概述
| 大模型缺陷 | Agent解决方案 |
|---|---|
| 只能聊天 | 会执行任务 |
| 不会调用API | Tool Calling |
| 不会长期记忆 | Memory |
| 不会拆解任务 | Planning |
| 不会纠错 | Reflection |
| 不会跨系统操作 | Workflow |
| 不会自主查资料 | Agentic RAG |
| 不会使用软件 | Computer Use |
用户:
分析上个月销售数据
Agent:
Step1 调SQL工具
Step2 获取数据
Step3 Pandas分析
Step4 生成图表
Step5 输出报告
| 一级方向 | 二级技术 | 解决问题 | 难度 |
|---|---|---|---|
| Tool Agent | Tool Calling | 调接口 | ⭐ |
| Workflow Agent | DAG | 多步骤任务 | ⭐⭐ |
| Planning Agent | Task Decompose | 自动拆任务 | ⭐⭐⭐ |
| Memory Agent | Long Memory | 长期记忆 | ⭐⭐⭐ |
| Reflection Agent | Self Correct | 自我纠错 | ⭐⭐⭐ |
| Multi-Agent | Agent Team | 多角色协作 | ⭐⭐⭐⭐ |
| Agentic RAG | Autonomous Retrieval | 自动检索 | ⭐⭐⭐ |
| Computer Agent | GUI操作 | 操作电脑 | ⭐⭐⭐⭐⭐ |
| Embodied Agent | Robot Agent | 机器人 | ⭐⭐⭐⭐⭐ |
| Graph Agent | Knowledge Graph | 推理关系 | ⭐⭐⭐⭐ |
| Code Agent | Coding Agent | 写代码 | ⭐⭐⭐ |
| Data Agent | BI Agent | 数据分析 | ⭐⭐⭐ |
| Web Agent | Browser Agent | 浏览网页 | ⭐⭐⭐ |
| MCP Agent | MCP Protocol | 标准化工具 | ⭐⭐⭐⭐ |
Tool Calling
对应你表里的:
- Tool Agent ⭐
你要先搞清三件事:
- LLM如何"决定调用工具"(function calling / tool schema)
- 工具如何被注册(schema / prompt / JSON)
- 工具执行链路(LLM → tool router → function → result → LLM)
目标产物:
- 一个"能调用2~3个工具"的LLM系统
例如:
- 查天气
- 查数据库
- 调用HTTP接口
👉 没这个,后面所有 Agent 都只是"高级聊天"
什么是Tool Calling
让LLM拥有「感知外部世界」和「操作外部世界」的能力。
Q:北京天气?
LLM:
需要调用weather_tool
↓
weather_tool("北京")
↓
26℃
↓
LLM
北京今天26℃...
为什么LLM会主动调用工具
LLM不会调用工具。
LLM只会:
预测下一个Token
Question:北京天气
Tools:
weather_tool(city)
LLM预测:
{
"name":"weather_tool",
"arguments":{
"city":"北京"
}
}Function Calling原理
只是作为一个可以调用的json工具类集合给AI
AI在返回调用哪个
java
{
"name":"weather",
"description":"查询天气",
"parameters":{
"type":"object",
"properties":{
"city":{
"type":"string"
}
}
}
}模型看到
用户:
北京天气
工具:
weather
{
"name":"weather",
"arguments":{
"city":"北京"
}
}
模型并没有调用工具的能力,只是返回需要调用的工具和参数的json协议格式,由对应的来进行运行,可能是反射,可能是代理
Spring AI里面如何实现

SpringAI实际上帮你做了四件事情。
tool注册
java
@Bean
ToolCallback weatherTool(){
return MethodToolCallback.builder()
