第五章 图像表达(题目)
1.简述Canny算子的边缘检测步骤:

2. 边缘检测。(1)Sobel算子和马尔算子各为几阶微分算子?请给出Sobel算子的3X3模板形式?(2)微分算子对图像噪声敏感,低通滤波可抑制噪声。试解释Sobel算子和马尔算子分别如何体现了这种思想?

3.特征表运。一副灰度图像,提取灰度直方图,LBP直方图,HOG特征、SIFT特征。

4. 图像经过线性灰度变换,HOG和LBP特征的变化(12),给一个rgb图,然后对图像里的像素采用y=a*x+b处理,(a>0),然后有3问,问经过变换后亮度,饱和度,色度相较于原先是否发生改变,问经过变换后的图像和之前相比,梯度方向直方图是否发生了变化,说明原因,问LBP是否发生了变化。
第一问:亮度、饱和度、色度是否发生改变?
结论:亮度改变,饱和度改变,色度(色相)不变。
- 原因分析 :设原始RGB通道值为 (R,G,B),经过线性变换 (y = a \cdot x + b) ((a>0)) 后,各通道变为 (R' = aR+b), (G' = aG+b), (B' = aB+b)。
- 亮度(Luminance/V) :由于像素的整体强度值发生了缩放和平移,图像的亮度值必然改变。
- 饱和度(Saturation/S) :饱和度公式为 S=max−minmaxS = \frac{\max - \min}{\max}S=maxmax−min。变换后 S′=a(max−min)a⋅max+bS' = \frac{a(\max - \min)}{a\cdot\max + b}S′=a⋅max+ba(max−min)。由于常数项 (b) 的存在,分子分母比例发生偏移,因此饱和度改变(除非 (b=0))。
- 色度(Hue/H) :色度由 RGB 通道之间相对差值的比例确定(例如 (H \propto \frac{G-B}{R-\min}) 等)。由于三通道应用的是相同的缩放系数 (a) 和平移量 (b) ,在计算差值相减时,平移项 (b) 会相互抵消,只剩下 (a) 倍原始差值;再相比时,系数 (a) 也被约去。因此色度(色相)保持不变。
第二问:经过变换后,梯度方向直方图(HOG)是否变化?
结论:HOG特征向量保持不变(前提是进行了L2归一化)。
- 原因分析 :
- 图像经过线性变换 (I'(x,y) = a \cdot I(x,y) + b) 后,对其求空间一阶偏导(梯度):
(\nabla I' = a \cdot \nabla I) - (注:常数项 (b) 在求导过程中直接变为0被抵消)。
- 计算梯度方向 时:(\theta' = \arctan\left(\frac{G'_y}{G'_x}\right) = \arctan\left(\frac{a G_y}{a G_x}\right) = \arctan\left(\frac{G_y}{G_x}\right) = \theta)。梯度方向绝对不变。
- 计算梯度幅值 时:(|G'| = a \cdot |G|)。梯度幅值整体统乘了系数 (a)。
- 为什么最终不变 :标准HOG算法在生成描述子后,一定会对特征向量进行 (L_2) 范数归一化。因为所有直方图Bin的值都等比例乘以了 (a),在归一化时,系数 (a) 会直接被作为公因数约去,因此最终输出的HOG特征向量完全不变。
- 图像经过线性变换 (I'(x,y) = a \cdot I(x,y) + b) 后,对其求空间一阶偏导(梯度):
第三问:经过变换后,LBP是否变化?
结论:LBP完全不变。
- 原因分析 :
- LBP(局部二值模式)的核心是比较邻域像素 (I_p) 与中心像素 (I_c) 的大小关系。
- 根据公式比较条件为:(I_p \ge I_c) 则标记为1,否则为0。
- 图像经过线性变换后,比较条件变为:
(a \cdot I_p + b \ge a \cdot I_c + b) - 由于题干明确给出 (a>0)(正缩放),不等式左右两边同时减去 (b) 并除以 (a),不等号方向不变,直接等价于原始条件:(I_p \ge I_c)。
- 结论 :对于图像上的每一个像素点 ,邻域像素与中心像素的相对大小关系不会发生任何改变 。因此,每个像素计算出的8位二进制序列、十进制LBP编码值,以及最终的LBP统计直方图均绝对保持不变。
5. HOG和LBP和空间位置有关系,如何证明他两和空间位置有关系,旋转不变性,给定一个方法,让HOG和LBP也具有旋转不变性
1. 如何证明 HOG 和 LBP 与空间位置有关系?
