note
1、文主实验用的 base VQA model 是 VisualQuality-R1,一个 VLM/视觉语言模型式的视频质量评估模型;微调方式是 LoRA + reinforcement-learning-to-rank,不是简单的"视频 → MOS 分数"的 MSE 回归。
2、他们在主实验中采用 VisualQuality-R1 作为 base VQA model,因为它是强的 VLM setting;failure predictor 也是在这个 base model 上加 LoRA,并用固定 prompt 让模型输出"这个视频质量评估有多难"的 difficulty score
3、训练数据:视频 + prompt → 质量判断 / 排序结果 / 分数
4、总结:MDS-VQA 这篇论文主实验是"筛选难样本视频 → 人标质量 → 构造成 pairwise quality ranking 数据 → 用 LoRA 微调 VisualQuality-R1 这种 VLM-VQA 模型",不是传统的简单 MOS 回归微调。
5、关键创新不是"又设计了一个更复杂的视频质量网络",而是把 模型诊断 → 数据选择 → 人工标注 → 模型微调 连成闭环。
它优先选择两类价值最高的样本:一类是对模型困难的,另一类是覆盖内容和失真类型更广的。
6、类型比较:
| 类型 | 输入 | 输出 | 微调数据长什么样 |
|---|---|---|---|
| 传统/专用 VQA 模型 | 视频帧/视频片段 | 一个质量分数,例如 MOS/DMOS | 视频 -> 人类质量分数 |
| LMM-VQA / 多模态大模型式 VQA | 视频 + 文本 prompt | 分数、等级、理由、JSON | 视频 + 指令文本 -> 分数/理由/JSON |
7、实验结论:
MDS-VQA 选出来的样本更容易暴露模型失败点,而且用很少的数据就能提升跨域效果。论文报告在每个目标域只选约 5% 子集 做标注和微调时,平均 SRCC 从 0.651 提升到 0.722,并在 gMAD 对抗式比较中取得最好排名,说明它选的数据确实更"有训练价值"。
文章目录
一、研究背景
MDS-VQA: Model-Informed Data Selection for Video Quality Assessment
CVPR 2026 Highlight
代码:https://github.com/Multimedia-Analytics-Laboratory/MDS-VQA
