USART串口数据包
那先看一下HEX数据包格式。首先,数据包的作用是把一个个单独的数据给打包起来,方便我们进行多字节的数据通信啊。我们之前学习了串口的代码,发送一个字节,接收一个字节都没问题。但在实际应用中,我们可能需要把多个字节打包为一个整体进行发送。
比如说我们有个陀螺仪传感器,需要用串口发送数据到 STM32。陀螺仪的数据,比如 X 轴一个字节, Y 轴一个字节, Z 轴一个字节,总共三个数据,需要连续不断的发送。当你像这样 XYZ XYZ XYZ 连续发送的时候,就会出现一个问题,就是接收方他不知道这数据哪个对应 X 哪个对应 Y 哪个对应 Z。因为接收方可能会从任意位置开始接收,所以会出现数据错位的现象。这时候我们就需要研究一种方式 4,把这个数据进行分割,把 XYZ 这一批数据分割开,分成一个个数据包,这样再接收的时候就知道了,数据包的第一个数据就是 X, 第二个是 Y, 第三个是 Z。 这就是数据包的任务,就是把属于同一批的数据进行打包和分割,方便接收方进行识别。那有关分割打包的方法,可以是自己发挥想象力来设计哈,只要逻辑行得通就行。
比如我可以设计,在这个 XYZXYZ 数据流中,数据包的第一个数据也就是 X 的数据包它的最高位置一,其余数据包最高位都置零。当我接收到数据之后,判断一下最高位,如果是一,那就是 X 数据,然后紧跟着的两个数据就分别是 Y 和 Z。 这就是一种可行的分割方法啊,这种方法就是把每个数据的最高位当做标志位来进行分割的。实际也有应用的例子啊,比如 UTF 8 的编码方法,和这就是类似的啊,不过它那个编码更高级一些啊,感兴趣的话可以了解一下。
那本节我们主要讲的数据包分割方法,并不是在数据的高位添加标志位这种方式啊,因为这种方式破坏了原有数据,使用起来比较复杂。我们串数据包通常使用的是额外添加包头包尾这种方式。
