目录
[1.6.3 认识请求"报头"(header)](#1.6.3 认识请求“报头”(header))
[User-Agent(简称 UA)](#User-Agent(简称 UA))
[Referer 的应用场景](#Referer 的应用场景)
[Cookie 格式](#Cookie 格式)
[Cookie 的应用场景](#Cookie 的应用场景)
[浏览器 - 服务器 之间的联动~~](#浏览器 - 服务器 之间的联动~~)
[1.6.4 认识请求"正文"(body)](#1.6.4 认识请求“正文”(body))
[1)application / x - www - form - urlencoded](#1)application / x - www - form - urlencoded)
[2)multipart / form - data](#2)multipart / form - data)
[3)application / json](#3)application / json)
书接上文:Java EE:7.网络原理- HTTP/HTTPS(第二弹)~~
1.6.3 认识请求"报头"(header)
header 的整体格式也是"键值对"结构
分成很多行,每一行是一个键值对
键和值之间使用:空格 分割
键 / 值 都是标准规定的~~RFC标准文档
闲聊:这种标准文档,工业界都很常见~~
有句话说的好:
三流公司做产品(卖产品赚钱)
一流公司做标准(引领行业潮流~~躺着赚钱~~)
美国人,为啥要制裁华为,不制裁腾讯阿里??
就是因为华为引领了时代潮流,尤其是通信领域,提出了非常多的业界标准~~
答疑:进华为有多难??
985学校,无脑进华为~~强211也是可以的~~差不多就是投简历的时候点击就送
但是普通一些的学校,就很难~~
双非校招,一般是不行的~~
报头的种类有很多,此处仅介绍几个常见的
Host
表示服务器主机的地址和端口
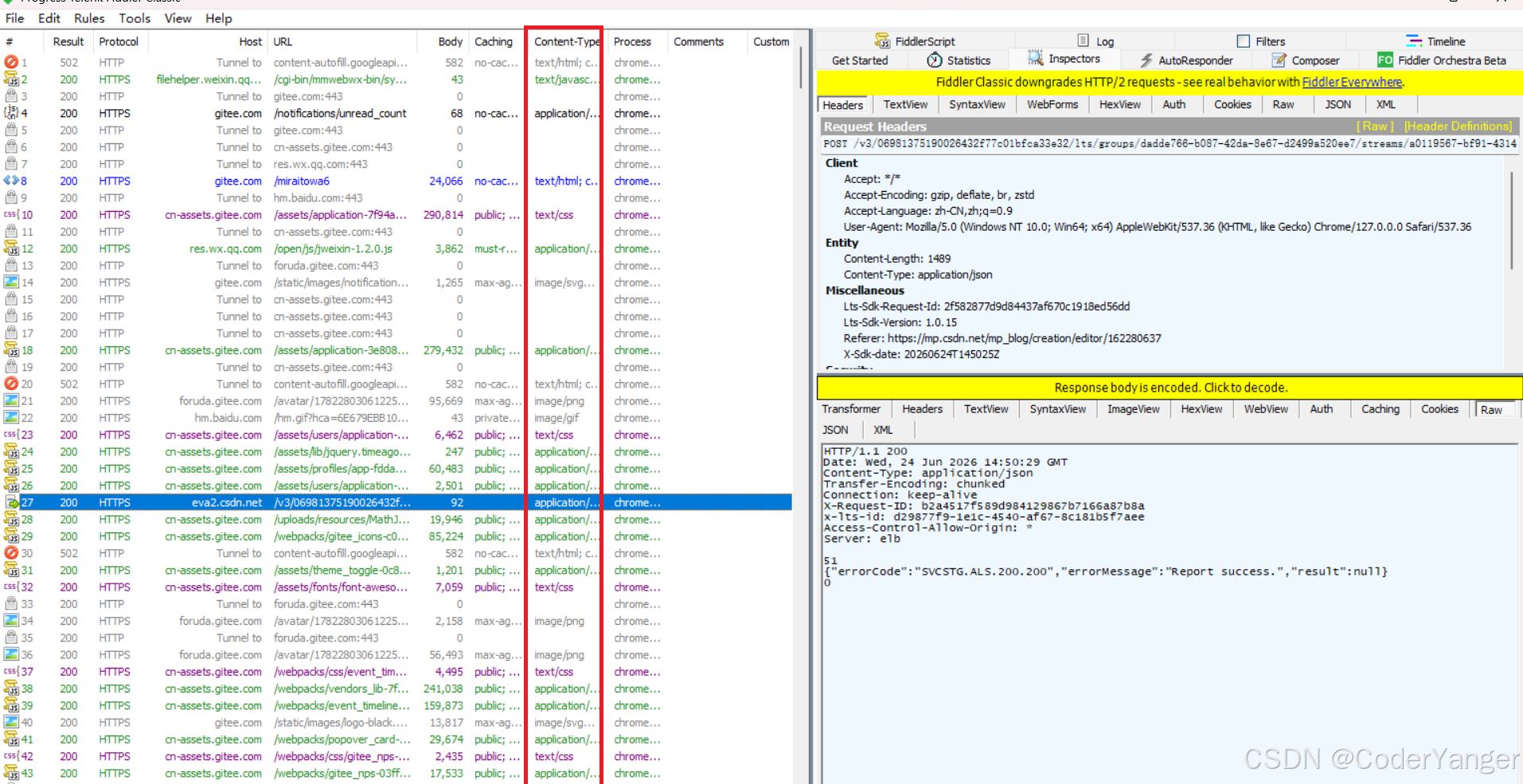
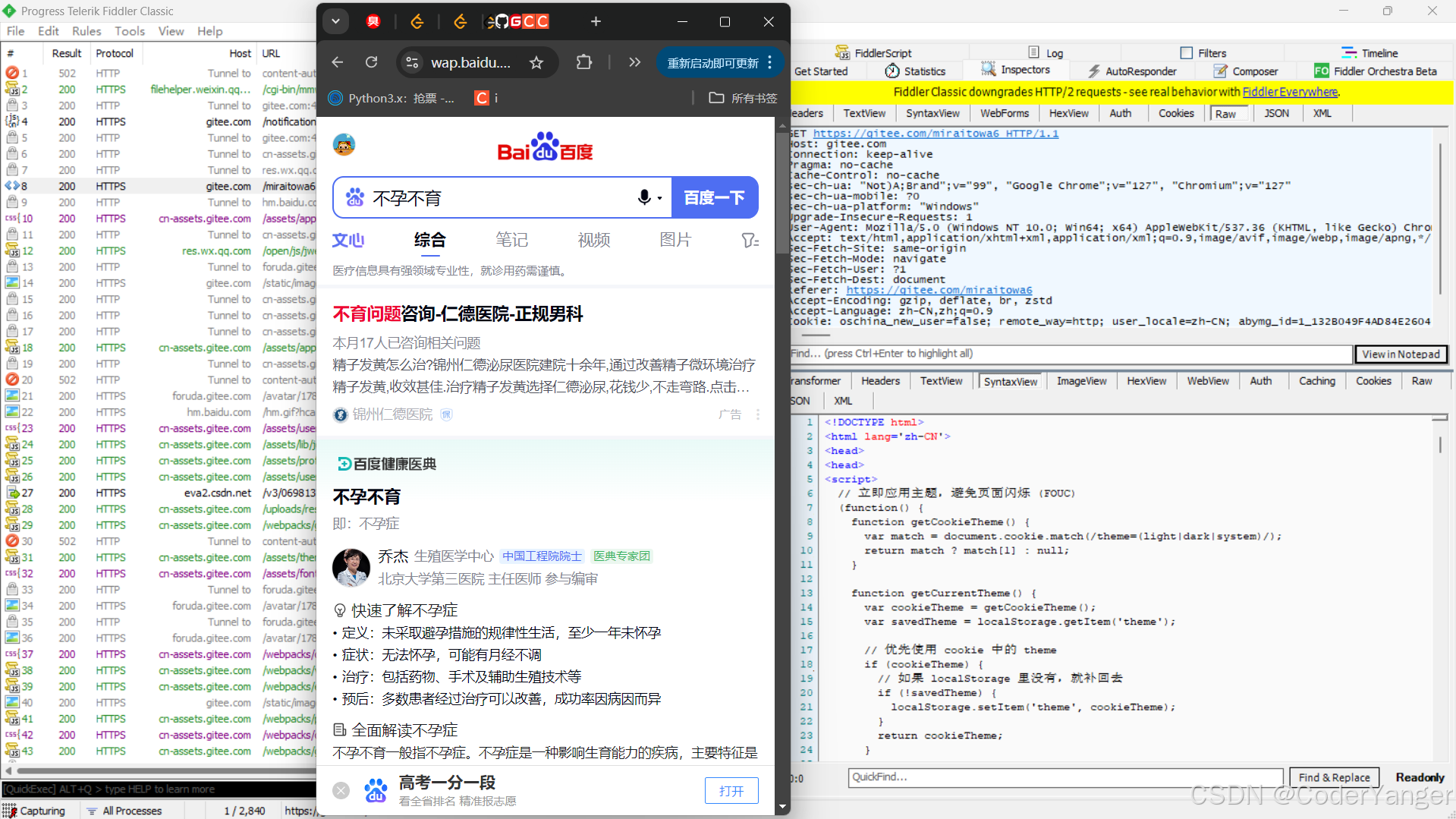
我们用 Fiddler 抓一下刷新码云网页的请求就能发现有👇
javaHost: gitee.com这里的 gitee.com 就是表示当前请求访问的服务器在哪里~~
如果是默认端口号,端口号就省略了,不是默认端口号,后面还会跟着个端口号
这里的 Host 可以认为绝大部分情况下跟我们前面学到的 URL 中的 IP地址(域名):端口号 属性是一致的~~
但是也有一些特殊场景下是不一致的~~
①比如说我们使用了代理~~这时候代理就会对 URL 进行修改,但即使使用了代理,也可以通过 Host 来获取到最原始的目标是啥
②还有一种情况:HTTP 协议中,传输的时候可能会涉及到"加密"(HTTPS)
URL 部分是不会被加密的,被加密的是 header 和 body
意味着 Host 也会被放进 header 中被进行加密,这样做的话也就相当于给服务器添加了一个校验的效果,服务器收到请求之后可以进行最终校验,验证 URL 中的内容 和 header 中加密的内容是否一致,提高了传输中的安全性~~
答疑
Q1:那登录密码安全吗??
