目录
[一、什么是Ollama, LLama Factory](#一、什么是Ollama, LLama Factory)
[1. Ollama:本地大模型运行器](#1. Ollama:本地大模型运行器)
[2. Qwen、Gemma、DeepSeek:模型本身](#2. Qwen、Gemma、DeepSeek:模型本身)
[3. Miniconda:Python 环境管理工具](#3. Miniconda:Python 环境管理工具)
[4. PyTorch:训练和推理的计算库](#4. PyTorch:训练和推理的计算库)
[5. LLaMA-Factory:大模型微调框架](#5. LLaMA-Factory:大模型微调框架)
[二、Ollama 本地部署](#二、Ollama 本地部署)
[安装 LLaMA-Factory](#安装 LLaMA-Factory)
今天在自己的 Windows 电脑上搭建一套本地大模型学习环境,所以记录一次真实搭建过程。
我的笔记本环境为:
-
Windows
-
NVIDIA RTX 4060 8GB
-
已安装 Ollama
-
使用 Miniconda 管理 Python 环境
-
使用 LLaMA-Factory 学习模型微调
如果看本文教程并进行学习部署, 请先更新电脑nvidia studi驱动为最新版。
一、什么是Ollama, LLama Factory
1. Ollama:本地大模型运行器
Ollama 可以理解成一个本地大模型运行平台,把已经训练好的模型下载到电脑上,然后在本机运行起来,我们可以直接调用。Ollama 会负责下载模型、加载模型、启动推理服务,并在本地提供 API。
2. Qwen、Gemma、DeepSeek:模型本身
