一、流批一体思想
1、有界流和无界流
在Flink中,批处理是流处理的一个特例。这个正好跟Spark相反。
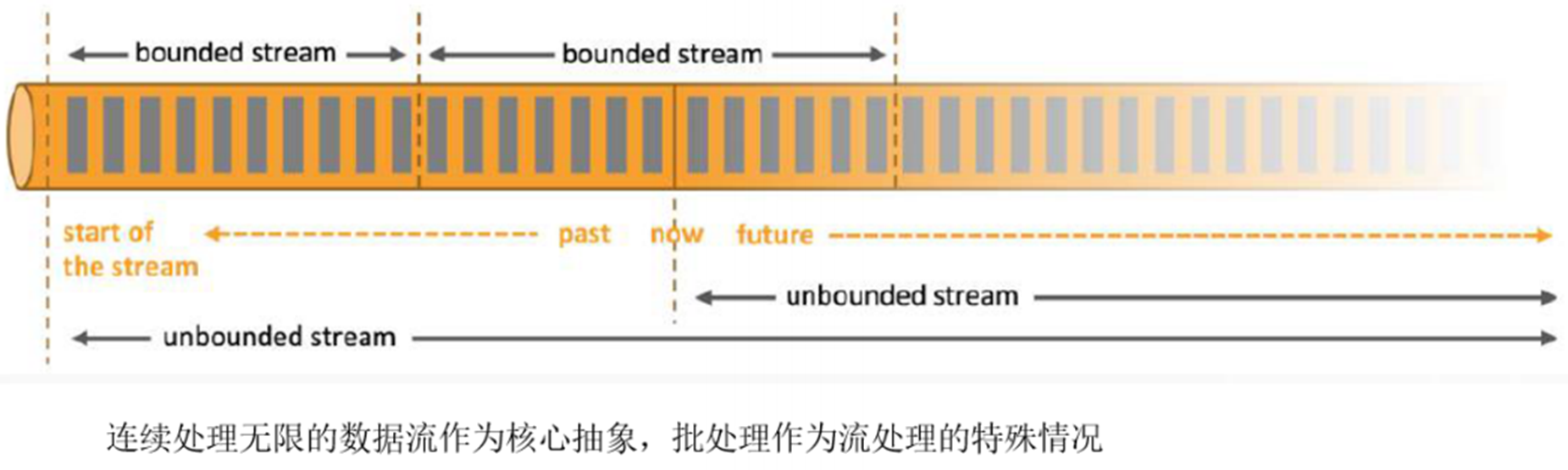
无界流:数据源源不断的进来,针对事件进行处理
有界流:基于时间窗口,对数据流进行处理
2、Flink老架构与问题
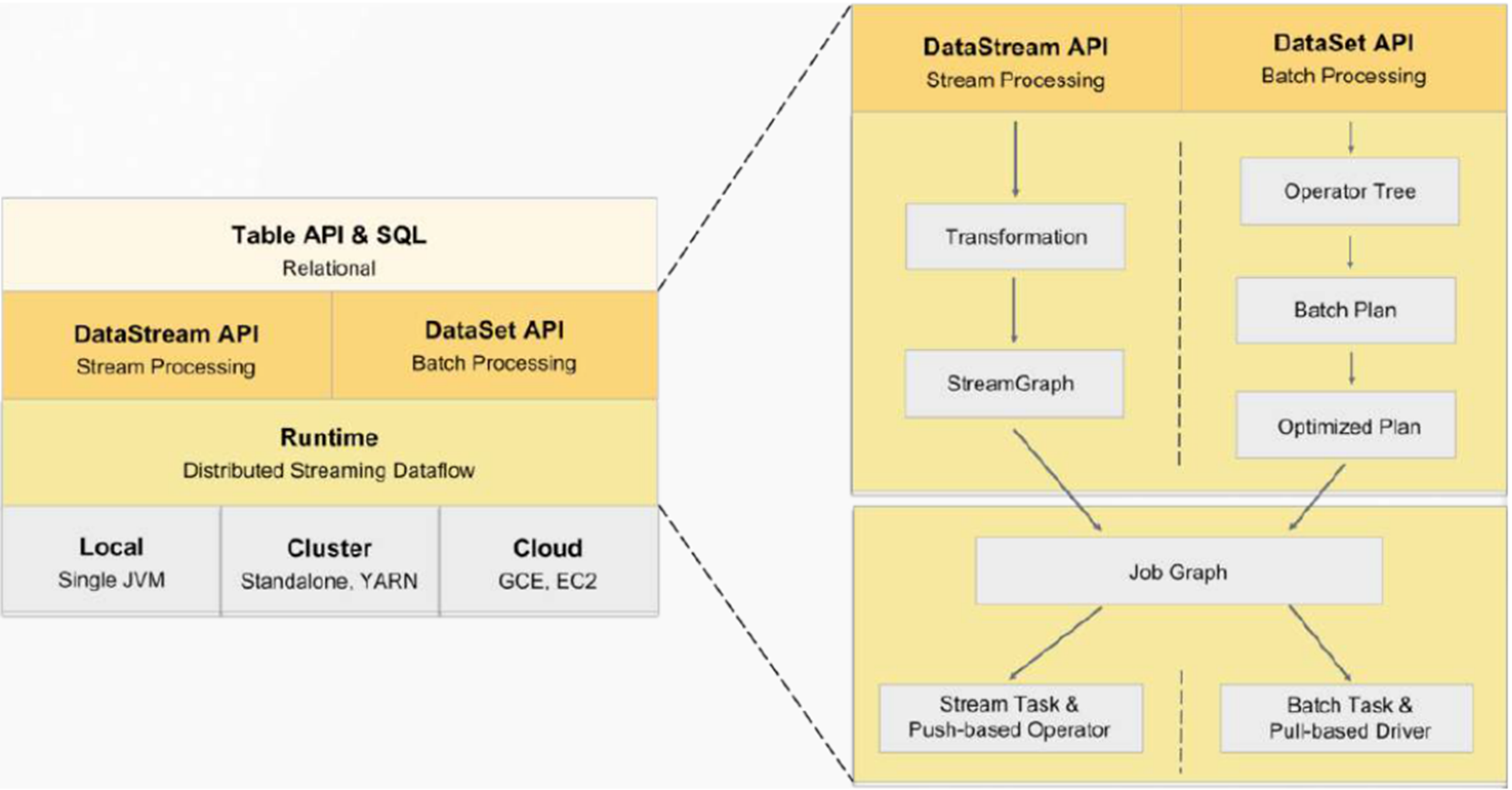
上图是老版本架构。本地模式、集群模式、云模型都可以运行。数据处理API有两种,流处理API和批处理API。上层是Table API和SQL都支持流处理和批处理。流处理和批处理需要两套代码。
(1)Flink老架构与问题
- 从Flink用户角度(企业开发人员)
- 开发的时候,Flink SQL支持的不好,就需要在两个底层API中进行选择,甚至维护两套代码。
- 不同的语义、不同的connector支持、不同的错误恢复策略等。
- Table API也会受不同的底层API、不同的connector等问题的影响。
(2) 从Flink开发者角度(Flink社区人员) - 不同的翻译流程,不同的算子实现、不同的Task执行。
- 代码难以复用。
- 两条独力的技术栈需要更多人力,功能开发变慢、性能提升变难、bug变多。
3、Flink新架构
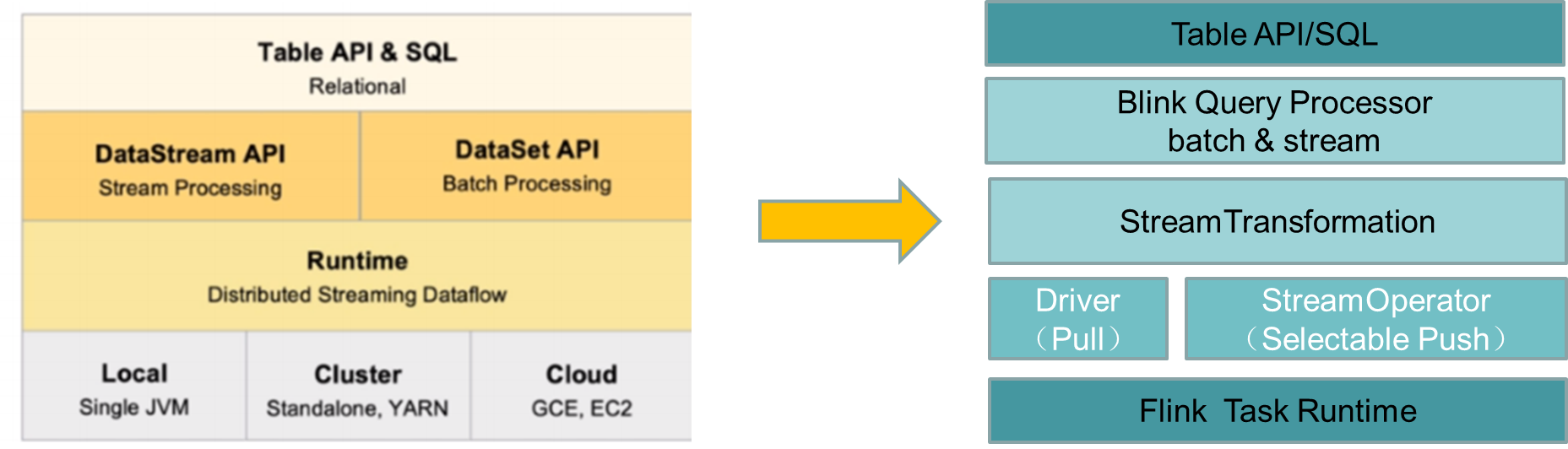
左图是老的架构。右图是新架构。新架构的上层的Table API和SQL对应的底层用统一的查询处理器,流批统一。
3.1、Flink SQL特性
- 流批一体:Flink SQL支持对流数据和批处理数据的统一处理。这意味着用户可以在同一个查询中同时处理流数据和批处理数据,无需为不同的数据处理模式编写不同的代码。
- 水位线处理:对于流数据,Flink SQL支持基于时间或计数的水位线(Watermark)处理,以确保数据的完整性和准确性。
- 时间属性:Flink SQL允许用户为表定义时间属性(如事件时间、处理时间等),以便进行时间窗口操作。
- 高效的连接操作:Flink SQL支持多种连接操作,如内连接、左外连接、右外连接等。同时,Flink SQL还通过优化连接策略来提高查询性能。
- 函数支持:Flink SQL支持自定义函数(UDF)、表值函数(TVF)和聚合函数(UDAF)等,以满足用户的多样化需求。
3.2、应用场景
- 实时数据分析:Flink SQL适用于实时数据分析场景,如实时监控、 日志分析、推荐系统等。通过Flink SQL,用户可以实时查询和分析流数据,从而快速获取业务洞察。
- 数据整合与转换:Flink SQL可用于数据整合与转换场景,如将多个数据源的数据整合到一张表中,或对数据进行清洗、转换等操作。
- 批处理任务:虽然Flink主要面向流处理场景,但Flink SQL同样适用于批处理任务。通过将批处理数据视为有限流,用户可以使用Flink SQL完成传统的批处理任务。
二、Flink Table API与SQL执行过程
1、API分层结构
- Flink1.12之前的版本,TableAPI和SQL处于活跃开发阶段,并没有实现流批统⼀的所有特性,所以使用的时候需要慎重。
- 从Flink1.12开始,Table API和SQL就已经成熟了,可以在生产上放心使用
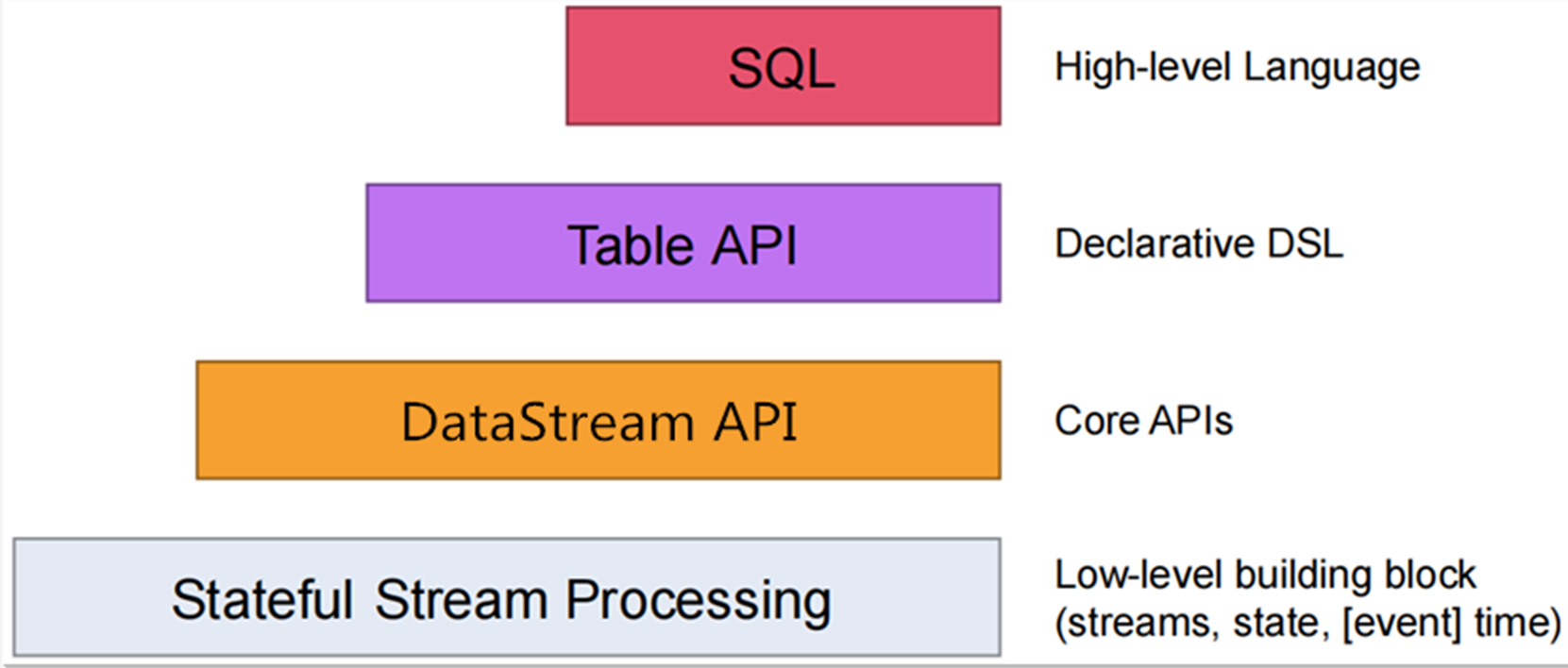
分层4层。最下面是有状态流。Table API是以表为中心的声明式编程,表可能会动态变化。最上层是Flink SQL是一种高阶的语言,它是基于apache calcite实现,支持ANSI SQL标准。它提供了Table API和SQL两种方式来定义和处理数据。Table API是一种类型安全的DSL,而SQL则是一种声明式的查询语言。两者都可以转换为相同的逻辑计划,从而确保了一致性。
2、 Flink Table****API/SQL 的执行过程

2.1. 解析(Parser)
- SQL 场景:借助 Apache Calcite 的 SQL 解析器(SqlParser),将字符串形式的 SQL 转换成 AST(抽象语法树)。
- Table API 场景:通过 Java/Scala 表达式 DSL 直接构建树形结构,跳过文本解析环节。
- 产物:未解析的逻辑计划(Unresolved Logical Plan),此时只记录了表名、字段名、函数名等标识符,缺少实际类型、Catalog 信息。
2.2. 未解析的逻辑计划(Unresolved Logical Plan)
