26年6月来自Nvidia、CMU和UC Berkeley的论文"ENPIRE: Agentic Robot Policy Self-Improvement in the Real World"。
在现实世界中实现灵巧的机器人操作,很大程度上依赖于人工监督和算法工程,这是通往通用物理智能道路上的一个主要瓶颈。尽管新兴的编程智体(coding agents)能够生成代码以实现算法搜索的自动化,但它们的成功主要局限于数字环境。实现机器人研究自动化所缺失的抽象概念,是一个针对现实世界策略改进的可重复反馈循环:重置场景、执行策略、验证结果以及优化下一轮迭代。为了弥补这一差距,其推出 ENPIRE------一个专为编程智体设计的框架,通过四个核心模块将这种物理反馈流程具体化:用于自动重置和验证的环境模块(EN)、启动策略优化的策略改进模块(PI)、利用单台或多台物理机器人并行评估策略的执行模块(R),以及让智体分析日志、查阅文献并改进训练基础设施与算法代码以应对失败模式的演化模块(E)。这一闭环系统将现实世界的机器人学习转化为一种可由智体管控的、可控的优化过程,从而在最大限度减少人工投入的同时,支持针对不同训练方案和智体变体进行公平的消融实验。
借助 ENPIRE,前沿编程智体能够自主开发策略,在现实世界的挑战性灵巧操作任务(如 PushT、将插针整理放入盒中、使用切刀剪断扎带)中实现 99% 的成功率。编程智体可以利用多种 PI 机制(如启发式学习、工具调用、行为克隆、离线或在线强化学习)来改进策略。此外,ENPIRE 可以在机器人集群上显著加速运行;其提出两个指标------平均机器人利用率(MRU)和平均 Token 利用率(MTU)------来衡量多智体物理自主研究的效率。还提供在 RoboCasa 环境中的仿真结果。
1. 编码智体与"代码即策略"
这一研究方向建立在一个核心抽象之上:将可执行代码视为智体的动作。具体流程为:模型生成程序,运行时环境返回结构化反馈,随后循环迭代。Code-as-Policies (25) 和 ProgPrompt (41) 将这一范式引入机器人领域,通过组合感知与技能 API 来构建任务规划;视觉推理研究 (42) 也将这种组合思想应用到视觉模块中。后续研究将"单次生成"模式扩展为由执行反馈驱动的多轮循环,涵盖"推理-行动"轨迹 (51)、自我批判与迭代修复 (32; 40)、推理时搜索 (52) 以及学习型工具调用 (37) 等方法;Wang (45) 提出,相比自然语言,代码是一种更强大的动作表征,因为代码的每一步执行都可以在运行时进行验证。另一条平行的研究路径致力于规范化智体与计算机之间的交互接口------即一个沙盒化的 Shell 环境,智体在此环境中读取、运行并调试代码;这一机制现已成为前沿编码类产品(如 3; 33; 35)的底层支撑。
在机器人领域,早期的"代码即策略"系统主要提供由人工设计的高级 API------例如封闭形式的技能、基于语言条件的抓取原语以及affordance评分器 (1)------从而让智体专注于任务分解,而非直接生成底层控制指令。Wang (44) 利用自我验证机制和自动课程学习(其中尝试成本极低)构建一个可复用的 Minecraft 技能库;Fu (15) 的研究发现,相比单纯使用底层原语,结合多轮反馈、技能合成与集成采样等技术能显著提高操作任务的可靠性。此外,还有相关研究利用大语言模型 (LLM) 合成辅助训练信号,包括奖励函数 (31; 49; 53)、仿真-到-现实 (sim-to-real) 的迁移协议 (30)、仿真环境 (46) 以及数据收集流水线 (2)。
