聊《Java 转大模型开发:把关键流程跑顺》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
最近后台收到不少私信,问得最多的就是:"我是做了五年 Spring Boot 的老手,现在想转大模型应用开发,是不是得重新学 Python?要不要去考个算法工程师证?"
我的回答一直很直接:别折腾,直接用你的 Java 背景。
大模型应用开发(LLM Application Development)目前并不是在训练底层模型,而是在做"应用层"的工程构建。这和传统的 Web 后端逻辑高度重合:数据处理、状态管理、API 集成、高并发处理、权限控制。这些恰恰是 Java 后端的强项。Python 生态虽然丰富,但在企业级稳定性、类型安全和运维成熟度上,Java 依然有着不可替代的优势。
今天不聊虚的,我就从我自己从纯 Java 转型到落地 LLM 项目的经验出发,聊聊怎么把这套流程跑顺,特别是如何把这些东西变成你简历里能拿得出手的作品集。
目录
- Java 开发者的隐性优势
- 需要补齐的 AI 技能树
- Spring AI 与 LangChain4j:选谁?
- 项目练习:打造一个"可展示"的作品集
- 面试准备:从后端视角切入
- 总结
Java 开发者的隐性优势
很多 Java 同学对 AI 有畏难情绪,觉得那是数学家的领域。其实做应用层,你缺的不是数学,而是对"非确定性"系统的工程化处理能力。
在传统后端,输入 A 必然得到输出 B,逻辑是确定的。但在 LLM 场景中,同样的 Prompt 可能每次返回不同的 JSON 结构,或者因为 Token 限制导致截断。这时候,Java 后端的防御性编程思维就是最大的优势。
比如,在处理 LLM 返回的复杂嵌套 JSON 时,传统做法可能直接强转,一旦格式微调就崩盘。而我现在的做法是利用 Jackson 或 Gson 的灵活映射,加上严格的 Schema 校验(如 JSON Schema Validation),甚至引入重试机制和 fallback 策略。这些"脏活累活",才是企业真正愿意买单的地方。
需要补齐的 AI 技能树
不用从头学机器学习理论,你只需要补齐以下三个维度的知识:
-
Prompt Engineering 的结构化思维 :不要只把它当成字符串拼接。要像设计 DTO 一样设计 Prompt,明确 System Role、Context、Input、Output Format。我会习惯性地用模板引擎(如 JMustache 或简单的 String.format)来管理 Prompt 版本,方便 A/B 测试。
-
Vector Database 的基础操作 :你不需要懂向量算法的原理,但必须知道什么是 Embedding,为什么需要向量数据库(Milvus, pgvector, Elasticsearch)。对于 Java 开发者,我强烈建议从
pgvector入手,因为它和你熟悉的 PostgreSQL 无缝集成,运维成本极低。 -
RAG(检索增强生成)的基本范式:这是目前最落地的场景。核心流程是:文档切片 -> 向量化 -> 存储 -> 查询相似度 -> 召回上下文 -> 组装 Prompt -> 生成回答。理解这个数据流向,比写任何代码都重要。

Spring AI 与 LangChain4j:选谁?
