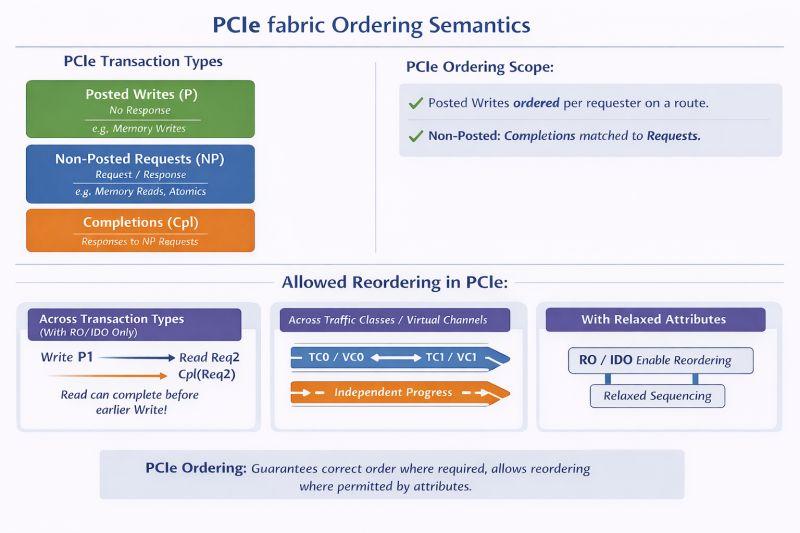
一、现网问题:交换机在"满速运行"下的隐性丢包
某高性能交换机在压测环境中表现出一个典型异常:
- 端口速率稳定在 2×100G 满负载
- PMD线程 CPU 持续 100% 运行(典型 busy poll)
rte_eth_stats显示 RX/TX 包数正常- 但业务侧出现间歇性流表命中失败与随机丢包
- 抓包结果显示:部分流量"完全消失",但链路无错误计数
初步判断:
- 非链路层问题(FCS/CRC正常)
- 非RSS分流问题(队列负载均衡正常)
- 非CPU调度问题(DPDK轮询无抖动)
问题逐渐收敛到一个极其底层的异常点:
部分RX Descriptor的DD位未按预期翻转,但数据实际上已被DMA写入
这直接指向DPDK收发路径中最核心但最容易被忽略的一致性问题。
二、DD位机制:DMA与软件世界的"握手信号"
在典型Intel 10G/25G/100G NIC(如ixgbe/i40e/ice)中,RX Descriptor结构如下:

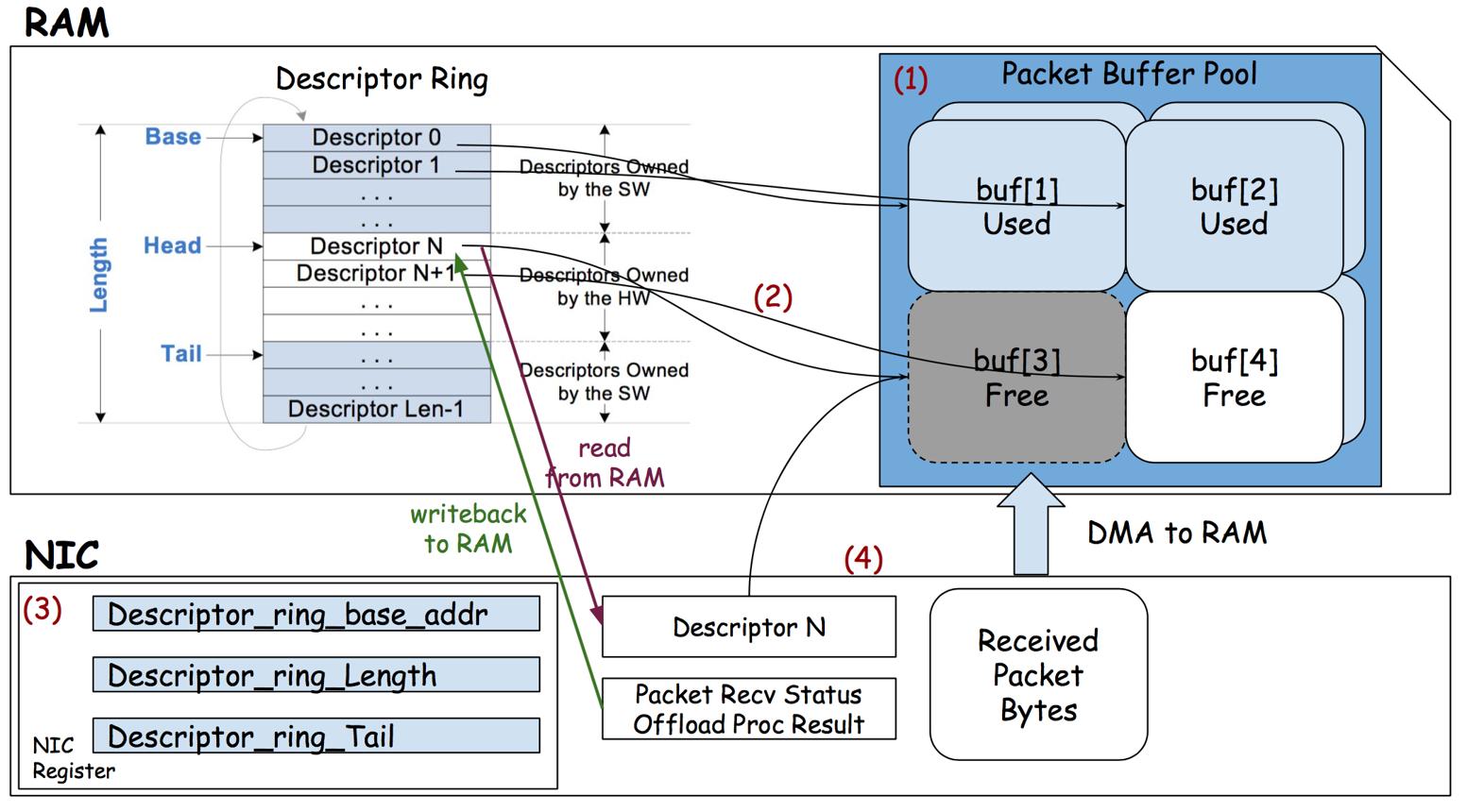
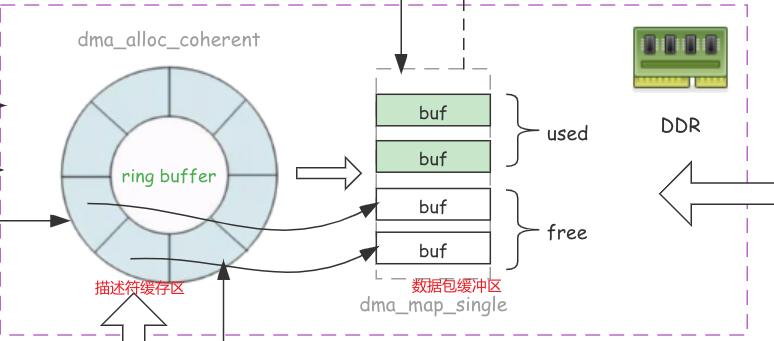
2.1 DD位的语义
DD(Descriptor Done)位表示:
硬件已完成该Descriptor对应的DMA操作,软件可以安全消费该buffer
RX路径:
- NIC DMA写入packet到host memory
- NIC更新descriptor status(设置DD=1)
- PMD轮询检测DD位
- 软件消费mbuf
- 清理descriptor重新归还硬件
TX路径:
- 软件填充descriptor
- NIC发送完成后设置DD=1
- 软件回收buffer
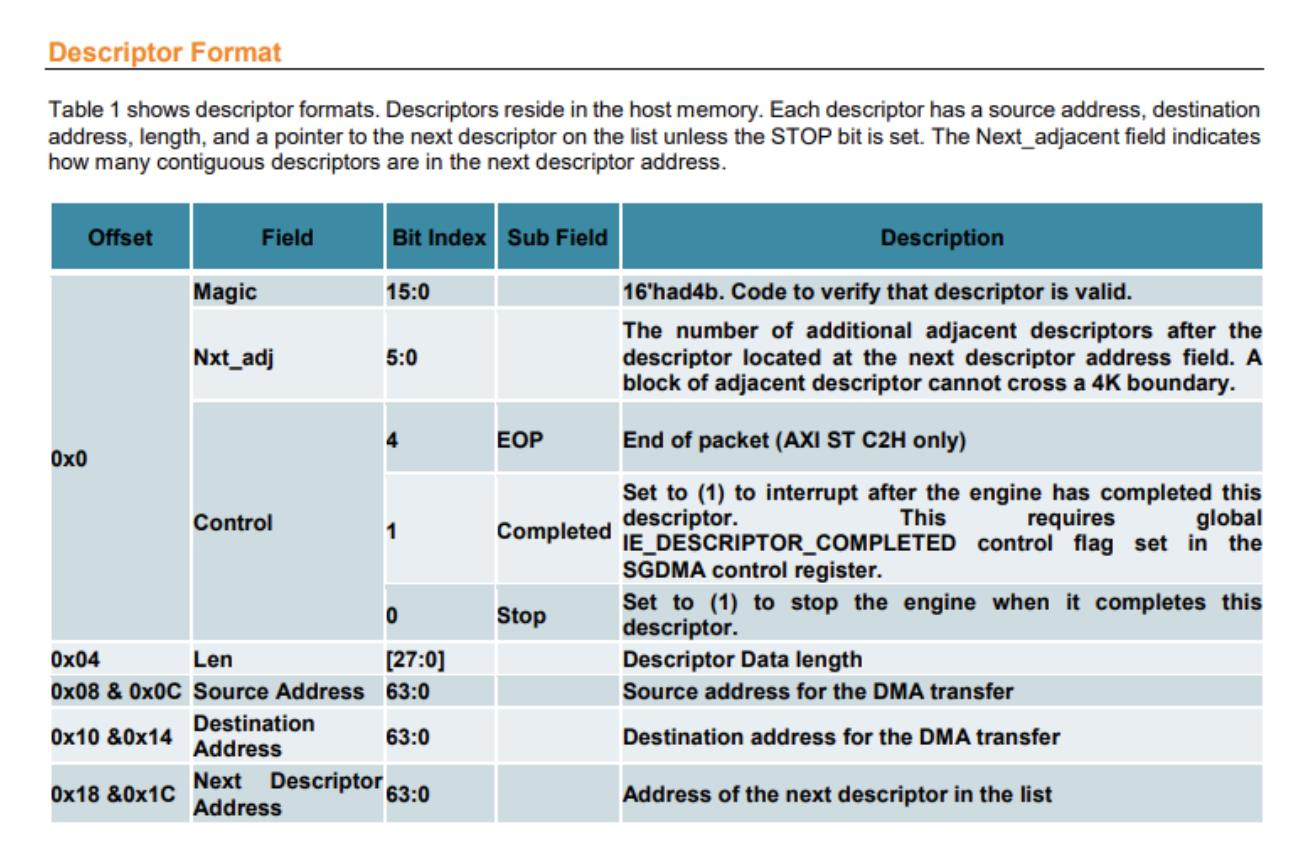
