一、视频元数据好看,但不好稳定拿
做视频搜索、内容监测或者训练数据准备时,第一步通常不是模型,也不是搜索算法,而是先拿到一批质量稳定的视频元数据。
比如我们想做一个个人视频搜索引擎,输入关键词 Cristiano,系统可以返回相关视频的标题、描述、播放量、时长、上传者和视频链接。听起来很简单,但真正做起来会发现,视频平台页面结构经常变化,不同入口返回的信息也不一样:频道页、搜索页、标签页、播放页,每个页面的数据组织方式都不同。
如果自己做这件事,通常会有几种方案。
第一种是自己写数据采集工具,直接解析 YouTube 页面。优点是灵活,想采什么字段都可以控制;缺点是页面结构变化频繁,搜索页、频道页、播放页的数据组织方式并不一致,维护成本会很高。
第二种是使用平台官方 API。优点是稳定、合规、字段清晰;缺点是配额、权限和可获取字段会受到限制,有些场景还需要额外申请,前期验证不一定方便。
第三种是使用通用网页采集工具。优点是上手快,适合一次性导出数据;缺点是如果要持续跑批量任务、查看任务状态、下载结构化结果,还需要自己补很多工程逻辑。
所以在视频搜索引擎这个场景里,更适合的是任务化的视频数据采集 API:提交 URL 或关键词后,由系统完成采集任务,并返回结构化结果。本文就用 Dataify API 做一个实际演示:
dataify官网链接:https://dataify.com?utm_source=yhjsgzs&utm_term=01
整体流程如下:
plain
Dataify API Token
↓
YouTube 视频采集工具
↓
URL / 关键词采集
↓
JSON / CSV / XLSX 结果
↓
字段清洗
↓
Elasticsearch
↓
