TPU本质上是一种专门用于矩阵运算的计算核心(TensorCore),与高速内存(也叫高带宽内存,HBM)结合使用。
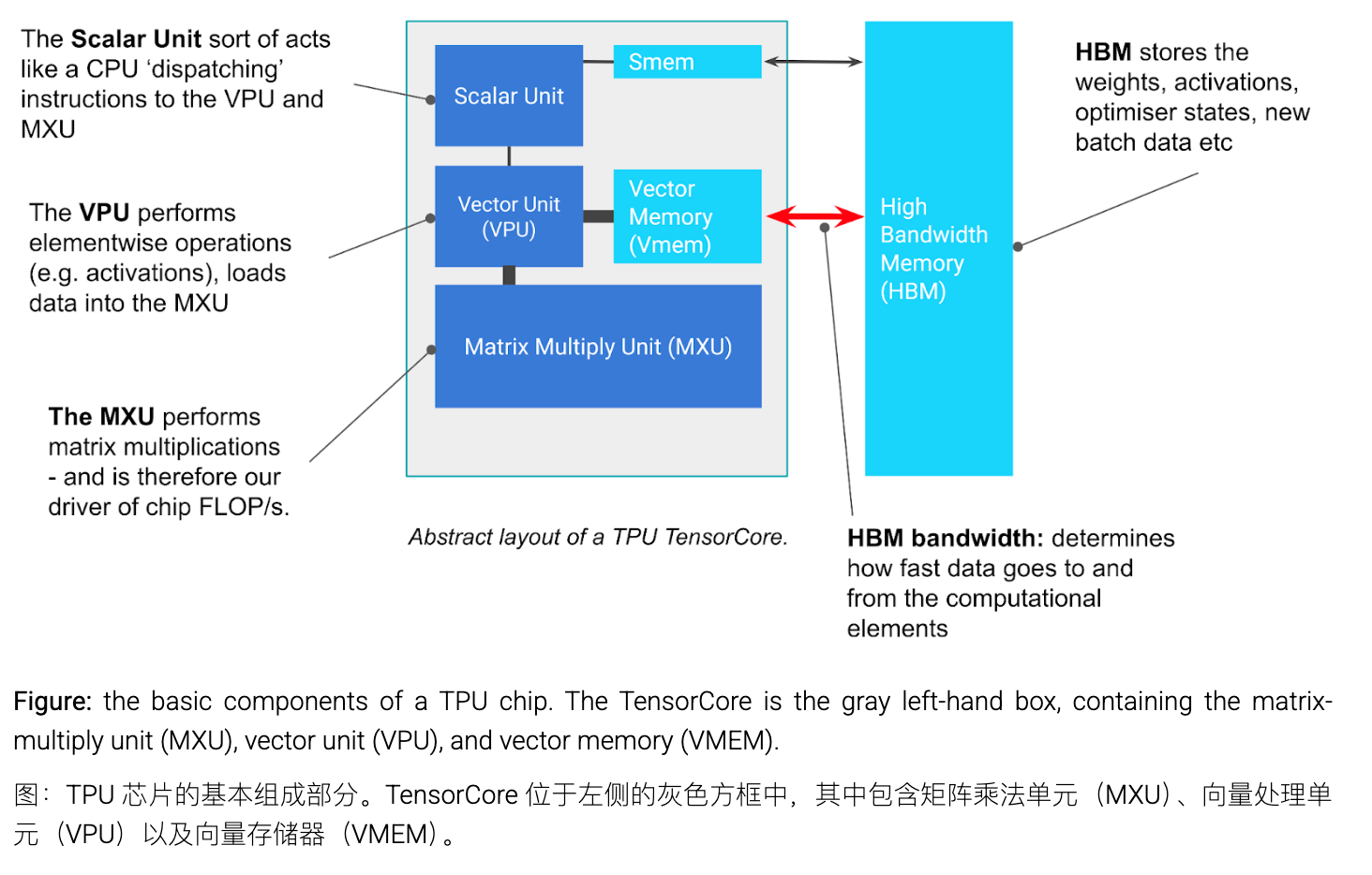
TPU的工作方式
TPU先把权重从HBM加载到VMEM,然后再从VMEM加载到systolic array中,这个systolic array每秒大约可以执行200万亿次乘加运算。
HBM和VMEM之间的带宽,以及VMEM和systolic array之间的带宽,决定了TPU能够执行高效执行哪些计算。
- systolic array 脉动阵列,专门高效执行矩阵乘法/乘加运算的硬件结构
关键组成部分
MXU Matrix Multiply Unit
MXU 矩阵乘法单元,是TensorCore的核心组件。
VPU Vector Processing Unit
