SmolVLA:轻量级视觉-语言-动作机器人模型的技术原理与落地实践
论文信息
标题 :SmolVLA: A vision-language-action model for affordable and efficient robotics
会议 :arXiv:2506.01844v1 cs.LG
单位 :Hugging Face、索邦大学、valeo.ai、巴黎萨克雷高等师范学院
代码 :https://github.com/huggingface/lerobot/tree/main/src/lerobot/policies/smolvla
论文:https://arxiv.org/pdf/2506.01844v1.pdf
一、引言:机器人通用大脑的"算力内卷"破局
自从RT-2把大模型搬进机器人之后,视觉-语言-动作(VLA)模型就成了机器人领域的当红赛道。但热闹归热闹,真正能上手玩的人没几个------主流VLA动则几十亿参数,训起来要集群显卡,跑起来要专业服务器,普通实验室和小团队根本碰不起,妥妥的"富人游戏"。
除了模型大,数据也是一道坎。顶尖VLA都靠工业界百万级的专业演示数据喂出来,社区里零散的低成本机器人数据根本入不了法眼。但现实是,越来越多的爱好者用千元级机械臂在攒数据,这些"野生数据"就像散落在各地的零件,没人把它们拼成能用的通用模型。
这篇工作推出的SmolVLA,就是冲着"把VLA拉下神坛"来的。它的核心目标很直白:用最少的参数、最少的数据、最低的算力,做出能打的通用机器人策略。最终交出的答卷是:
- 总参数仅4.5亿,是OpenVLA的1/15、RT-2-X的1/120;
- 预训练只用了2.3万条社区公开演示,比工业级数据集小一个数量级;
- 单张消费级显卡就能训、就能跑,甚至CPU都能推理;
- 性能直接打平甚至超越30亿参数级的VLA模型,在10+任务上全面领先同体量方法。
下图是SmolVLA的整体定位与架构概览:
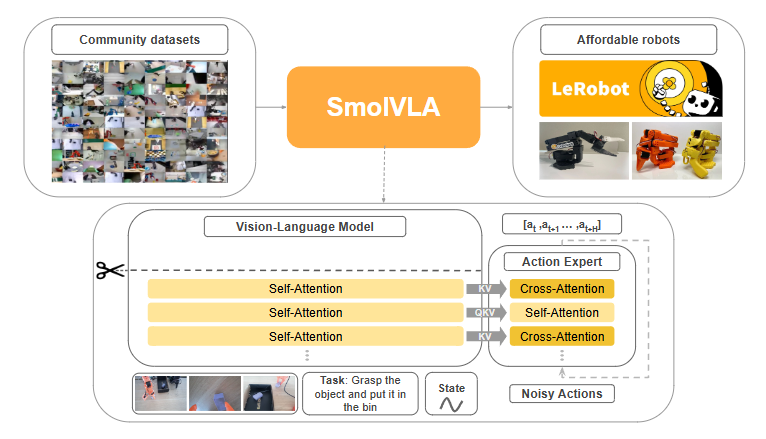
图1:SmolVLA整体架构示意。左侧为社区数据集预训练,中间为截断层的轻量VLM主干,右侧为交叉注意力+自注意力交替的动作专家模块,最终输出连续动作序列。
出处:原文Figure 1
通俗解释:
之前的VLA就像重型卡车,拉得多但油耗高、驾照难考、一般人开不起;SmolVLA就像新能源小货车,体型小、能耗低、普通人就能开,拉货能力居然还不比重卡差多少,性价比直接拉满。
二、模型整体架构:感知与控制解耦
SmolVLA没有搞复杂的端到端大一统设计,而是走了"感知大脑+动作专家"的解耦路线:前面用轻量VLM负责看懂环境、听懂指令,后面用专门的动作生成模块输出机器人控制指令,两部分各司其职,既能复用成熟的多模态预训练能力,又能保证动作生成的效率和精度。
2.1 两大核心模块
整个模型由两个核心组件构成:
- 视觉-语言模型(VLM)主干:负责环境感知与语义理解,输入图像、语言指令、机器人本体状态,输出融合后的多模态特征。
- 动作专家(Action Expert):负责连续动作生成,以VLM输出的特征为条件,基于Flow Matching生成一段连续的动作序列。
通俗解释:
VLM就像班长,负责看清楚现场情况、听明白任务要求,整理成一份行动纲要;动作专家就像操作手,拿着行动纲要,一步步算出机器人每个关节该怎么动。班长不用会拧螺丝,操作手不用会读说明书,分工明确效率才高。
2.2 VLM主干:极致轻量化设计
VLM没有选动辄几十亿的大模型,而是用了SmolVLM-2这个专为多模态效率优化的小模型。视觉编码器用SigLIP,语言解码器用SmolLM2,天生就适合处理多图和视频输入。
在此基础上,作者又做了三层"瘦身"操作:
- 视觉token压缩:通过像素洗牌(Pixel Shuffle)操作,把每帧图像的视觉token压缩到64个,是常规VLM的1/4,空间信息没丢多少,计算量直接砍四分之三。
