源码版本:1.7.15
总结
优势
- 代码精简,不依赖于外部库
- 内存按需分配,整体占用低(但malloc成为瓶颈)
- 成熟,长期稳定,兼容性好。
性能低的原因
- 递归解析
遇到深层嵌套的 JSON(如 {"a":{"b":{"c":...}}})时,可能导致栈溢出或 解析速度下降。其中,cJSON_parse、cJSON_Delete和cJSON_print内部都使用了递归处理JSON字符串。
为什么递归解析有性能问题?
- 函数调用开销
- 递归的调用链是 非连续内存访问,导致 CPU 缓存命中率低。迭代解析通常按顺序处理数据,更符合局部性原理(Locality),提高缓存效率。
- 动态内存分配
cJSON 使用了动态内存分配来管理 JSON 数据结构的内存,这涉及到频繁的内存分配和释放操作。
- 数据结构和算法设计(核心)
cJSON 的算法设计不够高效,导致性能较低。例如,在查找和访问 cJSON 对象的属性时,cJSON 使用线性搜索的方式,而不是更快速的数据结构(如哈希表)进行查找。比如cJSON_GetArraySize获取数组Size时,直接遍历了一遍链表,而没有记录该值。
优化方案
对应上面3条。
- 迭代(非递归)解析:用自定义栈结构代替 系统调用栈,手动管理解析状态。通过循环逐步处理数据,而不是嵌套调用函数。
- 使用内存池
- 使用高效的数据结构,如哈希表
优秀的设计
string类型估算长度,没有用strlen,而是估算(高估)。parse_string
优化示例1
读取一个10w规则的json文件,原处理方式:
c
int array_size = cJSON_GetArraySize(array); // 获取数组大小
for (int i = 0; i < array_size; i++) {
cJSON *item = cJSON_GetArrayItem(array, i); // 获取每个对象(优化点)
// 处理每个元素
cJSON *name = cJSON_GetObjectItem(item, "name");
cJSON *age = cJSON_GetObjectItem(item, "age");
............
}优化思路:外层不适用cJSON_GetArrayItem,而是直接通过 next 指针移动,避免重复从头遍历。
c
cJSON *array = cJSON_GetObjectItem(root, "data");
if (array && cJSON_IsArray(array)) {
cJSON *item = array->child; // 获取第一个元素
int index = 0;
while (item) {
// 处理当前元素
printf("处理第 %d 个元素\n", index);
// 直接移动到下一个元素(O(1)操作)
item = item->next;
index++;
}
}优化示例2
使用手动内存管理模式,内存池替代malloc。
数据存储方式
cJSON采用双向链表来存储数据。JSON的结构可以理解成无序的、可嵌套的key-value键值对集合。
其访问方式很像一颗树,每一个节点可以有兄弟节点,通过next/prev指针来查找;每个节点也可以有孩子节点,通过child指针来访问,进入下一层。注意只有节点是对象或数组时才可以有孩子节点。
cJSON结构如下:
c
typedef struct cJSON
{
struct cJSON *next;
struct cJSON *prev;
struct cJSON *child;
int type;
char *valuestring;
int valueint;
double valuedouble;
char *string;
} cJSON;从数据指向来说,next和pre指向兄弟节点,child指向子节点。
从数据存储来说,string表示key名,valuestring,valueint,valuedouble表示存储的内容。
cJSON类型如下:
c
#define cJSON_Invalid (0)
#define cJSON_False (1 << 0)
#define cJSON_True (1 << 1)
#define cJSON_NULL (1 << 2)
#define cJSON_Number (1 << 3)
#define cJSON_String (1 << 4)
#define cJSON_Array (1 << 5)
#define cJSON_Object (1 << 6)
#define cJSON_Raw (1 << 7) /* raw json */
#define cJSON_IsReference 256
#define cJSON_StringIsConst 512重点说几个特殊的类型:
- cJSON_Raw:cJSON_Raw类型表示JSON节点中的原始字符串数据,不进行任何转义或解析。它将字符串视为一个整体,不对其内容进行处理。
- cJSON_IsReference表示该项是一个引用类型,创建时不分配内存,同样不需要手动释放。
- cJSON_StringIsConst表示该项是一个字符串常量,如果是常量,也不需要在这里释放。
内存组织关系
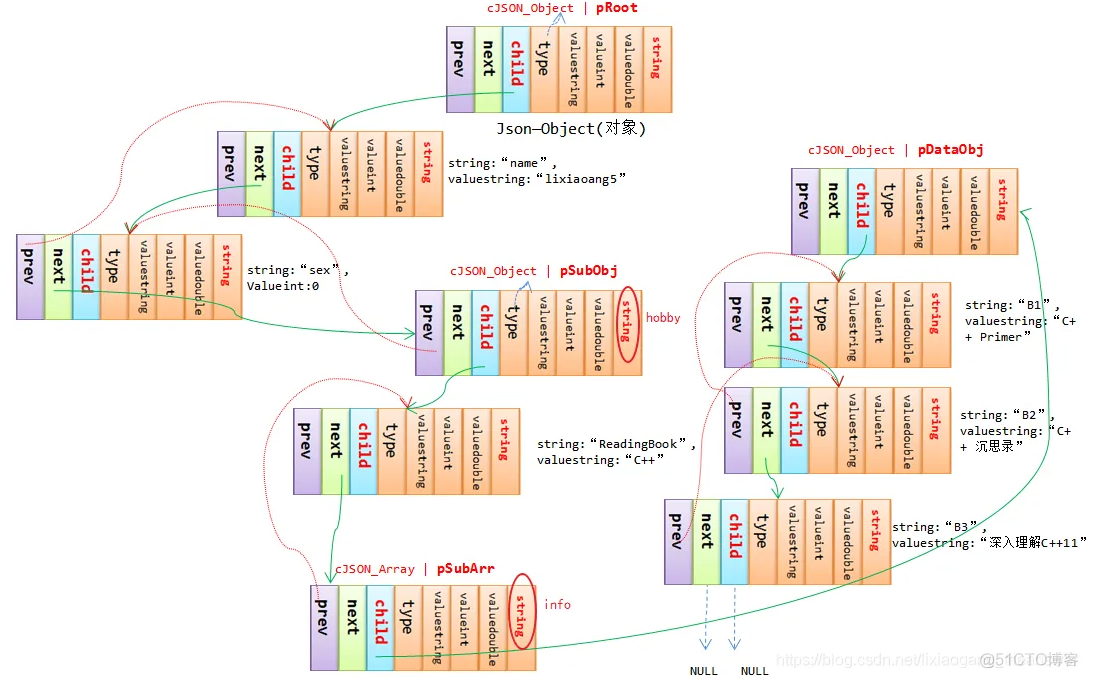
每使用cJSON_Creatxxx创建对应类型都将被分配一个cJSON结构,配合下面这个例子应该可以很好的理解cJSON数据存储的组织关系:
json
{
"name":"lixiaogang5",
"sex":0,
"hobby":{
"ReadingBook":"C++",
"info":[
{
"B1":"C++ Primer",
"B2":"C++ 沉思录",
"B3":"深入理解C++11"
}
]
}
}- 最外层的 cJSON 对象包含了
