- 主页:tokenscope.app/zh
- GitHub:github.com/HduSy/token...
用 Claude Code 写代码写久了,会冒出一个很朴素的问题:今天到底烧了多少 token?哪几个模型最贵?哪些 MCP 和 Skill 我用得最多?
Claude 自己那个用量条只有一个 5 小时的滚动窗口,刷一下就没了,根本看不清。所以我花了点时间写了 Tokenscope,一个 macOS 菜单栏小工具。技术栈是 Tauri 2 + React 做前端,Rust 做数据层。它干的事情就一件:读 Claude 已经落盘到本地的会话日志,把每天用了多少 token、大概花了多少钱、按模型和按 MCP/Skill 的调用统计算出来,常驻在菜单栏。
这篇文章不打算讲怎么用 Tauri 写 Hello World。我想把开发里真正费脑子、又特别容易踩坑的地方摊开:怎么不动 Claude 一根毛地采集数据;怎么避免流式重试把 token 算成两倍;Anthropic 那四类 token 到底该怎么对应到价格;以及打包分发一路上摔的跤。
长什么样
菜单栏图标旁边直接挂一个数字,比如 ⬡ 14.00M,代表今天用了 1400 万 token。点开是一个面板,Day / Week / Month 三档切换,有 token 的 input/output 拆分、估算花费、Requests / Sessions,还有按模型、按 MCP、按 Skill 的三个切片,一个成本甜甜圈,一张年度活跃热力图。
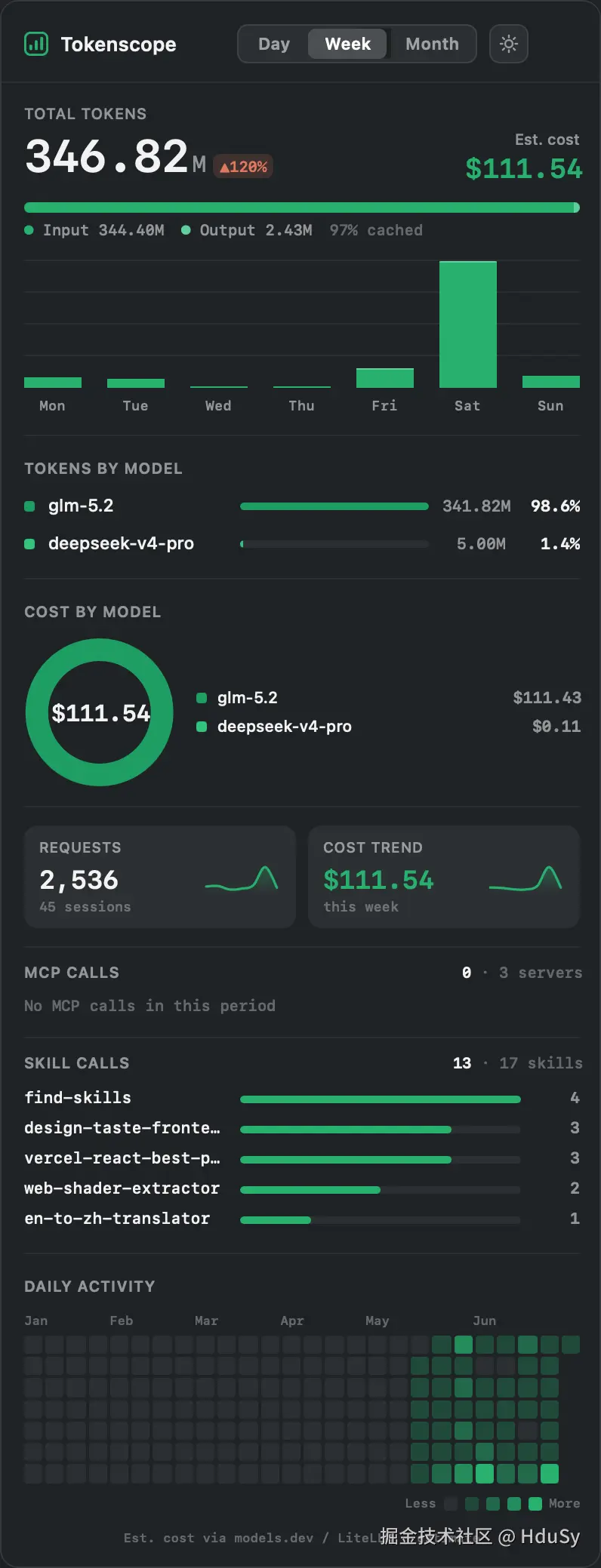
有一个设计点我想单独说一下:它只统计你自己装的 MCP 和 Skill,Claude 内置工具和 Anthropic 自带那批 MCP 一律不计入。不然数字会被那些默认工具淹没,看不出你自己扩展生态的真实情况。
为什么选 Tauri 2
需求其实很简单。要常驻菜单栏,要能读本地文件,要轻量。最好别让我写 Swift。
Electron 起步是快,可一个看 token 的小工具吃两三百兆内存,我不太能接受。原生 SwiftUI 体验最好,可那是一个我完全不熟的生态,投入产出比不划算。Tauri 2 卡在中间,前端继续用我熟悉的 React 和 TypeScript,数据层用 Rust,serde 解析 JSON 又快又稳,打包出来才十几兆,菜单栏走系统 tray。
还有一个意外收获。Tauri 2 的 tauri-plugin-single-instance 直接把「重复打开导致菜单栏出现两个图标」这种破事解决了,注册一下就行。
前端其实很薄,三个文件:data.ts 管类型和 Tauri 桥和格式化,charts.tsx 放图表原语,App.tsx 是主面板。真正的工作量全在 Rust 数据层。
数据从哪来:不动它,只读日志
Claude CLI 会把每次会话落盘成 JSONL,路径是:
javascript
~/.claude/projects/<project-hash>/<session-uuid>.jsonl每一行一个事件,type 可能是 assistant、user、system。assistant 消息长这样(只列关键字段):
json
{
"type": "assistant",
"sessionId": "...",
"timestamp": "2026-06-28T10:24:00.000Z",
"message": {
"id": "msg_01XYZ...",
"model": "claude-sonnet-4-6",
"usage": {
"input_tokens": 1234,
"cache_creation_input_tokens": 5600,
"cache_read_input_tokens": 18000,
"output_tokens": 420
},
"content": [
{ "type": "thinking", "thinking": "..." },
{ "type": "tool_use", "name": "mcp__github__create_issue", "input": {} },
