随着 React、Vue、Next.js 等现代前端框架的普及,传统 requests 爬虫越来越难直接获取完整页面内容。同时,各类网站不断升级反爬策略,仅依靠浏览器自动化也难以支撑长时间、大规模采集。本文将从现代网页的发展趋势出发,介绍 Playwright 的优势,并结合动态代理 IP,构建一套更加稳定、高效的网页采集方案。
目录
[二、为什么越来越多项目开始使用 Playwright?](#二、为什么越来越多项目开始使用 Playwright?)
[动态代理为什么开始成为 Playwright 的"标配"?](#动态代理为什么开始成为 Playwright 的"标配"?)
[三、代理 IP 在 Playwright 中到底解决了什么?](#三、代理 IP 在 Playwright 中到底解决了什么?)
引言
如果几年前问大家:"Python 爬虫应该用什么?"
相信大多数人的回答都是:
requests + BeautifulSoup
或者:
requests + lxml
因为那个时代的大多数网站都是服务端渲染(SSR),服务器直接返回完整 HTML,requests 获取源码之后即可解析。
例如:
import requests
html = requests.get("https://example.com").text
print(html)但是近几年,越来越多开发者发现:
- requests 返回的 HTML 越来越少;
- 页面源码只有一个
<div id="root"></div>; - 浏览器能够正常打开,代码却抓不到数据;
- 即使拿到了接口,也越来越容易出现 403、429 等访问限制。
很多人第一反应是 网站反爬越来越厉害了
其实并不完全如此。真正发生变化的是 现代网页的架构
一、为什么现代网页越来越复杂?
过去,一个网页通常是这样的流程:
浏览器 ------ HTTP请求 ------ 服务器 ------ 返回完整 HTML浏览器拿到 HTML 后直接显示。
而 requests 做的事情,其实就是模拟浏览器发送 HTTP 请求,因此能够直接获取完整页面。
但是今天,越来越多的网站采用了:
- React
- Vue
- Angular
- Next.js
- Nuxt
等现代前端框架。
浏览器真正访问的是:
浏览器 -> HTML(几乎空)-> JavaScript -> Ajax / Fetch -> API -> DOM 渲染也就是说:
requests 获取到的源码可能只有:
<body>
<div id="root"></div>
</body>真正的数据,是浏览器执行 JavaScript 后动态生成的。
因此很多开发者误以为网站加密了;而实际上只是浏览器替开发者完成了 JavaScript 渲染。
除此之外,现在的网站还有越来越完善的访问控制机制,例如:
- JavaScript Challenge
- Cloudflare 防护
- 浏览器指纹检测
- Cookie 校验
- LocalStorage
- SessionStorage
- IP Reputation(IP信誉)
- 请求频率限制
这些机制叠加之后,仅依赖 requests 已经很难完成复杂网页的数据采集。
因此,越来越多项目开始使用浏览器自动化框架。
二、为什么越来越多项目开始使用 Playwright?
如果说 requests 是:
HTTP 请求工具
那么 Playwright 更像是:
真正控制浏览器。
它启动的是 Chromium、Firefox 或 WebKit 浏览器,而不是简单发送 HTTP 请求。
整个流程变成:
Python -> Playwright -> Chromium 浏览器 -> 执行 JavaScript -> 网页完整渲染 -> 获取 DOM因此,对于:
- React
- Vue
- Next.js
- 无限滚动页面
- 登录后页面
- SPA 单页应用
Playwright 都具有天然优势。
相比 Selenium,Playwright 还拥有不少优点:
- 自动等待元素加载
- 多浏览器支持
- Browser Context 隔离
- 更快的执行速度
- 更丰富的 API
- 官方持续维护
例如访问一个页面,仅需要几行代码:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://baidu.com")
print(page.title())
browser.close()
相比 requests,它获取到的是:
浏览器真正渲染完成后的页面。
因此,Playwright 已经逐渐成为现代网页采集的重要工具。
动态代理为什么开始成为 Playwright 的"标配"?