一般登录密码这种,都是要在业务层加密的
依赖 HTTPS 这种操作,只能保证传输过程中是安全的
但是如果密码就明文保存在服务器上,服务器可能会被黑客攻击,严重会触发 拖库
也会造成密码泄露~~
过去十年中,拖库 这种现象屡见不鲜!!!
甚至一些知名公司,都被黑客拖过库~~
比如 CSDN,当时被黑客曝光库了之后,有些人忘记密码了,还在曝光的数据中意外找到了密码~~
类似的还有 携程~~
Q2:好厉害,想去试试,奈何技术不够~~
这个没什么难的,也没啥,但是风险太高了~~
Q3:滴滴被拖过好像,好像还给过美国什么数据~~
滴滴这个公司本身就有很多外国资本入股的,是属于被资本裹挟的~~不是被拖库了~~
下面介绍的 Content-Length 和 Content-Type 都是可有可无的,看你请求中是否有 body
没有 body 这俩东西自然就不需要,如果有的话那就很重要~~
请求和响应,都会用到这两个 header~~
如果有 body,但是没有这俩属性(哪怕只有一个),都认为是非法的 / 错误的 http 报文
Content-Length
表示 body 中的数据长度,单位是字节(不是字符)
HTTP 协议,传输层这里基于 TCP 实现的(版本号<=2.0)
所谓的 HTTP 协议,就是把字符串构造成 HTTP 约定的格式
对于 TCP 来说,一个连接上可以一次发多个请求~~
服务器这边收到数据的时候就得区分一下,从哪里到哪里是一个完整的 http 请求数据
1)没有 body 的 http 请求,读到空行,就可以认为是结束了
2)有 body 的 http 请求:
①读取首行 和 header,读到空行
②解析 header 中的 Content-Length,根据这里的值,判断接下来再读取固定字节的长度
答疑:UDP 也差不多吗??
UDP 中是面向数据报的~~
读写的基本单位就是一个 UDP 数据报
某个应用层协议,基于 UDP,一个 UDP 数据报就对应一个完整的应用层数据包
调用一次 receive 操作,就得到一个明确的 UDP 的数据包
我们前面写 TCP 代码的时候也体现出这一点了,是通过 next 来读取的(隐含了一个约束,使用 空白符 作为结束标记)
Content-Type
表示请求的 body 中的数据格式
提示了接收方如何解析 body 中的数据~~
HTTP 这里面能够携带的数据种类是比较多的:
HTML:浏览器就会解析其中的标签,把标签转换成界面显示
CSS:浏览器就会解析其中的 选择器 和 属性,并且把这里指定的内容应用到页面的样式上
JS:浏览器就会通过 js 引擎解释执行 js 中的逻辑
JSON:浏览器不会做任何处理(由对应的 js 程序员写的逻辑中处理)
图片:浏览器就会尝试按照图片的二进制格式,解析出来并显示
这里面对于每一种数据内容,浏览器做的内容都是不同的,对于服务器,服务器收到的时候会根据 body 的不同做不同的工作
为了能够对这些数据有个明确的区分,为了能够让浏览器下一步该怎样去进行工作,这时候用 Content-Type 进行区分,就很方便了👇
HTML:text/html
CSS:text/css
JS:application/javascript
JSON:application/json
图片:image/png 或者 image/jpg 之类的
答疑:这种就叫渲染吗??
一般谈到"渲染",指的是把 数据变成界面
比如我们上述提到的下面三个就是属于渲染的过程:
HTML:浏览器就会解析其中的标签,把标签转换成界面显示
CSS:浏览器就会解析其中的 选择器 和 属性,并且把这里指定的内容应用到页面的样式上
图片:浏览器就会尝试按照图片的二进制格式,解析出来并显示
下面我们抓包体会一下(Ctrl+F5强制刷新)👇
通过Fiddler抓包体会Content-Type
javaContent-Type: text/html; charset=utf-8这里后面还会有一个字符集:UTF-8
目的就是告诉浏览器通过什么方式编码组织的,能够避免出现乱码
javaContent-Type: text/cssCSS就只是一些样式,能被浏览器识别就行了,也不涉及中文,自然不会有乱码,就不用指定编码格式了
javaContent-Type: application/x-javascript通过观察 CSS 和 JS 抓到的请求我们会发现正文的这一部分貌似非常乱👇
但其实这些东西都是合法的 JS 的语句~~
只是看起来和咱们课堂上学的 JS 是不太一样的,但本质语法都是同一套~~
答疑
Q1:编译的??
这个叫混淆~~
像 C++ / Java 这样的代码,会编译成二进制,发布给用户
用户拿到的是二进制代码,用户想根据二进制,还原出原始的源代码是怎样的,是非常麻烦的~~
JS 这样的代码则是把原始代码直接由用户浏览器下载到
用户就能看到 JS 最原始的样子~~
但是引发了一个问题:程序员费劲千辛万苦,写的代码,一下子被别人拿到了~~
如果别人基于你的这个代码,也搭建出一样的网页,来和你竞争,抢你饭碗呢??
因此就出现了"代码混淆"
用专门的工具,就能把 JS 做出变换~~
在代码逻辑不变的情况下,把 JS 代码给该乱~~
比如说把变量名全换成一个字母、把所有空格去掉......让别人读起来的成本变高~~
让别人觉得去扒下来很麻烦,或者说有时间慢慢扒,自己都能写一套了~~
Q2:在网页F12不是可以看到源码吗??
