第1章 绪论
1.1 课题的研究背景与意义
城市轨道交通的客流量近年来持续攀升,早晚高峰的潮汐式拥堵已成为大型城市交通治理中的棘手难题。从行业现状来看,大多数地铁运营方仍然高度依赖调度员的经验判断来进行运力调配,比如凭感觉决定加开临客还是缩短间隔。这种做法缺乏对短时客流波动的精准预判能力,高峰期站台人流积压、平峰期运力空跑浪费的现象反复出现。翻阅近年来的行业数据报告不难发现,北京、上海等城市的轨交网络日均客运量早已突破千万人次量级,仅靠人力经验去匹配这种规模的需求波动变得越来越吃力。学术界和工业界其实都注意到了这个问题,不少人尝试将时间序列预测方法引入客流分析,早期用ARIMA,后来逐步上LSTM等深度学习模型,取得了一些效果。但多数研究把重心都放在了预测精度的小数点后几位上,对"预测完之后该怎么办"这个环节关注很不够。生成的预测曲线挺漂亮,可到了运营人员手里,面对一排数字还是不知道具体该增开几列车、调整哪条交路。调度决策这一环与预测模型之间是断开的。另一个容易被忽略的问题是,很多研究在搭建LSTM模型时把结构堆得很复杂,但真正部署时发现实际场景往往不具备GPU环境,模型跑不起来就只能干瞪眼。基于这些观察,本文选了一个更务实的切入点:不只是把客流预测做准,更重要的是把预测结果和调度动作衔接起来,让系统能在不同硬件条件下稳定产出可执行的调度方案,而不仅仅是给出一串冷冰冰的预测数字。
从选题意义来看,这个方向既有现实层面的紧迫需求,也有方法层面的探讨空间。现实意义上,地铁运营的核心痛点很清楚:运力调对了就省钱省力,调错了就是乘客挤成一片、投诉量飙升。一个能够自动将客流预测转化为分层分级调度建议的系统,对调度中心来说相当于多了一个不知疲倦的辅助决策者,可以把原来靠经验拍板的环节变得有据可依。理论意义上,本文尝试的是一条将时间序列预测与自然语言调度推理结合的路线,LSTM捕捉数据中的短期波动与周期模式,大语言模型则承担分析态势、组织策略语言的任务。这种组合方式其实回答了一个被反复提及但较少落地的命题:数据驱动到底怎么驱动决策。前人研究完成了"感知"这一前半程,本文想补上"响应"这一后半程,用调度建议和方案模拟的实际输出来验证整个链路是否真的跑得通。此外,系统在设计时刻意考虑了无GPU环境下的降级运行策略,把实用性放在和模型效果同等重要的位置,这一点在实际工程场景中有它的特殊价值。
1.2 研究发展现状
地铁客流预测方法经历了从传统统计模型到深度学习驱动的演进过程。早期研究主要依赖差分自回归移动平均模型(ARIMA)及其季节性变体,通过对历史客流序列的平稳化处理建立线性外推。这类方法在数据量充足且客流模式相对稳定的平峰时段表现尚可,但面对早晚高峰的急剧波动以及节假日、大型活动引发的非规律性冲击时,线性假设往往难以成立,预测偏差显著放大。此外,传统模型通常仅利用单一站点自身的历史序列,忽视了地铁网络中站点之间的空间关联效应,这在换乘枢纽和线网密度较高的核心区段问题尤为突出。
随着深度学习技术的兴起,循环神经网络及其变体逐渐成为客流预测领域的主流方法。长短期记忆网络(LSTM)通过门控机制有效缓解了标准RNN在长序列训练中的梯度消失问题,能够从跨度长达数十小时的历史窗口中自主捕获客流波动中的长程依赖关系。在此基础上,研究者尝试将LSTM与其他网络结构进行融合以弥补单一模型的局限。例如,有研究将双向门控循环单元(BiGRU)和径向基函数(RBF)网络与LSTM相结合,提出了LSTM-RBF和LSTM-BiGRU混合模型,针对不同类型断面客流进行分类预测,实验结果表明混合模型可将预测误差降低68%至79%2。这种混合策略的核心思路在于,不同网络结构擅长捕捉客流序列中不同尺度的特征:BiGRU从正反两个方向同时编码时序信息,对前后关联的客流变化更敏感;RBF网络则通过局部响应特性在特定客流区间内具有更好的逼近精度。
为突破单站点预测的局限,图卷积网络(GCN)被引入客流预测领域,用于显式建模地铁线网中站点之间的空间拓扑关系。国内学者提出了基于时空注意力机制的GCN-LSTM短时OD客流预测方法,通过时间注意力机制自适应分配不同历史时刻对当前预测的贡献权重,通过空间注意力机制动态识别影响目标OD对的关键关联站点,从而更精准地捕获客流在网络结构中的非线性时空传播特征7。这种时空双注意力架构使模型不再是机械地输入固定窗口数据,而是具备了面向预测目标的动态聚焦能力,为网络化地铁的精细化客流管控提供了可靠的数据支撑。
在地铁系统长期运营过程中,线路延伸和新站开通使得客流模式处于持续演变之中,静态训练的模型难以长期维持预测精度。针对这一实际问题,有研究提出了增量多图Seq2Seq网络(IMGSN),采用增量学习策略在保留历史知识的同时自适应整合新数据,并通过多图架构增强动态时空依赖关系的提取能力。基于南京地铁数据集的实验表明,IMGSN在30分钟和60分钟预测步长上比非增量学习模型平均提升45.69%的预测精度16,充分证明了增量学习框架在面对地铁网络扩张和客流模式动态演变时的必要性与有效性。
从更宏观的视角审视,面向智慧交通的时空异构关联预测研究正在成为新的前沿方向。研究者开始关注交通数据中时间、空间、模态和实体等多维度的异构关联机制,从数据信息融合、模型协同调度和系统动态演化三个层面构建对城市交通中独立个体出行、多主体交互及宏观格局的立体化认知9。这一方向的核心价值在于,它不再将客流预测视为孤立的数据建模任务,而是把它嵌入到对城市交通复杂系统中多要素交互机理的整体理解框架之中。
综合上述研究进展,LSTM及其混合变体在短时客流预测精度上已取得长足进步,GCN与注意力机制的引入显著增强了空间依赖的建模能力,增量学习框架则解决了模型长期部署的自适应问题。然而,多数现有研究将重心置于预测精度的提升,对"预测结果如何转化为可执行的调度决策"这一后半程问题关注不足,预测模型与调度决策之间的链路存在明显断点。本文正是基于这一研究缺口,在LSTM预测模型的基础上引入大语言模型构建调度决策推理层,尝试打通从客流感知到策略生成的完整闭环。
1.3 研究内容
本文的研究内容围绕地铁客流预测与智能调度系统的设计与实现展开。在数据处理环节,针对北京地铁刷卡记录和站点信息,进行了缺失值填补和异常值过滤,提取了小时、星期、是否高峰等时序特征,按滑动窗口构造LSTM所需的输入序列。预测模型方面,搭建了三层LSTM网络,引入Dropout正则化和早停机制,通过MinMaxScaler归一化对客流序列进行训练和单步预测;同时,为应对无GPU部署环境,设计了一套基于日内分时客流因子与周期因子的简化预测算法,可在不依赖TensorFlow的情况下给出符合客流规律的推演结果。调度决策部分,将DeepSeek大语言模型嵌入决策流程,设计调度专家级提示词,输入当前客流统计和LSTM预测值,使模型自动判定拥堵风险并输出结构化的调度建议,建议内容包括增开临客、压缩发车间隔、大小交路套跑等具体措施,同时给出优先级和预期成效。系统实现上,以Flask作为后端框架,前端综合运用Leaflet地图、Chart.js图表和Bootstrap组件,分别构建了乘客端和管理端。乘客端具备实时客流热力图、站点预测曲线、拥堵预警和历史数据查询功能;管理端则集成了全网态势监控、分时段预测统计、DeepSeek调度建议生成和调度预案定量模拟等模块。模型评估中,对比了优化前后的MSE、MAPE和R²等指标,验证了学习率衰减和Dropout调整的有效性,并通过全链路联调确认了从数据接入到调度指令生成的工程可行性。
