目录
用状态机和字典树统计单词:从"能数"到"数得清楚"
学习代码:count/count.c、count/count_every_word.c
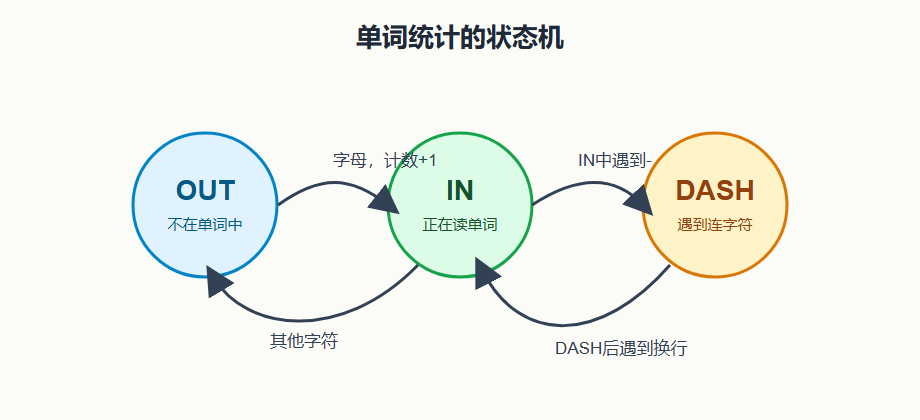
这个练习看起来只是统计文本单词数量,但真正训练的是"状态机思维"。如果只是遇到字母就加一,很快会出错,因为一个单词包含多个字母,连续字母不能重复计数。正确的想法是:遍历每个字符时,先判断自己当前处在什么状态,再根据输入字符决定是否切换状态。
在 count.c 里,我把状态拆成三个:
c
#define OUT 0
#define DASH 1
#define IN 2核心逻辑是从 OUT 读到字母时,说明一个新单词开始,所以计数加一;如果已经在 IN 状态,再读到字母就不重复加。代码片段如下:
c
if (isalpha((unsigned char)c))
{
if (status == OUT)
words++;
status = IN;
}
else if (c == '-' && status == IN)
{
status = DASH;
}
else if (c == '\n' && status == DASH)
{
status = IN;
}
else
{
status = OUT;
}这里我觉得最有价值的是 DASH 状态。英文文本里可能出现 word-\nword 这种换行断词,如果简单把横杠和换行都当成分隔符,就会把一个词误判成两个词。新增 DASH 状态后,程序能表达"我刚刚在单词中遇到了横杠,下一步要看是不是换行"的中间态。这个中间态就是状态机比简单 if 判断更清晰的地方。
在 count_every_word.c 中,需求从统计总数升级到统计每个单词出现次数,于是引入字典树:
c
typedef struct TrieNode_s
{
struct TrieNode_s *nodes[26];
int counts;
} TrieNode;每读到一个字母,就沿着 nodes[c - 'a'] 往下走;单词结束时,在当前节点 counts++。字典树的好处是前缀可以复用,比如 app 和 apple 前三个节点共用,查询和插入的复杂度主要取决于单词长度。
我的体会是,文本处理不能只盯着"字符",还要盯着"上下文"。状态机负责识别单词边界,字典树负责保存统计结果,一个解决解析问题,一个解决存储问题。把这两个工具组合起来,代码就从零散判断变成了有结构的程序。