作者:来自 Elastic Sachin Frayne
Elasticsearch 未命名的 hash() 以及证明它是 Murmur3 的 12 个字节。Elasticsearch 的 路由 公式使用 MurmurHash3 ,但文档从未说明这一点。本篇文章命名了该函数,完整拆解分片计算过程,并展示如何在外部复现它。
新接触 Elasticsearch 吗?参加我们的 Elasticsearch 入门 webinar。你也可以开始一个 免费云试用,或者现在就在你的 本地机器 上体验 Elastic。
当我第一次接触 Elasticsearch 时,我知道文档会被分布到多个 shards 上,也知道其中涉及某种 hash 机制。官方文档 甚至给出了这个公式:
routing_factor = num_routing_shards / num_primary_shards
shard_num = (hash(_routing) % num_routing_shards) / routing_factor但那个 hash() 调用?完全是黑箱。点进 routing field 文档,你找不到这个函数的名字。去问别人,得到的回答通常是:这是实现细节,被刻意抽象掉了,这样团队以后可以替换实现而不需要更新文档。
从技术上讲,这个回答是站得住脚的。但它并没有帮助我或我的客户理解为什么会出现不均匀的 document 分布。
这篇文章就是我当时希望能看到的解释。
什么是 MurmurHash3,以及 Elasticsearch 为什么使用它?
hash() 背后的函数是 MurmurHash3。它是一个非加密哈希函数,由 Austin Appleby 在 2008 年设计。与加密哈希函数(SHA-256、MD5)不同,它不是为安全性设计的;它不需要不可逆,也不需要抵抗有意的碰撞攻击。它只为一件事服务:以尽可能快的速度,将输入值均匀地分布到输出空间中。
这正好适合 shard routing。Elasticsearch 需要把一个 document ID 转换成一个数字,然后用这个数字来决定该 document 存放在哪个 shard 上。它的需求与 Murmur3 提供的能力完全一致:
| 属性 | 为什么它对分片路由很重要 |
|---|---|
| 均匀分布 | 文档可以在各个 shard 之间均匀分布,无需人工干预。 |
| 确定性 | 同一个 document ID 始终路由到同一个 shard。 |
| 速度 | 在每一次 index 和 get 操作中都会执行,因此必须几乎没有延迟开销。 |
如果你想深入了解,可以看 MurmurHash。简短版本是:Murmur3 在字节块上运行,通过一系列 multiply-rotate-XOR(乘法-旋转-异或)步骤不断混合数据,从而产生所谓的 雪崩效应 avalanche effects(输入的微小变化会导致输出发生巨大且不可预测的变化)。最终结果是一个 32 位或 128 位整数。Elasticsearch 使用的是 32 位版本。
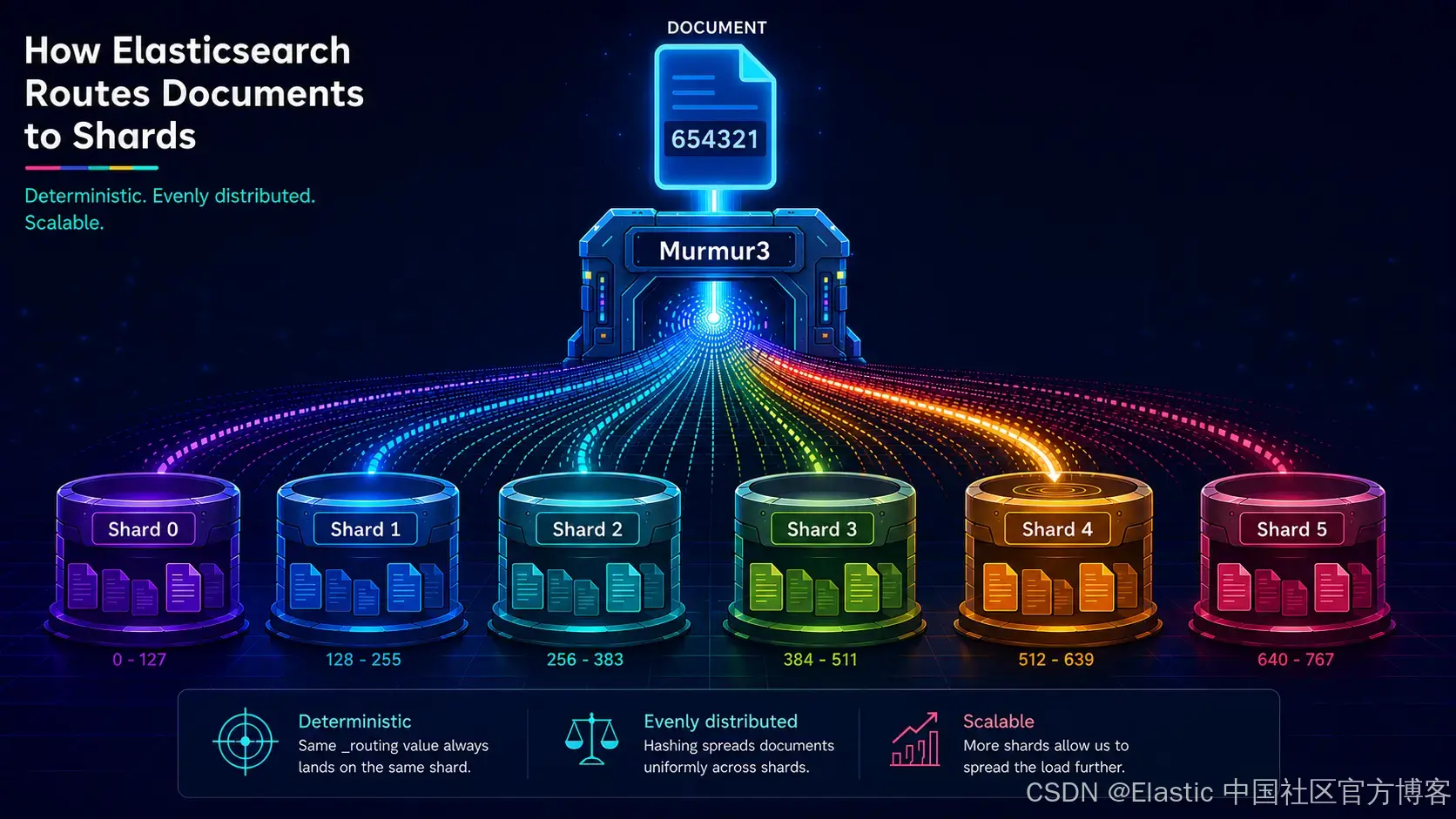
Elasticsearch 如何计算 shard number:一个完整示例
对于一个包含 6 个 shard 的 index,Elasticsearch 使用 768 个 routing shards,以及 128 的 routing factor。下面通过一个真实 document 来验证这一点。