"name"、"sex"、"hobby"通过next和pre依次连接。 "hobby"包含了两个元素"ReadingBook"、"info"通过next和pre字段依次连接。"info"包含了"B1"、"B2"和"B3"通过next和pre字段依次连接。"hobby"的child指针指向"ReadingBook","info"的child指针指向"B1"。
指向关系如下(网图侵删):
内存管理
默认内存管理
默认的内存处理函数为malloc和free,赋值给全局变量global_hooks。
c
#define internal_malloc malloc
#define internal_free free
#define internal_realloc realloc
static internal_hooks global_hooks = { internal_malloc, internal_free, internal_realloc };cJSON_InitHooks()是Hook内存管理函数。如果参数为NULL,则使用默认的内存管理,也就是malloc/free。默认方式管理内存不需要调用该函数,只有更改申请释放内存的函数时手动调用,并将Hook传进去即可。
c
CJSON_PUBLIC(void) cJSON_InitHooks(cJSON_Hooks* hooks)手动内存管理
c
typedef struct cJSON_Hooks {
void *(CJSON_CDECL *malloc_fn)(size_t sz);
void (CJSON_CDECL *free_fn)(void *ptr);
} cJSON_Hooks;
// 自己实现my_malloc和my_free
static cJSON_Hooks my_hooks = {
my_malloc,
my_free
};
cJSON_InitHooks(&my_hooks);cJSON_New_Item()
创建新的对象、数组时都会调用cJSON_New_Item(),并使用函数指针指向默认(或手动指定的)内存分配函数申请内存,返回值类型为cJSON*。
cJSON_Delete()
cJSON_Delete()用来在cJSON_Parse()之后释放内存,删除cJSON实体和所有子实体,这里使用了递归的方法。注意两个宏(也是cJSON的两种类型):
c
#define cJSON_IsReference 256
#define cJSON_StringIsConst 512cJSON_IsReference表示该项是一个引用类型,就是一个指针,指向另一个项,也就是说该类型的项在创建时是没有分配内存的,所以这里自然也不应该去释放。
cJSON_StringIsConst表示该项是一个字符串常量,如果是常量,也不需要在这里释放。
我们知道cJSON采用双向链表来存储数据,cJSON_Delete()从根节点开始,首先将当前结点的下一个结点保存在变量next中,如果当前结点不是引用类型且具有子结点,则递归调用 cJSON_Delete 函数来删除子结点。最后,使用全局钩子函数释放当前结点的内存,并将 item 指针更新为下一个结点,以便继续循环直到所有结点都被删除。
比如下面json,当使用cJSON_Delete()时,结点释放的顺序应为"John" -> "age" ->"city" -> "email" -> "address"
json
{
"name": "John",
"age": 30,
"address": {
"city": "New York",
"email": "a.com"
}
}注意:必须从整个json的根节点开始调用,否则会造成这个节点的所有父节点和兄弟节点没有被释放,可能导致意想不到的问题。
cJSON_malloc()和cJSON_free
这两个函数就是封装了一层,内部调用的还是默认/手动更改的内存管理函数。
c
CJSON_PUBLIC(void *) cJSON_malloc(size_t size)
CJSON_PUBLIC(void) cJSON_free(void *object)核心解析函数parse_value()
parse_value 负责将 JSON 字符串解析为对应的数据结构。在解析过程中,parse_value 函数会调用其他辅助函数,例如 parse_string、parse_number、parse_object、parse_array 等,以递归地解析 JSON 字符串的不同部分。它会根据 JSON 字符串的结构和内容,构建一个相应的 cJSON 数据结构。
c
static cJSON_bool parse_value(cJSON * const item, parse_buffer * const input_buffer)有一个和解析相关数据结构需要说明一下:
c
typedef struct {
const unsigned char *content;
size_t length;
size_t offset;
size_t depth; /* How deeply nested (in arrays/objects) is the input at the current offset. */
internal_hooks hooks;
} parse_buffer;parse_buffer 结构体是在 cJSON 库中用于解析 JSON 数据的上下文结构。它包含了解析过程中所需的各种信息和状态。
content:指向待解析的 JSON 数据的指针。它是一个指向无符号字符(unsigned char)类型的常量指针,指向 JSON 数据的起始位置。length:表示待解析的 JSON 数据的长度,即包含的字符数。offset:表示解析过程中的当前偏移量,即解析器当前所处理的位置在输入缓冲区中的偏移量。depth:表示当前解析的 JSON 数据的嵌套深度,即当前解析器在数组和对象中的嵌套层级。hooks:存储 cJSON 库内部的钩子(hook)函数,用于定制内存管理和其他特定行为。