{ "type": "tool_use", "name": "Skill", "input": { "skill": "find-skills" } },
{ "type": "text", "text": "..." }
]
}
}我的策略是不去碰 Claude 本身。不拦截它的请求,不往它进程里塞 hook,纯把这块日志当数据库用。好处很实在:不影响 Claude 的稳定性,Tokenscope 崩了或者没开数据也照常累积,Claude 升级了只要日志格式不大改就没事。
代价是得自己处理日志层的脏数据。流式重试会让 usage 重复,一条消息会被拆成好几行,这些都是后面要解决的。
增量读取和去重,这块最容易算错
先说增量
JSONL 日志一直在追加,每次都全量扫一遍很浪费。我用一个 per-file 的 manifest 记住每个文件读到了第几个字节:
rust
#[derive(Serialize, Deserialize, Default)]
struct Manifest {
// path -> (size, mtime_ms, 已读到的字节偏移)
files: HashMap<String, (u64, i64, u64)>,
}每次 ingest 先用文件大小加修改时间判断有没有变,没变直接跳。变了就 seek 到上次记的偏移量,只读新增的那截:
rust
let mut offset = match self.manifest.files.get(&key).copied() {
Some((psize, pmtime, poff)) => {
if psize == size && pmtime == mtime { continue; }
if size < poff { 0 } else { poff }
}
None => 0,
};
let mut f = fs::File::open(path)?;
f.seek(SeekFrom::Start(offset))?;
let mut buf = Vec::new();
f.read_to_end(&mut buf)?;
// 只处理到最后一个换行符为止
let process_until = match buf.iter().rposition(|&b| b == b'\n') {
Some(i) => i + 1,
None => 0,
};注意 rposition(b'\n') 这一行。日志文件正在被写的时候,最后一行很可能是半截。把半个 JSON 解析进去会失败,更糟的是可能整条数据都没了。所以我只截到最后一个换行符,把那截写一半的尾巴留给下一次 ingest。做实时增量读取,这一步躲不掉。
再说去重,这是整个项目最阴的一块
Claude 是流式响应,还带重试。同一条 assistant 消息,也就是同一个 message.id,会在日志里出现好几行,每一行都带着一模一样的 usage。要是不管三七二十一按行求和,token 直接翻倍。
我第一版的去重是「id 相同就整行丢弃」:
rust
if self.index.contains_key(&ev.id) { continue; } // 整行丢弃结果 Skill 和 MCP 的调用死活统计不上。
后来才看明白。一条 assistant 消息会拆成好几行:thinking 在一行,tool_use 在另一行,它们共用同一个 message.id,usage 还一模一样。我先吃到 thinking 那一行建了索引,带着 tool_use 的那行就被整个扔了。token 数倒是对的,因为 usage 本来就重复,丢了不影响求和。但工具调用的信息是真没了。
正确的做法是合并而不是丢弃。同一个 id 的后续行,把它的 mcp 和 skills 并到已有事件里,token 不再累加,因为各行的 usage 相同,计一次就够了:
rust
if let Some(&i) = self.index.get(&ev.id) {
let prev = &mut self.events[i];
prev.mcp.extend(ev.mcp);
prev.skills.extend(ev.skills);
continue;
}
self.index.insert(ev.id.clone(), self.events.len());