创建一个包含 6 个 primary shards 的 index:
PUT test
{
"settings": {"number_of_shards": 6}
}检查默认设置,重点关注 index.number_of_routing_shards:
GET test?include_defaults&flat_settings对于 6 个 primary shards,响应会显示 index.number_of_routing_shards = 768。文档中对这个设置的描述是:
默认值的设计目的是允许你按 2 的倍数进行拆分,最多扩展到 1024 个 shards。
它在实际中的含义是:Elasticsearch 以 primary shard 的数量为起点,不断进行翻倍,直到再翻倍会超过 1024 为止。对于 6 个 primary shards:
6 × 1 = 6
6 × 2 = 12
6 × 4 = 24
6 × 8 = 48
6 × 16 = 96
6 × 32 = 192
6 × 64 = 384
6 × 128 = 768
6 × 256 = 1536 ← too high这为你提供了足够的 routing 空间,使索引的 primary shard 数量可以在不重新索引的情况下最多翻倍 7 次。
对于我们的 index:
num_primary_shards = 6
num_routing_shards = 768
routing_factor = 768 / 6 = 128现在索引一个 document:
PUT test/_doc/654321
{
"field": "value"
}检查它落到了哪个 shard 上:
GET _cat/shards/test?v它最终落在 shard 4。我们来验证一下原因。
逐步计算 MurmurHash3 分片路由公式
使用上述值(num_routing_shards = 768,routing_factor = 128,document ID 654321),分片计算如下:
shard_num = Math.floorMod(hash("654321"), 768) / 128在这一点上,我们终于需要回答文档没有明确说明的问题:hash() 到底是什么?
在 Elasticsearch 中,它就是 MurmurHash3。对于字符串 "654321",它的返回值是 1424940152。
Math.floorMod(1424940152, 768) = 632
632 / 128 = 4Shard 4,正是 Elasticsearch 放置它的位置。
如果你想用自己的 ID 验证这一点,可以使用下面这个小型 Java 脚本,它使用 Lucene 的 Murmur3 实现,在 Elasticsearch 之外计算相同的 shard number。先在 Elasticsearch 中索引一个 document,查看它落到哪个 shard,然后把同一个 ID 传入这个脚本运行,确认结果是否一致。
将其保存为 Murmur3Demo.java:
class run {
// MurmurHash3 x86_32 --- a fast non-cryptographic hash by Austin Appleby.
