一、Oplog 概述
1.什么是 Oplog?
Oplog(operations log,操作日志)是 MongoDB 中一个特殊的定容集合(capped collection) 。它记录了对数据库中数据发起的所有修改操作------包括插入、更新、删除以及 DDL 命令。每个副本集成员都在 local.oplog.rs 集合中保存一份自己的 oplog 副本。
Oplog 与普通定容集合有一个关键区别:它可以超过配置的大小限制,以避免删除多数提交点(majority commit point)。这一设计保证了数据的一致性和可恢复性。
2.Oplog 的核心作用
| 作用 | 说明 |
|---|---|
| 复制 | Secondary 节点通过拉取并重放 Primary 的 oplog 条目,实现与 Primary 的数据同步 |
| 故障恢复 | 当节点故障重启后,可通过 oplog 追赶落后的操作 |
| 点时间恢复 | 结合全量备份与 oplog,可恢复至任意时间点 |
| 延迟节点 | 支持配置延迟副本集成员,用于误操作恢复等场景 |
3.Oplog 条目的结构
Oplog 中的每条记录都是一个 BSON 文档,主要字段如下:
| 字段 | 说明 |
|---|---|
op |
操作类型:i(插入)、u(更新)、d(删除)、c(DDL 命令)、n(空操作)、db(声明数据库) |
ns |
命名空间,格式为 数据库.集合 |
o |
操作的具体内容(document) |
o2 |
仅更新操作(op: "u")时有此字段,代表更新条件 |
ts |
操作的时间戳,用于判断 oplog 窗口 |
v |
Oplog 版本号 |
幂等性:Oplog 中的每个操作都是幂等的(idempotent)------无论应用一次还是多次,结果相同。这是 Secondary 节点能够安全地重放 oplog 条目的根本保证。
二、Oplog 的工作原理
1.复制流程
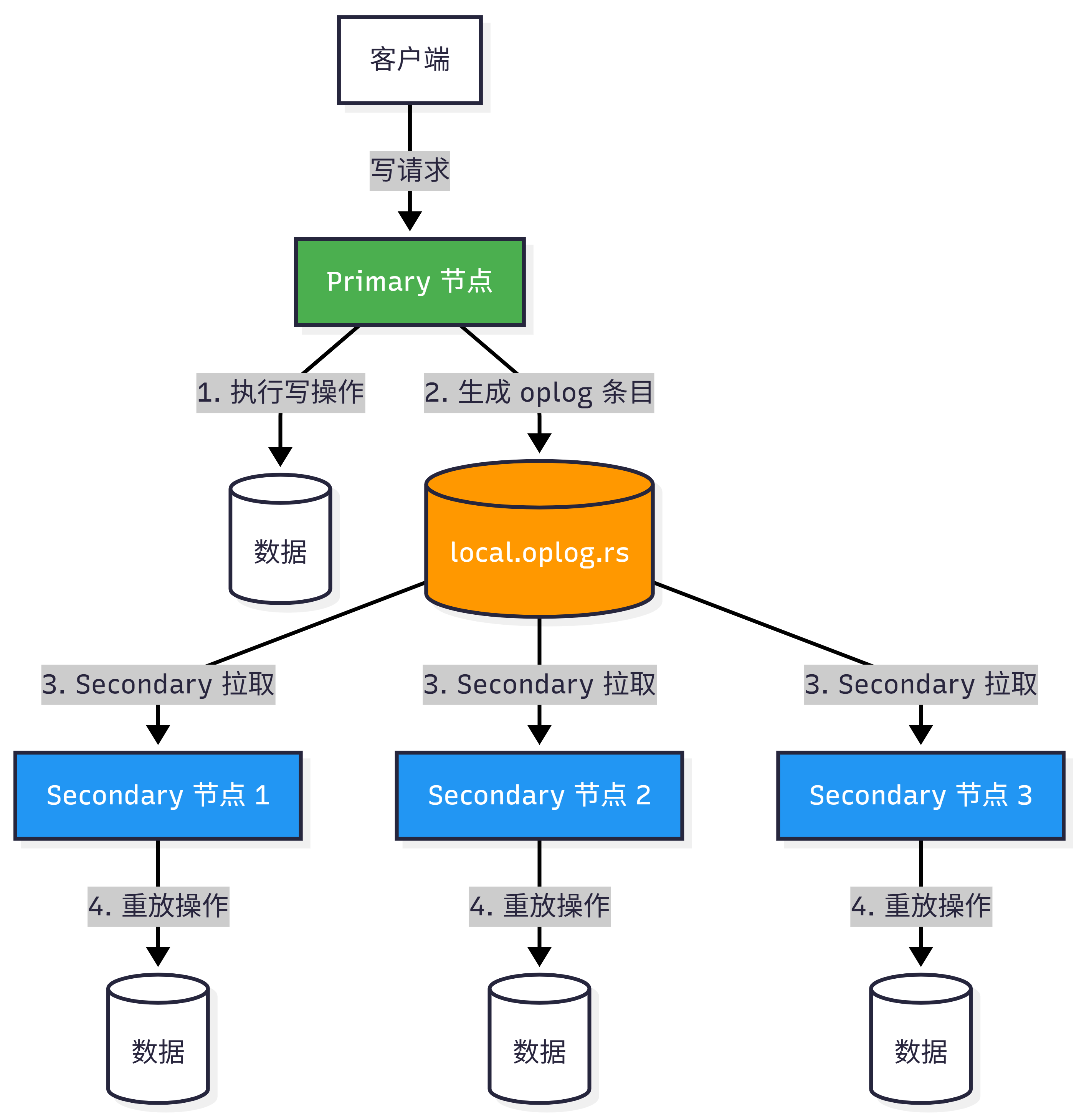
流程说明:
- Primary 节点接收客户端写请求,执行数据修改
- 操作完成后,MongoDB 将操作转换为幂等的 oplog 条目,写入
local.oplog.rs - Secondary 节点通过异步方式从 Primary(或其他有数据的节点)拉取 oplog 条目
- Secondary 节点重放这些操作,保持与 Primary 数据一致
所有副本集成员之间通过心跳(heartbeat)相互通信,任意 Secondary 都可以从任意其他成员导入 oplog 条目。
2.Stale 节点与重新同步