通过使用 parse_buffer 结构体,cJSON 库能够在解析过程中跟踪和管理解析的位置、数据长度以及嵌套深度等信息。
parse_string()
该函数解析cJSON类型为字符串的项,整体上分为两个步骤,第一步先估算输出字符串的长度(并且是高估),第二步将输入的json格式的字符串自动处理为utf-8格式。
第一步:估算输出字符串的长度
估算输出字符串长度的方式是遍历输入字符串,遇到转义字符则自动跳过,并且skipped_bytes++,最后allocation_length的值也是减掉skipped_bytes之后的。
在看到这里的时候,我有两个疑问:一个是为什么要估算?第二个是为什么要高估?
为什么要高估很好理解,是为了防止分配的内存空间太小导致缓冲区溢出。
那为什么要估算呢,得不出实际值吗,直接使用strlen(input_buffer->content)不就可以了吗。
事实上,直接使用strlen是可以的,都是遍历一遍输出字符串,时间复杂度都是O(1),只不过这个值会远大于实际的输出字符串的长度,造成内存的浪费,而使用估算的值可以最小限度的避免这种情况。
举个例子:
name的key值如下,其中\u6295\u8d44\u7406\u8d22为unicode字符集"投资理财"。使用strlen计算的值为34,而估算的值allocation_length为31,实际输出值的长度为22。
c
char *str = "{\"name\":\"HelloWorld\\u6295\\u8d44\\u7406\\u8d22\"}";
strlen("HelloWorld\\u6295\\u8d44\\u7406\\u8d22\") // 34
allocation_length // 31
strlen("HelloWorld投资理财") // 22而在parse_string中计算输出字符串近似大小的原因为:
在计算过程中,代码假设每个转义序列都需要额外的一个字符位置来存储转义后的字符。但事实上,并非所有的转义序列都会扩展为一个单个字符。例如,\u 开头的转义序列表示一个 Unicode 字符,可能需要多个字节来进行编码,比如"\u6295\u8d44"表示投资理财,一旦出现\uXXXX,那么估值就会增大,所以这个长度是一个高估值。
因此,第一遍遍历计算的 allocation_length 是一个较大的估计值,以确保在后续的字符串解析过程中不会发生内存溢出。这种策略在处理字符串中包含大量转义字符的情况下是有效的,因为它提供了足够的空间来存储转义后的字符。
第二步:将输入的json格式的字符串自动处理为utf-8格式
从输出字符串头开始遍历,依次将结果赋值到输出字符串中,如果当前字符不是转义字符,则直接使用 *output_pointer++ = *input_pointer++;完成赋值。如果是转义字符,则需要特殊处理。处理完最后在输出字符串添加'\0',并且填充该项。
处理转义字符的时候需要特殊说明下,如果是普通的转义字符根据\后面的值进行复制,如果utf-16编码的转义字符,也就是\uXXXX这种,则需要转换成utf-8。
**utf16_literal_to_utf8()**的函数实现这里不贴了,该函数的目标是处理UTF-16编码的输入,并将其转换为UTF-8编码的输出。
其中有一种特殊情况时,并且当遇到代理项时,需要特殊处理,将代理项转换为对应的Unicode代码点,然后再进行后续的UTF-8编码转换。代码量不大,但是和字符编码相关的细节比较多,感兴趣的可以自行去看源码。下面补充两个概念,有助于看这部分代码。
UTF-16 Surrogate Pair(代理项)
一种编码机制,用于表示Unicode字符集中超出基本多语言平面(BMP)的字符。
Unicode字符集的编码空间被划分为17个平面(Plane),其中基本多语言平面(BMP)占用了第0平面(Plane 0),包含了大部分常用的字符,范围是U+0000至U+FFFF。然而,Unicode字符集中还有许多字符超出了BMP的范围。
为了表示超出BMP范围的字符,Unicode采用了代理项的编码方案。代理项是由两个UTF-16编码单元组成的序列,其中第一个编码单元称为高位代理项(High Surrogate),范围是0xD800至0xDBFF,而第二个编码单元称为低位代理项(Low Surrogate),范围是0xDC00至0xDFFF。
代理项的组合方式是将高位代理项的10个有效比特与低位代理项的10个有效比特进行组合,得到20个比特,形成一个20位的Unicode代码点。然后通过以下公式计算Unicode代码点:
Unicode Code Point = ((High Surrogate - 0xD800) << 10) + (Low Surrogate - 0xDC00) + 0x10000
这样,通过代理项的组合,可以表示范围为U+10000至U+10FFFF的Unicode字符。
代理项的使用在UTF-16编码中非常重要,特别是在处理包含Emoji表情等辅助平面字符的文本时。在使用UTF-16编码的系统中,需要正确地处理代理项,以确保能够正确表示和处理超出BMP范围的字符。
字符编码
Unicode 是字符集,而 UTF-16 是一种针对 Unicode 字符的编码方式。Unicode 定义了字符的标识符,而 UTF-16 定义了如何将这些字符编码为字节序列。
举例:\uXXXX 是用于表示 UTF-16 编码中的 Unicode 字符编码的转义序列,其中 XXXX 是一个四位的十六进制数。
在UTF-8编码中,常见的汉字通常由3个字节表示。然而,某些较为罕见的汉字以及一些生僻字可能需要4个字节来表示,比如上面例子中的"投资理财",每一个汉字都占
parse_number()
c