.object(weatherService)
.method("query")
.build();
}SpringAI内部
java
/**
* 工具注册中心
* 底层使用Map结构存储全部工具定义,维护工具名称与工具元数据的映射关系
* 核心职责:工具注册、工具查询、工具删除、遍历全部已注册工具
* K:toolName 工具唯一名称
* V:ToolDefinition 工具完整定义信息(入参、描述、执行逻辑、权限等)
*/
public class ToolRegistry {
// 底层存储容器
/**
* 工具映射表
* key:toolName 工具唯一标识名称,全局不可重复
* value:ToolDefinition 工具元定义对象,包含工具所有配置信息
*/
private final Map<String, ToolDefinition> toolMap;
// 构造器注释示例
/**
* 初始化空的工具注册容器
*/
public ToolRegistry() {
this.toolMap = new HashMap<>();
}
/**
* 注册工具
* @param toolName 工具唯一名称
* @param definition 工具完整定义元数据
*/
public void register(String toolName, ToolDefinition definition) {
toolMap.put(toolName, definition);
}
/**
* 根据工具名称获取工具定义
* @param toolName 工具名称
* @return 存在返回工具定义,不存在返回null
*/
public ToolDefinition getTool(String toolName) {
return toolMap.get(toolName);
}
}
java
HashMap
{
"weather"
:
ToolDefinition
}Schema生成
SpringAI自动扫描
java
String query(String city)
java
{
name:"query",
parameters:{
city:String
}
}发送给大模型。
LLM推理
用户
↓
Prompt
↓
Tools
↓
Qwen
↓
ToolCall
{
"name":"query",
"city":"北京"
}
ToolRouter
ToolCallingManager
内部逻辑
if(toolCall){
findTool()
execute()
injectResult()
}

重点研究方向
| 研究方向 | 研究问题 | 代表技术 |
|---|---|---|
| Tool Selection | 选哪个工具 | ReAct |
| Tool Routing | 多工具调度 | Router |
| Tool Planning | 工具组合 | Plan&Execute |
| Tool Learning | 自动发现工具 | Toolformer |
| Tool Reflection | 工具失败修正 | Reflexion |
| Tool Memory | 工具经验记忆 | Memory Agent |
为什么Tool Calling是Agent的地基
因为后面的所有Agent,本质上都是在Tool Calling上增加能力。
| Agent | 本质 |
|---|---|
| Tool Agent | 单工具调用 |
| Workflow Agent | Tool Calling+DAG |
| Planning Agent | Tool Calling+任务拆分 |
| Memory Agent | Tool Calling+向量记忆 |
| Reflection Agent | Tool Calling+自我评审 |
| Agentic RAG | Tool Calling+Retriever |
| Multi-Agent | Tool Calling+Agent Router |
| MCP Agent | Tool Calling+标准协议 |
| Computer Agent | Tool Calling+GUI Tool |
| Code Agent | Tool Calling+IDE Tool |
Agent ≈ LLM(大脑) + Tool Calling(手脚) + Memory(记忆) + Planning(前额叶) + Reflection(自我监督)