Qwen、Gemma、DeepSeek 这些名字,指的是模型系列。
不同模型对应有不同的参数类型, 比如:
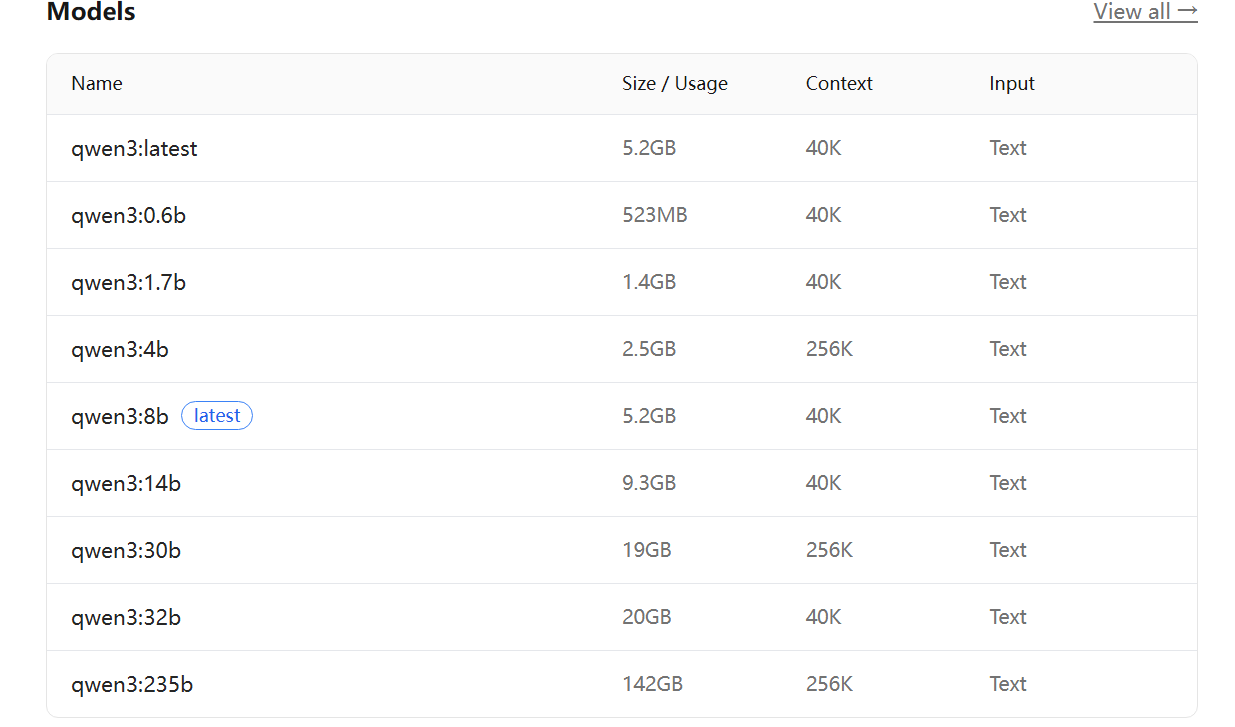
其中4b就是表示 40 亿参数规模。对于我本机RTX 4060 8GB的GPU来说,4B 模型比较适合作为入门选择。
3. Miniconda:Python 环境管理工具
Miniconda 它的作用是管理 Python 环境, 为每个项目创建独立环境:
Go
base
├── llamafactory
├── agent
└── rag像这样 LLaMA-Factory 用自己的依赖,Agent 项目用自己的依赖,RAG 项目也用自己的依赖,互不干扰。
4. PyTorch:训练和推理的计算库
PyTorch 是深度学习框架,负责底层张量计算、GPU 加速、模型训练等能力。如果说 LLaMA-Factory 是一个微调工具平台,那么 PyTorch 就是它底层真正干计算活的基础库,尤其是使用 NVIDIA 显卡时,需要安装支持 CUDA 的 PyTorch,这样训练或推理时才能调用 GPU。
5. LLaMA-Factory:大模型微调框架
LLaMA-Factory 是一个大模型微调框架,上面Miniconda,PyTorch就是运行LLaMA-Factory所需要的依赖。LLaMA-Factory可以不用写训练脚本,也能方便地对 Qwen、DeepSeek 等模型做 SFT、LoRA、QLoRA、DPO 等算法微调。
它还提供 WebUI,所以新手可以先通过页面理解模型、数据集、训练参数和导出流程。
简单说:
-
想运行模型,用 Ollama
-
想训练或微调模型,用 LLaMA-Factory
