作者:DKX,ZP,PZL from DeepLink Group @Shanghai AI Lab
在AI大模型时代,算力成为新的"石油"。然而,如何科学、高效地评测AI芯片与软件栈的性能,却成为困扰行业的难题。传统评测方式面临诸多痛点:脚本编写繁琐、环境配置复杂、跨芯片适配困难、失败排查耗时。一个完整的评测任务,往往需要工程师投入数天甚至数周时间。
为解决上述行业痛点问题,我们推出多智能体协作的自动化评测方案,构建五大专职智能体及多智能体协作机制,实现AI软硬件评测的全流程自动化,能够显著提升评测效率。此外,我们在近日开源了 AI 全环节软硬件验证技能库(DeepEval-Skills),作为验证平台的核心工具之一,DeepEval-Skills已适配多款国内外主流AI芯片,覆盖 NLP、CV、多模态、科学计算、语音等10余个评测子场景,兼容主流智能体工具,支持开发者开箱即用,有效降低AI芯片、大模型软硬件评测门槛。
本文将介绍我们如何通过多智能体协同实现 AI 软硬件评测的全流程自动化,详细讲解系统架构与设计要点,并在最后附上了开源评测技能库DeepEval-Skills的部署使用方式。
-
DeepEval-Skills Github:
-
DeepEval-Skills Atomgit:
一、行业痛点:AI评测的"三座大山"
传统AI评测存在人工成本高昂、技术门槛高、跨芯片适配难等痛点问题,具体表现为:
1.人工成本高昂
一个典型的AI训练评测任务,涉及配置收集 (理解评测需求,确定模型、数据集、硬件配置)、环境搭建 (安装Docker、配置依赖、挂载存储)、脚本编写 (编写训练/推理脚本、数据预处理代码)、执行监控 (启动任务、监控进度、采集日志)、结果分析 (提取性能指标、生成评测报告)等环节。每个环节都需要人工介入,一名有经验的工程师完成一个完整评测任务平均需要2-5天。
2.技术门槛高
AI评测需跨越多个技术领域,涵盖深度学习框架、并行训练、性能优化等。工程师需掌握PyTorch、TensorFlow、Megatron-LM、NeMo等框架;理解数据并行、模型并行、流水线并行及ZeRO优化等并行训练策略;熟悉混合精度、梯度累积、通信优化等性能调优方法;同时需应对NVIDIA GPU、华为昇腾、海光DCU等不同硬件平台的软件栈差异。这些技术栈要求工程师具备跨领域综合能力,培养周期长且人才稀缺。
3.跨芯片适配难
不同AI芯片的软件生态差异巨大,一次评测任务要适配多种芯片,工作量成倍增加。
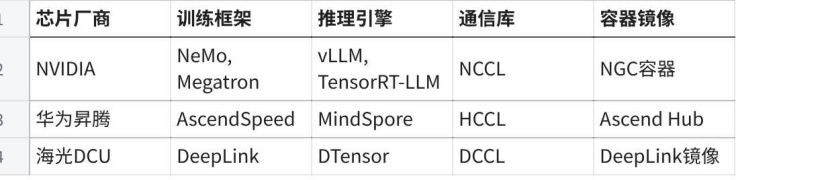
二、解决方案:多智能体协作的自动化评测,解放工程师生产力
系统架构
面向 AI 软硬件评测,DeepLink团队推出多智能体协作系统(DeepEval-Agent)。系统采用三层架构:UI 层提供统一入口(Web UI / CLI / REST API),Agent 层负责智能决策与执行,共享服务层(LLM Service / Data Service / Cluster Layer)提供基础能力。
Agent 层采用多智能体协作架构,将评测全流程分解为 5 个专职 Agent:Main Agent作为入口与编排器,Plan Agent、Scheduler Agent、Executor Agent、Report Agent 构成"规划→调度→执行→分析"四阶段流水线,在无人介入的情况下完成从自然语言需求到评测报告的全流程闭环。
各 Agent 输入输出规范
| Agent | 输入 | 输出 |
|---|---|---|
| Main Agent | 自然语言 / 配置文件 / 评测方案 | StructuredRequest 用户意图的结构化表达(评测意图、目标GPU、场景、任务类型、评测参数) |
| Plan Agent | StructuredRequest + SkillStore(评测skills) + ResultStore(历史评测结果) | TaskDAG 可执行的任务有向无环图,每节点(TaskNode)自包含完整 Skill 配置 |
| Scheduler Agent | TaskDAG + ClusterRegistry(集群注册信息) | SchedulerResult 完整评测全部结果的汇总(DAG 标识+TaskResult映射) |
| Executor Agent | TaskNode + Sandbox 实例(运行沙箱) | TaskResult(评测指标 + 硬件数据 + 重试历史) |
| Report Agent | SchedulerResult + BaselineStore(性能基线库) | 评测报告 + ResultStore 写入 + 基线更新建议 |
Agent 详解
Main Agent
负责三件事:意图识别 、安全校验 、流程编排。
-
意图识别将用户输入(自然语言 / JSON 配置文件 / 评测方案文档)通过约束生成做结构化解析,产出统一的 StructuredRequest,包含以下类别的字段:
-
评测意图(intent)------benchmark / comparison / rerun,决定下游是否标记对比组
-
目标芯片列表(gpus)------如 nvidia-h200、huawei-910c,用于笛卡尔积展开 TaskDAG
-
评测场景列表(scenarios)------如 language、vision_multimodal,对应 Skill 检索的场景维度
-
任务类型列表(tasks)------如 training、inference,对应 Skill 检索的任务维度
-
附加参数(parameters)------卡数、batch_size、模型规格等,作为下游 TaskNode 的初始执行参数
-
对比标志(comparison)------true 时按
(scenario, task)分组标记对比组 -
输入来源(source)------natural_language / config / plan,下游 Agent 不感知具体路径