当 Secondary 节点的复制进度严重落后,以至于 Primary 的 oplog 已经覆盖(覆写)了该节点尚未复制的条目时,该节点变为 stale(陈旧) 状态。
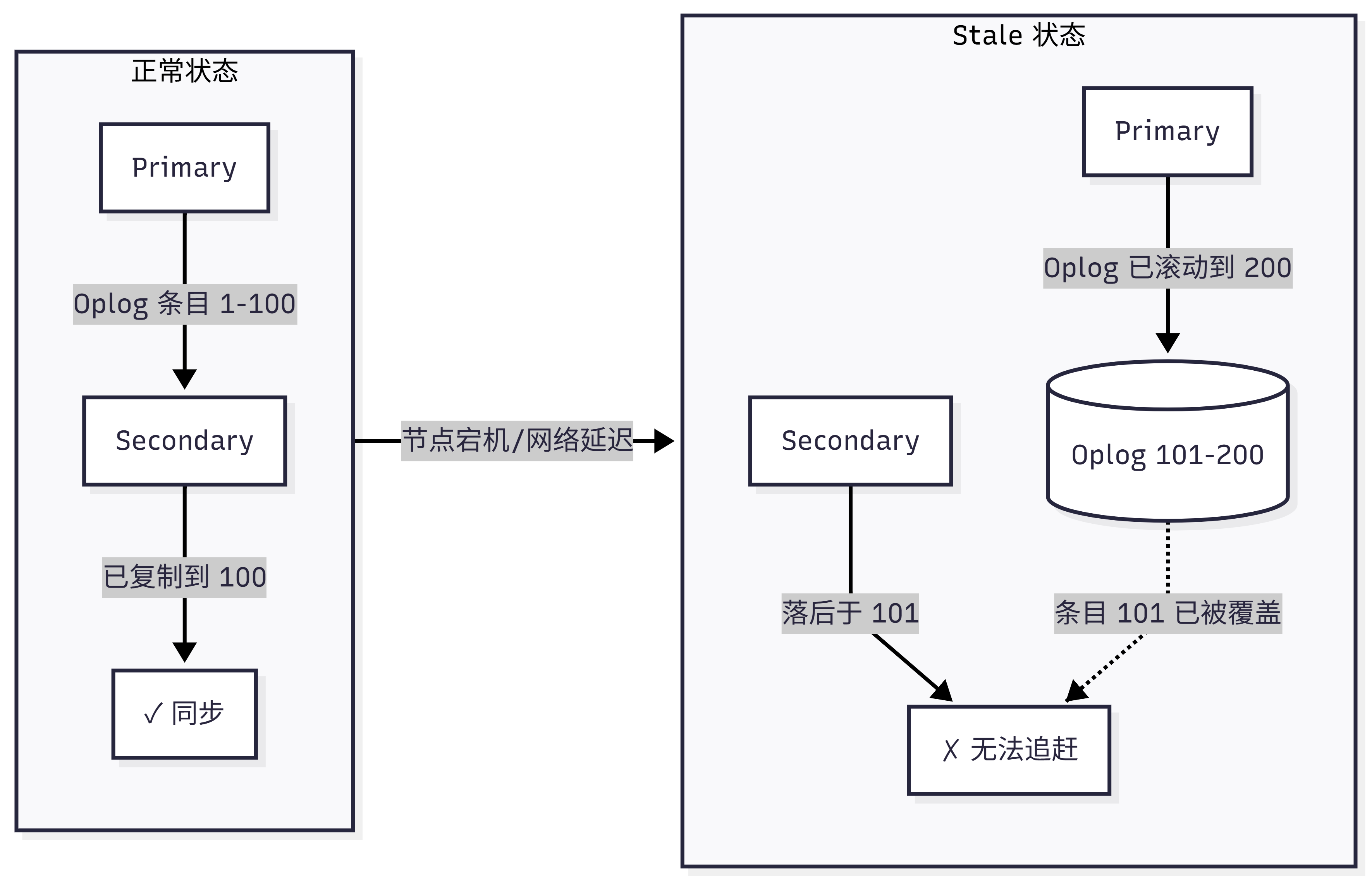
一旦节点变为 stale,唯一的选择是执行完整的重新同步(initial sync) ------删除该节点的数据,从头开始从其他成员同步。这就是为什么 oplog 大小规划如此重要------它直接决定了副本集对故障的容忍能力。
三、Oplog 大小配置
1.默认大小规则
当首次启动副本集成员且未指定 oplog 大小时,MongoDB 会根据存储引擎和操作系统自动计算默认值:
Unix / Windows 系统:
| 存储引擎 | 默认 Oplog 大小 | 下限 | 上限 |
|---|---|---|---|
| 基于物理内存 | 物理内存的 5% | 990 MB | 50 GB |
| 基于可用磁盘空间 | 可用磁盘空间的 5% | 990 MB | 50 GB |
约束说明:
- 最小默认值:990 MB。如果 5% 的计算值小于 990 MB,则默认取 990 MB
- 最大默认值:50 GB。如果 5% 的计算值大于 50 GB,则默认取 50 GB
50 GB 是「首次启动时未指定大小」情况下的默认上限
64-bit macOS 系统:
| 存储引擎 | 默认 Oplog 大小 |
|---|---|
| 基于物理内存 | 192 MB(物理内存) |
| 基于可用磁盘空间 | 192 MB(可用磁盘空间) |
2.配置方式对比
| 配置方式 | 适用场景 | 是否需要重启 | 命令/参数 |
|---|---|---|---|
oplogSizeMB 启动参数 |
首次部署前规划 | 是(首次启动时生效) | mongod --oplogSizeMB <size> |
replication.oplogSizeMB 配置文件 |
首次部署前规划 | 是(首次启动时生效) | 配置文件中的 replication.oplogSizeMB |
replSetResizeOplog 命令 |
生产环境运行时调整 | 否 | db.adminCommand({replSetResizeOplog:1, size:<MB>}) |
重要提示 :
oplogSizeMB仅在 首次创建 oplog 之前 有效。一旦节点启动并创建了 oplog,此参数将不再生效。运行时调整必须使用replSetResizeOplog命令。
3.运行时调整 Oplog 大小(replSetResizeOplog)
