一、TF-IDF在项目中主要用来干嘛?
TF-IDF 在项目中有 两个主要用途,都在 domain/baseline 模块内:
用途一:文本分类模型(TF-IDF + 逻辑回归)
文件:base04_train_sklearn.py
这是 baseline 模块的主力分类模型之一(与 FastText 二选一,默认使用 TF-IDF+LR)。
流程是:
用 TfidfVectorizer + JiebaTokenizer 将文本转为 TF-IDF 特征矩阵
接 LogisticRegression 分类器,组成 sklearn Pipeline
用于训练、评估、单条预测
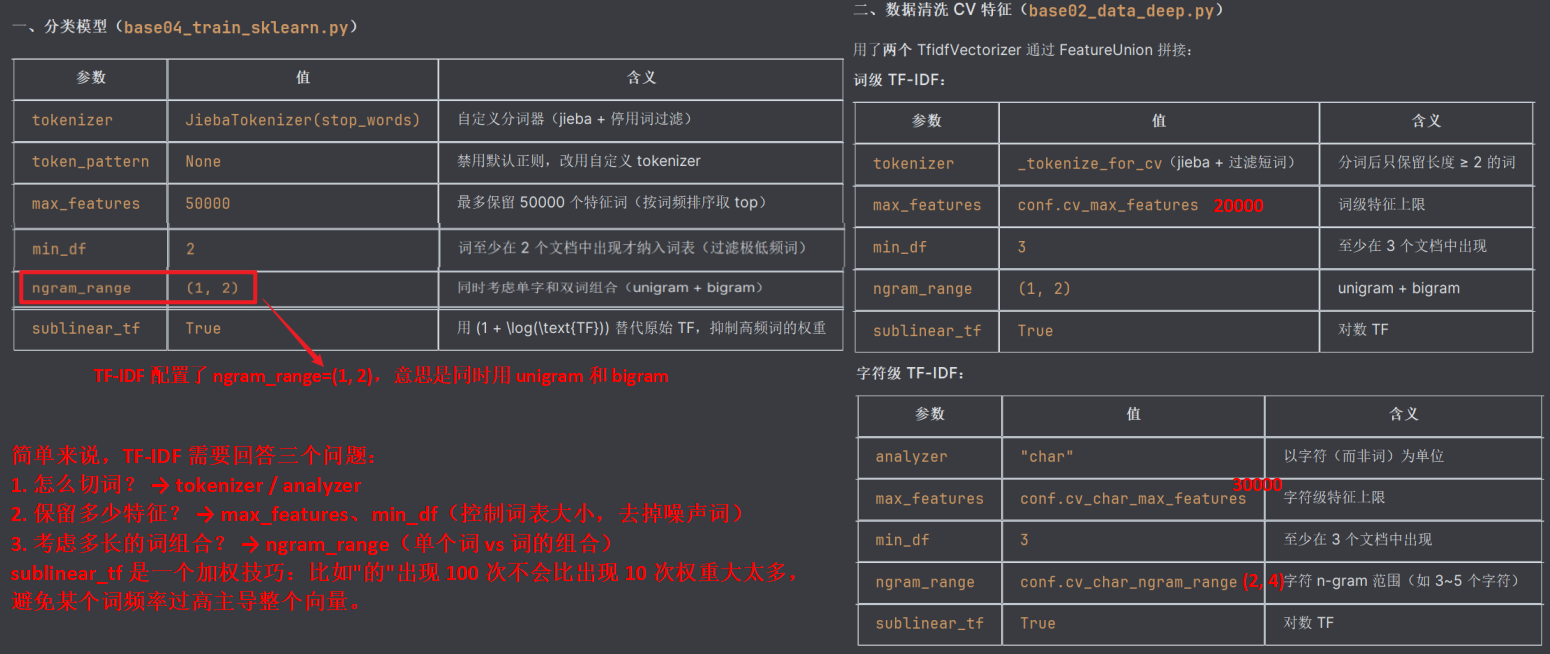
Pipeline([
("tfidf", TfidfVectorizer(tokenizer=JiebaTokenizer, max_features=50000, ngram_range=(1,2))),
("clf", LogisticRegression),
])从 summary.json 的结果看,TF-IDF+LR 的效果明显优于 FastText(dev F1 约 0.84 vs 0.68),所以它是 baseline 的默认模型。
用途二:数据清洗中的错标检测(CV 交叉验证)
文件:base02_data_deep.py
在深度清洗阶段,TF-IDF 被用来构建特征,辅助检测并剔除标注错误的样本:
- 词级 TF-IDF:TfidfVectorizer(tokenizer=_tokenize_for_cv, ngram_range=(1,2))
- 字符级 TF-IDF:TfidfVectorizer(analyzer="char", ngram_range=(3,5))
两者通过 FeatureUnion 联合,作为交叉验证分类器的输入
原理:用 5 折交叉验证训练分类器,如果模型对某条样本的真实标签置信度很低、且更倾向于另一个类别,就判定为错标并剔除。
用途三:冒烟测试(验证数据可学习性)
文件:temp_data_extract/01-data/validate_samples.py
用字符级 TF-IDF + LinearSVC 做快速冒烟测试,验证「标签与文本之间是否存在可学习的模式」,属于数据验证环节。
!\[Pasted image 20260624125703.png]
二、TF-IDF 主要是用来将文本转为数值的,与此不相关
用途一:分类模型 --- 直接相关