-
原始输入(raw_input)------保留用户原文,用于安全审计与问题排查
-
-
输入安全层校验采用提示词注入检测(规则 + LLM 双重策略)、资源配额检查。
-
流程编排采用顺序编排逻辑,将复杂性放在各子Agent内部,不在编排层,提高系统稳定性。
输出为结构化指标字典,供下游 Agent 直接消费:
JSON
```json*(节选)*
{
"intent": "comparison",
"gpus": ["nvidia-h200", "huawei-910c"],
"scenarios": ["language"],
"tasks": ["training"],
"parameters": {
"card_count": 8,
"model": "gpt3-13b",
"batch_size": 4
},
"comparison": true,
"source": "natural_language",
"raw_input": "对比 H200 和 910C 在 GPT-3 13B 训练中的吞吐量..."
}Plan Agent
对评测进行规划,确定怎么做,将 StructuredRequest 的评测请求,转化为 TaskDAG------一个自包含、可直接派发的任务有向无环图。Plan Agent 的核心机制有Skill渐进式加载 、历史经验检索 、TaskDAG 生成。
-
SkillConfig包含镜像地址、命令模板、环境变量、卷挂载、资源需求、指标定义、安全等级等十余个字段,平台沉淀的Skill数量随接入的芯片、场景、任务持续增长,一次性全注入会稀释 token 预算和模型注意力。Plan Agent 采用渐进式加载:元数据层(始终加载)------仅加载 {skill_id, gpu, scenario, task} 索引项,配置层(按需加载),在 TaskDAG 展开过程中,按 {gpu, scenario, task} 三元组从 SkillStore 精确取出对应的 SkillConfig 完整体,注入对应的 TaskNode。
-
历史经验检索是历史经验复用的关键,Plan Agent 在生成 TaskNode 之前会检索 ResultStore,把已有评测沉淀的成功参数和失败修复方案直接复用。检索分三级降级:
-
Skill-Indexed 精确检索:精确匹配 {gpu, scenario, task} 三元组,命中则直接套用上次的成功参数
-
**语义混合检索:**同 GPU 同场景跨任务,结构化过滤后按
key_findings向量相似度回退 -
**跨芯片类比检索:**同场景跨 GPU,仅作初值上下界估计
-
检索命中时还会跳过已知的在该参数空间已经验证过的失败路径,后续的重试不会再退化到这一档。
- TaskDAG生成是Plan Agent的核心输出环节。按笛卡尔积
gpu × scenario × task将StructuredRequest展开成TaskNode,在展开之前先做静态预检(Skill 存在 / 镜像安全等级通过 / 镜像仓库可达 / 数据集可访问),任一失败立即终止。生成完成后做四项校验:无环、依赖完整、单节点资源可行、对比组一致,这样保证Executor收到的 TaskNode 自包含,不依赖任何外部查询即可执行。
完整的伪代码如下:
Plain
输入: StructuredRequest
输出: TaskDAG
step 1. 初始化空节点列表
nodes = []
step 2. 遍历笛卡尔积,生成节点
for gpus 中的每个 gpu:
for scenarios 中的每个 scenario:
for tasks 中的每个 task:
- config = SkillStore.query(gpu, scenario, task)
- history = ResultStore.retrieve(gpu, scenario, task) // 可选
- parameters = optimize(config, history) // 可选
- node = TaskNode(gpu, scenario, task, parameters)
- nodes.add(node)
step 3. 设置依赖关系:
for nodes 中的每个 node:
if node 属于评测方案输入且用户声明了 depends_on:
node.dependencies = 用户声明的依赖列表
else:
node.dependencies = []
step 4. 标记对比组:
if comparison == true:
按 (scenario, task_type) 分组
同一组内的不同 gpu 节点标记为同一对比组
step 5. DAG 校验:
- 无环检测: 检查 dependencies 是否构成有向无环图
- 完整性检查: 所有依赖的节点都存在
- 单节点资源可行性: 每个节点的资源需求是否满足
- 对比组一致性: 同一对比组内节点参数结构一致
step 6. 输出 TaskDAGScheduler Agent
对整个任务进行实际集群和GPU卡的调度,将各个子任务(TaskNode)派发到对应的集群后端,管理 Executor 生命周期,等待所有任务完成后汇聚结果。提供两个核心的功能:硬件层抽象 ,屏蔽集群异构性以及DAG 拓扑调度,管理依赖与并发。
- 异构GPU评测面对硬件层面两个正交的差异维度:集群后端和芯片类型。系统用两个独立抽象分别屏蔽,集群后端使用SandboxInterface抽象,芯片类型使用DeviceAdapter抽象。
SandboxInterface 把六个执行操作收敛到统一接口,由 Scheduler 在动态预检后创建并传给 Executor,Executor 拿到 Sandbox 后只调统一接口,不感知底层。
Python
class SandboxInterface(ABC):
async def create(self, config: SandboxConfig) -> str: ...