操作步骤:
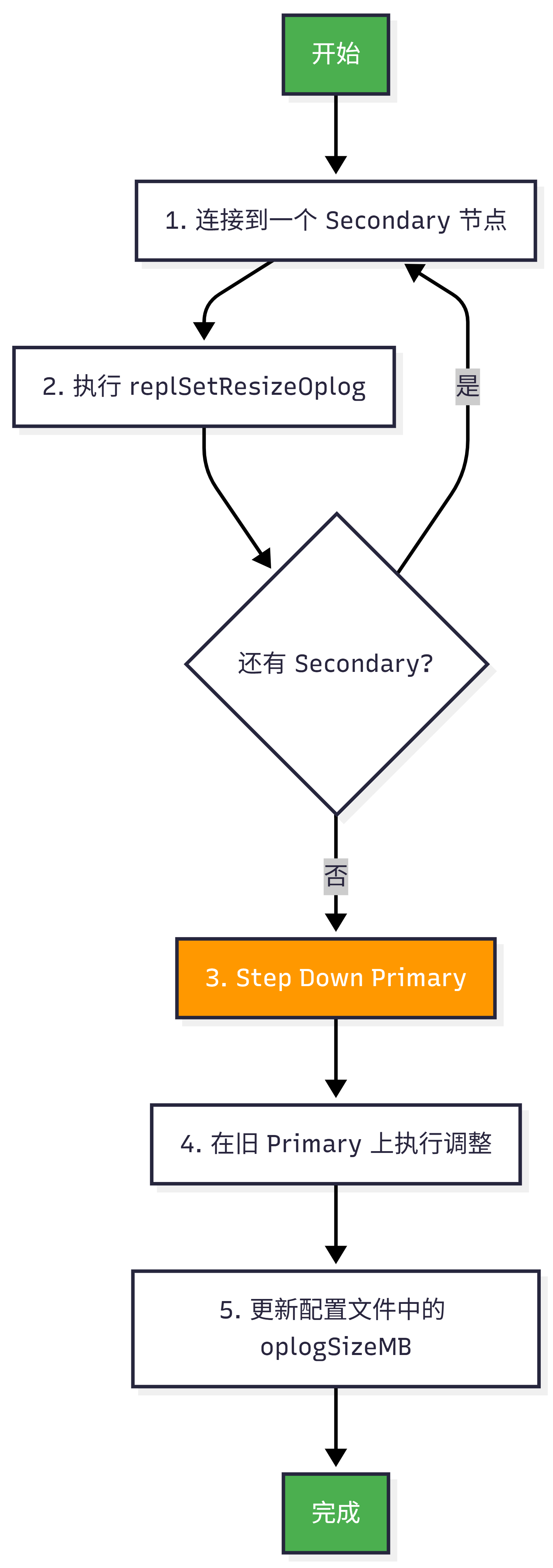
详细命令:
javascript
// 1. 连接到目标节点
mongosh --host <hostname>:<port>
// 2. 查看当前 oplog 大小(字节)
use local
db.oplog.rs.stats().maxSize // 返回字节数
// 3. 调整 oplog 大小(例如设为 16GB = 16000 MB)
// 注意:size 必须 > 990,且需用 Double() 显式转换
use admin
db.adminCommand({
replSetResizeOplog: 1,
size: Double(16000)
})
// 4. 可选:设置最小保留时长(MongoDB 4.4+)
db.adminCommand({
replSetResizeOplog: 1,
size: Double(16000),
minRetentionHours: Double(24) // 至少保留 24 小时
})关键限制:
- 最小值:990 MB
- 最大值:1 PB(1024 TB)
size参数类型必须为double
执行顺序 :先调整所有 Secondary,最后调整 Primary。这是因为调整 oplog 大小会短暂影响复制,先调整 Secondary 可以最小化对业务的影响。
注意 :minRetentionHours 的值是 double 类型,1.5 代表 1.5 小时。
生效条件 :只有当 Oplog 达到最大 size 时,才会根据此设置来删除旧条目。
4.回收磁盘空间
调整 oplog 大小后,MongoDB 不会自动释放已分配的磁盘空间。如需回收,需对 local.oplog.rs 集合执行 compact 命令:
javascript
use local
db.runCommand({ compact: "oplog.rs" })警告 :
compact操作期间,该节点无法同步 oplog 条目。必须在维护窗口执行,并确保集群有足够的冗余。
四、Oplog 大小规划与监控
1.规划原则
核心指标:Oplog Window(oplog 窗口)
Oplog window 是指 oplog 中保存的操作所覆盖的时间范围。如果 oplog 在 24 小时内被写满,则 Secondary 最多可以落后 24 小时而不变为 stale。
推荐值:
| 场景 | 推荐 Oplog Window | 说明 |
|---|---|---|
| 一般生产环境 | 24-48 小时 | 覆盖日常维护窗口 |