这是我最常被问到的问题。市面上有两个主流 Java AI 框架:Spring AI 和 LangChain4j。
- Spring AI:背靠 Spring 家族,生态整合好,配置简单,适合快速原型开发。它的抽象层做得很高,如果你已经深度依赖 Spring Cloud,用它上手最快。
- LangChain4j:更贴近 Python 的 LangChain 概念,灵活性更高,支持更多细粒度的定制,尤其是 Chain 和 Agent 的实现。
我的建议:如果是为了找工作或做内部 Demo,先玩 Spring AI,因为它社区活跃,文档更新快,容易找到现成的 ChatClient 实现。但如果你要做复杂的 Agent 工作流,或者需要对模型调用进行极其精细的控制,LangChain4j 会让你少些痛苦。
这里贴一段我用 Spring AI 实现的简单聊天助手代码,展示如何将上下文注入:
java
@Service
public class DocChatService {
private final ChatClient chatClient;
private final VectorSearch vectorSearch;
public DocChatService(ChatClient chatClient, VectorSearch vectorSearch) {
this.chatClient = chatClient;
this.vectorSearch = vectorSearch;
}
public String query(String question) {
// 1. 语义搜索相关文档
List<StructuredDoc> docs = vectorSearch.similaritySearch(question, 3);
// 2. 构建上下文