-
想管理 Python 依赖,用 Miniconda
-
想调用 GPU 做训练计算,用 PyTorch
二、Ollama 本地部署
下载Ollama: Download Ollama on Windows
下载完成之后运行OllamaSetup.exe文件然后一直Next下一步即可, 下载完 Ollama 时,页面里会看到很多模型、智能体或者带有cloud标识的东西。
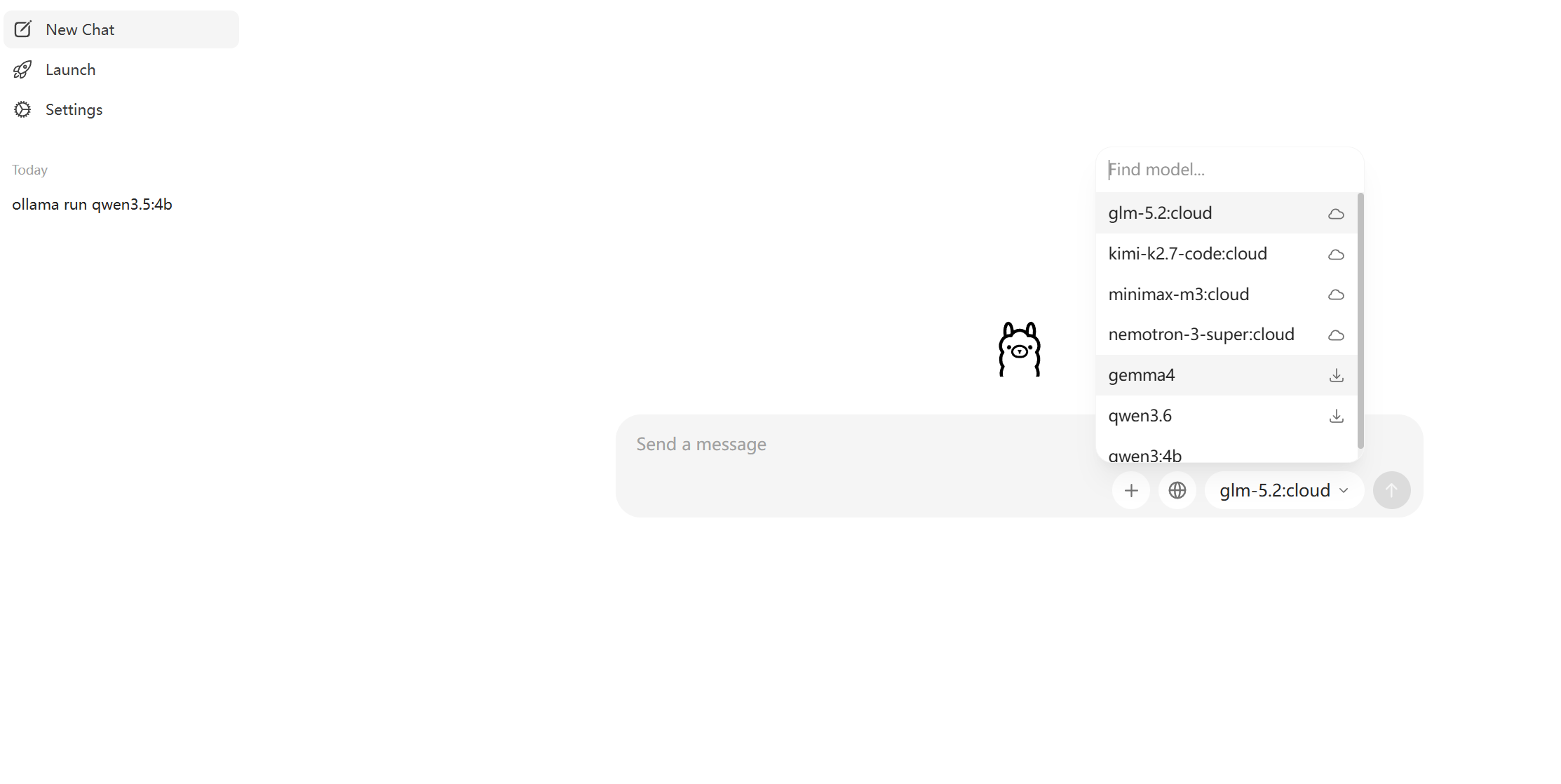
这里要先区分两件事:
-
Ollama Cloud:模型运行在云端,会涉及云服务额度
-
Ollama 本地模型:模型权重下载到本机,在本机 GPU 上推理
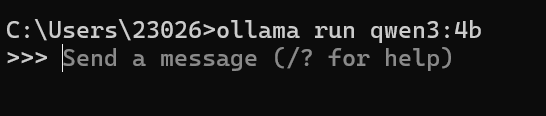
真正的本地模型通常是通过命令下载和运行的,例如:
bash
ollama run qwen3:4b如果本地没有这个模型,ollama run会先下载模型;如果已经下载过,就会直接加载本地模型并进入聊天界面。这里我下载过了直接可以交流了:
可以用下面的命令查看本地已经下载的模型:
bash
ollama list如果看到下面这样的输出,就说明模型已经在本机了:
三、安装LLaMA-Factory
安装Miniconda
-
首先安装python环境, 此处略过
-
安装Miniconda: Download Success | Anaconda
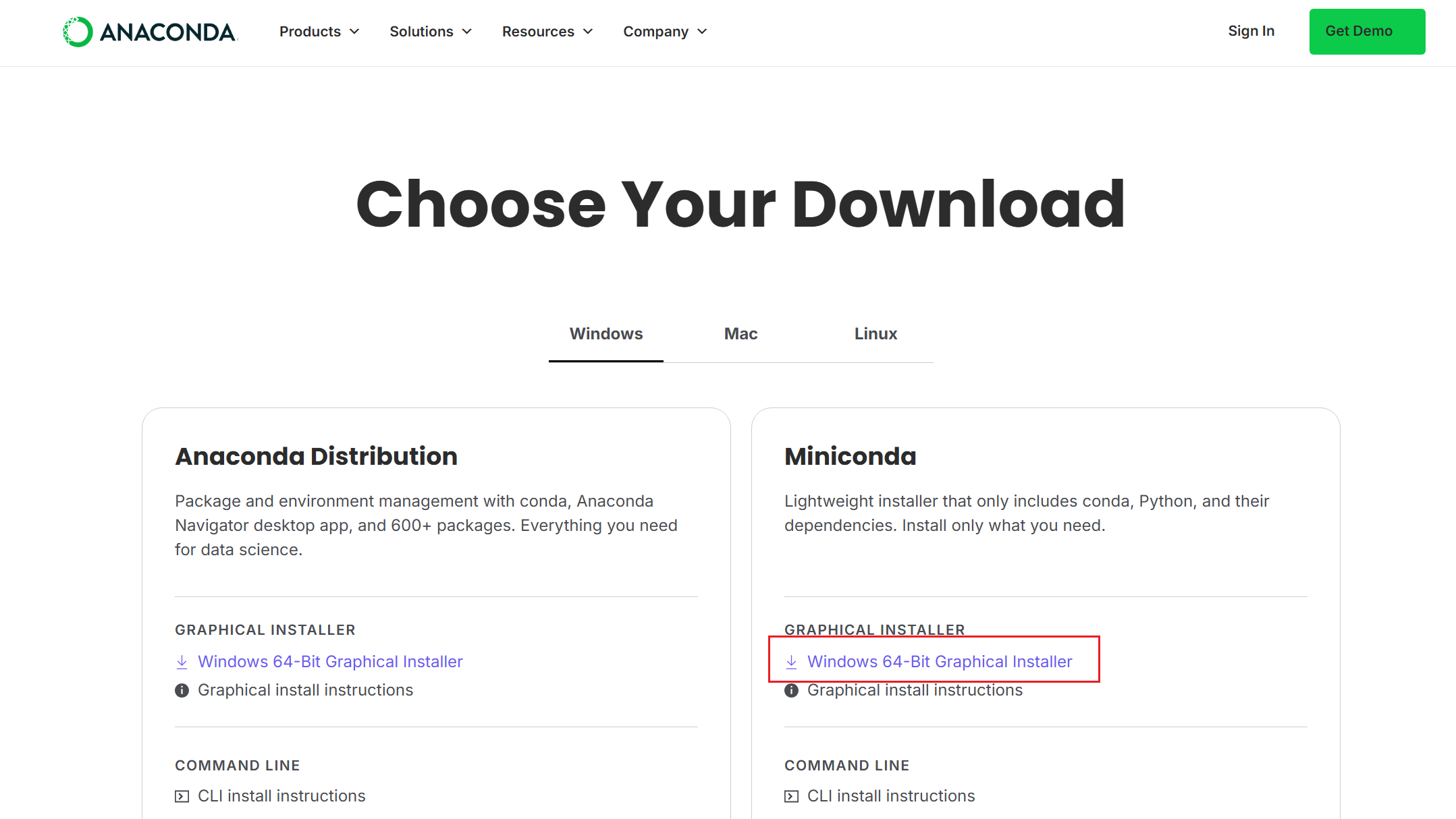
点击下载之后运行Miniconda3-latest-Windows-x86_64.exe文件, 依旧Next即可。
安装成功之后win键搜索Anaconda Prompt打开