Workflow Agent
而DAG Workflow解决的是:
大模型如何像项目经理一样组织多个工具协同工作。 ( 因为LLM天然没有流程控制。需要一个来进程合理的顺序调度的工具**)**
帮我分析特斯拉最近一个月股票走势,并结合最近新闻给出投资建议。
①股票数据
↓
②新闻检索
↓
③新闻总结
↓
④技术分析
↓
⑤风险评估
↓
⑥生成报告
Tool Calling开始失控。
因为LLM天然没有流程控制。
LLM擅长:
推理
不擅长:
调度
DAG
DAG
Directed Acyclic Graph
有向无环图
用户问题
↓
Planner
↓
生成DAG
↓
Executor
↓
结果
允许并行。
A
/ \
/ \
B C
\ /
\ /
D
Planner(任务规划层)↓ 输出编排拓扑
TaskGraph(任务依赖拓扑载体)
↓ 传入执行引擎
Executor(任务调度执行层)
↓ 聚合全部输出
Result(统一执行结果封装)
职责分离。
DAG四个核心组件
① Node
节点
就是任务。
例如
Node1
查股票
Node2
查新闻
Node3
分析新闻
Node4
生成报告
java
class Node{
String id;
String name;
Tool tool;
}② Edge
依赖关系
Node1
↓
Node3
意思
Node3等待Node1。
java
class Edge{
from;
to;
}③ State
java
WAITING
↓
READY
↓
RUNNING
↓
SUCCESS
↓
FAILED④ Executor
遍历DAG
判断依赖
调Tool
更新State
Planner为什么存在
这是Agent研究热点。
没有Planner。
用户
分析特斯拉Executor不知道干什么。
{
tasks:[
"查股票",
"查新闻",
"分析风险",
"输出报告"
]
}
生成
DAG
股票
\
风险
/
新闻
↓
报告
Executor干什么
Executor相当于CPU。 类似Java线程池。
SpringBoot怎么设计
TaskGraph
TaskNode
PlannerService
DagExecutor
WorkflowContext
WorkflowContext
所有节点共享数据。
类似
Spring IOC。
Map<String,Object>
股票工具
context.put(
"stock"
,data
);
新闻工具
context.put( "news" ,data );
LangGraph
DAG + State Machine
Workflow(DAG)就是 Agent 的神经系统和调度中心。
| 问题 | Tool Calling | Workflow Agent |
|---|---|---|
| 单工具调用 | √ | √ |
| 多步骤任务 | × | √ |
| 工具依赖 | × | √ |
| 并行执行 | × | √ |
| 失败重试 | × | √ |
| 中断恢复 | × | √ |
| 状态管理 | × | √ |
| 长任务执行 | × | √ |

需要自己做"编排层",Spring AI / 阿里百炼(DashScope)只提供"单步模型能力 + 工具调用能力",不直接提供完整 Workflow Agent 框架。
Java生态目前不如 Python:
- LangGraph(Python)
- AutoGen(Python)
- CrewAI(Python)
自己实现 Workflow Engine + LLM
Planning Agent
传统方式
用户 │ ▼ LLM一次输出缺点
不知道过程
无法暂停
无法修改
不能重试
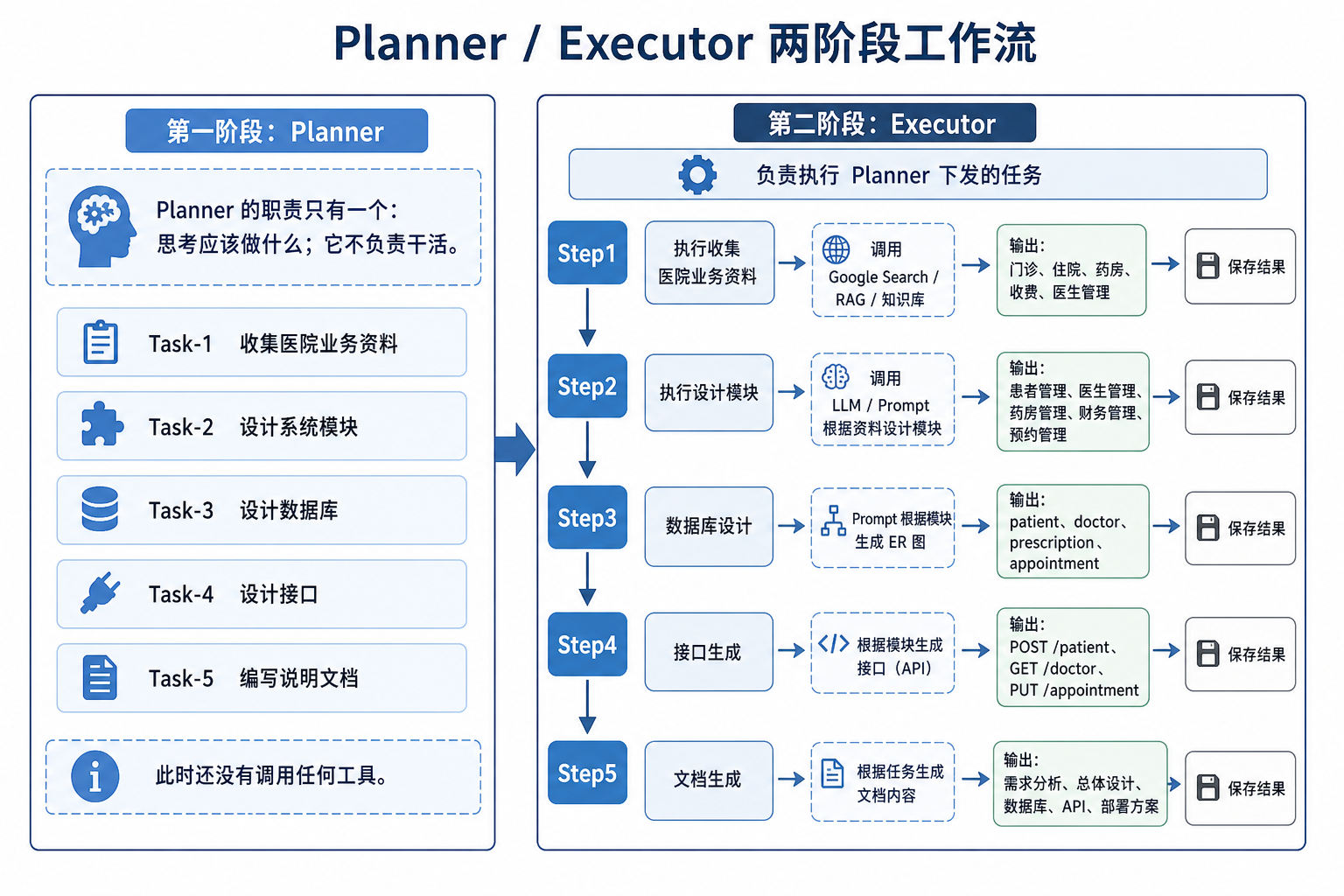
Planning Agent(任务规划代理)本质是:
将"复杂目标"拆解成可执行的结构化子任务(Task List / DAG),再交给执行模块逐步完成。
核心目标不是"回答问题",而是:
- 把问题变成步骤
- 把步骤变成可执行计划
- 把计划变成执行流程(Execute)
用户
│
▼
Planner 规划任务
│
▼
Task List 任务列表
│
▼
Executor 执行任务
│
▼
Result 结果
1. ReAct(Reason + Act)
思考 + 行动交替进行
Thought → Action → Observation → Thought → Action ...