- 层截断(Layer Skipping):不用VLM的全部解码器层,只取前N层。实验证明取前一半层数时,性能只掉一点点,推理速度直接翻倍。
- 冻结VLM主干:预训练和微调阶段都冻结VLM的参数,只训练动作专家。既保住了通用语义能力,又把训练参数量压到了最低。
有趣案例:
这就像给手机做续航优化:把2K屏降到1080P(压缩视觉token)、后台只留一半APP运行(截断解码器层)、核心系统不更新只装新软件(冻结VLM只训动作头)。看起来每步都在"减配",实际体验几乎没差,续航直接翻倍。
2.3 多模态输入融合
三种输入分别处理后拼接成统一的token序列送入解码器:
- 语言指令:直接分词为文本token
- RGB图像:经SigLIP编码为视觉token,压缩后送入
- 本体状态:关节角度、夹爪状态等传感器数据,经线性层投影为1个状态token
这种设计把机器人的本体状态也融入了语义理解,让模型知道"自己现在胳膊抬到哪了",而不是只看图像瞎猜。
三、核心数学原理:Flow Matching动作生成
动作专家是SmolVLA的核心创新之一,它没有用传统的回归损失,也没有用离散token化,而是选择了Flow Matching(流匹配)来生成连续动作序列。和扩散模型思路类似,但训练更稳定、推理步数更少,天生适合连续控制场景。
3.1 Flow Matching基础公式
Flow Matching的核心思想是:学习一个向量场,把噪声样本"流"向真实数据分布。对应到机器人场景,就是从随机噪声动作出发,沿着学到的向量场一步步流动,最终得到合理的动作序列。
训练损失函数定义如下:
Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∥vθ(Atτ,ot)−u(Atτ∣At)∥2 \mathcal{L}^{\tau}(\theta)=\mathbb{E}{p(A{t}| o_{t}),q(A_{t}^{\tau}| A_{t})}\left \\left\\\| v_{\\theta }(A_{t}\^{\\tau },o_{t})-u(A_{t}\^{\\tau }\| A_{t})\\right\\\| \^{2}\\right Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∥vθ(Atτ,ot)−u(Atτ∣At)∥2
符号逐一解释:
- Lτ(θ)\mathcal{L}^{\tau}(\theta)Lτ(θ):第τ\tauτ步的训练损失,参数为θ\thetaθ,最终对所有步数取期望
- E⋅\mathbb{E}\\cdotE⋅:数学期望,对所有样本和所有噪声步取平均
- p(At∣ot)p(A_t | o_t)p(At∣ot):给定观测特征oto_tot时,真实动作序列AtA_tAt的概率分布,也就是人类演示的动作分布
- q(Atτ∣At)q(A_t^\tau | A_t)q(Atτ∣At):从真实动作AtA_tAt加噪得到第τ\tauτ步带噪动作AtτA_t^\tauAtτ的概率分布
- vθ(⋅)v_\theta(\cdot)vθ(⋅):动作专家网络,可训练参数为θ\thetaθ;输入是带噪动作AtτA_t^\tauAtτ和观测特征oto_tot,输出是预测的向量场
- AtτA_t^\tauAtτ:第τ\tauτ步的带噪动作序列,由真实动作和噪声线性插值得到
- u(Atτ∣At)u(A_t^\tau | A_t)u(Atτ∣At):真实的向量场(也叫条件流场),是训练的"标准答案"
- ∥⋅∥2\|\cdot\|^2∥⋅∥2:均方误差,衡量预测向量场和真实向量场的差异
带噪动作的插值公式为:
Atτ=τAt+(1−τ)ϵ A_{t}^{\tau}=\tau A_{t}+(1-\tau) \epsilon Atτ=τAt+(1−τ)ϵ
符号逐一解释:
- τ\tauτ:时间步变量,取值范围0到1;τ=0\tau=0τ=0时是纯噪声,τ=1\tau=1τ=1时是真实动作
- AtA_tAt:真实动作序列(人类演示)
- ϵ\epsilonϵ:高斯噪声,服从标准正态分布N(0,I)\mathcal{N}(0, I)N(0,I)
- AtτA_t^\tauAtτ:插值后的带噪动作
真实向量场的表达式非常简洁:
u(Atτ∣At)=ϵ−At u(A_{t}^{\tau} | A_{t})=\epsilon-A_{t} u(Atτ∣At)=ϵ−At
符号含义同上。也就是说,网络只需要预测"噪声减去真实动作"这个恒定的向量场,训练目标极其简单稳定。
通俗解释:
你可以把动作分布想象成一片山地,合理的动作在山谷底,不合理的动作在山坡上。Flow Matching就是教你一条从山顶(纯噪声)滑到谷底(真实动作)的滑道。训练的时候,给你看半山腰的位置,让你预测滑道的方向;练多了,随便从哪个山顶出发,你都能顺着滑道滑到谷底,得到合理的动作。
3.2 交错注意力结构
动作专家的网络结构是Transformer,但和常规Transformer不一样,它采用了交叉注意力(CA)与因果自注意力(SA)交替堆叠的设计:
- 交叉注意力层:动作token作为Query,VLM输出的特征作为Key和Value,让动作生成"看着环境来",实现条件控制。
- 因果自注意力层:动作token之间互相注意,加上因果掩码,保证每个动作只能看到自己和之前的动作,维持时序连贯性。
之前的方法要么只用交叉注意力,要么只用自注意力,而SmolVLA通过实验证明,两者交替搭配效果最好:交叉注意力保证动作和场景对齐,自注意力保证动作序列平滑不抖。
通俗解释:
这就像开车,交叉注意力就是看路,保证车往正确的方向走;自注意力就是保持方向盘平稳,不会左右乱晃。只看路不扶方向盘,车会走S线;只扶方向盘不看路,会开沟里去。两者交替兼顾,才能开得又准又稳。
四、关键工程优化:从层裁剪到异步推理
光有算法设计还不够,SmolVLA能做到"消费级显卡可用",靠的是一堆实打实的工程优化。
4.1 VLM层截断:算力砍半性能不减
层截断是SmolVLA最反常识的优化之一:把VLM的解码器层砍掉一半,效果居然比用完整模型差不了多少,甚至在某些任务上还更好。
背后的原理是:VLM的底层负责提取基础的视觉、语言特征,高层更多负责复杂的语义推理和文本生成。而机器人控制不需要写长文,只需要基础的视觉理解和指令对齐,用底层特征就足够了。
实验验证:用32层的5亿参数VLM,只取前16层,性能只掉2%左右,计算量直接减少一半。这比直接用一个16层的小VLM效果还好------相当于用大模型的底层能力,享受了大模型预训练的红利,又只付小模型的算力成本。
4.2 推理加速:10步完成动作生成
Flow Matching天然支持少步推理,训练时用多步保证精度,推理时只需要10步就能生成高质量动作。配合层截断、token压缩,单张RTX 4090上能轻松跑到实时控制的帧率。
4.3 异步推理:控制速度提升30%
常规的VLA推理是"看一眼→算一串动作→全执行完→再看下一眼",执行动作的时候算力闲着,看图像的时候机器人等着,两边都有浪费。
SmolVLA提出了异步推理栈:把动作预测和动作执行解耦,机器人一边从队列里取动作执行,一边后台悄悄算下一段动作,两边并行不耽误。
核心控制逻辑是:动作队列里剩余动作少于阈值ggg时,就触发一次新的观测和推理,补充动作队列。阈值ggg是调节算力和响应速度的旋钮:
- g=0g=0g=0:完全同步,执行完才推理,算力最省但机器人会卡顿等待
- g=0.7g=0.7g=0.7:异步平衡模式,队列剩30%时就补新动作,算力和响应速度最优