2. 智体的自我改进
实现自我改进循环的前提是单次尝试的成本必须足够低,以便进行大规模重复;不同系统之间的主要区别在于单次尝试向智体返回何种信息。Ellis (13) 确立一种后续研究广泛沿用的保留模式:每当成功解决一个合成任务,系统便将相应的命名子程序添加到不断扩充的技能库中;由于执行过程无需成本,这种方法切实可行。Wang (44) 将这一思路引入具身(embodied)场景,用大语言模型(LLM)的自我验证和自动课程生成机制取代原有的"成功信号"------这种做法之所以可行,是因为在 Minecraft 中进行模拟推演(rollout)几乎没有成本。Yu (53)、Ma (31) 和 Xie (49) 的方法输出的是奖励信号而非具体技能:由 LLM 提出密集奖励(dense reward),基于该奖励训练策略,并根据训练统计数据修正奖励------Eureka 正是通过每分钟数千次的 Isaac Gym 模拟推演实现这一闭环。Ma (30) 尝试通过合成的域随机化(domain-randomization)参数将应用扩展至硬件层面,但其迭代过程仍在仿真环境中进行,仅在修正结束后才进行部署;在实验场景层面,Wang (46) 在仿真中生成新任务和资产,而 Ahn (2) 则协调移动机器人车队进行离线数据收集,而非在迭代循环内进行操作。在上述所有案例中,迭代闭环均在低成本的载体(如仿真环境)上完成,而真实机器人的执行过程仅作为"仿真-到-现实"(sim-to-real)的迁移目标或数据来源,从未直接充当迭代的媒介。本文保留这些技能积累和奖励生成机制,但直接在硬件上运行迭代循环;此时,制约系统的关键资源不再是算力,而是智体使用机器人的权限配额。
3. 自主研究智体与科学发现
最后一类研究工作致力于实现研究循环本身的自动化,理解这类工作的关键在于关注其实验开展的媒介环境。在 LLM 出现之前,自主系统是在真实的实验室硬件上完成"假设-实验"循环的 (9; 23)。而 LLM 时代的系统则实现了端到端的数字循环自动化 (26; 38; 39; 50);近期的一类研究则通过实验室自动化 (6; 29) 或人工执行的湿实验验证 (16),重新将触角延伸至物理科学领域。评估体系也反映这种对数字化的侧重:MLE-bench (11) 针对机器学习工程智体及其资源扩展能力进行评分,而针对 SWE-bench (21) 的分析则提醒人们,性能提升可能源于数据污染,而非智体能力的真正增强。
目前存在两项空白:其一,尚无系统能在明确的硬件预算约束下,自主运行并优化物理机器人实验闭环------传统的机器人科学家往往固定使用既定设备且不自行开发工具,而基于大语言模型(LLM)的研究智体则从未涉足真实机器人;其二,尚无基准测试能够衡量稀缺物理资源的利用率,现有的评估多侧重于能力或"每篇论文成本"。本文系统通过在真实机器人上运行并优化实验闭环,同时针对这一受预算约束的场景引入资源利用率指标,从而填补上述两项空白。
4. EMPIRE
自动学习灵巧操作技能一直是通往通用物理智能之路上的主要障碍。尽管前沿的策略训练方法成效显著,但它们仍依赖于人类在幕后参与数据收集、评估与重置(reset)以及算法调整这一全生命周期过程 (19; 20; 24)。随着在现实世界中扩大策略学习的规模,人类在监督策略改进过程中投入的劳动,不可避免地成为了制约机器人获取灵巧操作能力速度的瓶颈之一。