StringBuilder context = new StringBuilder();
for (StructuredDoc doc : docs) {
context.append(doc.getContent()).append("\n---\n");
}
// 3. 调用 LLM
return chatClient.prompt()
.system("你是一个专业的客服助手。请根据以下参考信息回答问题,如果参考信息中没有答案,请说明无法回答。")
.user(context.toString() + "\n用户问题:" + question)
.call()
.content();
}
}这段代码看似简单,但涵盖了 RAG 的核心逻辑。注意看 vectorSearch 的部分,在实际项目中,这里往往是性能瓶颈所在,需要仔细调优分片策略和索引类型。
项目练习:打造一个"可展示"的作品集
简历上写"做过一个问答机器人"毫无竞争力。面试官想看的是你如何解决实际问题。我推荐你做两个方向的项目,并着重记录以下细节:
1. 基于内部知识库的智能客服
亮点 :不要只做简单的问答。加入"引用溯源"功能,让 LLM 回答时标注出自哪篇文档的哪一段。这在法律、金融领域是刚需。
技术栈 :Spring Boot + Spring AI + PostgreSQL (pgvector) + ECharts (可视化检索过程)。
简历写法:解决了长文本检索精度低的问题,通过优化切片算法(重叠窗口法),将 Top-3 准确率从 65% 提升至 85%。
2. 自动化报表生成 Agent
亮点 :结合 SQL 生成和数据可视化。用户自然语言提问,系统生成 SQL,执行后展示图表。
踩坑点 :LLM 生成的 SQL 往往有误,且存在注入风险。
解决方案 :引入"SQL 校验中间件",先在预编译环境验证语法和执行计划,再在生产库执行。同时限制 DML 权限。
