一、常用的vibecoding工具
(1)AI原生IDE
Cursor
Windsurf
Trae
(2)CLI(不占用界面,只在终端打字)
Claude code
Aider
Cline
(3)即时生成(一句话生成可运行项目,快速出Demo)
Devin
秒哒
码上飞
二、人工智能、机器学习、深度学习三者关系?
人工智能:目标是机器有类似人类的智能
机器学习:机器学习是人工智能的核心实现方式,它通过数据训练模型,让机器自动学习规律,而不是依赖人工编写规则。常见方法有:线性回归/逻辑回归、决策树、随机森林、支持向量机
深度学习:是机器学习的一个重要分支,是一种基于多层神经网络,让机器自动从海量数据中学习特征与规律、从而实现感知、理解与生成的高级机器学习方法
三者关系:深度学习是机器学习的重要分支,机器学习是人工智能的核心实现方式
三:什么是LLM
大语言模型,是一种基于海量文本数据训练,能理解和生成人类语言的人工智能模型
四:什么是提示词(prompt)?提示词的基本结构包括哪些部分?什么是提示词工程(prompt Engineering)?
(1)提示词是用户或者系统提供给大语言模型的指令或者生成文本呢,用于引导模型生成特定输出.。
(2)提示词的基本结构
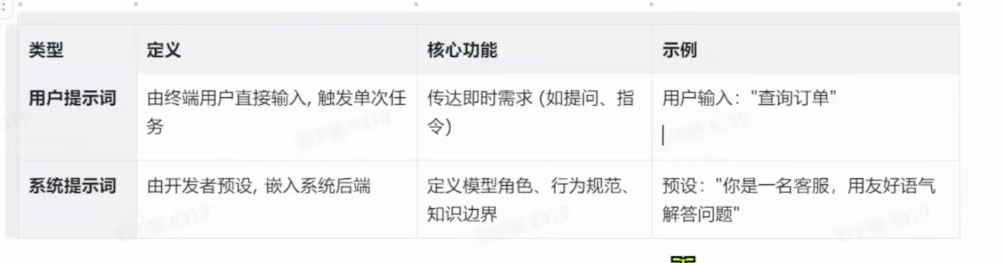 系统提示词如同"操作系统",用户提示词如同"操作指令"
系统提示词如同"操作系统",用户提示词如同"操作指令"
提示词工程 (Prompt Engineering),通俗来说,就是研究如何用最精准、最有效的语言"指挥"AI大模型(如DeepSeek、ChatGPT),从而稳定地获得高质量回答的一门学问和技术。
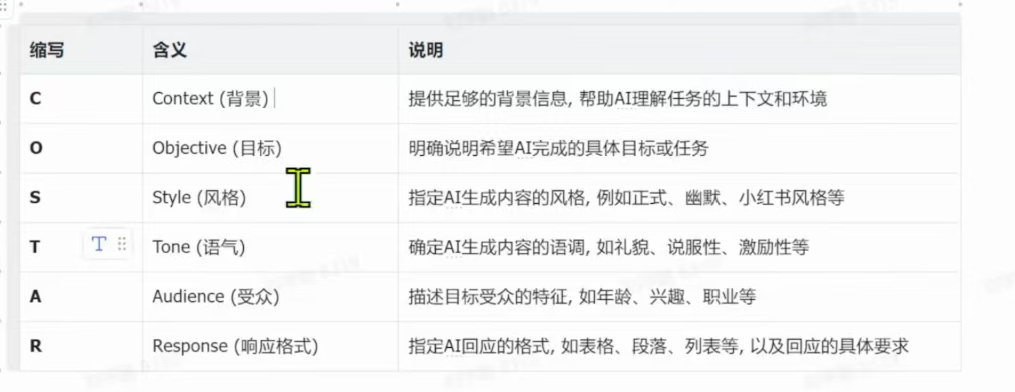
通常在设计提示词时,我们可以遵循"CO-STAR"结构化框架
五:有哪些设计和优化提示词的技巧?
基础提示技巧:
角色提示:通过设定身份来约束模型的语气,专业深度和思维方式
结构化指令引导:通过特定分隔符,列表,以及Markdown格式等来清晰的界定指令,提供1-3个正确示例,让模型快速的学习格式与规则
少样本提示:提供1-3个正确示例,让模型快速学习格式与规则
进阶推理技巧:
链式思考提示让模型分布推理,先思考再输出答案,大幅提升复杂问题准确率
自我一致性:传统链式思考提示只走一条推理路径,自我一致则探索多条路径,最终聚合为一致答案,他不在依靠一次思考定生死,而是通过多次尝试+投票机制来提高准确率
**优化与迭代策略:**由浅入深不要指望一次写出完美的提示词,先从简单的指令开始,观察输出,再根据不足逐步添加约束条件和背景
五:什么是Token?Token在大语言模型中作用是什么?