这个很好理解:
文本 → TF-IDF 转数值 → 逻辑回归分类 → 预测类别
TF-IDF 在这里就是标准的特征提取步骤,没问题。
用途二:错标检测 --- 其实也是间接依赖这个能力
你可能觉得数据清洗和"文本转数值"不相关,但逻辑是这样的:
文本 → TF-IDF 转数值 → 训练一个交叉验证分类器 → 用分类器的置信度来判断标签是否标错了
也就是说,要检测"这条数据的标签是不是标错了",需要一个分类模型来打分。而这个分类模型的特征输入,就是 TF-IDF 转出来的数值向量。
本质上还是:先把文本变成数值 → 然后让模型去判断 → 只不过这里模型的输出不是"最终预测结果",而是"这条数据是否可信"。
所以
TF-IDF 在项目中始终只做一件事:文本 → 数值向量。只是下游接的任务不同:
- 接 LR → 做分类
- 接 CV 分类器 → 做数据质量检查
你的直觉是对的,TF-IDF 本身不负责"清洗",它只是为清洗过程中的分类判断提供了数值化的特征基础。
三、总结
TF-IDF 在项目中是做特征提取的吗?:
TF-IDF 在项目里就是做特征提取的 ------把文本转成数值向量,让后续的机器学习模型能处理;
具体来说,项目中 TF-IDF 出现在两个地方,本质都是特征提取:
- TF-IDF + LR 分类模型 (base04_train_sklearn.py)
- TF-IDF 提取特征 → 逻辑回归做分类
- 这是标准的机器学习流程:特征提取 → 分类器
- 数据清洗中的错标检测 (base02_data_deep.py)
- TF-IDF 提取特征 → 交叉验证分类器打分 → 判断标签是否标错
- 同样需要先有数值特征,分类器才能工作
而 BERT 和 LLM 不需要 TF-IDF,是因为它们自己内部就能完成特征提取 ,而且提取出来的特征比 TF-IDF 更强大(上下文相关的稠密向量 vs 统计稀疏向量)。
一句话总结:TF-IDF 是传统机器学习管线中的特征提取步骤,BERT/LLM 把这个步骤内化到模型里了。
四、需要参数
核心参数解释
简单来说,TF-IDF 需要回答三个问题:
- 怎么切词? → tokenizer / analyzer
- 保留多少特征? → max_features、min_df(控制词表大小,去掉噪声词)
- 考虑多长的词组合? → ngram_range(单个词 vs 词的组合)
sublinear_tf 是一个加权技巧:比如"的"出现 100 次不会比出现 10 次权重大太多,避免某个词频率过高主导整个向量。