FAST:基于频域压缩的通用视觉-语言-动作模型高效动作令牌化技术深度解析
论文信息
标题 :FAST: Efficient Action Tokenization for Vision-Language-Action Models
会议 :arXiv:2501.09747v1 cs.RO
单位 :Physical Intelligence, UC Berkeley, Stanford University
代码 :https://pi.website/research/fast(HuggingFace 模型库: physical-intelligence/fast)
论文:https://arxiv.org/pdf/2501.09747.pdf
一、引言:自回归VLA的"高频死穴"
视觉-语言-动作(VLA)模型是当前通用机器人的核心技术路线之一:把预训练大模型的语义能力迁移到机器人控制,靠语言指令就能驱动机器人完成各种任务。但长期以来,自回归架构的VLA(比如RT-2、OpenVLA)一直有个难以突破的瓶颈:在高频灵巧操作任务上几乎学不动。
问题的根源不在模型大小,也不在数据量,而在最基础的动作令牌化(Action Tokenization)环节。传统方案采用"逐维度、逐时间步分箱"的朴素离散化方法,把连续动作切成256个离散档位。在5Hz、10Hz的低频抓取任务上还能凑合,一旦到了50Hz的叠衣服、拧瓶盖这类灵巧任务,动作序列长度暴涨,相邻时间步的动作几乎一模一样,自回归模型的"预测下一个token"目标就变得毫无信息量------模型不用学任何规律,直接复制上一步的token就能拿到极低损失,最终陷入局部最优,啥也学不会。
本文提出的 FAST(Frequency-space Action Sequence Tokenization) 就是针对这个痛点的解决方案。它借鉴JPEG图像压缩的思路,先通过离散余弦变换(DCT)把时域动作信号转到频域,集中能量、去除冗余,再配合字节对编码(BPE)做无损压缩,把原本几百个token的动作序列压缩到几十个。
最终效果非常亮眼:
- 自回归VLA第一次能稳定学习50Hz的灵巧操作任务,性能追平扩散架构的VLA;
- 搭配π₀模型在1万小时的跨体数据集上预训练,性能和原版扩散π₀持平,训练速度提升5倍;
- 训练出的DROID策略首次实现了完全 unseen环境下的零样本泛化,换个学校的实验室也能直接干活。
图1展示了FAST带来的训练效率提升:
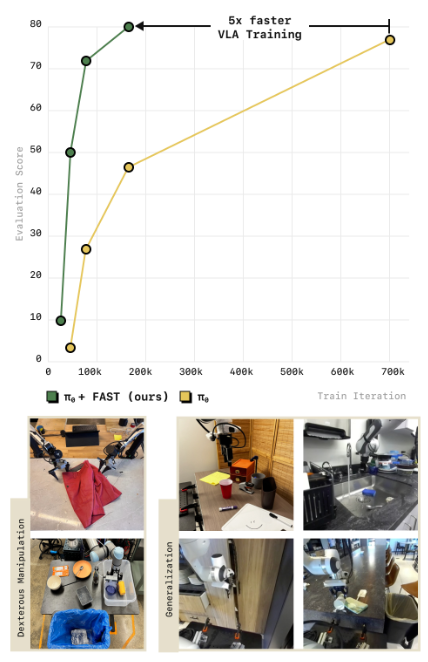
图1:π₀-FAST与扩散版π₀的训练收敛速度对比。在达到同等任务性能的前提下,FAST方案训练速度提升可达5倍。
出处:原文Figure 1
通俗解释:
传统动作令牌化就像让你逐像素临摹一幅画,分辨率越高越费劲,而且相邻像素几乎一样,画着画着就开始机械复制,根本抓不住整体形状。FAST就像先提取轮廓和主要色块,不管分辨率多高,都能用很少的信息抓住核心动作,模型学起来又快又准。
二、追根溯源:为什么朴素分箱在高频下彻底失效?