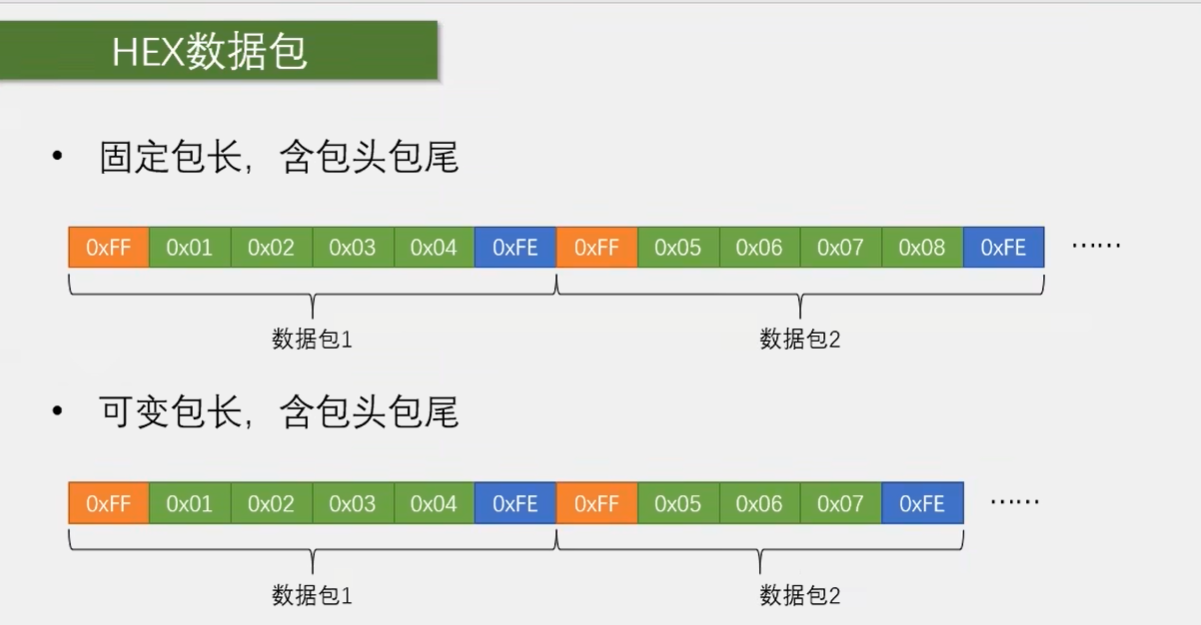
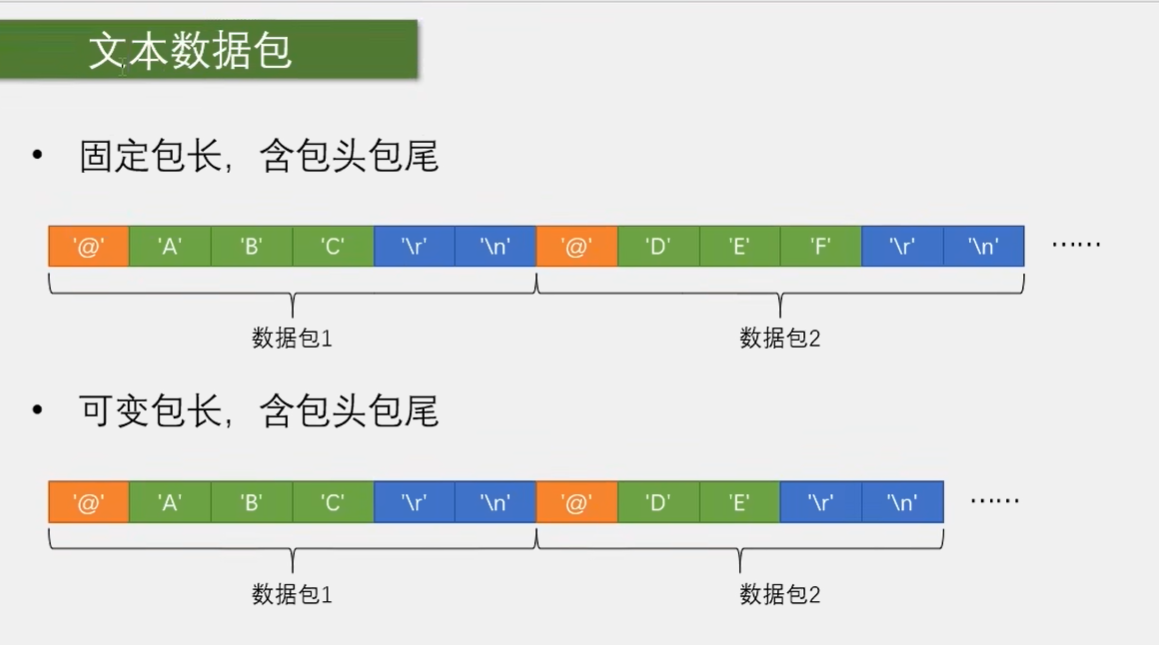
比如我这里就列举了两种数据包格式。第一种是固定包长,含包头包尾。也就是每个数据包的长度都固定不变。数据包前面是包头,后面是包尾。第二种是可变包长,含包头包尾。也就是每个数据包的长度可以是不一样的,前面是包头,后面是包尾。它们的数据包格式啊,可以是用户根据需求自己规定的,也可以是你买个模块,别的开发者规定的。
那我这里规定是,比如固定包长这里我一批数据规定有四个字节,在这四个字节之前加个包头,比如我定义 0xFF 为包头。在四个字节之后加一个包尾,比如我定义 0xFE 为包尾。那当我接收到 0xFF 之后,我就知道了,一个数据包来了。接着我再接收到的四个字节,就当做数据包的第一二三四,个数据存在个数组里,最后跟一个包尾。当我收到 0xFE 之后,就可以自己一个标志位,告诉程序我收到了一个数据包。然后新的数据包过来,再重复之前过程,这样就可以在一个连续不断的数据流中分割出我们想要的数据包了。这就是通过添加包头包尾实现数据分割打包的思路啊。
接着我们来研究几个问题啊:
第一个问题就是包头包尾和数据载荷重复的问题。这里定义 FF 为包头, FE 为包尾。如果我传输的数据本身就是 FF 和 FE 怎么办呢?那这个问题确实存在,如果数据和包头包尾重复,可能会引起误判啊。
对应这个问题我们有如下几种解决方法,第一种,限制载荷数据的范围。如果可以的话,我们可以在发送的时候对数据进行限幅。比如 XYZ 三个数据变化范围都可以是 0~100,那就好办了,我们可以在载荷中只发送 0~100 的数据,这样就不会和包头包尾重复了。