你看到的源码是 html 和 css,毕竟这东西你看一下页面结构就大概知道咋弄了,所以 html 和 css 这俩玩楞你嫖走就嫖走,本身成本也不高~~(混淆的意义就不大)
但是 JS 是带有一定的业务逻辑的,你就是用 F12 看到的也都是混淆过的,想看完整的、清晰的 JS,除非是你能把人家服务器给黑了,才能看到~~
Q3:现在给AI很容易解析了
这个就没办法了,毕竟这个混淆机制从上古时期就流传下来了,而 AI 是近些年来才发展起来,可以说 混淆机制是被 AI 天克了,不过以后应该会有一些对应的策略~~
User-Agent(简称 UA)
这个也是非常有意思的属性~~
User-Agent 里面表示了用户使用的设备的浏览器和操作系统的情况
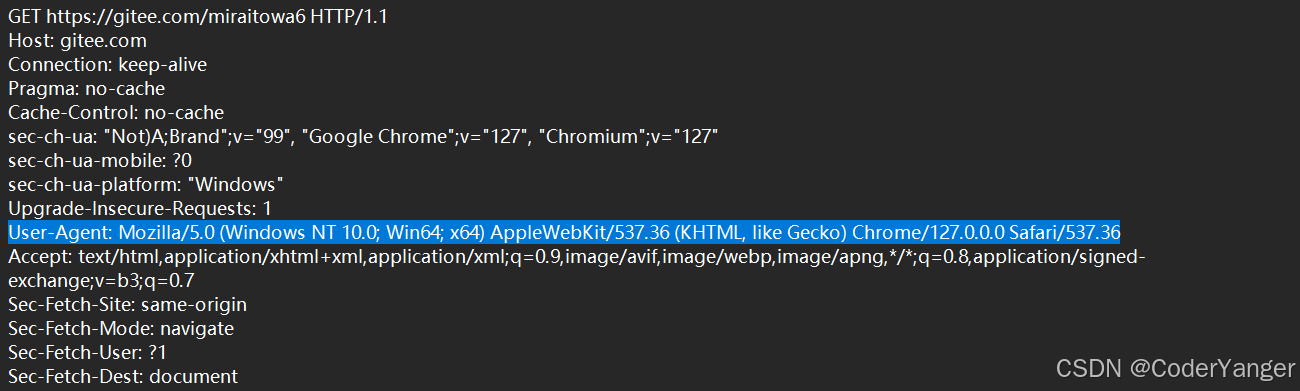
我们点开刷新网页时抓到的一个请求,会发现有这么一行👇
javaUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36简单解释一下:
①Mozilla/5.0
firefox(火狐浏览器)的开发者就叫 Mozilla,
②(Windows NT 10.0; Win64; x64):操作系统版本
③AppleWebKit/537.36 :浏览器内核
④(KHTML, like Gecko)
⑤Chrome/127.0.0.0 :浏览器版本
⑥Safari/537.36:苹果手机的浏览器
答疑:32位和64位的区别在哪??
从用户使用的角度来说,没有区别~~
硬件发展到一定程度了,对于32位的系统/CPU 来说,能够支持的最大内存,就是4G
因为 32位 CPU 意味着对应的指针变量就是32个bit 位,意味这在多大的内存空间上寻址,32个 bit 位转换过来也就 4GB
15年前,计算机的内存差不多就达到 4G 了
像我们现在 8G 内存的机器,就必须得是 64位 的 CPU 和操作系统~~
其实 32->64 这个过程在计算机圈子中是一件惊天动地的大事
但是对于普通人来说,是完全没有感知的~~
这就得益于 Windows 兼容做的好,64位的Windows系统也可以无缝的使用32位的程序~~
因为正常来说,32位CPU运行的是32位的程序,64位CPU运行的是64位的程序
一旦升级到64位,就意味着之前32位的程序就都用不了了~~
虽然Windows兼容做的很好,但是Linux就没这么幸运了,Linux就存在这个问题~~
有同学表示:用户决定马良~~其实程序员已经老早就骂过了~~
通过上面的分析,我们知道 User-Agent 主要体现出了 浏览器的信息和操作系统的信息
那么这两个信息又有什么用呢??
User-Agent 诞生于互联网快速发展的早期~~
最早,互联网主要是类似于"报纸杂志"这种感觉~~
这个时候,浏览器只要能显示文本就行了
后来在网页中加入了图片~~
后来加入了各种格式
后来加入了 js,实现各种逻辑
后来加入了多媒体......
由于发展速度太快了,这就导致同一时间段内
有些用户的浏览器,版本是比较旧的,支持的功能少
有些用户浏览器更新,支持的功能多
那么这个问题就扔给了程序员,你要咋开发??
你是要支持比较多的功能还是支持比较少的功能呢??
如果你要是支持的功能少,可能就打不过竞争对手~~
如果支持的功能多,旧版本浏览器设备的用户,可能就展示不了~~
因此就需要根据用户使用的设备,进行区分
通过 UA 中的浏览器版本/操作系统版本,区分出当前用户的设备,最多都支持那些特性~~
老的浏览器,返回功能少的网页,正确显示
新的浏览器,返回功能多的网页,体验丰富
但是这就苦了程序员,程序员就需要维护多套代码~~
但是到现在2026年,浏览器大家都大差不差~~
UA 就很少用来区分浏览器了,但是不是说没有,UA 还有另外一个用途,可以用来区分用户的设备
Windows / Mac=>PC
ios / Android=>手机
根据用户的设备,返回不同版本的页面,以满足不同用户设备的需求
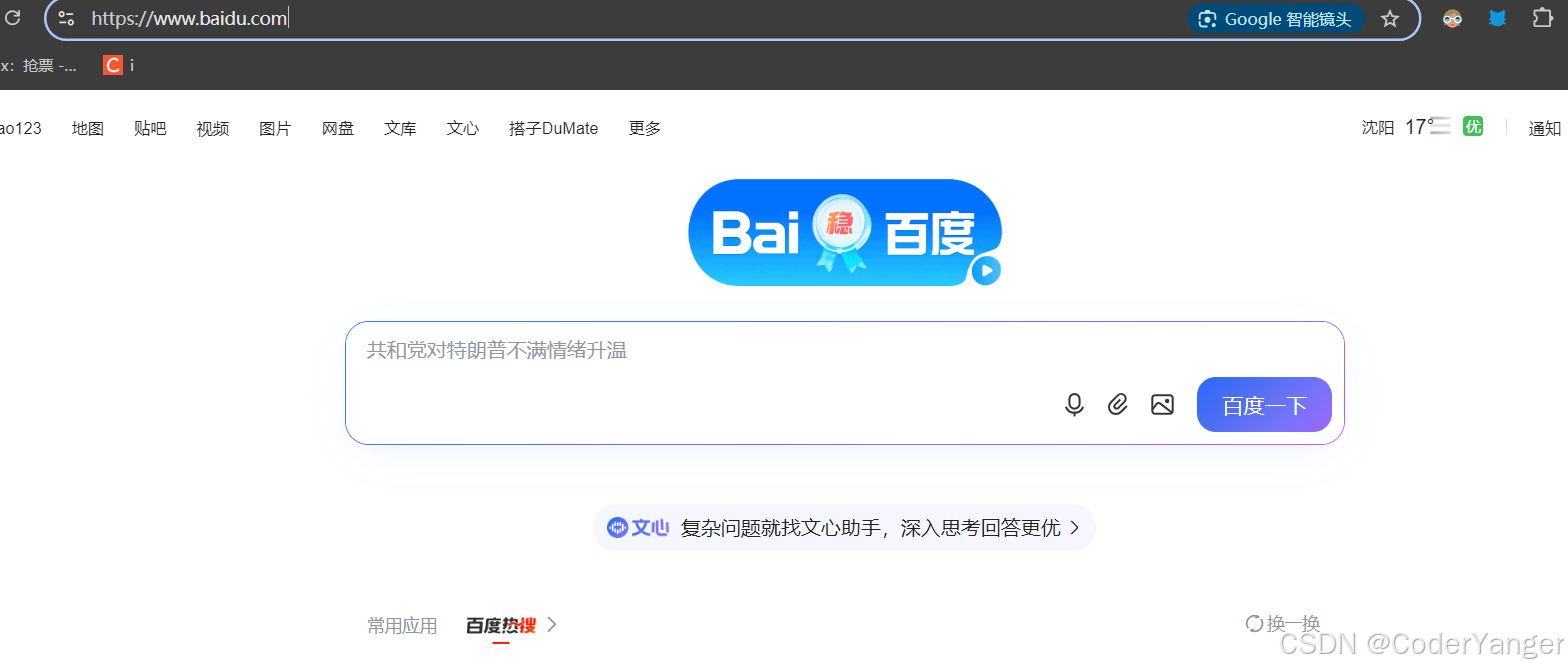
比如说 www.baidu.com 返回的就是PC端的页面👇
窗口缩小之后看起来就非常费劲,看起来特别纠结~~