输入:
bash
conda --version得到如下结果

安装成功
创建python环境
如果已经把 Conda 的环境目录配置到了 D 盘,可以直接用 -n 创建命名环境:
bash
conda create -n llamafactory python=3.11如果想明确指定环境路径,也可以使用 -p:
bash
conda create -p D:\baibaoplus\Miniconda\envs\llamafactory python=3.11执行后会有一些服务条款, 一直accept就行
-n 和 -p 的区别是:
| 参数 | 含义 | 示例 |
|---|---|---|
-n |
按环境名称创建 | conda create -n llamafactory python=3.11 |
-p |
按完整路径创建 | conda create -p D:\baibaoplus\Miniconda\envs\llamafactory python=3.11 |
如果用 -p 创建环境,激活时也要使用完整路径:
bash
conda activate D:\baibaoplus\Miniconda\envs\llamafactory安装PyTorch
安装PyTorch之前先看一下自己显卡CUDA驱动版本, 可以通过nvidia-smi命令查看
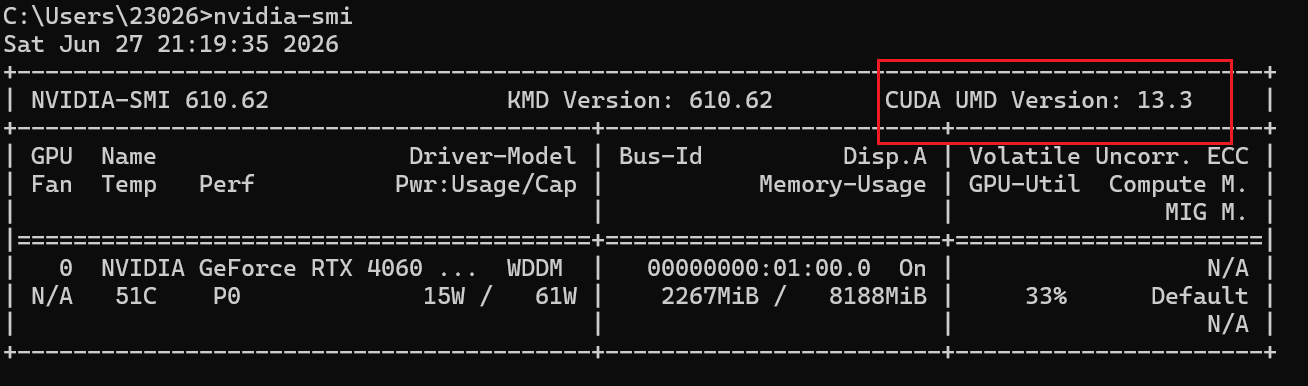
然后安装 PyTorch 官方当前 Stable 对应的 CUDA 版本。
我这是12.4兼容13.3version
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124验证 GPU 是否可用