2.2 本质问题
DD位不仅是"状态位",它本质是:
DMA完成 + cache一致性 + 写回顺序 的组合语义
任何破坏一致性的因素,都会导致:
- DD已置位但软件不可见
- DD未置位但数据已有效
- descriptor被重复使用
三、异常现象:DD位"逻辑正确但物理不可见"
在问题现场,通过DPDK debug dump观察到:
- RX descriptor buffer中packet数据已正确填充
- 但status字段DD位仍为0
- PMD持续轮询该descriptor
- 队列"看似卡死",但实际DMA已完成
表现为:
RX ring局部停滞 + 业务流随机断裂
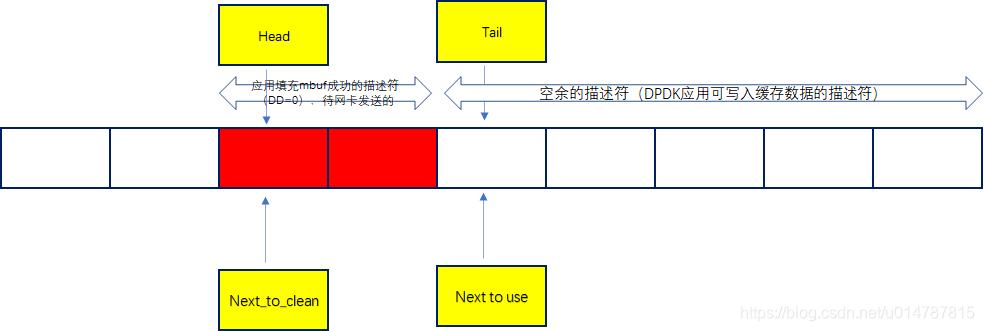
三维现象结构图
四、问题定位路径:从"包丢失"到"DD不可见"
4.1 第一步:排除协议栈
- AF_PACKET / kernel bypass无关
- RSS队列均衡正常
- flow director无异常
结论:问题在 PMD ↔ NIC descriptor 层
4.2 第二步:观察ring行为
关键指标:
rx_tail推进正常rx_head滞后异常- 某些descriptor长期未被释放
说明:
软件认为"未完成",硬件可能已经完成
4.3 第三步:抓descriptor原始状态
直接读取MMIO映射 descriptor ring:
发现:
- buffer data valid
- DD bit = 0(异常)
但硬件统计寄存器显示:
- RX packets increment 正常
形成矛盾:
硬件认为完成,软件认为未完成
五、根因分析:PCIe写回 + cache一致性断层
5.1 核心机制:Write-back延迟 + cache line竞争
现代NIC descriptor写回路径:
