1 基础知识
1.1 存储基础
我们知道,对于一个计算机设备而言,其存储功能是非常重要的,也就是说,任何一台电脑上,必须包含一个设备 ------ 磁盘。这个磁盘就是用于存储数据的
常见的的存储设备接口:
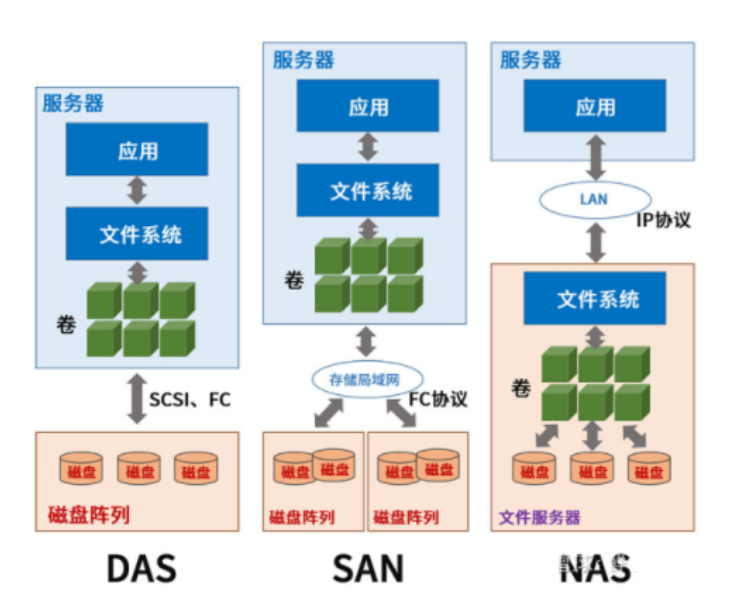
1.1.1 DAS:Direct-Attached Storage,直连存储
DAS设备:IDE、SATA、SCSI、SAS、USB
无论是以上哪种接口,都是存储设备驱动下的磁盘设备。存储设备直接挂在一台服务器上,中间没有其他网络
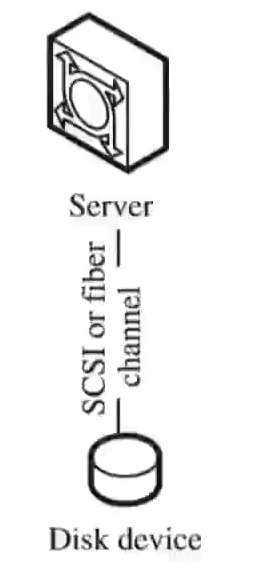
典型形式:
- 服务器主板插的SATA/NVMe盘
- 服务器通过 SAS 线缆外接一台磁盘柜
- 连接方式:PCIe/SATA/SAS/NVMe,这些本地总线协议
对于OS来说,/dev/sda、/dev/nvme0n1,这些盘就是这台集群的,别的机器看不见也挂不上。
特点一句话:简单、快、便宜但不能共享
1.1.2 SAN:Storage Area Network,存储区域网络
SAN设备:SCSI协议、FC SAN、iSCSI
把"盘"从服务器里抽出来,变成独立的一堆存储阵列,服务器通过一张"专用网络 "去访问那些盘,对 OS 看来还是 /dev/sdX块设备
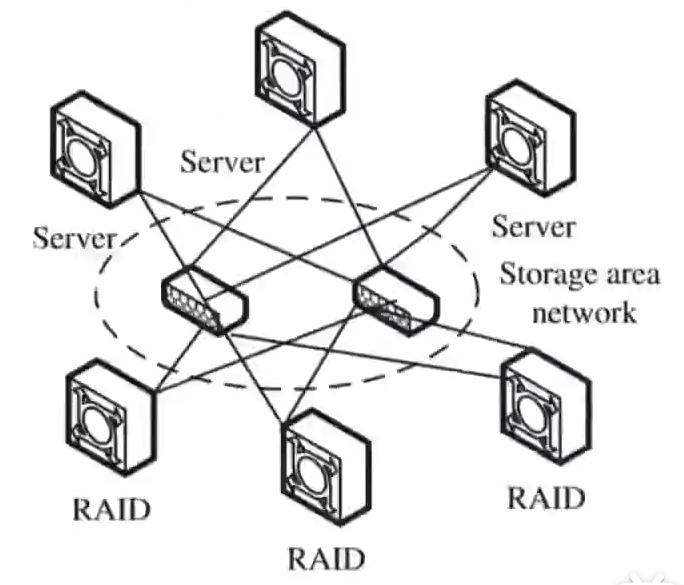
典型形式:
- 存储阵列厂商的硬件:EMC Symmetrix/VMAX、NetApp FAS、Huawei OceanStor、Hitachi VSP......
- 服务器插 HBA 卡(Host Bus Adapter) → 光纤交换机 → 存储阵列
- 协议:传统是 FC(Fibre Channel,光纤通道) ,后来也有 iSCSI(跑 IP 网络) 、FCoE 、NVMe-oF
对于OS来说 ,列阵里划的是LUN(Logical Unit Number)映射过来,变成/dev/sdb ------ OS以为是本地盘,其实盘在远端的阵列里面,数据走FC光纤过去
SAN 的"高级感"在哪:
- 盘不在本机 → 可以多台服务器看到同一个 LUN(当然一般要配合集群文件系统 GFS/OCFS2,不然 ext4 双挂会炸)
- 阵列自己做 RAID、快照、克隆、远程复制(容灾)
- 扩容是阵列管理员在界面上划 LUN,不用关机插盘
特点一句话:块存储的"企业级豪华版",贵、稳、功能多,但 vendor lock-in 严重
1.1.3 NAS:Network Attached Storage,网络附加存储
NAS设备:NFS、CIFS
一台专门用来存文件的"小电脑",通过以太网把自己的文件系统分享给其他机器
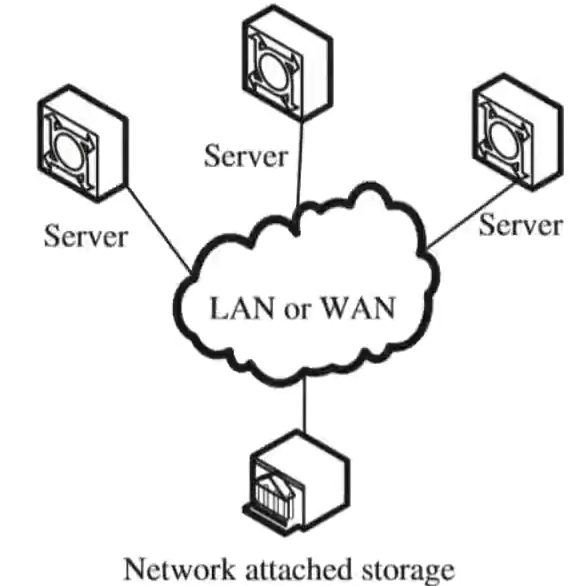
典型形态:
- 家用:群晖(Synology)、威联通(QNAP)------一个小盒子插几块盘,家里电脑通过 Wi-Fi 访问上面的共享文件夹
- 企业:NetApp FAS、EMC Isilon、Dell PowerScale------机架式设备,双控制器 + 大量磁盘,通过 NFS/SMB 协议给几百台服务器共享数据
对于客户端而言,mount -t nfs 192.168.1.100:/data /mnt/nas,之后 /mnt/nas就是一个完整的目录树,可以ls / cp / mv,跟本地文件系统一模一样
但是NAS也有一个缺点:**性能上限受制于 NAS 头,**所有文件操作都要经过 NAS 的控制器的 CPU 和内存,当客户端数量增多时,NAS 头会成为瓶颈(不像 SAN 那样每个客户端直接跟存储阵列的控制器交互,但 SAN 也需要头来处理块到盘的映射)。后续讲解DFS可以解决这个问题
1.1.4 三种整体对比
| 维度 | DAS | SAN | NAS |
|---|---|---|---|
| 抽象层级 | 块(LBA) | 块(LBA) | 文件(POSIX 目录树) |
| 连接方式 | 本地总线(SATA/SAS/NVMe) | 专用网络(FC / iSCSI / NVMe-oF) | 以太网(NFS / SMB) |
| 是否需要 mkfs | ✅ 需要 | ✅ 需要 | ❌ 不需要,直接挂载 |
| 共享性 | ❌ 独占 | ⚠️ 可共享(需集群 FS) | ✅ 天然多客户端 |
| 性能 | 最高(直通盘) | 高(专用网络 + 阵列缓存) | 中(协议开销 + 机头瓶颈) |
| 成本 | 低 | 高(阵列 + 交换机 + HBA) | 中(专用设备或通用服务器+软件) |
| 典型代表 | 服务器内置盘、JBOD | EMC VMAX、华为 OceanStor、iSCSI 存储 | 群晖、NetApp、NFS 服务器 |
| 扩展方式 | 加盘 / 换机箱 | 加磁盘框 / 换阵列头 | 加 NAS 节点(scale-out)或升级机头 |
| 管理复杂度 | 低(OS 层面管) | 高(存储管理员专用) | 中(Web UI 相对友好) |
1.2 DFS简介
存储处理能力不足:
传统的IDE的io值是100次/秒,SATA固态磁盘500次/秒,NVMe固态硬盘达到2000-4000次/秒。即使磁盘的io能力再大数十倍,难道能够抗住网站访问高峰期数十万、数百万甚至上亿用户的同时访问么?这还收到网络io能力的限制
存储空间不足:
单块磁盘容量再大,也无法满足用户正常访问所需的数据容量限制。
需求:
可以横向扩展存储系统,这种存储系统的表现方式有很多,不过他们有一个统一称呼------ 分布式文件系统
DFS = Distributed File System,分布式文件系统------注意它和前面 DAS/SAN/NAS 不在一个分类维度上
1.2.1 DFS核心特征
不管哪种 DFS,都满足这几条:
- 统一命名空间:所有client看到的都是同一棵目录树(/mnt/dfs/home/alice),不关心数据实际存在哪台机器
- 多client并发共享:几十/几百台机器可以同时mount同一个DFS,读写同一批文件(靠锁/租约/能力机制保证一致性)
- 数据分布在多节点:文件内容被切分(条带/块/对象),散到不同机器的盘上------聚合带宽=多机之和
- 元数据管理(多数DFS都有):目录树、inode、权限这些信息,要么集中给MDS管(CephFS/Lustre),要么用算法计算(GlusterFS/ HDFS 的 NameNode 算 block 位置),要么是分布式元数据(GPFS)
1.2.2 DFS和NAS区别
- NAS :一台存储机头 + 盘柜,通过 NFS/SMB 把文件系统共享出去,数据实际只存在这一台机头管的那堆盘里
- DFS :文件系统跨多台独立服务器存储,多 client 共享挂载,数据按某种规则(切片/哈希/条带)分散在多台机器的盘上
| 维度 | NAS | DFS |
|---|---|---|
| 服务端形态 | 单机头(或双控 HA) | 多节点集群 |
| 容量天花板 | 受机头 + 盘柜数限制 | 加节点就能扩(理论上线性) |
| 聚合带宽 | 受机头 CPU/网卡限制 | 多节点网卡之和 |
| 元数据 | 单机文件系统(ext4/xfs/ZFS) | 专用 MDS 或分布式元数据 |
| 共享语义 | POSIX,多 client 挂同一共享 | POSIX(多数)或近似 POSIX |
| 典型协议 | NFS / SMB | 各自私有(cephfs、lustre、gpfs 有自己 client) |
| 故障域 | 机头挂 → 全共享不可用(双控可 HA) | 单节点挂 → 数据仍可用(副本/EC) |
| 代表 | 群晖、NetApp、Isilon | CephFS、Lustre、HDFS、GlusterFS |
一句话区分 :NAS 是"一台机器 假装成文件系统给你用",DFS 是"一群机器凑成一个文件系统给你用"。
1.2.3 DFS 家族
| 流派 | 代表 | 元数据怎么管 | 定位 |
|---|---|---|---|
| 有专用 MDS | CephFS、Lustre | 集中/分片的 MDS 管目录树 | 企业/科研 POSIX 共享 |
| **无 MDS(去中心元数据)** | GlusterFS | 哈希算位置,无中心元数据服务 | 轻量、易部署 |
| **大数据专用(弱 POSIX)** | HDFS | NameNode 管 block 映射,但不追求完整 POSIX(append-heavy,不支持随机写) | Hadoop 生态 |
| 商业 HPC 向 | GPFS (IBM Spectrum Scale) | 分布式元数据,锁管理复杂 | 超算/金融 |
1.3 简介对象存储
作者也是第一次接触这个词语,之前没有听说过对象存储这个概念,希望通过这一小结能够给读者一些简单的了解
1.3.1 对象存储是什么
对象存储 = 用 HTTP REST 访问的扁平 K/V 存储,模型是 Bucket + Key → (Metadata + Data)。
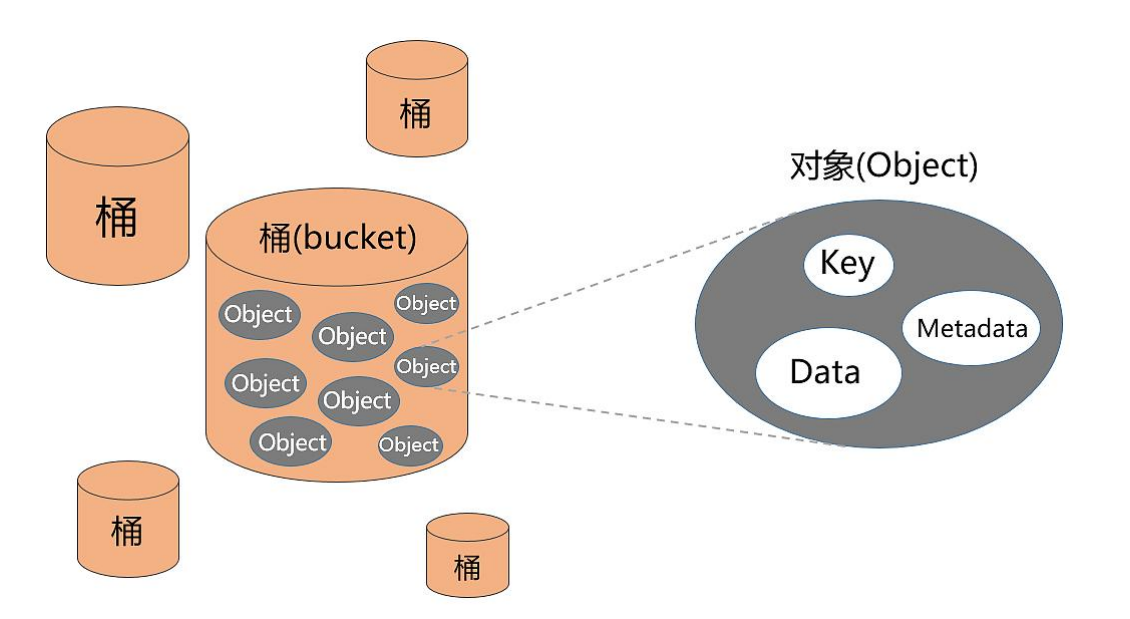
它没有目录树、没有 POSIX、没有 open/read/write,只有几个 HTTP 动词:
| 操作 | HTTP 方法 | 含义 |
|---|---|---|
| 上传 | PUT |
把对象写进去 |
| 下载 | GET |
把对象取出来 |
| 删除 | DELETE |
删对象 |
| 查元数据 | HEAD |
看大小/类型/ETag,不取数据体 |
| 列对象 | LIST |
按 prefix 列出 Bucket 下的 Key(模拟"目录"感) |
跟文件系统最大的架构差异:元数据是自携带的,不是集中存在 MDS/inode 表里。这是对象存储能"无限扩"的核心------对象之间零依赖,加节点就加容量,不需要一个中心节点管全局目录树。
1.3.2 为什么有对象存储
DFS/NAS 的设计假设是**"像本地文件系统一样用"** ------POSIX 语义、目录树、多 client 共享。这套在互联网场景里开始别扭:
- 规模 :微信每天新增的照片多少亿张?DFS 的 MDS 管得动这么平的目录树吗?
