一、引言
Hudi 的 Metadata Table(元数据表)是 Hudi 0.11 版本引入、并在 1.x 版本中逐步成熟的核心基建。它通过将文件列表、列统计信息、布隆过滤器等元数据以 Hudi MOR 表的形式进行本地化管理,从根本上消除了对云存储(如 S3、HDFS)list files操作的高频依赖,显著提升了查询规划(Query Planning)速度和写入效率。
二、架构设计
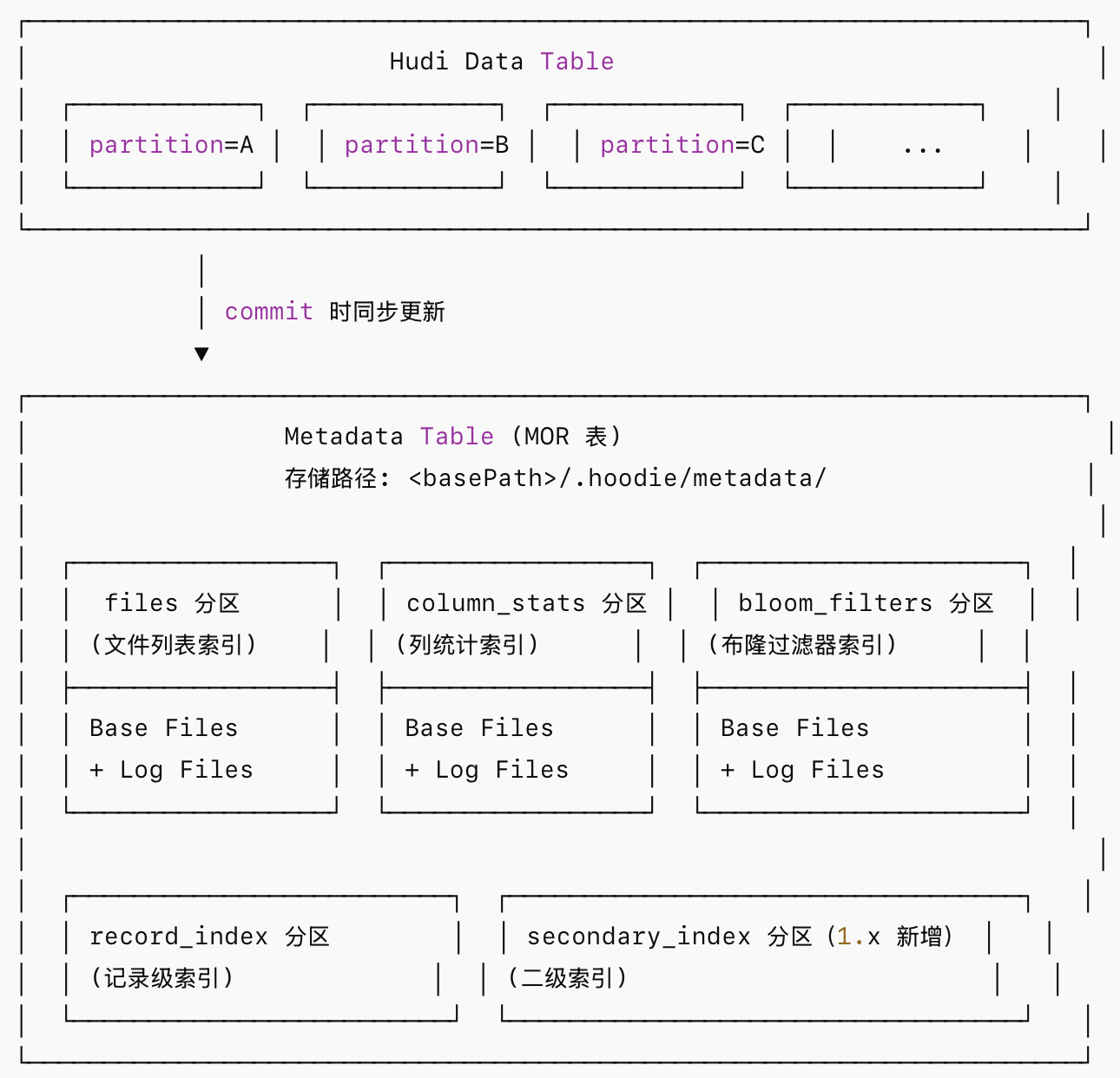
Metadata Table 本身就是一张 Hudi MOR(Merge-On-Read)表,具备以下特征:
- 存储位置:<table_base_path>/.hoodie/metadata/
- 表类型:MOR(通过 log file 追加写入,定期 compaction 合并为 base file)
- 分区方式:按功能分为多个逻辑分区(files、column_stats、bloom_filters、record_index 等)
- 记录格式:HFile 格式作为 base file(支持点查优化),Avro 格式的 log file
PS:Hudi 1.x 中 Metadata Table 的 base file 默认使用 HFile 格式而非 Parquet,这是为了支持高效的 key-based lookup(点查),因为元数据的访问模式以精确查找为主。
Hudi 1.x 的 Metadata Table 采用多分区设计,每个分区承载不同类型的索引数据:
|-----------------|---------------------------------------------|------------------------------------------|------------------------------------------------|
| 分区名称 | 功能 | Key 设计 | 启用配置 |
| files | 存储每个分区下的文件列表 | <partitionPath> | 默认启用 |
| column_stats | 存储每个文件的列级统计(min、max、null count、value count) | <colName><partitionPath><fileId> | hoodie.metadata.index.column.stats.enable=true |
| bloom_filters | 存储每个文件的布隆过滤器序列化数据 | <partitionPath>_<fileId> | hoodie.metadata.index.bloom.filter.enable=true |
| record_index | 记录级别的 recordKey → 文件位置映射 | <recordKey> | hoodie.metadata.record.index.enable=true |
| secondary_index | 二级索引(Hudi 1.x 新增,实验性) | 自定义 | 按需配置 |
三、工作原理
1.写入流程中的 Metadata 更新
┌─────────────────────────────────────────────────────────────────┐
