torch的历史由来
利用pytorch搭建一层神经网络
python
import torch
import torch.nn as nn
net = nn.Linear(2,1)
x = torch.tensor([[1.0,3.0]])
out = net(x)
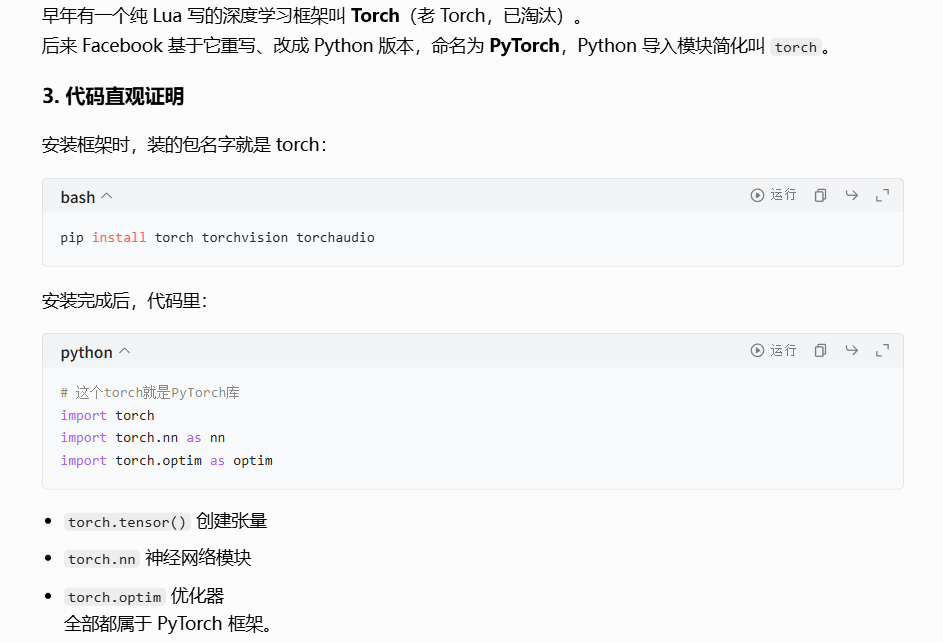
print(out)输出结果
每次会给不同的w,b所以每次运行输出的结果都会改变
自动求导+反向传播更新参数
python
import torch
import torch.nn as nn
#1.数据
x = torch.tensor([[1.0],[2.0],[3.0]])
y_true = torch.tensor([[2.0],[4.0],[6.0]])
print(y_true.shape)
#2.模型 + 损失 + 优化器
model = nn.Linear(1,1,bias=False)
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
#一轮训练(前向传播 -> 求损失 -> 反向传播 -> 更新参数)
#前向传播
y_pred = model(x)
loss = loss_fn(y_pred,y_true)
#反向传播求梯度
loss.backward()
#更新权重
optimizer.step()
#清空梯度,防止累加
optimizer.zero_grad()
print("权重w:",model.weight.item())
print("loss值:",loss.item())输出
每次执行时输出的结果都会改变

反向传播
w新 = w旧 - 学习率 * 梯度
python
import torch
# 参数1.初始值 2.是否自动微分 3.数据类型
w = torch.tensor(10, requires_grad=True, dtype=torch.float)
print(f'w:{w}')
# 定义loss变量,表示损失函数
loss = 2 * w ** 2 # loss求导loss = 2w² ---> 求导: 4w
# 打印梯度函数类型
print(f'梯度函数类型:{type(loss.grad_fn)}')
print(loss.sum())
# 计算梯度,梯度 = 损失函数的导数,计算完毕后会记录到w.grad属性中
loss.sum().backward() # 保证loss是1个标量
# loss.backward()
w.data = w.data - 0.01 * w.grad # (学习率是0.01,梯度是w.grad)
# 打印最终结果
print(f"更新后的权重:{w}")自动微分让损失越来越小
就是深度学习中最重要的让损失越来越小,预测值无限接近于真实值。
python
import torch
# 参数1.初始值 2.是否自动微分 3.数据类型
w = torch.tensor(10, requires_grad=True, dtype=torch.float)
print(f'w:{w}')