简历写法:设计了多层安全防护机制,实现了 NL2SQL 的零误报执行,保障了数据安全性。
面试准备:从后端视角切入
面试时,不要装作自己是 AI 算法专家。你要强调你是**"懂 AI 工程化的后端专家"**。
准备好回答这些问题:
- "如何处理 LLM 输出的幻觉?" -> 我会提到 RAG 的上下文过滤、Few-shot Learning 以及最后的输出校验层。
- "系统延迟太高怎么办?" -> 我会谈到流式响应(Streaming)的前端配合,以及异步处理非核心链路。
- "Token 成本控制怎么做?" -> 我会分享如何通过 Prompt 压缩、缓存相似请求、选择性价比高的模型组合来省钱。
这些答案体现了你的工程思维,这正是传统后端转 AI 的核心壁垒。
总结
Java 转大模型开发,不是换赛道,而是升级装备。
你拥有的高并发处理经验、分布式架构视野、严谨的代码规范,都是纯 AI 出身的人所缺乏的。不要陷入学习 Python 语法的陷阱,直接利用 Spring AI 或 LangChain4j 等工具链,把你的后端能力迁移到 AI 应用场景中。
最关键的一点:尽快做一个完整的、带监控、带日志、有异常处理的 Demo,并部署上线。 当你能指着线上运行的地址说"这是我做的,我解决了这个问题"时,你就已经跨过了那道门槛。
路就在脚下,跑起来再说。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
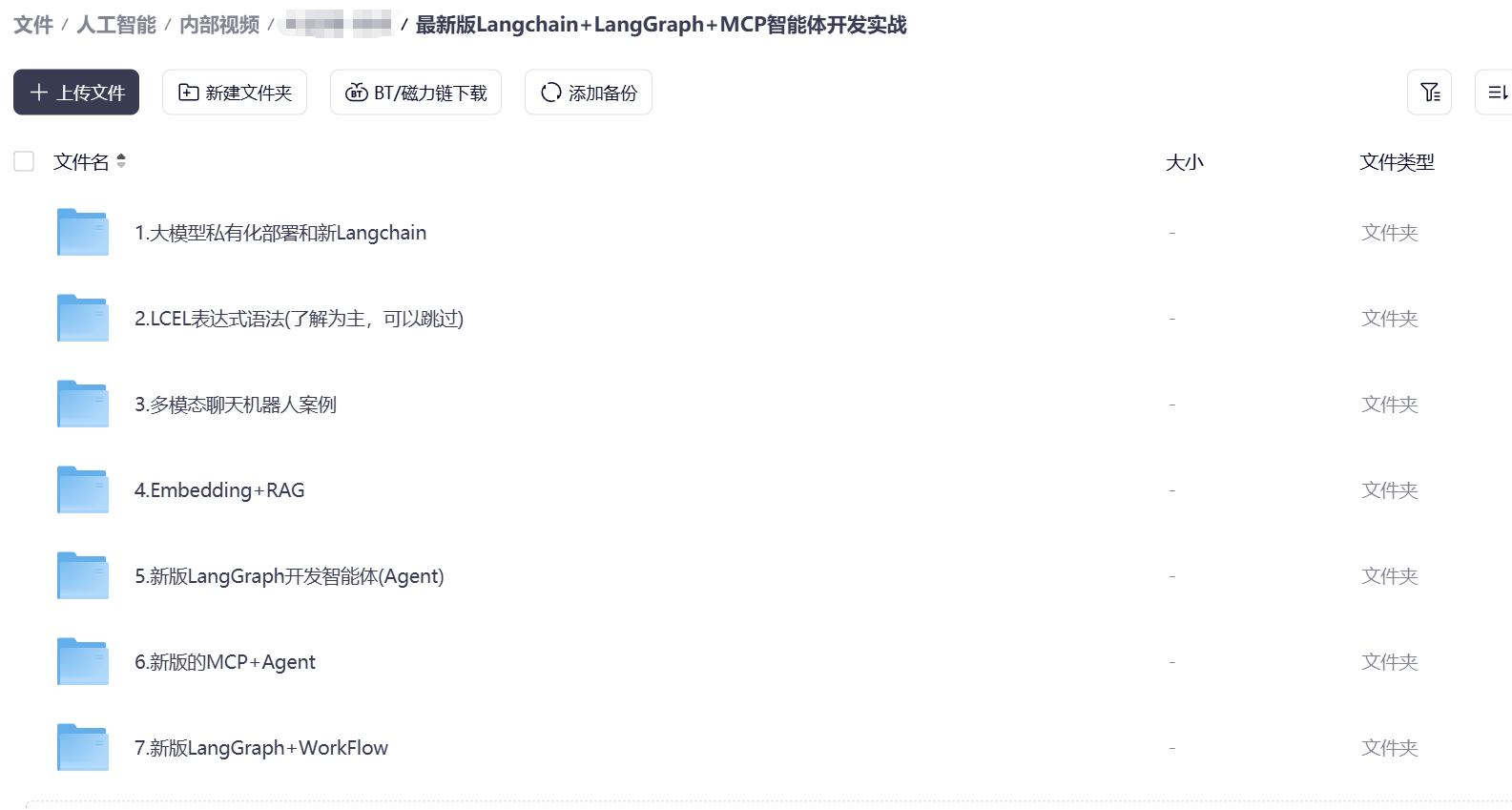
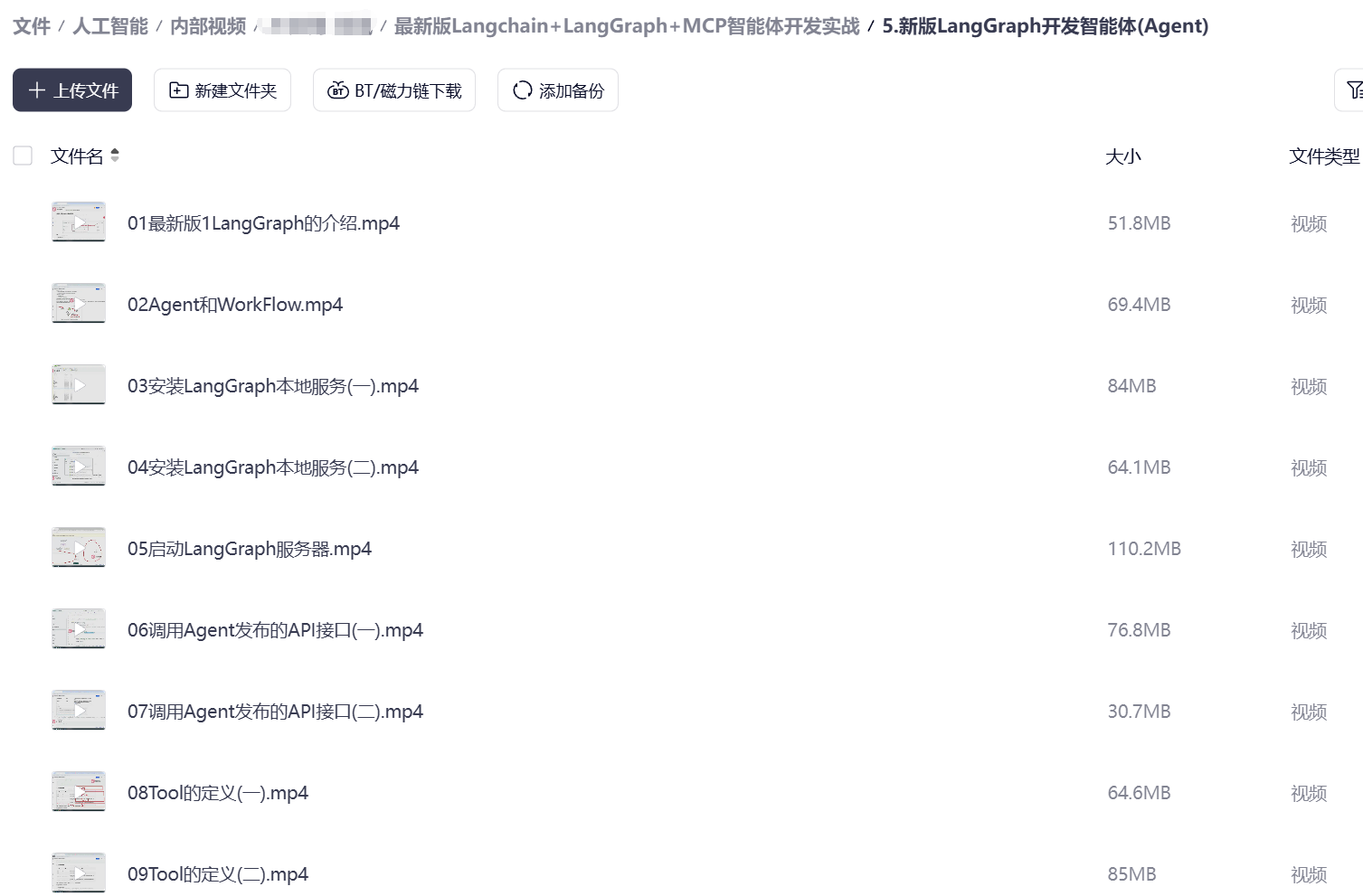

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。