self.events.push(ev);这是典型的去重粒度没想清楚。我以为「id 相同就是完全重复」,其实只是 token 重复,工具调用的信息可能散在不同行里。修法也很直接,把丢弃的粒度从整行降到字段。
另外,每次改了解析逻辑,我都会去 bump 一个 STORE_VERSION。不然旧的增量 manifest 会跳过已经读过的字节,新提取的字段就漏掉了:
rust
// v2: 统计 /skill 斜杠命令调用,不只是 Skill tool_use
// v3: 跨行合并共享 message.id 的 tool_use
const STORE_VERSION: u32 = 3;Token 怎么计价:四类互斥 token
理解成本估算的钥匙在这里。Anthropic 把一条消息的 token 拆成四个互不重叠的计数,同一颗 token 不会被算两次:
| 阶段 | usage 字段 | 含义 | 单价(相对 input) |
|---|---|---|---|
| Input(未缓存) | input_tokens |
本轮新发的提示词 | 1× |
| Cache 写入 | cache_creation_input_tokens |
写进 prompt cache 的上下文 | 约 1.25× |
| Cache 命中(读) | cache_read_input_tokens |
从缓存重放的上下文 | 约 0.1× |
| Output | output_tokens |
模型生成的 token | 约 5× |
计价就是把四类各自乘上单价再相加:
rust
fn cost(&self, model: &str, input, output, cache_create, cache_read: f64) -> Option<f64> {
let p = self.lookup(model)?;
Some(
input * p.input
+ output * p.output
+ cache_create * p.cache_create
+ cache_read * p.cache_read,
)
}这里有个坑很容易把用户带偏。UI 上为了好看,默认把 cache 的写入加读取折进 In 里显示,再单列一个 cached 百分比。但如果成本也按 In 统一用 input 的单价算,就会严重高估。因为那一大坨 token 多数是 cache 命中,单价只有 0.1 倍。
所以计价必须老老实实按四类分别套单价。这也是为什么你经常看到 token 总量吓人,账单却没那么夸张,大头是 cache 命中,按 0.1 倍算。这个观察本身我觉得就是这个工具值得一做的理由之一。
模型价格匹配:日志里只有个裸名
又一个头疼事。Claude 日志里的 model 字段只有裸模型名,比如 claude-sonnet-4-6、glm-5.1。没有厂商前缀,版本分隔符也不统一,有的用点,有的用 p,比如 glm-5p1。可价格源里模型 id 的格式五花八门,得想办法对上。
我用三层兜底。主源是 models.dev,它用裸模型名做 key,和 Claude 日志天然对齐。补它覆盖不到的用 LiteLLM,覆盖面最广。两个都拿不到的时候用内置的一份快照兜底,至少离线首次启动有数。
价格文件缓存在 ~/Library/Caches/tokenscope/,24 小时刷新一次。联网失败就回退到过期的本地缓存,保证离线也能算出价,哪怕不是最新的:
rust
fn fetch_cached(name: &str, url: &str) -> Option<String> {
if 缓存新鲜(<24h) { return Some(本地缓存); }
if let Ok(resp) = ureq::get(url).timeout(10s).call() {
if 拉到的是合法 JSON { 写盘; return Some(文本); }
}
fs::read_to_string(缓存路径).ok() // 过期也读,离线兜底
}查表分两步走,先精确 id,再归一化 id:
rust
fn lookup(&self, model: &str) -> Option<&ModelPrice> {