- 这是一棵由 Calcite 的 RelNode 组成的树,节点包含 LogicalTableScan、LogicalProject、LogicalFilter 等。
- 表名和列名仅以字符串形式存在,尚未与 Catalog 中的元数据关联,无法进行任何类型相关的操作。
2.3. 验证与解析(Validation & Resolution)
- 核心动作:通过 Catalog(内存 Catalog、Hive Metastore 等)将未解析标识符绑定到实际的表、视图、字段和函数上。
- 具体工作 :
- 查找表/视图定义,注入 Schema(列名、类型、约束)。
- 解析函数签名并进行类型推导。
- 对 SQL 语义进行校验(如字段是否存在、类型是否匹配)。
- 产物:已解析的逻辑计划(Resolved Logical Plan),其中每个算子都带有完整的类型信息和指向 Catalog 对象的引用。
4. 已解析的逻辑计划(Resolved Logical Plan)
- 仍然是 RelNode 树,但节点中的 Table 已被替换为 CatalogTable 或具体的 Table 实现,表达式带有明确的返回类型。
- 为后续优化提供了完备的语义基础。
5. 逻辑优化(Logical Optimization)
- Flink 使用 Calcite 提供的优化框架(HepPlanner 和 VolcanoPlanner),应用大量关系代数等价规则,包括但不限于:
- 谓词下推(Predicate Pushdown):将过滤条件提前到数据源侧。
- 列裁剪(Projection Pruning):只读取实际使用的字段。
- 常量折叠(Constant Folding):静态表达式提前求值。
- 子查询去相关化(Subquery Decorrelation):将子查询转为 Join 等操作。
- Join 重排序:基于代价估算重新排列 Join 顺序。
- 分区裁剪:结合 Catalog 信息,在读取时跳过无关分区。
- Flink 还注入了一些针对流处理的特殊规则,例如窗口聚合优化、时间属性推导、状态 TTL 配置等。
- 产物:优化后的逻辑计划(Optimized Logical Plan),结构更精简高效,仍保持逻辑层独立。
6. 优化后的逻辑计划(Optimized Logical Plan)
- 逻辑上等价于原查询,但算子的编排方式已经经过显著的规则重写,性能大幅提升。
- 例如,一张大表与一张小表 Join 可能被优化为 Broadcast Hash Join 的逻辑表示(仍在逻辑层)。
7. 物理计划生成(Physical Planning)
- 目标:将逻辑算子映射到 Flink 具体的执行原语上。
- 过程 :
- Calcite 根据代价模型,为每个逻辑算子选择一个物理实现(例如 LogicalTableScan → DataStreamScan、LogicalJoin → HashJoin/SortMergeJoin 等)。
- 转换成 Flink 内部的 Transformation 图(类似 DataStream API 的算子图),如 SourceTransformation、OneInputTransformation、TwoInputTransformation。
- 区分流/批模式,确定使用 DataStream 还是 DataSet(已逐步被统一到流引擎),并处理时间属性(Event Time / Processing Time)和窗口算子等。
- 产物:物理执行计划(Physical Plan),在代码层面表现为 Transformation 的 DAG。
8. 物理执行计划(Physical Plan / Transformation 图)
- 这是一张完全可执行的 DAG,节点包含具体的并行度、资源需求等信息,但尚未编译为字节码。
- 例如:Source( Kafka ) -> Filter -> KeyBy -> Window -> Process。
9. 代码生成(Code Generation)
- Flink(尤其是 Blink Planner)会动态生成部分算子的执行代码,以替代解释性执行。
- 生成范围:表达式求值、函数调用、部分聚合逻辑、排序比较器等。
- 利用 Janino 或 ASM 动态编译生成高效的 Java 类,直接操作二进制数据(如将行数据序列化成 RowData 处理),大幅降低 CPU 开销。