个人视频搜索引擎二、为什么适合做视频搜索引擎的数据入口
在个人视频搜索引擎这个场景里,我们最关心的不是单个视频页面能不能打开,而是能不能稳定拿到一批结构化字段。
搜索系统需要的字段通常很固定:
plain
title
description
url
thumbnail
viewCount
date
likes
channelName
channelUrl
duration
subtitles
resolution
success
input
error_code这些字段里,title 和 description 用来做全文检索,url 用来跳转原始视频,viewCount、likes、duration 可以作为排序或筛选条件,channelName 和 channelUrl 可以用于频道维度聚合。
对比自己写数据采集工具、直接调用官方 API 或使用通用采集工具,Dataify 更适合作为这个场景的数据入口,主要体现在三个点。
第一是任务化处理。 开发者提交一个 URL 或关键词后,系统会创建任务,任务完成后再下载结果。这样比一次性在终端里等待数据返回更适合批量场景,也方便在后台查看状态、成功率、文件大小和积分消耗。
第二是多入口支持。 同样是视频数据,有时候我们需要采集指定频道的视频列表,有时候需要按关键词获取一批候选视频,有时候还需要按标签、搜索过滤器、评论或字幕继续扩展。Dataify 把这些入口拆成不同工具,调用时只需要切换对应参数。
第三是结果结构化。 采集完成后可以直接下载 JSON、CSV 或 XLSX。对于开发者来说,JSON 适合进入后端流程,CSV 适合导入 Elasticsearch、PostgreSQL 或 ClickHouse,XLSX 则适合给业务同事直接查看。