第二种,如果无法避免载荷数据和包头包尾重复,那我们就尽量使用固定长度的数据包哈,这样由于载荷数据是固定的,只要我们通过包头包尾对齐了数据,我们就可以严格知道哪个数据应该是包头包尾,哪个数据应该是载荷数据,在接受载荷数据的时候,我们并不会判断它是否是包头包尾,而在接受包头包尾的时候,我们会判断它是不是确实是包头包尾,用于数据对齐哈。这样在经过几个数据包的对齐之后,剩下的数据包应该就不会出现问题了。
第三种就是增加包头包尾的数量,并且让它尽量呈现出载荷数据出现不了的状态。比如我们使用 FF FE 作为包头, FD FC 作为包尾,这样也可以避免载荷数据和包头包尾重复的情况发生哈。
接着第二问题是这个包头包尾并不是全部都需要的哈。比如我们可以只要一个包头,把包尾删掉。这样数据包的格式就是一个包头 FF 加四个数据,这样也是可以的哈。当检测到 FF 开始接收,收够四个字节后,字标多位,一个数据包接收完成。这样也可以,不过这样的话载荷和包头重复的问题会更严重一些。比如最严重的情况下,我载荷全是 FF,包头也是 FF,那你肯定不知道哪个是包头了。而加上 FE 作为包尾,无论数据怎么变化,都是可以分辨出包头包尾的哈。
之后第三个问题就是固定包长和可变包长的选择问题。对应 hex 数据包来说,如果你的载荷会出现和包头包尾重复的情况,那就最好选择固定包长哈,这样可以避免接受错误。如果你又会重复又选择可变包长,那数据很容易就乱套了哈。如果载荷不会和包头包尾重复,那可以选择可变包长。数据长度像这样,四位啊,三位啊,等等,一位,十位,来回任意变肯定都没问题。因为包头包尾是唯一的,只要出现包头就开始数据包,只要出现包尾就结束数据包,这样就非常灵活了哈。这就是固定包长和可变包长选择的问题。
最后一个问题就是各种数据转换为字节流的问题。这里数据包都是一个字节一个字节组成的哈。如果你想发送 16 位的整形数据,32 位的整形数据, float,double,甚至是结构体,其实都没问题啊,因为它们内部其实都是由一个字节一个字节组成的。只需要用一个 unit 8 杠 t的指针指向它,把它们当做一个字节数组发送就行了。
