前面我们绍过使用AiEduLab.tech中"图像分类------手写数字识别"项目来完成图像分类模型的构建、训练、使用。实际上,AiEduLab.tech还支持多输出模型。
有时我们不仅仅需要一组分类结果可能还希望同时得到另一组无法融合的结果。这可以通过训练另一个模型来实现,但当数据、模型基本相同仅仅输出不同时,训练两个模型明显会训练一部分神经网络。多输出模型可以很好的解决这个问题:多个输出头共享前面的卷积等,每个输出头学习自己输出部分的内容。
仍然以MNIST数据集为例,我们可以在"图像分类与回归------手写数字分类与定位"任务中使用多个输出头,每个输出头可以定义为分类任务或回归任务。也就是说,我们可以同时输出一个图片商的数字是几、是奇数还是偶数(两个输出头都是分类);也可以一个输出是几、另一个输出其位置(分类任务+回归任务)。
一、模型构建
在构建多数出头任务时,第一个块仍然是"输入层",接下来使用"多输出模型"积木:
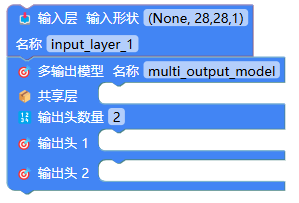
共享层的设计和单输出模型基本相同:
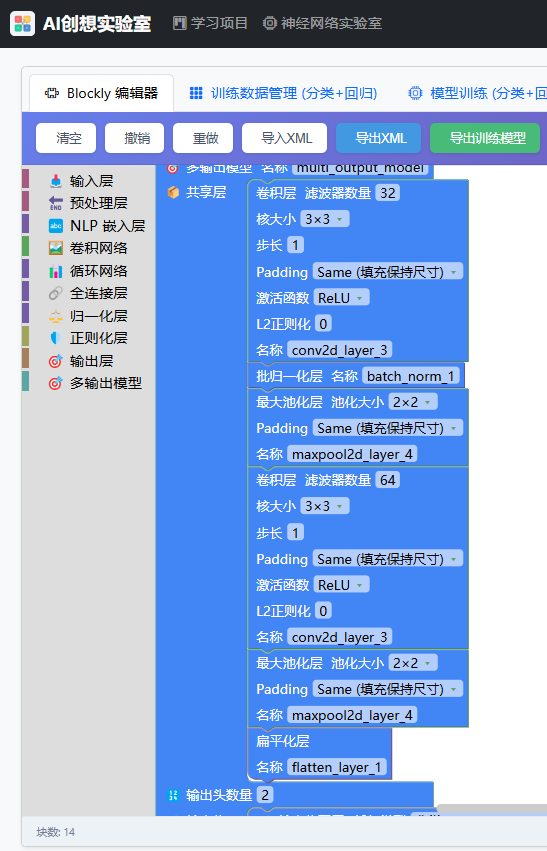
都是通过多层卷积来实现。为了输出分类,我们设置输出头1为分类任务------共10分类,然后给它增加一个全连接层,该全连接层负责分类任务:
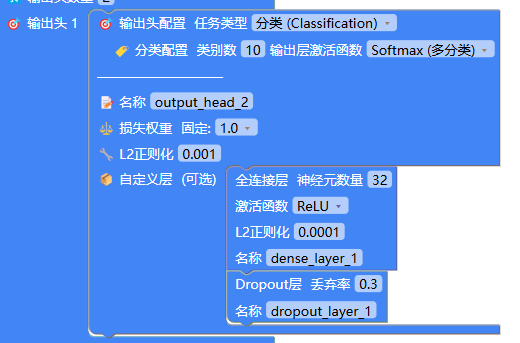
将输出头2设置为"边界框"(注意,边界框并不是标准的任务类型,它只是为了让初学者更容易设置而设计的,你可以用回归任务来设置相同的参数来实现),并增加一个全连接层,该全连接层负责学习回归任务:

当然,如果你愿意尝试输出"奇偶"就把它设置为分类任务,全连接层神经元可以少很多。由于分类任务和回归任务学习难度有所不同,所以你可以尝试为两个输出头设置不同的权重。
二、不确定性加权