所以这篇文章后面的实践会分两步走:
plain
先用 URL 采集 C 罗频道视频,验证字段是否完整
↓
再用关键词 Cristiano 批量获取 100 条视频数据
↓
下载 CSV / XLSX 结果
↓
把标题和描述写入 Elasticsearch
↓
实现个人视频搜索这种路线比较适合从零开始验证项目。先小批量跑通,再扩大关键词数量和数据规模。
三、上手实践:从 Token 到 C 罗视频数据采集
上面几种方案里,如果只是做一次性实验,自己写脚本或手工整理也能完成。但如果目标是后续持续采集不同频道、不同关键词,并且希望结果可以直接进入搜索或分析流程,任务化 API 会更省维护成本。
所以接下来用 Dataify 做一个完整链路演示:从获取 Token,到采集 C 罗频道视频,再到关键词批量采集。
- 开通账户并获取 API Token
进入 Dataify 后台,在「设置 → Token 管理」里可以查看和新增 API Token。
Token 用于接口鉴权,建议放在环境变量里:
python
export DATAIFY_TOKEN="你的_API_TOKEN"不要把真实 Token 写进代码仓库,也不要放在公开文章截图里。
通过 URL 采集频道视频
进入:
plain
网页数据采集 → 网页采集商店 → YouTube视频帖子采集工具 → 通过URL采集可以看到配置区域和右侧自动生成的 cURL 请求。
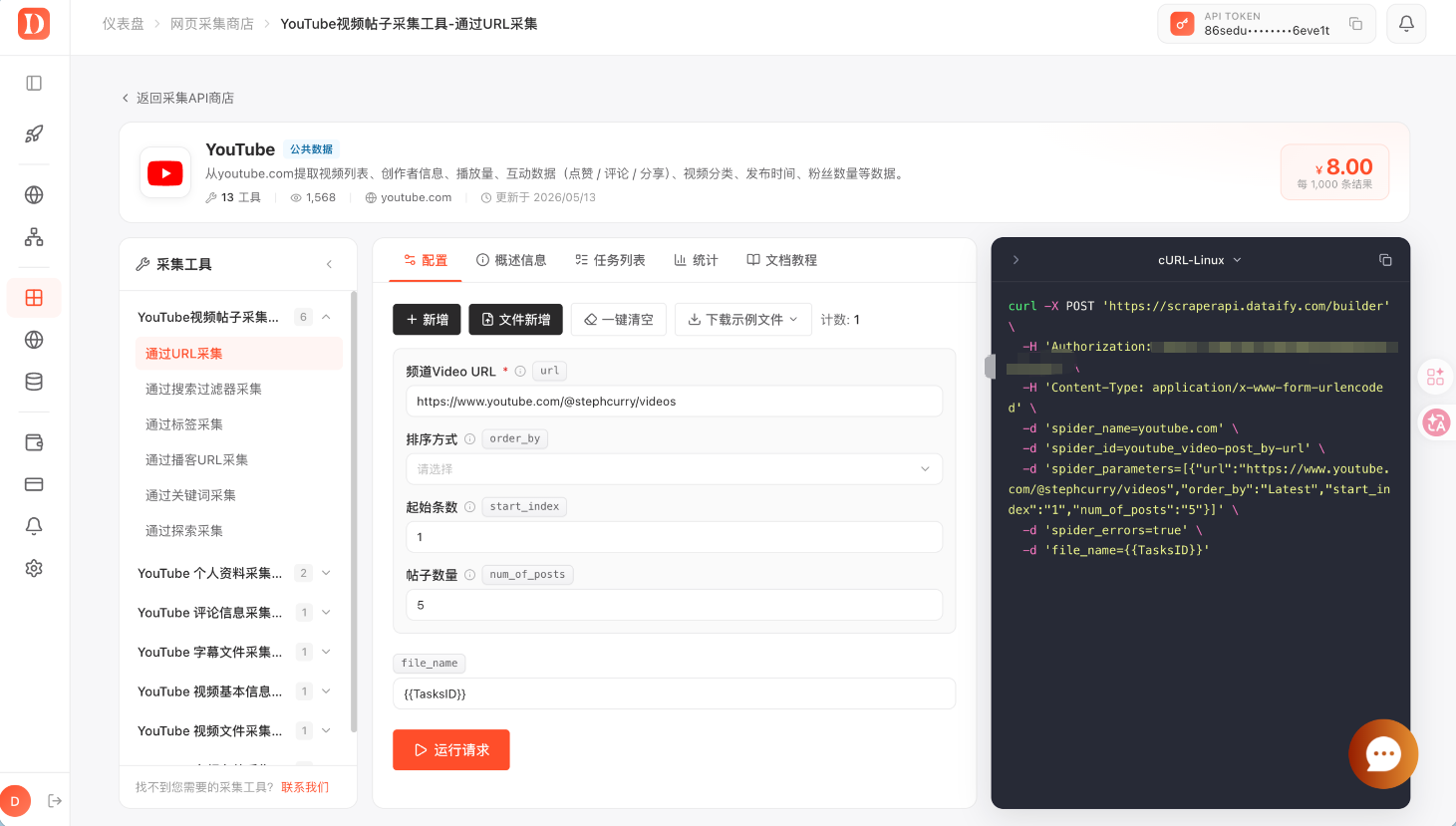
URL 采集适合处理某个频道的视频列表,例如:
python
https://www.youtube.com/@stephcurry/videos点击运行后,任务不会立即在页面上展开所有数据,而是会进入任务列表。