- 代码生成的结果(编译后的 Operator 类)会注入到对应的 Transformation 节点中,形成最终的执行算子。
10. 构建执行图(JobGraph / ExecutionGraph)
- Transformation 图 → JobGraph :
- 将多个 Transformation 算子按条件串联成算子链(Operator Chain),减少线程切换和序列化开销。
- 确定每个任务的输入输出格式、序列化器,分配 Slot 共享组等资源信息。
- 生成可提交给 JobManager 的 JobGraph(二进制大对象)。
- JobGraph → ExecutionGraph (运行时):
- JobManager 根据 JobGraph 进一步细化成可调度的 ExecutionGraph,包含具体任务的并行实例、状态分布和容错配置。
- 这一步对 Table API/SQL 用户完全透明,由框架自动完成。
11. 执行并返回结果
- JobManager 将任务分发到 TaskManager,各 TaskManager 启动 Operator 实例开始处理数据。
- 流式查询:持续不断地输出更新,结果可以通过 toChangelogStream、executeInsert 写入外部系统。
- 批式查询(Flink SQL):采用有界流模式执行,结束后将结果通过 collect() 返回客户端,或直接写入文件/表。
- 执行过程中依赖 Checkpoint 机制保证 Exactly-Once 语义(如果启用)。
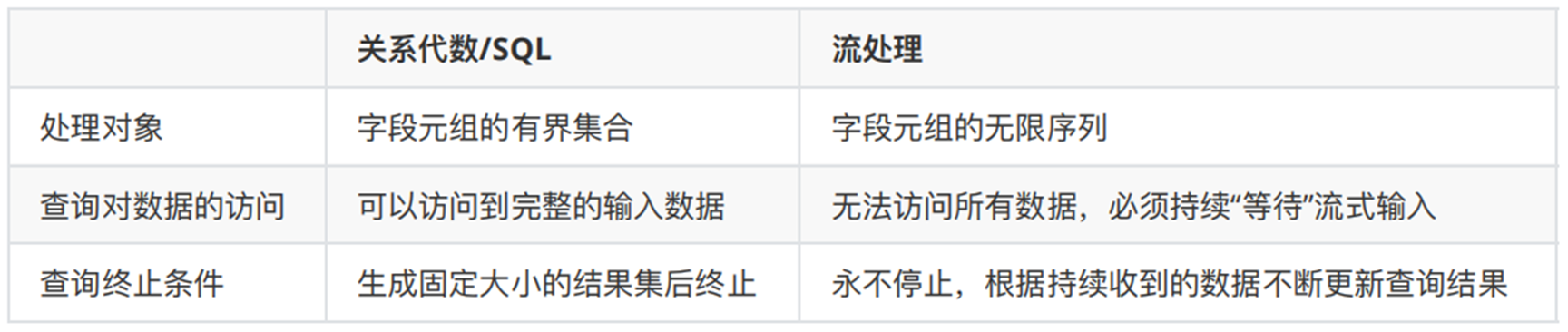
三、关系代数与流处理
- Flink上层提供的Table API和SQL是流批统一的,即无论是流处理(无界流)还是批处理(有界流),Table API和SQL都具有相同的语意。
- 我们都知道SQL是为关系模型和批处理而设计,所以SQL查询在流处理上比较难以实现和理解,我们首先从流处理的几个特殊概念入手来帮助大家理解Flink是如何在流处理上执行SQL的。
- 关系代数(主要就是指关系型数据库中的表)和 SQL,主要就是针对批处理的,这和流处理有天生的隔阂。
四、理解动态表与连续查询
在 Flink SQL 里,动态表 和连续查询 是把"无界流数据"当作"会变化的表"来处理的核心概念。

在数据流上执行关系查询时,数据流与动态表的转换关系图的主要步骤如下:
- 将数据流转换为动态表。
- 在动态表上进行连续查询,并生成新的动态表。
- 生成的动态表再转换为新的数据流。
1、从"静态表"到"动态表"
你熟悉的数据库表,比如一张 orders 表:
sql
-- 传统数据库的表
SELECT * FROM orders;执行时你会得到那一刻 的所有行。之后有新订单插入,你得再查询一次 才能看到变化。这张表是静态的。
但在流处理场景,数据是源源不断到来的。我们把这个无界的订单流也抽象成一张表 ------ 动态表(Dynamic Table):
动态表是一张随时间持续变化的表,每来一条新数据,表的内容就更新一次。
你可以把它想象成一个"无限长的 Excel 表格",有新行插入,也可能有旧行被修改或删除。
比如,一个订单流:
sql
用户A, 金额10 (10:00:00)
用户B, 金额20 (10:00:05)
用户A, 金额15 (10:00:10)转换成动态表 orders,它会经历三个时刻:
sql
时刻1 (10:00:00):
+---------+--------+
| user | amount |
+---------+--------+
| A | 10 |
+---------+--------+
时刻2 (10:00:05):
+---------+--------+
| user | amount |
+---------+--------+
| A | 10 |
| B | 20 |
+---------+--------+
时刻3 (10:00:10):
+---------+--------+
| user | amount |
+---------+--------+
| A | 10 |
| A | 15 |
| B | 20 |
+---------+--------+关键认知:流和动态表是一一对应的。
- 把流看成表,流上不断到来的数据就是表的 INSERT(也可能是 UPDATE/DELETE)。
- 把表看成流,表的变化记录(Change Log)就形成了一个流。
2、什么是"连续查询"?