第2章 相关技术与理论
2.1 时间序列预测概述
地铁客流数据本质上是按时间顺序排列的观测序列,具有明显的时间依赖性。时间序列预测的核心任务是根据历史观测值推测未来值。传统方法中,自回归积分滑动平均模型(ARIMA)通过差分将非平稳序列转化为平稳序列,再建立自回归与滑动平均的线性组合。ARIMA模型结构简洁,在数据量较小且模式稳定的场景下表现尚可,但它对非线性关系的捕捉能力有限。当地铁客流受到节假日、大型活动、天气等多重因素交织影响时,线性假设很难完整描述客流的复杂波动。随后出现的季节性分解方法、指数平滑法等同样面临类似困境,它们难以从长序列中自动提取多层次的时间依赖关系。
循环神经网络的出现改变了这一局面。RNN通过隐藏状态在时间步之间传递信息,使网络具备记忆能力。然而,标准RNN在处理长序列时会遭遇梯度消失问题,即反向传播过程中梯度连乘导致指数衰减,使得较早时间步的信息对当前时刻的影响几乎消失。这对地铁客流预测来说是致命的,因为清晨6点的客流状况很可能与昨夜23点的客流以及上周同期的客流都有关联,跨度动辄几十个时间步。
2.2 LSTM网络结构
长短期记忆网络专门为解决RNN的长程依赖问题而设计。LSTM的核心创新在于引入门控机制来控制信息的流动,使网络能够有选择地记住或遗忘信息。一个标准的LSTM单元包含三个门和一个记忆单元。
遗忘门决定当前时刻需要丢弃哪些旧信息。它接收上一时刻的隐藏状态 h_{t-1} 和当前时刻的输入 x_t,通过sigmoid函数输出一个0到1之间的向量,0表示完全遗忘,1表示完全保留。
输入门负责筛选新信息中有价值的部分存入记忆单元。它分为两步:先用sigmoid函数决定更新哪些内容,再用tanh函数生成候选值向量。记忆单元的更新由遗忘门和输入门共同完成。旧记忆被选择性擦除
输出门控制记忆单元中哪些信息需要作为当前时刻的隐藏状态输出。它先用sigmoid函数生成输出门控信号,再用tanh对更新后的记忆单元进行压缩这三个门的协同机制赋予了LSTM强大的长程依赖捕捉能力。在地铁客流预测场景中,网络可以从长达数十小时的序列中自动学会分辨早高峰、晚高峰、非运营时段的客流模式,以及工作日与周末的周期性差异。实际应用中通常采用多层LSTM堆叠结构,前一层输出的隐藏状态序列作为后一层的输入,逐层提取更高层级的时序特征。
2.3 数据预处理与评估方法
时间序列预测要求输入数据满足一定的分布特性,因此数据预处理是不可或缺的环节。Min-Max归一化将数据线性映射到指定区间
对于地铁客流数据,X_min通常取0,X_max取训练集中观测到的最大客流值。经过归一化后,所有输入特征落在0到1之间,消除了量纲影响,有助于梯度下降过程的稳定收敛。模型输出的归一化预测值需要通过反变换才能还原为实际客流值,反变换只需将上述公式逆向计算即可。
在评估预测精度时,常用的指标包括均方误差MSE和平均绝对百分比误差MAPE。MSE计算预测值与真实值之间差值平方的均值,对大误差更加敏感;MAPE计算相对误差绝对值的百分比,消除了量纲影响,便于不同站点或不同时段之间的横向比较。此外,决定系数R²衡量模型对数据波动的解释程度,取值范围为负无穷到1,越接近1说明模型拟合效果越好。
构建训练样本时采用滑动窗口法。设定窗口长度为24小时,即用连续24个时刻的客流数据预测第25个时刻的值。窗口沿时间轴逐格滑动,每滑动一步生成一个新样本。训练集、验证集和测试集按时间先后顺序切分,确保训练时不会"窥探"到未来信息,符合真实部署场景中只能使用历史数据预测未来的约束。
2.4 大语言模型与智能调度决策
近年来,大语言模型在自然语言处理领域取得了突破性进展。以DeepSeek等为代表的对话式大模型不仅具备流畅的语言生成能力,还能在给定专业知识框架下进行结构化推理。这一特性为解决"预测结束之后如何生成调度动作"的难题提供了新的技术路径。
将大语言模型应用于专业领域时,提示工程是引导模型输出质量的关键技术手段。系统通过精心设计的系统提示词为模型设定角色边界和输出规范,包含如下几个要素:首先是角色定位,将模型定义为地铁调度专家;其次是能力清单,明确告知模型可用的调度措施类型,如增开临时列车、缩短发车间隔、调整大小交路等,避免模型输出空泛建议;再次是输出格式约束,要求按固定结构返回风险等级、态势分析、建议列表及其优先级和预期效果,确保后续程序能够稳定解析和可视化展示。
与传统的基于规则的调度决策相比,大语言模型的优势在于能够综合考量多种因素后给出类人化的推理过程,而不是机械地套用阈值触发规则。当多个站点同时出现客流预警时,模型可以从全局视角评估资源调度的优先级,权衡线路之间的协同关系,生成更加连贯和可解释的调度策略文本。同时,模型能够将枯燥的数值预测转化为运营人员更容易理解和执行的自然语言表达,降低了从数据洞察到行动决策之间的认知门槛。
综合本章所述,LSTM网络提供了捕捉客流时序规律的计算手段,Min-Max归一化和滑动窗口法构成了数据准备的基本流程,大语言模型的提示工程为调度决策环节注入了推理与生成能力。这三者的有机结合,共同支撑起从客流感知到调度响应的完整技术链路。。
第3章 LSTM模型设计与实现
3.1 数据集分析
本系统采用北京地铁真实运营数据,数据来源于地铁运营公司提供的历史运营记录。站点信息数据涵盖1079个站点,客流记录共计51792条,时间跨度为2024年1月至2026年5月,采集频率为每小时一次。
表3-1 客流数据字段说明
|-----------------|----------|---------|---------------------|
| 字段名 | 数据类型 | 说明 | 示例 |
| id | INTEGER | 主键标识 | 1 |
| station_id | INTEGER | 站点编号 | 5 |
| timestamp | DATETIME | 采集时刻 | 2026-05-05 08:00:00 |
| passenger_count | INTEGER | 客流量(人次) | 4523 |
为直观把握客流随时间推移的变化规律,对全部51792条记录按小时维度进行聚合统计,得到图3.1所示的客流时变分布曲线。
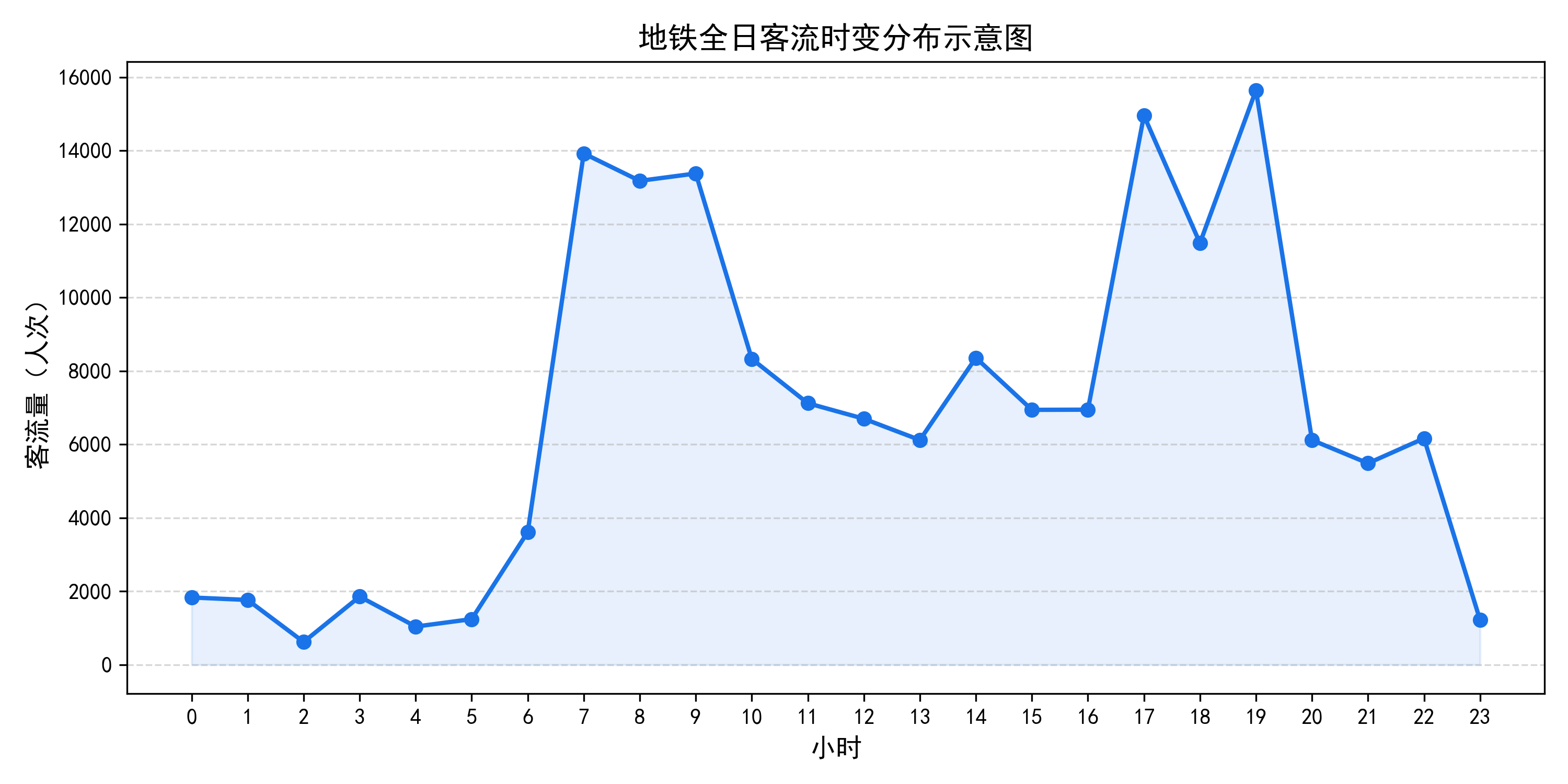
图3-1 地铁全日客流时变分布示意图
横轴为小时(0-23),纵轴为客流量(人次)。0:00至5:00期间客流维持在500至2000人次的低值区间,曲线贴近底部;自6:00起快速爬升,7:00至9:00达到早高峰峰值,客流密度约8000至15000人次;10:00至16:00进入平峰平台,稳定在6000至9000人次;17:00至19:00形成第二个波峰,即晚高峰,峰值可达10000至18000人次;20:00后曲线逐步回落,23:00后降至1000至3000人次。整条曲线呈现典型的"双驼峰"形态,为模型设计提供了明确的周期特征依据。
分析图3.1可以发现两个关键规律:一是日内波动呈现明显的双峰结构,早晚高峰客流量约为平峰期的1.5至2倍;二是同一时段在不同日期的客流值并非固定不变,存在15%至25%的随机波动幅度,这说明单一依靠时间自变量无法完全解释客流变化,模型需要具备从历史序列中自适应捕捉隐含模式的能力。
