用 Hugging Face 数据集给现成 RAG App 做离线评估
我手上已经有一套能跑的 RAG App,也已经接了 ragas。
这篇文章记录我用 Hugging Face 上的 HotpotQA 数据集,把现有 RAG App 接到离线评估里的过程。
Git 链接:
https://github.com/NyaRu-Kiss/RAG-RAGAS.git
先说结论
这次离线评估链路:
- 先让 RAG App 对样本问题生成回答
- 再把回答结果交给
ragas做离线测评
还要补上公开数据集接到现有系统里的流程。
dataset数据
我用的是:
- dataset:
hotpotqa/hotpot_qa - config:
fullwiki - split:
validation
这里顺手补一下 Hugging Face dataset 常见的两个概念:
subset
也就是数据集配置。HotpotQA 这里我用的是fullwiki。split
也就是数据切分。HotpotQA 这里我用的是validation。
这次做 ragas 测试时,我用的是 fullwiki + validation,先把前 15 条样本保存到本地 JSON,再从里面选前 5 条跑一轮。
原始数据截图:
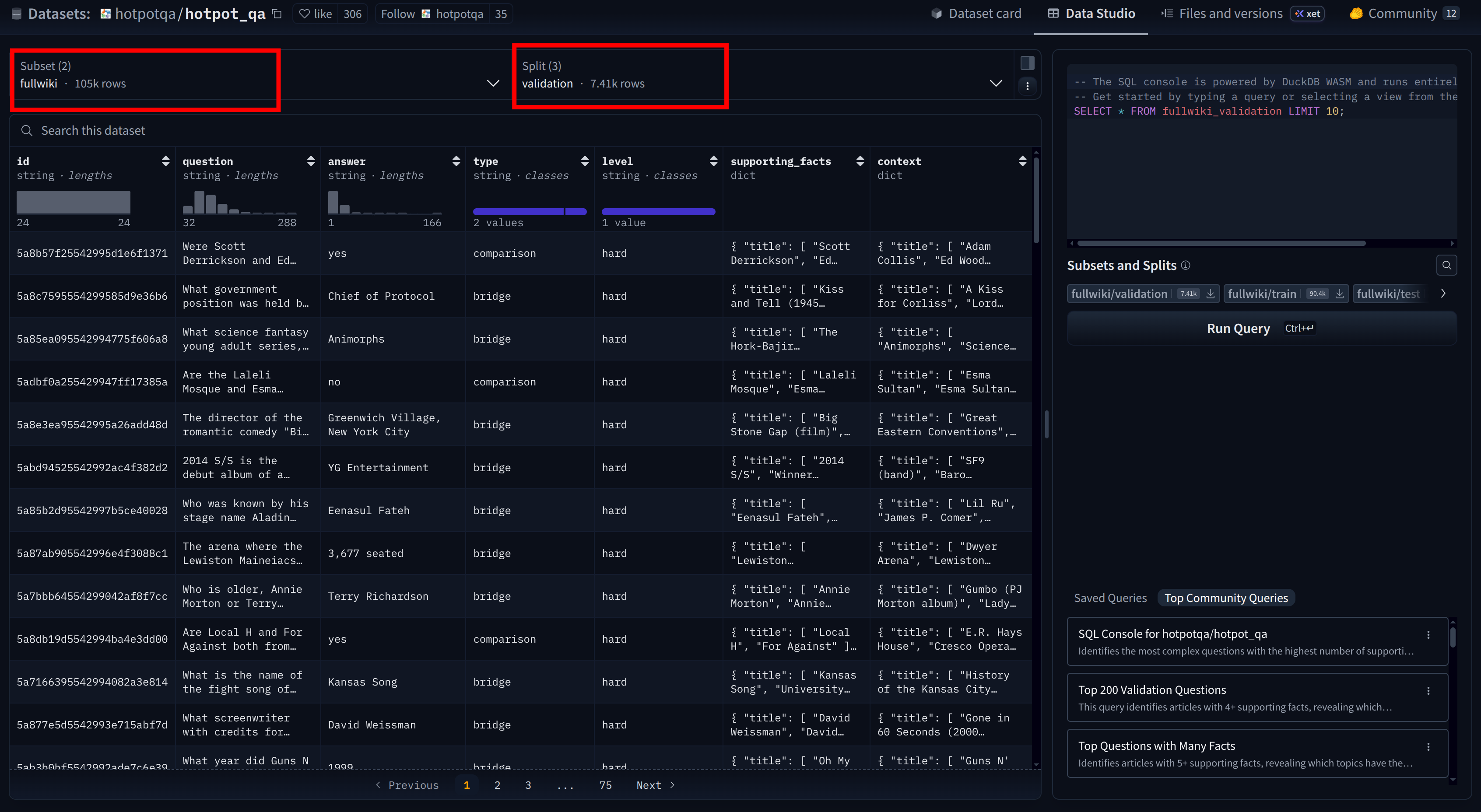
dataset链接:https://huggingface.co/datasets/hotpotqa/hotpot_qa/viewer/fullwiki/validation
RAG 评估流程
这次流程分两步:
-
RAG App 先回答
用样本里的
question去检索和生成response。 -
ragas再测评用
response、标准答案和参考证据做离线打分。
这个顺序不能反。先有 RAG 的真实输出,后面才有 ragas 的评估对象。