证明逻辑 :HOG 和 LBP 的标准提取流程包含了**"分块统计"和"向量级联"**的操作,这使得它们天然隐含了空间布局信息。
- HOG 的空间证明 :标准 HOG 不是统计整张图的梯度直方图,而是将图像划分为若干个重叠的 Block(块) ,Block 内部再划分为 Cell(网格) 。对每个 Cell 提取 9维直方图,然后将所有 Block 的向量首尾拼接成一整条长向量。
- 结论 :如果我们将图像中的两个物体(比如一只狗和一只猫)的位置互换 ,虽然整张图的"全局梯度直方图"可能依然接近,但各个局部 Block 的顺序发生变化,最终拼接出的 HOG 特征向量必定截然不同 。这就证明了 HOG 特征中 "特征出现在哪里" 的定位信息是完全被保留的。
- LBP 的空间证明(LBPH) :纯 LBP 只是给每个像素打了一个标签(模式值)。而在人脸识别和图像检索中应用的 LBPH(LBP 统计直方图) 同样会先将图像划分为 (m \times n) 个局部网格,分别统计每个网格的 LBP 直方图,再级联成最终的长向量。若局部区域的纹理发生空间换位,即使全图总模式数一样,最终的特征向量也会不同。
2. 标准的 HOG 和 LBP 是否具有旋转不变性?
结论:标准的 HOG 和 LBP 本身都不具备旋转不变性。
- HOG 的缺陷 :HOG 统计的是绝对梯度方向(通常将 0°~180° 划分为 9 个固定的 Bin)。一旦图像发生旋转,原本指向 20° Bin 的梯度就会落入 40° 或 0° Bin 中,导致直方图分布发生剧烈变化,特征向量严重失配。
- LBP 的缺陷 :标准的 LBP 是按照固定的相对顺序(比如固定从正上方开始顺时针)排列邻域像素形成一个二进制数。图像旋转后,邻域点的出场顺序发生了变化,导致二进制数完全改变,LBP 编码值失效。
3. 给定一种方法,让 HOG 和 LBP 具有旋转不变性。
① 赋予 HOG 旋转不变性:采用"主方向对齐"
参考 SIFT 描述子的思路,我们可以在提取 HOG 之前先做角度归一化:
- 在局部区域(Block 或 Cell)内,首先统计该区域的梯度方向直方图。
- 找到直方图最高的峰值方向 ,将其作为该区域的主方向。
- 旋转坐标轴 :将该局部区域的所有像素坐标,绕区域中心旋转至主方向对齐(通常旋转到 0°)。
- 在旋转对齐后的坐标系上,重新提取该 Block 的梯度方向直方图。这样无论原图像如何旋转,特征点的局部 HOG 方向特征都会保持相对稳定。
6. 拉普拉斯变换公式,2种常见的拉普拉斯模板,Marr(马尔)算子和拉普拉斯变换联系和实现
一、 拉普拉斯变换公式(离散形式)
在数字图像处理中,拉普拉斯算子是对图像求二阶空间导数 的线性算子。对于图像函数 (f(x, y)),连续域的定义为:
∇2f=∂2f∂x2+∂2f∂y2\nabla^2 f = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2}∇2f=∂x2∂2f+∂y2∂2f
在离散图像中,利用差分近似代替微分,(x) 方向和 (y) 方向的二阶偏导分别近似为:
∂2f∂x2≈f(x+1,y)+f(x−1,y)−2f(x,y)\frac{\partial^2 f}{\partial x^2} \approx f(x+1, y) + f(x-1, y) - 2f(x, y)∂x2∂2f≈f(x+1,y)+f(x−1,y)−2f(x,y)
∂2f∂y2≈f(x,y+1)+f(x,y−1)−2f(x,y)\frac{\partial^2 f}{\partial y^2} \approx f(x, y+1) + f(x, y-1) - 2f(x, y)∂y2∂2f≈f(x,y+1)+f(x,y−1)−2f(x,y)