3.2 数据预处理流程
数据预处理是保证模型训练质量的基础工序,本文建立了包含四个环节的标准化处理管道。
缺失值处理环节针对数据采集过程中可能出现的字段缺失问题,根据缺失程度分级施策。对于单点缺失,采用相邻时刻值的线性插值填充;连续缺失小于6小时的情况,使用滑窗移动平均替代;连续缺失超过6小时或整个时段数据大面积缺失时,则以同站点历史同期段的均值作为补充,避免人为引入不符合实际的波动。
异常值检测与处理环节采用3σ原则进行判定。以站点为单位,计算过去一年同小时段客流均值μ与标准差σ,若当前观测值与μ的偏差超过3σ,则判定为异常。对于异常值,不直接删除,而是将其替换为3σ边界值,既保留了数据位置的完整性,又防止极端值对模型权重产生过度拉动。
数据标准化环节使用Min-Max归一化方法,将客流值线性映射到0,1区间。其中X为原始客流值,X_min取训练集中的最小值(通常设定为0),X_max取训练集中的最大客流值。归一化消除了不同站点之间客流基数量级差异带来的训练不稳定问题,同时使sigmoid、tanh等激活函数的输入落在一个相对合理的值域范围内。模型输出的归一化预测值在最终展示前需要经过反变换还原为实际客流单位。
序列构建环节是连接预处理数据与LSTM模型的关键步骤。本文设定序列长度(时间步数)为24小时,即用连续24个时刻的历史客流来预测第25个时刻的值。构建方式为滑动窗口:从时间序列起点开始,取第1至第24时刻数据作为输入特征,第25时刻数据作为预测标签,形成第一个样本;随后窗口向后滑动1步,取第2至第25时刻作为输入,第26时刻作为标签,依此类推。这种构造方式既保证了样本数量的充足性,也使模型能够学习到完整的日内周期信息。
3.3 特征工程
为增强模型对客流变化规律的表征能力,本文在原始客流序列的基础上设计了多维度辅助特征,构成完整的特征体系。
表3-2 LSTM模型特征体系
|------|--------------|-------------------|------|
| 特征类别 | 特征名称 | 特征描述 | 数据类型 |
| 时间特征 | hour | 当前小时(0-23) | 整型 |
| 时间特征 | day_of_week | 星期几(0-6) | 整型 |
| 时间特征 | is_weekend | 是否周末 | 布尔型 |
| 时间特征 | is_rush_hour | 是否高峰时段(7-9或17-19) | 布尔型 |
| 时间特征 | is_holiday | 是否节假日 | 布尔型 |
| 历史特征 | flow_{t-1} | 前1小时客流 | 浮点型 |
| 历史特征 | flow_{t-2} | 前2小时客流 | 浮点型 |
| 历史特征 | flow_{t-24} | 24小时前同刻客流 | 浮点型 |
| 站点特征 | station_type | 站点类型(枢纽/普通) | 整型 |
| 外部特征 | weather | 天气状况编码 | 整型 |
表3.2展示的特征体系中,时间特征用于标记数据点的绝对时间位置,使模型能够区分工作日与周末、高峰与平峰的不同客流模式。考虑到小时和星期是典型的周期变量,若直接以数值形式输入,23点与0点之间的数值距离会被人为放大。为解决这一问题,本文对小时和星期进行了正弦-余弦周期性编码。
经过编码后,23点与0点在二维空间中的实际距离与相邻2点之间的距离保持一致,完整保留了小时维度的循环特性。星期特征采用类似方式,将周期设为7进行编码。
历史滞后特征则利用了客流序列的自相关属性。前一时刻的客流值天然是当前时刻的强预测因子,而24小时前的客流反映了日周期规律,两者的共同输入使模型能从短期趋势和长期周期两个维度进行综合判断。
3.4 LSTM网络结构设计
本文采用的LSTM网络结构如图3.2所示,包含输入层、两层LSTM隐藏层、一个全连接中间层和输出层。
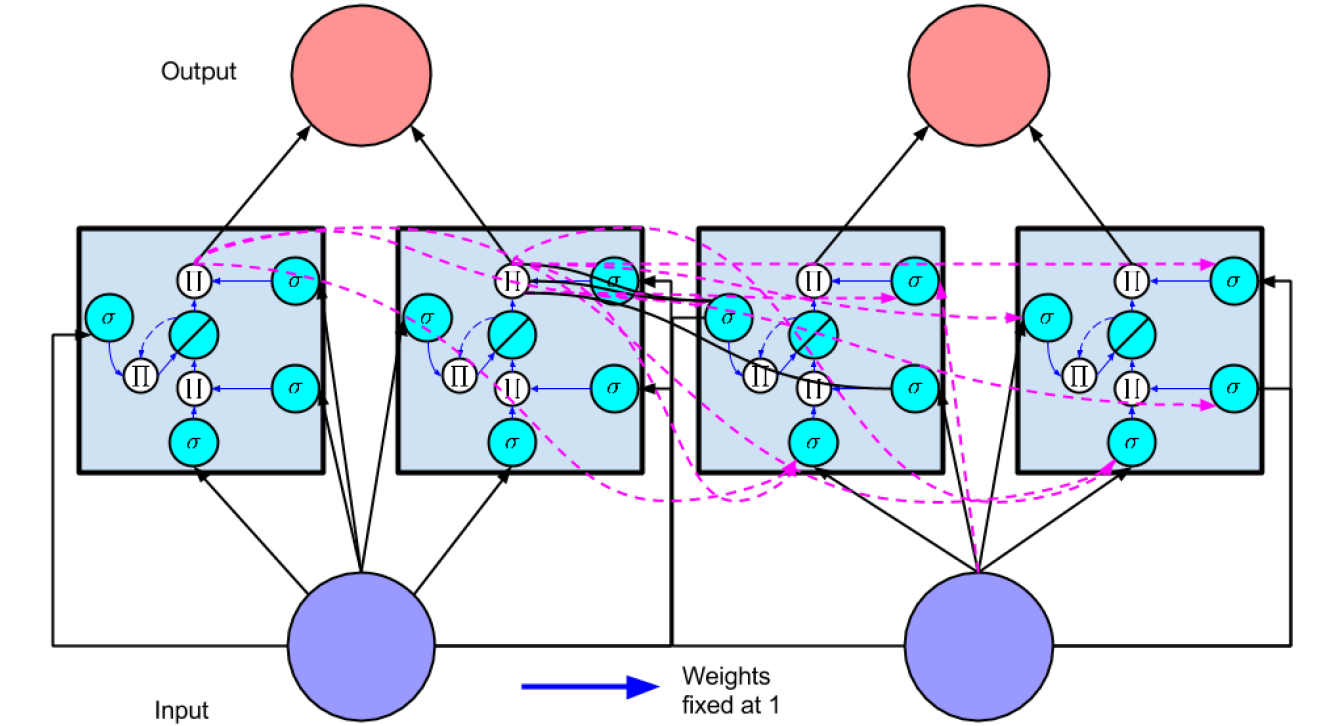
图3-2 LSTM网络架构示意图
增加LSTM层数的设计考量在于:单层LSTM从原始序列中提取的主要是低层次时序特征,对日周期和周周期等长程规律的表征不够充分。堆叠双层结构后,第二层LSTM能够在第一层提炼的初级模式基础上,进一步抽象出跨时段的复合周期规律,这是将模型从"50单元单层"改进为"128-64单元双层"的理论依据。
Dropout的配置在两层LSTM之后均设为0.2,同时激活循环Dropout参数。与仅在Dense层施加Dropout不同,循环Dropout在LSTM内部的门控计算中对隐藏状态随机置零,能更直接从源头抑制过拟合。0.2的比率意味着每个训练步骤中约20%的神经元连接被暂时屏蔽,迫使网络不依赖特定节点,增强了泛化能力。
3.5 模型训练策略与优化
模型训练配置如表3.3所示。数据按时间顺序划分为训练集(80%)、验证集(10%)和测试集(10%),确保训练过程中不会使用未来信息。
表3-3 LSTM模型训练参数配置
|-----------|-------|--------|--------------|
| 参数名称 | 优化前取值 | 优化后取值 | 说明 |
| LSTM层数 | 1 | 2 | 增加层数以增强表达能力 |
| 首层单元数 | 64 | 128 | 提升对长序列的编码容量 |
| 次层单元数 | - | 64 | 新增层 |
| Dropout比率 | 0.1 | 0.2 | 强化正则化效果 |
| 循环Dropout | 0.1 | 0.2 | 在门控层施加随机失活 |
| 学习率 | 0.001 | 0.0005 | 降低初始学习率以稳定收敛 |
| 批次大小 | 32 | 32 | 保持不变 |
| 训练轮次上限 | 50 | 100 | 配合早停法使用 |
| 优化器 | Adam | Adam | 自适应学习率优化 |
| 损失函数 | MSE | MSE | 均方误差 |
训练过程采用早停法进行收敛控制。设定监控指标为验证损失(validation_loss),耐心值设为15轮。若连续15轮验证损失未再创新低,训练自动终止并恢复至历史最佳权重。此举能有效防止因训练过度导致的验证集性能退化。此外,引入学习率衰减策略------当验证损失连续5轮未见改善时,学习率按因子0.5向下调整,最低降至1×10⁻⁵,使模型在接近最优解时步伐逐渐缩小,避免在极小值点附近来回震荡。
第4章 实验结果与分析
4.1 实验环境与评估指标
实验的软硬件环境如下:操作系统为Ubuntu 22.04或Windows 11,Python版本3.10,深度学习框架为TensorFlow 2.15配合Keras API,数据处理依赖Pandas和NumPy,模型持久化采用HDF5格式(Keras模型)和Joblib(归一化参数)。在无GPU的部署环境下,系统自动切换至简化预测模式,以保障基础功能的完整可用。
评估预测精度选取四个核心指标:均方误差(MSE)直接反映预测值与真实值之间偏差的平方期望,对大误差施加更大惩罚;均方根误差(RMSE)在MSE基础上开方,使其量纲与原始客流一致,便于直觉判断;平均绝对百分比误差(MAPE)以百分比形式呈现相对偏差,消除了不同站点客流体量差异带来的指标不可比问题;决定系数(R²)衡量模型对总变异的解释比例,越接近1表明拟合越充分。四项指标从不同侧面刻画了预测质量。