在静态表上,SQL 查询只执行一次:
sql
SELECT user, SUM(amount)
FROM orders
GROUP BY user;你会得到那个时刻的聚合结果,之后订单再变,查询结果不变。
在动态表上,我们不会"只查一次",而是启动一个永不停止的查询 ------连续查询(Continuous Query)。
连续查询就像一个"一直运行着的物化视图",当动态表发生任何变化(插入、更新、删除),查询逻辑都会被重新触发,计算结果也随之更新,并输出变化的结果。
还是上面的例子,对动态表 orders 启动连续查询:
sql
SELECT user, SUM(amount) as total
FROM orders
GROUP BY user;这个查询会随着 orders 表的变化,产生对应的结果动态表 user_summary:
sql
时刻1 (收到第一行后):
+------+-------+
| user | total |
+------+-------+
| A | 10 |
+------+-------+
时刻2 (收到第二行后):
+------+-------+
| user | total |
+------+-------+
| A | 10 |
| B | 20 |
+------+-------+
时刻3 (收到第三行后):
+------+-------+
| user | total |
+------+-------+
| A | 25 | ← A 的总和从 10 更新为 25
| B | 20 |
+------+-------+可以看到,连续查询就像一个自动重算的公式:只要 orders 表有变化,user_summary 表就自动更新,并且会输出变化(这里是 A 的记录先插入 10,再更新为 25)。
3、用 Flink SQL 实现:完整示例
假设订单数据来自 Kafka,我们想实时计算每个用户的总金额,并将结果写入 MySQL。
3.1. 定义输入动态表(连接 Kafka)
sql
CREATE TABLE orders (
user_id STRING,
amount DECIMAL(10,2),
order_time TIMESTAMP(3),
-- 定义事件时间,便于做窗口
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order-topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);说明:orders 就是一个持续接收 Kafka 消息的动态表,每来一条消息,相当于表中新增一行。
3.2. 定义输出动态表(连接 MySQL)
sql
CREATE TABLE user_total (
user_id STRING PRIMARY KEY,
total DECIMAL(10,2)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydb',
'table-name' = 'user_total',
'username' = 'root',
'password' = '123456'
);user_total 是最终存储结果的动态表,Flink 会把计算结果的更新同步进去。
3.3. 定义连续查询并写入结果表
sql
INSERT INTO user_total
SELECT user_id, SUM(amount) as total
FROM orders
GROUP BY user_id;提交这个 INSERT INTO ... SELECT 后,Flink 就会启动一个长期运行的流作业,逻辑就是:
- orders 表每来一行(新订单),就触发 SUM 计算。
- 当某个 user_id 的总和发生变化,user_total 表就更新该行(通过 MySQL 的 UPSERT 语法)。
4、如何理解"动态表的更新模式"?
上述聚合查询,结果表中的 A 的记录从 10 变成了 25,这对下游意味着什么?这涉及动态表的两种输出模式:
- **追加模式(Append-only)**结果动态表只增加行,不修改旧行。比如普通的时间窗口聚合,窗口关闭后才输出,每一行都是"最终结果",不会更新。例:每小时订单数。
- **撤回/更新模式(Retract/Upsert)**结果行可能会被更新或删除。前面例子就是更新模式,A 先输出一个 +A,10,后来输出 -A,10(撤回旧值)和 +A,25(新值)。如果下游是支持 upsert 的存储(如 MySQL、Elasticsearch),会自动翻译为 upsert 操作;如果打印到控制台,你会看到 -U 标记。
5、总结要点
|-----------------|----------------------------------------------|
| 概念 | 解释 |
| 动态表 | 一个基于流数据的、随时间变化的逻辑表,是流处理的"表视角"。 |
| 连续查询 | 在动态表上持续运行的 SQL,源表变化驱动结果表变化,永不终止。 |
| 关系 | 输入流 → 输入动态表 → 连续查询 → 输出动态表 → 输出流/外部系统。 |
| 与传统 SQL 的区别 | 传统 SQL 是"快照查询",结果固定;连续查询是"持续物化视图",结果随数据实时更新。 |
通过这种抽象,你可以用熟悉的 SQL 语法,描述一个 7×24 小时持续运行的流计算任务,而不必写底层代码。这正是 Flink SQL 强大的地方------把无限流动的数据,看作一张动态变化的表,查询也跟着"活"了起来。
五、动态表详解之动态表定义
理解了基本概念后,我们再来深入剖析动态表在 Flink SQL 中是如何定义的 。动态表不会存储数据,它只是一个声明式的连接器 ,告诉 Flink:"外部有这样一个数据源/目标,请按照这个结构来理解数据流"。
1、动态表定义的语法骨架
一个完整的动态表定义用 CREATE TABLE 语句完成,大致结构如下:
sql
CREATE TABLE 表名 (
列名 数据类型 [列的约束],
...,
-- 时间属性
某个列 AS PROCTIME(), -- 处理时间
-- 或
事件时间列 AS TO_TIMESTAMP(原始列),
WATERMARK FOR 事件时间列 AS 事件时间列 - 延迟时间,
-- 主键
PRIMARY KEY (列名) NOT ENFORCED
) WITH (
'connector' = '连接器名称',
'连接器参数1' = '值',
'format' = '数据格式'
...
);注意:Flink SQL 中的 PRIMARY KEY 必须加上 NOT ENFORCED,因为 Flink 不会校验键的唯一性,它只是用于优化和决定 changelog 模式。
2、逐部分拆解详解
2.1. 列定义
- 物理列:直接对应消息中的字段。如 user_id STRING, amount DECIMAL(10,2)。
- 元数据列:暴露消息本身的元信息(如 Kafka 的分区、偏移量、时间戳)。用 列名 类型 METADATA FROM '元数据键' 声明。例如,要读取 Kafka 消息的 offset:event_offset BIGINT METADATA FROM 'offset'。
- 计算列:用 AS 基于其他列计算出来的虚拟列,可简化后续 SQL。比如把一个字符串字段转为时间戳:ts AS TO_TIMESTAMP(time_str, 'yyyy-MM-dd HH:mm:ss'),后续可以直接用 ts 做事件时间。
2.2. 时间属性
这是流处理的核心,定义了记录在时间维度上的位置。
- 处理时间:记录被 Flink 算子处理时的机器系统时间,用 proc AS PROCTIME() 声明。它无需在消息中携带,常用在不需要严格事件语义的聚合中。
- 事件时间 :记录真实发生的时间,由消息中的某个字段提取,并需要水位线来应对乱序。声明步骤:
- 先得到事件时间列:event_time AS TO_TIMESTAMP(时间戳字段) 或直接使用 TIMESTAMP(3) 类型的列。
- 在该列上定义水位线:WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND,意思是允许事件迟到最多 5 秒。
2.3. 主键与分区键
- PRIMARY KEY (列名) NOT ENFORCED:告诉 Flink 这张动态表可以按该键进行更新或删除(即 upsert 模式)。聚合查询(如 GROUP BY)或带 PRIMARY KEY 的结果表,会自动产生撤回/更新流,写入支持 upsert 的外部系统(如 MySQL、HBase)。
- PARTITIONED BY (列名):在定义文件系统结果表(如 filesystem)或 Kafka 结果表时使用,指定消息在外部系统的分区字段。
2.4. WITH 子句
这里配置连接器的具体细节,最常见的是 connector(连接器类型)和 format(消息格式)。
- 常用连接器:kafka, upsert-kafka, jdbc, filesystem, print 等。
- 格式:json, csv, avro, debezium-json(CDC 数据)等。
- 其他参数随连接器不同而不同,比如 Kafka 的 topic, properties.bootstrap.servers。
3、 Watermark(水位线)
3.1、为什么处理流数据必须关注"时间"?