不过,当很多开发者开始使用 Playwright 后,很快又会遇到新的问题。
浏览器虽然能够正常打开页面,但如果:
- 长时间运行;
- 高并发采集;
- 多任务同时访问;
- 不同地区的数据抓取;
仍然可能触发网站的访问限制。
原因也很简单。
浏览器解决的是页面渲染问题, 而不是网络身份问题。
因此,在很多生产项目中,浏览器自动化通常都会配合代理 IP 一起使用。
相比传统维护本地代理池,现在越来越多代理服务开始提供 HTTP API 获取代理 的方式。
例如测试过程中使用的 B2Proxy,可以直接通过 API 获取代理 IP,返回 JSON 数据,程序无需提前维护大量代理列表,只需要在浏览器启动之前获取一次代理即可。
这种方式最大的优势是:
- 可以按数量动态获取代理;
- 支持不同国家或地区节点;
- 返回 JSON,便于 Python 直接解析;
- 不需要自行维护代理池和更新机制。
对于 Playwright 这类浏览器自动化项目来说,代理获取已经可以像调用普通 HTTP 接口一样简单。
三、代理 IP 在 Playwright 中到底解决了什么?
很多刚接触 Playwright 的开发者都会有一个疑问
为什么浏览器自动化仍然容易被限制?
很多开发者第一次接触 Playwright 时都会有一个误区,认为浏览器自动化已经模拟了真实浏览器,就不再需要代理 IP。实际上,Playwright 和代理 IP 解决的是两个完全不同的问题。Playwright 负责浏览器渲染、JavaScript 执行、页面交互等浏览器层面的能力,而代理 IP 决定的是请求最终以什么网络身份访问目标网站。浏览器能够正常打开页面,并不意味着目标网站会一直接受来自同一个 IP 的大量访问请求。
对于一个短时间运行的脚本来说,固定 IP 往往不会出现明显问题,但在真实项目中,一个采集任务可能持续运行数小时甚至数天。当所有请求都来自同一个出口 IP 时,即使浏览器行为完全正常,也可能因为访问频率过高、IP 信誉下降或者地区限制等原因触发网站风控。因此,大规模网页采集通常都会将浏览器自动化与代理 IP 结合使用,Playwright 负责解决页面渲染问题,而代理 IP 则负责网络出口和访问身份,两者共同组成完整的采集方案。
与过去维护代理 IP 列表相比,现在越来越多代理服务开始提供 API 获取模式。程序无需提前保存几百甚至几千个代理地址,只需要在启动浏览器之前请求一次代理接口,即可获得最新可用的代理 IP。
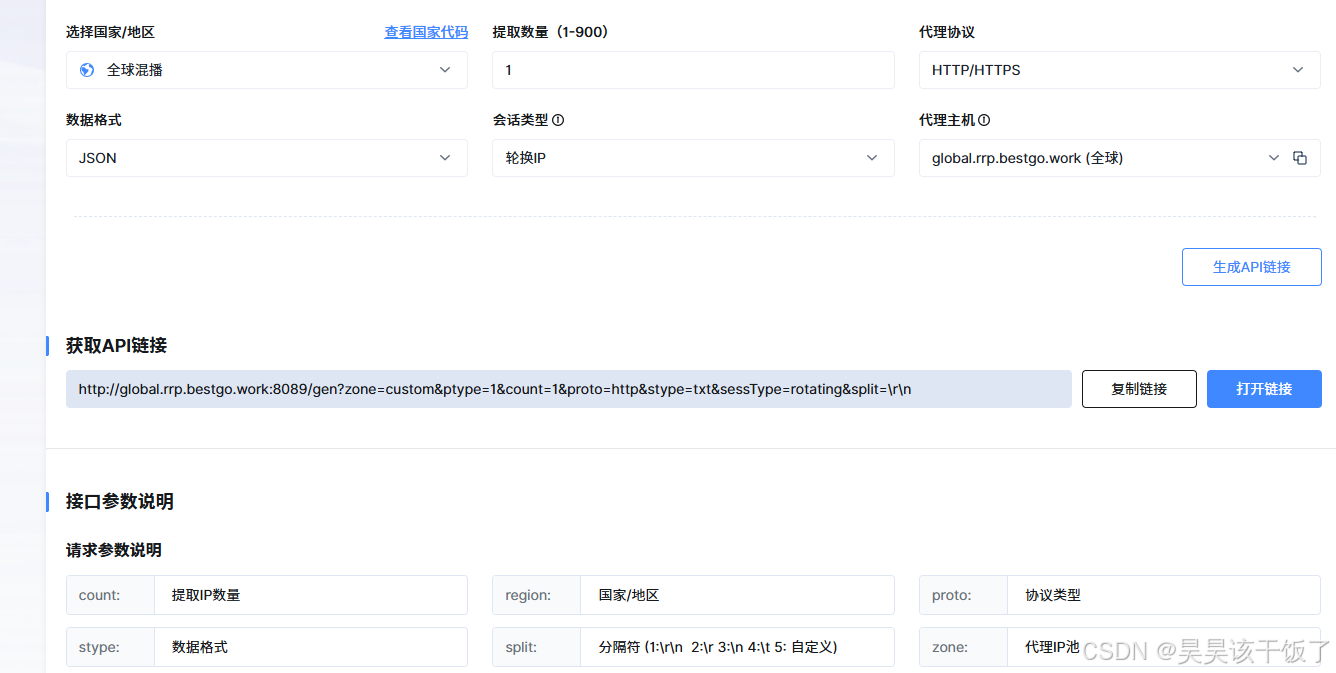
这种方式不仅降低了维护成本,也更适合自动化项目持续运行。例如 B2Proxy 提供的 动态代理ip 就采用了 API 获取模式,接口返回标准 JSON 数据,可以直接在 Python 中解析,无论是 requests 还是 Playwright,都能够快速完成代理配置。
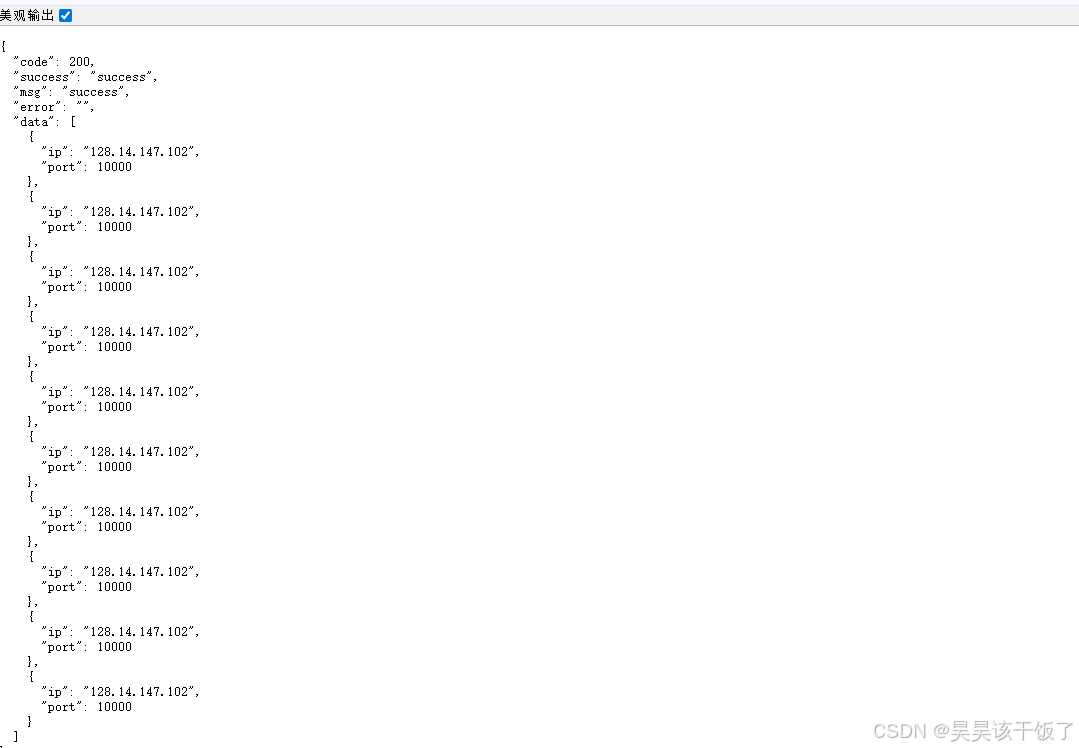