ls一个大目录都能卡半天 - 访问模式 :照片存进去就很少改,大部分是"按 URL 读"------要 POSIX 的
rename/link/truncate干嘛? - 跨地域/跨语言 :C 程序
open()能跨公网吗?不能。但 HTTP 能,curl就能读 - 成本:DFS 要养 MDS、要养 client 内核模块,对象存储一个 nginx + 哈希环就能起
所以对象存储的设计取舍:放弃 POSIX、放弃目录树、放弃随机写,换来:无限扩展 + HTTP 生态 + Immutable Blob 友好 + 成本极致
1.3.3 对象存储的核心特征(对比 DFS/NAS)
| 维度 | NAS | DFS (CephFS/Lustre) | 对象存储 (S3) |
|---|---|---|---|
| 接口 | NFS/SMB (POSIX) | POSIX 或近似 | HTTP REST (非 POSIX) |
| 命名 | 目录树 | 目录树 | 扁平 Bucket/Key |
| 共享 | 多 client | 多 client | 多 client(更甚) |
| 元数据 | 集中(MDS/机头) | 集中或分布式 | 自携带(跟着对象) |
| 改文件 | ✅ 随意 | ✅ 随意 | ❌ 基本整对象替换 |
| 扩展上限 | 中(机头瓶颈) | 中高(MDS 瓶颈) | 极高(无中心元数据) |
| 协议 | RPC on TCP | 私有 client 协议 | HTTP(全球通用) |
| 典型场景 | 家目录、共享挂载 | HPC、AI 数据集 | 图片/视频/备份/大数据湖 |
对象存储的"Immutable"是关键
S3 语义下,对象基本是不可变的:
- 不能
append 100 字节到 01.jpg 末尾 - 要改?
PUT整个新版本覆盖(或 Multipart Upload 分片拼,对外仍是整对象替换)
好处:存储层简单、EC 好做、CDN 缓存友好
代价:不适合数据库 WAL、不适合频繁小改场景
所以"对象存储 vs DFS"的取舍很清晰:要 POSIX + 随机写 → DFS;要规模 + HTTP + 写一次读万次 → 对象存储。
2 什么是ceph
众所周知,ceph是一种分布式存储系统,是有着"ceph之父"之称的Sage Weil读博期间的研究课题项目诞生于2004年,在2006年基于开源协议开源了Ceph的源代码,在经过了数年的发展之后,已经成为了开源社区受关注较高的项目之一。
Ceph可以将多台服务器组成一个超大集群,把这些机器中的磁盘资源整合到一块儿,形成一个大的资源池(支持PB级别),然后按需分配给客户端应用使用。
- ceph官网:https://ceph.com/
- ceph官方文档(英文):Welcome to Ceph --- Ceph Documentation
- ceph官方文档(中文):http://docs.ceph.org.cn/
2.1 ceph特点
- 支持三种:块存储、文件存储、对象存储接口,称之为统一存储
- 采用CRUSH算法,数据分布均衡,并行度高,不需要维护固定的元数据结构
- 数据具有强一致性,确保所有副本写入完成后才返回确认,适合读多写少场景
- 去中心化,没有固定的中心节点,集群扩展灵活
2.2 ceph缺点
- 去中心化的分布式解决方案,需要提前做好组件和节点部署规划设计
- ceph扩容时,由于其数据分布均衡特点,会导致整个存储系统性能下降
2.3 ceph相较于其他存储方案的优势
- CRUSH算法
- CURSH是ceph的两大创新之一(另一大就是去中心化),ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法计算的方式完成数据的寻址操作
- crush算法有强大的扩展性(即高扩展性),理论上支持上千个存储节点规模
- 高可用
- 数据副本数可以灵活调整
- 可以通过crush算法指定副本的物理存放位置以分割故障域,支持数据强一致性
- 支持多种故障场景自动尝试进行修复
- 支持多份强一致性副本,副本能够垮主机、机架、机房、数据中心存放,安全可靠
- 存储节点可以自管理、自动修复。无单点故障,容错性强
- 高性能
- 因为是多个副本,因此在读写操作时能够做到高度并行化,理论上,节点越多,整个cpeh集群的IOPS和吞吐量就越高
- ceph客户端读写数据可直接与存储设备-OSD交互,在块存储和对象存储中无需元数据-MDS服务
- 特性丰富
- 支持三种存储接口:对象存储,块存储,文件存储,三种方式可一同使用
- 支持自定义接口,支持多种语言驱动
3 ceph三种存储接口(块存储、文件系统存储、对象存储)
ceph可以一套存储系统同时支持块存储、文件系统存储和对象存储三种存储功能。没有存储基础的读者比较难以理解ceph的块存储、文件系统存储和对象存储接口。该章节让读者理解这三者在ceph的区别我们再去研究ceph的架构和原理
3.1 ceph的块设备存储接口
首先,什么时块设备?
块设备是i/o设备的中的一类,时将信息存储在固定大小的块中,每个块都有自己的地址,还可以在设备的任意位置读取一定长度的数据。如果无法理解,可以暂且为块设备就是硬盘或者虚拟硬盘。
我们可以看一下linux环境中的设备
bash
root@nb:~$ ls /dev/
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdb1 /dev/hda /dev/rbd1 /dev/rbd2上面的/dev/sda、/dev/sdb、/dev/hda都是块设备文件,这些文件时怎么出现的呢?
当给计算机连接块设备(硬盘)后,系统检查到有新的块设备,该类型块设备的驱动程序就在/dev/下创建对应的块设备文件,用户就可以通过设备文件使用该块设备了
它们怎么有的叫sda?有大家sdb?有的叫hda?
以sd开头的块设备文件对应的时SATA接口的硬盘,而以hd开头的块设备文件对应的时IDE接口硬盘。两个接口有什么区别呢?其实只需要了解,IDE接口硬盘已经很少见到了,逐渐被淘汰,而SATA接口的硬盘时目前的主流。而sda和sdb的区别呢?当系统检测到多个SATA硬盘时,会根据检查到的顺序对硬盘设备进字母顺序的命名。
怎么还有叫做rbd1和rbd2呢?rbd(rados block devices)
这个rdb*就是我们的主角。rbd*就是有Ceph集群提供出来的块设备。可以这样理解,sda和hda都是通过数据线连接到真实硬盘的,而rbd时通过网络连接到Ceph集群中的一块存储区域,往rbd设备写入数据,最终会被存储到Ceph集群的这块区域
那么块设备怎么用呢?这里举个例子:
打个比方,一个块设备是一个粮仓,数据就是粮食。农民伯伯可以存粮食(写数据)了,需要存100斤玉米,粮仓(块设备)这么大放哪里呢,就挨着放(顺序写)吧。又需要存1000斤花生,还是挨着放吧。又需要存....
