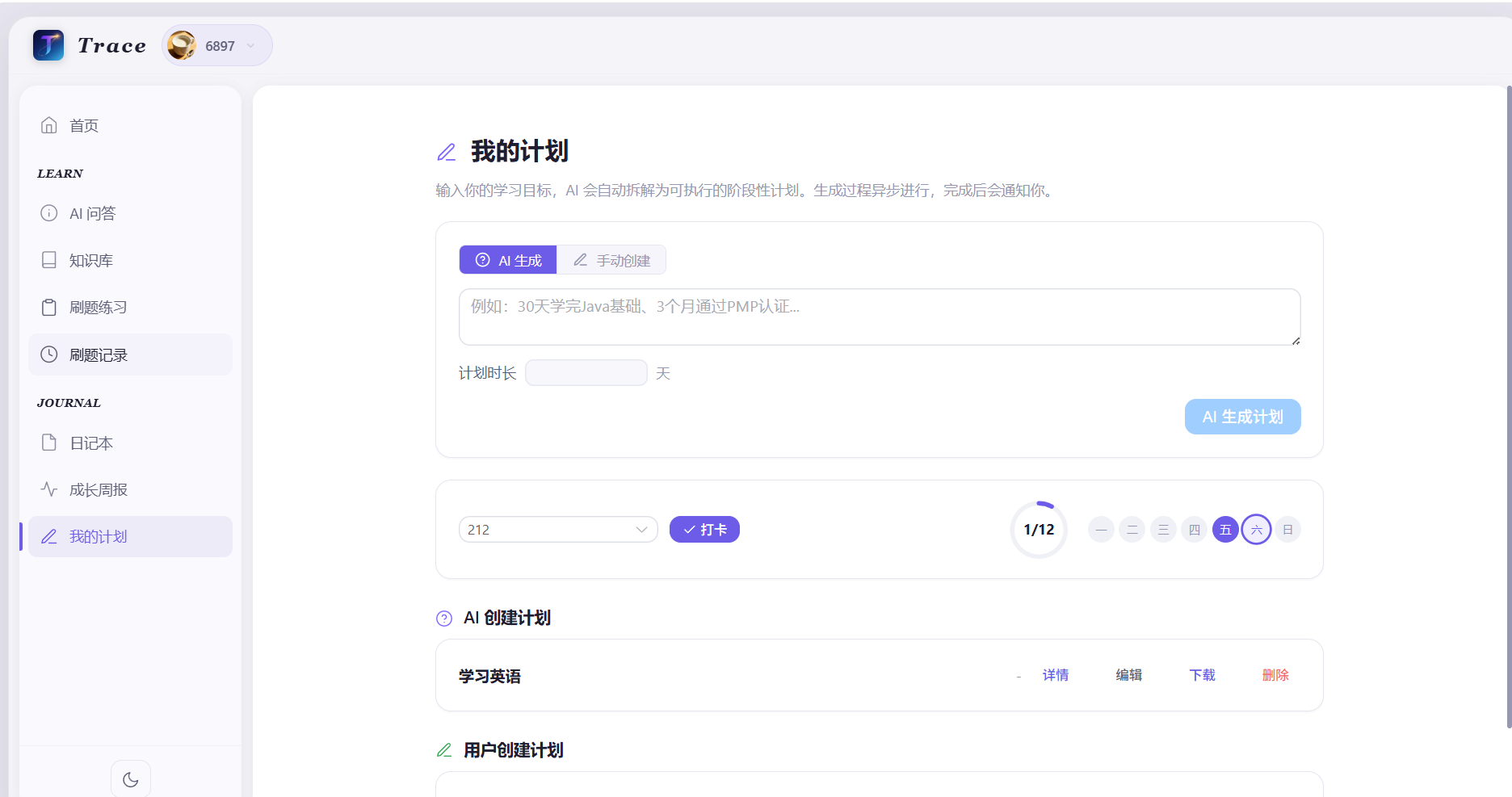
最近也是用ai独立开发一个玩具项目,不过登录模块,限流,长期记忆和rag问答检索流程,还是花了比较多的时间去想和实现的,目前已经开源到了,感兴趣的朋友可以去看看。one7ing/trace: my first independence creats project
其实用ai开发的这段时间还是觉得,核心业务还是得我们自己来review,因为很可能ai已经给你写了一大堆的屎山代码。
接下来我说说比较值得去学习的几个地方吧。
双Token鉴权机制
解决了什么问题:传统JWT方案Token有效期固定,被窃取后风险窗口大,登出后无法主动失效。