而 wap.baidu.com 返回的就是手机端的页面👇
窗口缩小之后就更像手机了,比较舒适~~
因此显示 Windows 的时候也可能是手机,显示 Android 也可能是电脑
在前端圈子中,有个词叫"响应式编程",通过 CSS 中的"媒体查询"功能,感知到当前窗口的尺寸(宽度),通过不同的尺寸,设置不同的样式
这样就能够做到,一个页面适配不同的窗口~~
顺便给大家介绍一个前端好玩的👇(改个支付宝余额啥的,发朋友圈装B用🤭)
前端娱乐技巧
Referer
描述了当前页面的来源,这个页面是从哪个页面跳转来的
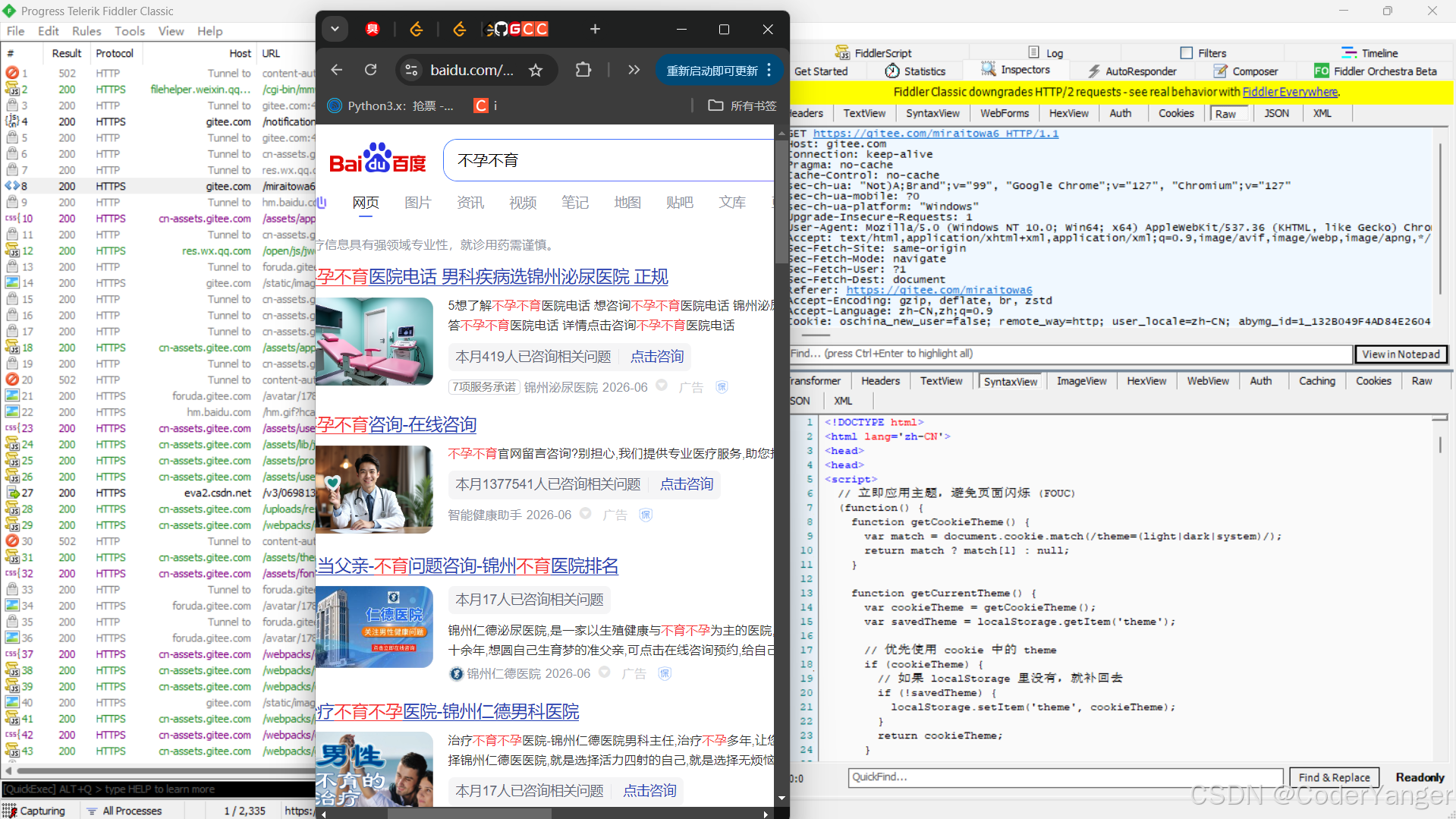
这个 Referer 是不一定有的,比如直接输入 URL / 点收藏栏 打开的页面是没有 Referer 的👇
Referer 的演示
我们发现,直接输入一个 URL 是没有 Referer 的
当我们从主页跳转到搜索页,搜索页的 Referer 就是主页的 URL👇
Referer: https://cn.bing.com/当我们从搜索页跳转到广告页,广告页的 Referer 就是搜索页的 URL👇
javaReferer: https://cn.bing.com/search?q=%E4%B8%8D%E5%AD%95%E4%B8%8D%E8%82%B2&form=QBLH&sp=-1&lq=0&pq=%E4%B8%8D%E5%AD%95%E4%B8%8D%E8%82%B2&sc=12-4&qs=n&sk=&cvid=040A48ACD4F7495CA974B556718B32FDReferer 的应用场景
那么 Referer 这东西有什么应用场景呢??
比如说广告系统,通常是按点击计费(CPC 广告)
这就需要统计某个广告,在一定时间(一个月)一共点击了多少次~~
这个统计工作需要必应和广告主两方一起做,否则另一方不放心~~
两边都统计完之后对数字,能对上,就完事儿,对不上,就得找程序员排查问题~~
对于必应的统计方式就好办:
点击广告跳转的时候,先访问搜狗的"计费服务器"(有记录日志),再从计费服务器跳转到广告页面
对于广告主:
广告主服务器也有日志,统计广告主服务器日志中访问的次数就可以了~~
但是,一个广告主可能同时在多个平台投放广告,比如说同时在百度、必应、搜狗、360同时投放广告
此时就需要用 Referer 区分出来哪些广告是从必应跳转过去的,进而正确统计~~
运营商劫持
那么接下来就出现一个问题:是否存在可能,有人把 Referer 给改了??本来是必应的 Referer 改成别人的 Referer??
不是可能,这种现象在2014年的时候,非常普遍~~
当时程序员也没排查出来问题,当时就认了,按照少的来了,可以说对广告平台造成了一定的损失~~
那么什么人有能力把 Referer 给改了呢??什么人有动机去做这件事呢??
运营商(中国移动、中国联通......)
这种行为叫做"运行商劫持",大白话翻译过来就是"抢劫!!!",抢劫是不论金额的,一定 100% 判刑的,而且国家公检法部门会提起公诉~~
有能力的:用户上网的时候,HTTP 请求都是经过运营商的路由器 / 交换机
运行商只需要通过软件,分析数据流量,把一些广告的数据的 HTTP 数据报进行修改就行了~~
有动机的:运营商也有自己的平台(运营商 和 搜狗 / 百度 是竞争关系)
后来百度拉着其他广告平台一起~~
在技术上反制~~=>HTTPS
2015年的时候,百度牵头,其他广告平台跟进(包括搜狗),大家一起把广告平台从 HTTP 升级成 HTTPS
HTTPS 协议能够有效的对 HTTP 数据报进行加密传输(Referer 也被加密了)
HTTPS 这条路趟平之后,此时其他中小型公司也纷纷跟进了~~
2026年的今天,想在互联网上找到纯 HTTP 的网站,已经很难了~~
答疑
Q1:法律不管吗??
2014年,互联网还是新鲜东西,很多关于网络的法律条文是不完善的~~
官司要打,大概率能赢~~但是中间的过程会很复杂,肯定要大量的扯皮~~
Q2:搜狗怎么知道的??
不止搜狗,还针对 百度、360 这些所有的广告平台都会受到影响~~
这些大厂自然有牛人能有办法知道的~~
Q3:官司打赢没??