后来,农民伯伯来提粮食(读数据)了,他当时存了1000斤小麦,哎呀妈呀,粮仓这么大,小麦在哪里啊?仓库管理员找啊找,然后哭晕在了厕所.....
新管理员到任后,想了个法子来解决这个问题,用油漆把仓库划分成了方格状,并且编了号,在仓库门口的方格那挂了个黑板,当农民伯伯来存粮食时,管理员在黑板记录,张三存了1000斤小麦在xx方格处。后来,农民伯伯张三来取粮食时,仓库管理员根据小黑板的记录很快提取了粮食。
因此,没有方格和黑板的仓库(块设备)称为裸设备。由上例可见,裸设备对于用户使用时很不友好的,直接导致了旧仓库管理员的狗带。例子中的划分方格和挂黑板的过程其实就是在块设备上构建文件系统的过程,文件系统可以帮助块设备对存储空间进行条理的组织和管理,于是新管理员通过文件系统(格子和黑板)迅速找到了用户(农名伯伯张三)存储的数据(1000斤小麦)。针对多种多样的使用场景,衍生出了很多文件系统。有的文件系统提供更好的读性能,有的文件系统提供更好的写功能。我们平时使用的xfs、ext4就是读写性能各方面比较均衡的通用文件系统。
那么一块裸盘的应用我们可以理解为以下四个步骤进行使用:
-
分区(可选,现在常跳过直接用整盘)
bashfdisk /dev/sdb # 分一个 sdb1,或者直接整盘用也行 -
mkfs ------ 在块设备上"种"文件系统"
bashmkfs.xfs /dev/sdb # 或 mkfs.ext4按 xfs/ext4 格式,在 sdb 的 LBA 空间里写 superblock、inode table、bitmap......让这块盘从"裸扇区串"变成"xfs 格式的盘"。
-
mount ------ 挂进目录树
bashmount /dev/sdb /dataVFS 通过 xfs 驱动解析 sdb 里的结构,把
/data这个挂载点跟 xfs 根 inode 关联起来。 -
正常使用
bashtouch /data/a.txt echo hello > /data/a.txt从这一刻起,
write()系统调用 → VFS → xfs → 块层 → 写 sdb 的对应 LBA → 真盘。
回头看定义:块设备自己不认"文件",mkfs让它变得"能认",mount让它"挂进目录树能用"。这就是块设备的标准打开方式。
能否直接使用不含有文件系统的块设备呢?
答案是可以的,xfs和ext4等通用的文件系统旨在满足大多数用户的存储需求,所以在数据存储的各方面的性能比较均衡。然而,很多应用往往不需要这种均衡,而需要突出某一方面的性能,如小文件的存储性能。此时xfs、ext4等通用文件系统如果不能满足应用的需求,应用往往回在裸设备上实现自己的数据组织和管理方式。简单的说,就是为了强化某种存储特性而实现自己定制的数据组织和管理方式,而不使用通用的文件系统
总结一下,块设备可理解成一块硬盘,用户可以直接使用不含文件系统的块设备,也可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持。
3.2 ceph的文件系统存储接口
什么是Ceph文件系统接口?
上面说到块设备的文件系统的时候,用户可以在块设备上创建xfs和ext4等其他文件系统。ceph集群实现了自己的文件系统用来组织管理集群的存储空间,用户可以直接将ceph集群的文件系统挂载到用户机上使用。
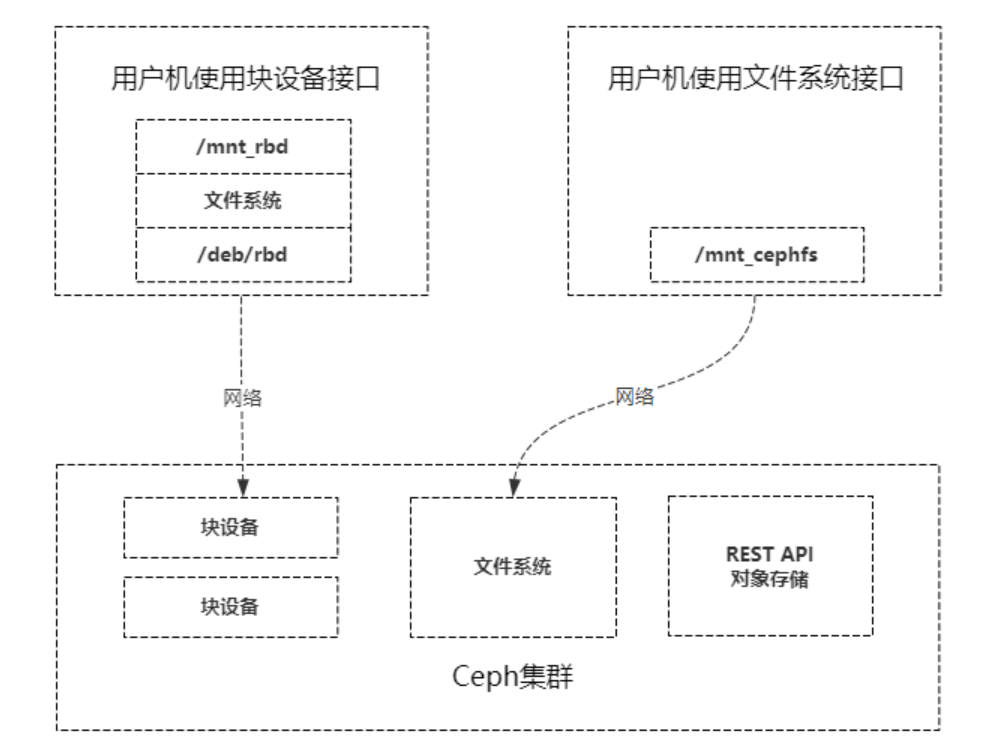
ceph有了块设备接口,在块设备上完全可以建立一个文件系统,那么ceph为什么还需要文件系统接口呢?
主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写,目前主要用在OpenStack上作为虚拟磁盘,而Ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性。
为什么ceph的块设备接口不具有共享性,而ceph的文件系统接口具有呢?