你想做实时统计,比如 "每分钟的点击量" ,这就必然要用到时间。流数据不像批数据那样"静止等你处理",它是持续涌入的。当你想做**"过去 5 分钟的订单总额"。** 这类统计时,你必须回答一个问题:这 5 分钟,是谁的 5 分钟?在流处理中,时间有两种标准:
- 处理时间(Processing Time) :数据到达 Flink 算子的那一刻,用机器的系统时钟。优点:简单,无需任何配置。缺点:如果数据有延迟,会导致计数不准。比如 10:01 产生的点击,因为网络延迟 10:05 才到 Flink,按处理时间会被算到 10:05 的窗口里。
- 事件时间(Event Time) :数据实际发生 的时间,通常来自数据本身的时间戳字段。优点:结果准确,不受计算引擎吞吐、网络延迟影响。缺点:数据可能是乱序的,也可能严重迟到------Flink 怎么知道该等多久才能触发窗口计算?这就引出了 Watermark。
3.2、事件时间的核心难题:如何判断"数据到齐了"?
使用事件时间后,Flink 面临一个无解的理论困境:
(1)问题:
消息可以乱序到达 (早发生的事件反而晚到),也可以延迟很久 才来。Flink 永远不知道"还有没有更早时间的消息在路上"。
(2)业务需求:
窗口必须在某个时刻触发计算 ,不可能永远等下去。低延迟和高完整性是矛盾的。
(3)示例:
想象一个公交车场景:
你规定"每 5 分钟一趟车",并把这段时间内到的乘客看作一组。但在现实中,有些乘客可能晚到(数据延迟),甚至 5 分钟的车都开走了,他才跑过来喊"等等我"(乱序)。
作为调度员,你什么时候才能决定"这班车已经开走,不再等了呢"?
( 4)Watermark 的语义
在流计算里,如果严格等待所有数据,那窗口永远无法关闭;如果不等,窗口计算就漏掉了迟到数据。
因此需要一个权衡机制 ------Watermark(T) 就是告诉你: **"我保证,事件时间 ≤ T 的数据已经(基本)全部到达了。"**后续如果再来事件时间 ≤ T 的消息,就视为迟到数据(Late Event),按策略处理或丢弃。
Watermark 是一条特殊的数据记录,它带着一个时间戳,在流中流动。算子看到它,就知道"不需要再等待比这个时间更早的事件了"。
3.3、Watermark 如何工作(配图思维)
(1)基于WaterMark的Windows触发条件
窗口的开始时间和结束时间是基于自然时间创建的,比如指定一个5s的窗口,那么1分钟内就会创建12个窗口。
- watermark时间>=window_end_time
- 在[window_start_time, window_end_time)区间中有数据存在,注意是左闭右开区间
同时满足以上2个条件, window才会触发。
(2)数据流处理模拟案例 - 案例1
以下模拟一条真实数据流,窗口大小10秒,允许乱序2秒,观察Watermar推进及窗口推进过程 - 00-10s窗口
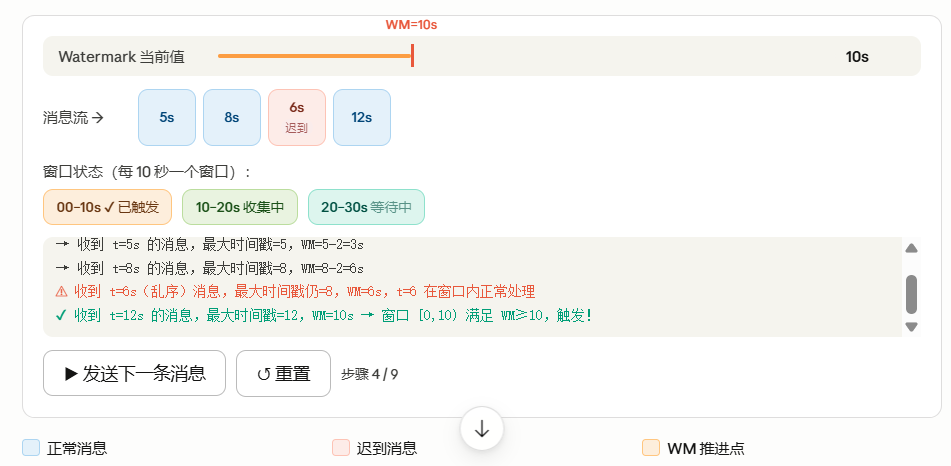
- 10-20s窗口

- 20-30s窗口
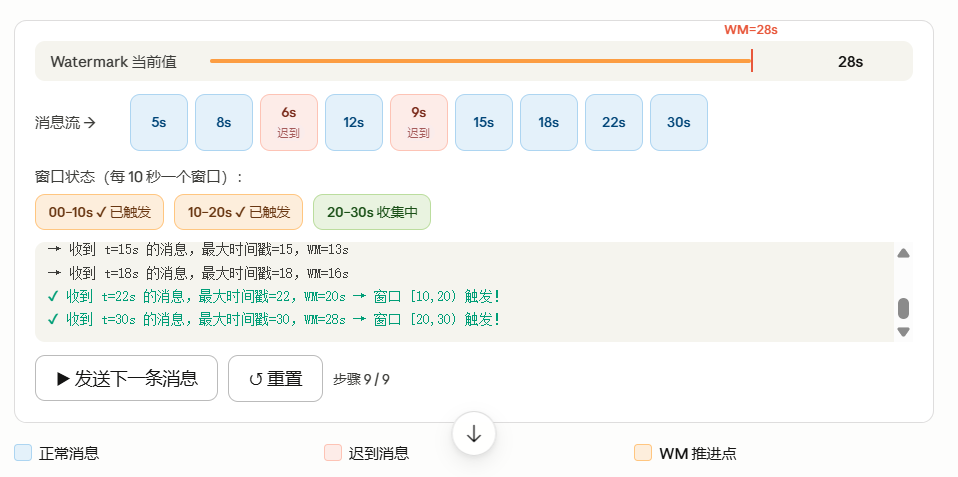
案例2:
假设数据里的事件时间乱序到来,我们设定 允许最大迟到 5 秒:
- 声明 Watermark 生成策略:WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND意味着:每来一条数据,会生成一个 Watermark = (当前数据的事件时间 - 5秒)。
- Flink 算子维护一个当前最大的 Watermark(取各分区 Watermark 的最小值,多并行度时)。比如先后收到事件时间分别为 10:00:03、10:00:01、10:00:07 的数据,Watermark 会推进成:第一条: 10:00:03 - 5s = 09:59:58第二条: 10:00:01 - 5s = 09:59:56 → 保留最大值 09:59:58第三条: 10:00:07 - 5s = 10:00:02 → 最大值更新为 10:00:02
- 窗口算子判断:我维护一个 [10:00:00, 10:01:00) 的窗口,它的结束时间是 10:01:00。当 Watermark 推进到 10:01:00 或更大时,说明事件时间 < 10:01:00 的所有数据都已被认为到齐(因为我们允许 5 秒迟到,Watermark 比最大事件时间慢 5 秒),窗口可以触发计算并输出结果了。
这样,即便有事件时间在 10:00:59 的数据乱序于 10:01:02 到达(事件时间晚于 Watermark?不,事件时间 10:00:59 小于窗口结束 10:01:00,但是它的到来使得 Watermark 可能变成 10:00:59 - 5s = 10:00:54,此时 Watermark 仍小于窗口结束,窗口不会关闭。如果此数据来得很晚,比如系统已收到过 10:01:06 的数据,Watermark 已经到了 10:01:01,那这条 10:00:59 的数据就会被视为迟到,可能被丢弃或交给侧输出),通过允许的 5 秒乱序,大部分合理迟到都能被容纳。
3.4、Flink SQL 中如何定义 Watermark
只需在 CREATE TABLE 时,在事件时间列上添加 WATERMARK 声明。
sql
CREATE TABLE click_log (
user_id STRING,
page STRING,
click_time TIMESTAMP(3), -- 直接是 TIMESTAMP 类型的事件时间
-- 声明水位线,允许最大 5 秒乱序
WATERMARK FOR click_time AS click_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
...