由编码智体(coding agents)驱动的自主研究(autoresearch)领域的最新进展 (22),为实现算法改进的自动化展示了一条充满希望的路径。然而,当将这一范式扩展到现实世界策略学习的自动化时,便面临着独特的挑战。首先,编码智体缺乏一套用于物理世界闭环假设验证的现实环境接口,而这种验证需要自动化的策略部署、评估及场景重置功能。其次,当在机器人集群中扩展自主研究的吞吐量时,如何在保持资源利用效率的同时筛选并验证假设,仍是一个亟待解决的难题。
为了应对这些挑战,ENPIRE是一个利用自主环境接口套件来实现可扩展物理自主研究的智体驾驭(agent harness)框架。ENPIRE 将灵巧操作技能的获取过程分解为两个自主研究阶段。在第一阶段(即 ENPIRE 中的 EN 部分),编码智体根据人类反馈构建自主环境接口。通过这一初始研究循环,智体实现并优化程序化工具调用,从而为特定任务建立安全边界、自动重置机制及验证流程。这些工具调用仅需一次性设置成本即可完成优化;一旦确定,它们便作为不可变 API 在后续阶段中被重复使用。第二阶段(即 ENPIRE 中的 PIRE 部分)转入完全自主的研究流程,编码智体在此阶段根据现实世界的反馈不断改进策略。在环境自动验证信号的完全引导下,智体无需人工干预,自主探索并优化各种方法,以最大化现实世界任务的成功率。
为了在多个机器人上并行扩展这一流程,ENPIRE 引入一种基于演化策略的假设筛选机制,从而加速策略的改进。其部署一个去中心化的智体团队来异步测试各种训练方案(training recipes),并根据平均成功率来共享或舍弃构想。由此积累的知识还可以迁移应用到类似的新任务中。
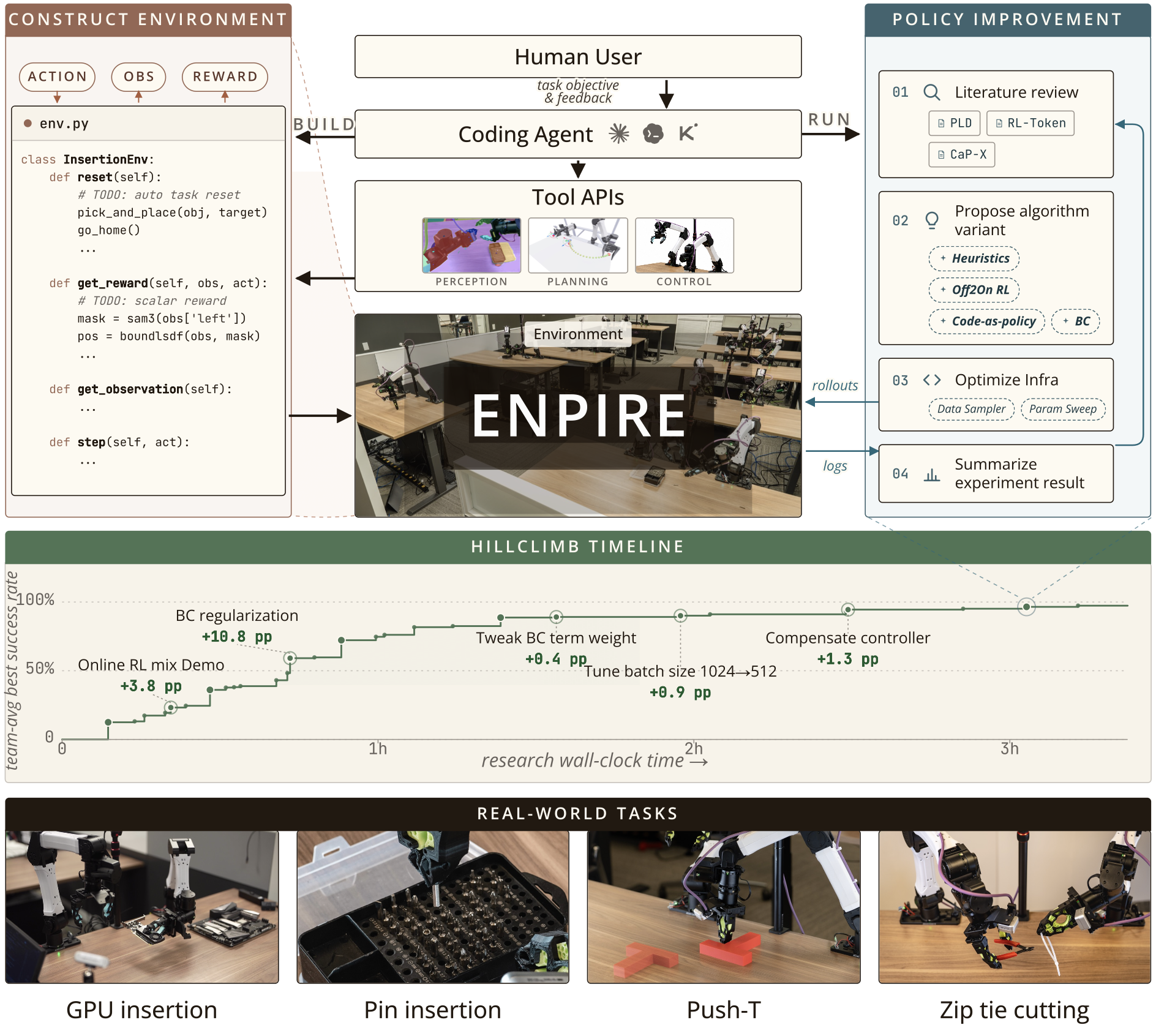
ENPIRE概述如图 2 所示:
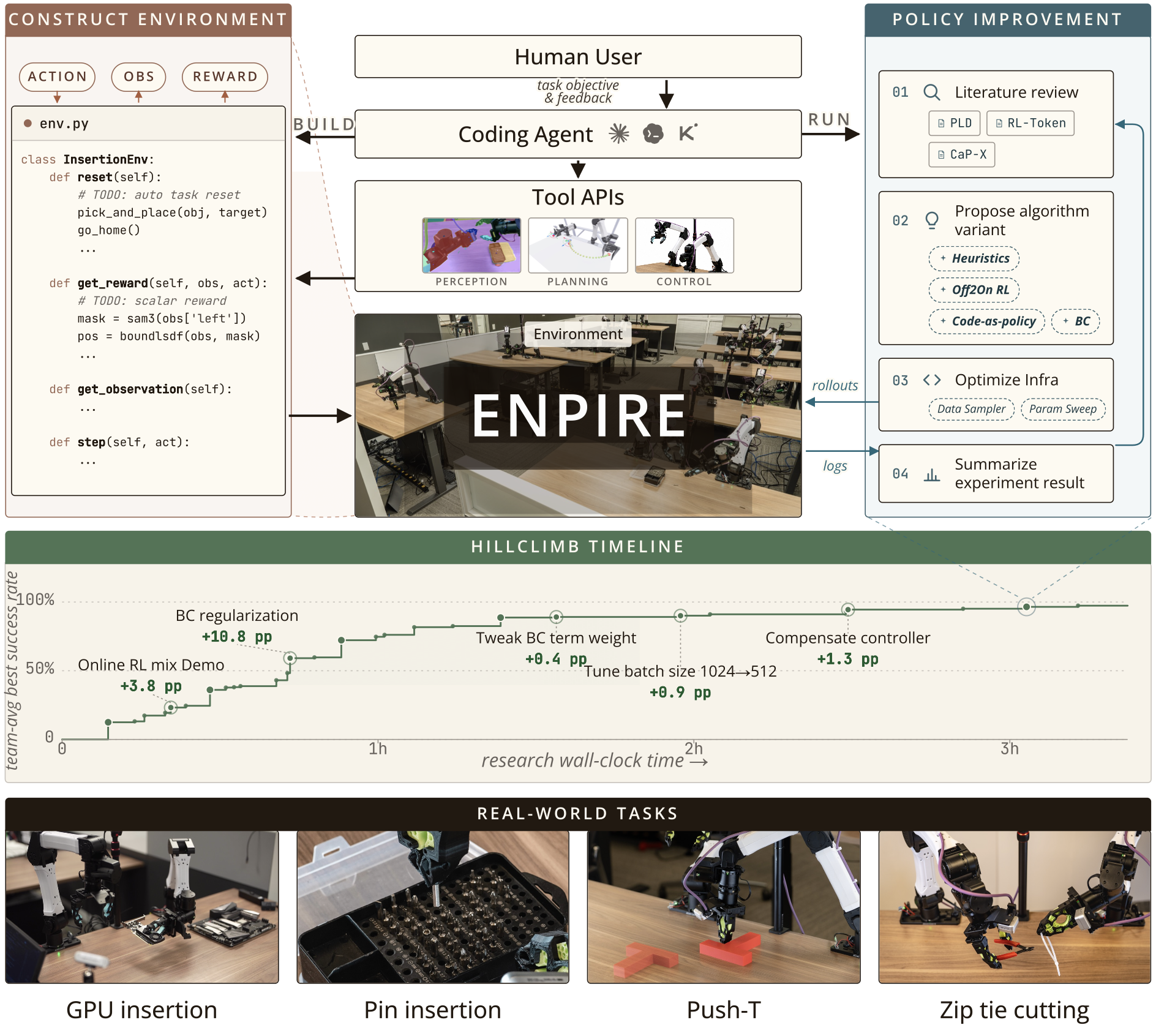
讨论一种支持编程智体在物理世界中开展自动化研究的系统架构。该流程分为两个阶段:基于人类反馈构建环境(即 ENPIRE 中的 EN),以及基于现实世界反馈自动改进策略(即 ENPIRE 中的 PIRE)。
1. 第一阶段:基于人类反馈构建环境
为了让编程智体(coding agents)能够自主开展物理层面的自我探索与研究,首先需要构建一个对智体友好的环境,将物理交互与反馈抽象为结构化的形式。该环境包含支持长期运行的特定任务安全约束、用于反馈与信用分配的实时自动化验证流程,以及确保快速迭代的稳健自动重置机制。为提升可靠性,智体利用程序化工具调用来构建环境 API,并根据人类评估结果不断优化其实现。人类投入属于一次性成本,在后续自动策略改进过程中,该成本将分摊到所有机器人上的各项实现中。
硬性安全约束
将机器人的配置空间和运动学行为限制在安全操作范围内。这些安全区域既足以支持任务完成,又充当硬性约束:一旦超出这些限制,将立即导致任务失败并触发自动重置。这既是现实世界交互中的安全保障,也是导致回合终止或截断的触发条件。
自动验证
在现实世界的实验中,机器人学习过程需要基于传感器输入的实时验证,以量化实验进展。为了最大限度减少人工工程投入,系统利用"编码智体"(coding agents)通过程序化工具调用来构建二元奖励函数,从而区分任务结果。仅需少量的成功与失败演示数据,这些智体便能利用视频和本体感知记录,在最大化预测准确率的同时最小化处理延迟。例如,自动研究(AutoResearch)发现一种针对插销插入任务的鲁棒奖励函数,该函数基于视觉对齐、末端执行器高度及力估算。如图4所示,编码智体还展示设计依赖感知的奖励函数的能力(以扎带插入任务为例),并将推理延迟优化至150毫秒以内,这一速度已接近人类视觉系统的反应水平(43)。