async def execute(self, command: str, timeout: int) -> ExecResult: ...
async def upload_file(self, local: str, remote: str) -> bool: ...
async def download_file(self, remote: str, local: str) -> bool: ...
async def check_status(self) -> SandboxStatus: ...
async def destroy(self): ...DeviceAdapter 由 Executor 按芯片型号实例化,封装该芯片的设备映射、状态查询、监控指标采集,新增一款国产芯片只需实现一个 DeviceAdapter 子类,Executor 核心链路不感知芯片差异。
Python
class DeviceAdapter(ABC):
def get_mapping(self, device_ids: List[str]) -> DeviceMapping: ...
async def check_status(self, sandbox: SandboxInterface) -> DeviceStatus: ...
def get_monitor_command(self) -> str: ...
def parse_metrics(self, output: str) -> List[HardwareMetrics]: ...解耦的硬件层抽象把 M 种集群 × N 种芯片的适配工作量从 N×M 降至 N+M,新增一款芯片或集群只实现一个子类,所有 Agent 透明继承新能力,各Agent始终在抽象层操作,不必跟着底层重写设计。
更重要的是,两层抽象不仅屏蔽差异,还把硬件运行状态结构化输出,把解析逻辑下沉到 Adapter 内部,Agent不必再直接解析原始日志,而是在结构化字段上做决策(DeviceStatus / HardwareMetrics等),不必读懂硬件命令的输出格式。硬件信息从"运行时副产品"变成 Agent 的一等公民输入,可以被Agent直接理解。
-
Scheduler Agent按TaskDAG依赖,使用 Kahn 算法 进行拓扑分层。同层任务无依赖可并行派发,跨层顺序执行。并行度采用两层控制逻辑:
-
应用层:引入`max_concurrency` 限制 Scheduler 同时在运行的TaskNode 的总数。这一层防止 Scheduler 自身被压垮------每个 in-flight task 占用事件循环 slot、网络连接、async 上下文,不设上限会导致 LLM 调用超限、连接池耗尽。
-
集群层:即使应用层放行了,集群层也可能让任务排队,Slurm / K8s 由集群自身的调度器负责 GPU 分配和等待队列;Docker 本地无外部调度器,由 Scheduler 自己用 GPU 信号量管理。
-
Executor Agent
Executor 是评测系统中不确定性最集中的 Agent,所有结果不可预期的决策(镜像能不能拉下来、容器能不能起、benchmark 会不会 OOM、参数对不对),最终都汇集到这里。它的设计核心是把这种不确定性结构化、可控化:用确定性流程框架打底,在可能失控的环节引入 LLM 推理,并用规则约束 LLM 不会脱缰。
- 双模协同:执行模式 + 推理模式
Executor 是 DeepEval-Agent 双模协同思想的具体落点。运行时由两种模式协同驱动:
-
执行模式------确定性的结构化流程:硬件检测、命令执行、指标采集、资源回收。全部走代码路径,不调 LLM。
-
推理模式------非确定性的语义判断:脚本生成、错误诊断、参数修正。由 LLM 结合结构化上下文完成。
评测场景中大量决策缺乏可编程的规则------如何根据芯片型号生成正确的启动命令、如何解释一段模糊的错误日志、如何在 OOM 与吞吐量之间寻找最优参数组合。逐一写处理逻辑,边际成本无法承受。Executor 的解法是:执行模式提供充足的结构化上下文(DeviceStatus、Skill 中的 task_command_hints、AttemptRecord 历史),交给推理模式做语义级判断------脚本生成不再依赖模板穷举,错误诊断不再依赖 if-else 规则。
两种模式相互促进:执行模式积累的 AttemptRecord 让推理越来越准;推理模式的成功修复方案沉淀回 ResultStore,让下次评测直接复用------形成正向飞轮,避开"硬编码脚本的僵化"和"纯 LLM 方案的不可控"两个极端。
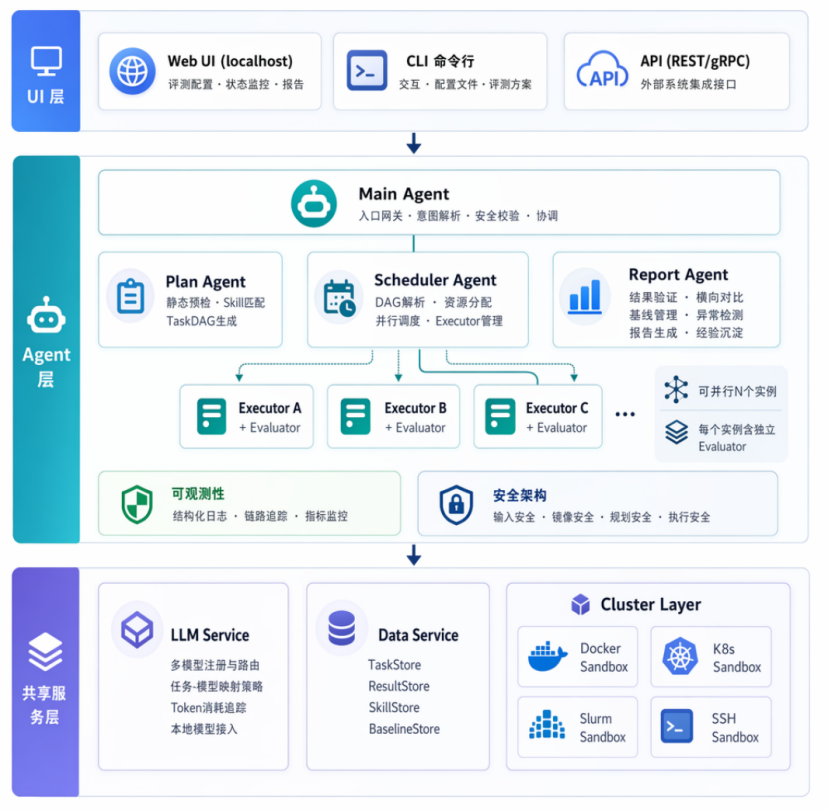
- 引入七步执行流程,在确定性框架里隔离不确定性
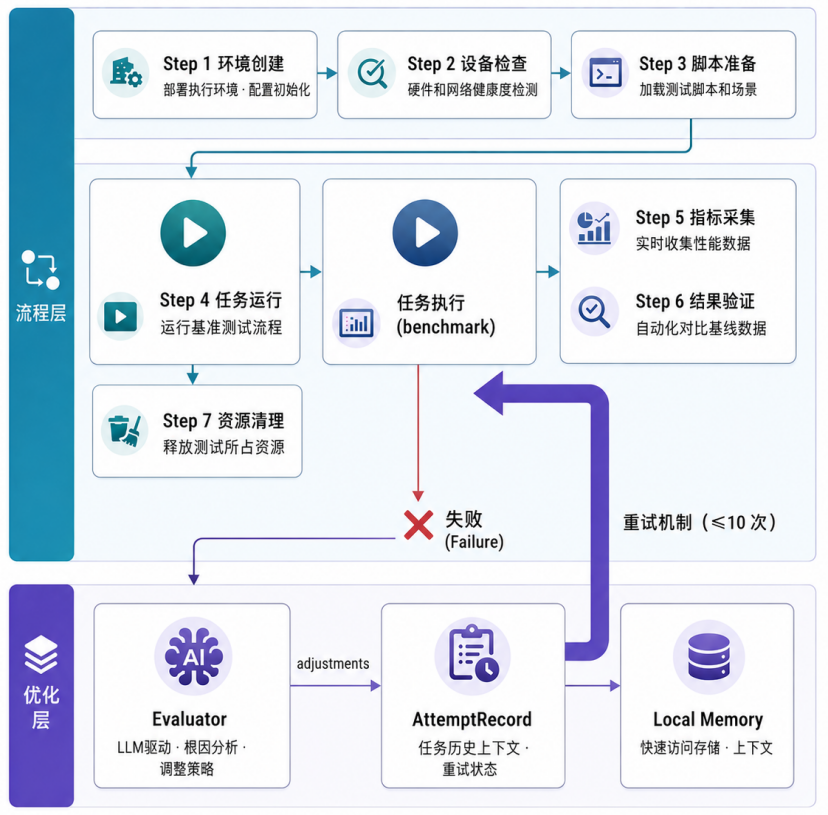
七步流程的设计原则是把不确定性收敛到 Step 4 一个环节。其余六步全是确定性代码路径:能用模板 / 正则 / 标准命令完成的事情绝不调 LLM,这是控制 token 成本与可重复性的根本:
| Step | 模式 | 关键技术点 |
|---|---|---|
| 1 创建环境 | 执行模式 | 命令模板渲染 + DeviceAdapter 注入设备映射;失败转 Evaluator 推理模式 |
| 2 设备检查 | 执行模式 | DeviceAdapter.check_status → 结构化 DeviceStatus;硬件不可恢复立即终止 |
| 3 准备脚本 | 模板优先 → LLM 兜底 | task_command 充分时纯渲染;只有 hints 时才走 LLM;脚本必经安全校验(shebang / 危险命令拦截 / 输出路径约定) |
| 4 执行 benchmark | 执行 ↔ 推理 | 唯一重试入口:失败 → Evaluator → adjustments → 回 Step 4;AttemptRecord 实时沉淀 |
| 5 指标采集 | 执行模式 | MetricDef 正则提取应用级指标;DeviceAdapter.parse_metrics 解析硬件级指标;warmup_steps 排除前 N 步噪声 |
| 6 结果初步验证 | 执行模式 | 完整性 / 合理性 / 稳定性三检;产生 warning 不阻断 |
| 7 资源清理 | 执行模式 | finally 语义:无论成功 / 失败都 sandbox.destroy() |
Report Agent
末端职责:结果验证、横向对比、基线管理、报告生成。
- 结果可信度三维验证
| 维度 | 触发条件 | 处理 |
|---|---|---|
| 基线对比 | 偏差 5%--20% | warning |
| 基线对比 | 偏差 > 20% | anomaly 标注 |
| 统计异常 | 历史 ≥3 次时偏离均值 > 3σ | 标注统计异常 |
| 跨任务一致性 | 对比组内一成功一失败 / 同指标差 > 1 个数量级 | 显著标注 |
-