**Token概念:**Token词元是大语言模型处理文本时的最小语义单位,将文本拆解为模型可理解的离散单元(不是字,也不是单词)
Token通过大模型的分词器将文本拆分而来,不同模型的分词器不同,同一个词在不同模型中可能被拆分为不同的token
**Token的分类:**Prompt Token/Input Token(输入token)发送给模型的内容、问题、历史对话、上传的文档、系统提示词等
Completion Token/Output Token(输出token)模型生成的回答
Token在大语言中的作用:
1.计费单位
2.上下文长度限制
3.决定模型理解能力:Token拆分的越合理,模型越能理解语义,同时token数量直接影响推理速度,显存占用成本
六:什么是会话记忆?有什么作用?
在对话系统中,会话记忆指的是模型对历史对话内容的存储和利用机制,属于上下文理解的核心能力之一
本质就是对话的整体语境与状态,主要包括:
1.主题与话题走向
2.指代关系
3.用户的意图与角色设定
4.对话历史中的关键信息
会话记忆的作用:
1.上下文连贯
2.减少重复输入
3.个性化体验
4.多轮任务完成
七:会话记忆和上下文窗口是什么关系?
会话记忆上一题
上下文窗口:大语言模型一次最多能处理的输入Token数量
两者的关系:上下文窗口=背包容量;当前输入+会话记忆+系统提示词=你要装进去的东西
八:什么是多模态?常见的模态有哪些?典型的应用场景有哪些?
多模态:是指融合文本、图像、音频、视频等多种类型信息,让模型能理解、生成不同模态数据的技术。
常见模态:文本、图像、音频、视频
典型应用场景:智能问答;图生文、文生图;语音助手;视频理解
九:什么是Rag(检索增强生成)?它能解决大模型的什么问题?
RAG是一种结合外部知识库检索与大模型生成的计数。核心是让大模型在回答前先"查资料"(外部知识库),再基于检索到的权威信息生成答案,解决模型知识的过时,幻觉,专业知识不足三大核心问题。(从背书机器变成会查资料的专家)
Rag解决的问题:
知识过时问题:大模型训练数据是历史的,rag可以接入:最新文档、实时数据、内部知识库、实现动态知识
幻觉问题:模型容易编答案,Rag基于真实文档回答提供依据大幅降低幻觉
私有知识问题:模型默认不知道:公司内部数据、私有文档、业务规则。Rag可以接入:企业知识库,本地文件,实现企业专属AI
上下文窗口限制:模型不能一次读太多内容。Rag检索相关片段,而不是全部数据节省Token
可解释性问题:传统模型回答"黑盒",Rag可以返回"引用来源"支持溯源
十:Rag的核心工作流程
离线准备阶段:
第一步:数据采集,数据来源包括:文档,数据库,API,网页
第二步:文档切分(chunking),把长文档拆成小块以提高检索精度,适配上下文窗口
第三步:向量化(embedding),将每个chunk转化为向量
第四步:将向量存储到向量数据库(除向量外一般还存储:原文、metadata),常见的向量数据库有:Milvus,Pinecone
在线查询阶段:
第一步:数据查询检索,用户输入问题将问题转化为向量,然后在向量数据库中进行相似度搜索,寻找最相似的文档块(常见算法:余弦相似度,向量距离)
第二步(可选):重排序(re-ranking)对检索结果可以进行再次排序即使用更强模型筛选最相关内容,称为重排序,此操作为可选操作
第三步:Prompt构建(关键)&答案生成:将检索结果和用户问题组合起来,构造一个完整的Prompt,放入上下文窗口调用大模型,模型生成答案并返回
十一:什么是工具调用(Tool calling)?