这个操作方法我在指针教程里也讲过哈,不会的话可以去看一下。有关 hex 数据包定义的内容我就讲这么多啊。
接下来看一下文本数据包。文本数据包和 hex 数据包就分别对应了文本模式和 hex 这两种模式啊。在 hex 数据包里面,数据都是以原始的字节数据本身呈现的。而在文本数据包里面,每个字节就经过了一层编码和译码,最终表现出来的就是文本格式啊。但实际上每个文本字符背后其实都还是一个字节的 hex 数据对吧。
那么看一下,这里我同样给出了固定包长和可变包长这两种模式。由于数据译码成了字符形式,这就会存在大量的字符可以作为包头包围它。可以有效避免载荷和包头包尾重复的问题。比如我这里规定的就是以@这个字符作为包头,以反斜杠 r 反斜杠 n 也就是换行啊,这两个字符作为包围。在载荷数据中间可以出现除了包头包尾的任意字符,这很容易做到哈。所以文本数据包基本不用担心载荷和包头包尾重复的问题,使用非常灵活。可变包长啊,各种字母啊符号数字都可以随意使用哈。当我们接收到载荷数据之后,得到的就是一个字符串,在软件中再对字符串进行操作和判断,就可以实现各种指令控制的功能了。而且字符串数据包表达的意义很明显啊,可以把字符串数据包直接打印到串口助手上,什么指令什么数据,一眼就能看明白啊。所以这个文本数据包通常会以换行作为包围,这样在打印的时候就可以一行一行的显示了,非常方便。
那 hex 数据包和文本数据包这两种对比下来,其实也是各有优缺点啊。
hex 数据包优点是传输最直接,解析数据非常简单,比较适合一些模块啊发送原始的数据,比如一些使用串口通信的陀螺仪啊温湿度传感器啊。缺点就是灵活性不足啊,载荷容易和包头包尾重复。