这个就不得而知了,哈哈~~
Cookie
浏览器展示页面的过程中,页面里虽然可以通过 JS 来实现一些逻辑,但是 JS 代码无法访问你的硬盘的(文件系统)
就像我们平时浏览网页的时候应该就能发现,没有哪个网页你一点开就能把你电脑上所有文件和目录都列出来
有同学会说,那这种不就列出来了吗??👇
注意这种选择文件不是 JS 实现的,是浏览器原生态实现的
换句话说,你没办法通过 JS 去读取文件,这是浏览器给 JS 戴上的"紧箍咒"~~
怕 JS 要是能操作用户的文件系统,再瞎搞呢~~要是有人通过 JS 把你电脑上所有文件全删除了,这可太吓人~~
为了保证用户的安全性,严禁 JS 操作文件系统,这是势在必行的事情~~
引出问题
但实际开发中,有的时候还是希望把某些数据能够保存到本地硬盘的~~
因此浏览器就引入了 Cookie 机制
Cookie 就是浏览器允许网页在本地硬盘存储数据的一种机制
不是让网页代码直接访问文件系统,而是做了一层抽象:
浏览器的 Cookie 提供了键值对存储机制~~
也就是说你的网页代码中只能往电脑中存键值对,键是啥,值是啥,你乐意咋设定就咋设定,但是你没法去干预 Cookie 具体去保存一个什么样的文件名、具体保存到哪个目录里,以及这个目录里都有哪些别的东西,这些东西你一概干预不了,你也一概感知不到,只能够存键值对(字符串),这就有效的保证了安全性~~
就像某些网站,会让用户决定,是否愿意存他的 Cookie 数据~~
Cookie 这里是按照 键值对存储的,对于键值对我们并不陌生,之前就接触过很多次:
1.URL 的 query string:程序员自定义
2.header 部分也是键值对:标准规定
3.header 中 Cookie 里存的数据还是键值对:程序员自定义
4.body 是 json 格式,仍然是键值对:程序员自定义
我们会发现,大部分都是程序员自定义,这也是让程序员更多的操作空间,能够结合实际情况,基于 HTTP 实现一些个性化的功能需求~~
这也是 HTTP 能火、能广泛使用的一个原因~~
Cookie 格式
键值对以 分号 分割,每个分号是一个键值对
键和值之间以 = 分割
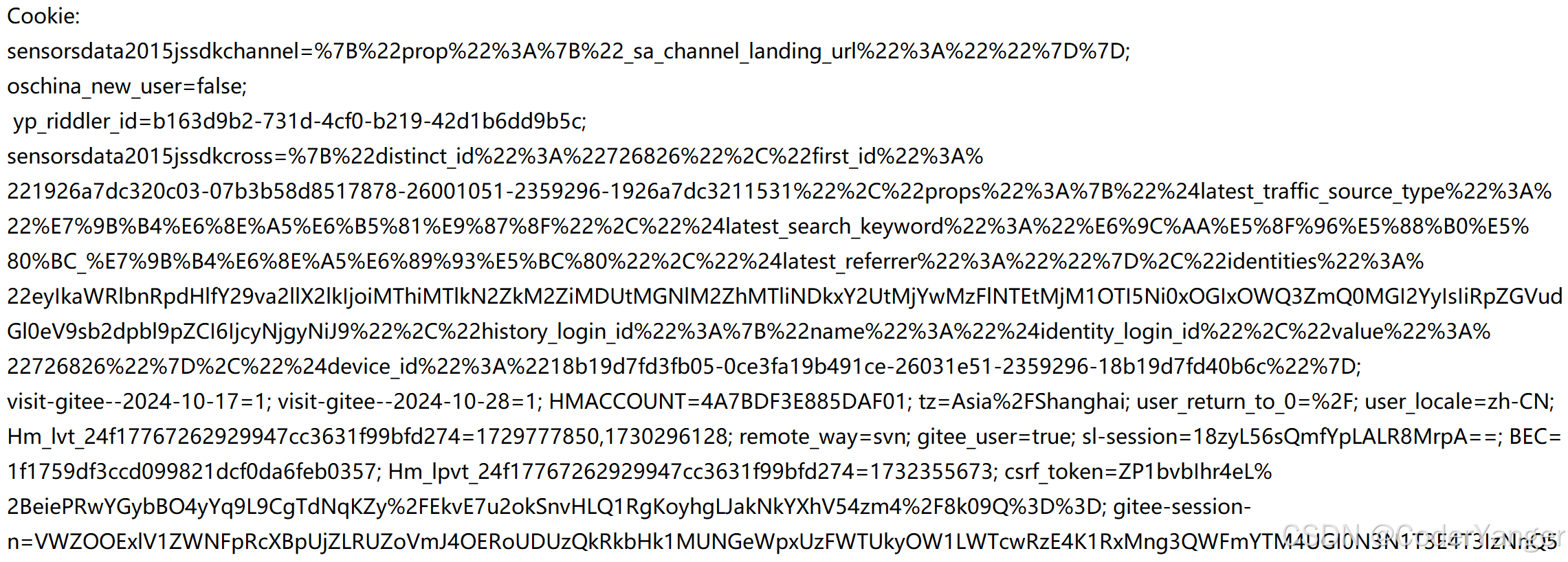
下面我们随便找一个 Cookie 分析👇
我们看起来会很乱,其实浏览器中是可以直接看到当前页面保存的 Cookie 有哪些的~~
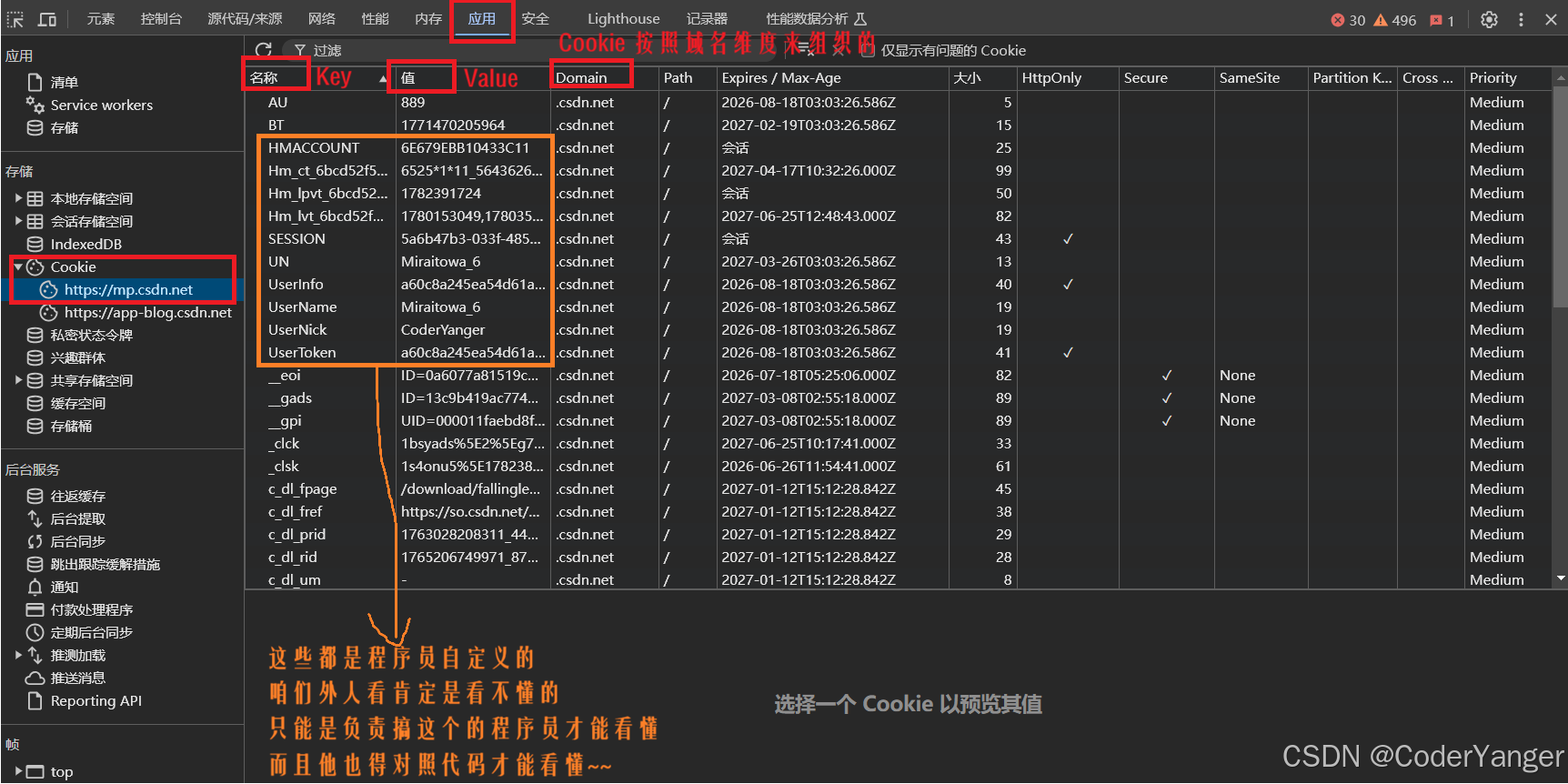
按 F12 在开发者工具中就能找到👇
浏览器保存了这些 Cookie 之后,就会在后续给服务器发送请求的时候,把这些 Cookie 键值对放到 请求 Cookie header 中传输给服务器
Cookie 到哪里去:最终发回给服务器
Cookie 从哪里来:也是从服务器这边来的(有哪些键值对,是后端开发程序员决定的)
有没有办法看到服务器返回 Cookie 的过程呢??