- g=1g=1g=1:每步都推理,响应最快但算力消耗最大
下图展示了不同阈值下动作队列的长度变化:
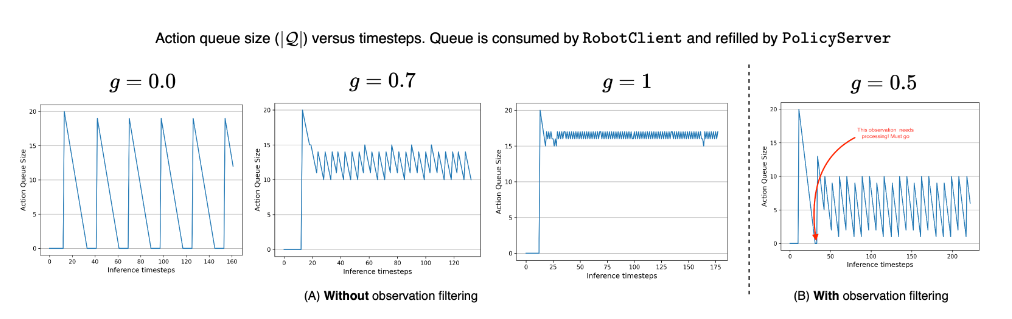
图3:不同阈值下动作队列长度随时间的变化。A为无重复观测过滤,B为加入关节空间相似性过滤,避免重复推理浪费算力。
出处:原文Figure 3
有趣案例:
这就像外卖配送的调度逻辑。同步模式是骑手送完一单回店里取下一单,路上空跑浪费时间;异步模式是店里提前出餐,骑手送完一单刚好回来接下一单,无缝衔接。同样的人力,单量直接提升30%,效率高多了。
异步推理还有一个隐藏优势:推理可以放在远程服务器上跑,机器人本体只需要接收动作队列就行。低算力的嵌入式机器人也能用上大模型策略,不用把显卡装在机器人身上。
五、社区数据预训练:小数据也能训出通用能力
SmolVLA另一个反常识的点是:它的预训练数据完全来自社区公开数据集,没有工业级的百万级演示,也能练出不错的泛化能力。
5.1 数据集概况
预训练数据来自Hugging Face上的481个社区数据集,总共2.29万条轨迹、1060万帧图像,覆盖多种机械臂、多种场景、多种任务。
| 数据集数量 | 轨迹总数 | 图像总帧数 |
|---|---|---|
| 481 | 22.9K | 10.6M |
表1:社区预训练数据集统计
出处:原文Table 1
这个数据量是什么概念?比RT-2、OpenVLA用的数据集小了至少一个数量级,真正的"小样本预训练"。
5.2 数据标准化:给野生数据"整容"
社区数据最大的问题是"乱":每个数据集的摄像头命名不一样、任务描述写得乱七八糟、数据质量参差不齐。直接拿来训肯定训崩,所以作者做了两步标准化处理:
- 任务标注自动补全:用现成的VLM(Qwen2.5-VL-3B)给每个数据集自动生成规范的动作式指令,把"随便动动""往上走"这种模糊描述,改成"把红色方块放进右边的盒子"这种清晰指令。
- 摄像头视角归一化:手动把每个数据集的摄像头映射成标准视角(顶视、腕视、侧视),统一命名顺序,避免模型搞混"哪个摄像头拍的是哪"。
通俗解释:
这就像整理一堆不同人拍的错题本,有的写得龙飞凤舞,有的题目都没写全。你先统一用标准字体抄一遍(自动补全标注),再按科目分类摆好(视角归一化),这样拿去训练学习效率才高。
六、实验评测:小体量打平大模型
作者在仿真和真实机器人两大场景、多个基准上做了全面评测,验证SmolVLA的性能、泛化能力和效率。
6.1 仿真环境基准测试
首先在LIBERO和Meta-World两个经典仿真基准上测试,对比不同参数量的模型和主流基线方法。
LIBERO多任务结果
LIBERO包含空间泛化、物体泛化、目标泛化、长时序四种任务类型,考验模型的综合泛化能力。
| 方法 | 参数量 | 空间泛化 | 物体泛化 | 目标泛化 | 长时序 | 平均成功率 |
|---|---|---|---|---|---|---|
| Diffusion Policy | - | 78.3% | 92.5% | 68.3% | 50.5% | 72.4% |
| Octo | 0.09B | 78.9% | 85.7% | 84.6% | 51.1% | 75.1% |
| OpenVLA | 7B | 84.7% | 88.4% | 79.2% | 53.7% | 76.5% |
| π₀ (VLM初始化) | 3.3B | 87% | 63% | 89% | 48% | 71.8% |
| π₀ (机器人预训练) | 3.3B | 90% | 86% | 95% | 73% | 86.0% |
| SmolVLA | 0.24B | 87% | 93% | 88% | 63% | 82.75% |
| SmolVLA | 0.45B | 90% | 96% | 92% | 71% | 87.3% |