自动重置
一旦任务完成或失败,智体便会执行一系列工具调用,将环境恢复至初始状态。针对涉及复杂接触交互的任务,其采用受 CaP-X (15) 启发的程序化工具调用方法,利用模块化操作技能将环境直接重置到最具挑战性阶段的起始点。通过将机器人精确放置在关键动作(如插入销钉、安装 GPU 或抓取剪刀)的起始时刻,能有针对性地引导学习系统专注于这些高精度要求的难点环节。
安全约束、自动验证与自动重置共同构成环境模块(即 ENPIRE 中的 EN)。策略接收来自视觉与本体感觉传感器的输入,并向机器人控制器发送动作指令;这一过程与奖励机制相结合,构成"Rollout"模块(即 ENPIRE 中的 R)。这些模块构建完成后,编码智体可通过不可变的 Gym API (7) 对其进行访问,从而获取反馈信号与调试信息,以实现策略的自动优化。
2. 第二阶段:基于真实世界反馈的自动化策略改进
第二阶段利用自动化研究来训练针对特定任务的策略。在初始化时,编程智体(coding agent)接收任务描述,其最终目标是通过自主实验最大化任务成功率。为实现这一目标,智体被授予对精简训练代码库的写入权限,该代码库支持基础的端到端策略训练和基于代码的策略合成。
一个典型示例
以插销任务为例来说明这一过程,该任务要求将插销插入一个间隙仅为 4 毫米的紧密配合孔中。在此自动化研究阶段,智体通过策略改进模块(PI)运作:它查阅文献以获取洞察,提出假设,并直接修改训练代码(例如行为克隆或强化学习算法),从而根据真实世界的自动验证结果优化性能。为了收集丰富的证据,智体调用环境 API 来记录运行过程中的机器人轨迹、视频录像和奖励信号,并分析这些统计数据以指导后续的改进工作。
通过多智体扩展加速自动化研究
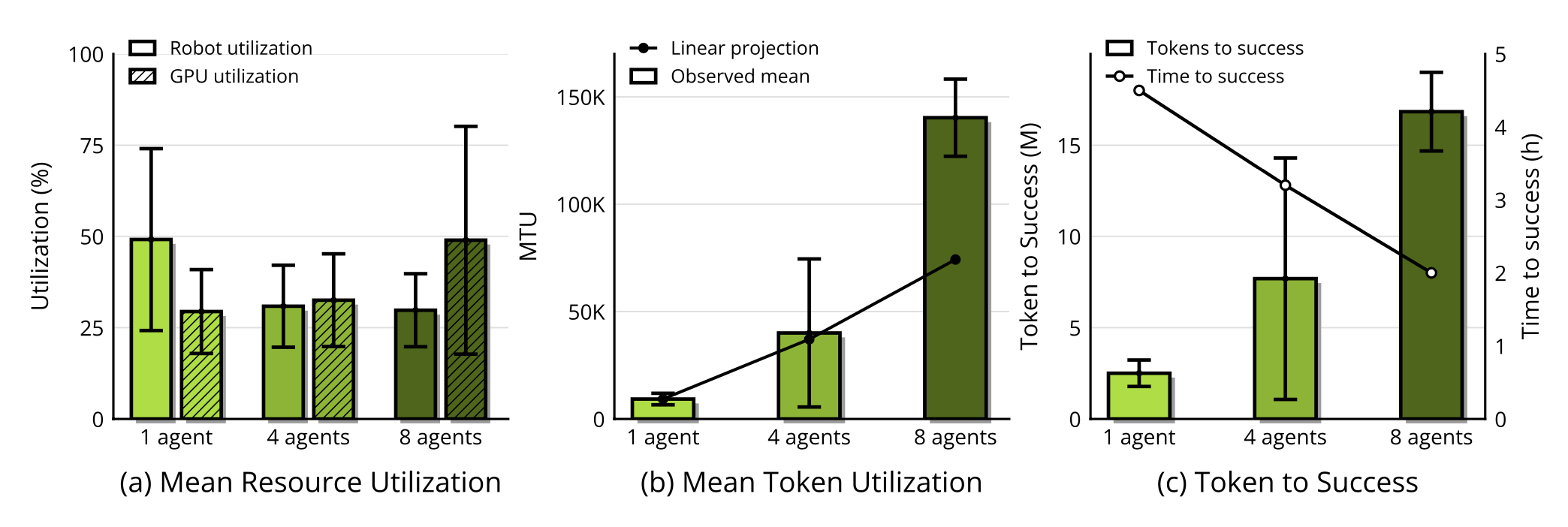
尽管自动重置和验证机制增强单一部署循环的可扩展性,但通过启动并行、多智体去中心化协作协议,可以进一步加速物理环境下的自动化研究。该协议在 N 台物理机器人上部署 N 个智体,以异步方式测试 N 个假设。每个智体都基于同一个基准策略训练代码库进行分支开发,并通过 Git 进行自主协作,从而扩展这一演化模块(E)。在无需人工干预的情况下,智体会自发地挑选、复制或合并来自同伴的成功训练方案,以优化其代码搜索过程。实验观察表明,增加并行智体-机器人对的数量,能显著缩短发现高成功率策略方案所需的实际耗时(wall-clock time),如图 3 所示。为了量化编程智体将其分配的物理资源转化为研究进展的效率,提出两个与任务级结果相辅相成的利用率指标。平均机器人利用率(MRU)是指机器人在实际执行实验的研究耗时占比;GPU 利用率是指 GPU 处于活跃使用状态的研究耗时占比。一个资源利用率达到极致的智能体会使这两个指标都趋近于 1;在实践中,对于评估的任何前沿编码智体,这两个指标均未达到该数值。
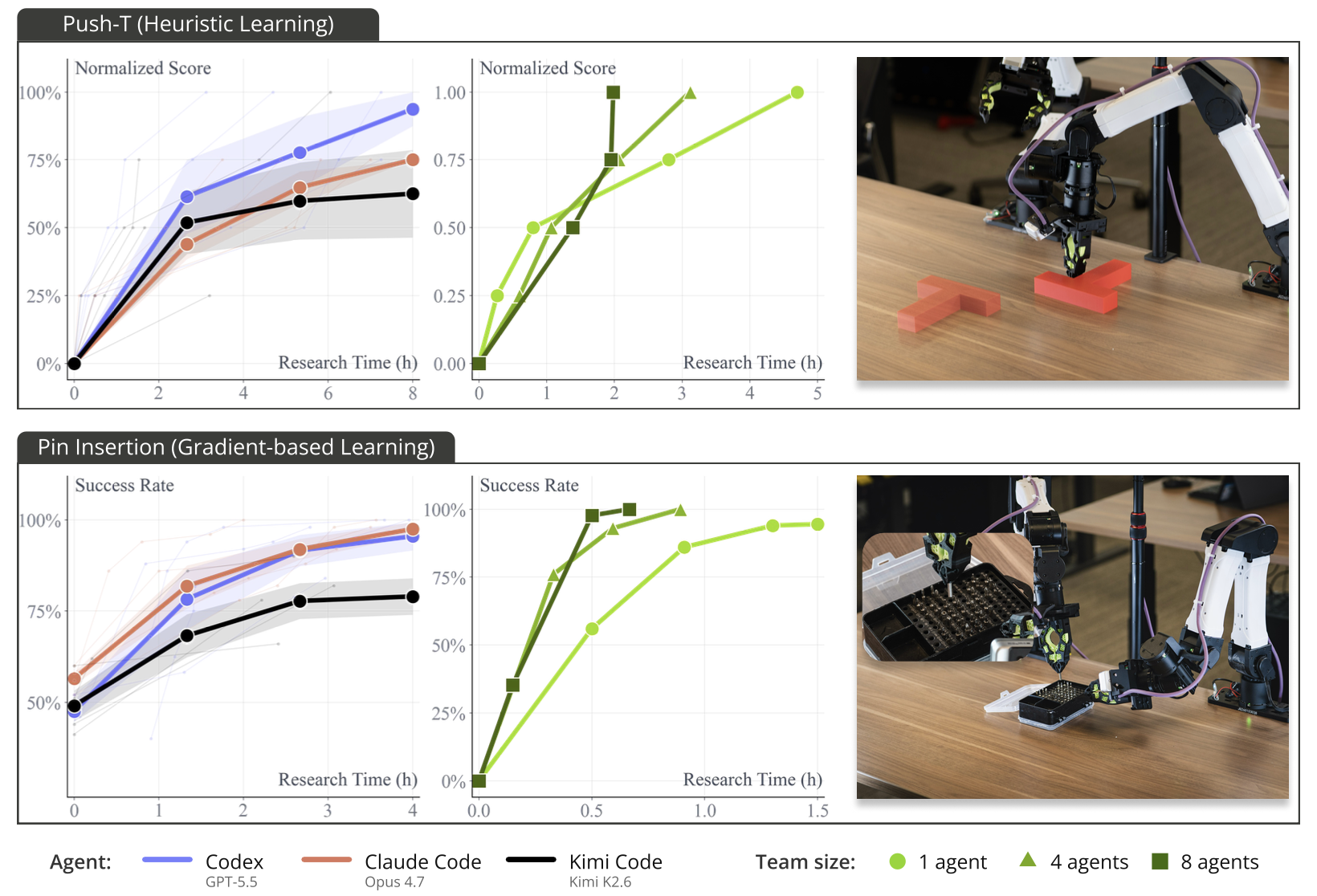
ENPIRE 是一种能力强大且具备可扩展性的自主研究(autoresearch)智体设计。
• 首先,ENPIRE 支持在环境构建完成后的自主策略学习。