static cJSON_bool parse_number(cJSON * const item, parse_buffer * const input_buffer)cJSON处理number的方式比较简单,按位取,直接放到临时的buffer中,然后调用c库函数strtod转成double类型。
然后更新type的值,以及input_buffer->offset。
parse_array()
c
static cJSON_bool parse_array(cJSON * const item, parse_buffer * const input_buffer)分析解析数组的源码之前,看一个宏定义,cJSON限制了解析深度的值:
c
#ifndef CJSON_NESTING_LIMIT
#define CJSON_NESTING_LIMIT 1000
#endif挑几个关键的步骤说一下:
buffer_skip_whitespace()跳过空白字符,核心在于buffer_at_offset(buffer)[0] <= 32,我们知道ASCII 编码中的前 32 个字符是控制字符,用于控制文本的显示和传输。这些字符没有可打印的图形表示,而是用于控制设备和通信协议的行为。
每解析一个数组元素,就调用cJSON_New_Item()生成一个new_item,并加入到链表中,而current_item永远都指向最新的一个Item,便于快速的追加新元素。
而后每次都调用了parse_value来解析新的数组元素,由此可以看出,JSON格式中,数组内的元素可以是不同类型的。(实测验证此结论)
如果遇到']'则证明数组结束。
而item->child指向了head,也就是第一个Item。
parse_object()
c
static cJSON_bool parse_object(cJSON * const item, parse_buffer * const input_buffer)解析object和上面解析array的部分逻辑是类似的,这里只说一下不同的地方。
当循环开始后,先解析object的key值,因为key的类型是固定的string,所以调用parse_string来进行解析。
而后有一个操作是:
c
/* swap valuestring and string, because we parsed the name */
current_item->string = current_item->valuestring;
current_item->valuestring = NULL;因为parse_string()后,Item键的值被解析并存储在item->valuestring中,根据cJSON结构的定义,Key值应该存储在string中。
而当第二次解析的时候使用了parse_value(),这是因为value的值可能为各种类型,解析完后将结果存储在valuexxx中。
创建cJSON项
cJSON_NULL
cJSON_NULL类型的创建比较简单,调用cJSON_New_Item之后给item->type赋值即可。那么cJSON_NULL有什么用处呢,举个例子:
json
{
"name": null
}创建这个对象的代码如下:
c
// 创建一个空的 cJSON 对象
cJSON *root = cJSON_CreateObject();
// 创建一个表示 null 的 cJSON 对象
cJSON *nullValue = cJSON_CreateNull();
// 将 null 对象添加为 "name" 字段的值
cJSON_AddItemToObject(root, "name", nullValue); cJSON_False、cJSON_True
c
CJSON_PUBLIC(cJSON *) cJSON_CreateTrue(void)
CJSON_PUBLIC(cJSON *) cJSON_CreateFalse(void)
CJSON_PUBLIC(cJSON *) cJSON_CreateBool(cJSON_bool boolean)该函数实现和cJSON_CreateNull类似,没什么好说的。下面举个例子说明该类型的应用场景和创建方式。
例子1:
json
{
"status": true
}创建方式为:
c
// 创建一个空的 cJSON 对象
cJSON *root = cJSON_CreateObject();
// 设置 "status" 字段为 true
cJSON_AddItemToObject(root, "status", cJSON_CreateTrue());或者使用另一个接口也可以,而且更简洁:
c
cJSON *root = cJSON_CreateObject();
// 设置 "status" 字段为 true
cJSON_AddTrueToObject(root, "status");cJSON_AddTrueToObject()是一种合二为一的写法,内部先调用了cJSON_CreateTrue(),然后调用add_item_to_object将该item添加到另一个object
cJSON_Number
c
CJSON_PUBLIC(cJSON *) cJSON_CreateNumber(double num)cJSON_CreateNumber内部依然是调用cJSON_New_Item,不过对数字的处理考虑了超出范围情况,如果传入的数字大于等于INT_MAX,则将此值设置为INT_MAX,INT_MIN同理。
cJSON_String
c
static unsigned char* cJSON_strdup(const unsigned char* string, const internal_hooks * const hooks)cJSON_CreateString()和上述的创建函数没有明显区别,只不过这里调用了cJSON_strdup()来为字符串分配一个内存空间。