| 高写入负载 | 72 小时 | 覆盖周末等长维护窗口 |
| 延迟节点(Delayed Member) | 大于延迟配置值 | 确保延迟节点能追上 |
为什么推荐 72 小时? 这允许一个节点在周末离线进行维护(如操作系统升级、硬件更换)后,仍能通过 oplog 追赶而无需全量重新同步。
2.监控方法
1. 查看复制延迟
javascript
// 在 Primary 上执行
rs.printSecondaryReplicationInfo()输出示例:
source: 192.168.56.101:27027
syncedTo: 'Thu Jun 25 2026 17:23:46 GMT+0800 (中国标准时间)',
replLag: '0 secs (0 hrs) behind the primary '2. 查看 Oplog 窗口
javascript
// 连接任意节点
use local
db.oplog.rs.stats().maxSize // oplog 最大大小(字节)
```javascript
// 生产环境的标准确认命令
rs.printReplicationInfo()
// 执行后会直接输出类似:
configured oplog size: 16000MB
log length start to end: 24hrs (XX天)
oplog first event time: Mon Jun 10 2026 02:29:31 GMT+0000 (UTC)
oplog last event time: Thu Jun 25 2026 09:26:15 GMT+0000 (UTC)
now:
// 查看 oplog 首尾时间戳
db.oplog.rs.find().sort({$natural: -1}).limit(1).pretty() // 最新
[
{
op: 'n',
ns: '',
o: { msg: 'periodic noop' },
ts: Timestamp({ t: 1782379575, i: 1 }),
t: Long('3111'),
v: Long('2'),
wall: ISODate('2026-06-25T09:26:15.172Z')
}
]
db.oplog.rs.find().sort({$natural: 1}).limit(1).pretty() // 最旧
[
{
op: 'n',
ns: '',
o: { msg: 'periodic noop' },
ts: Timestamp({ t: 1780305975, i: 1 }),
t: Long('988'),