向量处理单元,执行ReLU激活函数调用,以及点对点加法或乘法运算。该单元还能进行求和等运算。
VMEM Vector Memory
向量内存是一种位于TensorCore芯片内部的临时存储区域,位置靠近各个计算单元。与HBM相比,VMEM的容量要小得多。VMEM的运作方式类似CPU中的L1/L2缓存。在TensorCore上对HBM中的数据进行处理之前,必须先将其复制到VMEM中。
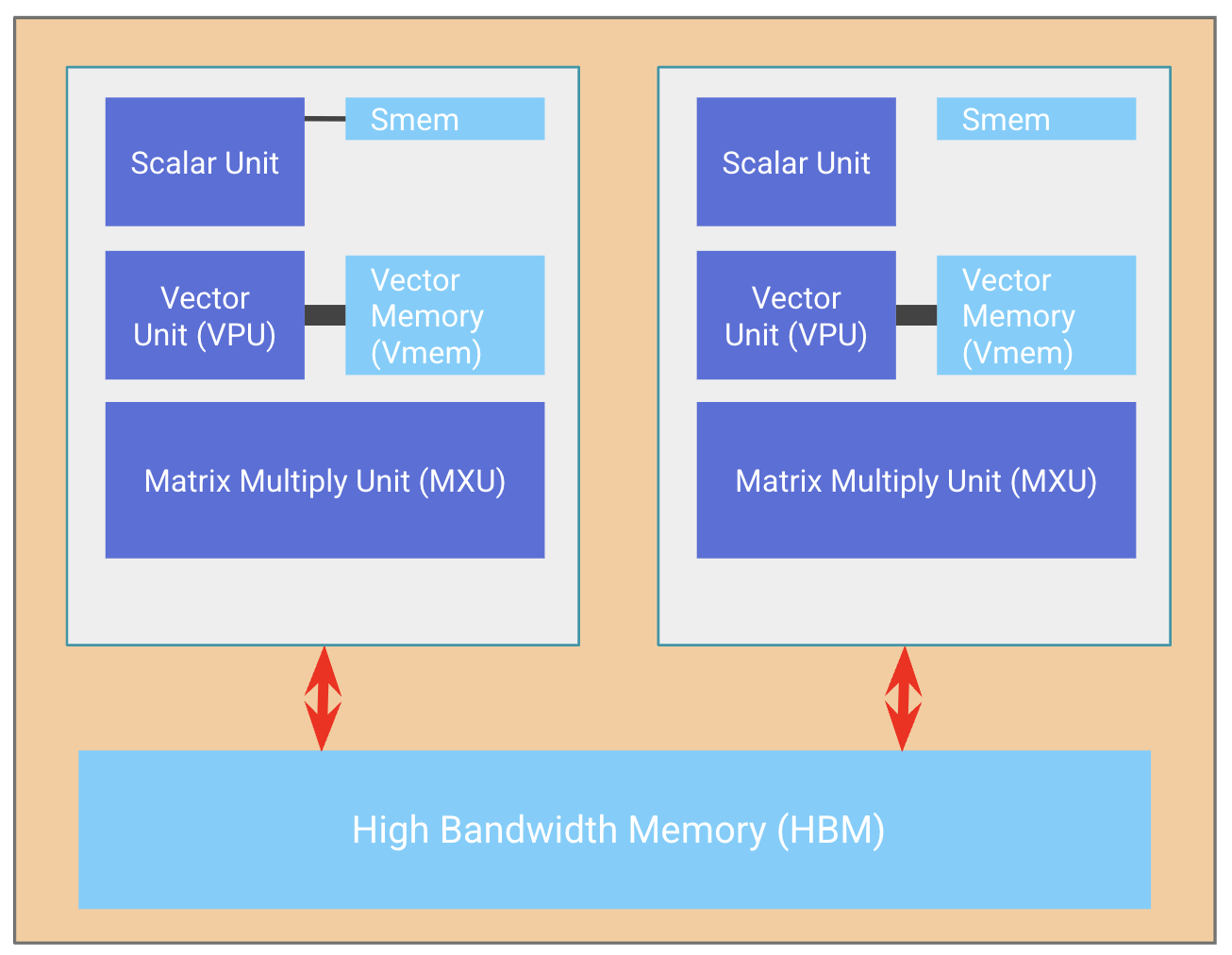
TPU芯片组成
TPU芯片通常由两个TPU核心组成,这两个核心共享内存。可以被视为一个大型加速器,其浮点运算能力是普通加速器的两倍。
两个核心之间通过HBM来协同工作的TPU。橘色框框是一个chip。
chip 以四个一组的形式被安置在 tray 上,这些 tray 通过PClc网络来和CPU主机相连。