| SmolVLA | 2.25B | 93% | 94% | 91% | 77% | 88.75% |
表2:LIBERO仿真基准成功率对比
出处:原文Table 2
结果分析:
- 4.5亿参数的SmolVLA,平均成功率87.3%,直接超过33亿参数的π₀(86.0%),是7B OpenVLA的1.14倍。
- 长时序任务上优势尤其明显,SmolVLA 71% vs OpenVLA 53.7%,说明流匹配生成的动作序列时序连贯性更强。
- 参数量从2.4亿涨到4.5亿提升明显,再涨到22.5亿收益收窄,4.5亿是性价比最高的甜点。
Meta-World难度分级结果
Meta-World按任务难度分为简单、中等、困难、极难四档,考验模型在不同复杂度任务下的表现。
| 方法 | 参数量 | 简单 | 中等 | 困难 | 极难 | 平均成功率 |
|---|---|---|---|---|---|---|
| Diffusion Policy | - | 23.1% | 10.7% | 1.9% | 6.1% | 10.5% |
| TinyVLA | - | 77.6% | 21.5% | 11.4% | 15.8% | 31.6% |
| π₀ (VLM初始化) | 3.5B | 80.4% | 40.9% | 36.7% | 44.0% | 50.5% |
| π₀ (机器人预训练) | 3.5B | 71.8% | 48.2% | 41.7% | 30.0% | 47.9% |
| SmolVLA | 0.45B | 82.5% | 41.8% | 45.0% | 60.0% | 57.3% |
结果分析:
- SmolVLA以1/7的参数量,平均成功率比35亿的π₀高出近10个百分点。
- 难度越高优势越大,极难任务上SmolVLA 60%,比π₀高出至少16个百分点,说明小模型+流匹配在复杂动作建模上反而有优势。
6.2 真实机器人测试
仿真好不代表真机能用,作者在SO100、SO101两款低成本机械臂上做了真实场景测试。
SO100多任务结果
测试取放、堆叠、分类三个任务,多任务联合训练。
| 方法 | 参数量 | 取放 | 堆叠 | 分类 | 平均成功率 |
|---|---|---|---|---|---|
| ACT(单任务训) | 0.08B | 70% | 50% | 25% | 48.3% |
| π₀(多任务训) | 3.5B | 100% | 40% | 45% | 61.7% |
| SmolVLA(多任务训) | 0.45B | 75% | 90% | 70% | 78.3% |
表3:SO100真实机器人多任务成功率
出处:原文Table 3
结果分析:
- SmolVLA平均成功率78.3%,比35亿参数的π₀高出16.6个百分点,是ACT的1.6倍。
- π₀在简单的取放任务上拿了满分,但堆叠、分类这种需要精细操作的任务拉胯;SmolVLA各项均衡,复杂任务优势巨大。
预训练与多任务的增益
作者专门做了消融,验证社区预训练和多任务联合训练的价值:
| 配置 | 取放 | 堆叠 | 分类 | 平均成功率 |
|---|---|---|---|---|
| 单任务训练,无预训练 | 55% | 45% | 20% | 40.0% |
| 多任务训练,无预训练 | 80% | 40% | 35% | 51.7% |
| 多任务训练,有预训练 | 75% | 90% | 70% | 78.3% |
表5:预训练与多任务训练的性能影响
出处:原文Table 5
结果非常直观:
- 社区预训练带来了26.6个百分点的绝对提升,证明"野生数据"也能练出通用迁移能力。
- 多任务联合训练本身也有增益,再叠加上预训练,效果1+1>2。
SO101泛化测试
在SO101机械臂上测试乐高积木取放任务,分布内是训练过的位置,分布外是全新位置。