怎么解决的:基于Spring Security + JWT实现了双Token机制------短Token 15分钟有效用于日常鉴权,长Token 7天有效仅用于无感刷新。结合Redis白名单/黑名单策略,支持Token主动失效与登出控制。这要求前端配合,前端设置一个全局拦截器,然后用长token进行短token请求。
这一部分是在阅读javaguide的时候得到的灵感,然后马上去进行了设计和修改,发现效果还是不错的。

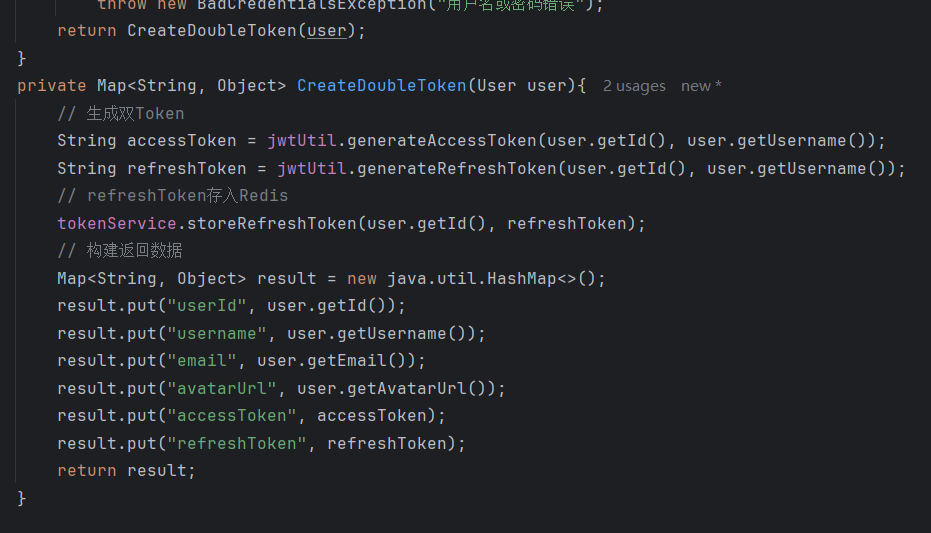
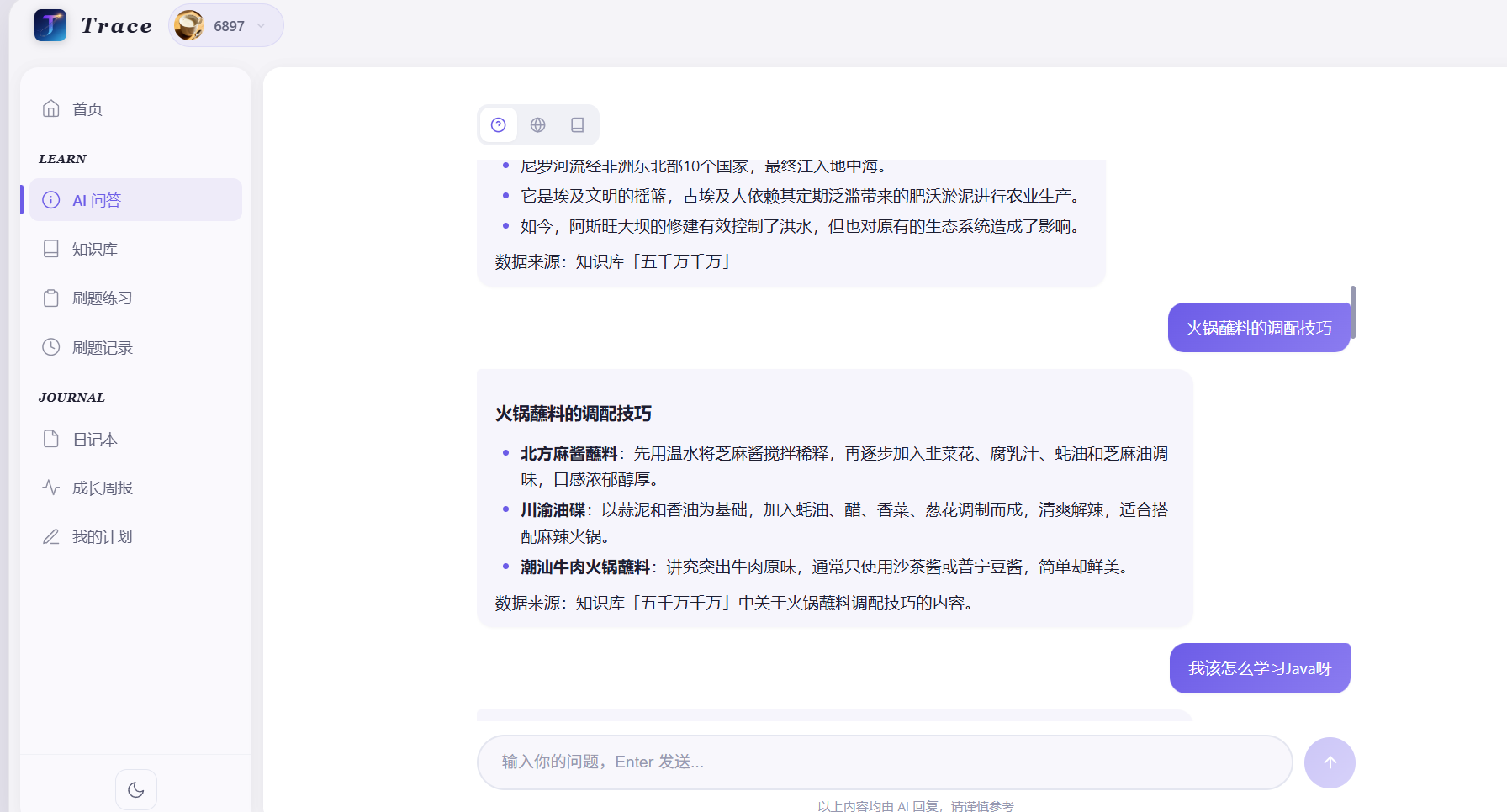
根据知识库类型的检索策略
解决了什么问题:不同类型的知识,检索需求不同。闲聊知识(公司文化、生活常识)用自然语言提问,需要语义理解;专业知识(Java面试题、技术文档)包含大量精确术语,需要关键词匹配。