作用:
- 一边规划一边调用工具
- 适合"动态任务"
用户:分析一个电商系统
Thought:需要了解系统结构
Action:搜索/读取资料
Observation:得到信息
Thought:开始设计模块
2. Tree-of-Thought(ToT)
树状多路径推理(不是一条路走到底)
方案A
/ \
任务 → 方案B 方案C
\ /
评估选择最优
- 多方案并行思考
- 用评分/评估函数选择最优路径
- 适合设计类任务(架构/系统设计)
3. Plan-and-Execute(规划-执行分离)
这是现在 Agent 系统的主流结构。
(1)Plan(规划器)
输入:
分析XX系统输出:
1. 信息收集
2. 模块设计
3. 数据库设计
4. 接口设计
5. 文档输出Execute(执行器)
逐步执行:
Step1 → Tool/LLM
Step2 → Tool/LLM
Step3 → Tool/LLM
...特点:
- 解耦(规划和执行分离)
- 可控性强
- 易扩展(可插 DAG / 工具)
4 区别
输入:写一个"分析XX系统"
输出:
收集信息
设计模块
设计数据库
输出文档
DAG 版本:
用户请求
│
▼
┌──────────────────┐
│ Planner │
│ (任务规划器) │
└──────────────────┘
│
▼
┌──────────────────────────┐
│ Task List │
│--------------------------│
│1. 收集资料 │
│2. 设计功能模块 │
│3. 设计数据库 │
│4. 编写API接口 │
│5. 输出设计文档 │
└──────────────────────────┘
│
▼
┌──────────────────┐
│ Executor │
│ (执行器) │
└──────────────────┘
│
┌──────────────┼─────────────┐
▼ ▼ ▼
Tool1 Tool2 Tool3
(搜索) (LLM) (DB)
│ │ │
└──────────────┼─────────────┘
▼
最终结果汇总
│
▼
输出文档
Prompt│
▼
ReAct
(边思考边执行)
│
▼
Plan-and-Execute
(先规划后执行)
│
▼
Workflow Agent
(DAG编排)
│
▼
Multi-Agent
(多个Agent协作)
│
▼
Digital Employee
(数字员工系统)
主流框架
| 框架 | 公司 | 定位 | Planning | DAG | Multi-Agent | 推荐 |
|---|---|---|---|---|---|---|
| Spring AI | VMware/Spring | Spring生态AI框架 | ★★ | × | × | ⭐⭐⭐⭐⭐ |
| LangChain4j | 社区 | Java版LangChain | ★★★ | × | ★★ | ⭐⭐⭐⭐⭐ |
| LangGraph4j | 社区 | Java版LangGraph | ★★★★ | ★★★★ | ★★ | ⭐⭐⭐⭐ |