两者相加即得到离散的拉普拉斯模板系数。(注意:拉普拉斯模板的所有系数之和必须为零,以保证在平坦灰度区域输出值为0)。
二、 2种常见的拉普拉斯模板(掩模)
拉普拉斯算子的卷积核通常为 (3 \times 3) 矩阵。根据是否包含对角邻域像素,有两种最经典的标准模板:
1. 4-邻域拉普拉斯模板(仅含上下左右)
0101−41010 \begin{bmatrix} 0 & 1 & 0 \\ 1 & -4 & 1 \\ 0 & 1 & 0 \end{bmatrix} 0101−41010
2. 8-邻域拉普拉斯模板(包含对角线)
1111−81111 \begin{bmatrix} 1 & 1 & 1 \\ 1 & -8 & 1 \\ 1 & 1 & 1 \end{bmatrix} 1111−81111
三、 Marr算子(属于高斯拉普拉斯,属于LoG)与拉普拉斯变换的联系
联系核心:
Marr算子在本质上就是**"高斯平滑 + 拉普拉斯二阶导"**的结合体。数学上通过卷积的线性性质可以证明:
先高斯平滑再拉普拉斯≡直接用高斯函数的拉普拉斯算子(LoG)卷积原图\text{先高斯平滑再拉普拉斯} \quad \equiv \quad \text{直接用高斯函数的拉普拉斯算子(LoG)卷积原图}先高斯平滑再拉普拉斯≡直接用高斯函数的拉普拉斯算子(LoG)卷积原图
- 推导公式 :设高斯函数为 (G(x,y)),则 LoG 算子的连续解析式为:
∇2G(x,y)=∂2G∂x2+∂2G∂y2=(x2+y2σ4−2σ2)exp(−x2+y22σ2)\nabla^2 G(x,y) = \frac{\partial^2 G}{\partial x^2} + \frac{\partial^2 G}{\partial y^2} = \left( \frac{x^2 + y^2}{\sigma^4} - \frac{2}{\sigma^2} \right) \exp\left(-\frac{x^2 + y^2}{2\sigma^2}\right)∇2G(x,y)=∂x2∂2G+∂y2∂2G=(σ4x2+y2−σ22)exp(−2σ2x2+y2)
为什么引入Marr算子?(作用)
纯拉普拉斯算子是二阶导,对图像中的随机噪声极其敏感 (噪声的高频特性会在求二阶导时被剧烈放大)。Marr算子通过先使用高斯滤波对图像做平滑去噪 ,再计算拉普拉斯算子,极大地提高了边缘检测的抗噪能力和稳定性。它常被用于寻找图像边缘的零交叉点(Zero-crossing)。
四、 Marr算子的实际实现
在计算机图像处理中,Marr算子(LoG)有两种实现方式:
-
实现方式 1:分步实现(实际工程常用)
- 平滑:先用一个标准的高斯卷积核(大小如 (5\times5) 或 (7\times7))与原始图像做卷积,去除高频噪声。
- 求导 :再对上一步的结果应用前面提到的8-邻域拉普拉斯模板(如 (1,1,1; 1,-8,1; 1,1,1))进行卷积。
- 检测边缘 :最终在结果中找到二阶导数过零点的位置,即为目标的精确边缘。
-
实现方式 2:一步卷积实现(理论整合)
- 构造 LoG 核 :先根据高斯平滑参数 (\sigma),直接算出上方的离散 LoG 模板矩阵。一个典型的 (5 \times 5) LoG 掩模系数例如:
00−1000−1−2−10−1−216−2−10−1−2−1000−100 \begin{bmatrix} 0 & 0 & -1 & 0 & 0 \\ 0 & -1 & -2 & -1 & 0 \\ -1 & -2 & 16 & -2 & -1 \\ 0 & -1 & -2 & -1 & 0 \\ 0 & 0 & -1 & 0 & 0 \end{bmatrix} 00−1000−1−2−10−1−216−2−10−1−2−1000−100 - 将此模板直接与原始图像做卷积运算(一步到位完成平滑和微分)。