NIC DMA → Host Memory → CPU cache line → PMD load关键问题:
❗ 问题1:write-back未触发及时刷新
NIC完成DMA后:
- descriptor status写入host memory
- 但CPU cache line可能仍是旧值
导致:
PMD读取的是"旧cache中的DD=0"
❗ 问题2:缺失memory barrier语义
部分PMD实现中:
while (!desc->dd) {
rte_prefetch(desc);
}但缺失:
- load-acquire语义
- read barrier(rmb)
导致乱序可见性问题
❗ 问题3:PCIe relaxed ordering影响
某些平台启用:
- Relaxed Ordering
- No Snoop
可能导致:
DMA写回与CPU观察顺序不一致
六、关键突破:为什么"包已经到了但DD没翻"
最终定位到三个叠加因素:
6.1 cache line bouncing
descriptor与data buffer共享cache line边界
导致:
- data buffer被DMA更新
- descriptor status未刷新到一致性域
6.2 PMD loop过于激进
典型 fast path:
while (1) {
for (i = 0; i < BURST; i++) {
if (desc[i].dd)
process(pkt);
}
}缺少:
- rte_rmb()
- compiler barrier
6.3 descriptor reuse过早
在某些优化路径:
- software提前rearm descriptor
- NIC仍在写回状态
导致:
DD状态被"覆盖竞争"
七、修复方案:工程级优化组合
7.1 引入严格内存屏障
rte_smp_rmb();
status = desc->status;保证:
- DMA写回对CPU可见
7.2 RX descriptor分离cache line
结构优化:
- descriptor 64B对齐
- status字段独立cache line
避免:
- false sharing
- cache pollution
7.3 调整rearm策略
避免:
- 未确认DD就recycle descriptor
改为:
DD确认 → mbuf释放 → descriptor归还
7.4 关闭/调整PCIe relaxed ordering
BIOS / driver层:
- disable relaxed ordering
- enable strict ordering for RX path
7.5 PMD读取优化
增加:
- prefetch hint
- rmb fence
- batch check DD
八、体系化理解:DD位的本质不是"状态",而是"时序契约"
在高性能交换机数据面中:
DD位 = DMA完成 + cache一致性 + PCIe排序 + CPU可见性
任何一个环节失效,都可能导致"逻辑正确但不可观测"。
九、经验总结(工程视角)
围绕DPDK高性能路径,可以总结三条核心原则:
1)状态位不可信,时序才可信
DD不是绝对事实,而是延迟可见的结果。
2)DMA系统必须显式建模一致性
不能假设"写入即可见"。
3)descriptor设计必须避免cache语义耦合
否则会引入随机性问题。
十、结语:高性能系统的隐性复杂性
在高性能交换机中,真正困难的从来不是"处理包",而是:
在CPU 100% busy poll的极限状态下,让硬件、缓存、DMA与软件观察保持一致
DD位问题只是一个入口,它背后是整个数据面一致性模型的工程化挑战。
当系统规模进一步扩大,这类问题不会消失,只会以更隐蔽的方式出现。
但一旦掌握这一层语义,你会发现DPDK数据面的"黑盒",开始变得可预测、可控、可设计。