| Semantic Kernel Java | Microsoft | 企业Agent | ★★★ | ★★★ | ★★★ | ⭐⭐⭐⭐ |
| AutoGen Java | 社区实现 | 多Agent | ★★★ | ★★ | ★★★★ | ⭐⭐⭐ |
| Jlama | 社区 | 本地模型推理 | ★ | × | × | ⭐⭐ |
| Quarkus LangChain4j | RedHat | 企业微服务AI | ★★★ | ★★ | ★★ | ⭐⭐⭐⭐ |
Spring AI 更像 Agent 的 Spring Framework ,而不是 Agent 的 LangGraph 或 AutoGen。这也是很多 Java 团队最终会走向"Spring AI + 自研编排层"的原因。
Memory Agent
为什么需要
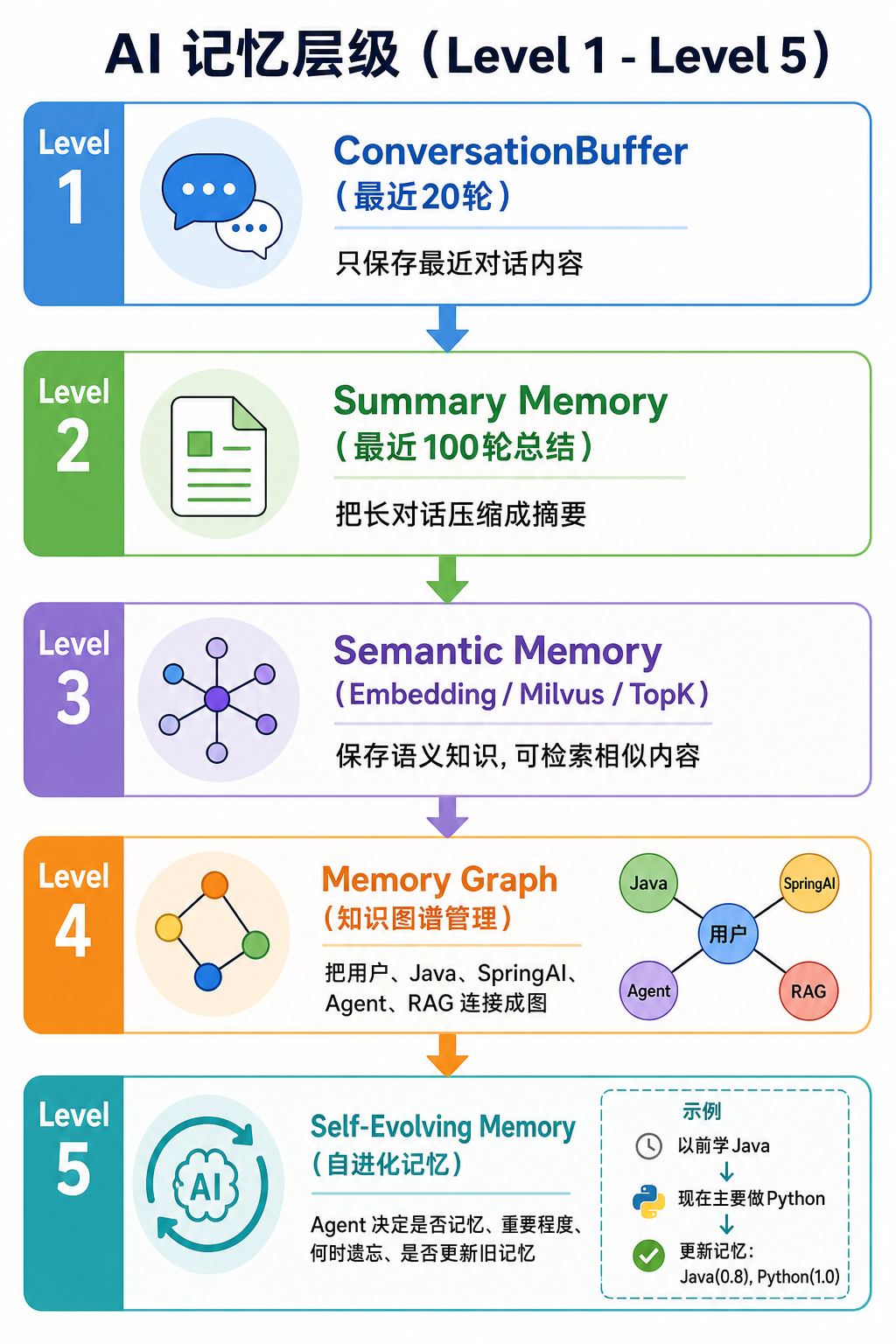
拥有可检索、可推理、可成长的长期记忆智能体(Long-term Memory Agent)
GPT上下文
最近20条消息
超出后:
遗忘
第一次用户:
我是Java开发
第二次
用户:
推荐Agent框架
Agent:
根据你的背景:
Java
SpringBoot
SpringAI
推荐:
SpringAI
Langchain4j
Semantic Kernel Java
User│
│
▼
┌─────────────────┐
│ Short Memory │
│ 最近对话 │
└─────────────────┘
│
│
▼
┌─────────────────┐
│ Memory Manager │
└─────────────────┘
│
┌──────┴──────┐
│ │
▼ ▼
Semantic Store Profile Store
向量数据库 用户画像
│
▼
Milvus
FAISS
pgvector
两种Memory
① Short Memory
上下文记忆
就是Prompt
messages=[
user,
assistant,
user,
assistant
]
| 特点 | 说明 |
|---|---|
| 速度快 | ⭐⭐⭐⭐⭐ |
| 成本低 | ⭐⭐⭐⭐⭐ |
| 容量小 | ⭐⭐ |
| 易丢失 | ⭐⭐⭐⭐⭐ |
Long Memory
真正的Memory Agent核心
不是保存聊天。
而是:
保存「知识」
用户喜欢Java
用户做Spring
用户正在学Agent
用户公司用MySQL
用户有个毕业设计
最好附带时间线
Memory写入
原始聊天
用户:
我是Java开发
最近研究SpringAI
以后想做Agent
{"user_skill":"Java",
"interest":"SpringAI",
"goal":"Agent"
}
- user_skill 存储用户掌握的核心技术栈、编程语言、专业技能,用于标识自身技术基础。
- interest 记录用户感兴趣的前沿框架、技术组件,代表学习与研究偏好。
- goal 写明技术学习、开发方向的最终目标,指明长期深耕的业务 / 技术领域。
Embedding
变成向量
我是Java开发
↓
Embedding
↓
[0.123,
0.881,
0.532...