if let Some(p) = self.exact.get(model) {
return Some(p);
}
self.norm.get(&normalize_key(model))
}归一化干两件事,去掉厂商路径前缀,再把点统一换成 p。于是 z-ai/glm-5.1、glm-5.1、glm-5p1 全部坍缩成同一个 key glm-5p1:
rust
fn normalize_key(s: &str) -> String {
let base = s.rsplit('/').next().unwrap_or(s);
base.to_lowercase().replace('.', "p")
}还有个细节。models.dev 里同一个模型可能同时有带前缀和裸名两种 id。我让裸名优先,排序时把 contains('/') 的排到后面,保证官方裸名价在冲突时赢。日志里就是裸名,官方价最权威。
至于两个源都查不到的模型,UI 会保留它的 token 统计,只是标一个「暂无定价」,每个模型都带一个 priced 标记。数字是真的,只是暂时算不出钱,不至于因为查不到价就把统计删了。
只统计你自己的 MCP 和 Skill
工具调用的分类也得讲究,不然数字会被 Claude 内置工具污染。
MCP 这边。日志里工具名长这样 mcp__<server>__<tool>,先拆出 server,再查它是不是在你自己的 ~/.claude.json 里(顶层 mcpServers 加上各 project 下的 mcpServers)。在白名单里才算你的一次 MCP 调用,否则忽略。这样 Anthropic 自带的那些 server 就不会混进统计。
rust
let name = block.get("name").and_then(|n| n.as_str()).unwrap_or("");
if let Some(rest) = name.strip_prefix("mcp__") {
mcp.push(rest.split("__").next().unwrap_or("").to_string());
}
// 后面在 compute_event 里用 cfg.is_user_mcp() 过滤Skill 这边有两条路,这是另一个我踩的坑。一条是模型主动调,Skill 工具的 tool_use,skill 名在 input.skill 里。另一条是你手敲斜杠命令,比如 /find-skills。这条在日志里根本不是 tool_use,是一条 user 消息,带个 <command-name>/find-skills</command-name> 标签。两条路都得认,不然斜杠命令触发的 Skill 永远统计不上。
踩过的坑,挑几个说
开发期间我记了 13 个 bug,完整的在仓库 docs/BUGFIXES.md。这里挑几个最能说明问题的。
一个百分号公式差点让指标凭空消失。 Day 视图里 Total tokens 旁边的环比百分比一直不显示。找了半天,原公式是 ((cur-prev)/prev*100).round()/100。问题在于它先乘 100 又除 100,正好抵消,返回的是个小数,比如 0.2,而不是百分比 20。UI 再对它取整,0.2 变成 0%,触发「为零就隐藏」,指标直接没了。改成 ((cur - prev) / prev * 10000.0).round() / 100.0,返回真正的两位小数百分比才好。这种比率公式写完一定要拿真实数字验算一遍,别被乘除对称的假象骗了。
斜杠命令触发的 Skill 不被统计。 用 /find-skills 调的 Skill 从来不出现,计数反而卡在一个八竿子打不着的旧 Skill 上。原因是斜杠命令在日志里是 user 消息加 <command-name> 标签,不是 tool_use,原解析只看 tool_use,这类调用永远隐形。那个卡住的旧 Skill 是之前一次真实的 Skill 调用,恰好落在可见时间窗里。修法是单写一条 parse_user_command 路径,从 <command-name> 标签里抠出 skill 名。这类事件没有 model 也没有 token,所以聚合时得判断 model 是不是空,不然会凭空多出一个 request 或一个没名字的模型。