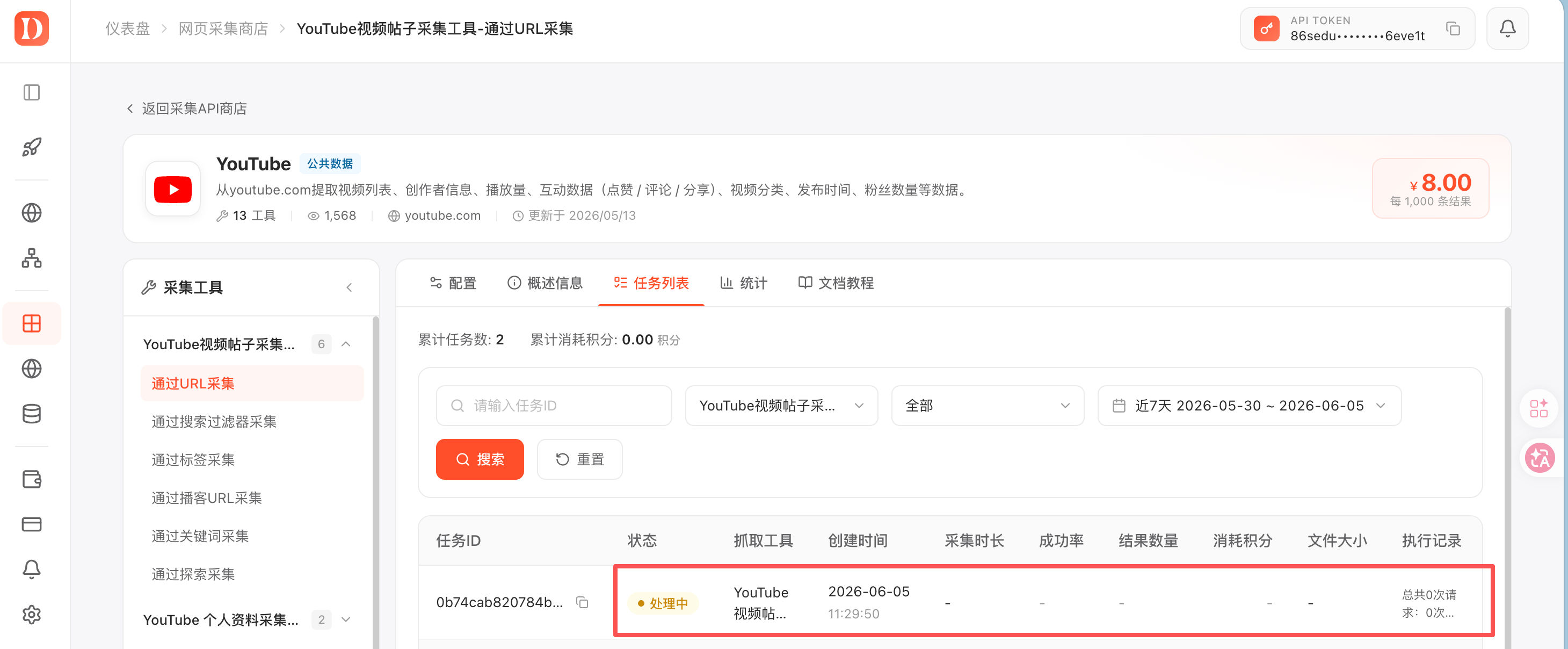
以 C 罗频道为例采集视频数据
打开 YouTube,搜索 C 罗,可以进入他的官方频道页面。
为了获取频道视频列表,建议使用频道视频页:
plain
https://www.youtube.com/@cristiano/videos在 Dataify 中把 URL 换成 C 罗频道地址,并设置采集数量为 10。
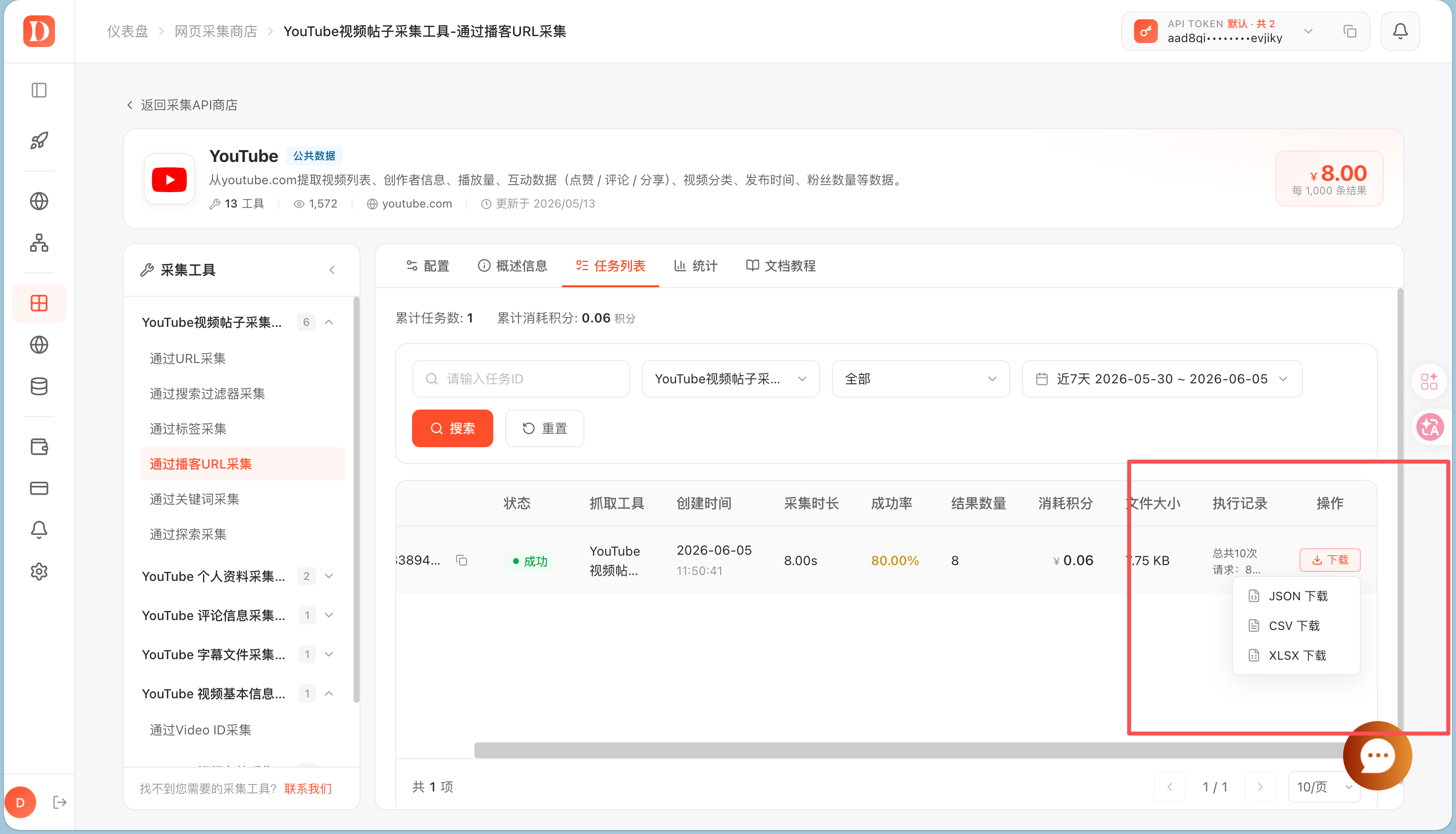
运行完成后,可以在任务列表看到任务状态、成功率、结果数量和消耗积分。结果支持三种下载方式:
- JSON 下载
- CSV 下载
- XLSX 下载
下载后的表格结果如下:
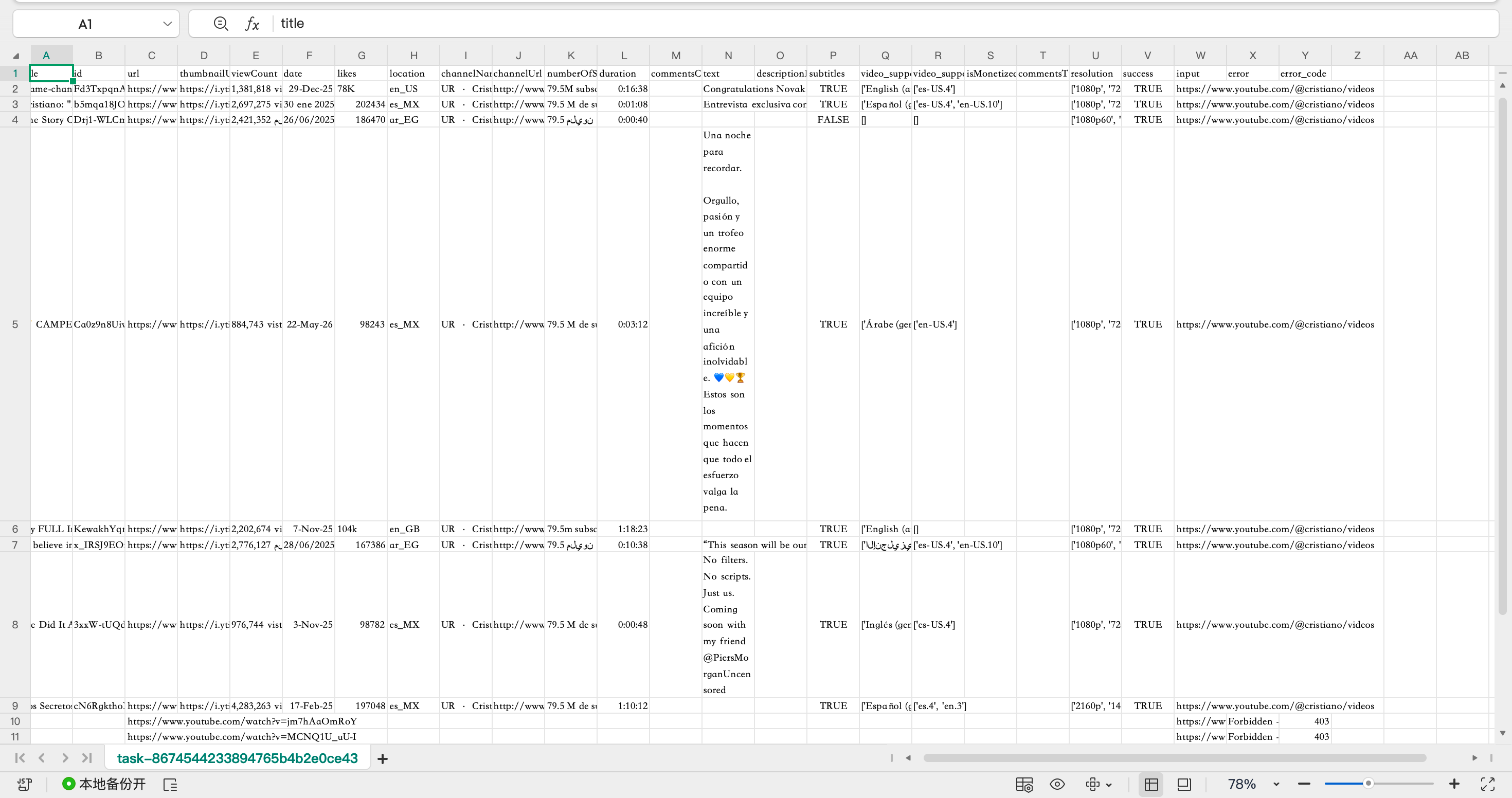
可以看到,结果已经整理成结构化字段,包括:
| 字段 | 说明 |
|---|---|
| title | 视频标题 |
| id | 视频 ID |
| url | 视频地址 |
| thumbnail | 缩略图 |
| viewCount | 播放量 |
| date | 发布时间 |
| likes | 点赞数 |
| channelName | 上传者 / 频道名 |
| channelUrl | 频道地址 |
| duration | 视频时长 |
| description | 视频描述 |
| subtitles | 是否包含字幕 |
| resolution | 分辨率 |
| success | 当前记录是否成功 |
| input | 本次输入参数 |
| error_code | 错误码 |