1536]
作用:
语义检索
写入Vector DB
例如
{
id:1001,
text:"用户熟悉Java",
vector:....,
metadata:{
type:"skill",
time:"2026"
}
}
Memory检索
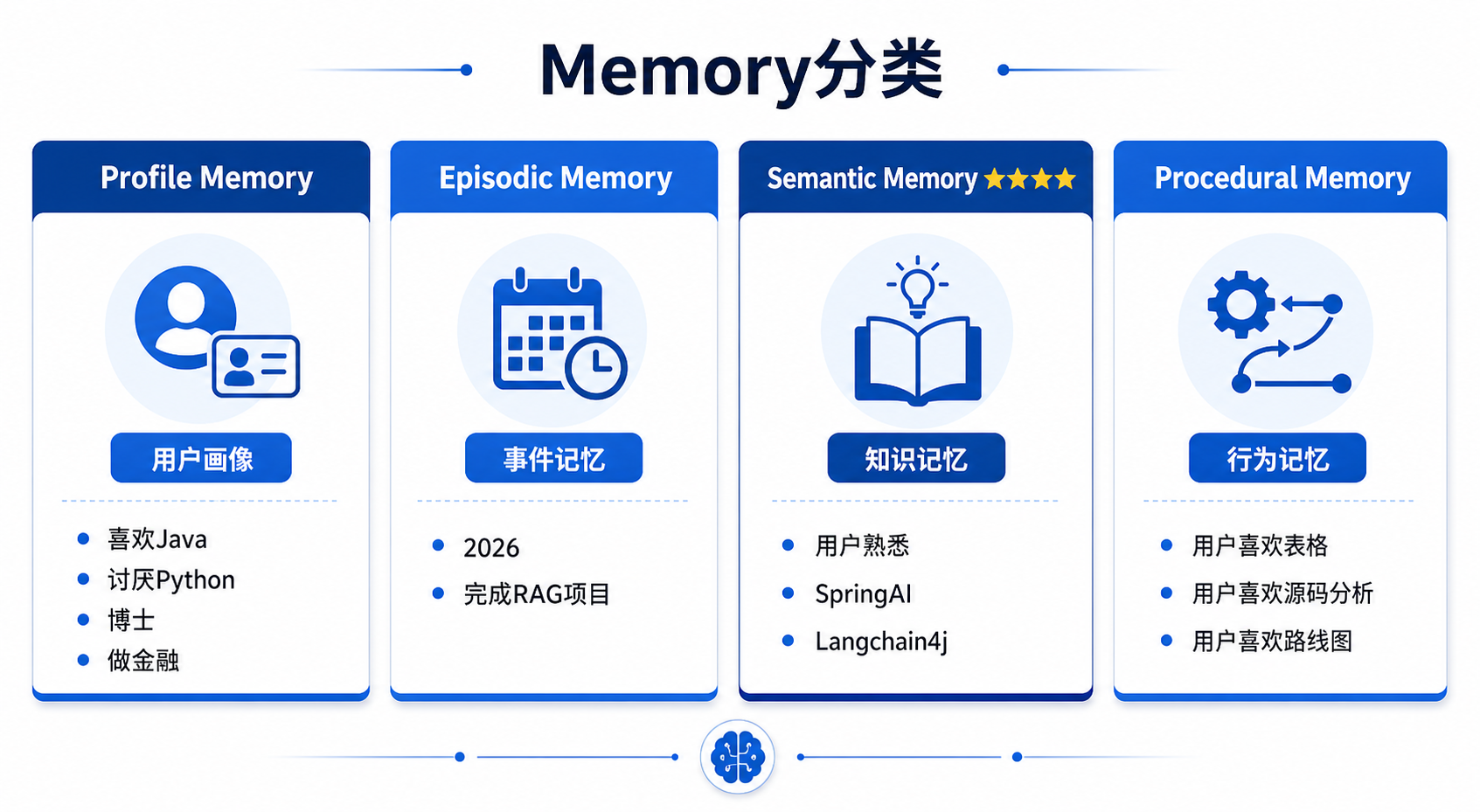
RAG那一套,的优化可以拿过来
Memory分类
RAG + Memory
聊天
│
▼
Memory Extractor
│
Embedding
│
Milvus
│
TopK
▼
Prompt Builder
▼
LLM
Memory Agent进阶
RAG进阶+聊天记录总结
| 模块 | 技术 | 作用(通俗解释) | 重要度 |
|---|---|---|---|
| Embedding | 文本向量化模型 | 把"文字"变成"语义坐标(向量)",让机器能理解相似性(比如Java≈Spring) | ⭐⭐⭐⭐⭐ |
| Vector DB | Milvus | 专门存"向量记忆库",支持语义搜索(不是关键词,而是意思匹配) | ⭐⭐⭐⭐⭐ |
| Vector DB | pgvector | PostgreSQL的向量扩展,把"数据库+向量检索"合一,适合中小系统 | ⭐⭐⭐⭐ |
| Vector DB | FAISS | Facebook开源的向量检索库,本地高性能相似度搜索引擎 | ⭐⭐⭐⭐ |
| RAG | 检索增强生成 | 先"查资料",再"让LLM回答",避免模型胡编 | ⭐⭐⭐⭐⭐ |
| Memory Extractor | LLM结构化抽取 | 从聊天中提取"有用记忆"(兴趣、技能、项目等),过滤噪声 | ⭐⭐⭐⭐⭐ |