| 方法 | 分布内成功率 | 分布外成功率 |
|---|---|---|
| ACT | 70% | 40% |
| SmolVLA | 90% | 50% |
表4:SO101真实机器人泛化测试
出处:原文Table 4
结果:SmolVLA在分布内和分布外都领先ACT,泛化能力更强,说明预训练学到的通用技能确实能迁移到新机器人上。
下图展示了四个真实任务的起始和结束画面:

图4:四个真实机器人任务示例,A为SO100平台,B为SO101平台,覆盖取放、堆叠、分类等典型操作。
出处:原文Figure 4
6.3 异步推理效果
同步和异步两种推理模式的对比如下:
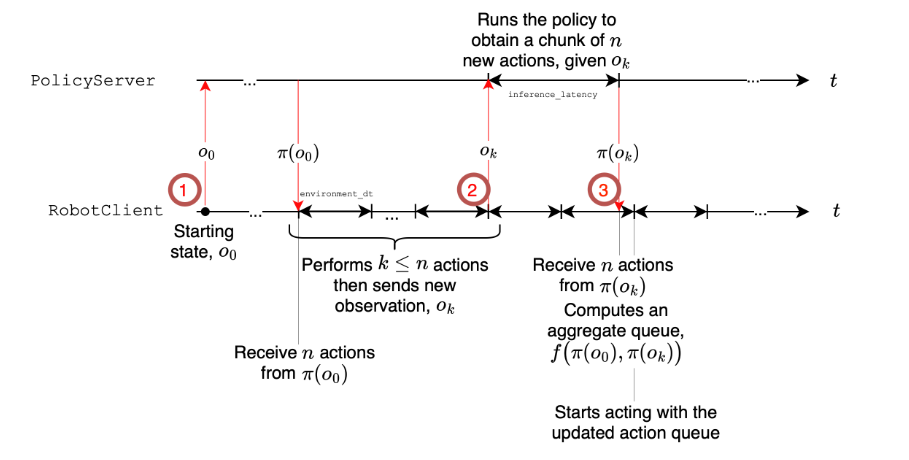
图5:同步与异步推理对比。左:成功率基本持平;中:异步任务完成时间缩短30%;右:固定时间内异步完成的任务数量翻倍。
出处:原文Figure 2
核心结论:
- 成功率几乎没降,异步模式平均73.3% vs 同步78.3%,在可接受范围内。
- 单任务完成时间从13.75秒降到9.7秒,提速约30%。
- 固定60秒内,异步能完成19次取放循环,同步只能完成9次,效率翻倍还多。
6.4 消融实验:每个设计都有道理
作者在LIBERO上做了全套消融实验,验证每个设计选择的必要性。
注意力结构消融
| 注意力机制 | 平均成功率 |
|---|---|
| 仅交叉注意力(CA) | 79.0% |
| 仅自注意力(SA) | 74.5% |
| CA+SA交替(本文) | 85.5% |
表6:注意力结构消融
出处:原文Table 6
结论:两种注意力互补,交替堆叠效果最好,比单用一种高出6个百分点以上。
因果掩码消融
| 注意力掩码 | 平均成功率 |
|---|---|
| 双向注意力 | 67.5% |
| 因果掩码 | 74.5% |
表7:注意力掩码消融
出处:原文Table 7
结论:因果掩码能防止动作"偷看未来",长时序任务上提升尤其明显,长时序任务从23%涨到40%。
VLM层截断消融
| 使用层数 | 平均成功率 |
|---|---|
| 8层 | 75.0% |
| 16层 | 78.5% |
| 24层 | 79.5% |
| 32层(全量) | 80.3% |
表8:VLM层数消融
出处:原文Table 8
结论:从32层降到16层,性能只掉1.8个百分点,速度翻倍,性价比极高;甚至隔层跳着取(Skip 50%)都比用小VLM效果好。
训练目标消融
| 训练目标 | 平均成功率 |
|---|---|
| L1回归 | - |
| Flow Matching(本文) | 85.5% |
结论:Flow Matching显著优于普通回归,因为它能建模多模态的动作分布,而回归只能学平均动作,遇到多解场景就会失效。
七、核心代码实现
下面给出基于LeRobot框架的SmolVLA核心推理与训练代码,可直接用于部署和二次开发。
7.1 推理代码
python
import torch
from lerobot.common.policies.smolvla.configuration_smolvla import SmolVLAConfig
from lerobot.common.policies.smolvla.modeling_smolvla import SmolVLA
# 加载预训练模型
config = SmolVLAConfig.from_pretrained("lerobot/smolvla")
model = SmolVLA.from_pretrained(
"lerobot/smolvla",
config=config,
torch_dtype=torch.bfloat16
).to("cuda")
# 准备输入
observation = {