代码补了什么
为了把 Hugging Face 数据集接进现有 RAG App,我补了一层预处理和运行入口。它做的事情不复杂:
- 从本地 JSON 读取样本
- 生成 RAG 可 ingest 的文档
- 生成
ragas可用的评测jsonl - 调 RAG App 生成回答
- 调
ragas做离线评分
代码位置:
eval/prepare.pyeval/cli.pyeval/runner.py
实际运行方式
我这里最后是用虚拟环境里的 Python 跑的,不是直接用系统 python3。
这个细节不能省,因为我中途就踩过一次坑:系统解释器和项目 .venv 的依赖不一致,导致 app.rag 能在前端服务里正常工作,但命令行评估直接导入失败。
所以最终命令是:
bash
. .venv/bin/activate
python -m eval.cli run-hotpotqa-local \
--input eval/datasets/hotpotqa_fullwiki_validation_15.json \
--limit 5这条命令会完成:
- 准备语料
- 生成评测集
- 重建隔离索引
- 逐条调用 RAG
- 调用
ragas - 落盘报告
测试结果展示
报告目录下主要看这几个文件:
summary.jsonsummary.mdsamples.jsonlfailures.json
其中:
summary.json看整体分数samples.jsonl看单条样本答了什么、检索到了什么、每条分数是多少
报告截图:

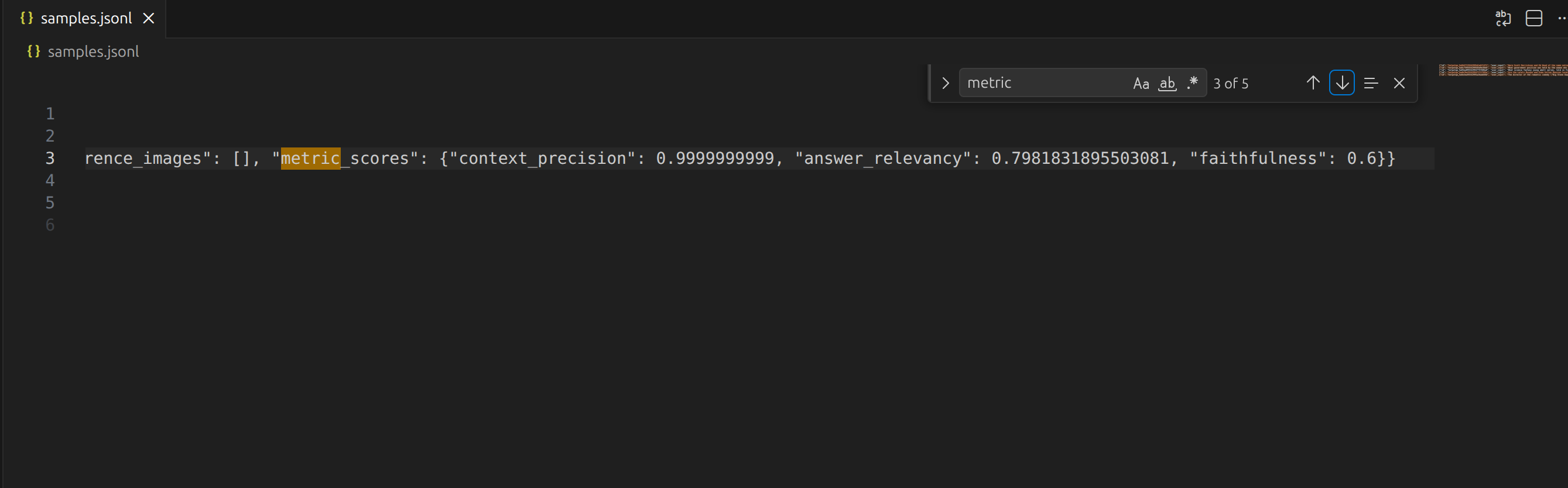
主要看三个指标:
context_precision检索准不准answer_relevancy回答有没有答到问题faithfulness回答是不是忠于检索证据
如此我们可以根据评估结果更好地迭代RAG应用。