| Reranker | 重排序 | 对检索结果再打分排序,让最相关的记忆排前面 | ⭐⭐⭐ |
| Memory Graph | 图数据库 | 用"节点+关系"存记忆(如用户→掌握→Java),表达结构化知识 | ⭐⭐⭐⭐ |
| Forgetting | 遗忘机制 | 自动删除/降权旧信息,避免记忆越积越乱 | ⭐⭐⭐⭐ |
| Reflection | 自我反思机制 | Agent定期总结和修正自己的记忆(更新偏好、纠错) | ⭐⭐⭐⭐⭐ |
主流开源
Mem0(非常重要 ⭐⭐⭐⭐⭐)
定位:
轻量级"LLM长期记忆层"
核心能力:
- 自动提取用户偏好
- 存入向量数据库
- 自动检索相关记忆注入Prompt
- 支持个性化对话
特点:
- API极简
- 可直接接 OpenAI / Claude / 本地模型
- 适合快速做"有记忆的ChatGPT"
适合你:
Java做Agent + Python服务层很常见组合
Zep(生产级 Memory Server ⭐⭐⭐⭐⭐)定位:
专门为 LLM 设计的"长期记忆数据库服务"
核心结构:
- Chat History Store(原始对话)
- Vector Memory(语义记忆)
- Summary Memory(摘要记忆)
能力:
- 自动总结对话
- 自动embedding
- session memory + long memory融合
- REST API直接调用
特点:
- 很像"Memory中间件"
- 可以替代你自己写 Milvus + Extractor
Letta(原 MemGPT)定位:
"有记忆的自主Agent框架"
核心思想:
把 Memory 当成"操作系统"
结构:
- Working Memory(短期)