怎么解决的:设计双模式检索策略------闲聊类知识走纯语义检索,专业类知识走向量+全文混合检索。配合查询改写。
这一部分特别是在对于如何切块和如何设置阈值,我是一个个试的然后通过和ai的交互,测试最终才确定了这部分怎么做。当然也只能保证大部分没问题。
分层记忆体系
解决了什么问题:让AI在跨会话场景下记住用户是谁、经历过什么,而不是每次对话都从零开始。
怎么解决的:构建了"短期+长期"双层记忆架构。短期记忆存Redis,维持当前对话连贯性;长期记忆存PgVector,通过事件驱动+MQ异步提取+向量去重+容量控制。
自定义滑动窗口限流
解决了什么问题:接口被恶意刷量时,需要后端精确控制请求频率。固定窗口限流存在"边界突刺"问题(2秒内可能通过2倍限制)。
怎么解决的:基于Redis + Lua实现了滑动窗口限流。通过自定义@RateLimit注解和Spring MVC拦截器,支持全局、用户、IP等多维度精确限流,有效防止边界突刺。
在这一块我发现对于流式对话它会进行两次限流判断。
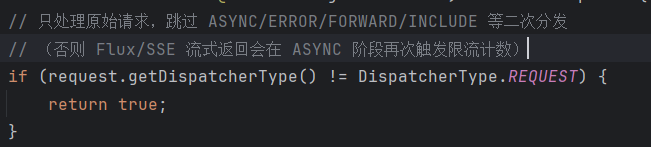
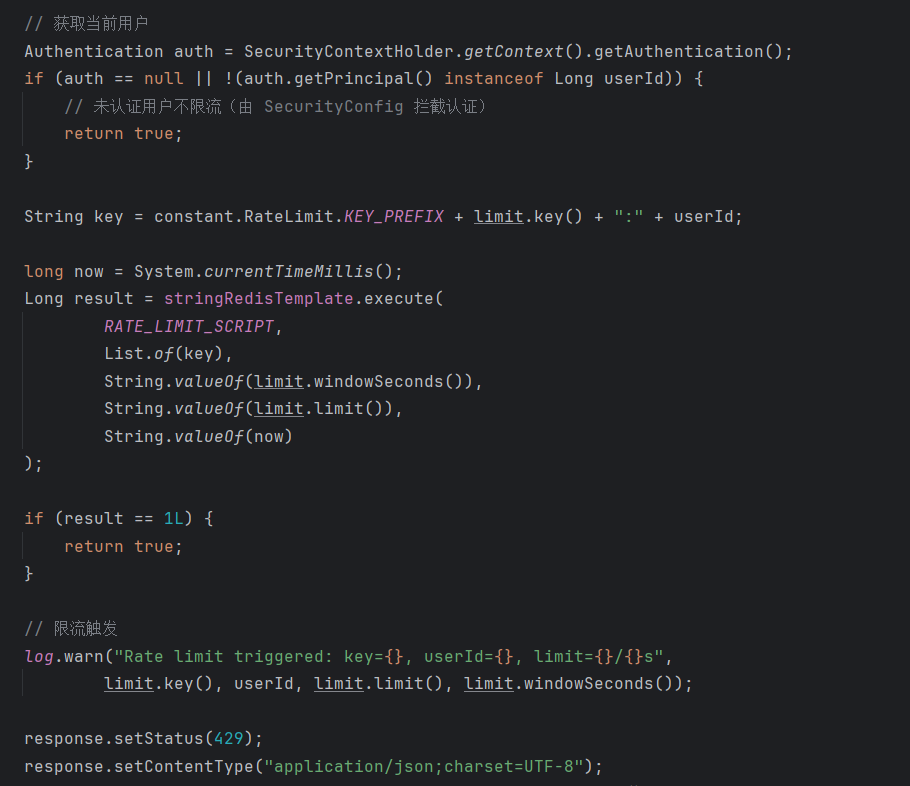
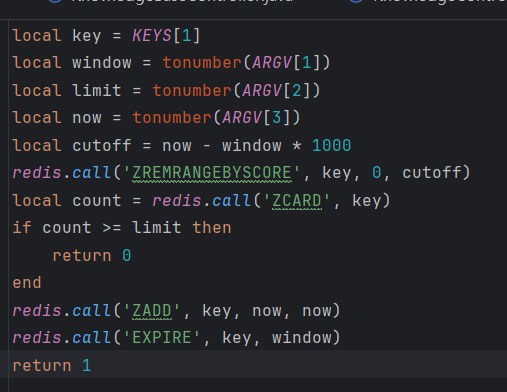
这一块为什么没有使用aop,其实aop也是可以的,但是我个人认为,aop重点是在业务,但是针对我这个项目来说,直接在接口拦截更好,我们可以直接获取response,然后直接设置消息返回。
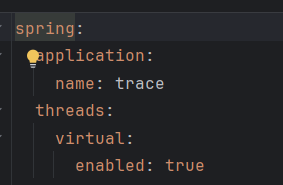
Java 21 虚拟线程