'format' = 'json'
);- click_time 必须是 TIMESTAMP(3) 或可转化为它的类型。
- click_time - INTERVAL '5' SECOND 就是"事件时间减去 5 秒"作为 Watermark,表示系统认为后续不会有事件时间比它再早 5 秒以上的数据。
- 如果原始数据的时间是字符串,可以用计算列先转成 TIMESTAMP:
click_time AS TO_TIMESTAMP(click_time_str, 'yyyy-MM-dd HH:mm:ss'), WATERMARK FOR click_time AS click_time - INTERVAL '5' SECOND
3.5、完整示例:带 Watermark 的窗口聚合
假设 Kafka 中有用户点击流,JSON 格式:
sql
{"user_id":"u1","page":"/home","ts":"2026-05-25 10:00:03"}
{"user_id":"u2","page":"/home","ts":"2026-05-25 10:00:07"}
{"user_id":"u3","page":"/cart","ts":"2026-05-25 10:01:02"}1. 定义动态表并设置 Watermark
sql
CREATE TABLE clicks (
user_id STRING,
page STRING,
ts_str STRING,
-- 计算列转换为 TIMESTAMP
event_time AS TO_TIMESTAMP(ts_str, 'yyyy-MM-dd HH:mm:ss'),
-- 定义水位线,允许5秒乱序
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);2. 滚动窗口查询:每分钟各页面的点击量
sql
SELECT
TUMBLE_START(event_time, INTERVAL '1' MINUTE) AS win_start,
TUMBLE_END(event_time, INTERVAL '1' MINUTE) AS win_end,
page,
COUNT(*) AS cnt
FROM clicks
GROUP BY TUMBLE(event_time, INTERVAL '1' MINUTE), page;3. 实际执行过程推演
假设流中数据按以下顺序到达 Flink(注意乱序):
- 第一条:u1, /home, 10:00:03 → 事件时间 10:00:03,Watermark 09:59:58
- 第二条:u2, /home, 10:00:01 (迟到?不,事件时间 10:00:01,小于已见最大时间,但 Watermark 取最大事件时间-5s,现最大事件时间为10:00:03,所以 Watermark 仍为 09:59:58,该事件时间10:00:01 > Watermark,没有被丢弃,正常进入窗口)
- 第三条:u3, /cart, 10:01:06 → 事件时间 10:01:06,Watermark 更新为 10:01:06 -5s = 10:01:01此时 Watermark 10:01:01 已经大于等于窗口 [10:00:00, 10:01:00) 的结束时间 10:01:00,因此这个窗口会触发计算,输出:
sql
win_start: 2026-05-25 10:00:00, win_end: 2026-05-25 10:01:00, page: /home, cnt: 2注意,虽然 u3 事件本身属于下一个窗口,但它的到来推进了 Watermark,从而触发了前一个窗口的关闭。
- 若后面又来了一个延迟严重的 u4, /home, 10:00:59(事件时间属于前一个窗口),它到来时的 Watermark 已经是 10:01:01 或更高,这条数据的事件时间 10:00:59 < 10:01:00 但 10:00:59 < Watermark(10:01:01),因此会被认为是迟到数据,默认会被丢弃,不在窗口计算中(你也可以配置侧输出收集它们)。
3.6、Watermark 解决问题的本质与权衡
解决的问题 :在数据乱序、延迟的流式世界中,给出一个可预见的窗口触发时机,使得计算结果在"精确性"和"延迟"之间取得平衡。
- 延迟越长(如INTERVAL '30' SECOND):可以容忍更大的乱序,结果更准,但窗口输出延迟变高(因为 Watermark 推进慢)。
- 延迟越短(如INTERVAL '0' SECOND):输出延迟极低,但乱序数据很容易被丢弃,结果可能不准。
这就是 Flink SQL 中 Watermark 的哲学:你不必等待永远,只需等待一个可以接受的期限。
3.7、常见疑问速查
|-------------------------|-------------------------------------------------------------------------------|
| 问题 | 答案 |
| 没有定义 Watermark 能用事件时间吗? | 不行,必须显式声明,否则系统不知道如何推进时间。 |
| 处理时间需要 Watermark 吗? | 不需要。处理时间基于系统时钟,不存在乱序问题。 |
| 迟到数据真的就丢了吗? | 默认丢弃。但你可以用 FLINK-1.17+ 的 table.exec.source.idle-timeout 等处理空闲流,或用侧输出 LATE 语义。 |
| 多个并行度时 Watermark 怎么取? | 算子取所有上游分区 Watermark 的最小值,保证不会因为某个分区太快而丢失另一分区的迟到数据。 |
现在再去看 WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND,你就能理解它背后的精巧设计:它既不是魔法,也不是累赘,而是让你用一条简单的声明,就能搞定乱序流中精确窗口计算的核心武器。
4、完整示例1:Kafka 源表(事件时间、元数据)
假设我们要从 Kafka 读取用户点击日志,每条消息是 JSON:
sql
{"user_id":"u1","page":"home","click_time":"2026-05-25 10:00:00"}定义动态表:
sql
CREATE TABLE click_log (
-- 1. 物理列
user_id STRING,
page STRING,
click_time_str STRING, -- 原始字符串格式的时间
-- 2. 计算列:将字符串转为标准 TIMESTAMP,方便后续用
click_time AS TO_TIMESTAMP(click_time_str, 'yyyy-MM-dd HH:mm:ss'),
-- 3. 元数据列:取得 Kafka 的 topic、分区和偏移量(可选,方便排查)
kafka_topic STRING METADATA FROM 'topic',
kafka_part INT METADATA FROM 'partition',
kafka_offset BIGINT METADATA FROM 'offset',
-- 4. 定义事件时间并加上水位线(允许5秒乱序)
WATERMARK FOR click_time AS click_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'user_clicks',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'flink_consumer',
'scan.startup.mode' = 'latest-offset', -- 从最新数据开始消费
'format' = 'json',
'json.fail-on-missing-field' = 'false', -- 字段缺失时不报错
'json.ignore-parse-errors' = 'true' -- 忽略解析错误的消息
);逐块解释:
- 物理列 user_id、page、click_time_str 直接映射 JSON 字段。
- 计算列 click_time 由 click_time_str 转换而来,之后使用事件时间就写 click_time,方便又清晰。
- 元数据列让我们能在后续查询中看到每条数据来自 Kafka 的哪个位置,不必从消息本身携带。
- WATERMARK FOR click_time 定义了基于 click_time 的水位线,允许 5 秒延迟。这是窗口计算的前提。
- WITH 中指定了 Kafka 连接器,topic,启动位置等。
用这张表查询每5分钟滚动窗口的 PV:
sql
SELECT
TUMBLE_START(click_time, INTERVAL '5' MINUTE) AS win_start,
page,
COUNT(*) AS cnt
FROM click_log
GROUP BY TUMBLE(click_time, INTERVAL '5' MINUTE), page;此时 Flink 就会根据水位线推进来触发窗口计算并输出结果。
5、完整示例2:MySQL 结果表(支持 UPSERT)
把上一课中的用户总金额结果写入 MySQL。MySQL 表 user_total 需要提前建好,字段是 user_id 和 total,但 Flink 可以自动通过 JDBC 连接器创建表(如果权限允许)。
定义动态结果表:
sql
CREATE TABLE user_total_mysql (
user_id STRING,
total DECIMAL(10,2),
-- 声明主键,让 Flink 产生 upsert 流
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink_db',
'table-name' = 'user_total',
'username' = 'root',
'password' = '123456',
-- 写入时使用 upsert 语义:有则更新,无则插入
'sink.buffer-flush.max-rows' = '100', -- 每次写入攒够100条
'sink.buffer-flush.interval' = '2s' -- 或者2秒刷一次
);当执行 INSERT INTO user_total_mysql SELECT user_id, SUM(amount) FROM orders GROUP BY user_id; 时,每个 user 的汇总金额会被持续同步到 MySQL 中,并保持与最新计算结果一致。
6、动态表定义的核心思想总结
|-------------|--------------------------------------------|
| 部分 | 作用 |
| 列定义 | 描述数据的"形状",物理列、计算列、元数据列分别承担不同角色。 |
| 时间属性 | 赋予动态表"时间流动"的语义,是窗口、时间关联等操作的基础。 |
| 主键 | 声明行的唯一标识,让 Flink 知道可以用 update/delete 模式输出。 |
| WITH 配置 | 桥接外部世界,决定数据从哪里来、到哪里去、用什么格式。 |
可以把动态表的 CREATE TABLE 理解成一张"智能的管道说明书",它不存数据,但定义了流动数据的结构、时间特征以及与外部系统的连接方式。一旦定义好,你就可以完全用熟悉的 SQL 语法去写持续运行的流处理逻辑了。
六、动态表详解之连续查询
1、什么是连续查询?
