软件安装清单
按顺序安装以下软件:
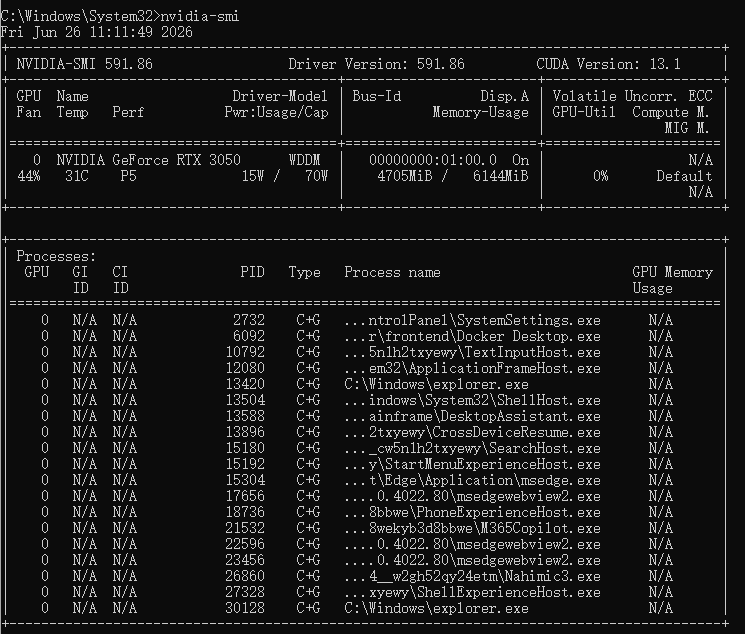
- NVIDIA 显卡驱动 :前往 NVIDIA 官网 下载最新驱动,安装后在命令行输入
nvidia-smi确认 CUDA Version 显示正常
- Git :前往 git-scm.com 下载安装 本地已有
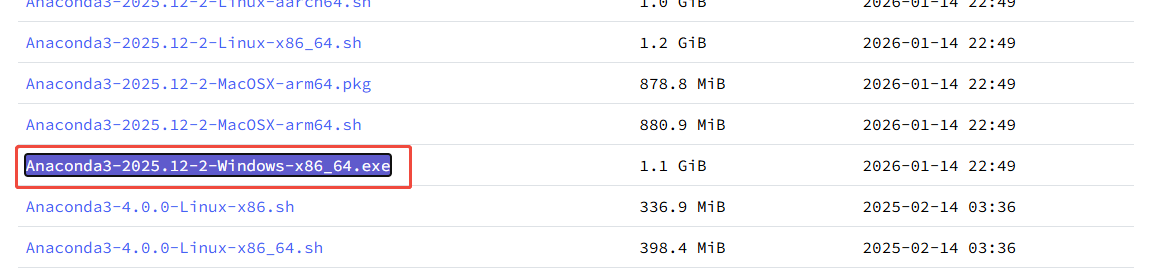
- Anaconda / Miniconda :前往 anaconda.com 下载安装,用于管理 Python 虚拟环境
国内地址:
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
- FFmpeg :用于音频/视频处理,下载后将
bin目录加入系统环境变量 PATH -----该这里了
FFmpeg 是一个开源的音视频处理工具套件,广泛用于视频转码、剪辑、合并、流媒体推流等任务。对于Windows用户,推荐直接下载编译好的可执行文件(Builds),无需自行编译。以下是详细的下载安装步骤:
-
访问官网下载页面
打开浏览器,访问 FFmpeg 官方下载地址:https://ffmpeg.org/download.html
-
选择 Windows 版本
在页面中找到 "Windows" 部分,点击 "Windows builds from gyan.dev" 或 "BtbN" 链接(推荐使用 gyan.dev,更新更频繁)。
-
下载压缩包
在 gyan.dev 页面中,找到 "ffmpeg-release-full.7z" 文件并下载。该版本包含所有常用编解码器,适合大多数用户。
-
解压到指定目录
将下载的 .7z 文件解压到一个不含中文和空格的路径,例如:C:\ffmpeg
-
配置环境变量
右键"此电脑" → "属性" → "高级系统设置" → "环境变量"。
在"系统变量"中找到 "Path",点击"编辑" → "新建",添加路径:C:\ffmpeg\bin
点击"确定"保存所有设置。
-
验证安装
打开命令提示符(CMD)或 Anaconda Prompt,输入:
ffmpeg -version
如果输出版本信息,说明安装成功。
wget -c https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-full.7z
第一步:克隆项目代码
打开 Anaconda Prompt(以管理员身份运行),执行:
# 克隆项目(国内网络慢可用 Gitee 镜像)
git clone https://github.com/lipku/LiveTalking.git
# 或使用国内镜像:
# git clone https://gitee.com/lipku/LiveTalking.git
# 进入项目目录
cd LiveTalking💡 建议项目路径中不要包含中文,避免后续报错。
cd /d D:\meta_human\LiveTalking
conda --version
第二步:创建 Python 虚拟环境
# 创建 Python 3.12 的虚拟环境(官方推荐版本)
conda create -n livetalking python=3.12
# 激活环境
conda activate livetalking

第三步:安装 PyTorch(CUDA 版本匹配)
先在命令行运行 nvidia-smi,查看右上角的 CUDA Version(这是驱动支持的最高 CUDA 版本),然后选择对应的 PyTorch:
# CUDA 12.x 版本(推荐,适用于大多数 RTX 30 系显卡)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121⚠️ Windows 上不要硬装 CUDA 11.3,建议用 CUDA 12.x + 对应 PyTorch,否则极易失败。
清华源:
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple
第四步:安装项目依赖
安装依赖:
设置国内镜像源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple

pip install -r requirements.txt第五步:下载模型文件
这是最关键的一步,需要下载两类文件:
| 网盘 | 地址 |
|---|---|
| 夸克云盘 | https://pan.quark.cn/s/83a750323ef0 |
- 将
wav2lip256.pth拷贝到项目的models/目录下,重命名为wav2lip.pth
- 将