文本数据包呢,优点是数据直观易理解,非常灵活,比较适合一些输入指令进行人机交互的场合。比如蓝牙模块常用的 AT 指令, CNC 和 3D 打印机常用的 G 代码,都是文本数据包的格式。那缺点就是解析效率低,比如你发送的数 100, HEX 数据包就是一个字节 100 完事。文本数据包就得是三个字节的字符 100 收到之后还要把字符转换成数据才能得到 100。所以说我们需要根据实际场景来选择和设计数据包格式哈。好,数据包格式的定义讲完了,
接下来我们就来学一下数据包的收发流程。首
首先是数据包的发送,其实数据包的发送非常简单哈,不用说大家应该也都能想到。在 hex 数据包这里,我如果想发送这样一个数据包,就定义一个数组,填充数据,然后用上小节我们写过的 send array 一发就完事了,对吧?文本数据包这里也很简单,写一个字符串,然后调用 send string 一发送也完事了,对吧?所以说发送这个数据包是很简单的,因为发送过程是完全自主可控的,想发啥就发啥。我们写代码的时候也能感受到哈,串组发送比接收简单多了。
那接下来接收一个数据包,这就比较复杂了,我们来学习一下。我这里演示了固定包长 HEX 数据包的接收方法,和可变包长文本数据包的接收方法。其他的数据包也都可以套用这个形式。等会我们写程序就会根据这里面的流程来。
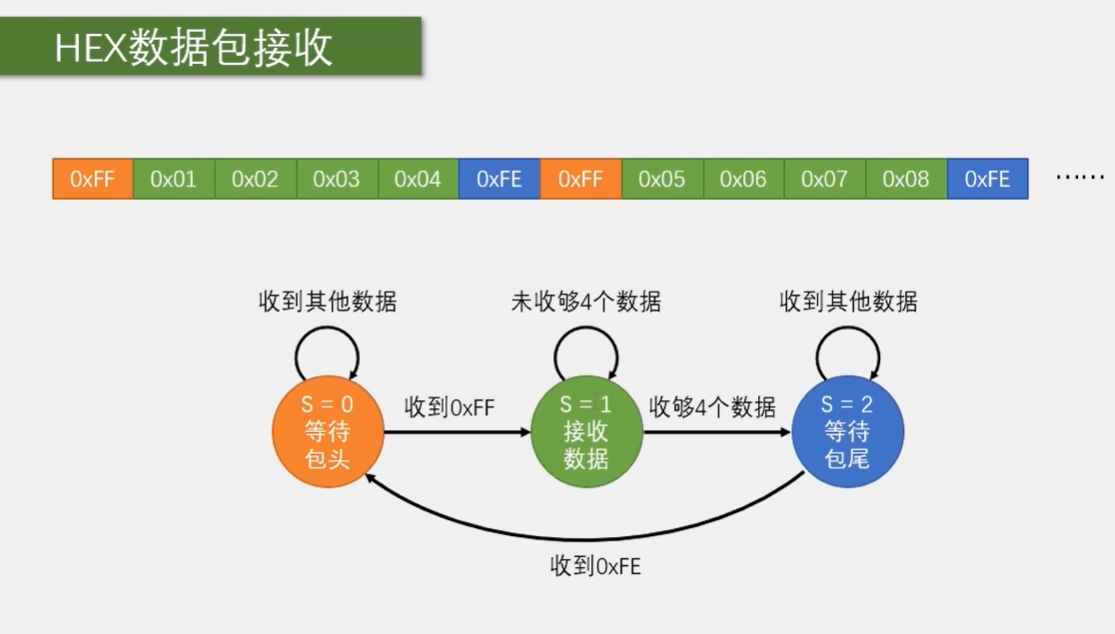
我们先看一下如何来接收这个固定包长的 Hive 数据包。首先根据之前的代码我们知道,每收到一个字节,程序都会进一遍中断。在中断函数里,我们可以拿到这一个字节。但拿到之后我们就得退出中断了,所以每拿到一个数据都是一个独立的过程。而对于数据包来说,很明显它具有前后关联性,包头之后是数据,数据之后是包尾。对于包头数据和包尾这三种状态,我们都需要有不同的处理逻辑,所以在程序中我们需要设计一个能记住不同状态的机制。在不同状态执行不同的操作,同时还要进行状态的合理转移哈。这种程序设计思维就叫做状态机。