cJSON_String类型表示JSON节点中的普通字符串数据,会进行转义和解析。它将字符串内容作为标准的JSON字符串进行处理。
下面的示例使用该函数创建:
c
cJSON* stringObject = cJSON_CreateString("Hello, world!");
char* jsonString = cJSON_PrintUnformatted(stringObject);cJSON_Raw
c
CJSON_PUBLIC(cJSON *) cJSON_CreateRaw(const char *raw)cJSON_Raw类型表示JSON节点中的原始字符串数据,不进行任何转义或解析。它将字符串视为一个整体,不对其内容进行处理。
例如,如果JSON字符串中的某个字段的值是"{\"foo\": \"bar\"}",当使用cJSON库解析时,该值将被视为原始字符串,而不会进一步解析为对象或其他数据类型。
cJSON_Raw类型可以和cJSON_String类型对比来看。同样是"{\"foo\": \"bar\"}",使用cJSON_String来解析,该值将被解析为一个具有键值对的JSON对象。
假如有如下JSON字符串:
cjson
{
"raw_data": "{\"foo\": \"bar\"}",
"string_data": "{\"foo\": \"bar\"}"
}使用如下代码解析:
c
#include <stdio.h>
#include <cJSON.h>
int main() {
const char* json_string = "{\"raw_data\": \"{\\\"foo\\\": \\\"bar\\\"}\", \"string_data\": \"{\\\"foo\\\": \\\"bar\\\"}\"}";
cJSON* root = cJSON_Parse(json_string);
if (root == NULL) {
printf("Failed to parse JSON.\n");
return 1;
}
cJSON* raw_data_node = cJSON_GetObjectItem(root, "raw_data");
if (raw_data_node != NULL && raw_data_node->type == cJSON_Raw) {
const char* raw_data_string = raw_data_node->valuestring;
printf("Raw data: %s\n", raw_data_string);
}
cJSON* string_data_node = cJSON_GetObjectItem(root, "string_data");
if (string_data_node != NULL && string_data_node->type == cJSON_String) {
const char* string_data_string = string_data_node->valuestring;
printf("String data: %s\n", string_data_string);
}
cJSON_Delete(root);
return 0;
}输出结果如下:
Raw data: {"foo": "bar"}
String data: {"foo": "bar"}尽管它们的值都是相同的"{\"foo\": \"bar\"}",但它们的处理方式不同。
- 对于"cJSON_Raw"类型的节点,它被视为原始字符串,不进行进一步的解析。因此,它的值
"{\"foo\": \"bar\"}"被保留为原样。 - 对于"cJSON_String"类型的节点,它会被解析为一个具有键值对的JSON对象。因此,它的值
"{\"foo\": \"bar\"}"被解析为{"foo": "bar"},其中键"foo"的值为字符串"bar"。
cJSON_Object、cJSON_Array
c
CJSON_PUBLIC(cJSON *) cJSON_CreateArray(void)
CJSON_PUBLIC(cJSON *) cJSON_CreateObject(void)cJSON_IsReference
cJSON_IsReference是一个特殊的类型,用于表示JSON节点的引用。引用类型指示节点是另一个节点的引用,而不是独立的节点。
cast_away_const函数用于将const限定符从指针类型中移除,将常量指针转换为非常量指针。
cJSON库使用位掩码来表示节点的类型和属性。引用类型使用cJSON_IsReference标志来指示节点是引用类型。当节点的类型为引用类型时,它的实际类型可以通过使用位掩码和逻辑运算来获取。
引用类型可以实现共享数据,减少内存消耗和创建/释放内存的开销。
比如下面这种情况需使用引用来创建:
c
const char* str = "Hello, OpenAI!";
cJSON* refObject = cJSON_CreateStringReference(str);cJSON_CreatxxArray()
c
CJSON_PUBLIC(cJSON *) cJSON_CreateIntArray(const int *numbers, int count)创建特定类型的Array包含四个函数,内部实现类似:
c
CJSON_PUBLIC(cJSON *) cJSON_CreateIntArray(const int *numbers, int count);
CJSON_PUBLIC(cJSON *) cJSON_CreateFloatArray(const float *numbers, int count);
CJSON_PUBLIC(cJSON *) cJSON_CreateDoubleArray(const double *numbers, int count);