这些字段后续可以直接进入搜索、分析或训练数据处理流程。
通过关键词批量获取视频元数据
除了频道 URL,也可以使用关键词采集。比如输入:
plain
Cristiano并设置采集数量:
plain
100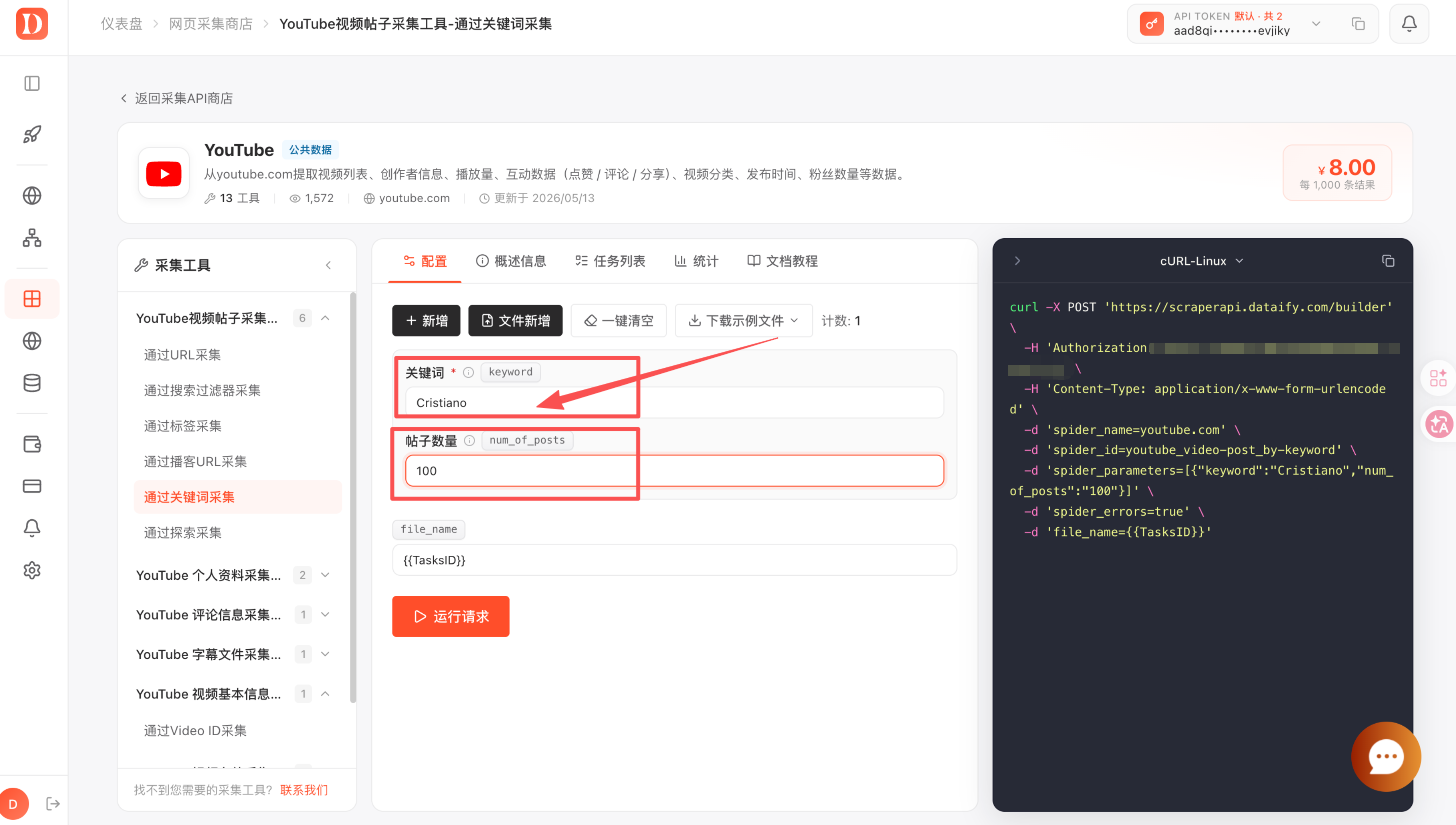
对应的核心参数是:
plain
[
{
"keyword": "Cristiano",
"num_of_posts": "100"
}
]任务完成后,可以看到成功采集了有效结果:
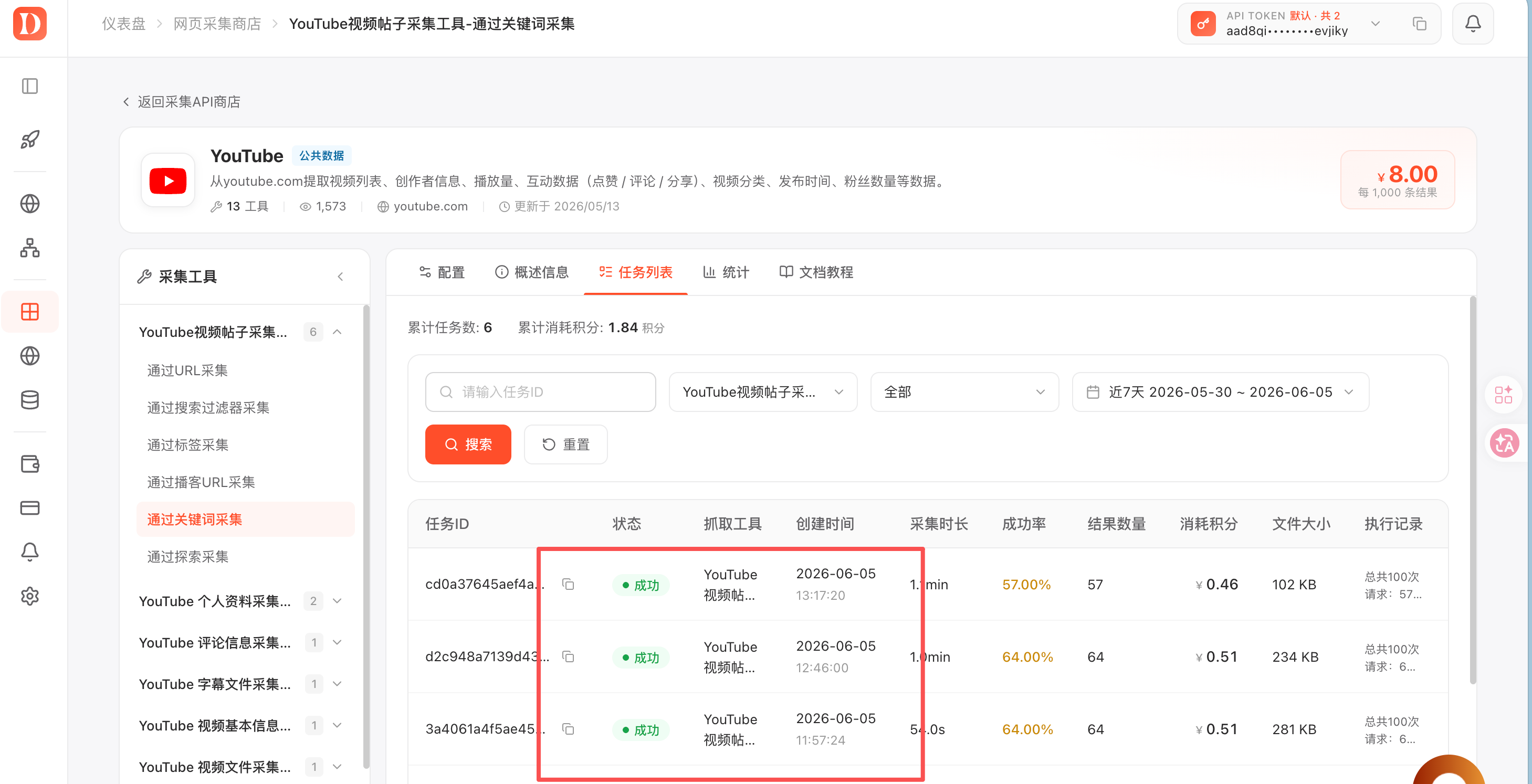
下载后的结果如下:

从截图可以看到,关键词任务请求 100 条数据,实际返回了几十条有效结果,积分消耗不到 1 个。对于前期验证、搭建 demo、做小批量数据分析来说,这个成本比较容易接受。
四、代码接入:把下载结果写入 Elasticsearch
上一步已经拿到了 CSV 或 XLSX 结果。接下来要做的是把数据写入 Elasticsearch,让标题和描述可以被检索。
这里推荐先用 CSV,因为处理最简单。
安装依赖
python
pip install pandas elasticsearch启动 Elasticsearch
本地测试可以用 Docker:
python
docker run -d \
--name video-es \
-p 9200:9200 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
elasticsearch:8.13.4检查服务是否正常:
python
curl http://localhost:9200导入 CSV