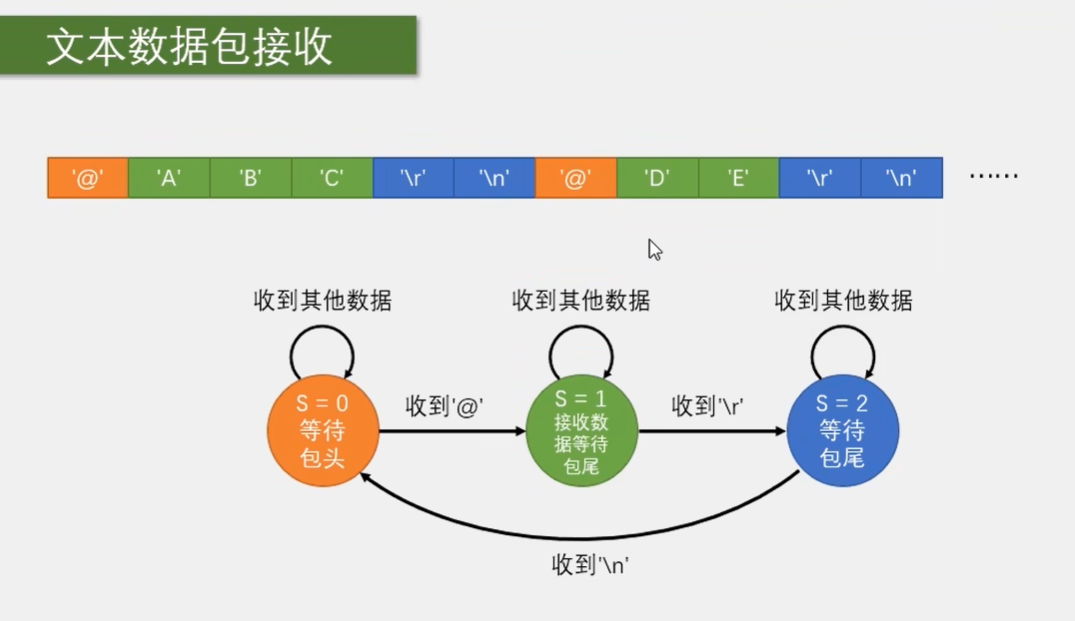
在这里我们就使用状态机的方法来接受一个数据包。要想设计一个好的状态机程序,画一个这样的状态转移图是必要的哈。我们看一下。对于上面这样一个固定包长 Hive 数据包来说,我们可以定义三个状态。第一个状态是等待包头,第二个状态是接收数据,第三个状态是等待包尾。每个状态需要用一个变量来标志一下,比如我这里用变量 s 来标志。三个状态依次为 S 等于 0, S 等于 1, S 等于 2。这一点类似于置标志位哈,只不过标志位只有 0 和 1,而状态机是多标志位状态的一种方式哈。
然后执行流程是,最开始 S 等于 0,收到一个数据进中断,根据 S 等于 0 进入第一个状态的程序,判断数据是不是包头 FF, 如果是 FF, 则代表收到包头,之后置 S 等于 1,退出中断,结束。这样下次再进中断,根据 S 等于 1 就可以进行接收数据的程序了。在第一个状态如果收到的不是 FF, 就证明数据包没有对齐哈,我们应该等待数据包包头的出现。这时状态就仍然是 0,下次进中断就还是判断包头的逻辑,直到出现 FF, 才能转到下一个状态。
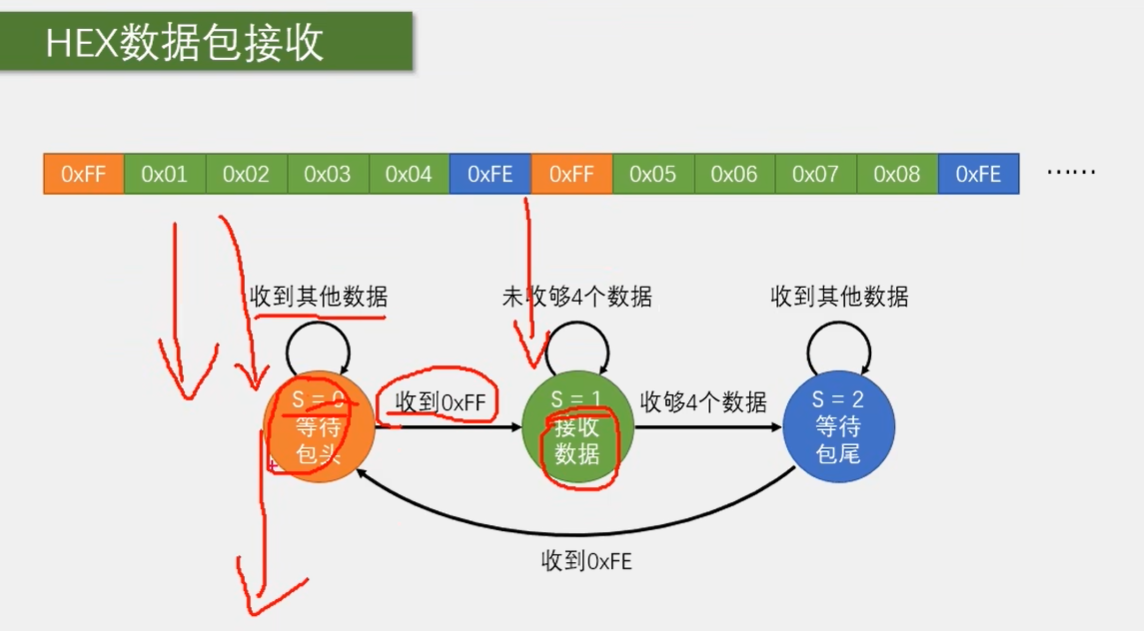
那之后出现了 FF, 我们就可以转移到接收数据的状态。这时再收到数据,我们就直接把它存在数组中。另外再用一个变量记录收了多少个数据,如果没收够 4 个数据,就一直是接收状态,如果收够了,就置 S 等于 2。下次进入段时就可以进入下一个状态了。
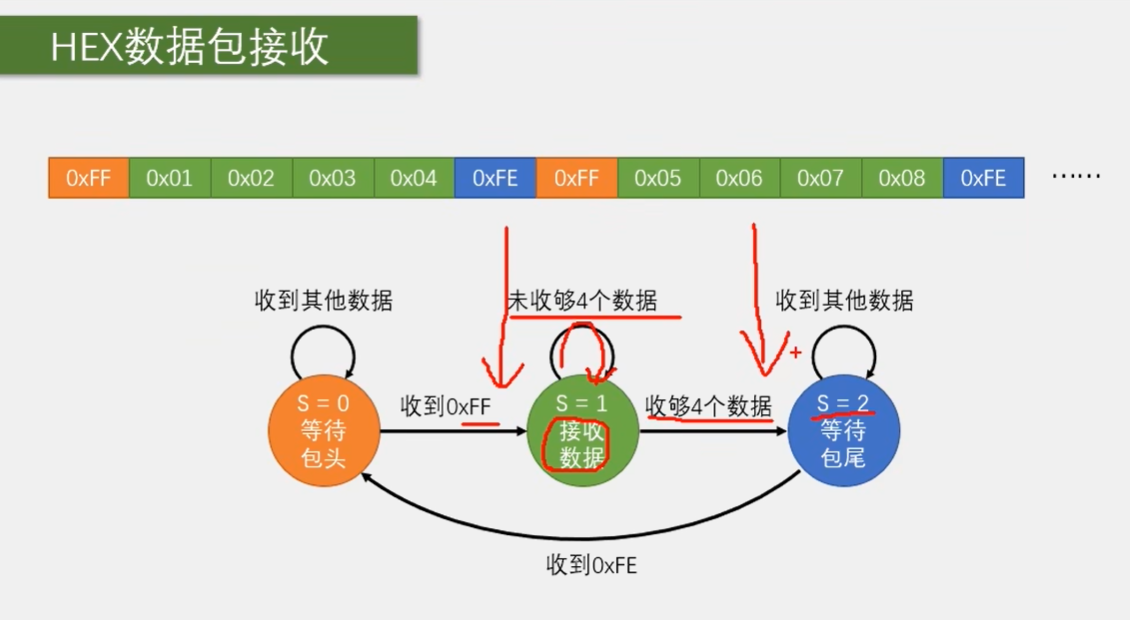