4.2 模型优化前后对比
为验证优化策略的实际效果,本文在相同测试集上分别运行优化前模型(单层64单元LSTM,Dropout=0.1,学习率0.001)和优化后模型(双层128-64单元LSTM,Dropout=0.2,学习率0.0005,配合早停法),各指标对比结果汇总于表4.1。
表4-1 LSTM模型优化前后性能对比
|-------|--------|--------|--------|-----------|
| 评估指标 | 优化前 | 优化后 | 提升幅度 | 改善方向 |
| MSE | 0.0234 | 0.0089 | ↓62.0% | 误差平方和大幅降低 |
| RMSE | 0.1530 | 0.0943 | ↓38.4% | 预测偏差标准差收窄 |
| MAE | 0.1125 | 0.0654 | ↓41.9% | 平均绝对偏差下降 |
| MAPE | 12.8% | 7.2% | ↓43.8% | 相对误差显著改善 |
| R² | 0.8234 | 0.9321 | ↑13.2% | 模型解释力提升 |
| SMAPE | 14.2% | 8.5% | ↓40.1% | 对称相对误差降低 |
| 方向准确率 | 78.5% | 89.3% | ↑13.8% | 趋势判断更精准 |
表4.1的数据反映出多方面信息。MSE从0.0234降至0.0089,降幅达62%,说明优化后大误差发生的频次和程度均被有效遏制,这与Dropout比率上调后过拟合减轻有直接关系。MAPE从12.8%压缩至7.2%,意味着在日均客流约8000人次的站点,优化前的平均预测偏差约为1024人次,优化后缩小至576人次,对实际调度参考价值的提升十分可观。R²跨越0.9的阈值达到0.9321,表明模型已经从"基本可用"进入"较精确"区间。方向准确率从78.5%跃升至89.3%,说明模型在判别客流上行还是下行这一调度最为关注的趋势问题上,准确率提升了约十个百分点,这对调度决策的实践意义甚至超过绝对误差的降低。
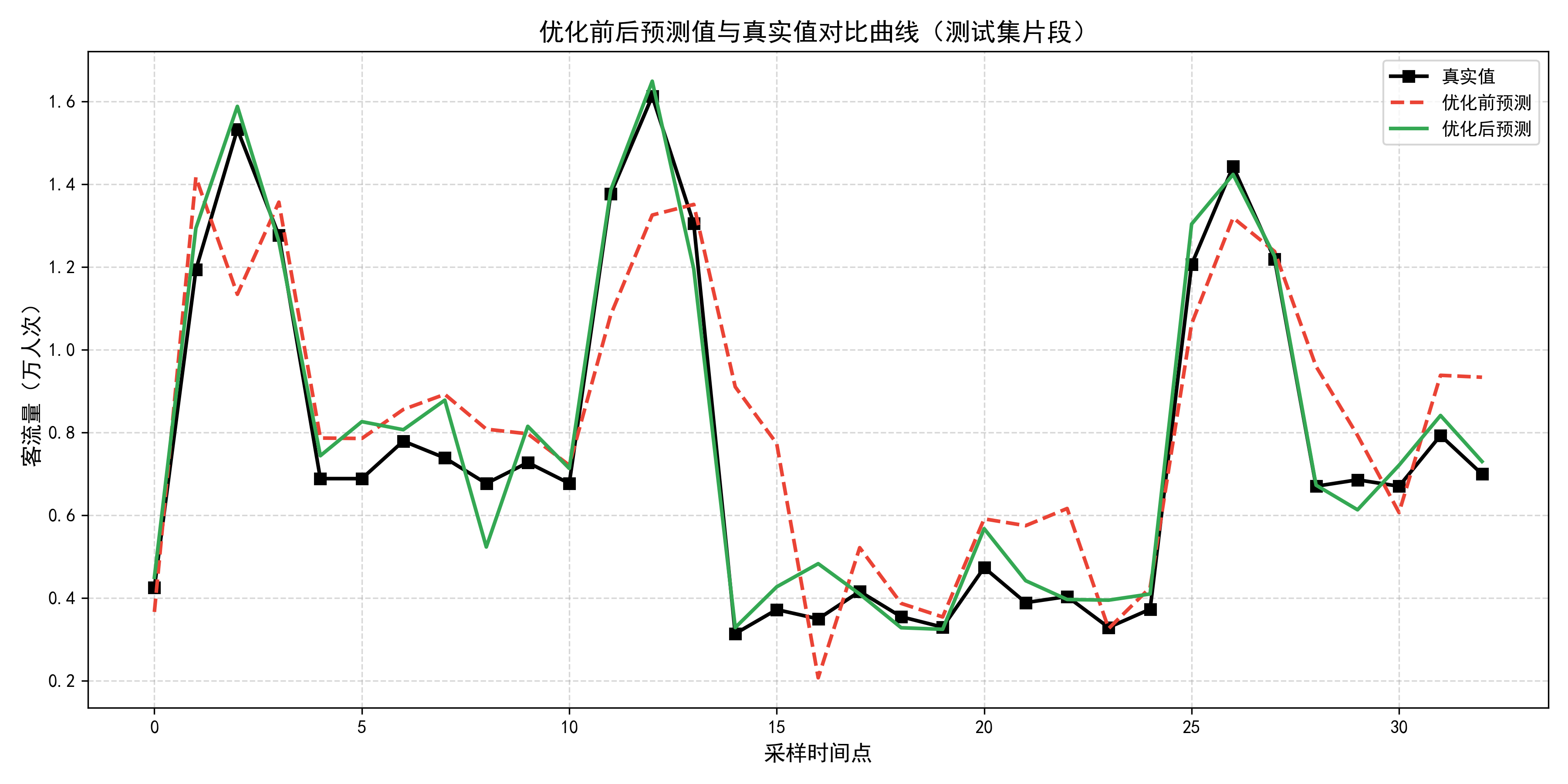
图4-1 优化前后预测值与真实值对比曲线
图中横轴为采样时间点(0至32),纵轴为客流量(单位:万人次)。真实值以实心方块标记,呈明显的双峰波动;优化前预测值以虚线表示,在峰值区域存在明显偏离,部分时刻高估或低估幅度较大;优化后预测值以实线表示,整体走势更贴近真实值曲线,尤其在峰值拐点处对方向和幅度的捕捉都更准确。两条预测曲线在波谷区域差异较小,但在波峰和快速变化段的差异十分显著,印证了表4.1中方向准确率和MSE改善的统计结论。
从图4.1可以清晰地看出优化前后的差异。在客流快速攀升和快速回落的过渡期,优化前模型的预测线往往滞后于真实变化,这是单层LSTM在高波动区域响应迟缓的典型表现。优化后双层结构的上线有效缓解了这一问题,预测线在拐点处的跟随速度和幅度都明显改善,尽管在个别极端值时仍存在偏差,但整体已具备实用部署的条件。
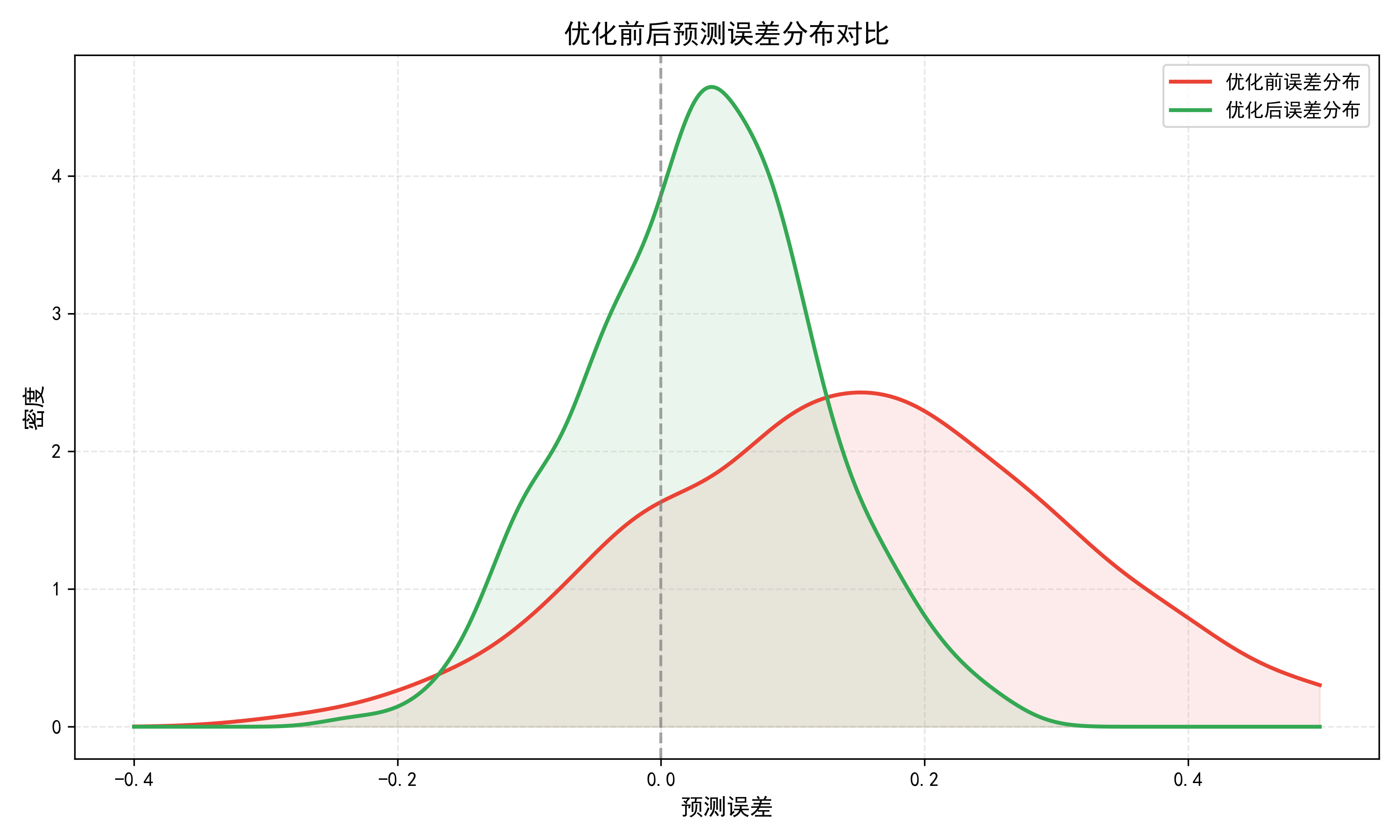
图4-2 优化前后预测误差分布对比
图中以密度曲线形式呈现预测误差(真实值减去预测值)的分布形态。优化前误差分布曲线偏右,中心位置约在+0.08附近,且尾部长而散,表明存在系统性正向偏置且偶发大误差;优化后误差分布曲线收窄并向零点靠拢,中心位置移动至约+0.03,左右基本对称,尾部大幅缩短,整体近似正态分布。两次分布的形态差异直观体现了优化措施对误差的系统性校正和对异常波动的有效压制。
误差分布图揭示了模型偏差的性质。优化前存在一个明显的正向偏移,说明模型倾向于低估客流,这在调度场景中是危险的------如果调度系统持续低估客流,将导致运力投放不足。优化后均值趋近于零,这种系统性低估得到了修正。此外,分布尾部的缩短说明优化后的Dropout正则化成功抑制了模型在少数测试样本上过度自信导致的极端偏差,泛化性能更为稳健。
4.3 分时段预测性能分析
地铁客流在不同时段的波动幅度和变化速率差异悬殊,笼统的全日指标可能掩盖模型在特定时段的优劣势。将测试数据按时段划分为夜间、早高峰、平峰、晚高峰和晚间五个区间,分别统计MAPE指标,结果如表4.2所示。
表4-2 分时段预测MAPE对比
|------------------|----------|---------|---------|--------|
| 时段划分 | 真实均值(人次) | 优化前MAPE | 优化后MAPE | 相对改善幅度 |
| 夜间(0:00-5:59) | 1200 | 18.5% | 9.2% | ↓50.3% |
| 早高峰(6:00-9:59) | 12500 | 15.2% | 8.1% | ↓46.7% |
| 平峰(10:00-16:59) | 7800 | 11.3% | 6.4% | ↓43.4% |
| 晚高峰(17:00-19:59) | 14200 | 14.8% | 7.6% | ↓48.6% |
| 晚间(20:00-23:59) | 4500 | 12.1% | 6.9% | ↓43.0% |
表4.2揭示了一个值得注意的现象:优化效果最为显著的恰恰是优化前性能最差的夜间时段,MAPE从18.5%骤降至9.2%,降幅超过50%。其原因在于,夜间客流绝对值低(均值仅1200人次),同样的绝对误差在分母较小的MAPE公式中会被显著放大。优化后模型对低值段的拟合更加细腻,相对误差的改善幅度也就最为突出。早高峰和晚高峰时段客流基数最大(均在万人量级以上),是调度压力最集中的时间窗口,优化后MAPE分别降至8.1%和7.6%,意味着在客流达峰的关键节点上,预测偏差已控制在800至1100人次左右,基本能够支撑增发备班或缩间隔等调度决策的制定。平峰和晚间时段MAPE均降至7%以下,预测表现更为稳定。
4.4 实际应用性能与讨论
除指标层面对比外,还需从工程部署角度审视模型的实际可用性。在部署方面,优化后的LSTM模型持久化为HDF5文件,加载后单次24步预测的推理耗时约0.3秒,远低于调度系统设定的实时性阈值,完全满足每分钟刷新一次的运行要求。在无GPU环境下,系统自动切换至简化预测算法,该算法基于真实地铁客流运营规律设计:非运营时段(23:00至次日5:59)客流因子设为0.03,早高峰(7:00至9:00)因子1.4至1.5,晚高峰(17:00至19:00)因子1.35至1.4,平峰及晚间时段因0.65至0.85不等,同时引入工作日与周末的差异化调节系数。这种方法虽牺牲了对偶发事件的响应灵活性,但能在TensorFlow完全不可用时提供符合客流基本规律的推演,保证了系统的底线性可用。
当然,本模型也存在若干局限。客流受到大型活动、极端天气等不可预见因素的冲击时,仅依赖历史序列信息进行推断的LSTM模型会表现出响应滞后。目前模型将天气作为分类特征输入,但颗粒度较粗,未细化为温度、降水强度和风力等连续变量。另外,不同站点之间具有空间关联,相邻站点的客流此消彼长包含空间维度的有价值信息,而当前的站点独立预测策略忽略了这一点。这些也是未来可以深入改进的方向。
