一、堆排序(Heap Sort)算法
堆排序基于完全二叉树 + 大顶堆 实现,属于不稳定排序,平均 / 最好 / 最坏时间复杂度均为 O(n log n),空间复杂度 O(1),原地排序。 整体流程分为两大阶段:构建大顶堆 + 循环交换堆顶并调整堆。
java
public class HeapSort {
public static void main(String[] args) {
int[] arr = {3, 1, 4, 2, 7, 5, 9, 6, 8};
heapSort(arr);
System.out.print("堆排序结果:");
for (int num : arr) {
System.out.print(num + " ");
}
}
/**
* 堆排序入口方法
* @param arr 待排序数组
*/
public static void heapSort(int[] arr) {
int len = arr.length;
// 第一步:构建初始大顶堆,从最后一个非叶子节点向前调整
for (int i = len / 2 - 1; i >= 0; i--) {
heapify(arr, i, len);
}
// 第二步:循环交换堆顶与堆底,缩小堆范围并重新调整堆
for (int i = len - 1; i > 0; i--) {
// 交换堆顶最大值和当前堆末尾元素
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 仅对根节点调整堆,有效长度缩小为i
heapify(arr, 0, i);
}
}
/**
* 堆维护方法:以i为根,调整子树满足大顶堆规则
* @param arr 原数组
* @param root 当前根节点下标
* @param heapLen 当前堆有效长度
*/
public static void heapify(int[] arr, int root, int heapLen) {
while (true) {
// 假设当前根是最大值下标
int maxIndex = root;
// 左孩子下标
int left = 2 * root + 1;
// 右孩子下标
int right = 2 * root + 2;
// 左孩子存在且值更大,更新最大值下标
if (left < heapLen && arr[left] > arr[maxIndex]) {
maxIndex = left;
}
// 右孩子存在且值更大,更新最大值下标
if (right < heapLen && arr[right] > arr[maxIndex]) {
maxIndex = right;
}
// 根已经是最大值,无需调整,退出循环
if (maxIndex == root) {
break;
}
// 交换根与最大值节点
int temp = arr[root];