• 其次,ENPIRE 成功率的收敛速度随机器人及 Token 资源规模的增加而提升。
重点关注以下需要基于感知反馈进行精确且实时响应控制的灵巧操作任务:Push-T (12)(机器人利用非抓取式动作将 T 形块对齐至目标区域);插销任务(机器人通过将插销插入直径 4mm 的孔中来整理插销盒);GPU 插入任务(机器人将 GPU 芯片安装到主板上的薄型插槽中);以及扎带剪切任务(机器人抓取并闭合剪刀以剪断扎带尾部)。图 2 展示这些任务的可视化效果。
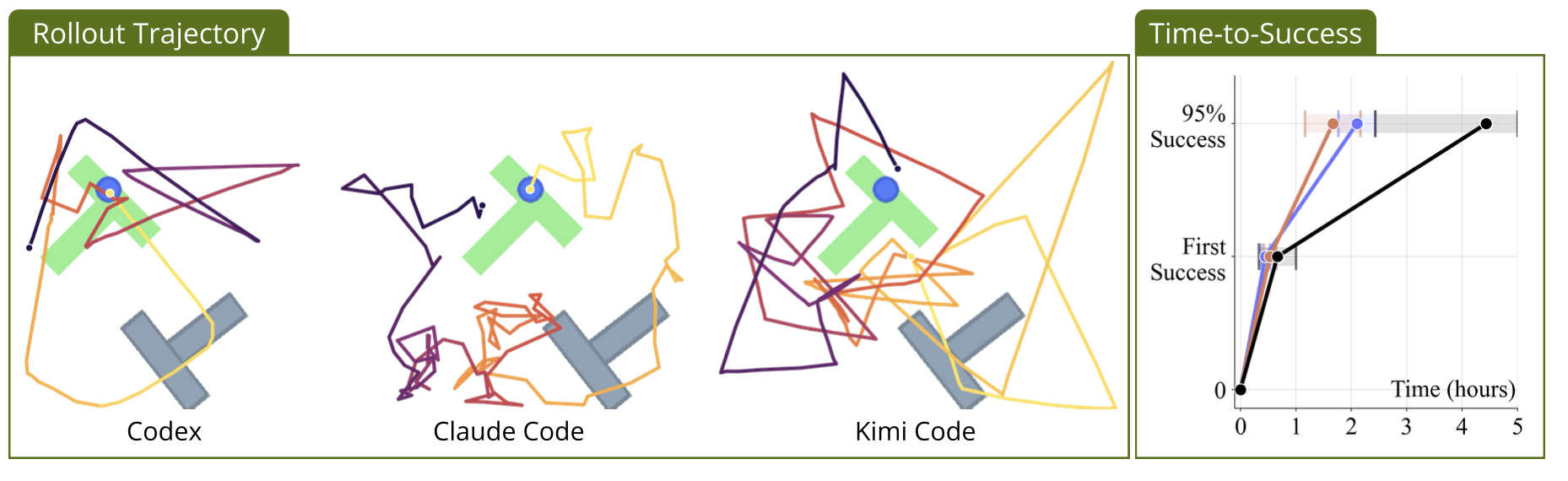
利用 ENPIRE 在多种策略学习范式下开展自主研究。负责编写代码的智体(coding agents)可以自由选择各种方法及其组合来解决任务,包括端到端神经网络训练(如行为克隆 BC (36) 或现实世界强化学习 RL (18)),以及无梯度学习方法(如启发式学习 (47) 和基于代码的策略合成 (25))。实体机器人平台是双臂 6 自由度 YAM 机器人。在物理环境下的自主研究实验中,对三种代码编写智体进行基准测试,分别是:搭载 GPT-5.5 xhigh 的 Codex (35)、搭载 Opus 4.7 High 的 Claude Code (3) 以及搭载 Kimi K2.6 thinking 的 Kimi Code (33)。
1. 面向启发式学习的自主研究
测试ENPIRE 在最简单形式下推动自动策略改进的能力,即通过综合感知和控制工具调用(25)来学习启发式规则(47)。为此,构建一个现实世界的 Push-T 环境,并建立相应的仿真环境以进行对比。
物理环境自主研究面临的独特挑战
如图 5 和图 3 所示,所有编码智体(coding agents)均能利用启发式学习在仿真环境中成功完成 Push-T 任务。然而,现实世界环境的挑战性要大得多,导致三个智体中有两个未能成功。尽管仿真器能提供一致且可预测的物理特性,便于进行低方差的假设检验,但现实世界的条件具有非确定性和时变性:机器人动力学、接触摩擦力以及物体运动等因素本质上更难预测,且会随实验轮次和硬件设备的不同而变化。
为了提高在现实世界中的鲁棒性,在后续任务中鼓励智体探索甚至结合多种学习方法------涵盖启发式学习和基于梯度的学习------以应对现实部署中出现的极端情况(corner cases)。此外,还提出扩展物理智体团队的规模,以便在多样化且非确定性的现实物理环境中验证假设。
2. 基于梯度的策略改进的自动研究
除了支持启发式学习外,如图3所示,ENPIRE 还能在对精度要求极高的"插针"(pin insertion)任务中训练端到端策略。在该任务中,编码智体(coding agents)需要在实际环境评估中连续成功50次。智体尝试多种改进策略的方法,包括行为克隆(BC)、结合在线展开(rollout)数据聚合的迭代式 BC,以及带有 BC 正则化项的在线、离线及"离线转在线"(offline-to-online)强化学习(RL)。此外,智体还调整了诸如批次大小(batch size)、Actor-Critic 策略更新率以及 BC 项超参数等参数。
3. 机器人集群上的策略学习扩展
进一步研究增加机器人和智体的数量是否能缩短达到相同目标任务性能所需的实际耗时(wall-clock time)。将一个编码智体分配给一台机器人,并在该机器人集群上配置相同的环境接口、奖励函数和重置机制。在 Push-T 和插针任务中,分别考察包含 1 台、4 台和 8 台机器人的集群规模。