那最后一个状态就是等待包尾了。判断数据是不是 FE, 正常情况应该是 FE 啊,这样就可以置 S 等于 0,回到最初的状态,开始下一个轮回。当然也有可能这个数据不是 FE, 比如数据和包头重复导致包头位置判断错了,那这个包尾位置就有可能不是 F1。这时就可以进入重复等待包尾的状态,直到接收到真正的包尾。这样加入包尾的判断,更能预防因数据和包头重复造成的错误哈。
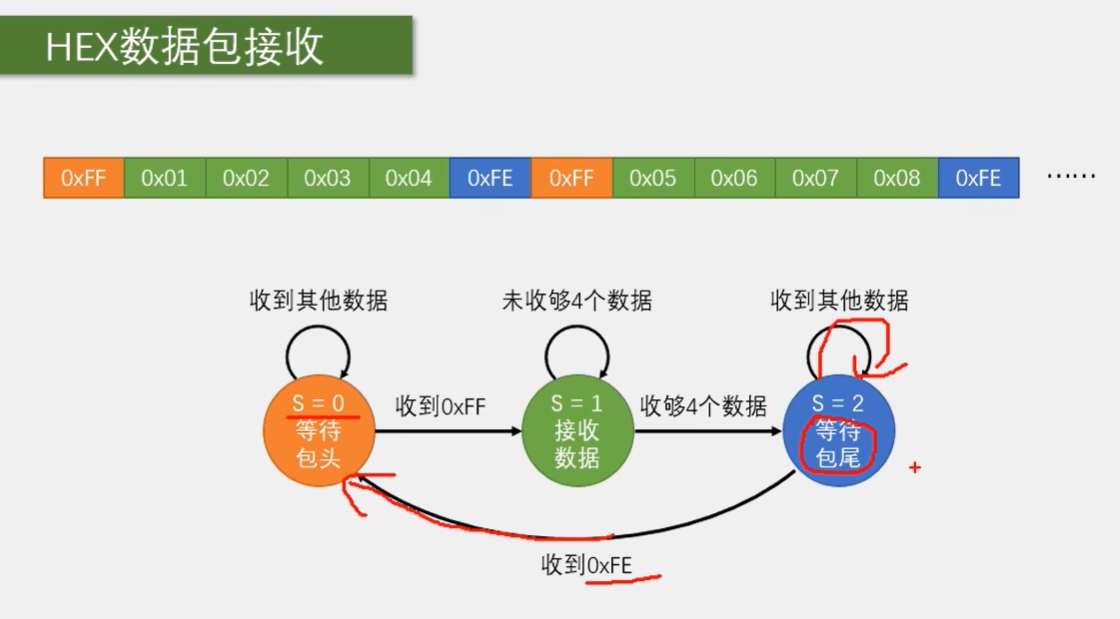
这就是使用状态机接收数据包的思路。这个状态机其实是一种很广泛的编程思路哈,在很多地方都可以用到。使用的基本步骤是,先根据项目要求定义状态,画几个圈哈。然后考虑好各个状态在什么情况下会进行转移,如何转移画好线和转移条件,最后根据这个图来进行编程,这样思维就会非常清晰了哈。比如你要做个菜单,就可以用到状态机的思维,按什么键切换什么菜单,执行什么样的程序。还一些芯片内部逻辑哈,也会用到状态机,比如芯片什么情况下进入待机状态,什么情况下进入工作状态,这也是状态机的应用哈,希望大家可以研究一下,对你的编程肯定会有帮助。
那接下来继续,我们来看一下这个可变包长文本数据包的接收流程,同样也是利用状态机,定义三个状态。第一个状态等待包头,判断收到的是不是我们规定的艾特符号。如果收到艾特,就进入接收状态。在这个状态下依次接收数据。同时这个状态还应该要兼具等待包尾的功能。因为这是可变包长,我们接收数据的时候也要时刻监视是不是收到包尾了,一旦收到包尾了就结束。那这里这个状态的逻辑就应该是,收到一个数据,判断是不是杠 r,如果不是则正常接收,如果是则不接收,同时跳到下一个状态,等待包尾杠 n,因为这里数据包有两个包尾,杠 r 杠 n, 所以需要第三个状态。如果只有一个包尾,那在出现包尾之后就可以直接回到初始状态了啊,只需要两个状态就行,因为接收数据和等待包尾需要在一个状态里同时进行啊。由于串口的包头包尾不会出现在数据中,所以基本不会出现数据错位的现象啊。这就是使用状态机接收文本数据包的方法。