假设从 Dataify 下载的文件名是:
python
cristiano_videos.csv新建 import_to_es.py:
python
import hashlib
import pandas as pd
from elasticsearch import Elasticsearch, helpers
ES_URL = "http://localhost:9200"
ES_INDEX = "youtube_videos"
CSV_PATH = "cristiano_videos.csv"
def make_doc_id(row: dict) -> str:
raw = row.get("id") or row.get("url") or str(row)
return hashlib.sha1(str(raw).encode("utf-8")).hexdigest()
def clean_value(value):
if pd.isna(value):
return None
return value
def create_index_if_needed(es: Elasticsearch):
if es.indices.exists(index=ES_INDEX):
return
es.indices.create(
index=ES_INDEX,
body={
"mappings": {
"properties": {
"title": {"type": "text"},
"description": {"type": "text"},
"url": {"type": "keyword"},
"thumbnail": {"type": "keyword"},
"viewCount": {"type": "keyword"},
"date": {"type": "keyword"},
"likes": {"type": "keyword"},
"channelName": {"type": "text"},
"channelUrl": {"type": "keyword"},
"duration": {"type": "keyword"},
"input": {"type": "keyword"},
"success": {"type": "keyword"},
"error_code": {"type": "keyword"},
}
}
},
)
def main():
es = Elasticsearch(ES_URL)
create_index_if_needed(es)
df = pd.read_csv(CSV_PATH)
actions = []
for _, row in df.iterrows():
doc = {key: clean_value(value) for key, value in row.to_dict().items()}
# 低质量过滤:没有标题或 URL 的记录,不进入搜索库
if not doc.get("title") or not doc.get("url"):
continue
actions.append(
{
"_op_type": "index",
"_index": ES_INDEX,
"_id": make_doc_id(doc),
"_source": doc,
}
)
if not actions:
print("No valid records to import.")