"observation.images.top": torch.randn(1, 3, 512, 512).to("cuda", dtype=torch.bfloat16), # 顶视图像
"observation.state": torch.randn(1, 6).to("cuda", dtype=torch.bfloat16), # 6维关节状态
}
instruction = "把红色方块放进右边的盒子里"
# 预测动作序列(50步动作chunk)
with torch.no_grad():
action_chunk = model.select_action(observation, instruction, num_inference_steps=10)
print(f"生成动作序列形状: {action_chunk.shape}")
# 输出: [1, 50, 7] batch, 预测步数, 动作维度(6维位置+夹爪)7.2 Flow Matching训练核心代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class FlowMatchingLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, model, action_gt, condition_feat):
"""
Args:
model: 动作专家网络 v_theta
action_gt: [B, T, action_dim] 真实动作序列
condition_feat: [B, cond_dim] VLM输出的条件特征
"""
B, T, D = action_gt.shape
# 随机采样时间步 tau ~ Uniform(0, 1)
tau = torch.rand(B, 1, 1, device=action_gt.device)
# 采样高斯噪声
noise = torch.randn_like(action_gt)
# 线性插值得到带噪动作
noisy_action = tau * action_gt + (1 - tau) * noise
# 计算真实向量场 u = noise - action_gt
target_vector = noise - action_gt
# 模型预测向量场
pred_vector = model(noisy_action, tau.squeeze(), condition_feat)
# 计算MSE损失
loss = F.mse_loss(pred_vector, target_vector)
return loss
# 使用示例
if __name__ == "__main__":
from lerobot.common.policies.smolvla.modeling_smolvla import ActionExpert
# 初始化动作专家
action_expert = ActionExpert(
action_dim=7,
hidden_dim=384,
cond_dim=512,
num_layers=4,
n_heads=8
)
# 模拟输入
gt_actions = torch.randn(8, 50, 7)
cond_feats = torch.randn(8, 512)
# 计算损失
criterion = FlowMatchingLoss()
loss = criterion(action_expert, gt_actions, cond_feats)
print(f"Flow Matching损失: {loss.item():.4f}")7.3 异步推理队列实现
python
import collections
import threading
import time