2.1 问题形式化定义
我们的目标是训练策略 π(a1:H∣o)\pi(a_{1:H} | o)π(a1:H∣o):给定观测 ooo,输出长度为 HHH 的未来动作序列(动作chunk)。动作令牌化的本质是定义一个连续到离散的映射:
Ta:a1:H→T1,T2,...,Tn T_{a}: a_{1:H} \to T_1, T_2, ..., T_n Ta:a1:H→T1,T2,...,Tn
符号逐一解释:
- TaT_aTa:动作令牌化映射函数,输入连续动作,输出离散令牌序列
- a1:Ha_{1:H}a1:H:长度为 HHH 的连续动作chunk,每个时间步包含 ∣A∣|A|∣A∣ 个动作维度(比如关节角度、夹爪开度、底盘速度)
- T1,T2,...,TnT_1, T_2, ..., T_nT1,T2,...,Tn:输出的离散令牌序列,每个令牌来自大小为 ∣V∣|V|∣V∣ 的固定词表
- nnn:令牌总数,随动作内容变化,和文本分词的变长特性一致
传统朴素分箱方案的做法很直接:每个时间步、每个维度单独离散化,均匀切成 N=256N=256N=256 个区间。最终token总数为 H×∣A∣H \times |A|H×∣A∣,和时间步长成正比。
2.2 玩具实验:频率越高,误差越离谱
为了直观验证tokenization的影响,论文做了一个极简的对照实验:让自回归Transformer预测一条三次样条曲线,其他条件完全不变,只改变曲线的采样频率。
结果如图3所示:
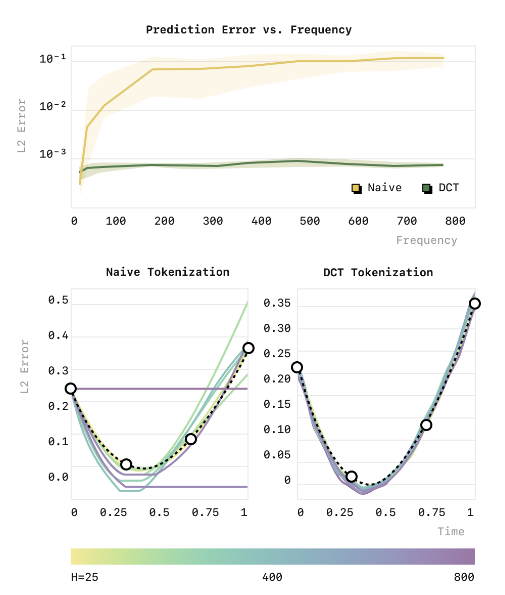
图3:不同采样频率下的预测误差对比。左:朴素分箱方案随频率升高误差急剧上升,最终退化为复制初始值;右:基于DCT的FAST方案在所有采样频率下都保持稳定的低误差。
出处:原文Figure 3
可以看到:
- 朴素分箱方案:采样率从25升到800,预测误差指数级上涨,到最后模型直接摆烂------输出一条水平线,完全复制第一个点的值。
- DCT方案:不管采样率多高,预测误差都很低,曲线拟合得非常好。
2.3 底层逻辑:边际信息量归零
自回归模型的训练目标是"给定前面所有token,预测下一个token",学习信号的强度和下一个token的边际信息量成正比。
对于平滑的动作信号,采样频率越高,相邻两步的差异就越小。当频率高到一定程度,下一个token几乎和上一个完全一样,边际信息量趋近于0。模型不用学任何运动规律,直接把上一步的token抄过来就能拿到极低的损失,最终卡在很差的局部最优里。
这也解释了为什么OpenVLA在低频的BridgeV2数据集上表现不错,但到了频率更高的DROID数据集就训不动------不是模型不行,是tokenization拖了后腿。
通俗解释:
这就像你听0.5倍速的慢歌,每个字都清晰可辨,你能轻松接上下一句歌词;但如果加速到10倍速,每个字都和上一个粘在一起,你根本听不出区别,只能瞎蒙。自回归模型在高频动作上遇到的就是这个问题。
三、FAST核心算法:频域压缩+熵编码的组合拳
3.1 核心设计思路
FAST的核心洞察很朴素:连续动作信号冗余度极高,先压缩再令牌化。
机器人的动作大多是平滑的,不会突然跳变,时域上相邻点高度相关。而频域变换能把能量集中在少数低频系数上,高频分量都是细微抖动,大部分可以舍弃。这和JPEG压缩图片的原理一模一样:人眼对低频的色彩、轮廓敏感,对高频细节不敏感,丢掉高频信息几乎不影响观感,还能大幅压缩体积。