bash
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))输出(验证本机硬件信息):
bash
Driver Version : 610.62
CUDA UMD : 13.3
GPU : RTX 4060 8GB安装 LLaMA-Factory
bash
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"启动:
llamafactory-cli webui
XML
(llamafactory) C:\Users\23026>llamafactory-cli webui
Visit http://ip:port for Web UI, e.g., http://127.0.0.1:7860
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.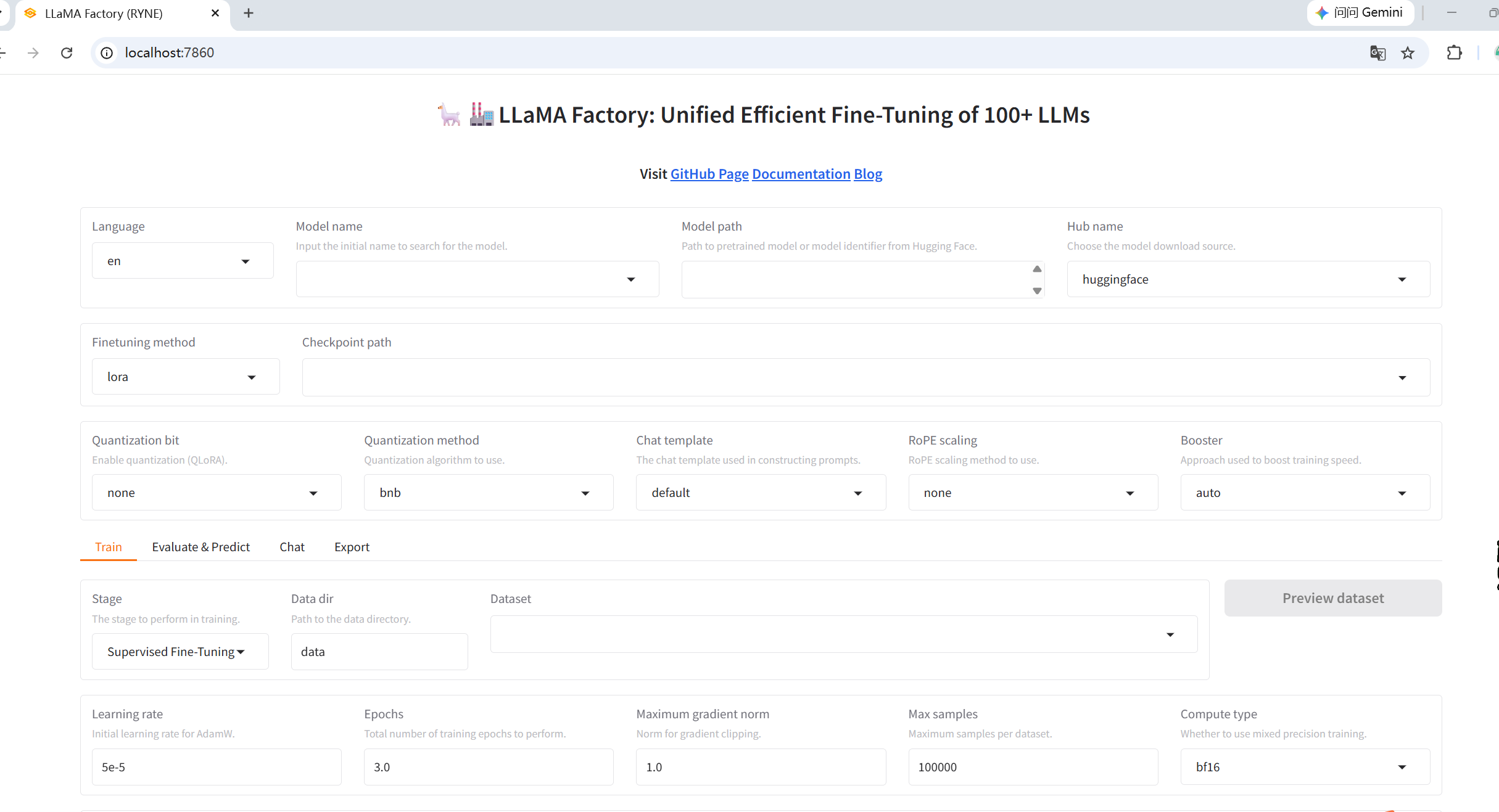
浏览器端口7860被访问到,页面展示即安装成功,接下来就是参数微调,下篇续写。
参考资料
-
Ollama Windows 官方文档:Windows - Ollama
-
LLaMA-Factory 官方文档:https://llamafactory.readthedocs.io/en/latest/
-
PyTorch 官方安装页:https://pytorch.org/get-started/locally/
-
LLaMA-Factory GitHub Releases:Releases · hiyouga/LlamaFactory · GitHub