return
success, errors = helpers.bulk(es, actions, raise_on_error=False)
print(f"Imported records: {success}")
if errors:
print(f"Failed records: {len(errors)}")
if __name__ == "__main__":
main()运行:
python
python import_to_es.py实现全文检索
新建 search_videos.py:
python
from elasticsearch import Elasticsearch
ES_URL = "http://localhost:9200"
ES_INDEX = "youtube_videos"
def search_videos(keyword: str, size: int = 10):
es = Elasticsearch(ES_URL)
response = es.search(
index=ES_INDEX,
body={
"query": {
"multi_match": {
"query": keyword,
"fields": [
"title^3",
"description",
"channelName",
],
}
},
"size": size,
},
)
return response["hits"]["hits"]
if __name__ == "__main__":
while True:
keyword = input("search> ").strip()
if keyword in {"exit", "quit"}:
break
if not keyword:
continue
results = search_videos(keyword)
for index, hit in enumerate(results, start=1):
item = hit["_source"]
print("-" * 80)
print(f"{index}. {item.get('title')}")
print(f"channel: {item.get('channelName')}")
print(f"views: {item.get('viewCount')}")
print(f"duration: {item.get('duration')}")
print(f"url: {item.get('url')}")运行:
plain
python search_videos.py输入:
plain
Cristiano就可以检索刚才导入的视频数据。
五、效果对比:从手工整理到 API 任务化
这次实践里,URL 采集和关键词采集分别解决了两个问题。
URL 采集适合拿指定频道的数据。比如 C 罗频道,我们只需要把频道视频页填进去,再设置采集数量,就能拿到一批视频元数据。
关键词采集适合扩大数据量。比如关键词 Cristiano,一次请求 100 条,任务完成后可以下载结构化结果。从截图看,这类任务实际返回了几十条有效数据,积分消耗不到 1 个,用来做前期验证是比较划算的。
| 对比项 | 手工整理 | Dataify API |
|---|---|---|
| 数据入口 | 人工打开页面逐条整理 | URL 或关键词提交任务 |
| 批量能力 | 不适合处理几十到上百条 | 可通过 num_of_posts 控制数量 |
| 结果格式 | 需要自己整理表格 | 支持 JSON、CSV、XLSX |
| 状态追踪 | 依赖人工记录 | 任务列表展示状态和成功率 |
| 错误信息 | 不容易统一记录 | 结果中包含 success、error_code |
| 后续入库 | 需要额外清洗 | CSV / JSON 可以直接进入处理脚本 |
| 成本判断 | 时间成本不直观 | 后台可看到积分消耗 |
这里不建议只看"请求了多少条",更应该看"有效结果数"和"字段完整度"。
比如标题、URL、频道名、描述这些字段越完整,后面做搜索和分析就越顺。
六、最佳实践与扩展
这个项目第一版不用做得太复杂。能完成下面这条链路,就已经可以验证价值:
plain
关键词 / URL
↓
视频元数据
↓
CSV / JSON 下载
↓
Elasticsearch 入库
↓
标题和描述检索几个建议可以提前加上。
第一,先小批量测试。
URL 采集先设置 5 或 10 条,确认字段没问题后,再调到 100 或更多。
第二,保留 input 字段。 这个字段能告诉你数据来自哪个 URL 或关键词。后面如果同时采集多个关键词,比如 Cristiano、Messi、Mbappe,就可以靠 input 做来源区分。
第三,入库前做基础过滤。 标题为空、URL 为空、success 不是成功状态的数据,不建议直接进入搜索库。
第四,先采元数据,再处理更重的内容。
如果后续要继续做字幕、评论或训练数据,建议先用元数据筛选出高价值视频,再进入下一步。这样成本更好控制。
比较推荐的端到端流程是:
plain
Dataify 视频数据采集 API
↓
视频元数据
↓
质量过滤
↓
Elasticsearch 检索
↓
筛选高价值视频
↓
字幕 / 评论数据
↓
训练数据或内容分析对于个人视频搜索引擎来说,核心难点不是"能不能打开某个视频页面",而是能不能持续、稳定、批量地拿到结构化元数据。
自己写数据采集工具适合高度定制,官方 API 适合规范场景,通用采集工具适合一次性导出;而 Dataify 更适合把采集过程做成任务化流程,并直接输出 JSON、CSV、XLSX 等结构化结果。
这样不是单纯演示怎么点后台,而是通过 Dataify API 把视频元数据变成可检索、可分析、可继续加工的数据资产。