# 定义loss变量,表示损失函数
loss = w ** 2 # loss求导loss = w² ---> 求导: 2w
# 打印梯度函数类型
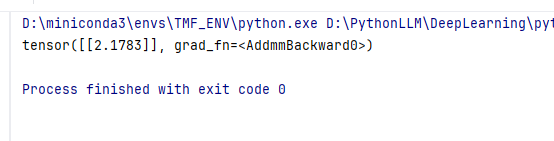
print(f"开始权重初始值:{w},(0.01 * w.grad):无, loss:{loss}")
#迭代100次,求最优解
for i in range(1,101):
#3.1正向计算(前向传播)
loss = w**2
#3.2 梯度清零w.grad.zero_() 默认梯度会累加
# 至此(第一次的时候),还没有计算梯度, 所以w.grad = None,要做非空判断
if w.grad is not None:
w.grad.zero_()
#3.3反向传播 损失函数的导数,计算完毕后会记录到w.grad属性中
loss.sum().backward()
#3.4 梯度更新 w.data = w.data - 0.01 * w.grad
w.data = w.data - 0.01 * w.grad
# 3.5打印本次梯度更新后权重参数结果
print(f"第{i}次,权重初始值:{w},(0.01 * w.grad):{0.01 * w.grad}, loss:{loss}")
#打印最终结果
print(f"最终结果权重:{w},梯度:{w.grad},loss:{loss}")输出的结果
detach()
一个张量一旦设置了 自动微分,这个张量就不能直接转成 numpy的 ndarray对象了,需要通过 detach()函数解决.
python
#一个张量一旦设置了 自动微分,这个张量就不能直接转成 numpy的 ndarray对象了,需要通过 detach()函数解决.
import torch
t1 = torch.tensor([10, 20], requires_grad=True, dtype=torch.float)
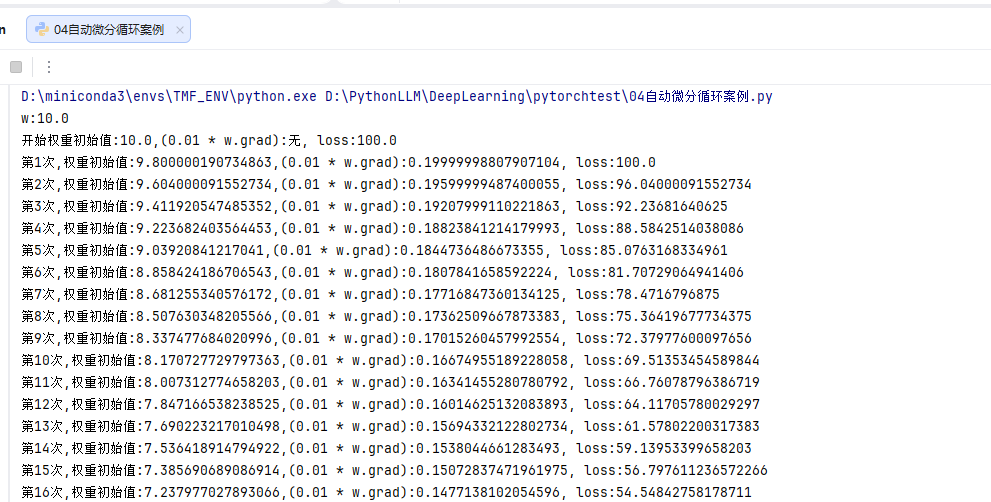
print(f"t1:{t1},type:{type(t1)}")
#尝试把上述张量 ---> numpy对象
n1 = t1.numpy()
print(f"n1:{n1},type:{type(n1)}")报错
优化后输出
python
#一个张量一旦设置了 自动微分,这个张量就不能直接转成 numpy的 ndarray对象了,需要通过 detach()函数解决.
import torch
t1 = torch.tensor([10, 20], requires_grad=True, dtype=torch.float)
print(f"t1:{t1},type:{type(t1)}")
#尝试把上述张量 ---> numpy对象
# n1 = t1.numpy()
# print(f"n1:{n1},type:{type(n1)}")
#解决办法通过detach()函数,拷贝一份张量然后转换
n1 = t1.detach().numpy()
print(f"n1:{n1},type:{type(n1)}")