FAST把这个思路搬到了动作信号上:用时域压缩去除冗余,让每个token都携带足量信息,自回归模型才能真正学到东西。
3.2 完整流水线详解
FAST的完整处理流程如图4所示,一共5步,所有步骤都可逆,解码速度极快:
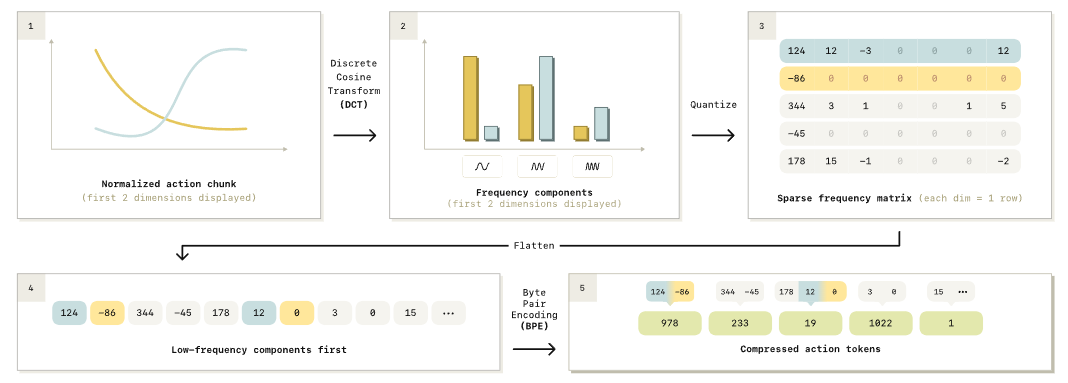
图4:FAST动作令牌化完整流程。从归一化的动作chunk出发,经DCT频域变换、系数量化、低频优先展平、BPE压缩,最终输出稠密的动作令牌。
出处:原文Figure 4
步骤1:分位数归一化
首先对每个动作维度做归一化,用训练集的1%和99%分位数把数值映射到 −1,1-1, 1−1,1 区间。
- 用分位数而不用最大最小值,是为了抗离群点,避免偶尔的异常动作把整个归一化范围拉偏;
- 统一到相同区间也方便跨机器人、跨数据集的混合训练。
步骤2:逐维DCT变换
对每个动作维度单独做离散余弦变换(DCT-II),把时域信号转到频域。
- 低频系数:对应动作的整体趋势、大的运动轨迹,是核心信息;
- 高频系数:对应细微抖动、噪声,占比很小,可以压缩。
变换之后,大部分系数都接近0,能量集中在前几个低频分量上,天然具备了稀疏性。
步骤3:系数量化
把DCT系数乘以缩放因子 γ\gammaγ 后取整,完成连续到离散的转换。
- γ\gammaγ 是唯一的核心超参数,越大精度越高、token越多,越小压缩率越高、精度越低;
- 论文默认用 γ=10\gamma=10γ=10,在重建精度和压缩率之间取得了很好的平衡。
步骤4:低频优先展平
把 ∣A∣×H|A| \times H∣A∣×H 的系数矩阵展平成一维向量,这里有个关键设计:按频率维度优先排列,先放所有动作维度的第0阶低频系数,再放第1阶,依次类推。
这么设计是为了适配自回归从左到右的预测顺序:模型先预测所有维度的整体运动趋势,再逐步补充细节,和人类做动作的逻辑一致,策略部署时更稳定。
步骤5:BPE无损压缩
量化后的系数非常稀疏,大部分都是0,直接当token用还是很浪费。因此论文再用字节对编码(BPE)做一次无损压缩:
- 合并频繁出现的系数组合,把大量重复的零值合并成单个token;
- 最终生成固定大小的词表,可以直接替换VLM词表里的低频token,不用改模型结构。
通俗解释:
这一步就像把文章里反复出现的"的""了""是"合并成更短的符号,进一步压缩篇幅,而且完全不损失信息。BPE是大语言模型的标准操作,这里直接复用,兼容性拉满。
3.3 重建精度与压缩率的权衡
所有离散化方案都存在"压缩率"和"重建精度"的权衡,论文对比了FAST、朴素分箱、FSQ三种方案在不同数据集上的表现,如图12所示:
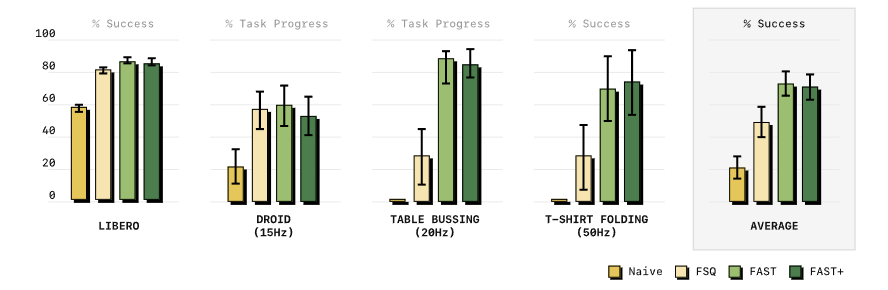
图6:不同令牌化方案的压缩率-重建精度权衡曲线。FAST在高精度区域优势显著,更适合对控制精度要求高的机器人任务。
出处:原文Figure 6
结论很明确:
- 低精度、高压缩率场景下,FSQ等学习式量化方法略有优势;
- 高精度区域(机器人控制的核心需求),FAST的表现远超其他方案,能用更少的token达到更高的重建精度。
四、FAST+:开箱即用的通用动作令牌化器
如果每次换数据集都要重新训BPE词表,还是有点麻烦。论文直接放出了FAST+:一个在百万级真实机器人轨迹上预训练好的通用动作令牌化器,拿来就能用,不用自己训。
4.1 训练数据