在 Push-T 任务中,将智体数量从 1 个增加到 8 个,使达到 1.0 归一化得分所需的时间从约 5 小时缩短至 2 小时。在插针任务中,将智体数量从 1 个增加到 8 个,使达到近乎完美的成功率所需的时间从超过 1.5 小时缩短至约 40 分钟。这表明,ENPIRE 能够通过分布式假设选择,将额外的机器人资源转化为更快的策略改进。
在多智体场景下,ENPIRE 还能利用基于代码策略,在重置过程中自动应用域随机化(domain randomization)。例如,在插针任务中,空间配置的变化范围远超以往研究(48)中的设定,从而增强了策略的鲁棒性。
如图1 所示用于物理自主研究的机器人机群:

4. 通过智体持续学习迁移自动研究经验
多智体物理自动研究过程中积累的洞察,同样可以迁移到类似的新灵巧操作任务中。在插销插入任务的自主探索阶段结束后,智体会记录并反思其训练方案的演变过程。当针对 GPU 插入任务启动新一轮自动研究时,若将这些既有知识附加到新任务的指令中,编码智体便能实现极高的成功率。
5. ENPIRE 发现基于代码的策略与 VLA 之间的协同效应
除了端到端训练或启发式训练外,ENPIRE 还能自动将视觉-语言-动作模型(VLA)(8) 与程序化工具调用相结合,以执行长程操作任务。在 RoboCasa365 仿真环境 (34) 中,智体利用运动规划和检测工具,在抓取物体前先悬停于其上方,从而提升 GR00T VLA (5) 的成功率。本文成功将这一策略迁移到现实世界:如图 2 所示,智体学会悬停在剪刀上方、抓取剪刀并剪断扎带。
6. 量化智体资源利用率
图 7 总结 ENPIRE 在插销插入任务中,分别使用单智体、四智体和八智体集群时的资源扩展特性。依据前文定义的指标,报告平均机器人利用率(MRU)和 GPU 利用率。此外,还测量平均 Token 利用率(MTU),即每分钟消耗的 Token 数量;并进一步测量"成功所需 Token 数"和"成功所需时间",以此量化完成自动研究目标所需的 Token 预算与实际耗时。
机器人集群架构
物理基础设施由八个双臂机器人工作站组成,采用去中心化方式运行。每个工作站都配备专属的机械臂、摄像头、计算资源以及独立的编程智体(coding agent)。来自各工作站智体的硬件控制请求均通过本地 FastAPI 服务器进行路由。工作站间的协作完全通过 Git 实现:各工作站不向中央服务器流式传输状态数据,而是通过向公共代码仓库推送(push)和拉取(pull)代码、配置、工具及结果来进行共享;这样,在某个工作站上发现的改进就能通过常规的版本控制机制推广到其他工作站。由于所有协作都基于 Git,智能体之间可以相互借鉴思路:它们能够自由合并来自其他分支的变更或挑选(cherry-pick)特定的提交,从而有选择地采纳在其他工作站上发现的有前景的方法与结果。这种机制确保集群的松耦合与容错性,因为各个工作站的运行、故障及恢复均相互独立,而共享的 Git 历史记录则作为"单一事实来源",记录每个工作站的尝试与学习成果。
控制端点