arr[root] = arr[maxIndex];
arr[maxIndex] = temp;
// 向下迭代,继续调整交换后的子树
root = maxIndex;
}
}
}1. 核心思路与数组下标映射
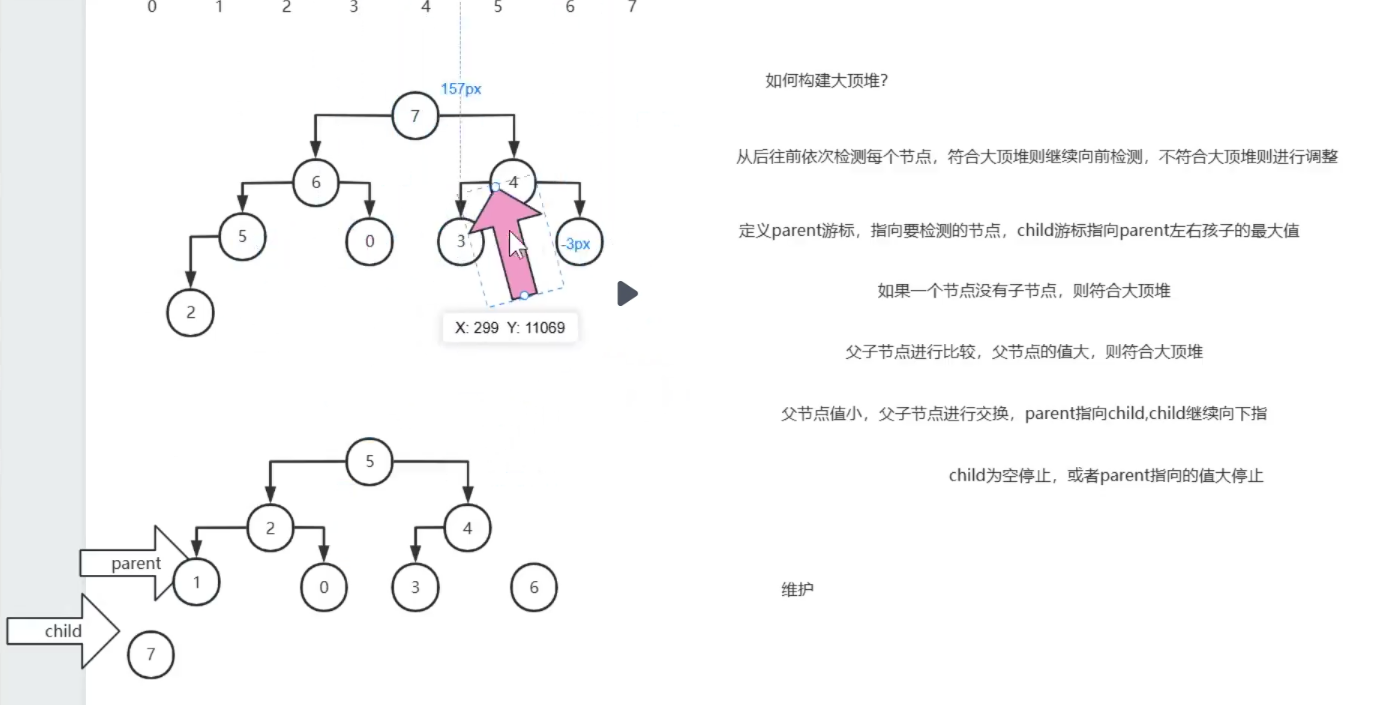
(1)大顶堆规则
完全二叉树结构,任意父节点数值 ≥ 左右子节点数值,堆顶是当前区间最大值。 堆排序整体两步:
- 对整个数组构建初始大顶堆;
- 将堆顶最大值与堆末尾元素交换,缩小有效堆长度,对剩余元素重新调整大顶堆,循环直到全部有序。
(2)数组下标映射(无需新建二叉树)
数组直接存储完全二叉树,通过下标换算父子节点:
- 父节点下标:
i - 左孩子下标:
2 * i + 1 - 右孩子下标:
2 * i + 2
(3)堆维护 heapify 统一逻辑
堆调整方法 heapify 作用:保证以i为根的子树满足大顶堆规则。 两种场景共用同一个维护方法:
- 初始建堆:从最后一个非叶子节点倒序向前,逐个调用 heapify;
- 交换堆顶后调整:仅需对根节点下标 0 调用一次 heapify。
(4)heapify 调整逻辑
- 传入数组、当前父节点下标、堆有效长度;
- 循环查找父、左、右三者最大值下标;
- 若最大值不是父节点,交换父子元素;
- 把最大值下标作为新父节点,继续向下循环调整,直到满足大顶堆或超出边界。
2. 时间复杂度推导
- 单次
heapify向下调整,遍历层数为树高度,复杂度O(log n); - 初始建堆:遍历所有非叶子节点,总代价
O(n); - 交换 + 调整阶段:共 n 次循环,每次调用一次
heapify,总代价O(n log n); - 整体总时间复杂度:
O(n log n),无论原始数组有序 / 逆序 / 乱序均稳定。 - 空间复杂度:原地排序,仅常数临时变量,
O(1)。
二、归并排序(Merge Sort)算法
归并排序采用分治思想 ,稳定排序,时间复杂度稳定O(n log n),缺点是需要额外临时数组,空间复杂度O(n)。
java
/**
* 合并左右两个有序区间
* @param arr 原数组
* @param left 左区间起始下标
* @param mid 左右区间分割点
* @param right 右区间结束下标
*/
public static void merge(int[] arr, int left, int mid, int right) {
// 右区间起始指针
int s2 = mid + 1;
// 创建临时数组,存储本次合并后的有序数据,长度=当前区间元素总数
int[] temp = new int[right - left + 1];
// temp数组写入下标
int index = 0;
// 1. 双指针循环:同时遍历左右有序区间,取较小值存入temp