CJSON_PUBLIC(cJSON *) cJSON_CreateStringArray(const char *const *strings, int count);创建特定类型的数组,首先调用cJSON_CreateArray创建一个空的数组,而后依次调用cJSON_CreateNumber创建number追加到数组中。
代码中通过i的值来区分当前子节点是否为第一个,如果是第一个,则a->child指向它,如果不是第一个,则追加到后面。
a->child->prev = n;依然指向最后一个子节点,以便于下次再添加子节点时可以时间复杂度为O(1)。
类型判断的函数
cJSON中类型的判断使用cJSON_IsXXXX函数,例如cJSON_IsString。内部使用(item->type & 0xFF) == cJSON_XXXX通过按位与进行判断。
追加函数
将Item追加到Array。
c
CJSON_PUBLIC(cJSON_bool) cJSON_AddItemToArray(cJSON *array, cJSON *item)如果array没有子节点,则执行if (child == NULL)代码,其中比较关键的是item->prev = item;后面会用到这个pre指针。
如果array有子节点,则通过上面的pre指针直接找到数组的最后一个子节点,然后将item插到最后。可以看到每一次插入新的item,array->child->prev都会指向最新的item,这样不需要遍历整个链表到最后一个元素,时间复杂度为O(1)。
将Item追加到Object
c
CJSON_PUBLIC(cJSON_bool) cJSON_AddItemToObject(cJSON *object, const char *string, cJSON *item)可以看到追加到Object的内部调用了add_item_to_array(),也就是说后面追加的流程是一样的,重点看下追加之前做了什么操作。
这里首先生成一个key,赋值给了item->string,用来表示该项的名字。
然后使用new_type = item->type & ~cJSON_StringIsConst;将item->type的常量属性清除,以确保后续使用cJSON_Delete()可以释放。
而如果想设置该项类型为常量,使用cJSON_AddItemToObjectCS(),同样是调用add_item_to_object(),但是constant_key的值为true。
c
CJSON_PUBLIC(cJSON_bool) cJSON_AddItemToObjectCS(cJSON *object, const char *string, cJSON *item)具体调用cJSON_AddItemToObjectCS还是cJSON_AddItemToObject取决于该Item报错的是指针还是字符串内容,如果是字符串常量,则不需要释放,调用cJSON_AddItemToObjectCS,若是指针则调用cJSON_AddItemToObject。
后面看源码,还有一个函数(cJSON_AddItemReferenceToObject)说一下:
c
static cJSON *create_reference(const cJSON *item, const internal_hooks * const hooks)
CJSON_PUBLIC(cJSON_bool) cJSON_AddItemReferenceToObject(cJSON *object, const char *string, cJSON *item)cJSON_AddItemReferenceToObject和上面的不同在于使用 create_reference 函数创建一个新的引用对象,以确保在添加引用类型项时能够对其进行适当的处理,而不会修改原始的 item 引用。
是因为 add_item_to_object 函数可能会修改引用对象的类型或其他属性,而我们不希望修改传入的原始 item 引用。通过创建新的引用对象,可以确保在修改过程中不会影响到原始引用对象的状态。
从Array或Object中移除Item
c
CJSON_PUBLIC(cJSON *) cJSON_DetachItemViaPointer(cJSON *parent, cJSON * const item)用于通过指针从 cJSON 结构中分离(移除)一个特定的 cJSON 项(item)。这里的操作,属于双向链表的删除操作,稍加理解即可。
需要注意的是Detachxxxx函数并不会释放内存。而Deletexxxx函数会,因为在分离之后,调用了cJSON_Delete()。
c
CJSON_PUBLIC(void) cJSON_DeleteItemFromArray(cJSON *array, int which)获取信息
获取数组大小
CJSON_PUBLIC(int) cJSON_GetArraySize(const cJSON *array)这里仅仅是遍历了一遍Array的子节点,做了一个统计。
获取数组中的对象
c
static cJSON* get_array_item(const cJSON *array, size_t index)
CJSON_PUBLIC(cJSON *) cJSON_GetArrayItem(const cJSON *array, int index)也是链表操作,通过下标遍历,找到查找的对象,然后返回。
获取对象中的项
c
CJSON_PUBLIC(cJSON *) cJSON_GetObjectItem(const cJSON * const object, const char * const string)链表操作,其中参数string表示key值,返回一个cJSON项,再根据类型取出对应的值。注意该函数是不区分大小写的,如果想要区分,应使用cJSON_GetObjectItemCaseSensitive。