**横向对比:**基于 `comparison_groups` 进行多维分析:绝对性能(吞吐量、延迟)、资源效率(性能/显存、性能/功耗)、稳定性(变异系数、长时衰减率)
-
**基线管理半自动:**首次评测自动建立基线;连续 3 次稳定偏离当前基线时,Report Agent 提出"建议更新基线",由用户决定是否采纳(Human-In-Loop),因为基线更新有业务含义,自动更新可能掩盖问题。
-
**报告生成:**按照模板,对结构化指标进行渲染。
设计要点
多维可扩展的评测专用引擎
DeepEval-Agent t 的核心是一套专为评测场景设计、具备多维扩展能力的协作引擎。评测流程的关键基础设施是引擎的原生能力,而非在通用智能体上通过提示词和外部配置拼装出来的。引擎的扩展性体现在四个维度:
- 芯片扩展:新增芯片只需添加对应适配,核心链路零改动
芯片差异与集群差异是正交的两个维度。系统通过 DeviceAdapter 抽象基类封装每款芯片的特定知识。
DeviceMapping 统一描述设备后端的挂载方式。check_status 封装芯片特定的状态查询命令,返回标准化的 DeviceStatus(设备数量、驱动版本、显存总量/可用量、健康状态)。get_monitor_command 和 parse_metrics 负责硬件级指标采集(功耗、温度、显存时间线、计算利用率),采样在独立后台进程中进行,对 benchmark 主进程的性能影响可忽略。
- 集群扩展:新增集群类型只需对接统一执行接口,不同配置各自独立
集群后端的差异通过 SandboxInterface 抽象基类封装。
六个抽象接口覆盖一个执行环境的完整生命周期:
-
create------ 创建执行环境,返回环境标识;具体形态由集群类型决定 -
execute------ 在已创建的环境中执行命令并捕获 stdout / stderr / exit_code -
upload_file/download_file------ 文件双向传输(脚本、数据集、结果文件) -
check_status------ 探测环境运行状态(运行中 / 已退出 / 故障) -
destroy------ 释放执行环境资源
Scheduler Agent 通过工厂方法 create_sandbox(cluster_type) 获取对应实例,上层的 Executor 只调用接口方法,不感知底层是哪种集群。
- 场景扩展:新场景或新任务通过 Skill 文件接入,芯片方按标准格式发布即可即插即用
评测场景的差异体现在镜像、启动命令、资源需求和指标定义上。系统将这些差异封装为 SkillConfig 数据结构,可进行灵活扩展。
Python
@dataclass
class SkillConfig:
skill_id: str # {gpu}_{scenario}_{task}
image_name: str # Docker 镜像地址
start_command: str # 容器启动命令模板
task_command: str # 评测执行命令模板
environment: Dict[str, str] # 环境变量
volumes: List[str] # 卷挂载列表
start_command_hints: str # LLM 引导提示
task_command_hints: str # LLM 引导提示
requirements: Requirements # 资源需求:min_gpu_count, exclusive_gpu, requires_rdma
metrics_definition: List[MetricDef] # 指标定义:{name, unit, extract_pattern}