有时候为了得到效果较好的权重配置我们可能需要调参很久,但实际上对于多输出任务采用"自动化"的权重配置更好------使用一个可训练张量即可。这就是不确定性加权,它在模型训练过程中同时训练一个张量,这个张量再作为权值作用于训练过程。在AiEduLab.tech的"图像分类+回归"任务类型中,支持使用不确定性加权来训练模型。
三、数据准备
在该数据管理器中,设置标签的方法是点击列头工具进行批量设置或者单独设置每行。
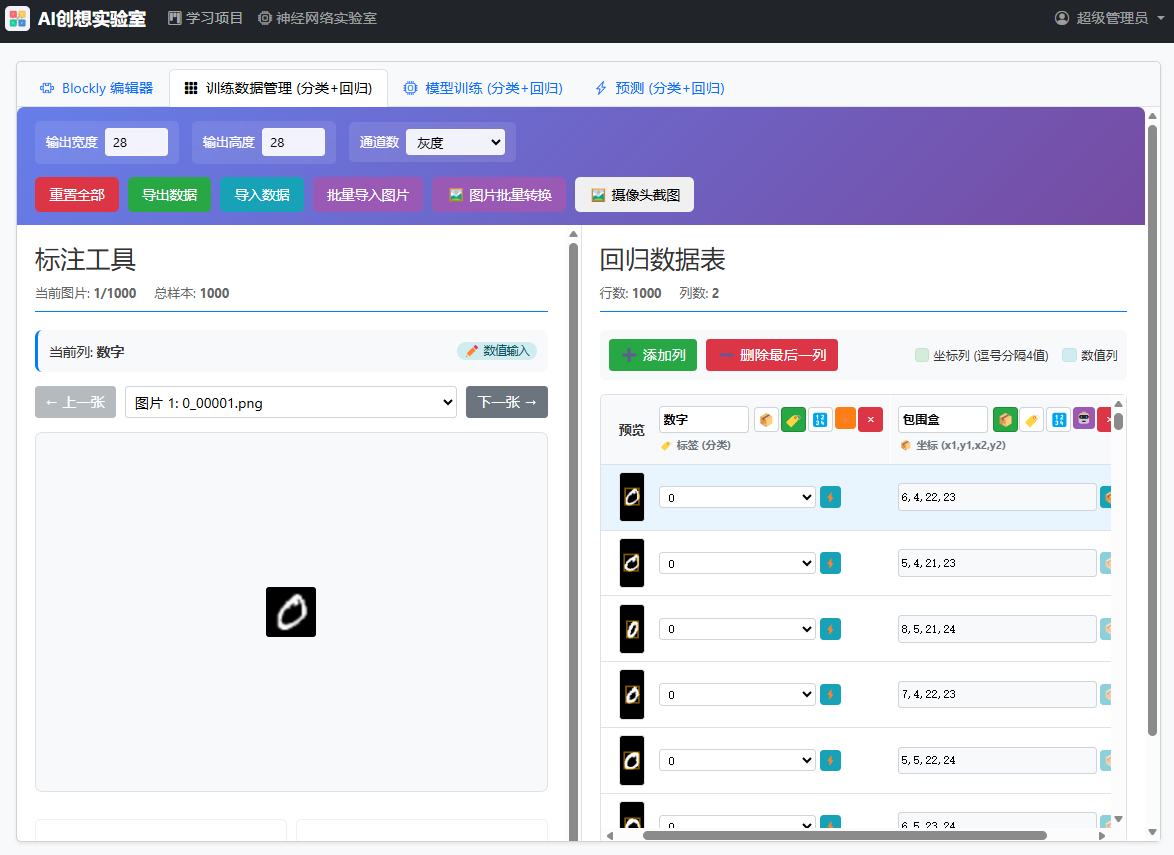
数据管理器提供了快捷工具,对于MNIST这样的数据集可以快速标注:
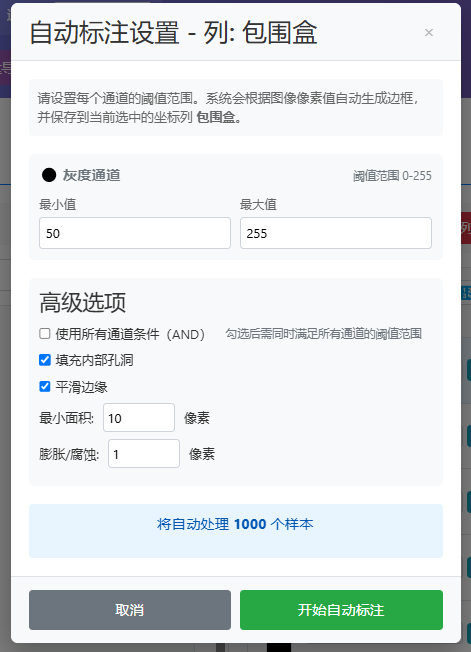
四、训练
对于混合任务来说,包围框的重新计算是耗时较大的操作,并且边界的处理等也需要仔细斟酌,所以提供的数据增强方法比较保守:
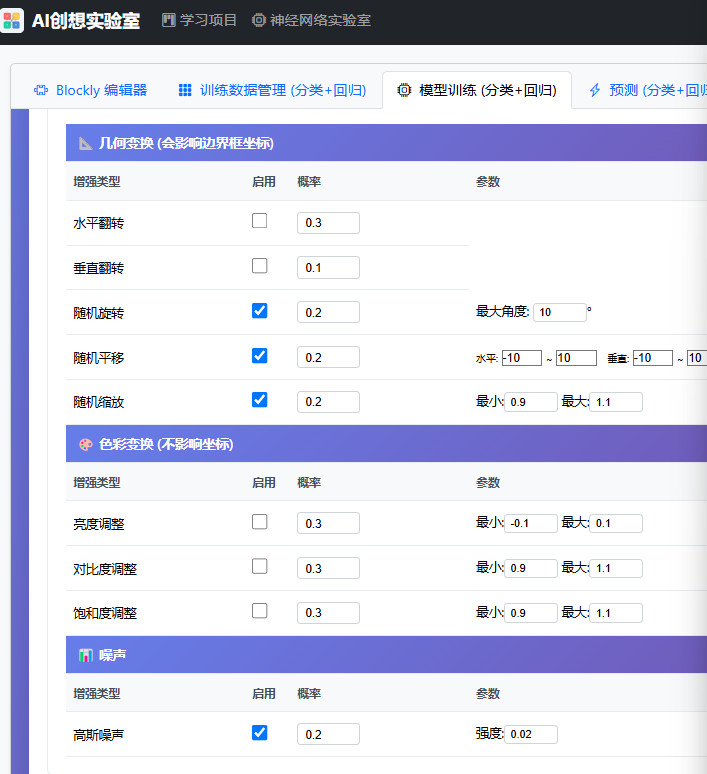