wav2lip256_avatar1.tar.gz解压后整个文件夹拷贝到data/avatars/目录下
启动服务:
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar12.3 客户端接入
| 方式 | 说明 |
|---|---|
| 浏览器 | 打开 http://serverip:8010/index.html,点击"开始连接"播放数字人视频,在文本框输入文字提交即可 |
| API 调用 | 参考 API 文档 通过 HTTP 接口驱动 |
| 桌面客户端 | 下载地址: https://pan.quark.cn/s/d7192d8ac19b |
参考:LiveTalking: 实时交互数字人
-------------------------------------------------------------
5.1 数字人模型(Wav2Lip)
由于你是 RTX 3050,推荐使用 wav2lip256 模型(显存占用最小):
- 从项目 README 或官方文档中提供的网盘链接下载
wav2lip256.pth - 重命名为
wav2lip.pth,放入项目的models/目录下
5.2 数字人形象素材
- 下载官方提供的
wav2lip256_avatar1.tar.gz - 解压到项目的
data/avatars/目录下
💡 如果想自定义数字人形象,可以用自己的闭嘴不说话的正面视频生成:
cd wav2lip
python genavatar.py --video_path 你的视频.mp4 --img_size 256 --avatar_id wav2lip256_myavatar生成后将 results/avatars 下的文件复制到 data/avatars/ 目录。
5.3 国内下载加速
如果 HuggingFace 模型下载慢,设置镜像:
# Windows CMD 环境
set HF_ENDPOINT=https://hf-mirror.com
# Windows PowerShell 环境
$env:HF_ENDPOINT="https://hf-mirror.com"第六步:配置 TTS(文本转语音)
LiveTalking 2.0 支持多种 TTS 引擎,按复杂度排列:
表格
| TTS 引擎 | 特点 | 是否需额外部署 |
|---|---|---|
| EdgeTTS(默认) | 免费、速度快、无需 GPU | ❌ 开箱即用 |
| GPT-SoVITS | 音色克隆、质量高 | ✅ 需单独部署 |
| CosyVoice | 阿里开源、中文效果好 | ✅ 需单独部署 |
| QwenTTS(v2.0 新增) | 大模型驱动、情感丰富 | ✅ 需单独部署 |
💡 新手建议先用默认的 EdgeTTS 跑通流程,后续再升级音色。
第七步:启动服务
方式一:WebRTC 模式(浏览器交互,推荐新手)
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1启动后,用浏览器打开:
http://localhost:8010/webrtcapi.html⚠️ 需要确保防火墙放行 TCP 8010 端口和 UDP 端口。
方式二:RTMP 推流模式(用于直播平台)
先启动 SRS 流媒体服务器(通过 Docker):
docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8080:8080 \
registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5然后启动数字人服务:
python app.py --transport rtmp --model wav2lip --avatar_id wav2lip256_avatar1第八步:验证运行
启动成功后,终端会输出推理帧率信息。关注两个指标:
- inferfps(推理帧率):应 ≥ 25
- finalfps(最终帧率):应 ≥ 25
如果帧率过低,可以尝试:
- 降低分辨率(wav2lip 固定 256×256,已是最小)
- 关闭不必要的后台程序释放显存
- 确认使用的是 GPU 推理而非 CPU
📌 针对 RTX 3050 的优化建议
表格
| 优化项 | 操作 |
|---|---|
| 模型选择 | 只用 wav2lip256,不要尝试 musetalk/ernerf |
| TTS 引擎 | 用 EdgeTTS(零 GPU 占用) |
| 分辨率 | 保持 256×256(wav2lip 默认) |
| 并发数 | 只开 1 路,不要尝试多路并发 |
| 显存监控 | 运行 nvidia-smi 实时监控,确保显存不溢出 |