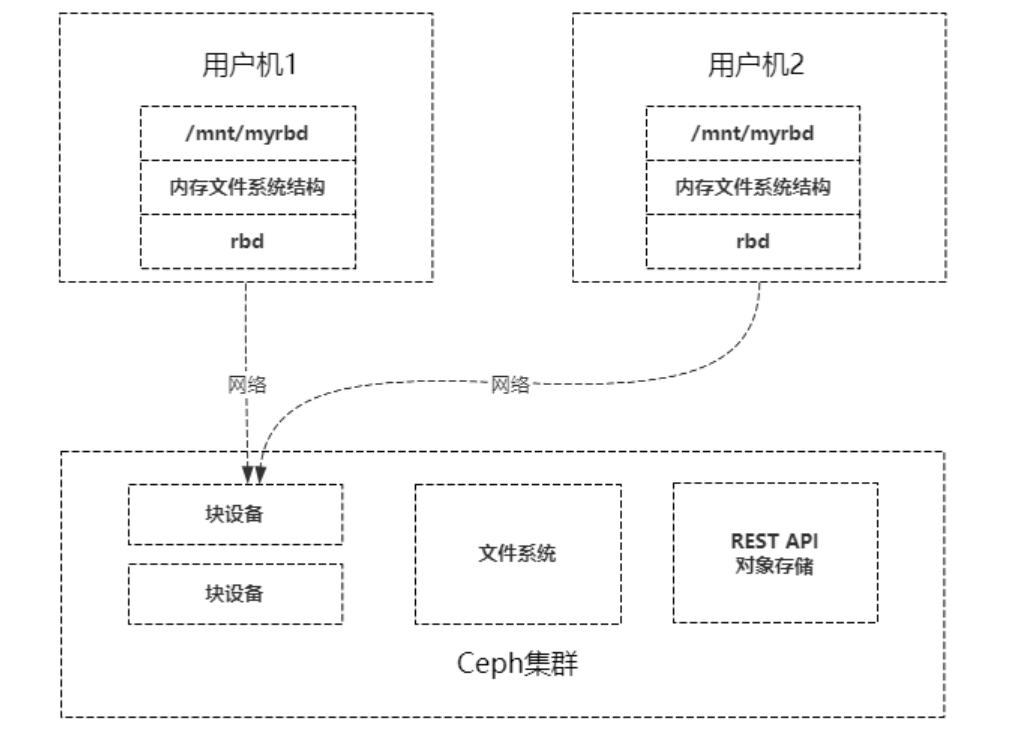
对于Ceph的块设备接口,如下图,文件系统的结构状态是维护在各用户机内存中的,假设Ceph块设备同时挂载到了用户机1和用户机2,当在用户机1上的文件系统中写入数据后,更新了用户机1的内存中文件系统状态,最终数据存储到了Ceph集群中,但是此时用户机2内存中的文件系统并不能得知底层Ceph集群数据已经变化而维持数据结构不变,因此用户无法从用户机2上读取用户机1上新写入的数据。
也即是说 ,ext4/xfs 的 page cache、journal、inode 分配都是在单机内核里维护的,A 机改了 inode 表,B 机不知道,双挂必炸文件系统一致性。
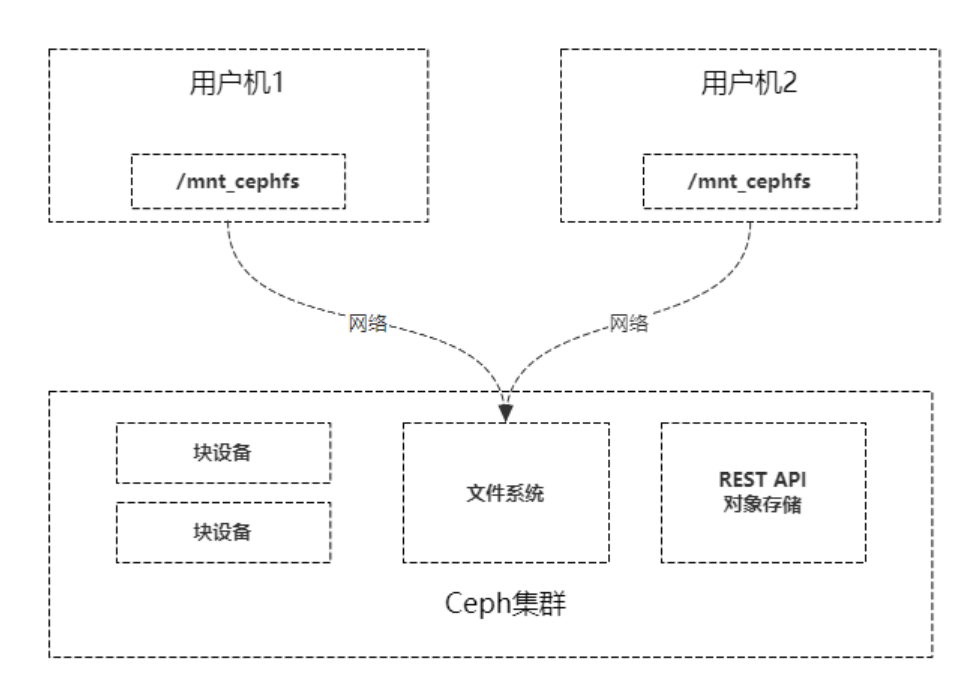
而对于ceph的文件系统接口,如下图,文件系统结构状态时维护在远端的ceph集群中的,ceph文件系统同时挂载到了用户机1和用户机2,当往用户机1挂载点写入数据后,远端的ceph集群中的文件系统状态结构随之更新,当用户机2的挂载点访问数据时回去远端的ceoh集群取数据,由于远端的ceph集群已更新,所有用户机2都能够获取最新数据
ceph文件系统使用方式?
将ceph的文件系统挂载到用户机目录
bash
mkdir -p /mnt/ceph_fues
ceph-fuse /mnt/ceph_fuse大功告成,在/mnt/ceph_fuse下读写数据,都是读写远程Ceph集群
总结一下,ceph文件系统接口弥补了ceph的块设备接口共享性方面的不足,ceoh的文件系统接口符合posix标准,用户可以像使用本地存储目录一样使用ceph文件系统的挂载目录。还是不了解?你可以这样理解,无需修改你的程序,就可以将程序的底层存储换成空间无限并可以多处共享读写的ceph集群文件系统
3.3 ceph的对象存储接口
首先,我们通过图片来看看对象存储接口是怎么用的?
简单的说就是通过http协议上传下载删除对象(文件即对象)
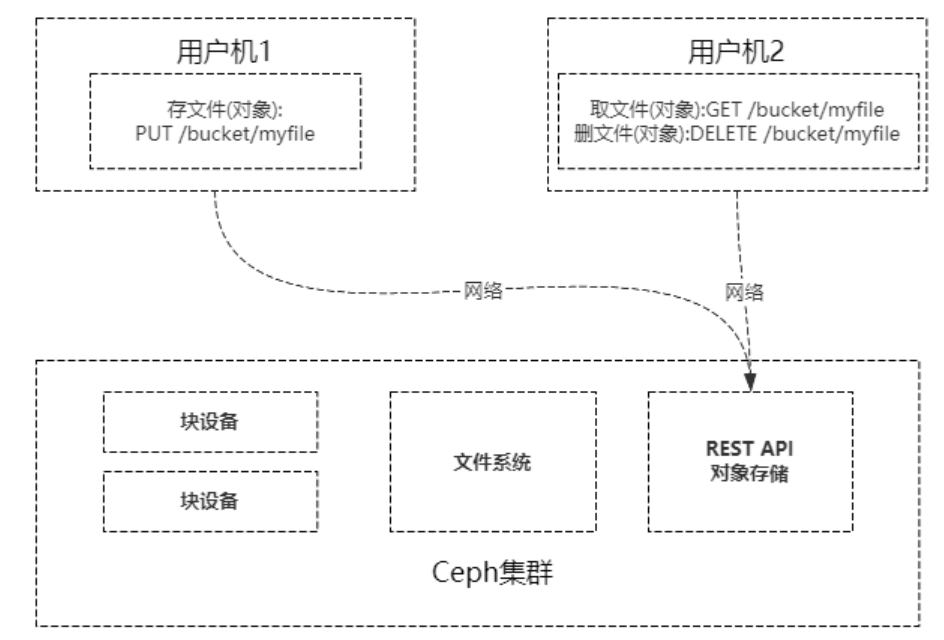 老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
往简单了说,ceph块设备存储具有优异的存储性能但不具备共享性,而ceph的文件系统具有共享性但较块设备存储性能更差,为什么不权衡一下存储性能和共享性,整一个具有共享性而存储性能好于文件系统的存储呢?对象存储就这样出现了
对象存储为什么性能会比文件系统好?