获取代理后,Playwright 配置代理实际上非常简单,只需要在启动浏览器时传入 proxy 参数即可。
from playwright.sync_api import sync_playwright
import requests
# 注意要将下面连接换成自己的api 获取api前往:https://www.b2proxy.com/?utm_t=1&utm_i=192 (需要海外网络)
api = "http://global.rrp.bestgo.work:8089/gen?zone=custom&ptype=1&count=10&proto=http&stype=json&sessType=rotating"
proxy = requests.get(api).json()["data"][0]
with sync_playwright() as p:
browser = p.chromium.launch(
headless=False,
proxy={
"server": f"http://{proxy['ip']}:{proxy['port']}"
}
)
page = browser.new_page()
page.goto("https://httpbin.org/ip")
print(page.text_content("body"))
browser.close()整个过程几乎不需要额外修改业务代码,只是在浏览器启动之前增加了一次代理获取过程。相比维护本地代理池,这种方式最大的优势是代理始终保持最新状态,同时还能根据不同业务动态调整代理数量、国家地区以及协议类型,更容易集成到长期运行的采集项目中。
在实际项目中,更推荐将代理获取封装成独立模块,而不是在每一个采集脚本中重复调用代理接口。浏览器只负责页面采集,代理管理模块负责获取代理、异常切换以及失败重试,两者相互独立,后续即使更换代理服务,也无需修改采集逻辑,只需要替换代理提供层即可,这也是目前大多数大型采集系统采用的架构方式。
四、工程实践中的几点建议
当 Playwright 与代理 IP 结合之后,一个简单的网页采集脚本基本就具备了生产环境的雏形。不过,在实际项目中,还需要关注几个容易被忽略的细节。
首先,不建议每次任务都重新启动浏览器。Chromium 的启动成本相对较高,更推荐复用 Browser 实例,通过多个 Browser Context 隔离不同采集任务。这样不仅可以降低资源消耗,也能减少浏览器启动时间。
例如,一个 Browser 可以创建多个 Context:
browser = playwright.chromium.launch(headless=True)
for _ in range(5):
context = browser.new_context()
page = context.new_page()这种方式比不断创建 Browser 更轻量,也是 Playwright 官方推荐的使用方式。