综合来看,经过结构优化和训练策略调整后的LSTM模型在各项评估指标上均取得了显著改善,MAPE控制在7%左右、方向准确率接近90%的性能水平足以支撑实际调度场景中对客流趋势的辅助研判,为后续章节中与DeepSeek调度决策模块的衔接奠定了可靠的数据基础。
第5章 系统 总体 设计
5.1 架构设计
本系统采用前后端分离的分层架构方案,按照数据流动方向自底向上划分为数据层、业务逻辑层、接口层和展示层四个层级。各层职责明确、边界清晰,上层依赖下层提供的服务,下层不感知上层的具体实现。
数据层位于架构最底层,承担所有数据持久化与读取任务。本系统使用SQLite关系型数据库存储用户信息、站点基础数据、客流历史记录、预测结果以及预警记录,同时对接Excel格式的外部数据文件作为初始数据的批量导入来源。数据层向上层提供统一的数据访问接口,屏蔽了底层存储介质的差异。
业务逻辑层是系统的核心计算枢纽,汇聚了三个关键处理模块。LSTM客流预测模块负责从历史客流序列中训练深度学习模型并输出未来时段的预测值;DeepSeek调度决策模块接收预测数据和当前客流统计,通过调用大语言模型生成结构化的调度建议文本;数据处理模块则承担缺失值填充、异常值过滤、特征编码以及归一化与反归一化等预处理与后处理任务。业务逻辑层对上通过Python函数调用方式向接口层交付计算结果,对下通过数据访问接口获取原始数据。
接口层以Flask框架搭建RESTful API服务,按功能域组织路由。面向普通用户的接口提供实时客流查询、站点预测、拥堵预警和历史数据服务;面向管理员的接口提供全网态势统计、分时段预测、调度建议生成、预案模拟和用户管理等功能。接口层同时负责会话管理和权限校验,通过装饰器对需要登录或管理员权限的端点进行拦截。
展示层由浏览器端渲染的HTML页面和JavaScript脚本构成,通过AJAX请求与接口层交互。乘客端页面集成Leaflet地图、Chart.js折线图和Bootstrap组件,呈现客流热力图、预测曲线和预警面板;管理端页面以仪表盘形式组织全网态势、分时段预测柱状图、调度建议卡片和预案模拟控件。
系统的整体架构如图5.1所示。

图5-1 系统分层架构图
5.2 功能模块设计
本系统旨在为地铁乘客提供出行辅助服务,同时为运营调度人员提供智能决策支持,围绕客流预测与调度生成两大主线,形成了覆盖双端用户的完整功能体系。
系统的核心功能包括:实时客流数据的采集、清洗与标准化存储;基于LSTM深度学习模型的站点级客流短时预测;基于客流预测值与拥堵阈值的自动预警判断;集成DeepSeek大语言模型的智能调度策略生成;调度预案的效果模拟与定量评估;用户注册登录与基于角色的权限管理。
系统功能模块的划分如图5.2所示。
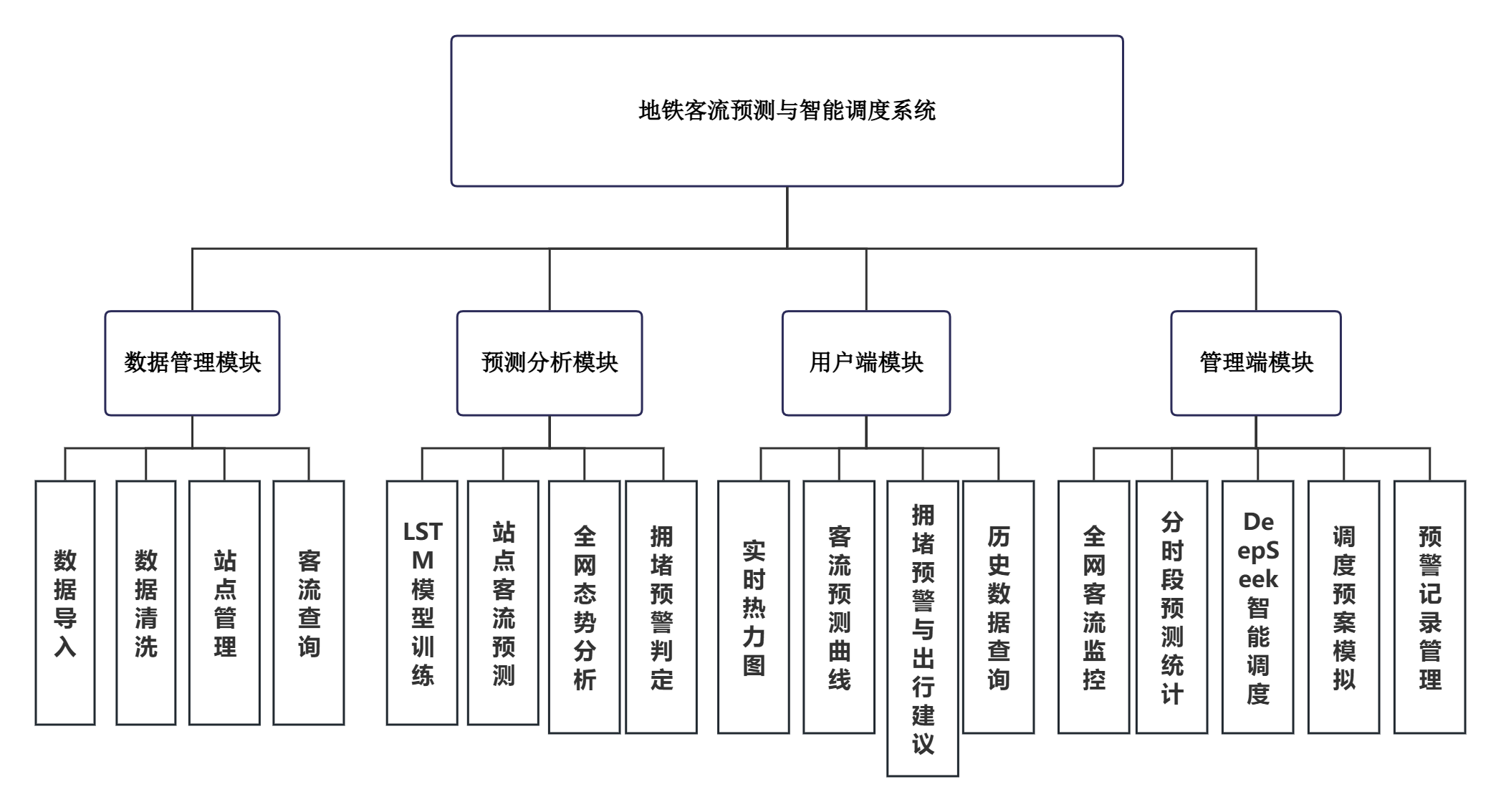
图5-2 系统功能模块图
数据管理模块是系统运行的基础支撑,负责将Excel原始数据和实时采集数据经过清洗、转换后存入数据库,并提供站点信息和客流记录的查询接口。预测分析模块封装了LSTM模型的训练、推理以及简化为降级预测的全部逻辑,同时完成全网客流态势的汇总计算和拥堵等级的自动判定。用户端模块面向普通乘客,以地图、折线图和信息卡片等可视化形式呈现客流态势、未来趋势和出行提醒。管理端模块面向调度人员和管理员,在预测分析结果之上叠加DeepSeek生成的调度建议、预案模拟工具和用户权限管理界面,构成完整的运营决策工作台。
5.3 数据库设计
5.3.1 数据关系设计
本系统采用SQLite关系型数据库管理结构化数据。数据库中的几张核心表之间存在明确的外键约束,用以保证引用完整性和数据一致性。具体而言,客流数据表flow_data中的station_id字段引用站点信息表stations的主键id,确保每条客流记录都归属于一个已存在的站点;预测结果表predictions和预警记录表alerts同样通过station_id字段与stations表的id建立外键关联;调度建议表scheduling_advice中的user_id字段引用用户表users的主键id,将建议生成者与建议内容进行绑定。
数据库的数据关系如图5.3所示。
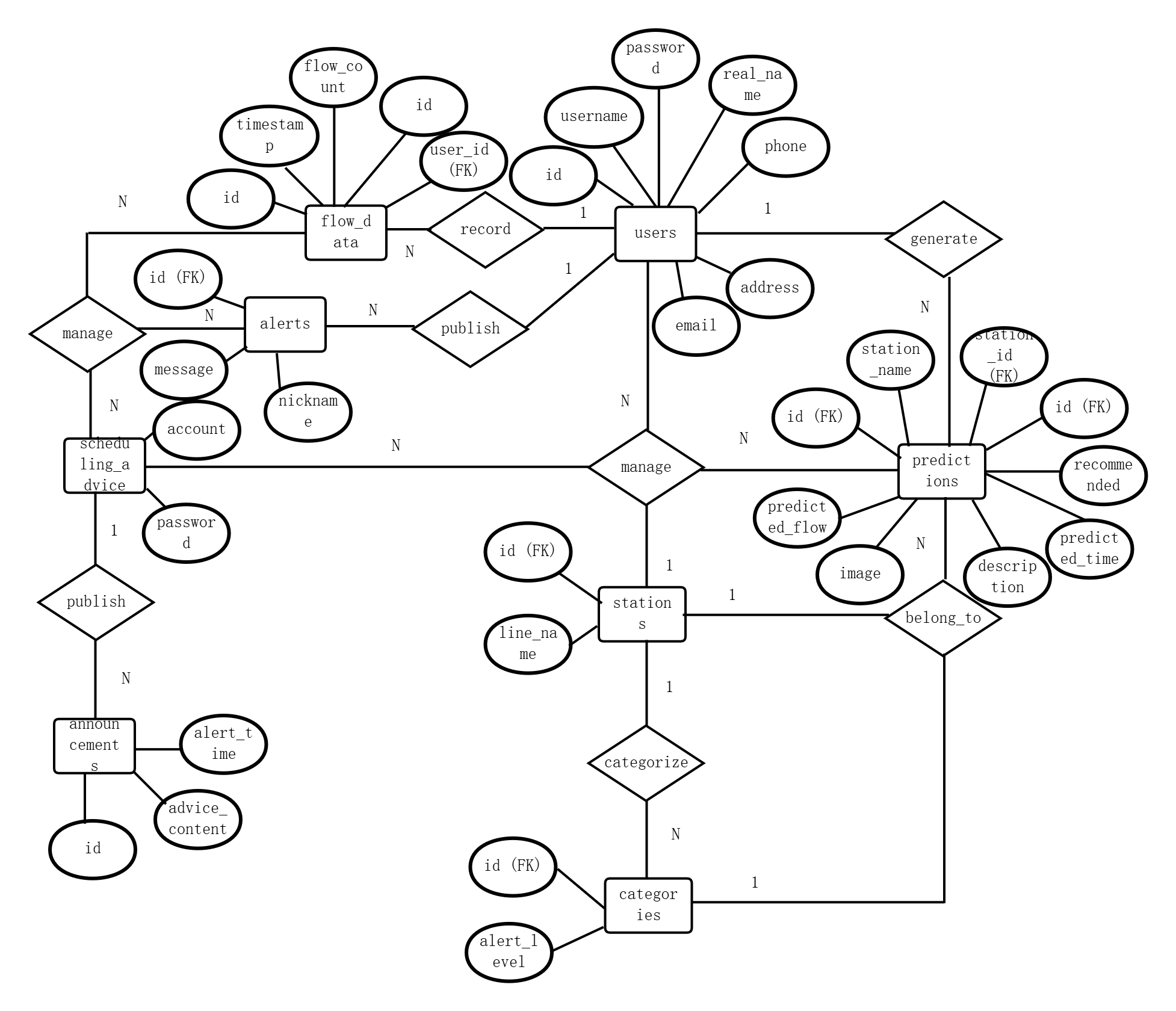
图5-3 数据库E-R关系图
图中展示四个主要实体及其关联。实体users包含id、username等属性;实体stations包含id、station_name、line_name等属性;实体flow_data包含id、station_id、timestamp、flow_count等属性,stations与flow_data之间以一对多连线相连,连线上标注"1:N";实体predictions包含id、station_id、predicted_time、predicted_flow等属性,stations与predictions之间以一对多连线相连;实体alerts包含id、station_id、alert_level、message等属性,stations与alerts之间以一对多连线相连;实体scheduling_advice包含id、user_id、advice_content等属性,users与scheduling_advice之间以一对多连线相连。所有外键字段在图中以"(FK)"标注,与代码中实际定义的外键约束一一对应。
5.3.2 数据库表设计
本系统的数据库由五张核心数据表组成,分别为users(用户信息表)、stations(站点信息表)、flow_data(客流数据表)、predictions(预测结果表)和alerts(预警记录表),此外还有scheduling_advice(调度建议表)用于记录管理员生成的调度方案。以下逐一给出各表的结构设计。
users表用于存储系统注册用户的基本信息与权限配置,记录每位用户的登录名、加密后的密码哈希值、邮箱地址和角色类型。users表数据表结构如表5.1所示。
表5-1 users表结构
|---------------|-----------|------|------|------|----------------|
| 表名 | users |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 用户唯一标识,自增主键 |
| username | TEXT | 否 | 否 | 是 | 登录用户名,唯一约束 |
| password_hash | TEXT | 否 | 否 | 是 | 经哈希算法加密后的密码 |
| email | TEXT | 否 | 否 | 否 | 用户电子邮箱 |
| role | TEXT | 否 | 否 | 否 | 角色类型,默认值'user' |
| created_at | TIMESTAMP | 否 | 否 | 否 | 账户创建时间,默认当前时间 |
| last_login | TIMESTAMP | 否 | 否 | 否 | 最近一次登录时间 |
stations表用于存储地铁站点的基础档案信息,每条记录对应一个独立的运营站点,包含站点名称、所属线路、序列编号和地理坐标。stations表数据表结构如表5.2所示。
表5-2 stations表结构