FAST+在约100万条1秒动作chunk上训练,数据覆盖极其全面:
- 机器人形态:单臂、双臂、移动操作臂、灵巧手、人形机器人;
- 动作空间:关节空间、末端世界坐标系、末端相机坐标系;
- 控制频率:从5Hz到60Hz全覆盖。
所有动作统一补零到32维,兼容不同维度的动作空间。
4.2 极简调用方式
官方提供了HuggingFace格式的封装,三行代码就能完成令牌化:
python
from transformers import AutoProcessor
tokenizer = AutoProcessor.from_pretrained("physical-intelligence/fast", trust_remote_code=True)
tokens = tokenizer(action_chunk)也可以在自己的数据集上继续微调,生成专属tokenizer:
python
new_tokenizer = tokenizer.fit(custom_action_dataset)4.3 跨域通用性验证
论文在14个完全没见过的数据集上测试了FAST+的压缩率,覆盖单臂、灵巧手、人形、自动驾驶等完全不同的领域,结果如图8所示:
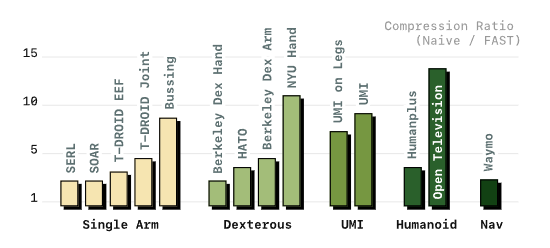
图8:FAST+通用令牌化器在各类未见数据集上的压缩倍率。所有场景下都能实现2倍以上压缩,高频灵巧场景提升更显著。
出处:原文Figure 8
所有数据集都实现了2倍以上的压缩,高频灵巧场景甚至能到10倍以上。这说明FAST+学到了通用的动作压缩规律,不是只在某一类机器人上好用。
通俗解释:
FAST+就像一个万能压缩软件,不管是文档、图片、视频还是安装包,都能给你压得又小又准,不用针对每种文件格式单独调参数,开箱即用。
五、全方位实验验证
5.1 实验设置
- 模型骨干:主实验用π₀(PaliGemma-3B),消融实验用OpenVLA(Prismatic 7B);
- 评测任务 :共7个,覆盖仿真到真实、低频到高频、简单到复杂:
- Libero(仿真,多任务操作)
- 收桌子(20Hz,单臂UR5,12个物体分类收纳)
- 叠T恤(50Hz,双臂ARX,衣物折叠)
- 装购物袋(20Hz,单臂UR5)
- 烤面包机取吐司(50Hz,双臂Trossen)
- 叠衣服(50Hz,双臂ARX,从筐里取衣+折叠+堆叠)
- DROID零样本泛化(15Hz,未见环境桌面操作)
- 对比方法:朴素分箱、FSQ有限标量量化、数据集专属FAST、通用FAST+
5.2 压缩率对比
首先看最直观的token数量对比,在重建精度相当的前提下,FAST的压缩效果如表1所示:
| 数据集 | 动作维度 | 控制频率 | 朴素分箱token数 | FAST token数 | 压缩倍率 |
|---|---|---|---|---|---|
| BridgeV2 | 7 | 5 Hz | 35 | 20 | 1.75 |
| DROID | 7 | 15 Hz | 105 | 29 | 3.6 |
| 收桌子 | 7 | 20 Hz | 140 | 28 | 5.0 |
| 叠T恤 | 14 | 50 Hz | 700 | 53 | 13.2 |
表1:朴素分箱与FAST的平均token数对比(1秒动作chunk)
出处:原文Table I
结果分析:
- 频率越高,压缩收益越大:50Hz的叠T恤任务直接压缩了13.2倍,从700个token降到53个,效果极其显著。
- token数稳定:单臂任务稳定在30个token左右,双臂在60个左右,和控制频率关系不大。这说明FAST提取的是动作的本质复杂度,不是简单按采样率线性增长。
5.3 策略性能对比
不同令牌化方案训练出的策略实际表现如图6所示:
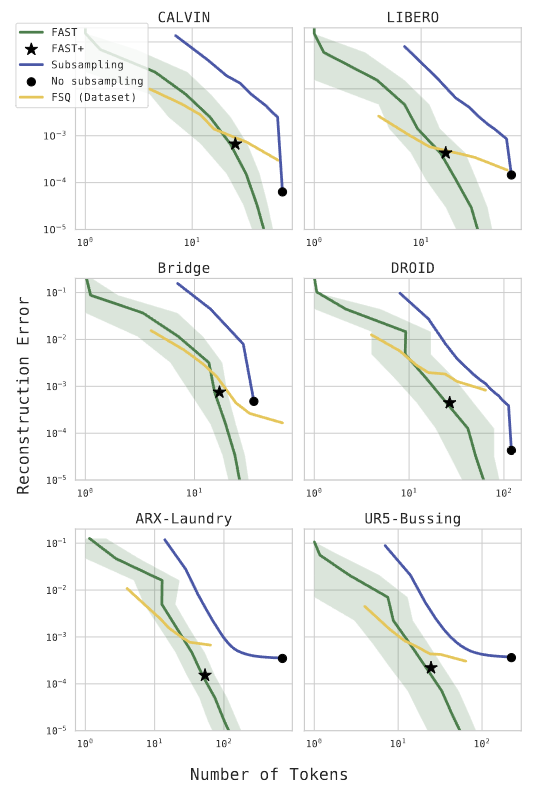
图12:四类任务下不同令牌化方案的策略性能对比。朴素分箱在高频任务上完全无法收敛,FAST全面领先,通用版FAST+和数据集专属版性能接近。
出处:原文Figure 12
核心结论:
- 朴素分箱在高频任务直接失效:20Hz的收桌子、50Hz的叠T恤任务上,朴素分箱训练的策略任务进度为0,完全学不会。
- FAST全面优于FSQ:哪怕和学习式量化方法比,FAST在灵巧任务上的表现也更好,而且不需要额外训练量化网络,简单得多。
- 通用tokenizer够用:FAST+和在单个数据集上专门训练的FAST性能几乎持平,说明通用版完全可以开箱即用,不用额外调优。
5.4 DROID零样本泛化突破
FAST的另一个重磅成果是:第一次在DROID数据集上训出了能纯零样本部署的策略。
之前的DROID相关工作都只能在共训练环境或者微调后测试,而用FAST训练的策略,直接拿到三个完全没见过的大学校园实验室(伯克利、斯坦福、华盛顿大学),靠自然语言指令就能执行任务,如图7所示:

图7:DROID策略零样本跨环境测试。同一模型在三所不同大学的实验室中直接部署,无需微调即可执行各类桌面操作任务。
出处:原文Figure 7
策略能完成抓取放置、开关抽屉、开水龙头、擦桌子等基础操作,哪怕失败的尝试,也会正确伸向把手等目标位置,行为逻辑非常合理。
5.5 消融实验
5.5.1 和模型骨干无关
论文在OpenVLA上也做了测试:原本在叠T恤任务上完全学不会的OpenVLA,换上FAST tokenization之后性能暴涨。
这说明FAST是通用方案,不绑定特定VLA骨干,任何自回归Transformer架构都能直接用。
5.5.2 BPE模块的作用
去掉BPE之后,策略性能会下降,但依然远好于朴素分箱。
原因很直观:DCT已经完成了核心的信息压缩,但大量重复的零token会稀释学习信号,还会拖慢推理速度。BPE把冗余的零值合并,既提升了学习效率,又加快了推理。
5.6 和扩散VLA正面PK
之前大家普遍认为"自回归VLA做不了灵巧任务,扩散架构才是正道",FAST直接推翻了这个结论。论文把π₀-FAST和原版扩散π₀做了全面对比,结果如图9所示:
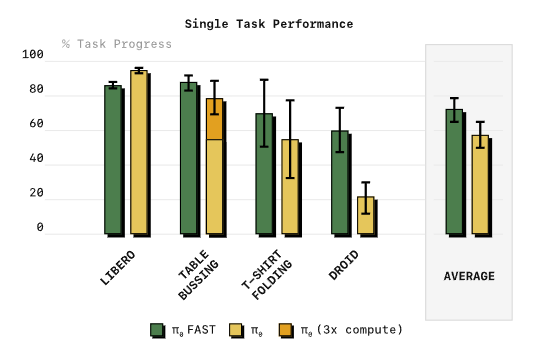
图9:自回归FAST方案与扩散π₀的单任务性能对比。小数据集两者持平,大数据集FAST收敛更快,且语言跟随能力更强。
出处:原文Figure 9
具体对比:
- 小数据集(<50小时):两者性能差不多,打个平手;
- 大数据集:FAST收敛速度快3倍,用更少的训练步数就能达到高性能;
- 语言跟随能力:FAST的自回归架构更听指令,在DROID任务上扩散模型经常忽略语言描述,得分更低;
- 推理速度:扩散版更快,RTX 4090上约100ms出结果;FAST要约750ms,因为需要自回归生成几十个token,且用的是全量3B参数骨干。
5.7 万小时级大规模预训练