模型开源:https://huggingface.co/hollow404/VQR1-7B-YouTubeUGC/tree/main
核心:
1、挑出最值得标注的视频作为训练集、评测集,基于VisualQuality-R1进行Lora微调一个视频质量评估模型
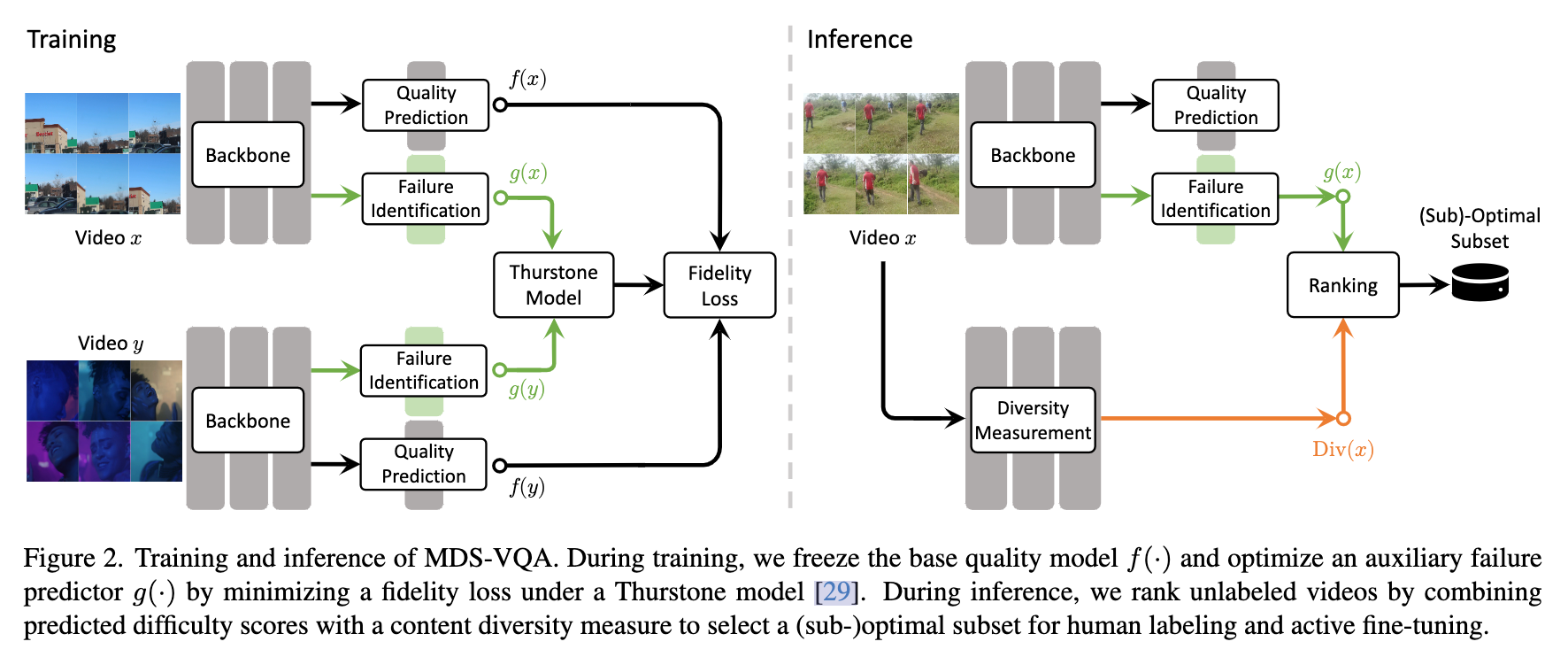
2、MDS-VQA 先冻结已有 VQA 模型 f,训练一个 failure predictor g 来判断哪些视频会让 f 出错(视频质量评估模型f容易出错的,说明这条是hard视频样本);推理时再结合 g(x) 的困难度和 Div(x)的多样性,从未标注视频中筛出最值得人工标注的子集,最后再用这些样本去微调 VQA 模型。
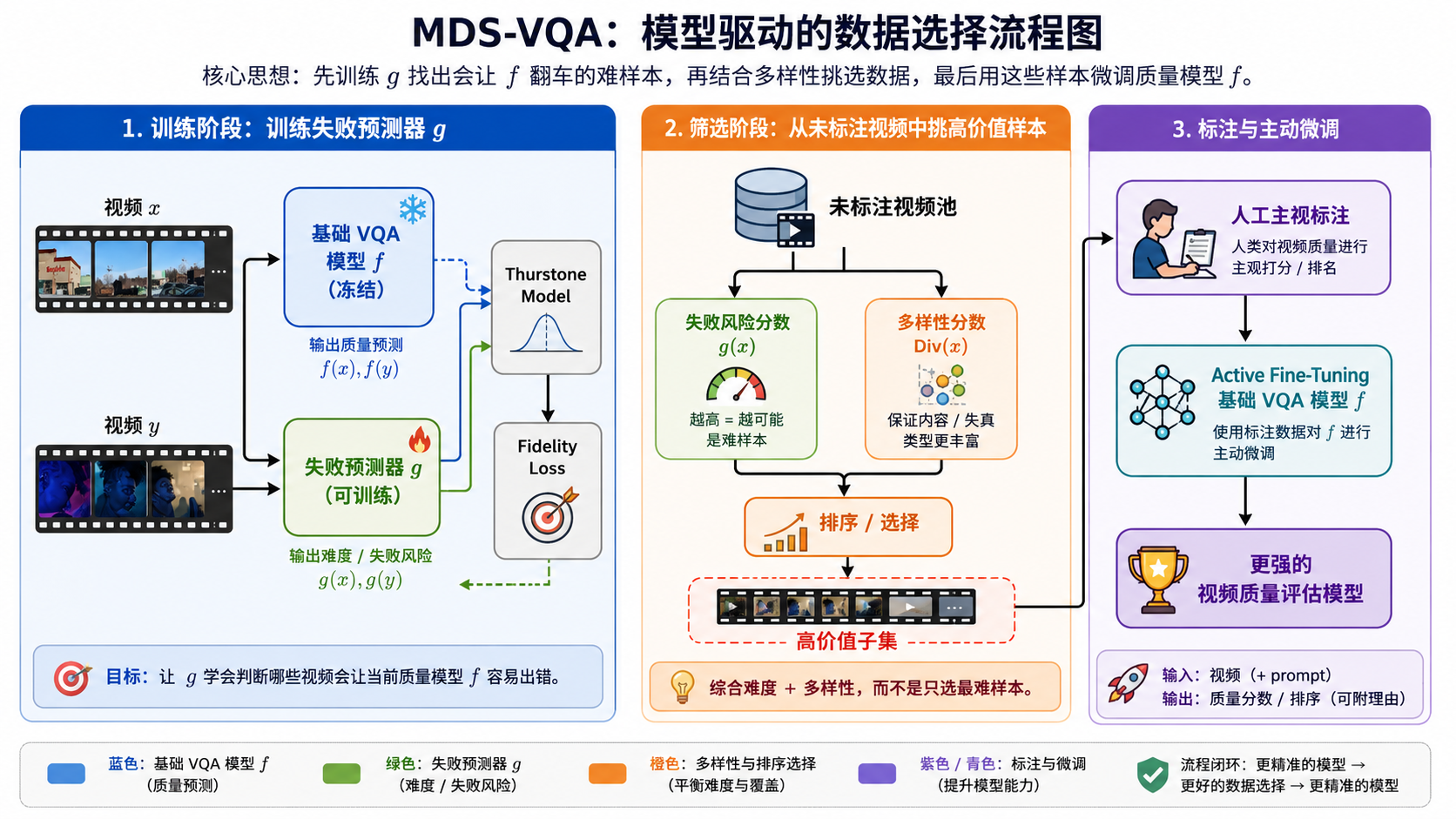
- 研究问题:这篇文章要解决的问题是如何在视频质量评估(VQA)中有效地选择和标注难以处理且内容多样的未标注视频,以提高模型的适应性和泛化能力。
- 研究难点:该问题的研究难点包括:模型设计和数据集创建之间的脱节,模型中心的方法通常在固定的基准上进行迭代,而数据中心的方法则花费大量资源收集新的人类标签,但没有系统地针对现有VQA模型的弱点进行改进。
- 相关工作:该问题的研究相关工作有:早期的VQA模型依赖于手工特征,深度学习模型直接从数据中学习感知线索,最近的大规模预训练模型利用丰富的视觉先验知识来实现更人类对齐的质量推理。数据中心的VQA主要通过主观研究收集人类感知判断,但这些工作通常没有系统地针对当前顶级VQA模型的失败模式。
二、MDS-VQA
这篇论文提出了MDS-VQA,一种基于模型信息的数据选择机制,用于VQA。
- 难度估计:首先,通过一个带有排名目标的辅助失败预测器来估计每个未标注视频的难度。该预测器通过低秩适应(LoRA)模块附加到基础VQA模型的线性层上,使用Thurstone模型将预测误差解释为单位方差高斯随机变量的均值,并通过损失函数优化预测器的输出。
- 多样性测量:其次,使用深度语义视频特征来衡量内容的多样性。具体来说,每个视频被表示为一组帧级语义特征,通过帧级特征之间的Chamfer距离来测量两个视频之间的不相似性。
- 选择策略:然后,结合难度估计和内容多样性度量来选择一个预算内的子集进行人工标注。采用贪心选择策略,迭代地选择最难且最不重复的视频。