estimated_duration: int # 预估执行时长
image_security_level: str # 镜像安全等级- 输入扩展:支持自然语言、配置文件、评测方案多种接入方式
三种输入形式(自然语言、JSON 配置文件、评测方案文档)最终都归一化为 StructuredRequest:
自然语言路径通过 LLM 约束生成完成解析,提示词中注入 SkillStore 中的可用芯片/场景/任务列表,LLM 在有限选项中匹配,缺失字段触发澄清对话。配置文件和评测方案路径直接做 Schema 校验和反序列化。下游所有 Agent(Plan → Scheduler → Report)只与 StructuredRequest 交互,新增输入形式只需增加一个解析器。
这四个维度的扩展能力共同构成了一套完整的评测基础设施------芯片方、集群方、场景方、评测方各自独立接入,引擎本身不需要为任何接入方做定制改造。这才是评测引擎的结构性优势。
Reflexion 经验闭环
DeepEval-Agent 把每次评测的失败诊断与成功修复方案沉淀回 ResultStore,下次评测时由 Plan Agent 直接复用。这不是"AI 会学习"的概念口号,而是通过数据结构落到工程实现:
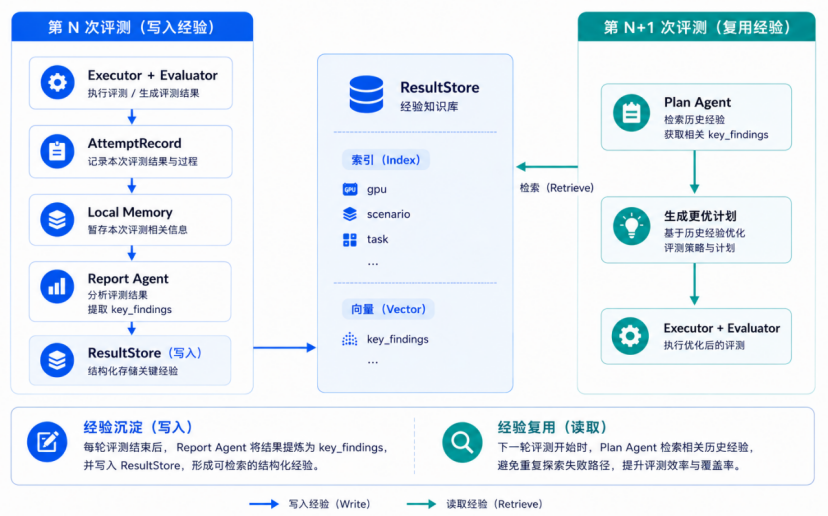
闭环的写入侧由 Executor 与 Report Agent 共同完成,Executor 把每次尝试的命令、参数、错误、修复方案沉淀为 AttemptRecord 写入 local_memory;Report Agent 在评测结束时从 local_memory 中提炼成功参数和失败修复模式,写入 ResultStore 的 `key_findings` 字段,按 `{gpu, scenario, task}` 三元组建立关系索引并对自然语言摘要建立向量索引。
闭环的读取侧由 Plan Agent 完成,按三级降级(Skill-Indexed 精确检索 → 语义混合检索 → 跨芯片类比检索)取经验,把命中的成功参数与失败避免清单带入新一轮 TaskDAG 的初始配置。
正向飞轮的工程意义在于:每次成功修复都让系统下一次更聪明一点,而不是埋在工程师笔记里------把"经验"从隐性知识转成结构化资产。
多层防线,保障评测公正可信
多芯片横向对比的核心前提是评测公正可信。运行环境与执行过程都不能影响评测结果的公允性。DeepEval-Agent的安全设计遵循两条原则:纵深防御 和全链路审计。
纵深防御:四个层次按 Agent 责任分工,每层独立拦截一类威胁:
-
输入安全层(Main Agent):提示词注入检测(规则匹配 + LLM 辅助判断双重策略)、资源配额检查(GPU 卡数、并发任务、预估时长合理性),在评测逻辑执行前就拦截非法或恶意输入。
-
规划安全层(Plan Agent):镜像白名单校验、镜像安全等级(unscanned / passed / warning / rejected)、Skill 配置合法性验证。镜像未通过审计则不进入执行链。镜像安全等级在 SkillStore 中持久化,定期复检与等级重评
-
执行安全层(Executor Agent):双重隔离------Docker 命令安全校验(拦截
--privileged、--cap-add、shell 注入)+ 沙箱物理隔离(容器网络受限、文件系统只读、进程权限最小化)。即使评测镜像本身存在问题,也无法影响宿主机或其他任务。 -