class AsyncActionQueue:
def __init__(self, model, threshold=0.7, chunk_size=50):
self.model = model
self.threshold = threshold
self.chunk_size = chunk_size
self.queue = collections.deque()
self.lock = threading.Lock()
self.running = True
def get_next_action(self):
"""获取下一步动作,由机器人控制循环调用"""
with self.lock:
if len(self.queue) == 0:
return None
return self.queue.popleft()
def _inference_worker(self, observation, instruction):
"""后台推理线程,生成动作chunk并入队"""
action_chunk = self.model.select_action(observation, instruction)
with self.lock:
# 重叠部分保留旧队列,补充新动作
overlap = int(self.chunk_size * (1 - self.threshold))
for i in range(overlap, len(action_chunk[0])):
self.queue.append(action_chunk[0][i])
def check_and_trigger_inference(self, observation, instruction):
"""检查队列长度,不足阈值则触发新推理"""
with self.lock:
remaining_ratio = len(self.queue) / self.chunk_size
if remaining_ratio < self.threshold:
# 后台线程执行推理,不阻塞控制循环
thread = threading.Thread(
target=self._inference_worker,
args=(observation, instruction)
)
thread.daemon = True
thread.start()代码说明:
- 推理代码支持10步快速生成,bfloat16精度下单卡即可运行
- Flow Matching损失实现了论文中的核心训练目标,可直接替换动作头网络
- 异步队列实现了解耦的推理-执行架构,可直接接入机器人控制循环
八、总结与展望
核心结论
- 小体量也能有高性能:4.5亿参数的SmolVLA,在多个基准上超越30亿+参数的VLA模型,证明VLA领域不是"越大越好",合理的架构设计和训练目标能带来极高的性价比。
- 社区数据有大价值:仅用2万多条社区演示预训练,就能带来显著的泛化提升,说明低成本机器人数据也能撑起通用策略,不用全靠工业级大数据。
- 工程优化打通落地最后一公里:层截断、token压缩、异步推理这一套组合拳下来,消费级显卡甚至CPU都能跑,真正把VLA从实验室带到了普通人手里。
未来方向
- 更大规模的社区数据:现在只有2万多条轨迹,未来数据量上去后,小模型的性能还能继续涨。
- 端侧部署优化:进一步量化、蒸馏,做到嵌入式芯片实时运行,让小型机器人也能用上通用策略。
- 强化学习微调:目前还是纯行为克隆,未来结合在线强化学习进一步提升成功率和鲁棒性。
总的来说,SmolVLA不是简单的"把大模型改小",而是从架构、数据到推理全链路重新思考了"低成本VLA该怎么做"。它的出现意味着通用机器人策略不再是大厂的专属玩具,普通开发者用一张显卡、一套千元机械臂,就能开始自己的具身智能探索。