- 对象存储组织数据方式相对简单,只有bucket和对象两个层次(对象存储在bucket中),对对象的操作也相对简单
- 而文件系统存储具有复杂的数据组织方式,目录和文件层次可具有无限深度,对目录和文件操作也复杂的多,因此文件系统存储在维护文件系统的结构时回更加繁杂,从而导致文件系统的存储性能偏低
ceph的对象存储接口如何使用?
ceph的对象存储接口符合亚马孙S3接口标准和OpenStack的Swift接口标准,可以自行学习
总结一下,文件系统存储具有复杂的数据组织结构,能够提供给用户更加丰富的数据操作接口,而对象存储精简了数据组织结构,提供给用户有限的数据操作接口,以换取更好的存储性能。对象接口提供了RESTAPI,非常适用于作为web应用的存储。
3.4 总结
概括一下,块设备速度快,对存储的数据没有进行组织管理,但在大多数场景下,用户数据读写不方便(以块设备位置offset+数据的length来记录数据位置,读写数据)。而在块设备上构建了文件系统后,文件系统帮助块设备组织管理数据,数据存储对用户更加友好(以文件名来读写数据)。Ceph文件系统接口解决了"Ceph块设备+本地文件系统"不支持多客户端共享读写的问题,但由于文件系统结构的复杂性导致了存储性能较Ceph块设备差。对象存储接口是一种折中,保证一定的存储性能,同时支持多客户端共享读写。
4 Ceph架构
4.1 ceph核心架构组件
支持三种接口
- Block(块):支持精简配置、快照、克隆
- File(文件):Posix接口、支持快照
- Object(对象):有原生的API,而且也兼容Swift和S3的API
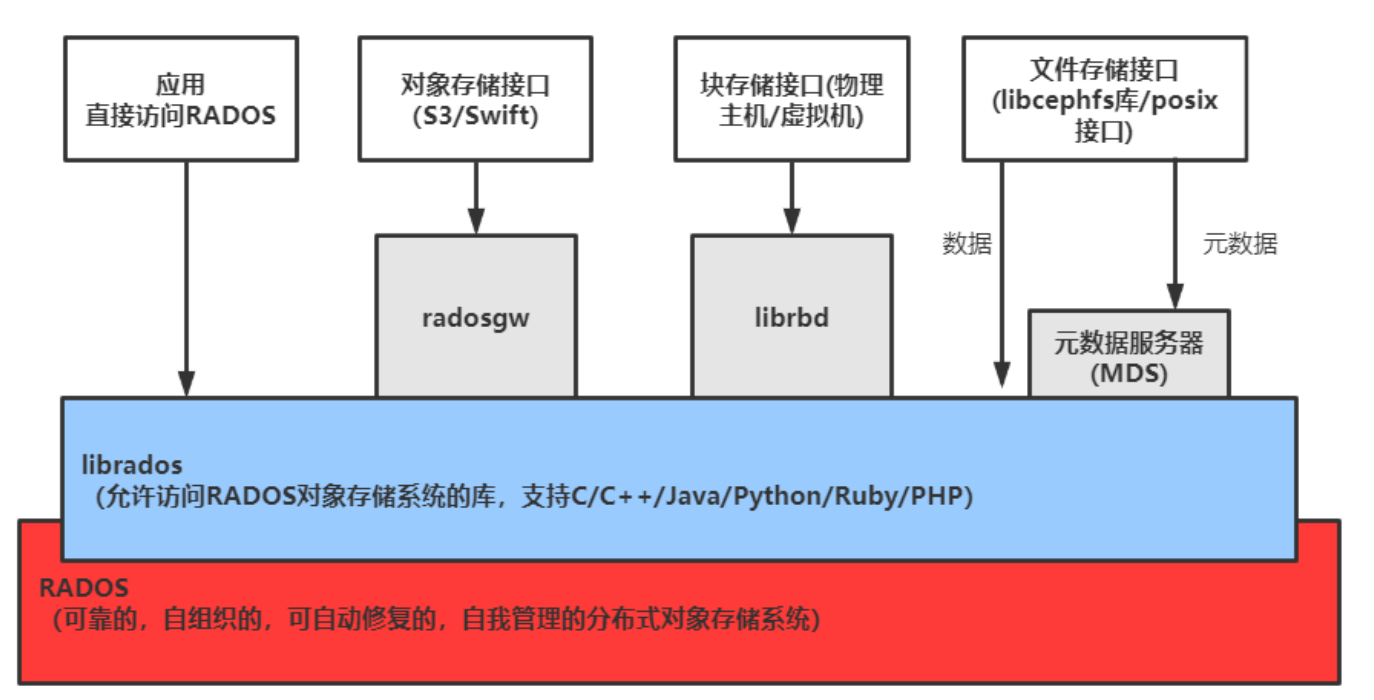
自下而上分为4个层次:
- 基础存储系统RADOS(Reliable Autonomic Object Store,可靠、自动、分布式对象存储):RADOS是ceph存储集群的基础,这一层本身就是一个完整的对象存储系统。Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也都是由这一层所提供的,在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象,确保了数据一致性和可靠性。RADOS = OSD 集群 + PG 抽象 + CRUSH 分布算法 + 自修复机制,它对外只暴露一件事------"给我一个 object 名,我能可靠地存/取它,并且知道它该放哪"。
- 基础库LIBRADOS:LIBRADOS基于RADOS之上,它允许应⽤程序通过访问该库来与RADOS系统进⾏交互,⽀持多种编程语⾔,⽐如C、C++、Python等
- 上层接口RADOSGW、RBD、CEPHFS:基于LIBRADOS层开发的三个接口,其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口
- RADOSGW(简称RGW)提供对象存储服务,是一套基于RESTFUL协议的网关,支持对象存储,兼容S3和Swift
- RBD提供分布式的块存储设备接口,主要面向虚拟机提供虚拟磁盘,可以被映射、格式化,像磁盘一样挂载到服务器使用
- CephFS是一个POSIX兼容的分布式文件系统,依赖MDS来跟踪文件层次结构,基于librados封装原生接口,他和传统的文件系统如ext4是一个类型的,但区别在于分布式存储提供了并行化能力,像NFS等也属于文件系统存储
RGW为Rados Gateway的缩写,ceph通过RGW为互联网云服务提供商提供对象存储服务。RGW在librados之上向应用提供访问ceph集群的RestAPI,支持Amazon S3和openstack swift两种接口。对RGW最直接的理解就是一个协议转换层,把从上层应用符合S3或Swift协议的请求转换成rados的请求,将数据保存在rados集群中。
4.2 Ceph核心组件及概念
- Monitor(ceph-mon):维护集群Cluster Map的状态,维护集群的Cluster MAP二进制表,保证集群数据的一致性。ClusterMAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置的桶列表,map中包含monitor组件信息,manger组件信息,osd组件信息,mds组件信息,crush算法信息。还负责ceph集群的身份验证功能,client在连接ceph集群时通过此组件进行验证。
- OSD(ceph-osd):OSD全称Object Storage Device,⽤于集群中所有数据与对象的存储。ceph 管理物理硬盘时,引⼊了OSD概念,每⼀块盘都会针对的运⾏⼀个OSD进程。换句话说,ceph 集群通过管理 OSD 来管理物理硬盘。负责处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送⼼跳,然后向Mon提供⼀些监控信息。当Ceph存储集群设定数据有两个副本时(⼀共存两份),则⾄少需要三个OSD守护进程即三个OSD节点,集群才能达到active+clean状态,实现冗余和⾼可⽤。
- Manager(ceph-mgr) :⽤于 收集ceph集群状态、运⾏指标,⽐如存储利⽤率、当前性能指标和系统负载。对外提供 ceph dashboard(ceph ui)和 resetful api。Manager组件开启⾼可⽤时,⾄少2个实现⾼可⽤性。
- MDS(ceph-mds) :Metadata server,元数据服务。为ceph⽂件系统提供元数据计算、缓存与同步服务(ceph 对象存储和块存储不需要MDS)。同样,元数据也是存储在osd节点中的,mds类似于元数据的 代理缓存服务器,为 posix ⽂件系统⽤户提供性能良好的基础命令(ls,find等)不过只是在需要使⽤CEPHFS时,才需要配置MDS节点。
- Object:Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据
- PG:PG全称Placement Grouops,是⼀个逻辑的概念,⼀个PG包含多个OSD。引⼊PG这⼀层其实是为了更好的分配数据和定位数据。