v: Long('2'),
wall: ISODate('2026-06-24T09:26:15.172Z')
}
]1. 最直观的计算(推荐):使用 wall 字段
Oplog Window = 最新记录的 wall 时间 - 最旧记录的 wall 时间
- 最新时间 :
2026-06-25T09:26:15.172Z - 最旧时间 :
2026-06-24T09:26:15.172Z
计算结果 :
两者相差约为 24小时。
2. 精确计算(技术笔试常用):使用 ts.t 时间戳
Oplog 中的 ts.t 字段是 Unix 时间戳(秒级),直接用这个数字相减即可得到窗口秒数:
- 最新
ts.t:1782379575 - 最旧
ts.t:1780305975
差值计算:
1782379575 - 1780305975 = 2,073,600 秒
2,073,600 ÷ 86,400(一天秒数) = 24小时3. 关键告警指标:
- Replication Lag(复制延迟):持续增长 → 需关注
- Oplog Window(oplog 窗口):持续缩短 → 需增加 oplog 大小
- Oplog GB/Hour(每小时 oplog 生成量):峰值写入速率
3.常见问题与解决方案
| 问题 | 现象 | 解决方案 |
|---|---|---|
| Oplog 窗口过短 | Secondary 延迟持续增加,告警频繁 | 增加 oplog 大小 |
| 节点变为 Stale | Secondary 无法追上,状态变为 RECOVERING | 全量重新同步 |
| 磁盘空间不足 | Oplog 无法扩容 | 清理数据或扩容磁盘 |
| Compact 阻塞复制 | 节点在 compact 期间无法同步 | 安排在维护窗口,逐个节点执行 |
4.最佳实践清单
- 首次部署时 :根据预估写入负载,在配置文件中合理设置
oplogSizeMB,避免使用默认值 - 生产环境 :将 oplog window 保持在 24-72 小时
- 监控:对 replication lag 和 oplog window 设置告警
- 变更前备份:调整 oplog 大小前,确保有完整备份
- 配置文件同步 :使用
replSetResizeOplog调整后,同步更新配置文件 中的oplogSizeMB,否则节点重启后会恢复为配置值 - Atlas 用户 :通过 Atlas 控制台调整,
replSetResizeOplog命令在 Atlas 中不受支持
五、常见面试题
面试题 1:什么是 Oplog?它在 MongoDB 复制中扮演什么角色?