│ Hudi 写入流程(含 Metadata 更新) │
└─────────────────────────────────────────────────────────────────┘
① Writer 开始 Commit
│
▼
② 写入数据文件到对应分区
│
▼
③ 收集变更的元数据信息:
- 新增/删除/更新的文件列表
- 新文件的列统计信息
- 新文件的布隆过滤器
- 记录的位置映射变更
│
▼
④ 将元数据变更写入 Metadata Table 的对应分区 (log files)
│
▼
⑤ 在数据表 Timeline 上提交 commit(原子操作)
同时完成 Metadata Table 的 commit
│
▼
⑥ Commit 完成,数据与元数据保持一致2.查询规划中的 Metadata 读取
┌────────────────────────────────────────────────────────────┐
│ 查询规划流程(使用 Metadata Table) │
└────────────────────────────────────────────────────────────┘
Query Engine (Spark/Flink/Trino)
│
│ ① 获取文件列表
▼
┌──────────────────────────┐
│ MetadataTable.files 分区 │ ──► 返回指定分区的所有文件
└──────────────────────────┘ (替代 fs.listStatus)
│
│ ② 列统计过滤 (如果启用)
▼
┌────────────────────────────────┐
│ MetadataTable.column_stats 分区 │ ──► 根据查询条件过滤
└────────────────────────────────┘ 无关文件 (Data Skipping)
│
│ ③ 生成最终的 Scan 计划
▼
只读取满足条件的文件 → 显著减少 I/O3.一致性保障机制
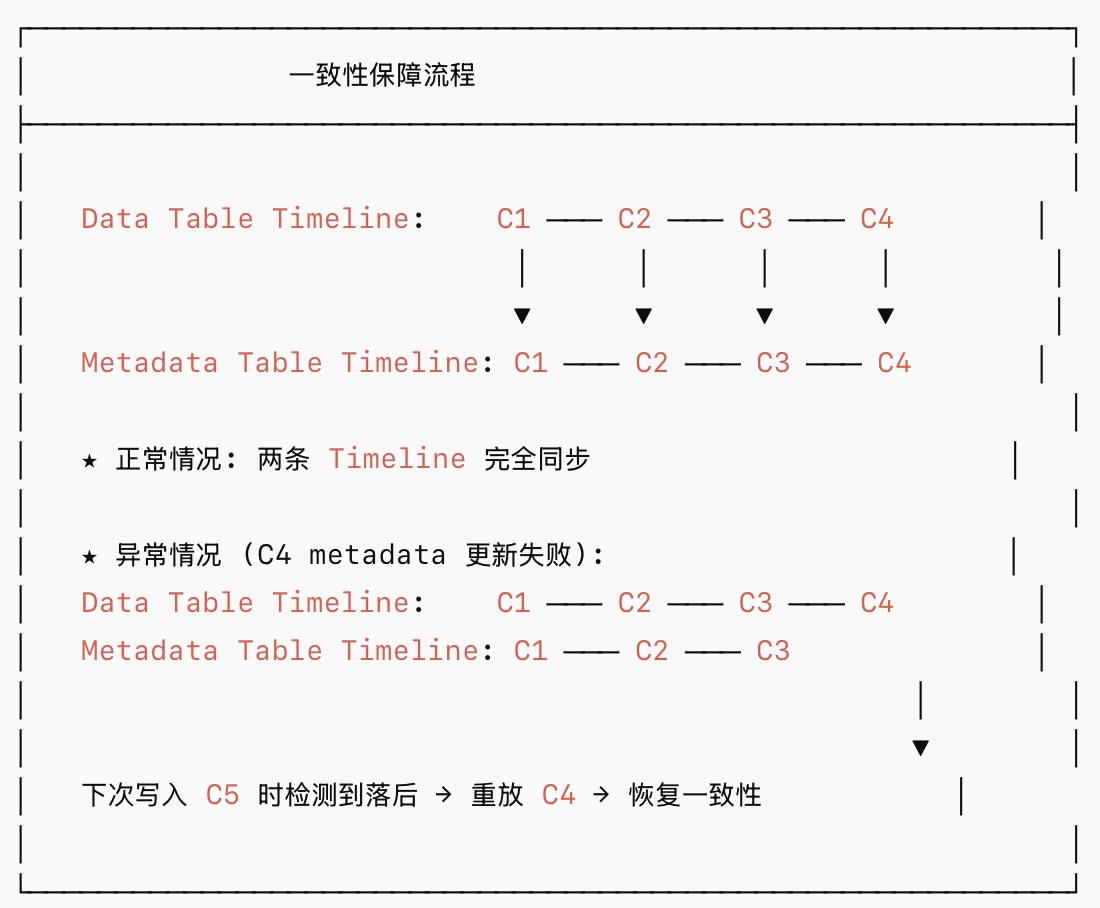
Hudi 1.x 通过以下机制确保 Metadata Table 与数据表的一致性:
- Timeline 同步:Metadata Table 的 instant 与数据表的 instant 一一对应
- Failover 回退:如果 Metadata Table 更新失败,下一次写入会通过 Timeline 检测到不一致,触发自动修复(重放丢失的 commit 到 Metadata Table)
- Validation:通过比较 Timeline 上的 instant,检测 Metadata Table 是否落后于数据表
- 乐观并发控制:多 writer 场景下,基于 Timeline Server 或文件系统锁进行冲突检测
四、分区深度解析
1.Files 分区
功能:替代文件系统的 LIST 操作,存储每个分区路径下的全量文件信息。
数据模型:
- Key:分区路径(partition path)
- Value:该分区下所有数据文件的元信息(文件名、大小、创建时间等)
性能收益:
- 大表场景下查询规划从分钟级降低到秒级
- 消除 S3 LIST 的最终一致性问题
- 降低 API 调用成本