// These two constants were chosen empirically for their avalanche (bit-mixing) properties.
static final int C1 = 0xcc9e2d51;
static final int C2 = 0x1b873593;
static int murmurhash3(byte[] data, int seed) {
int len = data.length;
int h = seed;
// Mix in 4 bytes at a time (little-endian 32-bit words)
int blocks = len / 4;
for (int i = 0; i < blocks; i++) {
int k = (data[i*4 ] & 0xFF)
| (data[i*4+1] & 0xFF) << 8
| (data[i*4+2] & 0xFF) << 16
| (data[i*4+3] & 0xFF) << 24;
k *= C1;
k = Integer.rotateLeft(k, 15);
k *= C2;
h ^= k;
h = Integer.rotateLeft(h, 13);
h = h * 5 + 0xe6546b64;
}
// Mix in any leftover 1--3 bytes
int t = blocks * 4;
int k = 0;
if ((len & 3) == 3) k = (data[t+2] & 0xFF) << 16;
if ((len & 3) >= 2) k |= (data[t+1] & 0xFF) << 8;
if ((len & 3) >= 1) {
k |= (data[t] & 0xFF);
k *= C1;
k = Integer.rotateLeft(k, 15);
k *= C2;
h ^= k;
}
// fmix32: force all bits to fully avalanche before returning
h ^= len;
h ^= h >>> 16; h *= 0x85ebca6b;
h ^= h >>> 13; h *= 0xc2b2ae35;
h ^= h >>> 16;
return h;
}
public static void main(String[] args) {
String id = args[0];
int n = Integer.parseInt(args[1]);
// Elasticsearch encodes strings as UTF-16LE (2 bytes per char, low byte first)
byte[] bytes = new byte[id.length() * 2];
for (int i = 0; i < id.length(); i++) {
char c = id.charAt(i);
bytes[i*2 ] = (byte) c;
bytes[i*2+1] = (byte) (c >>> 8);
}
// To avoid modulo bias, Elasticsearch rounds n up to the next power-of-2 (r),
// takes floorMod(hash, r), then scales back down with / (r/n).
int r = n;
while (r * 2 <= 1024) r *= 2;
System.out.println(Math.floorMod(murmurhash3(bytes, 0), r) / (r / n));
}
}运行方式如下:
java Murmur3Demo.java 654321 6它会输出:
4这与上面的分片分配结果一致。
如果你的 index 在创建时显式设置了 index.number_of_routing_shards,请直接使用该值,而不是从 number_of_shards 推导。
Elasticsearch 源码:hash() 如何编码 routing 值
Elasticsearch 源代码 会在将 routing 值传入 MurmurHash3 之前,将其编码为 UTF-16LE。下面是相关方法:
public static int hash(String routing) {
assert assertHashWithoutInformationLoss(routing);
final int strLen = routing.length();
final byte[] bytesToHash = strLen * 2 <= MAX_SCRATCH_SIZE
? scratch.get()
: new byte[strLen * 2];
for (int i = 0; i < strLen; ++i) {
ByteUtils.LITTLE_ENDIAN_CHAR.set(bytesToHash, 2 * i, routing.charAt(i));
}
return hash(bytesToHash, 0, strLen * 2);
}这里有两个值得注意的点:
第一,routing value 是一个字符串,在进行 hash 之前,每个字符都会被写成一个 little-endian 的两字节序列。这就是为什么不能把 ID 当作 ASCII 来复现 hash:"654321" 会被编码成 12 个字节,而不是 6 个。
第二,这个函数返回的是一个有符号 32 位整数,但 Elasticsearch 会对结果使用 Math.floorMod,以避免出现负的 shard number。如果你要在其他语言中复现 routing 计算,一定要注意 signed / unsigned integer 的差异。
当 MurmurHash3 路由导致 hot shards 以及如何检查
对于大多数 workload,你不需要关心这些细节。使用自动生成的 document ID 写入时,Murmur3 的均匀分布会把数据很好地分散到各个 shard 上。真正容易出问题的是使用自定义 ID 或 routing value,并且这些值分布不均匀的情况。比如顺序整数、基于时间戳的值,或者具有明显模式的标识符,并不一定会导致 skew,但如果你观察到 hot shards,就值得检查。
hash 函数本身并不是问题来源:Murmur3 的设计目标就是均匀分布输入。但如果 shard 分布看起来异常,首先应该检查的是你的 ID 或 routing value 的选择。
如果你发现 hot shards,并且使用了自定义 ID,可以对一部分真实 ID 重复刚才对 "654321" 的计算过程:用 Murmur3 对每个 ID 计算 hash,然后应用 Math.floorMod(..., num_routing_shards),再除以 routing factor,看看它们最终分别落在哪些 shard 上。
为什么 Elasticsearch 不公开 hash 函数的名称
将实现细节隐藏在稳定接口之后,是一种良好的软件设计方式。routing 的计算公式是有文档说明且保证稳定的,但底层具体使用哪种 hash 函数则没有必要公开,因为它不依赖于这个实现细节;对几乎所有使用场景来说,关键在于文档能否均匀且一致地分布,而 Murmur3 正好可以做到这一点 ------ 无论你是否知道它的名字。
唯一的例外是在出现问题的时候。如果文档集中在某些 shard 上,而你又不知道 routing 的工作方式,你就很难开始排查。一旦你了解了这个公式以及背后的函数,从 "为什么这些 shard 变热(hot)?" 到得到具体答案之间,其实只差几行计算。
对大多数用户来说,这正是了解它是 Murmur3 的意义所在。现在你已经知道了。
原文:Why Elasticsearch shards go hot: MurmurHash3 explained - Elasticsearch Labs