- 在结果中寻找零交叉点。
- 构造 LoG 核 :先根据高斯平滑参数 (\sigma),直接算出上方的离散 LoG 模板矩阵。一个典型的 (5 \times 5) LoG 掩模系数例如:
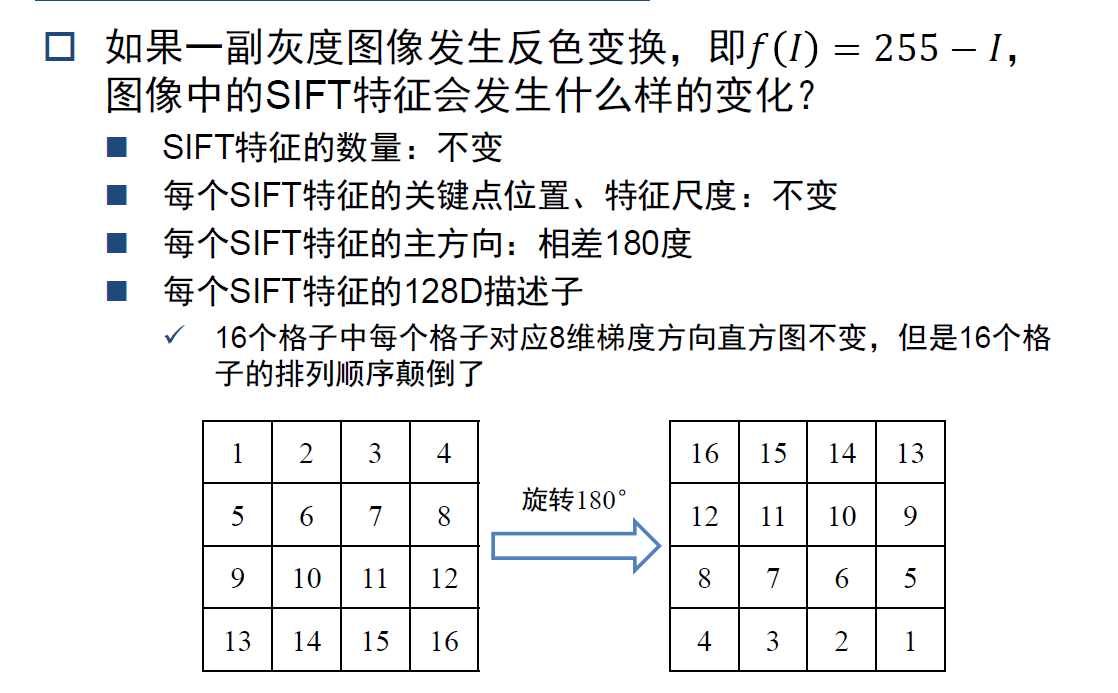
7.灰度图像在反色变换情况下,灰度直方图,LBP,SIFT的四个是否变换,若变,请说出怎么变化?
灰度直方图变,LBP不变,SIFT中特征变换如下图所示:
结合课件内容及考试简答题的规范,整理答案如下:
针对 反色变换((f(I)=255-I)),这几个特征的变化如下:
① 灰度直方图
- 变化。
- 怎么变 :图像所有像素灰度值由 (I) 变为 (255-I),直方图沿灰度轴发生左右镜像翻转(即原图中灰度为 (k) 的像素数量,变成新直方图中灰度为 (255-k) 的像素数量)。
② LBP(局部二值模式)
- 变化 。(纠正之前的回答)
- 怎么变:由于反色后 (I'_p = 255-I_p),(I'_c = 255-I_c),邻域与中心像素的相对大小完全反转((I'_p - I'_c = -(I_p - I_c)))。
- 结论 :原本大于等于中心像素的邻域(标记为 1)会变成小于中心像素(标记为 0),反之亦然。因此,LBP 的 8 位二进制码会变为原码的"按位取反"(若采用等价模式,其编码值也相应发生取反变化)。
③ SIFT 特征
- 变化。
- 怎么变 (结合 PPT 与严谨数学推导):
- 数量、关键点位置、特征尺度 :不变。
- 主方向 :相差 180 度。图像反色会使所有像素的梯度向量反转。
- 128D 描述子 :
- 空间排列(16个格子) :PPT 配图展示的是 16 个格子的排列顺序颠倒 (1~16 变成 16~1)。请注意,PPT 这里的配图其实属于图像"空间旋转 180 度"的情况,而非单纯的强度反色 (单纯反色不会让局部块的空间位置倒过来)。但在考试作答时,建议按照 PPT 给的结论来写,即"16 个格子排列顺序颠倒"。
- 每个格子的 8 维梯度直方图 :由于梯度方向反色后整体旋转 180 度,每个格子内的 8 维直方图也会发生循环移位(对应 8 个方向桶的相邻 4 个桶互换)。
8.梯度算子
结合中科大《数字图像分析》课件第3章"图像处理"中空间域锐化/边缘检测 的考点,常用的梯度算子主要分为一阶微分算子和二阶微分算子两大类。
考场简答题如果直接问"梯度算子包含哪些",标准作答只需分类列出主流算子名称、模板特点和核心特性即可。以下为完整的考试标准答案:
一、 基于一阶微分(梯度)的算子
这类算子通过计算图像的一阶导数来检测亮度变化的剧烈程度(即边缘的峰值)。
-
Roberts 算子
- 模板大小:(2\times2) 交叉差分。
- 特点:计算简单,利用对角线方向相邻像素之差来检测边缘。但对噪声极其敏感,且无法抑制噪声。
- 常见模板 :
100−1\]和\[01−10\]\\begin{bmatrix} 1 \& 0 \\\\ 0 \& -1 \\end{bmatrix} \\quad \\text{和} \\quad \\begin{bmatrix} 0 \& 1 \\\\ -1 \& 0 \\end{bmatrix}\[100−1\]和\[0−110
-
Prewitt 算子
- 模板大小:(3\times3)。