参考答案:
Oplog(operations log)是 MongoDB 副本集中一个特殊的定容集合(capped collection) ,存储在 local.oplog.rs 中。它记录了 Primary 节点上所有修改数据的操作。
在复制机制中,Primary 在执行写操作后将操作写入 oplog,Secondary 节点通过异步拉取 并重放 这些操作来保持数据同步。Oplog 中的每个操作都是幂等 的,即多次重放结果相同。如果 Secondary 落后太多,Primary 的 oplog 已经覆盖了未同步的条目,该节点就会变为 stale,必须全量重新同步。
面试题 2:MongoDB Oplog 的默认大小是如何确定的?可以修改吗?
参考答案:
默认大小取决于存储引擎和操作系统:
- Unix/Windows :取物理内存或可用磁盘空间的 5% (取决于存储引擎),下限 990 MB ,上限 50 GB
- macOS :固定 192 MB
可以修改,有两种方式:
-
首次启动前 :通过
oplogSizeMB启动参数或配置文件中的replication.oplogSizeMB设置 -
运行时 (无需重启):使用
replSetResizeOplog命令javascriptdb.adminCommand({ replSetResizeOplog: 1, size: Double(16000) })范围:990 MB ~ 1 PB
调整时需先修改所有 Secondary,最后修改 Primary。
面试题 3:如何判断当前 Oplog 大小是否足够?如果不够怎么办?
参考答案:
判断方法:
- 查看复制延迟:
rs.printSecondaryReplicationInfo() - 查看 oplog window(首尾时间差)
- 监控告警:如果 oplog window 持续缩短,说明写入量超过了 oplog 的轮转速度
如果不够:
- 使用
replSetResizeOplog动态增加大小 - 先调整所有 Secondary,最后调整 Primary
- 同步更新配置文件中的
oplogSizeMB - 如需要,对
local.oplog.rs执行compact回收磁盘空间
规划建议 :一般生产环境保持 24-48 小时 的 oplog window,高负载或需要长维护窗口的场景建议 72 小时。
面试题 4:什么是 Stale 节点?如何恢复?
参考答案:
当 Secondary 节点的复制进度严重落后,以至于 Primary 的 oplog 已经覆盖(覆写) 了该节点尚未复制的条目时,该节点变为 stale(陈旧)。
恢复方法 :必须执行完整的重新同步(initial sync):
- 删除该节点的数据目录
- 重启
mongod进程 - 节点自动从其他成员执行初始同步
预防措施:
- 合理规划 oplog 大小,确保足够的 oplog window
- 监控复制延迟,及时告警
- 维护操作(如升级、硬件更换)前确认 oplog window 足够覆盖维护时间
面试题 5:replSetResizeOplog 和 oplogSizeMB 有什么区别?
参考答案:
| 对比维度 | oplogSizeMB |
replSetResizeOplog |
|---|---|---|
| 生效时机 | 首次创建 oplog 前 | 运行时 |
| 是否需要重启 | 是(首次启动时) | 否 |
| 适用范围 | 仅首次部署 | 生产环境动态调整 |
| 配置位置 | 命令行参数或配置文件 | admin 数据库命令 |
| 大小范围 | 无明确限制(受系统资源约束) | 990 MB ~ 1 PB |
关键点 :一旦节点启动并创建了 oplog,
oplogSizeMB就不再生效。运行时调整必须使用replSetResizeOplog。调整后需同步更新配置文件,否则节点重启后会恢复为配置中的旧值。