2.Column Stats 分区
功能:存储每个数据文件中各列的统计信息,支持 Data Skipping。
存储的统计项:
- minValue:列的最小值
- maxValue:列的最大值
- nullCount:NULL 值数量
- valueCount:总值数量
- totalSize:列数据的总字节数
Data Skipping 原理:
查询: SELECT * FROM table WHERE city = 'Beijing'
文件 city.min city.max 是否需要读取
─────────────────────────────────────────────────
file_1.parquet "Anhui" "Chengdu" ✗ (跳过)
file_2.parquet "Beijing" "Hangzhou" ✓ (可能包含)
file_3.parquet "Nanjing" "Xian" ✗ (跳过)
file_4.parquet "Wuhan" "Zunyi" ✗ (跳过)
结果: 只需读取 1 个文件,跳过 3 个文件 (75% 跳过率)3.Bloom Filter 分区
功能:存储每个数据文件的布隆过滤器,加速 upsert 时的文件定位。
工作原理:
- 写入时:对每个数据文件中的 record key 构建布隆过滤器并存储到 Metadata Table
- Upsert 时:用传入记录的 key 探测布隆过滤器,快速排除不可能包含该 key 的文件
与传统方式对比:
- 传统方式:每次 upsert 都要从数据文件的 footer 中读取布隆过滤器 → 大量随机 I/O
- Metadata Table 方式:布隆过滤器集中存储,一次顺序读取即可完成所有文件的过滤
4.Record Index 分区
功能:维护 recordKey → (partition, fileGroupId, fileId) 的全局映射,实现 O(1) 的记录定位。
适用场景:
- 超大规模表的 upsert(数十亿记录级别)
- 需要精确定位记录所在文件组的场景
- 全局索引需求(跨分区去重)
性能特征:
- 彻底消除 upsert 时的文件扫描
- 写入时有额外开销(维护索引映射)
- 适合读多写适中、记录量极大的场景
五、Hudi 1.x 中的改进与新特性
相比早期版本,Hudi 1.x 在 Metadata Table 方面有以下关键改进:
|--------------------------|-------------------------------------------|
| 改进项 | 说明 |
| 默认启用 | Metadata Table 在 Hudi 1.x 中默认启用(files 分区) |
| 功能索引框架(Functional Index) | 1.x 引入了对表达式索引的支持,允许基于列的函数表达式构建索引 |
| 二级索引(Secondary Index) | 实验性支持非主键列的索引加速 |
| Record-Level Index 改进 | 更高效的存储格式和查询路径 |
| 并发写入增强 | 改进了多 writer 场景下 Metadata Table 的冲突处理 |
| Compaction 调优 | 更灵活的 Metadata Table compaction 策略配置 |