cJSON_HasObjectItem()
c
CJSON_PUBLIC(cJSON_bool) cJSON_HasObjectItem(const cJSON *object, const char *string)用于检查JSON对象中是否存在指定的项。它接受一个JSON对象和要检查的项的名称,并返回一个布尔值,指示该项是否存在。
例如:
c
const char* json_data = "{\"name\":\"John\",\"age\":30,\"city\":\"New York\"}";
// 解析JSON字符串
cJSON* root = cJSON_Parse(json_data);
// 检查是否存在name项
if (cJSON_HasObjectItem(root, "name")) {
printf("The JSON object has 'name' item.\n");
} else {
printf("The JSON object does not have 'name' item.\n");
}cJSON_GetErrorPtr()
c
CJSON_PUBLIC(const char *) cJSON_GetErrorPtr(void)用于获取cJSON解析过程中的错误信息。它返回一个指向错误信息字符串的指针,如果解析过程中没有发生错误,则返回NULL。
例如:
c
const char* json_data = "{\"name\":\"John\",\"age\":30,\"city\":\"New York\""; // 缺少右括号
// 解析JSON字符串
cJSON* root = cJSON_Parse(json_data);
if (root == NULL) {
const char* error_ptr = cJSON_GetErrorPtr();
if (error_ptr != NULL) {
printf("Error parsing JSON: %s\n", error_ptr);
} else {
printf("Unknown parsing error\n");
}
return 1;
}cJSON_GetStringValue & cJSON_GetNumberValue
c
CJSON_PUBLIC(char *) cJSON_GetStringValue(const cJSON * const item)
CJSON_PUBLIC(double) cJSON_GetNumberValue(const cJSON * const item)检查类型是否正确并返回对应的值。
更新数组项
cJSON_InsertItemInArray()、cJSON_ReplaceItemViaPointer()等增加或者替换指定的项,内部实现均为双向链表的操作,这里不展开了。
打印
cJSON_Print和cJSON_PrintUnformatted
c
static cJSON_bool print_value(const cJSON * const item, printbuffer * const output_buffer)这两个函数设置了默认的缓冲区参数:
c
static const size_t default_buffer_size = 256;
printbuffer buffer[1];
unsigned char *printed = NULL;
memset(buffer, 0, sizeof(buffer));
/* create buffer */
buffer->buffer = (unsigned char*) hooks->allocate(default_buffer_size);
buffer->length = default_buffer_size;
buffer->format = format;
buffer->hooks = *hooks;cJSON_Print和cJSON_PrintUnformatted都是封装的print函数,区别在于第二个参数不同,cJSON_Print打印的是格式化好的字符串,内部是通过如下代码实现的:
c
if (output_buffer->format)
{
*output_pointer++ = '\t';
}当调用cJSON_Print()函数时,它会递归地遍历JSON树的节点,并将其转换为字符串格式。每在打印key时,都会调用print_value,所以print_value是其中的核心函数。这里遍历各个节点拷贝数据到打印缓冲区不难理解,需要特别说明一下这部分的内存分配机制,也就是ensure这个函数。
static unsigned char* ensure(printbuffer * const p, size_t needed)
重点说一下这个ensure函数,它的作用是预分配一些内存,而且要确保打印缓冲区有足够的空间来存储指定数量的字节。
整个打印过程多次调用ensure,只要往打印缓冲区写内容,就要调用。其中参数needed表示本次需要的内存量;p->length表示打印缓冲区剩余长度。
而后面又进行了一次计算:needed += p->offset + 1;表示当前偏移+需要往打印缓冲区中写的数据量的大小,再和p->length做比较。
但并不是每一次调用都要分配内存,如果打印缓冲区空余的内存足够本次填充,则计算偏移后直接返回偏移后的指针。
c
needed += p->offset + 1;
if (needed <= p->length)
{
return p->buffer + p->offset;
}而如果当前需要的内存量大于打印缓冲区剩余内存,则需要使用reallocate函数分配内存,并且分配内存的大小赋值给length。
c
newsize = needed * 2;
// ......