最重磅的缩放实验:用π₀的完整10k小时跨体数据集(9.03亿时间步,覆盖7种机器人、68个任务)训练π₀-FAST,和原版扩散π₀比零样本性能。
结果如图11所示:
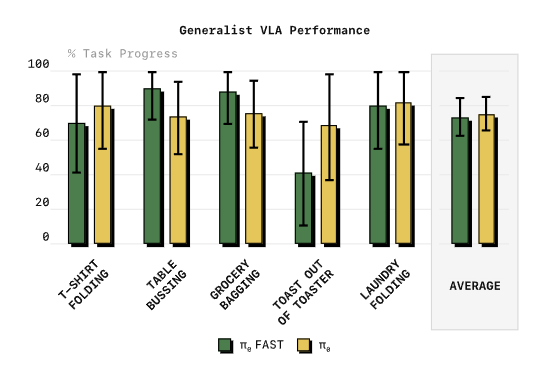
图11:大规模预训练后的零样本任务性能对比。π₀-FAST与扩散版π₀性能基本持平,包括难度最高的叠衣服任务。
出处:原文Figure 11
π₀-FAST在所有任务上都追平了扩散版π₀的性能,哪怕是最难的叠衣服任务也不落下风。而训练所需的GPU小时数只有扩散版的1/5,训练效率提升5倍。
如果用相同的训练算力对比(算力对齐),π₀-FAST的性能会显著超过扩散版,如图15所示:
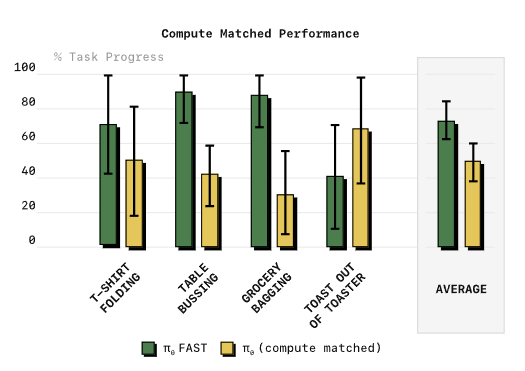
图15:相同训练算力下的性能对比。π₀-FAST凭借更快的收敛速度,在同等算力下性能明显优于扩散VLA。
出处:原文Figure 15
图10是π₀-FAST执行叠衣服任务的实拍效果,动作流畅度和完成度都和扩散模型没有区别:
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/666d9e9703b04979ade44c05c8b3711b.png#pic_center)
图10:π₀-FAST执行衣物折叠任务的实际效果。FAST让自回归VLA首次具备了复杂长时序灵巧操作的能力。
出处:原文Figure 10
六、核心代码实现
以下是FAST令牌化核心逻辑的简化Python实现,覆盖归一化、DCT变换、量化、展平、解码全流程,便于理解核心原理:
python
import numpy as np
from scipy.fft import dct, idct
class FASTTokenizer:
def __init__(self, action_dim=7, chunk_len=50, scale=10.0,
quantile_low=0.01, quantile_high=0.99):
"""
FAST动作令牌化器简化实现
Args:
action_dim: 动作空间维度数
chunk_len: 动作chunk的时间步长度
scale: DCT系数量化缩放因子 γ
quantile_low / quantile_high: 归一化分位数,抗离群点
"""
self.action_dim = action_dim
self.chunk_len = chunk_len
self.scale = scale
self.quantile_low = quantile_low
self.quantile_high = quantile_high
self.norm_min = None
self.norm_max = None
def fit_normalizer(self, action_dataset):
"""在数据集上统计归一化参数"""
all_actions = np.concatenate([seq.reshape(-1, self.action_dim)
for seq in action_dataset], axis=0)
self.norm_min = np.quantile(all_actions, self.quantile_low, axis=0)
self.norm_max = np.quantile(all_actions, self.quantile_high, axis=0)