有办法的,比如👇
观察服务器返回的Cookie
我们可以右键将 Cookie 清空,删了的 Cookie 是我们本地浏览器保存的 Cookie,此时这些数据在我们再次刷新浏览器还会出现的
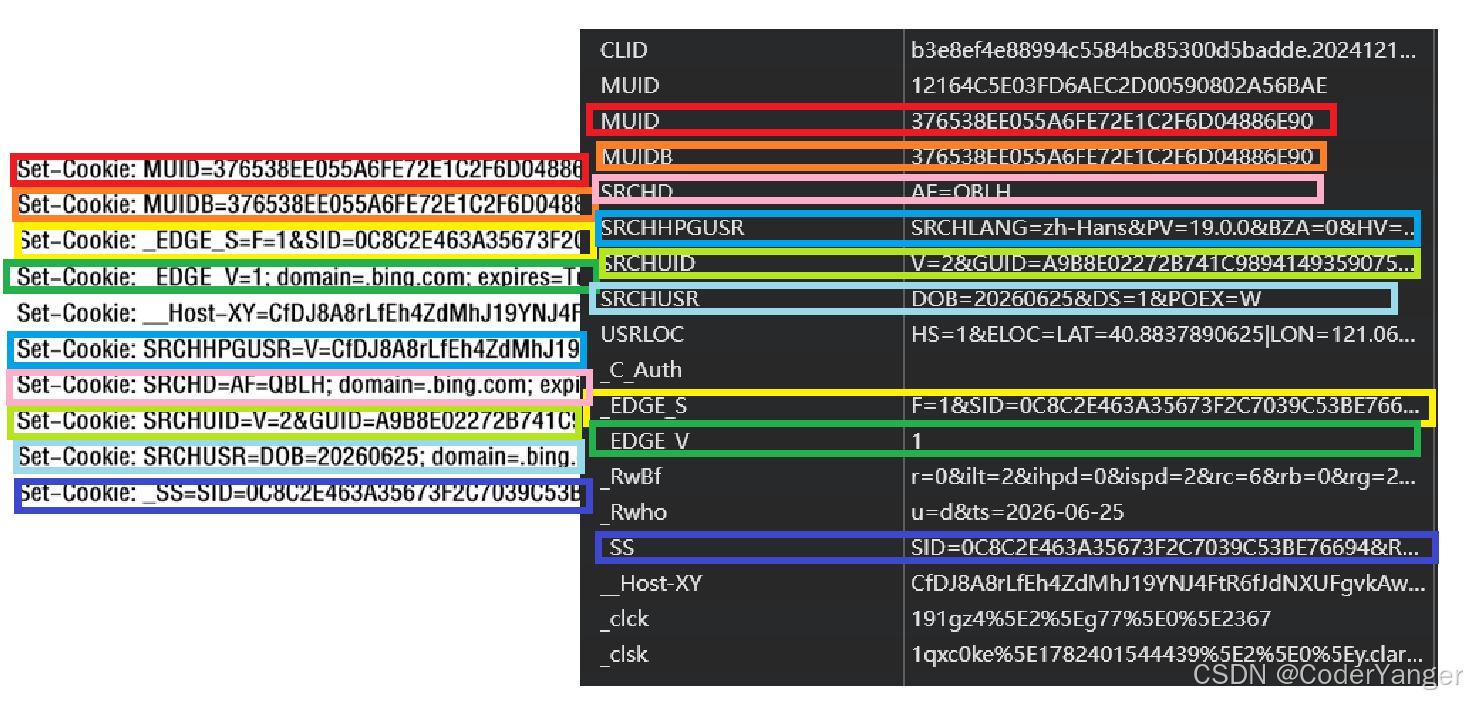
并且我们找到刷新时对应的请求数据,会发现在清除 Cookie 之后在给服务器发的数据里面就没有 Cookie 了,但与此同时,对应的响应里面就会带有一个 Set - Cookie(不一定一个,可能有多个)👇
Set-Cookie: MUID=376538EE055A6FE72E1C2F6D04886E90; domain=.bing.com; expires=Tue, 20-Jul-2027 15:22:47 GMT; path=/; secure; SameSite=None Set-Cookie: MUIDB=376538EE055A6FE72E1C2F6D04886E90; expires=Tue, 20-Jul-2027 15:22:47 GMT; path=/; HttpOnly Set-Cookie: _EDGE_S=F=1&SID=0C8C2E463A35673F2C7039C53BE76694; domain=.bing.com; path=/; HttpOnly Set-Cookie: _EDGE_V=1; domain=.bing.com; expires=Tue, 20-Jul-2027 15:22:47 GMT; path=/; HttpOnly Set-Cookie: __Host-XY=CfDJ8A8rLfEh4ZdMhJ19YNJ4FtSL9zy-5iBMQN_zu8nWsTwRWYBYEus7naqTfeb-mIqUpjfi-UmdpeclPpaSwJBRsfjyjbt2uHjyhHHvpFiQLI_kZe76r5Ju57PQVx3mlJWEHrmBxIeDSF7aqxex4TnchUrzoLLKLyADSjsKDOOhypgUTukuYL5Cd93Vsg34NDQsHuLgU1bJYPke7qoRuF2spV-OR01_Ef2ykSKMCnXZObtONz9-QZ96xlJCQVQPlegGPg; expires=Fri, 26-Jun-2026 22:22:47 GMT; path=/; secure; HttpOnly; SameSite=Lax Set-Cookie: SRCHHPGUSR=V=CfDJ8A8rLfEh4ZdMhJ19YNJ4FtRk-GgN1g8mi8VBhpzjh3OD8ICXuaiISVG7OKg4JcO8RhIKArpV-CFj_ZNgeDnnv9ESMbpBrvA1cMReXa5CoEd6Qdw2SChjrqt76Fmvwkpd5eUJFJD5ZRb0zumRFVKB6WU&SRCHLANG=zh-Hans&PV=19.0.0; domain=.bing.com; expires=Sun, 25-Jun-2028 15:22:47 GMT; path=/; secure; SameSite=None Set-Cookie: SRCHD=AF=QBLH; domain=.bing.com; expires=Sun, 25-Jun-2028 15:22:47 GMT; path=/; secure; SameSite=None Set-Cookie: SRCHUID=V=2&GUID=A9B8E02272B741C9894149359075A57A&dmnchg=1; domain=.bing.com; expires=Sun, 25-Jun-2028 15:22:47 GMT; path=/; secure; SameSite=None Set-Cookie: SRCHUSR=DOB=20260625; domain=.bing.com; expires=Sun, 25-Jun-2028 15:22:47 GMT; path=/; secure; SameSite=None Set-Cookie: _SS=SID=0C8C2E463A35673F2C7039C53BE76694; domain=.bing.com; path=/; secure; SameSite=None说明此时在给服务器发请求的时候,服务器就会在响应报文中添加若干个 Set - Cookie 字段,这些 Set - Cookie 就是我们要往浏览器中存的键值对,就以 Set - Cookie 的形式返回过来了,此时浏览器里面就可以看到对应的 Cookie 了
而且我们可以对照一下,这两个部分的内容是一致的👇
答疑:那这不对啊,重新刷新之后咋就剩这么几个了??刚才不是一大堆吗??