当导入训练数据和模型后,我们就可以开始训练了。此时可以选择"不确定性加权"复选框,以改善不恰当的输出头权重配置导致的难于训练的状况。
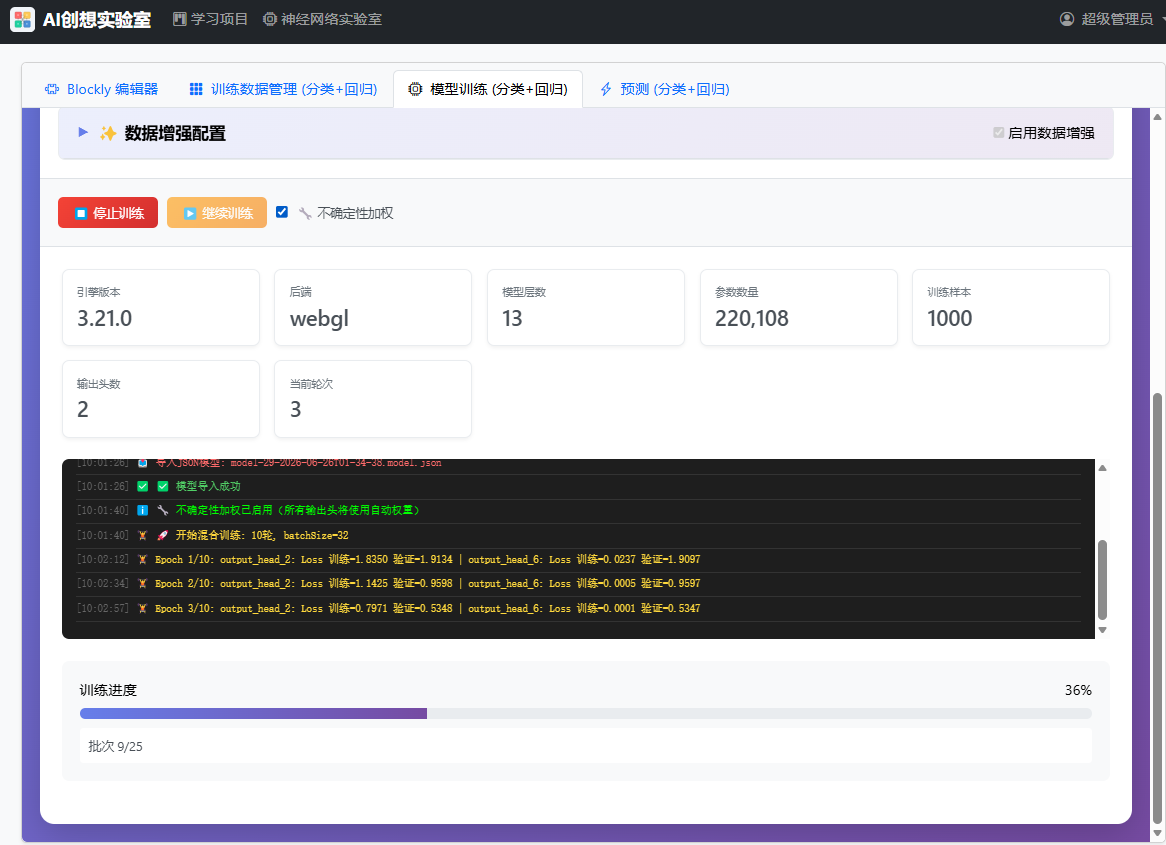
从图中可以看到,使用较小的模型和较少的训练数据,在核显上训练疑论仅需二十几秒。训练过程中我们需要关注不同输出头的损失情况,它们各自的变化以及训练情况。使用默认数据,在几分钟之内就可以得到一个满足教学需求的模型。
五、预测
将训练好的模型导出后,导入到预测器中进行预测。
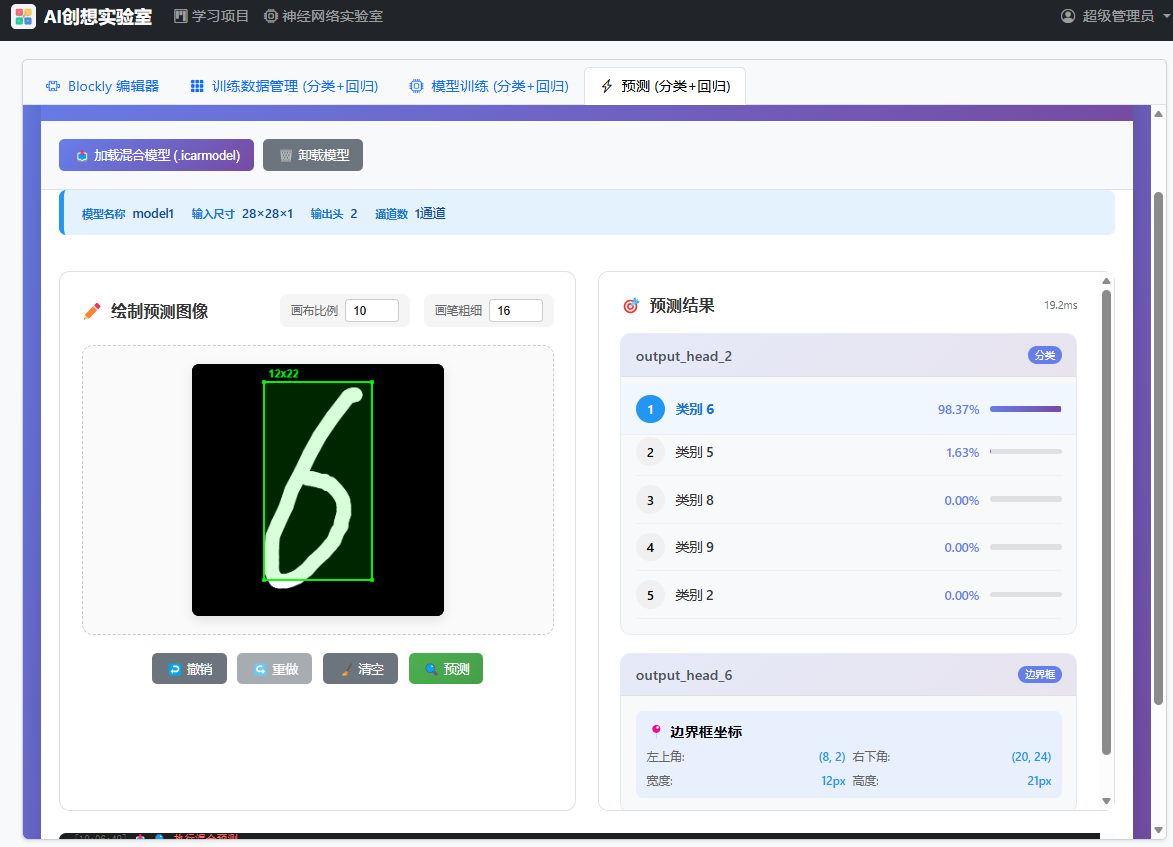
注意:该类型的项目在演示版中不提供训练功能,你会看到训练器中加载训练脚本的错误,但其他功能完全可用:Blockly编辑器,数据管理器,预测器均可用。你可以下载预设数据进行学习。
PS:"图像分类"任务也支持多输出模型,但你仅能设计多维度标签数据和模型,即:可以在"图像分类------手写数字识别"任务中体验多输出模型------输出数字同时输出奇偶。