- 主动微调:最后,在选定的子集上进行主动微调,使用LoRA进行参数高效的微调,以避免过拟合或灾难性遗忘,同时仍然能够高效地适应模型挑战样本。
绿色分支:这个视频对当前 VQA 模型来说有多容易出错 / 有多难。
具体做法:
1、先有一个基础 VQA 模型,用来预测视频质量分数。
2、再训练一个 failure predictor / difficulty predictor,判断某个未标注视频对当前 VQA 模型来说"有多难"。
3、在大量未标注视频池中,不只选"最难"的,还要选"内容多样"的,避免全是同一种黑场、抖动、压缩噪声。
4、用 greedy 策略在有限标注预算下选出一个小子集。
5、对这些视频做人类主观标注,再拿来 active fine-tuning 原 VQA 模型。
三、实验设计
- 数据集:使用了五个VQA数据集,包括YouTube-UGC、CGVDS、LIVE-Livestream、YouTube-SFV+HDR和AIGVQA-DB。YouTube-UGC作为源数据集用于训练基础模型,其他四个数据集作为目标域的"未标注"池。
- 实现细节:首先在YouTube-UGC上训练VisualQuality-R1以获得基础VQA模型。然后,训练失败预测器g(⋅),使用LoRA模块附加到基础模型上,训练过程中使用AdamW优化器,学习率为1×10−5,批量大小为8,训练10个epoch。
- 选择过程:在目标域的未标注池中使用贪心规则选择5%的子集进行标注。最后,在YouTube-UGC训练集和目标域选定的子集上更新基础VQA模型。
四、结果与分析
- 失败识别:在所有评估的目标域上,MDS-VQA在识别困难样本方面表现最佳,显著降低了基模型预测与人类判断之间的相关性。例如,在CGVDS上,MDS-VQA将SRCC降低到0.162,而随机采样的SRCC为0.673。
- 主动微调增益:在YouTube-UGC训练集和目标域选定的子集上进行微调后,MDS-VQA的平均相关性最高,表明选定的样本提供了广泛且可迁移的监督,而不是狭窄的领域特定过拟合。
- gMAD竞争:在LSVQ-1080p上进行gMAD竞争,MDS-VQA在平均情况和最坏情况下的评估标准上都达到了最高的gMAD排名,表明其增益在不同评估标准下都是一致的。
Reference
1 MDS-VQA: Model-Informed Data Selection for Video Quality Assessment