这个是跟你触发服务器的功能有关的,当前我们只是刷新了一下这个搜索页,所以这时候触发的 Cookie 只是当前刷新这一次访问页面的逻辑,随着你对网页更多的操作,操作过程中,它就会逐渐得到更多的 Cookie 了~~
上面我们介绍了几个点:
1.Cookie 是什么??
浏览器在本地持久化的一个机制,既然是持久化,就意味着我们哪怕重启浏览器,甚至重启主机,这个数据仍然存在,但是这个持久化不是说永远存在下去,Cookie 一般会有一些超时时间(过期时间)👇
会通过这个过期时间描述我们这个键值对最终到什么时候就会被浏览器删除
其实这个过期时间也可以不指定,都是可以灵活判定的
2.Cookie 从哪里来?
3.Cookie 到哪里去?
答疑:现在可以自己找一些 项目练手了嘛??
至少把 spring mvc 学一学
做网站基本流程了解一下~~
Cookie 的应用场景
由于 Cookie 里的数据都是程序员自定义的内容,因此 Cookie 的用途都是和业务相关的~~
我们这里讲解知识还不涉及业务,但是有一个典型的场景,属于"通用业务"(各种业务都会用的到):登录和用户认证~~
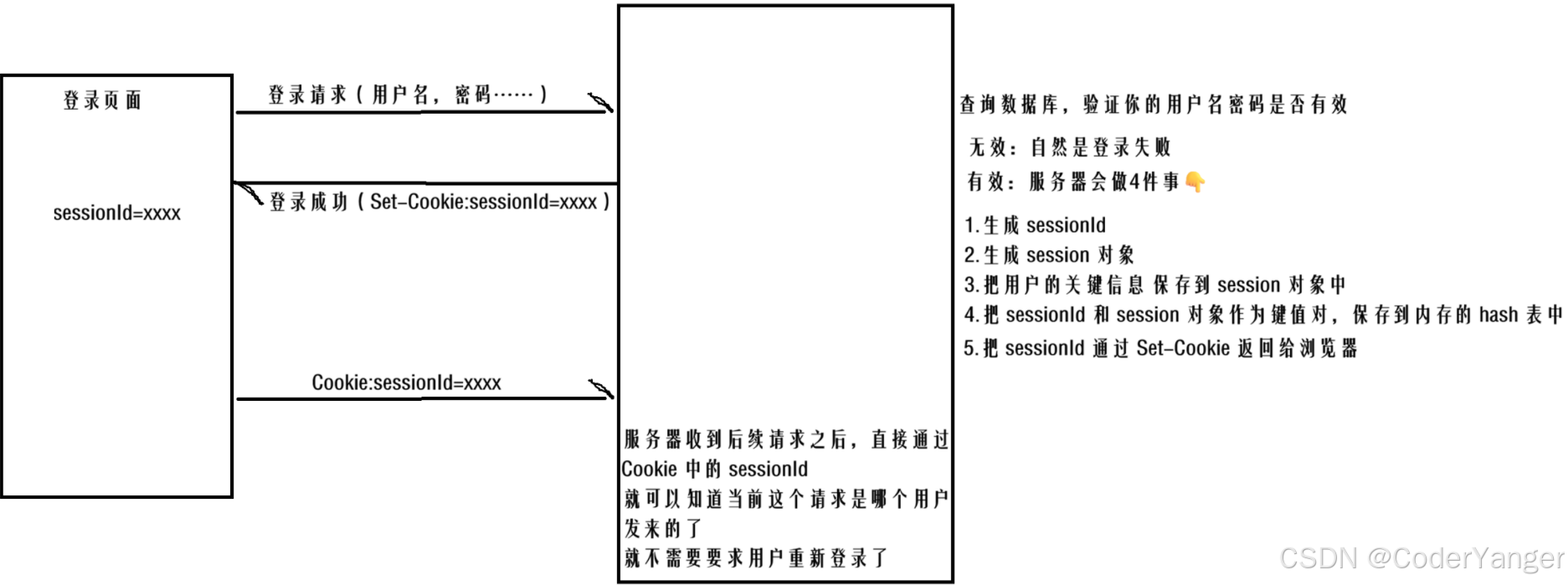
浏览器 - 服务器 之间的联动~~
这个 session 就是一个会话,session 对象也是可以存储用户自定义的数据的,表示了当前这一次会话的详细信息~~
课件上的图(其实都一样~~)👇
啥是一次会话呢??
比如说,你有一个好朋友,进去了,吃上了国家饭~~
你就想去探视他~~
你进行一次探视的过程,就可以称为是"一次会话",这一次会话过程中就会涉及到一些关键信息:
你是谁??
你探望的是谁(这个人犯了啥事儿,身高体重年龄,在几号宿舍......)
甚至说,你和他都聊了啥~~
于此同时,你隔壁,还有一个不认识的人,探视另一个人,这就属于另一个会话
过几天又去探视一次,有需要重新申请、重新审批,这又是另一次会话
再之后,你朋友的家人,也去探视你的朋友,这又是另一次会话~~
答疑
Q1:数据库建立连接是会话嘛??
我们上述讲到的会话,是描述了客户端和服务器之间的一种交互关系
数据库,也是服务器,对应的客户端,就是你的应用程序 / Workbench ......
你的客户端访问一次数据库服务器,这个中间的过程也可以称为是一次会话~~
但是这两种会话,还不太一样,可以理解为两个独立的会话~~
Q2:会话好像日志~~
会话和日志还不是一个东西,会话记录的是这个过程,关键数据的状态~~
会话中记录的内容,只是当前的状态
而日志会记录整个变化的过程(之前是啥样的,修改之后又是啥样的)
Q3:session 什么类型定义的
通过一些算法(uuid 之类的)生成的随机字符串
Q4:这个是不是类似于 记住密码??
二者还不太一样,存在本质区别,记住密码,完全属于浏览器自身的行为~~
我们知道,Cookie 是可能会过期的,服务器返回 Cookie 的时候,是可以设置有效时间的
如果 Cookie 中的 sessionId 过期了,此时就需要用户重新登录了
用户重新登录的过程中,是否需要重新手动输入一遍密码,这就是浏览器的记住密码功能解决的问题了
对于这个过期时间:
有的网站,对于安全性要求不高,过期时间就长
有的网站,对于安全性要求很高,过期时间就短
典型的例子,网银......这种涉及到钱的,只要你把页面关闭/几分钟之内不操作,就会自动过期
不然你在公共电脑上操作,人 就离开了~~下一个人拿到这个电脑,还能继续操作,那可就危险了~~
但是像 B站、抖音 这种以娱乐性为主的网站,过期时间就很长了~~
Q5:但是网吧不是自动关机吗?
网吧电脑是关机之后就可以还原(影子系统)~~
但是这个是网管可以控制是否要还原的~~
还有很多别的公共电脑~~
银行,营业厅里也有很多公共的电脑,查询自助、办理业务的......