- RADOS :RADOS全称Reliable Autonomic Distributed Object Store(可靠、⾃治、分布式对象存储),是Ceph集群的精华,⽤户实现数据分配、Failover(故障转移)等集群操作。
- Libradio驱动库:Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,⽬前提供PHP、Ruby、Java、Python、C和C++⽀持。
- CRUSH :CRUSH是Ceph使⽤的数据分布算法,类似⼀致性哈希,让数据分配到预期的地⽅。
- RBD :RBD全称RADOS block device,是Ceph对外提供的块设备服务。
- RGW :RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接⼝与S3和Swift兼容。
- CephFS :CephFS全称Ceph File System,是Ceph对外提供的⽂件系统服务。
5 Ceph底层存储过程
应用 echo hello > /mnt/rbd/a.txt (a.txt 在 mount 后的 xfs 里,底层是 /dev/rbd0)
│
├── VFS → xfs → 块层 → rbd.ko(内核)或 librbd(用户态 QEMU)
│ xfs 把 "a.txt 偏移 Y 的 4K" 翻译成 "/dev/rbd0 的 LBA Z"
│
├── librbd:把 LBA Z 反向映射回 "哪个 RBD image、哪个 object、object 内偏移"
│ RBD image 按 4M 切 object → 比如 object 编号 = LBA / 4M
│
├── librados(RADOS 客户端)
│ ① 拿 cluster map(从 MON 缓过来,不用每次问 MON)
│ ② object name → hash → PG id
│ ③ PG id → CRUSH → 算出 Primary OSD + Replica OSDs
│ ④ 直接把写请求发到 Primary OSD(不走 MON!)
│
├── Primary OSD
│ ① 走副本协议:自己写 + 发 replica OSD 写
│ ② 等副本 ack → 返回 client "写成功"
│ ③ 各自 OSD 把 object 交给本机 BlueStore
│
├── BlueStore(OSD 本机存储引擎)
│ Object 元数据 → RocksDB (on BlueFS)
│ Object 数据 → 直接写裸块设备(不再走 XFS)
│
└── 真盘(NVMe / HDD)5.1 File → Object
纯 RADOS 视角(比如 RGW 直接 PUT object)是没有 File 这层的,object 就是用户给的。但 RBD/CephFS 有"文件感",所以得先切。
RBD 的特殊一些 :image 是"伪装成的文件"。/dev/rbd0挂起来 mkfs.xfs后,你在里面写 a.txt------这条链路是两层切分:
- 外层(xfs 干的) :
a.txt的字节 → xfs 的 extent → 翻译成/dev/rbd0上的 LBA 偏移 - 中层(librbd 干的):LBA 偏移 → RBD image 的哪个 object(object_no = LBA / 4M)→ object 内偏移
所以 RBD 场景下,"File → Object"这一步其实是 xfs + librbd 合力完成的 ,对 RADOS 来说拿到手时已经是个 object_id + offset + data_len了。
CephFS :CephFS 是 MDS 管目录树,文件在 client 端按 layout/stripe 切条带 → 每条带一个 RADOS object。所以 CephFS 的 "File → Object" 在 client + MDS 手里完成,不进 RBD。
RGW :RGW 更简单:S3 的 PUT s3://bucket/key→ RGW 直接把 key 映射成 head object + tail objects(每 4M 一切),没有"文件→切条带"这层,因为对象存储本来就是 object 语义。
所以"File → Object"这步不是 RADOS 的活,是三个盖子各自按自己语义切的。RADOS 从"已经是个 object"开始接手。
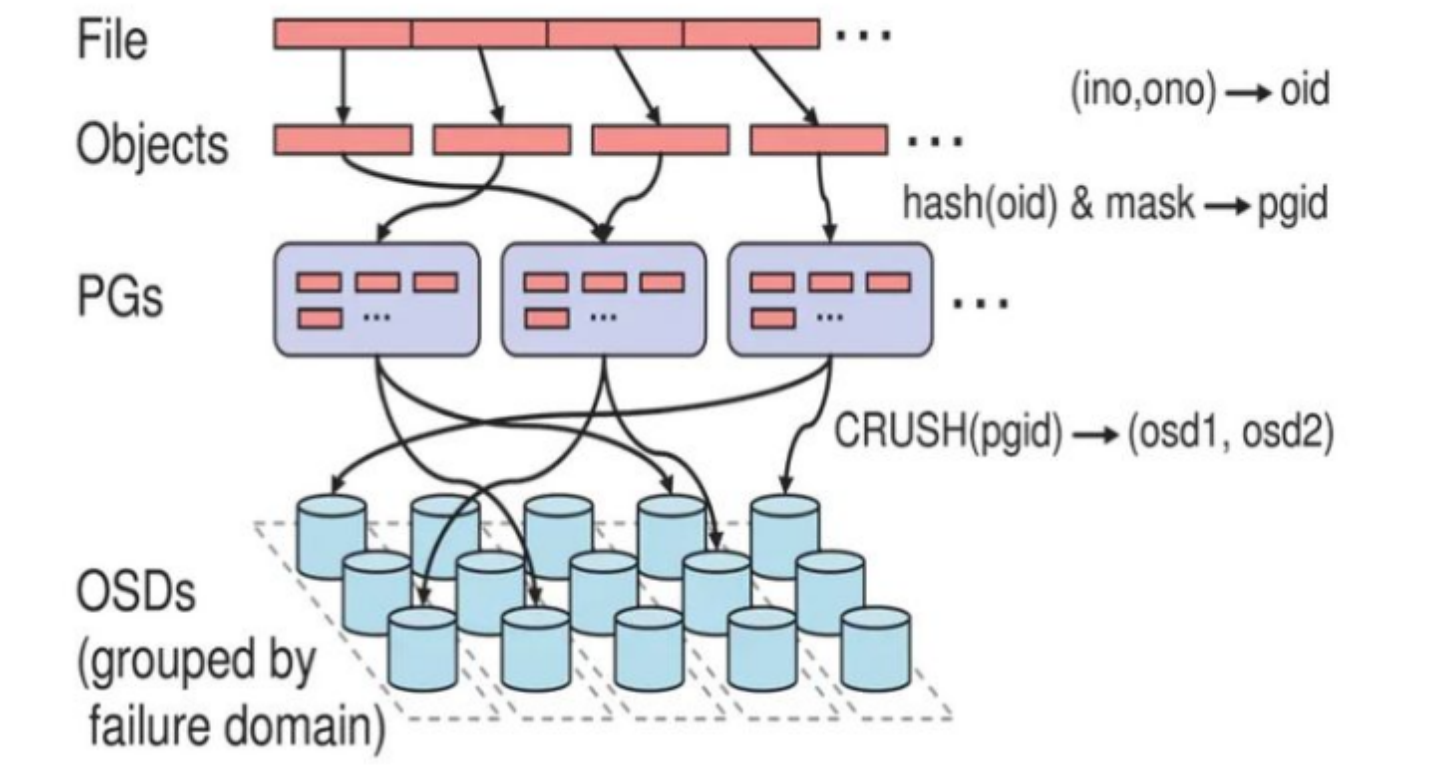
5.2 Object → PG(Hash取模)
RADOS 的 object 不会直接一对一绑到某个 OSD------那样 PG 数量一变全集群重构。所以插了 **PG(Placement Group)** 这层缓冲:
-
PG是"对象的分组容器",一堆object按hash归到一个PG下
-
PG数量在pool创建时定好(比如128、1024),之后基本不变
-
object → PG的算法(红帽官方描述的步骤):
输入:pool_id(如 liverpool=4) + object_name(如 "john") + pg_num(如 128)
① 对 object_name 做 hash → h
② pg_id_temp = h % pg_num → 比如 58
③ 最终 PG ID = pool_id.pg_id_temp → 4.58
PG 的存在意义:object 数量级是亿级,PG 数量级是千级。如果 client 直接算 object→OSD,cluster map 一变(加盘/掉盘)要重算亿次;插了 PG,只要重算千次 PG→OSD,再把 PG 下的 object 挪过去就行------这是 Ceph 能 scale 的关键设计之一。
5.3 PG → OSD(CRUSH算法,Ceph灵魂)
这是 RADOS 最牛的一步------不用查表,client 自己算。
CRUSH 输入:
- PG ID (比如
4.58) - CRUSH Map(描述集群拓扑:哪些 host、哪些 OSD、每 OSD 权重、故障域规则)
CRUSH 输出:
- 一组 OSD 列表 ,第一个是 Primary,后面是 Replicas(副本数由
pool size定,比如 3 副本 → 输出 3 个 OSD)
算法精神(不贴公式,讲直觉):
把 PG ID 当"种子"扔进集群拓扑里滚哈希,按规则
take → chooseleaf firstn 0 type host走------先选一个 bucket(比如 rack),再在 bucket 里选 host,再在 host 里选 OSD,保证副本落在不同 host/rack 上。
对比"一致性哈希":
- 一致性哈希:环上找节点,扩缩容影响 O(log n) 的节点
- CRUSH:可配置故障域 + 权重 + 规则 ,扩 OSD 时只迁移
1/(新总OSD数)的数据,且能控制"别让俩副本落同一 rack"
💡 这一步完成后,client 已经知道该把请求发哪台 OSD 了------所以真正 IO 不走 MON,MON 只负责吐 cluster map。这是 Ceph "去中心化"的来源。
5.4 写请求进OSD(副本写路径)
client 把写请求直接发 Primary OSD(算出来的第一个),Primary 走副本协议:
client
→ Primary OSD:prepare → 本地写 journal 意图
→ Replica OSD 1:prepare
→ Replica OSD 2:prepare
→ 全部 ack 回 Primary
→ Primary:commit → 回 client "OK"
→ 异步:Primary + Replicas 各自把数据刷进 BlueStore 最终存储- ack 给 client 的时机 :是
prepare全收齐就返(类似 Write-Ahead),还是commit完才返?------Ceph 默认是 PG 层 ACK 模式可配,但大致精神是"副本持久化意图 + 本地 commit"后就能返,延迟可控 - Primary 挂了怎么办:剩下的 Replica 里选新 Primary,peering 阶段比对 journal,补全没来得及 commit 的 object → 这就是"自修复"的起点
- PG 状态机 :
active+clean是健康态,degraded(少副本)→recovery→backfilling(全量补)→ 回到active+clean
EC(纠删码)写路径差异(进阶,面试加分)
如果 pool 是 EC(比如 4+2,4 数据 + 2 校验):
- 一个 object 被切成 4 数据块 + 2 校验块,分别写 6 个 OSD
- client 不是只发 Primary,而是算好每个块该去哪,并行发(EC 没有"Primary 协调全量写"那种模式,开销太大)
- 读的时候只要 4 块就能还原,容忍任意 2 块挂
💡 所以"副本写 vs EC 写"是面试常考点:副本写简单、延迟低、空间贵(3 副本=3x);EC 空间省(4+2=1.5x)、写路径复杂、读可能触发校验重建、延迟高------对象存储(RGW)冷数据爱用 EC,RBD 热数据基本 3 副本。
5.5 OSD 本机------BlueStore 落盘(这一代不再走 XFS 了)
FileStore(老一代,淘汰中)的痛点
- OSD 数据 → 本地 XFS 分区 → 每个 object 是一个 XFS 文件
- 写路径:object → Page Cache → XFS journal → XFS 最终写 → 盘
- 双重 journal (FileStore 自己的 + XFS 的)+ 双重 page cache,写放大严重
BlueStore(Luminous 起默认,现在主流)
Object 进 BlueStore
├── 元数据 (Onode: object→物理块映射、omap、快照...)
│ → RocksDB (KV 引擎)
│ → BlueFS (mini 文件系统,专门伺候 RocksDB 的 .sst/.log)
│ → 通常放 NVMe(block.db 分区)
├── WAL (RocksDB 的 write-ahead log)
│ → 可单独放更快的设备 (block.wal,NVRAM/NVMe)
└── 数据体
→ 直接写裸块设备(Raw Block Device)
→ BlueStore 自己的分配器(Allocator)管空间,不再经 XFS/ext4部署形态(生产推荐):
-
单设备:一块盘全给 OSD,BlueStore 自己分(数据 + RocksDB + WAL 挤一起)
-
分离式(主流生产) :HDD 做数据主体 + NVMe 分两个区做
block.db+block.wal→ RocksDB 和 WAL 走 NVMe,数据走 HDD,延迟和 IOPS 都香 -
三宝式(土豪):HDD 数据 + SSD 的 DB + NVDIMM 的 WAL
OSD 进程收到 object 写
→ BlueStore: 分配物理块(Allocator)
→ 数据体直接 pwrite 裸块设备(defer 或 直写,看是否走 WAL)
→ 元数据 (Onode) → RocksDB Put(写 WAL → SST)
→ RocksDB 持久化完 → OSD 返回 PG 层 "本地 commit 完"
BlueStore 比 FileStore 快在哪(官方口径 ~2x):
- 零拷贝:数据不走 page cache → XFS → 盘,直接用户态 → DIO 裸块
- 无双重 journal:FileStore 是"FileStore journal + XFS journal"两层,BlueStore 只有 RocksDB WAL 一层
- 校验和:所有数据/元数据写时算 CRC,读时验,比 XFS 那层更细
5.6 总结
Ceph 的一次写:client 把"pool + object name"按 hash 算 PG、再按 CRUSH 算 Primary OSD → 发 Primary → Primary 协调 replicas 走副本协议(或 EC 分片)→ 各 OSD 本机 BlueStore 把元数据扔 RocksDB/BlueFS、数据体直写裸块 → 盘。MON 全程不掺 IO,只管吐 cluster map。