大模型本身无法精确计算:在大数运算,复杂公式推导以及统计分析场景极易出现计算错误,无法保证结果完全正确。
Tool calling(工具调用)是AI应用中的一种常见技术模式,指的是大语言模型可以根据用户技术,智能地选择并调用外部工具(如函数,APi,服务)并获取执行结果,一次扩展并且增强自身能力的技术流程
Function calling(函数调用)是工具调用(Tool Calling)的早期叫法与核心形式,现在行业里一般统一称为工具调用,函数调用就是指LLM请求调用一个开发者预定义的函数,这里的函数就是你带代码中的一个方法,Tool Calling是一个更通用,更广泛的概念,不仅包含了Function Calling,还涵盖了其他类型的工具
十二:什么是Mcp?与Tool Calling的区别是什么?
Mcp(Model Context Protocal,模型上下文协议)由AI公司Anthropic推出的开源标准协议,为大语言模型于外部系统,工具,数据源提供标准化的安全双向通信接口,解决AI集成的复杂问题,常被类比为AI领域的USB-C或者通用接口
以前的大模型想要接入各类的外部系统或者工具等,每个模型和每个工具系统之间都要单独开发一套专属对接逻辑,适配成本极高,复用性极差
现在有了MCP,就像所有设备都统一用使用USB-C只要遵循这个标准,就能即插即用
其中,MCP Client是大模型系统内的"连接器",负责按Mcp协议发起连接,调用外部服务,其实现可基于MCP官方提供的SDK,只需完成协议适配和请求封装,无需复杂开发
MCP Sever是外部工具的"适配器",会按照MCP协议将工具功能封装成标准的接口,供Client调用,二者配合实现模型与工具的即插即用,Mcp Server支持两种获取方式,既可以基于Mcp官方规范自行开发,适配自身个性化需求,也可以直接使用现成的服务。为了方便开发者快速找到适配的现成Mcp Sever,无需自行从零开发,目前有多个主流渠道可获得各类的MCP Sever,具体如下:
与Tool calling的区别:Tool Calling是LLM调用外部工具的能力,MCP是LLM与工具交互的标准化协议
十三:MCP的核心工作流程是什么?
初始化连接(握手连接):MCP 主机启动,创建Mcp Client并按照配置与MCP建立通信连接(一个主机可以同时连接多个MCP Sever,每个Sever独立承担不同的工具与能力)
能力发现(工具/资源列表):Client想Sever发起能力查询,Sever返回结构化清单:名称,描述,参数,权限,Client将工具信息同步给主机,让LLM明确自身可以调用的外部能力边界
执行决策&调用工具(LLM驱动):用户输入问题之后,Client会自动整合可用工具列表,用户原始问题与对话上下文,并且以标准化格式封装之后发送给LLM,LLM依据上下文及工具进行智能决策
判断是否需要外部工具,选择具体工具并匹配合规入参
若无需调用工具,则直接生成自然语言回复,跳过后续执行环节。
若LLM确定调用工具,Client会将结构化的调用请求精准转发至对应MCP Server;由Sever承担实际执行职责,完成API调用,数据库读写,脚本运行或者文件系统操作等任务,执行完毕后,以统一结构化格式将结果回传给Client。
结果回传&输出:Client把工具执行结果回传给LLM,模型融合工具执行结果,用户问题与对话上下文,生成符合需求的自然语言回答,再由Client通过主机应用展示给用户。
十四:什么是工作流与Agent区别是什么?
**Agent:**能够感知环境输入、自助决策、规划行动路径,并可调用工具或执行操作以达成目标的自主性软件实体
**工作流:**是按照预先定义好的步骤和规则,依次执行任务的一种流程化的机制。特色:流程是固定的,
区别:工作流是"人预先定义步骤的自动化流程",而Agent是"大模型(LLM)根据目标动态控制流程走向"
十五:什么是多Agent,什么场景下需要使用多Agent协作而不是单个Agent解决?
**多Agent模式:**将一个复杂任务拆分给多个具备不同职责的Agent,由它们协作完成整体目标的系统。可以理解为:"从一个人干所有事",变成"一群分工明确的人协作"
什么场景下需要使用多Agent协作:当任务复杂到一个Agent无法稳定、清晰地完成时,就需要多Agent。尽管可采用单个Agent整合并执行复杂任务、但这种超级Agent架构存在明显的弊端。以下将对其主要问题展开说明
上下文限制:一个Agent需要将所有任务的内容、工具描述、历史记录都塞入有限的上下文窗口,这会导致信息过载、成本剧增、推理速度下降
角色冲突与指令污染:同一个Agent同时扮演多个角色时,系统提示词会发生冲突,导致行为混乱或平庸化
单点故障与脆弱性:单个Agent一旦在某个步骤推理出错或者遇到未知情况,整个任务链可能崩溃