FastAPI 服务器提供一组精简的端点,供智体控制数据采集与任务执行:/start 用于在真实硬件上启动一次运行(rollout),/restart 用于分配一个新的运行缓冲目录,/home 则将机械臂复位至初始配置状态。/restart 端点确保了连续多次运行相互独立且可单独寻址,从而避免了来自不同假设或实验的数据混淆:每次运行的数据都会写入其专属目录,使智体能够将结果归因于其正在测试的具体变更。这些端点在所有任务中通用。针对 Push-T 任务,系统额外提供 /avoid 和 /resume 端点以处理遮挡问题:/avoid 指令让机械臂退出顶部摄像头的视野范围,消除对场景的遮挡;/resume 指令则让机械臂返回原位,继续执行操作。
智体沙盒与上下文
每个工作站的编程智体都在一个限定于特定"自动研究"(autoresearch)代码仓库的沙盒环境中运行。在此沙盒内,智体拥有更高的自主权:它绕过动作层面的权限确认提示,无需人工逐步批准即可执行命令,并拥有不受限制的互联网访问权限。智体可获取当前自动研究会话期间采集的所有机器人数据,并能自由利用一切可用信息来实现其目标。对于常规的全新会话,系统会在初始化前清理原始仓库状态、部署数据、检查点以及过往会话产生的临时日志,从而确保智体在一个干净且隔离的工作空间内启动。而在迁移实验(例如在完成"引脚插入"任务后初始化"GPU 插入"任务)中,智体会接收一份明确的 Markdown 格式摘要,该摘要提炼自先前的"引脚插入"自主研究会话;尽管原始轨迹、隐藏日志和检查点仍会被移除,但这种迁移过程是基于书面摘要进行的,而非通过不受限制地访问过往会话状态来实现。
2. 工作站硬件
所有 8 个工作站的硬件都是相同的。每个工作站均由 I2RT 的两个采用固定双手配置的 YAM(又一个操纵器)手臂、一组摄像头以及一个运行 FastAPI 服务器、策略推理和工作站智体的工作站组成。
操纵器和驱动
每个手臂都是一个 6-DoF 机械手,配备有一个 1-DoF 平行爪夹持器,每个手臂有 7 个驱动关节,而双手对则有 14 个关节。所有关节均由无刷执行器通过 CAN 总线驱动。六个臂关节在带有重力补偿的 PD 控制下运行,而夹具则在力限制模式下运行,直接限制抓取力;利用这种夹具级别的力限制来实现强大的抓取和整个车队的安全、无人值守操作。
计算
每个站都在一个工作站上运行。 所有策略推理和站内计算都在该单一 GPU 上运行,没有共享集群或站外计算。
洞察力
除非另有说明,感知使用英特尔实感 D405 摄像头:一个自上而下的摄像头查看工作空间,两个腕式摄像头(每只手臂一个)提供所抓取物体和接触区域的近距离视图。一项任务还使用侧面安装的 RealSense D435i 来获得更广阔的第三人称视角。该策略以 30 Hz 的频率运行,其行动目标由下面描述的低级联合控制器跟踪,这些控制器通过 CAN 总线以 100 Hz 的频率运行。还使用 Viser 对机器人状态、相机帧和目标姿势进行基于浏览器的实时 3D 可视化,支持自主运行监控、校准调试和事件检查。
3.低级控制
策略操作以 30 Hz 的频率推断,每个操作目标由通过 CAN 总线以 100 Hz 运行的低级联合控制器跟踪。两个联合组的控制方式不同。六个臂关节使用带有重力补偿的 PD 控制,跟踪命令的关节目标,同时前馈重力项卸载静态负载,因此 PD 增益只需要处理残余误差。
1-DoF 夹持器作为扭矩限制兼容抓取运行:夹持器不是接近刚性目标宽度,而是应用由命令扭矩限制设置的有界夹持力。这种力限制是稳健和安全抓取的关键。由于手指以有限的力围绕物体,而不是驱动到固定位置,因此抓取可以适应物体姿势和尺寸的变化,并且对感知和放置误差具有鲁棒性。相同的约束限制了系统在抓取、接触和插入过程中可以施加的力,从而防止在尝试未对准或失败时损坏夹具、操纵部件和固定装置。由于车队在所有 8 个站点上自主且无人值守地运行,因此这种有界力行为至关重要:不良接触会导致安全失速,而不是导致硬件损坏的推动,并且循环中没有人进行干预。