六、最佳实践
1.基础配置推荐
# 启用 Metadata Table(1.x 默认已启用)
hoodie.metadata.enable=true
# 启用列统计索引(推荐对有过滤查询的表启用)
hoodie.metadata.index.column.stats.enable=true
# 指定需要收集统计的列(避免全量收集增加开销)
hoodie.metadata.index.column.stats.column.list=city,order_date,amount
# 启用布隆过滤器索引(对 upsert 密集表推荐)
hoodie.metadata.index.bloom.filter.enable=true
# 启用 Record Index(超大规模 upsert 场景)
hoodie.metadata.record.index.enable=true2.Compaction 调优
Metadata Table 作为 MOR 表,log 文件会持续增长,需要合理配置 compaction:
# Metadata Table 的 compaction 触发间隔(每 N 个 commit 后触发)
hoodie.metadata.compact.max.delta.commits=10
# 对于高频写入场景,可适当降低此值以控制读取放大
# 对于低频写入场景,可增大以减少 compaction 开销3.初始化 Metadata Table
对已有大表首次启用 Metadata Table 时,会触发初始化过程(遍历全表构建元数据),这是一个一次性的高开销操作,建议在低峰期执行,或通过独立作业完成初始化,初始化完成后后续写入仅需增量更新。
4.避免 Metadata 损坏的防护
# 启用 Metadata Table 的校验
hoodie.metadata.validate=true
# 如果 Metadata Table 损坏,可以通过以下方式重建:
# 1. 删除 .hoodie/metadata/ 目录
# 2. 下次写入时会自动重建5.Column Stats 索引的列选择策略
不建议对所有列开启统计收集,推荐策略:
优先收集统计的列类型:
├── 经常出现在 WHERE 条件中的列
├── 数据分布有明显 clustering 特征的列(如时间列)
├── 基数适中的列(太低则跳过率低,太高则 min/max 无意义)
└── 避免: 高基数字符串列、大对象列、很少用于过滤的列七、常见问题排查
|---------------------|--------------------------|-----------------------------|
| 问题 | 可能原因 | 解决方案 |
| 查询规划仍然很慢 | Metadata Table 未启用或损坏 | 检查配置,必要时删除 metadata 目录重建 |
| 写入失败报 Metadata 错误 | 并发冲突或 Metadata Table 不一致 | 检查锁配置,确认 Timeline 同步状态 |
| Metadata Table 体积过大 | Column stats 收集了过多列 | 精简 column.stats.column.list |
| Compaction 频繁失败 | 资源不足或配置不当 | 调整 compaction 并行度和内存配置 |