newbuffer = (unsigned char*)p->hooks.reallocate(p->buffer, newsize);
p->length = newsize;
p->buffer = newbuffer;这里使用double的方式简单粗暴的分配内存,并且更多的分配内存是有好处的:
- 减少频繁的内存分配:内存分配是一项相对较慢的操作,而且频繁的内存分配也可能导致内存碎片问题。通过一次性分配较大的空间,可以减少频繁的内存分配操作,提高性能。
- 节省空间和时间:通过分配比当前所需空间稍大一些的内存块,可以避免过早地耗尽分配的内存空间。如果每次分配都刚好满足当前需求,后续的数据增长可能导致频繁的重新分配和复制操作。通过预留额外的空间,可以减少这种情况的发生,节省时间和资源。
- 缓解内存碎片问题:内存分配和释放的过程中,可能会产生内存碎片,即存在一些小而不连续的空闲内存块。通过一次性分配较大的内存空间,可以减少内存碎片的产生,提高内存的利用率。
内存可以预分配一些,但这样一种方式是否合理呢?因为没有理解源码的用意,于是加了一个打印:
c
needed += p->offset + 1;
printf("needed = %d p->length = %d\n", needed, p->length);
if (needed <= p->length)
{
return p->buffer + p->offset;
}结果如下:
needed = 4 p->length = 256
needed = 4 p->length = 256
needed = 11 p->length = 256
// ......
needed = 30 p->length = 256
needed = 31 p->length = 256
needed = 34 p->length = 256
needed = 36 p->length = 256
// ......
needed = 297 p->length = 548
needed = 306 p->length = 548
needed = 307 p->length = 548
// ......
needed = 406 p->length = 548
needed = 451 p->length = 548
// ......
needed = 622 p->length = 1130
needed = 623 p->length = 1130
needed = 624 p->length = 1130这里有两个地方我认为不合理:
1)判断条件。这里是判断的是offset+即将写入的长度来和上一次分配的内存大小做比较。
c
needed += p->offset + 1;
if (needed <= p->length)
{
return p->buffer + p->offset;
}如果想清楚当前分配的内存是不是够这一次使用,是不是应该记录剩余内存的大小,然后去比较。源码里这样判断是可以的,但是会出现明明打印缓冲区有够用的内存,可因为判断条件的缘故,又分配了一次,造成性能降低和内存浪费。
2)分配的大小。每次分配都是double当前打印缓冲区中的数据长度,这样会出现一个问题,就是当前缓冲区长度越大,下一次分配的就越多。看上面的打印就能发现,浪费了将近一半内存。
c
newsize = needed * 2;
// ......
newbuffer = (unsigned char*)p->hooks.reallocate(p->buffer, newsize);
p->length = newsize;
p->buffer = newbuffer;cJSON这里的处理机制没有很理解,如果有理解这部分内容的,希望可以解惑。
cJSON_PrintBuffered
c
CJSON_PUBLIC(char *) cJSON_PrintBuffered(const cJSON *item, int prebuffer, cJSON_bool fmt)该函数使用 printbuffer 结构体来管理缓冲区和内存分配。它可以根据需要动态分配内存,适用于灵活地处理输出字符串的大小。可以选择启用或禁用动态内存分配,以及控制打印格式。这种方式适用于需要动态管理内存,或需要定制打印格式的情况。
如果对打印的内容非常清楚,可以调整内存分配机制,预分配的内存大小等,如果猜的准,可以减少内存分配次数,提升性能。
示例代码如下:
c
#include <stdio.h>
#include "cJSON.h"
int main() {
cJSON *root = cJSON_CreateObject();
cJSON_AddStringToObject(root, "name", "John Doe");
cJSON_AddNumberToObject(root, "age", 30);
printbuffer p;
p.buffer = NULL;
p.length = 0;
p.offset = 0;
p.depth = 0;
p.noalloc = false;
p.format = true;
p.hooks = cJSON_GetDefaultHooks();
cJSON_PrintBuffered(root, &p);
printf("JSON string: %s\n", p.buffer);
cJSON_Delete(root);
cJSON_free(p.buffer);
return 0;
}cJSON_PrintPreallocated
c
CJSON_PUBLIC(cJSON_bool) cJSON_PrintPreallocated(cJSON *item, char *buffer, const int length, const cJSON_bool format)该函数要求提供一个预分配的缓冲区,函数会将 JSON 字符串直接写入该缓冲区中,不进行动态内存分配。这种方式适用于已知输出所需的最大内存大小,并希望避免在运行时进行内存分配的情况,适用于对内存使用有限制或需要高效控制内存的环境。
该函数适用于对内存使用有限的嵌入式系统、低内存环境,或对输出字符串大小有明确限制的场景。通过预分配足够大的缓冲区,避免动态内存分配,并在运行时控制内存的使用。