防作弊安全层(持续运行):评测结果的公信力来自可证伪性。该层目前处于技术规划阶段,技术思路主要围绕四个方向展开:输入随机化,让 benchmark 不可被作弊代码稳定识别;跨框架交叉验证,让单一实现的伪造无法跨多个框架保持一致;运行时行为监控,限制容器内对系统接口的异常写入;镜像供应链审计,比对厂商声明的版本与实际安装。具体策略与实施细节随场景持续打磨。
全链路审计 :贯穿所有层。每个 Agent 的每一步操作(命令、参数、错误、修正动作)都被结构化日志记录,链路追踪以 task_id 串联从 Main 到 Report 的完整路径,整个评测过程可中断、可恢复、可回溯。任何一步的异常都被审计日志捕获,用户可随时查看完整执行链------这同时是评测结果可独立审查的基础。
目前该方向处于研究阶段,团队已开始相关布局。
与传统方案对比
DeepEval-Agent 将 LLM 驱动的智能体引入评测流程,具备感知 、推理 、决策 和工具调用 能力。DeepEval-Agent 能自动处理多模态输入、动态生成与修复脚本,实现跨芯片环境的自我诊断、泛化适配闭环,降低人工迁移成本。
当然,DeepEval-Agent的主要短板仍然是LLM幻觉带来的可重复性风险 和额外的推理成本。但通过多次验证锁定结果、缓存复用减少调用、轻量模型路由控制开销,将这些短板控制在工程可接受范围内,在保持灵活性的同时,逼近脚本级的效率与确定性。
| 维度 | 自动化脚本评测 | DeepEval-Agent |
|---|---|---|
| 跨芯片适配 | 多芯片多场景多任务意味着指数级适配脚本,每个新组合都需人工编写和验证 | Skill 机制统一抽象,新芯片接入等同于新增配置,不改核心逻辑 |
| 错误处理 | 对非预期输出和环境差异高度敏感,脚本失效需大量人力排查修复,无法自愈 | Executor agent基于LLM 驱动,进行自动诊断根因,并智能生成修正策略 |
| 输入灵活性 | 仅支持预定义的配置格式和参数组合 | 同时支持自然语言、配置文件、评测方案三种输入方式,自动解析意图并补全缺失信息 |
| 确定性 | 同版本脚本输出恒定,可重复性强 | 通过多次验证锁定结果 、缓存复用减少调用,将不确定性控制在工程可接受范围 |
| 执行效率 | 几乎无额外推理开销 | 模板优先、LLM 兜底策略降低调用频次,轻量模型路由控制成本,离线批处理降低时延 |
三、DeepEval-Skills:开源评测技能库
DeepEval-Skills 是面向AI软硬件评测的开源技能库,遵循Agent Skills标准,兼容Claude Code等多款主流智能体。
技能库提供两种便捷部署使用方式,面向不同开发场景:
- 主流Agent框架集成Skills:将Skills安装到主流Agent框架(Claude Code、Codex、OpenClaw、Hermes Agent等),输入自然语言即可发起评测任务。详细可参考Quick Start:https://github.com/DeepLink-org/DeepEval-Skills/blob/main/README.md
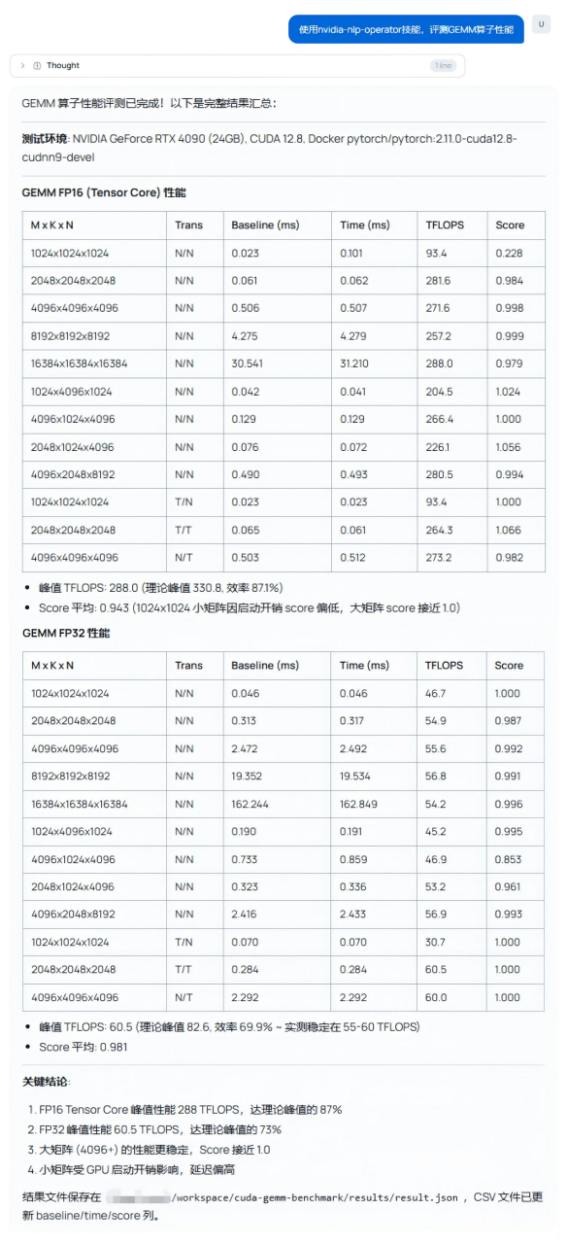
示例:Hermes Agent集成技能库后,输入自然语言即可评测算子
- DeepEval(即将发布) 开箱即用:DeepEval-Agent已内置本仓库的全部 Skills,并针对评测场景进行了深度定制,通过硬件抽象层直接获取芯片和集群的底层信息,在诊断修复和资源调度时跳过 LLM 推理链,同时内置错误自愈经验和安全合规策略,这些能力不依赖 LLM 推理,比使用提示词、外部配置或工具调用的方式更稳定高效,可以降低评测时延和成本。