其次,代理管理尽量不要直接写在业务代码中,而是封装成一个统一模块。浏览器只负责页面采集,代理获取交给 Proxy Manager 处理,后续无论更换代理服务还是增加代理验证,都不会影响业务逻辑。
例如:
def get_proxy():
res = requests.get(API_URL).json()
proxy = res["data"][0]
return f"http://{proxy['ip']}:{proxy['port']}"业务代码只需要:
browser = playwright.chromium.launch(
proxy={
"server": get_proxy()
}
)整个采集流程会更加清晰。
另外,并发数量并不是越高越好。相比一次启动几十个浏览器,更推荐根据机器性能控制 Browser 数量,每个 Browser 下创建多个 Context,再配合异步任务进行调度。这样既能保证采集效率,也能降低目标网站对异常访问的识别概率。
在测试过程中,我这里使用的是B2proxy
为什么选择 B2Proxy 您通往 可靠 代理的门户![]() https://www.b2proxy.com/?utm_t=1&utm_i=192 它提供了标准 HTTP API 获取代理,只需要在启动浏览器之前请求一次接口,就可以获得最新代理 IP,返回 JSON 数据后即可直接配置到 Playwright 中。相比维护本地代理池,这种 API 化的方式更适合长期运行的自动化采集项目,如果需要切换国家、协议或代理数量,也只需要调整接口参数即可,不需要修改业务代码。
https://www.b2proxy.com/?utm_t=1&utm_i=192 它提供了标准 HTTP API 获取代理,只需要在启动浏览器之前请求一次接口,就可以获得最新代理 IP,返回 JSON 数据后即可直接配置到 Playwright 中。相比维护本地代理池,这种 API 化的方式更适合长期运行的自动化采集项目,如果需要切换国家、协议或代理数量,也只需要调整接口参数即可,不需要修改业务代码。
最后,建议为采集任务增加简单的异常重试机制。当页面访问失败时,不要立即退出,而是重新获取代理并重新创建 Browser Context。例如:
try:
page.goto(url, timeout=30000)
except Exception:
browser.close()
# 获取新的代理后重新启动浏览器这种方式虽然代码不多,但对于长期运行的采集任务来说,可以显著提高整体稳定性。
现代网页采集已经从简单的 HTTP 请求演变为浏览器自动化、代理调度和异常恢复共同协作的工程体系。Playwright 负责页面渲染和交互,代理 IP 提供稳定的网络出口,再配合合理的浏览器复用与异常处理策略,基本可以覆盖绝大多数现代网页采集场景。对于需要长期维护的项目,这种架构相比传统 requests 爬虫更具扩展性,也更容易适应不断变化的网站环境。