def normalize(self, actions):
"""将动作映射到 [-1, 1] 区间"""
normed = 2 * (actions - self.norm_min) / (self.norm_max - self.norm_min) - 1
return np.clip(normed, -1, 1)
def denormalize(self, normed_actions):
"""反归一化回原始动作空间"""
actions = (normed_actions + 1) / 2 * (self.norm_max - self.norm_min) + self.norm_min
return actions
def encode(self, action_chunk):
"""
编码:连续动作 → 量化DCT系数(低频优先展平)
Args:
action_chunk: [chunk_len, action_dim] 原始连续动作
Returns:
flat_coeffs: 展平后的整数量化系数
"""
# 1. 归一化
normed = self.normalize(action_chunk)
# 2. 逐维度做DCT-II变换
dct_coeffs = np.zeros_like(normed)
for d in range(self.action_dim):
dct_coeffs[:, d] = dct(normed[:, d], type=2, norm='ortho')
# 3. 缩放 + 量化取整
quantized = np.round(self.scale * dct_coeffs).astype(int)
# 4. 低频优先展平:先遍历频率,再遍历维度
flat_coeffs = []
for freq_idx in range(self.chunk_len):
for dim_idx in range(self.action_dim):
flat_coeffs.append(quantized[freq_idx, dim_idx])
return np.array(flat_coeffs)
def decode(self, flat_coeffs):
"""
解码:量化DCT系数 → 连续动作
Args:
flat_coeffs: 展平的整数量化系数
Returns:
action_chunk: [chunk_len, action_dim] 重建的连续动作
"""
# 1. 恢复二维矩阵形状
quantized = np.zeros((self.chunk_len, self.action_dim), dtype=int)
idx = 0
for freq_idx in range(self.chunk_len):
for dim_idx in range(self.action_dim):
quantized[freq_idx, dim_idx] = flat_coeffs[idx]
idx += 1
# 2. 反量化
dct_coeffs = quantized / self.scale
# 3. 逐维度反DCT
normed = np.zeros_like(dct_coeffs)
for d in range(self.action_dim):