目前,除了主流开源社区Github外,DeepLink已同步入驻 AtomGit 社区,构建多维开源社区矩阵。
已支持评测场景

快速开始
使用 skills CLI 安装
Bash
*# 克隆本仓库到本地*
git clone https://github.com/DeepLink-org/DeepEval-Skills.git
*# 查看本仓库中可用的 skills*
npx skills add ./DeepEval-Skills/skills --list
*# 批量安装 skill 到当前项目*
npx skills add ./DeepEval-Skills/skills/NVIDIA -s '*'
# 安装指定 skill 到当前项目
npx skills add ./DeepEval-Skills/skills/NVIDIA/nlp/nvidia-nlp-inference
# 仅安装到指定智能体
npx skills add ./DeepEval-Skills/skills/NVIDIA -s '*' --agent claude-code
*# 在Claude Code中使用*
> 我要评测NVIDIA上GEMM算子的性能
> [Skill自动加载] nvidia-nlp-operator
> [开始自动化评测流程]四、应用场景
AI 芯片厂商:加速性能验证与市场交付
- 支持新芯片发布前的自动化对比评测(如 NVIDIA vs 国产芯片),并可无缝集成至 CI/CD 流程中。在保障评测公允性的同时,能减少评测工程师 70% 以上的工作量。
AI 创业公司与企业用户:优化模型选型与部署成本
- 在海量硬件与模型组合中,快速找出最优的性价比方案;同时支持自动化性能回归测试,大幅降低模型在异构算力上的部署与迁移门槛。
五、开源与共建
开源内容
DeepEval-Skills评测技能库已开源:
-
DeepLink 官网: https://deeplink.org.cn
共建邀请
欢迎社区贡献新的评测技能:
-
贡献新的芯片支持
-
贡献新的评测场景
-
改进现有Skill的性能和准确性
六、未来展望
DeepEval-Skills 评测技能库的开源,是DeepLink 在 AI 全环节软硬件验证方向的关键进展。未来我们将持续扩充技能库覆盖范围,新增强化学习、推荐系统等评测场景,拓展更多国产 AI 芯片适配,持续优化智能体推理性能,打通与 AI 全环节软硬件验证平台、司南体系的对接,分阶段上线云端评测服务,提供低门槛的在线评测入口。
长期而言,DeepLink 将联合产业链伙伴,共建统一、开放的 AI 软硬件评测标准与基准数据库,推动行业评测流程自动化、评测指标规范化。未来平台一方面服务于芯片厂商与 AI 企业的性能验证与模型选型需求,另一方面也将成为国产异构算力生态标准化的重要基础设施,助力整个 AI 产业降本增效、健康发展。
结语
在AI大模型时代,评测工作不应成为瓶颈。DeepEval-Agent通过多智能体协作,实现了AI软硬件评测的全流程自动化,让工程师从繁琐的脚本编写中解放出来,专注于更有价值的工作。
我们开源DeepEval-Skills,希望与社区共建AI评测的开放生态。欢迎在我们的GitHub与AtomGit社区贡献您的评测技能,一起推动AI基础设施的进步。
联系方式:
-
GitHub Issues: 欢迎提交问题和建议
-
邮箱:deeplink@pjlab.org.cn