rust
// store.rs
"user" => parse_user_command(&v),
// parser.rs: Agg.add 里
if !e.model.is_empty() { // 空 model = 非 LLM 请求
self.requests += 1;
*self.model_tok.entry(e.model.clone()).or_default() += ...;
}一条消息跨多行,tool_use 被去重逻辑丢了。 就是上一节详细讲的那个。教训值得再说一遍:去重的时候想清楚丢弃的粒度,会不会把只在某一行才有的附带信息一起扔了。保险的做法是合并字段,不是整行扔。
GitHub Release 看着没产物,因为它是 draft。 构建其实是成功的,dmg 和 app.tar.gz 也确实传上去了,可 draft release 对公众不可见,资产 URL 返回 404,Homebrew 自然下载不到。而且这些产物不会出现在 Actions 的 Artifacts 里,因为 tauri-action 是上传到 Release 而不是 workflow artifact。把 releaseDraft 设成 false 就好了。
Homebrew cask 把一个 404 页面算成了 sha256。 这个是潜在隐患。cask 脚本用 curl -sL(没加 f)拉资产,404 时 curl 还是返回 0,于是 GitHub 的错误 HTML 被当成 dmg 算进了校验和,brew install 时报 sha256 mismatch。改成 curl -fsSL,加 f 让 HTTP 错误直接失败,资产一直不出现就 exit 1。
打包分发那块还有一组有意思的。未签名应用被 Gatekeeper 拦(cask 里加个 postflight 跑 xattr -cr 解决),重装后菜单栏出现两个图标(加 tauri-plugin-single-instance),DMG 命名跟 tag 对不上导致 404(要同步改 package.json、tauri.conf.json、Cargo.toml 三处版本号)。完整故事在仓库的 docs/BUGFIXES.md。
回头看:把事实和派生分开
整个数据层我觉得最值钱的一个决定,是把「跟配置和价格无关的原始事实」跟「依赖当前配置和价格的派生结果」分成两层。
RawEvent 只存事实:时间、模型、四类 token、调了哪些工具。它在 ingest 时落盘,之后基本不动,除非解析逻辑升级触发重扫。Event 是每次请求现算的,套上当前的白名单、当前的价格、当前的时间窗。Dashboard 就是 Day/Week/Month 加热力图,发给前端。
为什么 Event 不落盘、每次现算?因为用户配置、模型价格、当前时间这三样都是会变的。你今天新装一个 MCP,过去所有调用过它的消息应该立刻出现在统计里。价格源 24 小时刷新一次,刷完历史成本应该用新价重算。Day/Week/Month 的窗口是相对于现在,每次打开面板都得重切。要是把派生结果固化进缓存,随便哪个条件变了都得想办法重算,不如每次从事实现算。RawEvent 只在 ingest 时持久化,体量小增长慢,Event 是纯函数计算,成本完全可控。
这个分开,就是「装个 MCP 立刻生效、刷个价立刻生效」能成立的根本。
最后
做完这个小东西,比起多会了一个 Tauri,我觉得更值钱的是这几条踩出来的经验。增量读取得处理写一半的尾行,只截到最后一个换行符。去重要想清楚粒度,message.id 相同不代表附带信息也重复,合并字段比整行丢弃安全。计价要严格对应 token 类型,cache 命中按 0.1 倍算,不然成本会高得离谱。价格匹配要分层兜底加归一化,事实层和派生层要分开,那些可变的东西留到每次现算。还有百分比公式写完一定用真实数字验算。
工具是开源的。你要也在用 Claude Code,想知道自己每天到底烧了多少 token,可以装来试试:
bash
brew install --cask hdusy/tokenscope/tokenscope完整的 Bug Log 在 docs/BUGFIXES.md。日志解析、增量去重、Tauri 菜单栏这些问题,评论区聊。