4个chip,8个核心(可以认为是4个逻辑核心)。
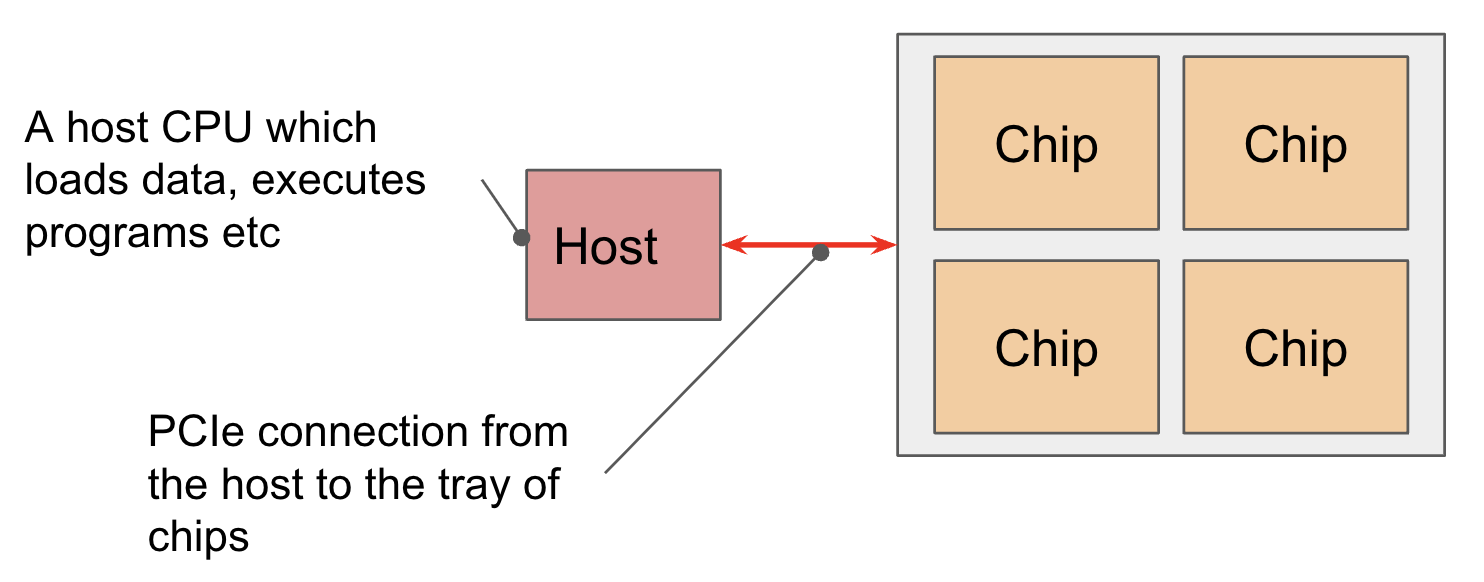
PClc
PClc的带宽是有限的,限制了数据从主机内存传输到HBM,或者从HBM传输到主机内存的速率。
TPU 网络技术
chip 在 一个 Pod 中,通过ICI网络相互连接。
- chip 指单个TPU芯片
- pod 指很多TPU芯片组成的大规模计算集群单元
- ICI Inter-Chip Interconnect 芯片之间的高速互联网络
2D和3D结构
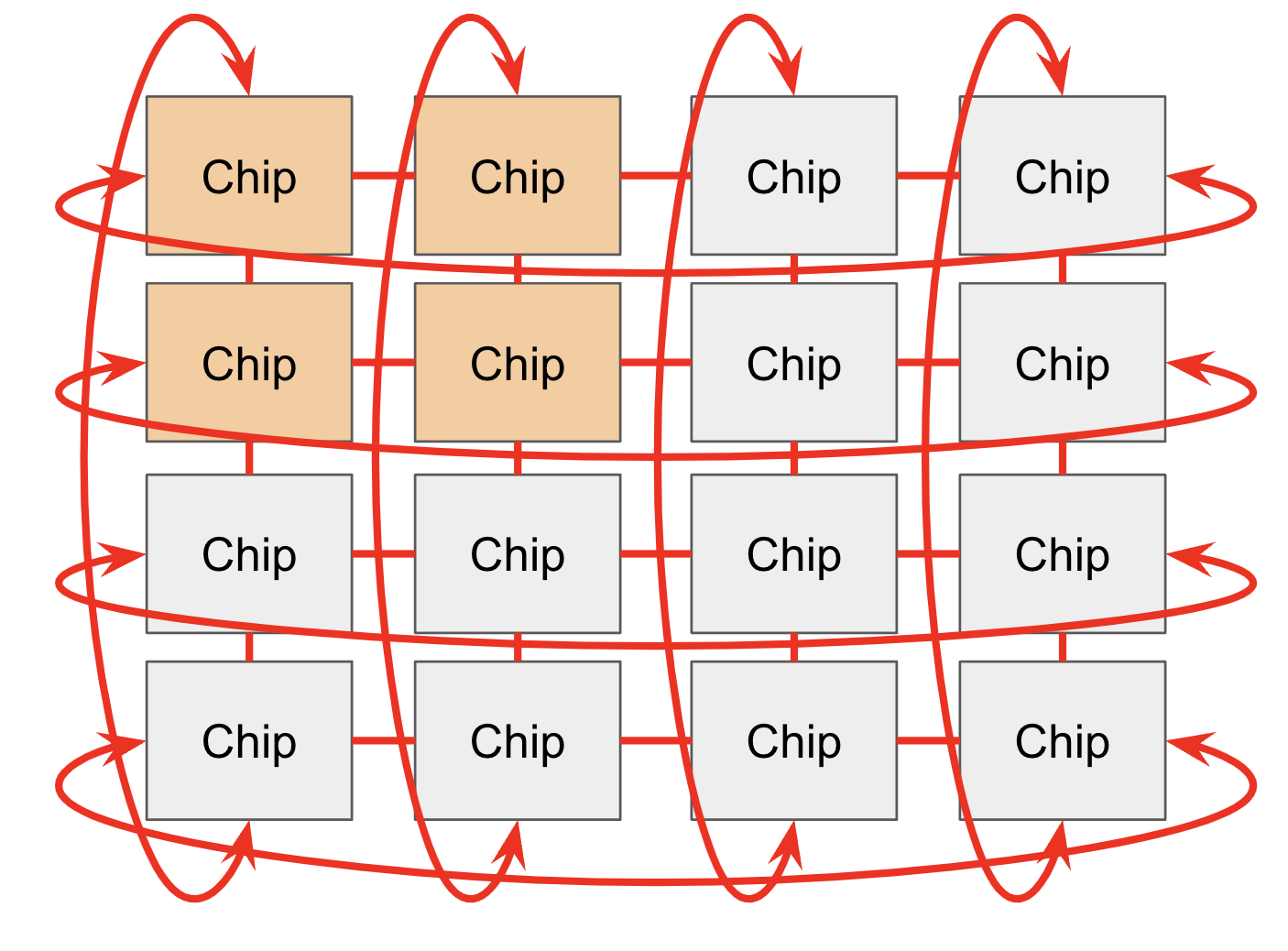
- 环绕传输和拓扑结构
虚拟内存与算术运算强度
VMEM的容量比HBM小,但是VMEM与MXU之间的数据传输带宽比HBM大。
如果一个计算任务的数据能全部放进VMEM,就不用频繁从HBM搬数据,TPU的MXU就能很快被喂饱;即使这个算法本身"计算量/数据量"不高,也仍然可能跑得很快。
- 算术强度 Arithmetic Intensity = FLOPs / Bytes ;表示每搬运 1 byte 数据,能做多少次运算。
- 算术强度低,容易遇到 memory-bound
带宽限制
通信受到各种网络带宽的限制。
- HBM带宽 指的是 TensorCore 与其所连接的 HBM 之间的数据传输带宽。
- ICI带宽 指的是 TPU 芯片与其最近的4个或6个相邻芯片之间的数据传输带宽。
- PCle带宽 指的是 CPU主机与其所连接的芯片组之间的数据传输带宽。
- DCN带宽 指的是多个CPU主机之间的连接带宽,这些主机通常不是通过ICI来连接的。
补充
bf16 可参考文章