在传统数据库里,查询是一次性的:
sql
SELECT * FROM orders WHERE amount > 100;你得到的是执行那一刻满足条件的行。新数据来了,结果不会变。
在 Flink SQL 中,数据流被抽象成动态表 。对着动态表写 SQL,得到的不是一次性的结果,而是一个永不停止的查询 ------ 连续查询(Continuous Query)。
连续查询就像一条"持续运行的物化视图"定义。动态表每变化一次(插入、更新、删除),查询逻辑就被重新触发,计算结果动态表也跟着变化,并输出变化记录。
这意味着:
- 源表有了新订单 → 连续查询立马算出新结果。
- 老订单被更新或取消 → 查询会把之前的结果撤回并更新。
整个过程由 Flink 自动维护,你只需要写熟悉的 SQL。
2、连续查询的三种输出模式
动态表的变化会以变更日志的形式传递到下游。根据查询逻辑的不同,结果变更的模式分为三类:
1. 追加模式(Append-only)
- 场景:结果表只会增加行,不会修改或删除之前的行。
- 典型的查询 :简单的过滤、投影、以及基于事件时间的窗口聚合(窗口关闭后才输出,每条结果都是最终值,不存在更新)。
- 输出形式:只有 +I(插入)消息。
- 适合的 Sink:Kafka(普通 topic)、文件系统、打印控制台。
例如,每次收到一条订单就原样输出:
sql
INSERT INTO result_kafka SELECT * FROM orders WHERE amount > 100;2. 撤回模式(Retract)
- 场景:结果行可能会更新或删除,下游系统需要先撤回旧结果。
- 输出形式 :
- 插入:+I消息。
- 更新:先发一条 -U(撤回旧值),再发一条 +U(新值)。
- 删除:发一条 -D(撤回)。
- 典型的查询:分组聚合(GROUP BY,不带窗口的持续汇总),某些 Join。
- 适合的 Sink:支持撤回语义的系统(如普通 DB 通过先删后插实现),或直接输出到日志。
例如,实时计算每个用户的总金额,它会不断更新:
sql
+I [A, 10]
-U [A, 10]
+U [A, 25]3. Upsert 模式
- 场景:结果表有主键,更新时只需新值,不需要旧值,因为外部系统可以根据主键直接更新(Upsert = Update or Insert)。
- 输出形式:+I(插入),+U(更新新值)。不需要 -U,因为下游能通过主键找到对应行并覆盖。
- 典型的查询:在 GROUP BY 或带 PRIMARY KEY 的结果表上,Flink 可以自动优化为 Upsert 模式。
- 适合的 Sink:JDBC(MySQL、PostgreSQL)、HBase、Elasticsearch、Upsert-Kafka。
前面的用户总额例子,如果结果表定义了 PRIMARY KEY (user_id) NOT ENFORCED,发送到 MySQL 时 Flink 会用 upsert 模式,只需发 +I 和 +U 即可,MySQL 侧执行 INSERT ... ON DUPLICATE KEY UPDATE。
3、连续查询是如何工作的?
Flink 内部把连续查询映射成一个流式算子拓扑。举个例子,一个简单的分组聚合:
sql
SELECT user_id, SUM(amount) AS total FROM orders GROUP BY user_id;Flink 会维护一个状态,保存每个 user_id 的累计金额。每来一条订单:
- 从状态中取出当前累计值。
- 加上新订单金额,得到新累计值。
- 更新状态,并产生变更消息:
- 如果该用户之前没有记录,输出 +I user_id, new_total。
- 如果已有记录,输出 -U user_id, old_total 和 +U user_id, new_total(Retract 模式)。
- 对于 upsert 模式,则只需输出 +I 或 +U。
状态的存在使得连续查询可以"记住"历史,而 Watermark 则帮助窗口查询决定何时输出。两者结合,就让 SQL 获得了处理无限流的超能力。
4、完整实战示例:实时订单大盘
我们来构建一个端到端例子:从 Kafka 读取订单数据,实现每分钟订单量和每用户累计金额,并将结果分别写入 Kafka(追加)和 MySQL(Upsert)。
4.1. 定义订单输入动态表(含 Watermark)
sql
CREATE TABLE orders (
order_id STRING,
user_id STRING,
amount DECIMAL(10,2),
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);4.2. 定义两个结果表
- 每分钟订单量结果表(追加模式,写入 Kafka):
sql
CREATE TABLE order_cnt_per_min (
window_start TIMESTAMP(3),
window_end TIMESTAMP(3),
cnt BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'order_cnt_output',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);- 用户累计金额结果表(Upsert 模式,写入 MySQL):
sql
CREATE TABLE user_total (
user_id STRING,
total DECIMAL(10,2),
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink_db',
'table-name' = 'user_total',
'username' = 'root',
'password' = '123456'
);4.3. 提交连续查询作业
查询一:每分钟订单量(窗口聚合,追加模式)
sql
INSERT INTO order_cnt_per_min
SELECT
TUMBLE_START(order_time, INTERVAL '1' MINUTE) AS window_start,
TUMBLE_END(order_time, INTERVAL '1' MINUTE) AS window_end,
COUNT(*) AS cnt
FROM orders
GROUP BY TUMBLE(order_time, INTERVAL '1' MINUTE);这个查询的结果表只有插入,没有更新。因为窗口一旦关闭并触发计算,就输出最终值,后续不会改变。Kafka Sink 会以追加方式写入。
查询二:用户累计金额(分组聚合,Upsert 模式)
sql
INSERT INTO user_total
SELECT user_id, SUM(amount) AS total
FROM orders
GROUP BY user_id;这是一个持续汇总,Flink 会通过状态维护每个用户的 total,每当 total 发生变化,就会生成 upsert 消息写入 MySQL。MySQL 表中,每个 user_id 始终只保留最新一行。
4.4. 数据流演示
假设订单依次到达:
sql
时间 order_id user amount
10:00:01 01 u1 10
10:00:03 02 u2 20
10:00:59 03 u1 15
10:01:02 04 u2 5- 每分钟订单量查询 的行为:
- 10:00:01 和 10:00:03 的数据到来时,窗口 [10:00:00, 10:01:00) 尚未关闭,状态暂存计数。
- 当时间推进到 Watermark > 10:01:00(比如收到 10:01:06 的数据,Watermark 为 10:01:01),前一个窗口触发计算,输出:
window_start: 10:00:00, window_end: 10:01:00, cnt: 3
该行被写入 Kafka,不再改变。 - 下一个窗口 [10:01:00, 10:02:00) 的计数逐渐增加,类似触发。
- 用户累计金额查询 的行为:
- o1 到达:状态 {u1:10},输出 +Iu1, 10 → MySQL 插入一行。
- o2 到达:状态 {u1:10, u2:20},输出 +Iu2, 20。
- o3 到达:状态 {u1:25, u2:20},u1 的总额从 10 变为 25,输出 -Uu1,10 和 +Uu1,25 (若为 upsert 模式只需 +Uu1,25),MySQL 更新 u1 行的 total 为 25。
- o4 到达:状态 {u1:25, u2:25},u2 变化,输出更新。
你可以看到,连续查询就像活的一样,数据一变,结果跟着变。
5、看懂执行计划:从 SQL 到 StreamGraph
当你提交一个 INSERT INTO ... SELECT 时,Flink 会解析 SQL,生成一个流式执行计划。可以用 EXPLAIN 查看:
sql
EXPLAIN INSERT INTO user_total SELECT user_id, SUM(amount) FROM orders GROUP BY user_id;输出类似:
sql
== 物理计划 ==
Sink: upsert to jdbc
<-> GroupAggregate(groupBy=[user_id], select=[user_id, SUM(amount)])
<-> Source: kafka这表明形成了一个持续运行的聚合算子,不断消费 Kafka 并输出到 MySQL。
6、如何理解"连续查询"与传统查询的差异?
