跑通 demo 后,工程会在 outputs/demo/<video_name>/ 下生成若干结果文件。比较关键的是:
text
outputs/demo/record_test_fixed/
├── 0_input_video.mp4
├── 1_incam.mp4
├── 2_global.mp4
├── record_test_fixed_3_incam_global_horiz.mp4
└── hmr4d_results.pt 或自定义导出的动作数据 .pt其中:
1_incam.mp4是相机系可视化结果,可以看人体 mesh 是否贴合原视频;2_global.mp4是世界系结果,可以看人体是否站在合理的地面上运动;*_3_incam_global_horiz.mp4是左右拼接视频,方便同时检查相机系和世界系效果;.pt文件中保存了后续处理需要的人体姿态、形状和轨迹参数。
对机器人学习而言,最重要的不是渲染视频本身,而是其中的世界系人体动作数据。GVHMR 输出的 smpl_params_global 可以进一步解析出根节点轨迹、身体朝向、关节姿态和脚部接触相关信息,这些都是动作重定向的重要输入。
下图是我们自行录制然后提取数据的结果:

从人体动作到机器人动作
完成 GVHMR 的动作提取后,接下来就进入我们之前文章中提到过的机器人动作重定向与模仿跟踪训练流程:
按照后续流程与部署,即得到了如下效果。


所以,让机器人学会视频里的人体动作,整体链路可以概括为:
text
真人舞蹈视频
-> GVHMR 恢复 SMPL-X 世界系人体动作
-> 解析人体 root、关节、足端轨迹
-> 将人体动作重定向到机器人骨架
-> 在仿真中进行模仿跟踪训练
-> 将训练好的策略部署到实机
-> 机器人复现真人舞蹈动作在这个过程中,GVHMR 解决的是第一步:把普通视频变成可计算、可重定向的人体动作表示。后续还需要处理人体和机器人结构差异,例如腿长、关节自由度、关节限位、足端接触、质心稳定性等问题。这些问题不能只靠视觉恢复解决,需要在 retargeting 和强化学习训练中继续约束。
从最终效果来看,这条路线是可行的,让动作数据不再强依赖复杂的遥操采集,而是可能能从海里的互联网数据中去学习。我们已经完成了从自己拍摄的视频中提取人体动作,再经过机器人数据重定向和模仿跟踪训练,最终部署到实机的完整流程。机器人也成功还原了视频中的舞蹈动作。