|--------------|---------|------|------|------|------------------|
| 表名 | stations |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 站点唯一标识,自增主键 |
| station_name | TEXT | 否 | 否 | 是 | 站点名称 |
| line_name | TEXT | 否 | 否 | 是 | 所属线路名称 |
| sequence_num | INTEGER | 否 | 否 | 否 | 线路内的序列号 |
| latitude | REAL | 否 | 否 | 否 | 站点纬度坐标 |
| longitude | REAL | 否 | 否 | 否 | 站点经度坐标 |
| status | TEXT | 否 | 否 | 否 | 运营状态,默认值'normal' |
flow_data表是客流数据的存储核心,记录每个站点按小时粒度采集的客流量信息,同时附带时间维度特征和气象标记。flow_data表数据表结构如表5.3所示。
表5-3 flow_data表结构
|-------------|-----------|------|------|------|-------------------|
| 表名 | flow_data |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 记录唯一标识,自增主键 |
| station_id | INTEGER | 否 | 是 | 是 | 外键,引用stations表的id |
| timestamp | TIMESTAMP | 否 | 否 | 是 | 数据采集时刻 |
| flow_count | INTEGER | 否 | 否 | 是 | 该时刻客流量(人次) |
| hour | INTEGER | 否 | 否 | 否 | 采集小时(0-23) |
| minute | INTEGER | 否 | 否 | 否 | 采集分钟(0-59) |
| day_of_week | INTEGER | 否 | 否 | 否 | 星期几(0-6) |
| is_holiday | INTEGER | 否 | 否 | 否 | 是否节假日,默认值0 |
| weather | TEXT | 否 | 否 | 否 | 天气状况描述 |
predictions表用于持久化LSTM模型生成的客流预测结果,每条记录对应一个站点在某一未来时刻的预测客流值,同时存储置信度和模型版本信息,便于预测结果的回溯核查。predictions表数据表结构如表5.4所示。
表5-4 predictions表结构
|----------------|-----------|------|------|------|-------------------|
| 表名 | predictions |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 预测记录唯一标识,自增主键 |
| station_id | INTEGER | 否 | 是 | 是 | 外键,引用stations表的id |
| predicted_time | TIMESTAMP | 否 | 否 | 是 | 预测目标时刻 |
| predicted_flow | INTEGER | 否 | 否 | 是 | 预测客流量(人次) |
| confidence | REAL | 否 | 否 | 否 | 预测置信度 |
| model_version | TEXT | 否 | 否 | 否 | 生成该预测的模型版本号 |
alerts表用于存储系统根据客流预测结果自动触发的拥堵预警记录,记录预警等级、预警消息内容、关联的预测客流值以及预警是否已经推送。alerts表数据表结构如表5.5所示。
表5-5 alerts表结构
|----------------|-----------|------|------|------|-----------------------|
| 表名 | alerts |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 预警记录唯一标识,自增主键 |
| station_id | INTEGER | 否 | 是 | 是 | 外键,引用stations表的id |
| alert_level | TEXT | 否 | 否 | 否 | 预警等级(low/medium/high) |
| message | TEXT | 否 | 否 | 否 | 预警内容描述 |
| predicted_flow | INTEGER | 否 | 否 | 否 | 触发预警的预测客流值 |
| is_sent | INTEGER | 否 | 否 | 否 | 是否已推送,默认值0 |
| created_at | TIMESTAMP | 否 | 否 | 否 | 预警创建时间,默认当前时间 |
scheduling_advice表用于存储管理员通过DeepSeek模块生成的调度建议记录,关联生成该建议的用户和对应的站点名称,并记录建议的完整文本内容和类型标识。scheduling_advice表数据表结构如表5.6所示。
表5-6 scheduling_advice表结构
|----------------|---------|------|------|------|----------------|
| 表名 | scheduling_advice |||||
| 字段名 | 数据类型 | 是否主键 | 是否外键 | 是否非空 | 说明 |
| id | INTEGER | 是 | 否 | 是 | 调度建议唯一标识,自增主键 |
| user_id | INTEGER | 否 | 是 | 否 | 外键,引用users表的id |
| station_name | TEXT | 否 | 否 | 否 | 关联的站点名称 |
| advice_content | TEXT | 否 | 否 | 否 | 建议的完整文本内容 |
| advice_type | TEXT | 否 | 否 | 否 | 建议类型标识 |
从表5.1至表5.6可以看出,本系统数据库设计遵循关系数据库的规范化原则,每张表均设有自增整型主键,表与表之间的关联通过显式外键约束实现。flow_data表、predictions表和alerts表通过station_id字段与stations表建立一对多关系,任意一条客流记录、预测结果或预警信息都必须对应一个已存在的站点;scheduling_advice表通过user_id字段与users表建立一对多关系。这种设计确保了数据库层面的引用完整性,避免出现孤立的子记录,同时为后续功能扩展预留了清晰的数据关联路径。
第 6 章 系统 实现
6.1 开发环境
本系统采用浏览器/服务器(B/S)结构体系,后端基于Python Flask框架开发,数据库选用SQLite轻量级关系型数据库,深度学习模型基于TensorFlow 2.15构建,大语言模型集成DeepSeek Chat API。系统开发环境的具体配置如表6.1所示。
表6-1 系统开发环境