while (s1 <= mid && s2 <= right) {
if (arr[s1] < arr[s2]) {
temp[index] = arr[s1];
s1++;
index++;
} else {
temp[index] = arr[s2];
s2++;
index++;
}
}
// 2. 左区间剩余元素全部拷贝进temp
while (s1 <= mid) {
temp[index] = arr[s1];
s1++;
index++;
}
// 3. 右区间剩余元素全部拷贝进temp
while (s2 <= right) {
temp[index] = arr[s2];
s2++;
index++;
}
// 4. 将临时有序数组写回原数组对应区间(关键步骤,防止数据丢失)
for (int j = 0; j < temp.length; j++) {
arr[left + j] = temp[j];
}
}1. 分治核心逻辑
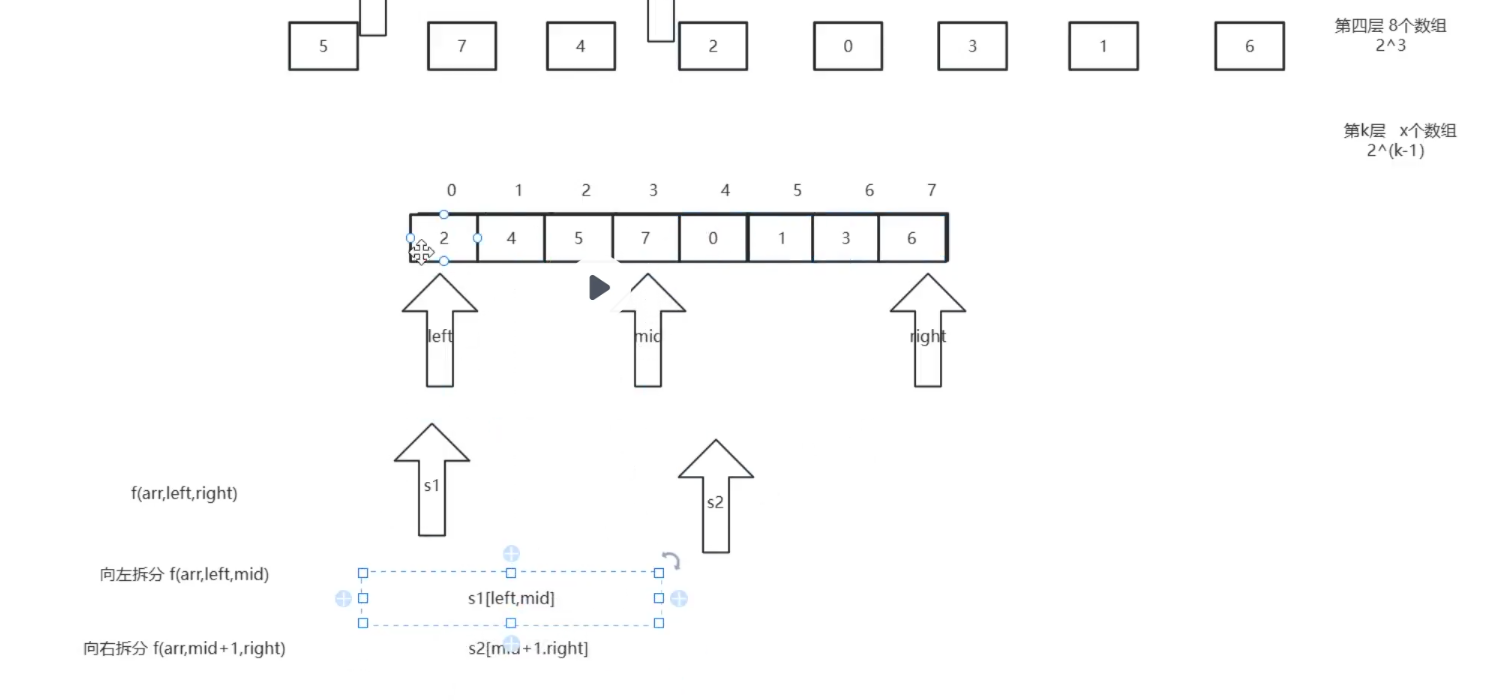
(1)递归拆分策略
递归将数组以中点切分为左、右两个区间,持续拆分直到区间只剩单个元素(天然有序),再逐层向上合并有序区间。
- 递归出口:
left >= right,区间无元素或仅一个元素,无需处理; - 仅传递左右边界下标划分区间,不新建子数组,节约内存。
(2)双指针合并有序序列
有两个有序子区间时,借助临时数组完成合并:
- 双指针 S1、S2 分别指向左右有序区间起始;
- 对比两个指针指向元素,将更小的值存入临时数组,对应指针后移;
- 某一侧区间遍历完毕后,把另一侧剩余元素全部拷贝进临时数组;
- 合并完成后,将临时数组整体写回原数组
[left, right]对应位置,防止原数据覆盖丢失。
2. 递归内存执行流程
- 递归拆分时,每层方法入栈保存 left、right、mid 参数;
- 递归到底触发出口后,逐层出栈执行合并逻辑;
- 每次合并会创建临时数组存放有序结果,属于堆内存;
- 合并完成将临时数组数据覆盖写回原数组,上层递归继续合并更大区间。
3. 复杂度总结
- 时间复杂度:拆分层数
log n,每层合并总遍历元素 n,稳定O(n log n); - 空间复杂度:需要辅助临时数组,
O(n); - 特性:稳定排序,适合外排序(海量磁盘数据排序)。
三、堆排序 vs 归并排序
| 维度 | 堆排序 | 归并排序 |
|---|---|---|
| 时间复杂度 | 稳定 O (n log n) | 稳定 O (n log n) |
| 空间复杂度 | O (1) 原地排序 | O (n) 需要临时数组 |
| 排序稳定性 | 不稳定 | 稳定 |
| 适用场景 | 内存内大数据排序、空间受限场景 | 外排序、要求稳定排序场景 |
| 实现难点 | 完全二叉树下标换算、堆调整 | 递归分治、双指针合并、数组回写 |