4. 针对各任务的配置
这四个任务共用工作站硬件及前述 30 Hz 频率的策略循环,仅在相机与控制配置的细节上有所不同。所有任务均使用一个俯视相机和两个腕部相机(型号均为 RealSense D405);其中 GPU 插入任务额外使用了一个侧装式 RealSense D435i 相机,以获取插槽更宽广的第三人称视角。
5. 真实世界 RL 系统集成
集成 PLD-RL 流水线 (48),为编码智体(coding agent)提供一个受控沙盒环境,以便在进行在线数据采集的同时开展算法自动研究。该基础设施基于 SERL (27; 28) 的异步设计理念开发。将其实现为一个三层分布式系统,将机器人交互、策略学习和推理过程解耦并分配到不同的进程中运行。部署层运行在靠近机器人的控制计算机上,负责硬件调度、回合(episode)记录以及人机协同的遥操作。第二层(学习器/Learner)运行在 GPU 主机上,利用经预训练视觉骨干网络编码后的像素观测数据来训练 RL 智体(包含 Actor 和 Critic 网络)。第三层(执行器/Actor)提供一个兼容 Portal/ZMQ msgpack 协议的端点,使控制器能够通过一套统一协议请求执行动作,该协议同时也适用于脚本控制和遥操作模式。
部署层与学习器之间的数据流转通过一种刻意设计的、基于磁盘的松耦合机制进行。部署层将每个回合序列化为逐步观测张量和同步的相机视频流(.mp4 格式),并存入 rollout-buffer 目录;同时附带逐步动作标签,用于标识动作来源(如 RL、人工操作等)。与此同时,一个守护线程(DiskBufferIngestor)定期轮询该目录,解析新完成的回合,并根据动作来源标签将状态转移数据(transitions)分流至不同的缓冲区,遵循 RLPD 风格的数据混合协议 (4):由 RL 生成的转移数据进入在线经验回放缓冲区(online replay buffer),而人工或手动操作产生的转移数据则进入独立的演示缓冲区(demonstration buffer),并在每次训练批次中进行混合采样。这种设计为混合不同来源的数据提供了灵活性。
6.插销任务的"创意树"
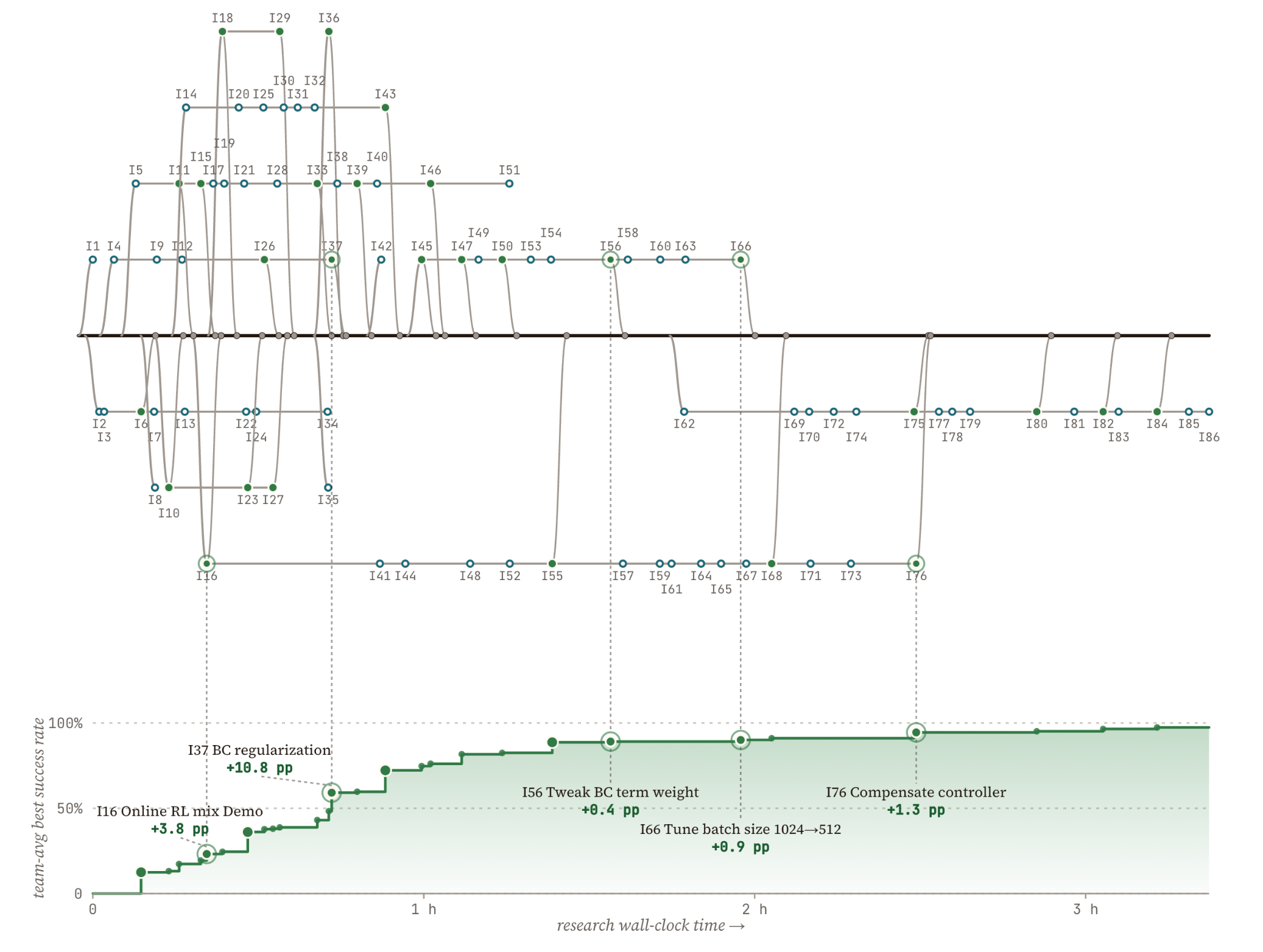
图12展示针对插销任务进行的智体团队自主研究过程,上方为"创意树",下方为对应的爬坡曲线。每个节点 I_k 代表团队探索的一个创意;相互关联的创意由水平线连接,每一条新轨道对应一个新的创意分支。实心绿色节点标记那些提升团队平均最佳成功率的创意,而空心节点则代表虽经评估但未带来性能提升的创意。粗黑线标示得分最高的创意及其演进路径。被圆圈标出的节点为重点创意,它们也标注在下方的爬坡曲线上,并由虚线与曲线上的对应点相连。底部图表展示团队平均最佳成功率随研究实际耗时(wall-clock time)的变化情况,并与上方的创意树共用时间轴。在智体通过 Git 进行协作的过程中,少数具有重大影响力的创意贡献大部分进展------最显著的是 BC 正则化(I_37,+10.8 个百分点);而随着成功率逼近 100%,后续的一些创意(如批次大小调整 I_66,+0.9 个百分点;控制器补偿 I_76,+1.3 个百分点)则主要带来较小幅度的渐进式改进。