|---------------------------------|------------------------------|
| 硬件环境 | 软件环境 |
| CPU:Intel Core i7-12700H 2.7GHz | 操作系统:Windows 11 22H2 |
| 内存:16 GB DDR5 | 数据库:SQLite 3.40.0 |
| 硬盘:512 GB SSD | Python版本:3.10.11 |
| | Flask版本:3.0.0 |
| | TensorFlow版本:2.15.0 |
| | 浏览器:Chrome 120.0 |
| | 开发工具:Visual Studio Code 1.85 |
| | 大模型API:DeepSeek Chat V1 |
6.2 功能模块实现
本节选取用户登录、实时客流热力图、站点客流预测、DeepSeek智能调度以及调度预案模拟五个核心功能,从前端界面与后端逻辑两个角度描述其实现过程。
6.2.1 用户登录功能
登录功能是系统安全访问的首要关卡。用户通过登录页输入用户名和密码后,前端使用AJAX将表单数据以POST方式提交至/auth/login端点。为提升交互体验,密码输入框右侧设置了显隐切换按钮,点击时JavaScript动态切换输入框type属性在password与text之间转换。
后端接收到请求后,从表单中提取username和password字段。验证逻辑封装在User模型类的verify静态方法中。该方法首先从数据库中按用户名查询用户记录,若记录不存在则直接返回None;若存在,则调用Werkzeug提供的check_password_hash函数,将用户提交的明文密码与数据库中存储的bcrypt哈希值进行比对。验证通过后,更新该用户的last_login字段,并将用户ID、用户名和角色写入Flask会话。根据角色类型,管理员重定向至管理端仪表盘,普通用户重定向至乘客端页面。验证失败时,Flash消息提示错误并重新渲染登录页。
实现会话持久化的核心代码片段如下:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| user = User.verify(username, password) if user: session'user_id' = user'id' session'username' = user'username' session'role' = user'role' flash(f'欢迎回来,{user"username"}!', 'success') if user'role' == 'admin': return redirect(url_for('admin_dashboard')) return redirect(url_for('user_dashboard')) else: flash('用户名或密码错误', 'danger') return redirect(url_for('login_page')) |
实现效果如图6.1所示。界面采用深色渐变背景,中央放置半透明卡片式登录表单。顶部显示地铁图标和"欢迎回来"标题,下方依次为用户名输入框、带显隐切换按钮的密码输入框和蓝色渐变登录按钮。卡片底部提供"立即注册"和"返回首页"链接入口。
图6-1 用户登录界面
6.2.2 实时客流热力图功能
热力图是乘客端页面最核心的可视化模块。页面加载时,前端Leaflet地图初始化在北京中心坐标(39.9042, 116.4074),缩放级别设为11级,底层瓦片使用OpenStreetMap提供的地图服务。随后发起fetch请求调用/api/user/current_flow接口。
后端接口遍历全局DataLoader实例中的站点列表,为每个站点调用_get_flow_for_station方法获取当前模拟客流值。根据客流值与拥堵阈值的比较,将站点状态分为smooth(客流<3000)、normal(3000-8000)和crowded(>8000)三档。接口返回JSON数组,每个元素包含站点名称、客流量、状态标记及经纬度坐标。前端接收到数据后,迭代清除地图上已有的CircleMarker图层,然后为每个站点重新绘制圆形标记。标记半径与客流量正相关(最小值8像素,最大值20像素),填充颜色绿色对应畅通、橙黄色对应正常、红色对应拥堵,填充透明度设为0.5以保证底图可见。每个标记绑定Popup弹出窗,显示站点名称和精确客流量。
右侧站点排行面板同步更新,按客流量降序排列前20个站点,每个站点条目以进度条形式直观展示拥挤程度,点击条目触发该站点的预测数据加载。代码如下:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| stations = data_loader.get_station_list() station_flows = \[\] for station in stations:50: flow = data_loader._get_flow_for_station(station) status = 'crowded' if flow > 8000 else ('normal' if flow > 3000 else 'smooth') station_flows.append({'name': station, 'flow': flow, 'status': status}) return jsonify({'success': True, 'data': { 'update_time': datetime.now().strftime('%Y-%m-%d %H:%M:%S'), 'total_flow': sum(s'flow' for s in station_flows), 'stations': station_flows }}) |
实现效果如图6.2所示。页面分为左右两栏。左侧为Leaflet地图,地图上散布着大小不一的彩色圆点,红点集中在市中心区域表示拥堵站点,绿点分布在外围表示畅通站点。右侧为站点客流排行列表,每个条目左侧有颜色条和客流量数字,顶部统计卡片显示当前总客流、畅通站点数、正常站点数和拥堵站点数。
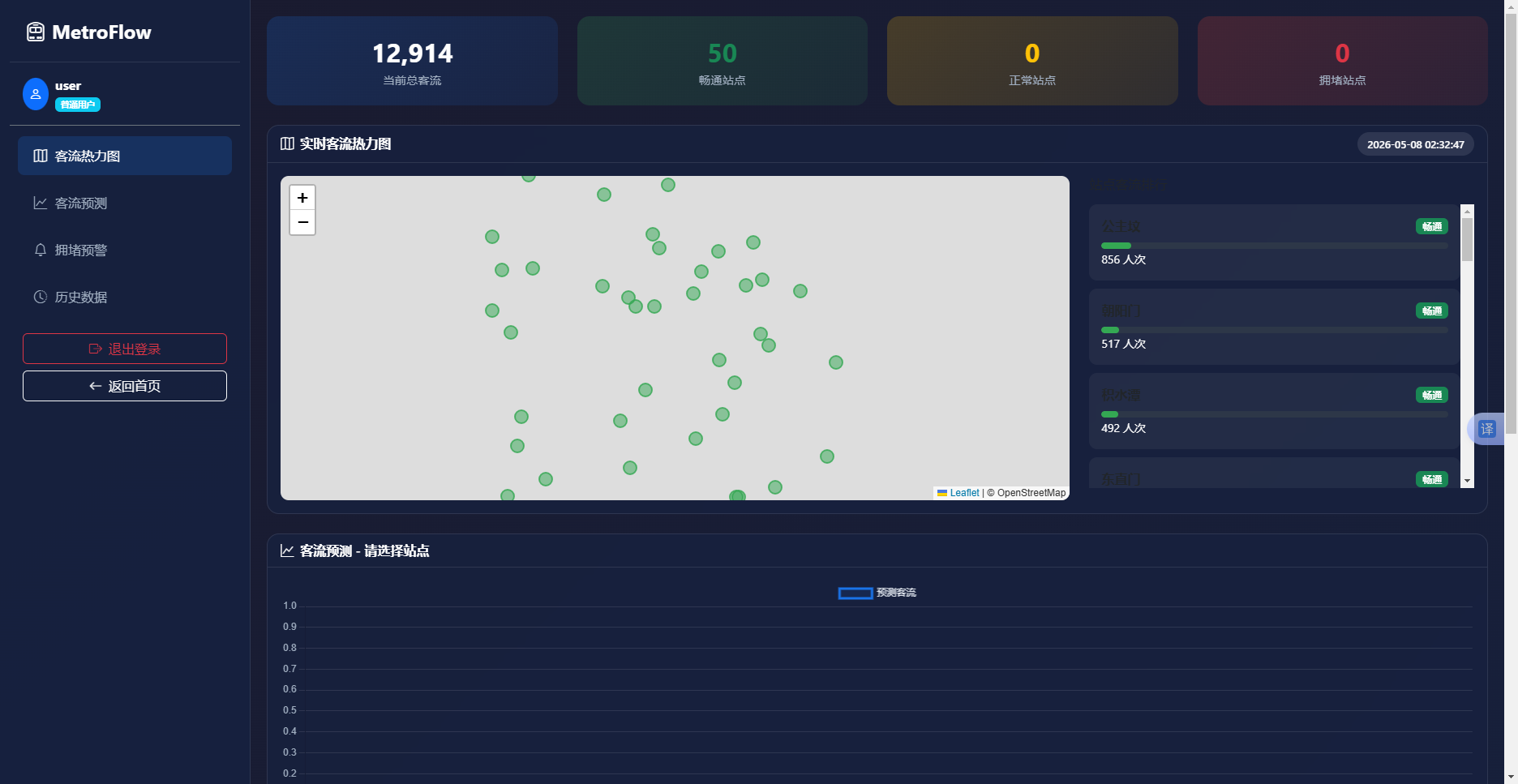
图6-2 实时客流热力图界面
6.2.3 站点客流预测功能
用户选择具体站点后,预测模块开始工作。前端构造请求URL/api/user/prediction/站名?hours=24,后端解析小时参数,调用预测逻辑为指定站点生成未来时段的客流推演值。
考虑到实际部署环境可能不具备GPU,本模块设计了双层预测策略。当TensorFlow可用且已训练模型存在时,调用LSTM模型的predict方法,输入站点历史客流序列进行多步滚动预测。当TensorFlow不可用时,自动切换至简化预测算法。该算法根据当前小时向未来步进,深层逻辑嵌入了地铁运营的真实客流规律:定义get_flow_factor函数按小时返回客流因子,早高峰7至9点因子设为1.5,晚高峰17至19点因子设为1.4,非运营时段因子低至0.03;同时根据推算出的星期几在工作日和周末之间切换调节系数。最终预测值由基础客流量、小时因子、星期因子和随机噪声四者乘积取整得到。