|-------------|-------------------------------|
| 传统 SQL 查询 | Flink SQL 连续查询 |
| 一次执行,返回当前快照 | 长期运行,输出持续更新的变化流 |
| 数据是静态表 | 数据是动态表,可以插入、修改、删除 |
| 结果一次性返回 | 结果以 changelog 流式输出 |
| 不能直接处理无限流 | 天然支持无限流,配合 Watermark 实现事件时间计算 |
可以说,动态表 + 连续查询 = 把流数据当作不断变化的数据库表,用 SQL 维护实时物化视图。
7、总结要点
- 连续查询是 Flink SQL 的核心执行单元,通过 INSERT INTO ... SELECT 定义。
- 根据查询逻辑,结果变更模式分为追加、撤回、Upsert。
- 窗口聚合(事件时间 + Watermark)产生追加模式结果;无窗口分组聚合产生更新模式,通常用 Upsert Sink 对接。
- 你可以像操作普通数据库一样,通过 SQL 构建实时看板、实时清洗、实时关联等任务,无需写一行 Java 代码。
七、动态表详解之动态表查询限制
1、无窗口聚合的状态无限增长
当你写这种查询时:
sql
SELECT user_id, COUNT(*) AS cnt
FROM clicks
GROUP BY user_id;这是一个永不结束的分组聚合。Flink 会为每个 user_id 维护一个计数状态,并实时更新。问题是:用户数量可以无限增长,状态也会无限膨胀,最终撑爆内存或磁盘。
限制本质:无窗口聚合会永久保留状态,无界流上的 GROUP BY 需要谨慎管理状态生命周期。
错误做法(在生产中直接长时间运行):
sql
-- 风险:每天新增数万用户,几个月后状态达 GB 级别
INSERT INTO user_stats
SELECT user_id, SUM(amount) FROM transactions GROUP BY user_id;正确方式 :配置状态 TTL(Time-To-Live),让 Flink 自动清理不活跃的键。
sql
-- 在 TableConfig 或 SQL 提示中设置状态保留 1 天
SET 'table.exec.state.ttl' = '86400000'; -- 毫秒或者,最好用窗口聚合把无界数据切成有界片段:
sql
-- 改用分钟级窗口,状态在窗口结束后即可清理
SELECT
TUMBLE_START(proc_time, INTERVAL '1' MINUTE) AS win_start,
user_id,
COUNT(*) AS cnt
FROM clicks
GROUP BY TUMBLE(proc_time, INTERVAL '1' MINUTE), user_id;2、流上的排序必须依赖时间属性
传统数据库的 ORDER BY 可以排序任意列,因为数据是有限的。但在流上,全量排序需要缓存所有数据,这是不可能的。
Flink SQL 允许 ORDER BY,但有一个硬性限制:
只能基于时间属性(事件时间或处理时间)进行排序,并且必须是升序。
这样做的原因是:数据流本身就是按时间自然递增的,排序不产生额外状态,结果可以直接追加输出。
错误做法(试图按非时间列排序):
sql
SELECT * FROM clicks ORDER BY amount DESC;执行会报错类似:Sort on non-time attribute is not supported.
正确做法(基于时间属性升序排序):
sql
-- 假设 order_time 是事件时间属性
SELECT * FROM orders ORDER BY order_time ASC;这个查询会把乱序流按事件时间升序重新排列(Flink 内部会等待 Watermark),输出结果为追加模式。
3、双流 JOIN 强烈建议带上时间区间
两条无界流的常规等值 JOIN(Regular Join)语法上允许:
sql
SELECT *
FROM order_a a
JOIN order_b b ON a.order_id = b.order_id;这会让 Flink 把两张表的所有数据都保存在状态里,永久不会清理,状态压力极大。
限制/最佳实践 :Flink SQL 提供间隔 JOIN(Interval JOIN),强制要求 JOIN 条件中包含时间区间,这样过期的状态就能被清理。
不推荐的做法(无时间限制的 Regular Join):
sql
-- 危险:两张流的所有记录永久驻留在状态中
SELECT a.*, b.*
FROM kafka_orders a
JOIN kafka_payments b ON a.order_id = b.order_id;推荐做法:使用 Interval JOIN,让 Flink 知道需要保留多久的历史数据。
sql
ECT a.*, b.*
FROM kafka_orders a
JOIN kafka_payments b
ON a.order_id = b.order_id
AND b.pay_time BETWEEN a.order_time - INTERVAL '10' MINUTE
AND a.order_time + INTERVAL '5' MINUTE;这里,pay_time 和 order_time 必须是时间属性。Flink 只会保留对应时间窗口内的数据,过期自动清理,保证状态可控。
4、窗口聚合必须基于时间属性
窗口查询是流处理的刚需,但窗口的切分只能依赖时间属性:
sql
-- 正确:TUMBLE 基于事件时间或处理时间
GROUP BY TUMBLE(order_time, INTERVAL '1' HOUR)
-- 错误:不能用普通数值列作为窗口时间
GROUP BY TUMBLE(order_id, INTERVAL '10') -- 语法错误同时,如果用事件时间窗口,必须先在源表上定义 WATERMARK,否则无法推进时间、触发窗口计算。
错误示例(没有 Watermark 就用事件时间窗口):
sql
CREATE TABLE orders (order_time TIMESTAMP(3), ...) -- 缺少 WATERMARK
WITH (...);
SELECT TUMBLE_START(order_time, INTERVAL '1' MINUTE), COUNT(*)
FROM orders
GROUP BY TUMBLE(order_time, INTERVAL '1' MINUTE);执行时窗口永远不会触发,因为没有 Watermark 推进。
正确做法:在 CREATE TABLE 时声明 Watermark。
sql
CREATE TABLE orders (
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);5、输出模式必须与目标表兼容
连续查询的结果变更模式有三种:追加、撤回、Upsert 。目标表(Sink)也分三类:仅支持追加(如 Kafka 普通 topic、文件系统)、支持 Upsert(如 MySQL、Elasticsearch)、支持撤回(如 Kafka upsert 格式)。如果模式不匹配,作业会失败。
典型冲突:把一个会产生更新的聚合查询,直接写入普通 Kafka topic。
错误示例:
sql
-- 用户总额聚合(产生更新流)
INSERT INTO kafka_append_only
SELECT user_id, SUM(amount) FROM orders GROUP BY user_id;
-- kafka_append_only 定义时没有声明主键和 upsert 模式Flink 会抛出异常:Table sink 'kafka_append_only' doesn't support consuming update and delete changes.
解决方法:
- 改为输出追加模式的窗口聚合:
sql
INSERT INTO kafka_append_only
SELECT TUMBLE_START(order_time, ...), user_id, SUM(amount)
FROM orders GROUP BY TUMBLE(order_time, ...), user_id;- 或使用支持 Upsert 的 Sink(如 MySQL、Upsert-Kafka):
sql
CREATE TABLE user_total_kafka (
user_id STRING,
total DECIMAL(10,2),
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
...
);
INSERT INTO user_total_kafka SELECT user_id, SUM(amount) FROM orders GROUP BY user_id;6、总结:记住"流式四大约束"
|-------------|------------------------|-----------------------------------|
| 限制类型 | 核心原因 | 正确应对方式 |
| 无界聚合 | 状态会无限增长 | 配状态 TTL,或改用窗口聚合 |
| 排序 | 全量排序需要缓存所有数据 | 只使用时间属性升序排序 |
| 双流 JOIN | 两表状态均无限增长 | 使用 Interval JOIN 限制时间窗口 |
| 窗口聚合 | 必须用时间属性切分并推进 Watermark | 定义好 WATERMARK,基于时间列建窗口 |
| 输出模式兼容性 | 更新流无法写入只支持追加的 Sink | 用追加查询写追加 Sink,或用 Upsert Sink 接收更新 |