normed[:, d] = idct(dct_coeffs[:, d], type=2, norm='ortho')
# 4. 反归一化
action_chunk = self.denormalize(normed)
return action_chunk
# -------------------
# 使用示例
# -------------------
if __name__ == "__main__":
# 模拟 7维、50Hz、1秒动作chunk
tokenizer = FASTTokenizer(action_dim=7, chunk_len=50, scale=10.0)
# 生成演示平滑动作
t = np.linspace(0, 2 * np.pi, 50)
demo_action = np.stack([np.sin(t + i * 0.5) for i in range(7)], axis=1)
tokenizer.fit_normalizer([demo_action])
# 编码
coeffs = tokenizer.encode(demo_action)
print(f"原始动作形状: {demo_action.shape} (共{50*7=350}个数值)")
print(f"量化后系数长度: {len(coeffs)}")
print(f"非零系数占比: {np.count_nonzero(coeffs) / len(coeffs):.1%}")
# 解码重建
recon_action = tokenizer.decode(coeffs)
mse = np.mean((demo_action - recon_action) ** 2)
print(f"动作重建MSE: {mse:.6f}")代码说明:
上述实现覆盖了FAST的核心DCT压缩与量化逻辑,BPE词表训练部分因依赖词表优化过程未纳入简化版。实际工程使用建议直接调用官方HuggingFace实现,包含完整的BPE编解码与预训练词表。
七、总结与展望
核心贡献
- 找到了问题根源:明确指出朴素分箱令牌化导致的"边际信息量归零",是自回归VLA在高频灵巧任务上失效的核心原因,而非自回归架构本身不行。
- 提出了简洁高效的方案:FAST基于DCT+BPE的频域压缩思路,无需修改模型结构,能直接接入任何自回归VLA,大幅提升训练效率和最终性能。
- 放出了通用开箱工具:FAST+通用令牌化器在百万轨迹上预训练,覆盖多种机器人形态与动作空间,拿来就能用。
- 验证了自回归路线的潜力:在万小时级预训练规模下,自回归VLA能达到和扩散VLA持平的性能,训练速度还快5倍,为通用机器人基础模型提供了更高效的技术路线。
局限与未来方向
- 推理速度优化:目前自回归推理比扩散慢,未来可以复用大语言模型的加速技巧,比如投机解码、量化、自定义推理核,提升实时性。
- 更多形态落地:目前主要在桌面操作机器人上验证了策略效果,灵巧手、人形机器人、自动驾驶等领域的实际策略表现还有待验证。
- 架构融合探索:压缩式令牌化和扩散架构并非互斥,两者结合或许能同时兼顾训练效率和推理速度。
- 更优压缩算法:DCT只是起点,小波变换、深度学习压缩等方案都有可能进一步提升压缩率和精度。
总的来说,FAST本质上补上了自回归机器人基础模型最关键的一块拼图------好的动作"分词器"。就像BPE让大语言模型实现了规模化腾飞一样,高效的动作令牌化也会让通用机器人模型的训练效率迈上新的台阶。