- Archival Memory(长期)
- Memory Manager(自动搬运)
特点:
- Agent会"自己决定记不记"
- 有遗忘机制
- 有反思机制(Reflection)
这是目前最接近你第四阶段模型的实现
LangChain Memory(基础版 ⭐⭐⭐)定位:
LangChain自带的Memory体系
类型:
- ConversationBufferMemory
- ConversationSummaryMemory
- VectorStoreMemory
特点:
- 教学级 / Demo级
- 不够智能(没有自动记忆筛选)
LlamaIndex Memory / Knowledge Layer
定位:
RAG + Memory + Knowledge Graph
能力:
- 文档记忆(RAG)
- 对话记忆
- 知识图谱增强
特点:
- 偏"知识系统"
- 很适合企业知识库 + Agent
LangGraph Memory(进阶 ⭐⭐⭐⭐)定位:
DAG Agent + Memory 状态管理
特点:
- Memory作为Graph State的一部分
- 支持多Agent协作
- 适合 Workflow + Memory 混合系统
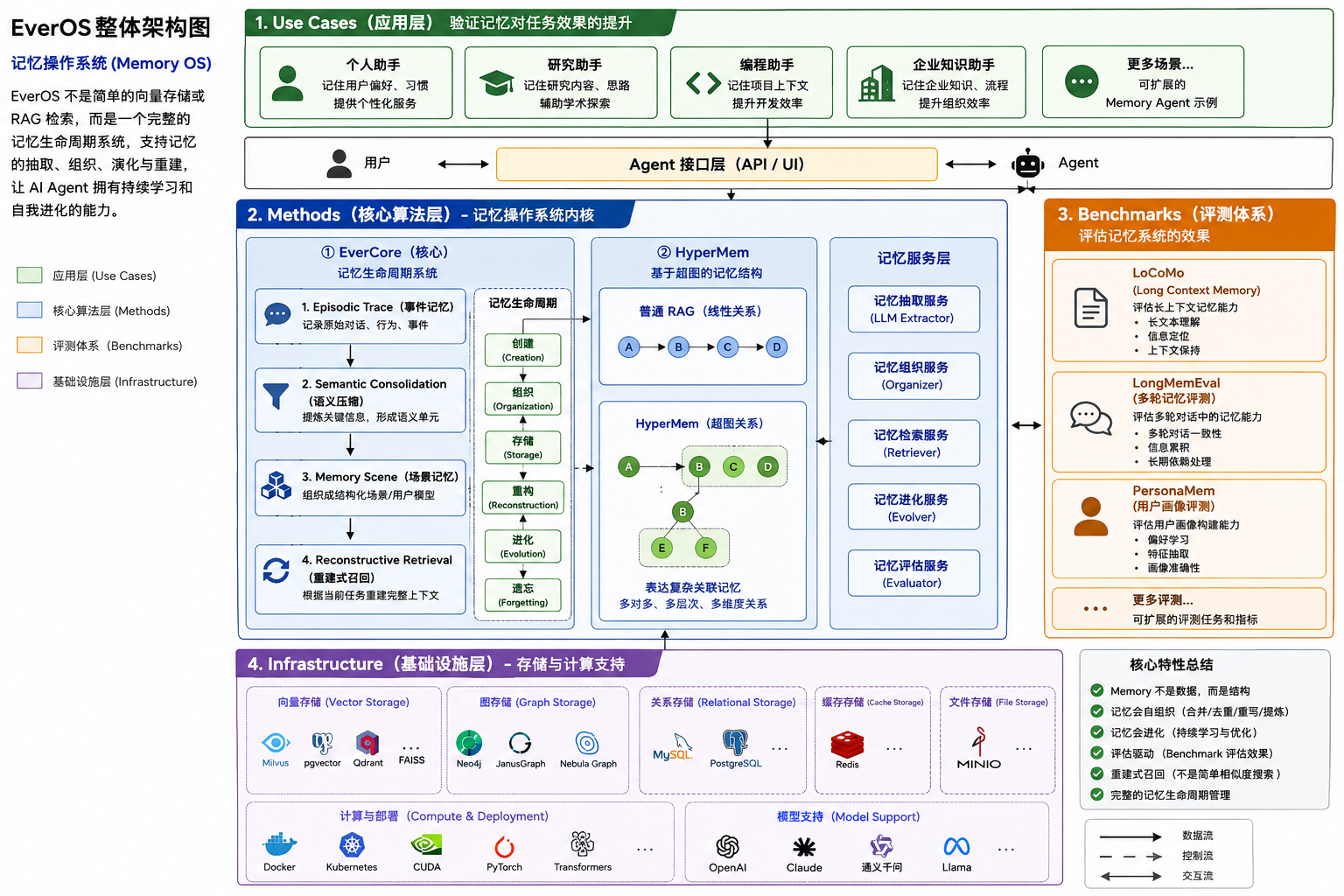
EverOS
EverOS = 用于构建、评估、集成 Long-term Memory 的 Agent Memory 操作系统
- 构建"可持续进化的 Agent"
- 提供统一 Memory 架构
- 提供评测体系(benchmark)
- 支持 self-evolving memory
Memory Lifecycle System(记忆生命周期系统)