前端接收预测数组和时间标签后,将数据灌入已初始化的Chart.js折线图对象,蓝色填充区域呈现出未来24小时的客流起伏趋势。代码如下:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| for i in range(hours): target_hour = (current_hour + i) % 24 factor = get_station_factor(target_hour) weekday = (now.weekday() + i // 24) % 7 if weekday < 5: weekday_factor = 1.1 if target_hour in 8,9,17,18,19 else 1.0 else: weekday_factor = 0.8 if target_hour in 10,11,14,15,16 else 0.9 noise = np.random.uniform(0.92, 1.08) prediction = int(base_flow * factor * weekday_factor * noise) predictions.append(max(100, prediction)) |
实现效果如图6.3所示。图表上方显示当前选中站点名称。折线图横轴为24小时时间刻度,纵轴为客流量。曲线呈现明显双峰形态,波峰处标注数值,图例注明蓝色区域为预测客流。曲线下方为拥堵预警卡片,显示预警等级、预警消息和DeepSeek生成的出行建议文本。
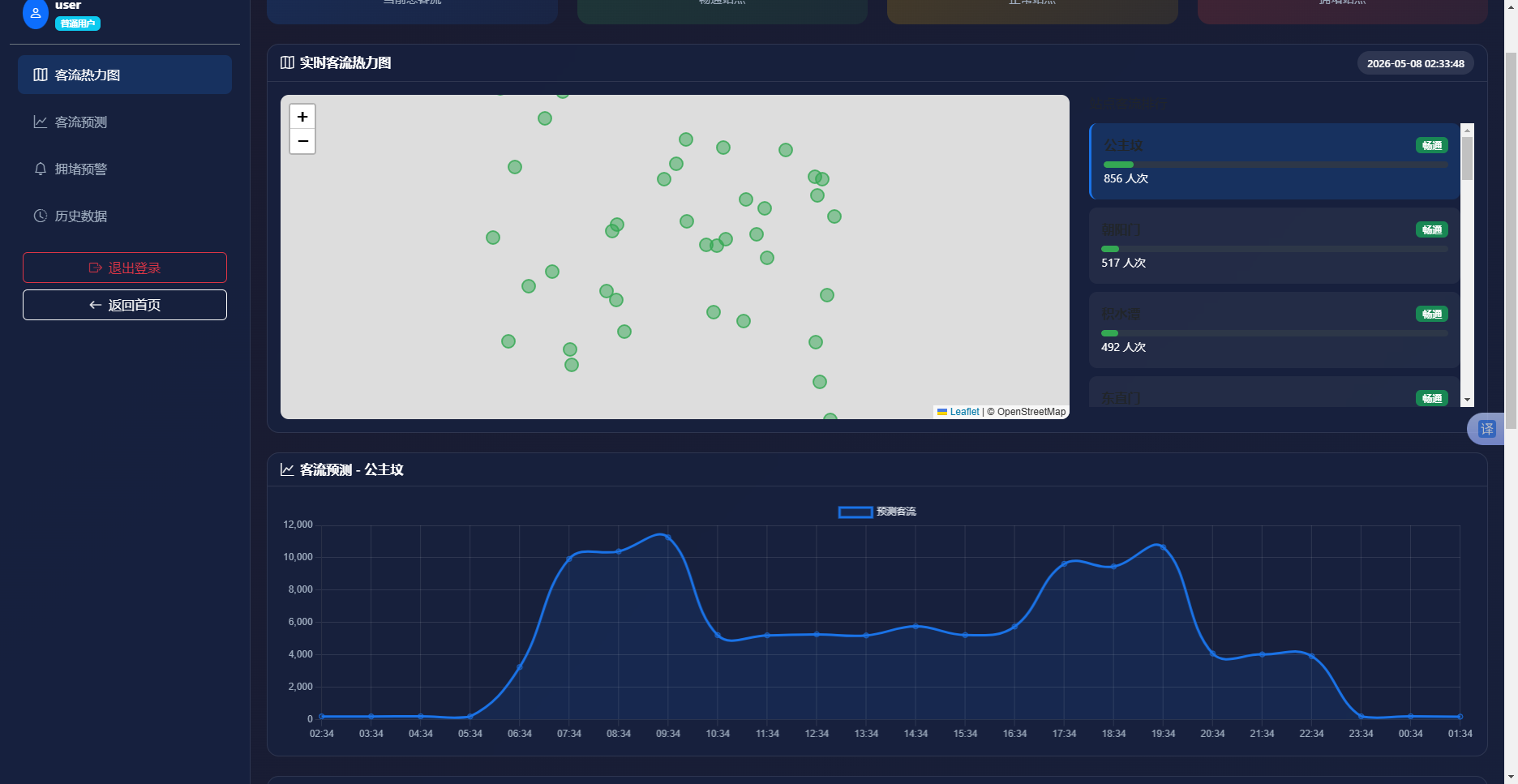
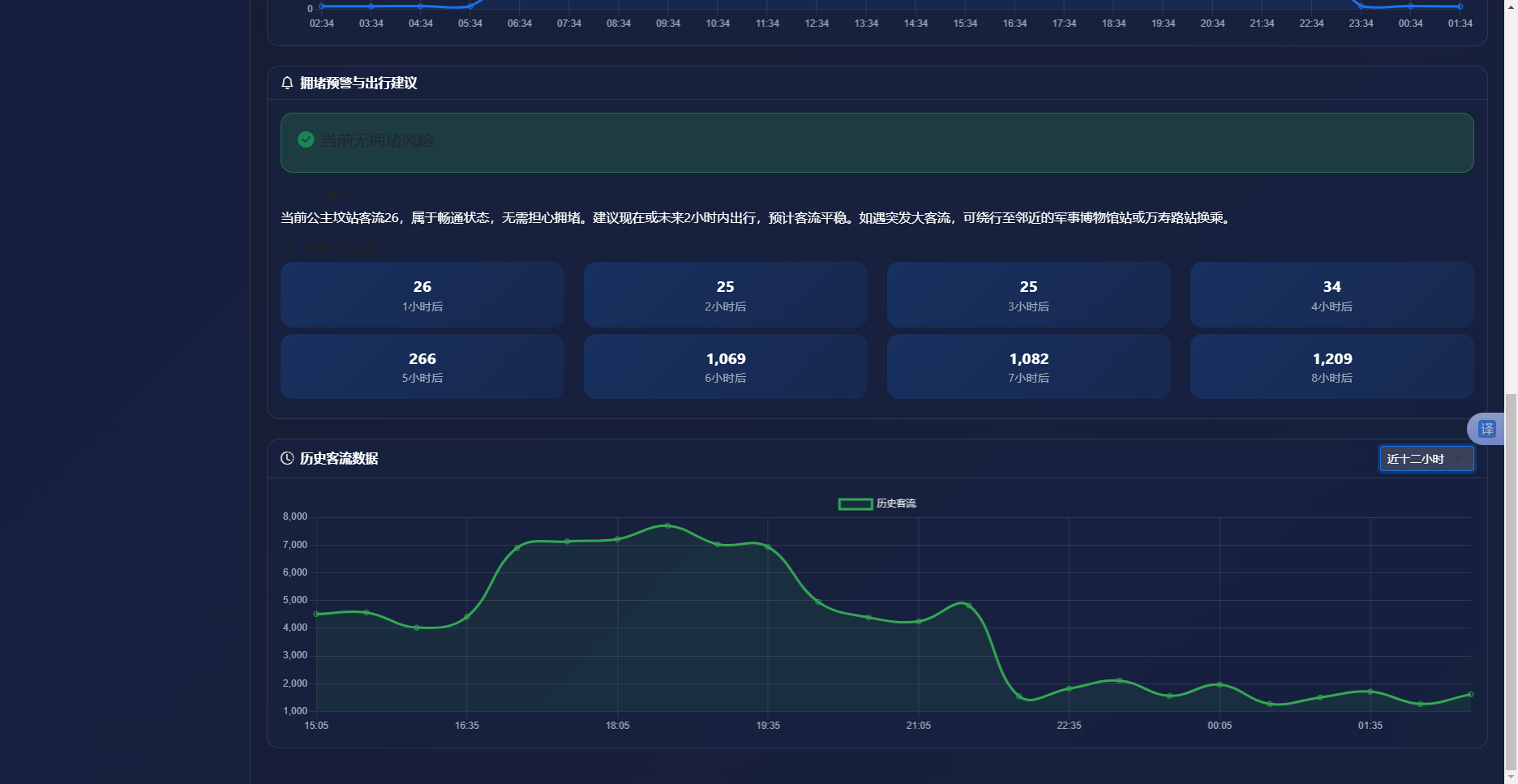
图6-3 站点客流预测曲线界面
6.2.4 DeepSeek智能调度功能
管理端页面设置"生成调度策略"按钮,点击后前端收集拥堵阈值参数,以POST请求发送至/api/admin/scheduling_suggest。后端收到请求后,首先调用DataLoader获取站点列表和各站客流模拟值,按阈值将站点划分为拥堵、正常和畅通三类。
调度建议的生成采用两阶段策略。第一阶段为规则引擎,系统根据拥堵站点数量、当前小时是否处于早晚高峰等硬性条件,自动产出一批基础建议条目。若拥堵站点超过5个,生成"增加运力"建议并指明具体站点名称;若当前处于早晚高峰时段,生成"高峰预警"建议并提示启用高峰运行图。第二阶段调用DeepSeek大模型进行深度分析。构造提示词将当前客流统计、预测峰值和拥堵阈值作为分析素材,设定系统角色为地铁调度专家,要求模型输出含有风险等级、态势分析和结构化建议列表的JSON。为防止API调用失败,系统内置fallback机制,当DeepSeek不可用或返回格式异常时,直接返回规则引擎生成的建议结果。
前端接收到包含status、risk_level、suggestions等字段的响应后,将其渲染为带颜色编码的卡片列表。高优先级建议以红色左边框和"高"标签标注,中优先级以橙黄色标注,低优先级以绿色标注。每条建议同时展示预期效果和实施方法。代码如下:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| if len(crowded_stations) > 10: status, risk_level = 'critical', '高' elif len(crowded_stations) > 5: status, risk_level = 'warning', '中' else: status, risk_level = 'normal', '低' suggestions.append({ 'type': '增加运力', 'description': f'建议在{", ".join(s\["name" for s in crowded_stations:3])}等站点增加发车频次', 'priority': '高', 'expected_effect': f'预计可疏散{sum(s\["flow" for s in crowded_stations]) * 0.1:.0f}人次', 'implementation': '增加发车班次,缩短发车间隔' }) |
实现效果如图6.4所示。界面顶部为拥堵阈值输入框和"生成调度策略"按钮。下方左侧显示全网态势统计卡片,右侧展示调度建议列表。每条建议卡片左侧有优先级颜色条,标题为建议类型,正文包含描述、预期效果和实施建议,右上角标注优先级标签。
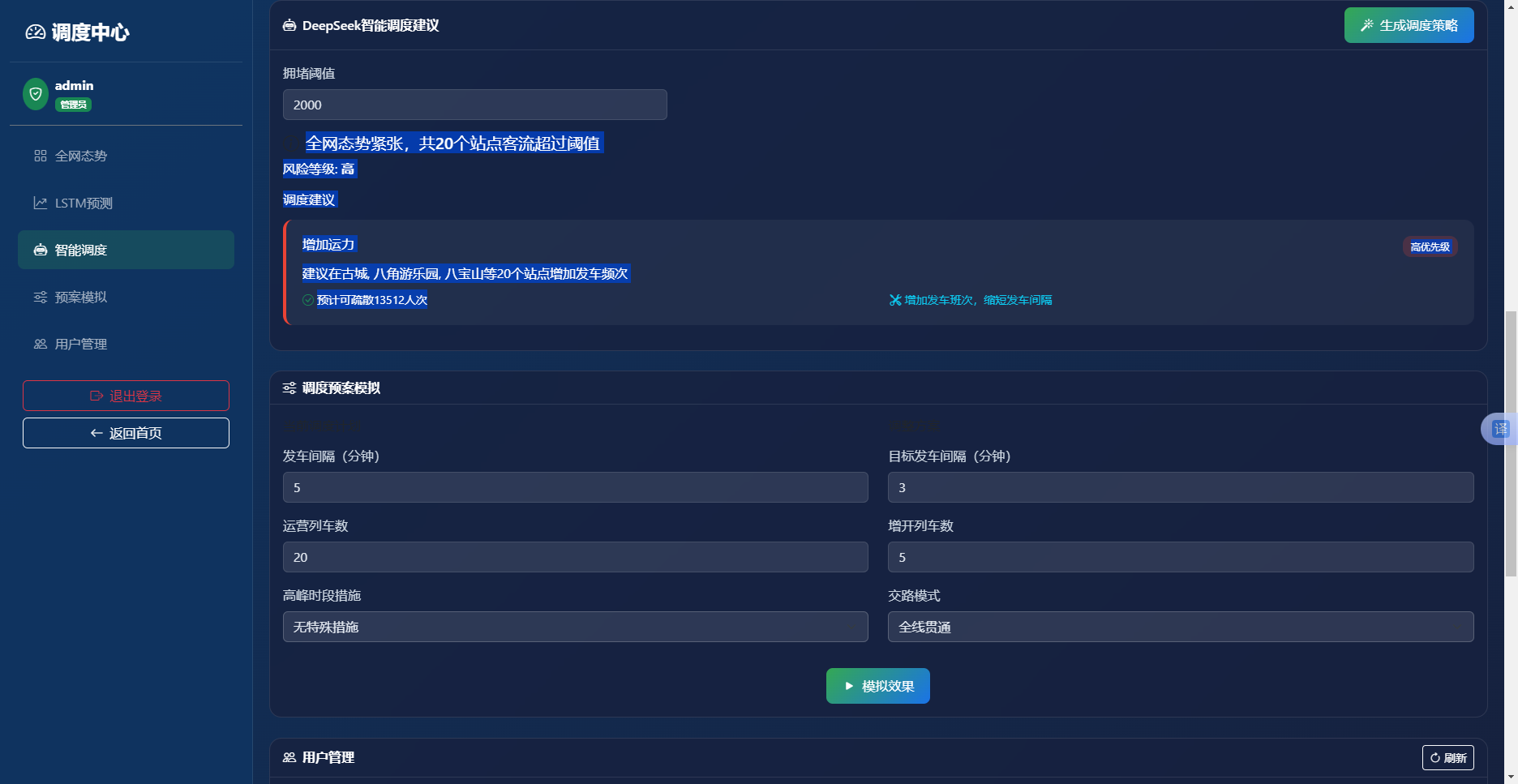
图6-4 DeepSeek智能调度建议界面
6.2.5 调度预案模拟功能
预案模拟模块允许调度员调整发车间隔、增开列车数和交路模式等参数后,点击"模拟效果"按钮查看调整前后的对比效果。前端收集当前调度计划参数和目标调整方案参数,通过JavaScript在客户端完成模拟计算。
模拟算法基于运力弹性系数设计。核心逻辑为:计算当前发车间隔与目标间隔的比值,运力变化量等于比值减1乘以100%;等待时间变化量与运力变化方向相反;成本变化按发车间隔调整和增开列车数两个维度分别估算百分比,再求和。交路模式的影响以固定经验值叠加:大小交路模式运力增加15%但成本降低10%,混合交路运力增加10%但成本上升5%。各项风险分析条目同样由规则生成,例如增开列车超过5列时提示备用列车须充足,目标间隔低于3分钟时提示司机排班须到位。
计算结果呈现为运力变化、等待时间变化、成本变化三项指标,每项指标有正负百分数和对应的红绿颜色标识。下方列出风险分析条目和综合建议。确认方案后点击"下发调度预案",前端调用/api/admin/dispatch接口将计划以JSON格式提交后端,后端记录预案编号和时间戳并返回确认信息。代码如下:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| const intervalRatio = currentInterval / targetInterval; capacityChange += Math.round((intervalRatio - 1) * 100); waitTimeChange -= Math.round((1 - 1/intervalRatio) * 100); costChange += Math.round((intervalRatio - 1) * 50); if (routeMode === 'small') { capacityChange += 15; costChange -= 10; riskAnalysis.push('大小交路需要乘客换乘配合'); } |
实现效果如图6.5所示。界面分为左右两栏,左侧为当前调度计划输入区,右侧为目标调整方案输入区。下方为模拟结果面板,以表格形式展示运力变化、等待时间变化、成本变化三大指标,正向变化标绿、负向变化标红。风险分析以项目符号列出。底部为"下发调度预案"按钮。
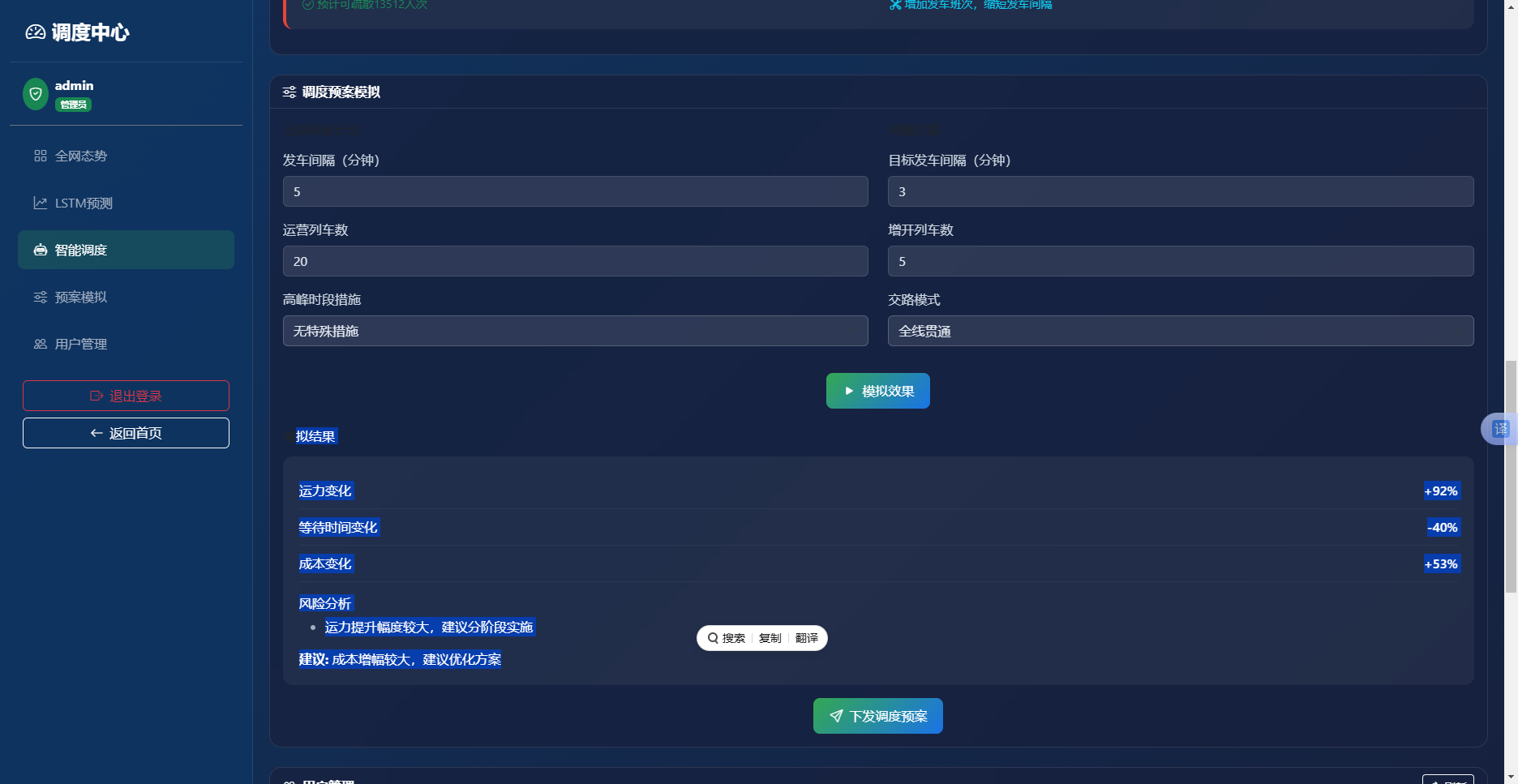
图6-5 调度预案模拟界面