解决了什么问题:AI对话涉及大量I/O操作(调用大模型、向量检索、数据库读写),传统线程池在并发场景下效率低下。
怎么解决的:在流式对话与SSE长连接场景中启用Java 21虚拟线程,用同步代码实现异步级并发能力,平台线程在等待I/O时自动释放,大幅提升并发吞吐量。
虚拟线程的诞生,直接打破了tomcat连接池的限制,甚至可以直接创建上万个虚拟线程。不过要注意真正干活的就那几个,所有它只适合io密集型,它的核心价值在于解放了平台线程,让平台线程不用阻塞,加大cpu的利用。配置很简单,直接在配置文件开启,然后自动替换。这里是直接替换了tomcat层面的,我项目也只需要这个。但是如果是其他异步任务也需要的话可以直接注入 VirtualThreadTaskExecutor 来执行自己的异步任务。
或者**@Async ,** 如果启用虚拟线程,@Async 默认也会使用虚拟线程执行器(需配合 @EnableAsync)
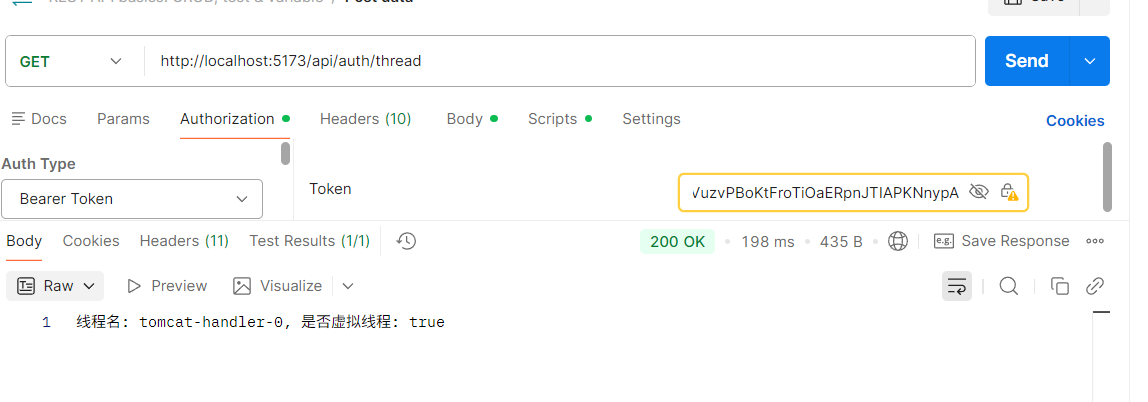
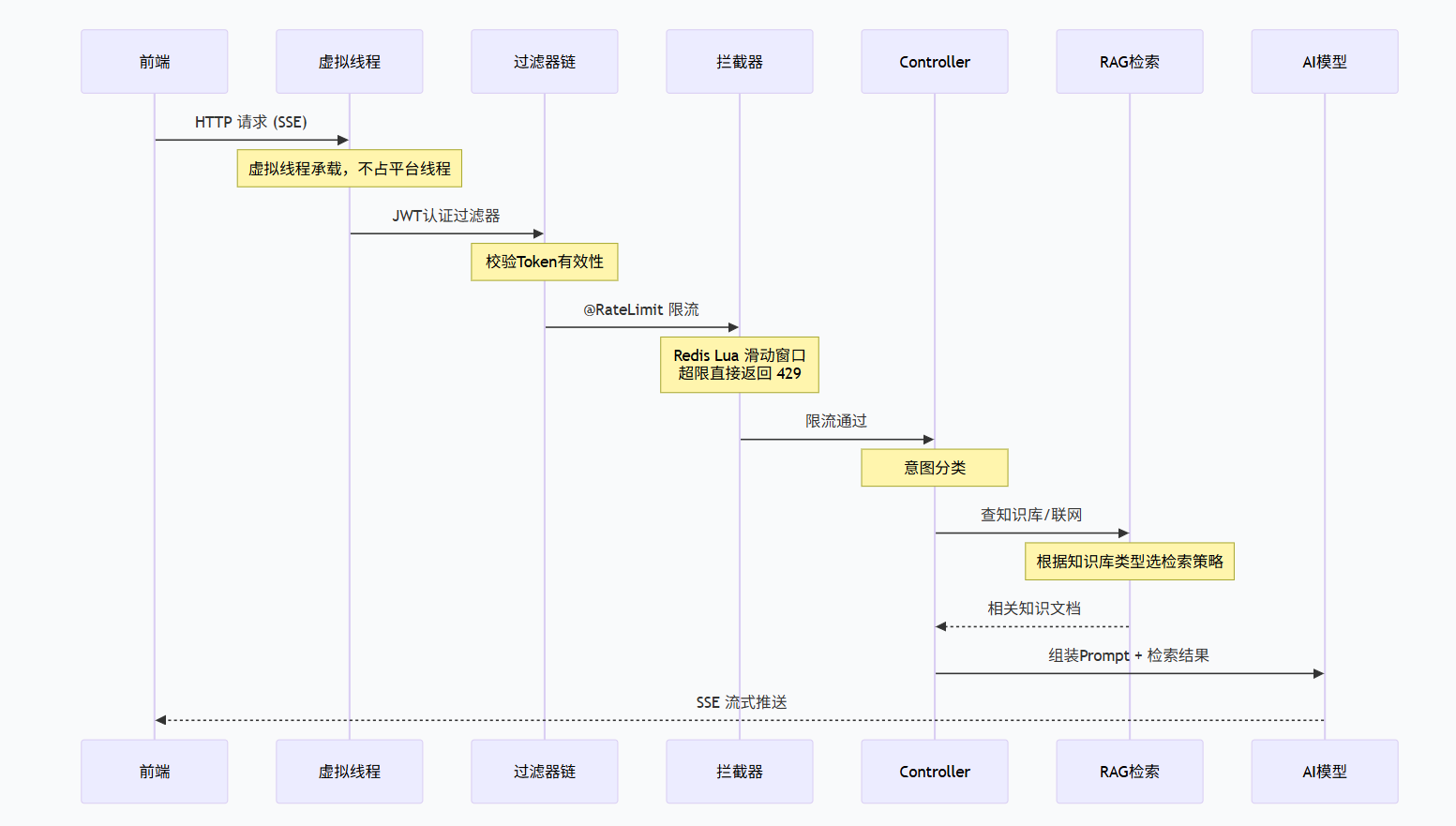
整体请求链路流程图
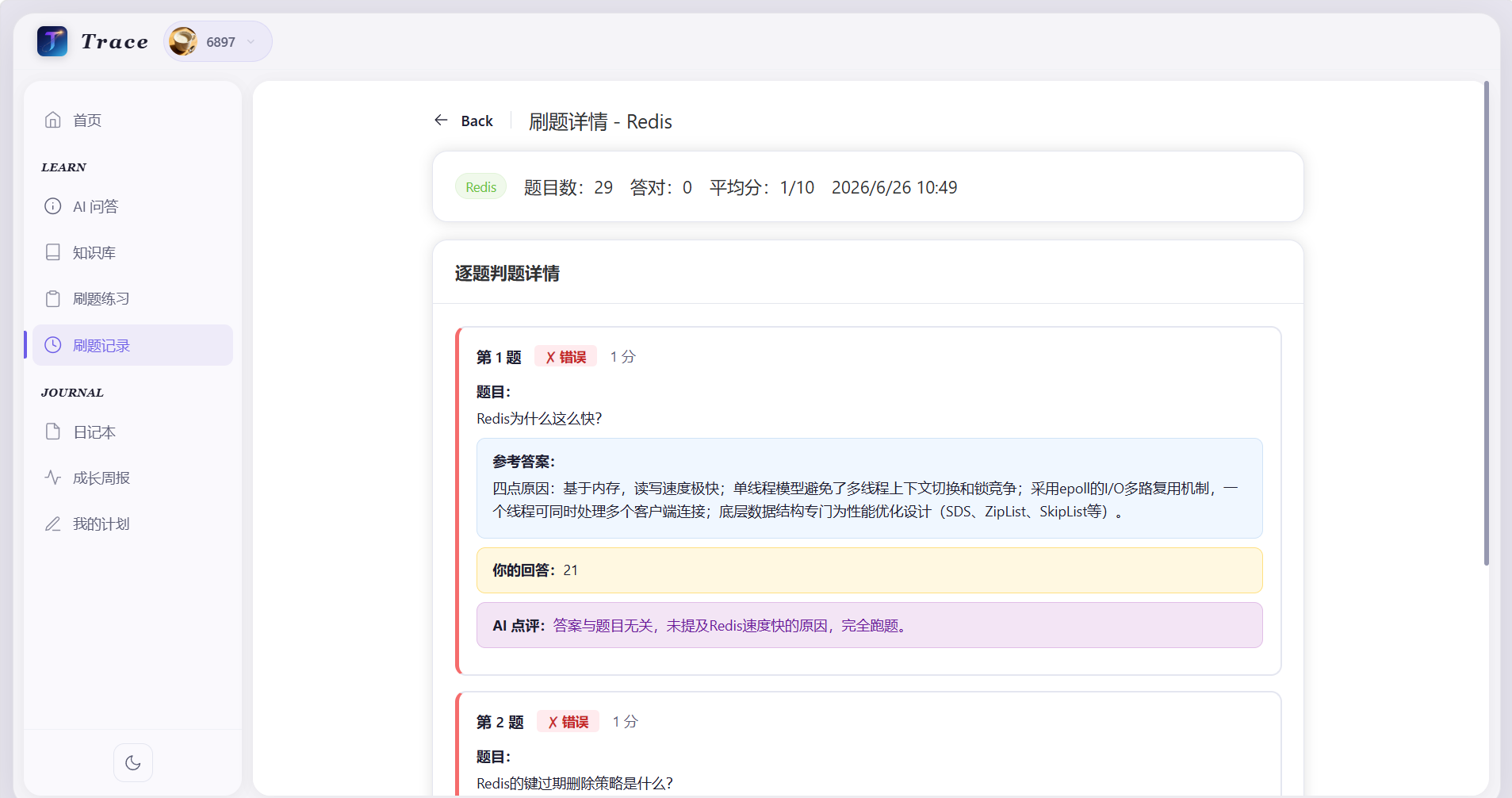
功能展示
总结
其实自己开发这些东西,虽然是和ai协作开发的,但是收获还是很多的,对于项目模块架构的设计,对于功能的优化,测试,这些东西我觉得还是得人来自己想,全交给ai还是不行的。并且当时ai给我写了很多屎山代码,我是一点点去改的,当时改的是真的痛苦,可读性不是很好,所有在进行ai开发的时候,首先就要把限制要求,代码开发规范,那些东西别动,那些东西它可以自己觉得,给他全部限制好。