图书馆,公共电脑~~
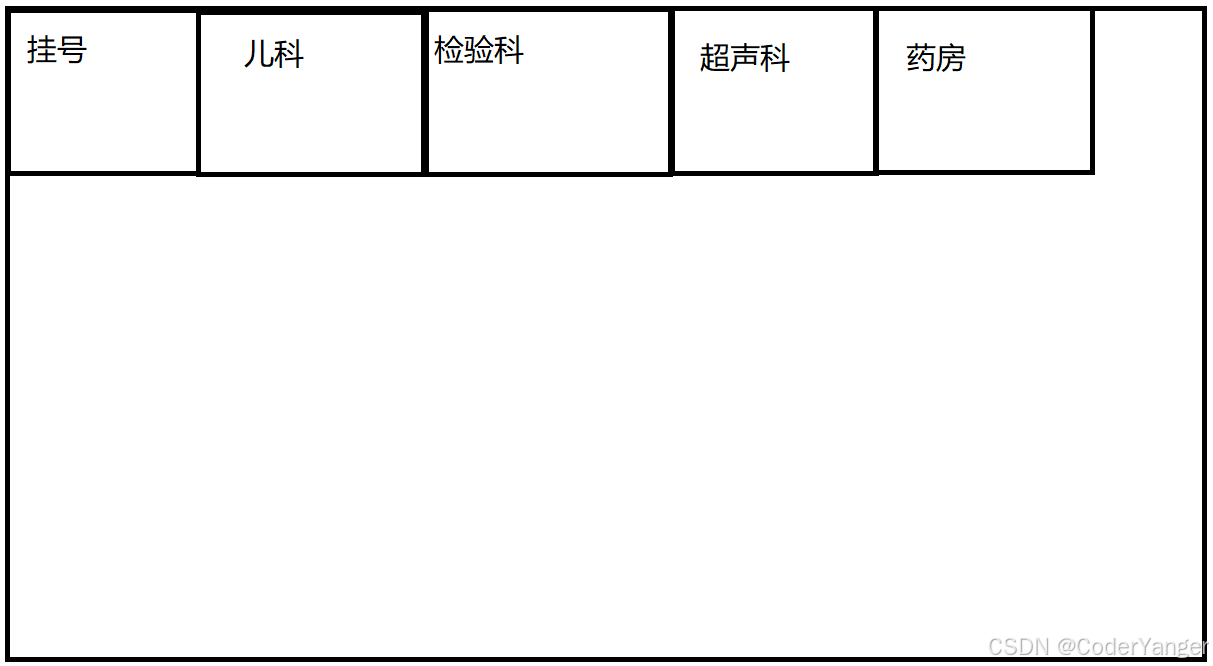
打个比方,去医院看病~~
1.挂号~~
办理一个就诊卡
就需要填写表格,记录一些核心信息
医生会把这些信息录入电脑,然后给我一个就诊卡~~
这就相当于生成了一个会话,由于卡可能会丢,于是就诊卡里面就只存储了一个会话 ID
2.儿科门诊
刷一下就诊卡~~
刷卡之后,医生电脑上就显示出了这个患者的所有信息~~
后续医生开了检查、开了一些单子,就会直接记录到这个会话中~~
3.检验科
刷一下就诊卡~~
检验科的医生就能立即看到了我这边要查啥~~
4.影像科
刷一下就诊卡~~
5.回到儿科诊室
刷一下就诊卡~~
检查结果,就直接显示到医生的电脑上了~~
看完病之后,不想要就诊卡了,就可以注销这个卡,此时患者的身份和就诊卡的关联就销毁了~~
这个过程不需要我们说什么,只需要带着就诊卡走一遍流程,也就把病给看了~~
这个过程中,就诊卡就相当于 sessionId~~
闲聊:
Q1:30块钱取鱼刺~~
这个可能会有生命危险的~~
鱼刺可能引起咽喉发炎,严重会导致气道闭塞=>喉咙肿了,把气管给堵死=>窒息~~
这种来的非常快=>一天之内就走了~~
Q2:还是小诊所下药猛,打几针就好了~~
小诊所的核心思路:大剂量抗生素~~
小病可以去诊所,但大病还是得去公立医院,公立医院是不敢乱搞的~~会严格按照国家标准限制使用的~~
Q3:现在大医院里随便一个实习生好像都是研究生了吧??
程序员35岁已经中年危机了
医生35岁才刚刚开始~~刚刚能坐诊,能够给病人独立看病~~
医生就属于妥妥的大后期英雄,前期要经过漫长的规培过程,比较难受,发育周期长,大后期,爆出神装了,就牛逼了~~
还有一些其他的报头,类似于:Accept、sec-ch-ua、sec-ch-ua-moblie、sec-ch-uaplatform、Sec-Fetch-Mode......这些在以后开发中很少用到,就不介绍了~~




阶段性小结
HTTP
1)
|----------------------|---------------------|
| 请求 | 响应 |
| 1.首行(方法 URL 版本号) | 1.首行(版本号 状态码 状态码描述) |
| 2.请求头(header):若干个键值对 | 2.响应头:若干键值对 |
| 3.空行 | 3.空行 |
| 4.正文 | 4.正文 |2)方法
GET 和 POST :混着用
区别:
1.语义上的区别:服务器上拿数据和往服务器提交数据
2.放哪:GET放 URL 的querystring里,POST 放 body 里
PUT、DELETE
DELETE 类似 GET,数据放 URL 里
PUT 类似POST,数据放 body 里
3)URL构成:协议名://IP:端口号/路径?查询字符串
版本号:HTTP/1.1
4)请求头,关键的属性
①Host:访问的服务器的主机IP和端口
②Content-Length:body 的长度(字节)
③Content-Type:body 的数据格式,html、css、js、json、图片......
④Referer:当前页面从哪里跳转过来的
⑤User-Agent:描述当前上网的设备的操作系统和浏览器信息
⑥Cookie:浏览器在本地存储数据的一种方式~~用键值对存储
从哪来:服务器通过 Set-Cookie 返回的
到哪去:后续给服务器发的请求,都会带上 Cookie
按照域名为维度,以键值对的方式来存储
Cookie 中的内容都是 程序员自定义,最典型的场景:实现登录身份认证
1.6.4 认识请求"正文"(body)
正文中的内容格式和 header 中的 Content-Type 密切相关,上面也罗列了三种常见的情况
下面属于课件内容,和之前介绍的 Content-Type 类似
在这里我们需要重点掌握 application / json ~~
通过抓包来观察这几种情况:
1)application / x - www - form - urlencoded
抓取码云上传头像请求
javaPOST https://gitee.com/profile/upload_portrait_with_base64 HTTP/1.1 Host: gitee.com Connection: keep-alive Content-Length: 107389 sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91" Accept: */* X-CSRF-Token: 6R0fZGr4Y7Qx8td1TuKCnrG8gb0DLCSUqUBZSw2b+ac= X-Requested-With: XMLHttpRequest sec-ch-ua-mobile: ?0 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, Content-Type: application/x-www-form-urlencoded; charset=UTF-8 Origin: https://gitee.com Sec-Fetch-Site: same-origin Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer: https://gitee.com/HGtz2222 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-4 avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0Ss实际的抓包结果比较长,此处没有全部贴出
2)multipart / form - data
抓取比特教务系统上的"上传简历"功能
javaPOST https://v.bitedu.vip/tms/oss/upload/file HTTP/1.1 Host: v.bitedu.vip Connection: keep-alive Content-Length: 293252 sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91" Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb25pbGlc2VySI6IjFiYThjMDM5L sec-ch-ua-mobile: ?0 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, Content-Type: multipart/form-data; boundary=----WebKitFormBoundary8d5Rp4eJgrUSS3wT Accept: */* Origin: https://v.bitedu.vip Sec-Fetch-Site: same-origin Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer: https://v.bitedu.vip/personInf/student?userId=665 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 Cookie: rememberMe=true; username=18691491410; Admin-Token=eyJhbGciOiJIUzUxMiJ9. ------WebKitFormBoundary8d5Rp4eJgrUSS3wT Content-Disposition: form-data; name="file"; filename="李星亚 Java开发工程师.pdf" Content-Type: application/pdf %PDF-1.7 %²³ 1 0 obj << /Names << /Dests 4 0 R>> /Outlines 5 0 R /Pages 2 0 R /Type /Catalog>> endobj 3 0 obj <</Author ( N v~N ) /Comments () /Company () /CreationDate (D:20201122145133+06' endobj 13 0 obj <</AIS false /BM /Normal /CA 1 /Type /ExtGState /ca 1>> endobj实际的抓包结果比较长,此处没有全部贴出
3)application / json
抓取比特教务系统的登录页面 https://v.bitedu.vip/login
javaPOST https://v.bitedu.vip/tms/login HTTP/1.1 Host: v.bitedu.vip Connection: keep-alive Content-Length: 105 sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91" sec-ch-ua-mobile: ?0 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS Content-Type: application/json;charset=UTF-8 Access-Control-Allow-Origin: * Accept: application/json, text/plain, */* Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization, Accep Origin: https://v.bitedu.vip Sec-Fetch-Site: same-origin Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer: https://v.bitedu.vip/login Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 Cookie: rememberMe=true; username=123456789 {"username":"123456789","password":"xxxx","code":"u58u","uuid":"9bd8e09ea27b48cd"}这个也是我们开发中最常用的一种格式,把 body 中的内容按照 json 的方式进行组织,也就是用一个大括号来保存若干个键值对👇
java{"username":"123456789","password":"xxxx","code":"u58u","uuid":"9bd8e09ea27b48cd"}键值对之间用 逗号 分隔,键和值之间用 冒号 分隔,这里的键值对同样也是程序员自定义的
我们后续进行 Web 开发的过程中,其实相当多的工作都是围绕着这里所定义的数据来展开的,大家先有一个明确的印象~~