- 特点:在求差分之前先进行了邻域平均(平滑),因此比 Roberts 算子具有一定的抗噪能力。
- 常见模板 :
−1−1−1000111和−101−101−101\begin{bmatrix} -1 & -1 & -1 \\ 0 & 0 & 0 \\ 1 & 1 & 1 \end{bmatrix} \quad \text{和} \quad \begin{bmatrix} -1 & 0 & 1 \\ -1 & 0 & 1 \\ -1 & 0 & 1 \end{bmatrix} −101−101−101 和 −1−1−1000111
-
Sobel 算子
- 模板大小:(3\times3)。
- 特点 :结合了高斯平滑和中心差分。它是一种加权平均,离中心像素越近,权重越大,抗噪能力比 Prewitt 更好。课件明确指出:Sobel算子等价于先在图像水平方向进行低通滤波,然后在垂直方向做中心差分。
- 常见模板 :
−1−2−1000121和−101−202−101\begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix} \quad \text{和} \quad \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix} −101−202−101 和 −1−2−1000121
-
Kirsch 算子
- 模板大小:(3\times3)。
- 特点 :属于方向梯度算子。它由 8 个不同方向(0°~315°,每隔 45°)的模板组成,可以检测各个方向的边缘,通常取 8 个方向响应中的最大值作为边缘强度。
二、 基于二阶微分(拉普拉斯)的算子
这类算子通过计算图像的二阶导数来检测边缘(检测二阶导数过零点)。与一阶算子相比,能精确定位边缘,但对噪声更为敏感。
-
拉普拉斯算子(Laplacian)
- 特点 :图像的二阶空间导数算子,是各向同性 的(旋转不变)。对孤立的点和噪声极敏感,且无法提供边缘的方向信息。
- 常见模板 (4邻域与8邻域):
0101−41010或1111−81111\begin{bmatrix} 0 & 1 & 0 \\ 1 & -4 & 1 \\ 0 & 1 & 0 \end{bmatrix} \quad \text{或} \quad \begin{bmatrix} 1 & 1 & 1 \\ 1 & -8 & 1 \\ 1 & 1 & 1 \end{bmatrix} 0101−41010 或 1111−81111
(注:拉普拉斯模板中心系数为负,所有系数之和必须为0)
-
Marr 算子(高斯拉普拉斯,LoG)
- 特点:它不是纯粹的拉普拉斯,而是先进行高斯平滑(抗噪),再进行拉普拉斯运算。该算子通过寻找**二阶导数的零交叉点(Zero-crossing)**来定位边缘,是目前基于二阶导数的边缘检测中稳定性较高的方法。
9.边缘检测(10)canny算子中非极大值抑制和双阈值检测和连接的作用, susan如何区分边缘点
1. Canny算子中非极大值抑制(NMS)的作用(2分)
梯度细化:沿着梯度方向,将当前像素的梯度幅值与前后两个像素比较。若当前点不是局部极大值,则将其置零。作用:保留梯度变化最剧烈的点,实现单像素宽边缘。
2. 双阈值检测和连接的作用(4分)
- 判定强边缘:幅值 > 高阈值的,直接标记为强边缘(保留)。
- 抑制噪声:幅值 < 低阈值的,直接剔除。
- 边缘连接(弱边缘处理) :介于两阈值之间的标记为弱边缘。仅当其 8 邻域内包含强边缘时,才将其保留并连接成完整边缘。
- 作用:在连接断裂边缘的同时,有效抑制伪边缘。
3. SUSAN如何区分边缘点(4分)
基于局部灰度统计,不依赖梯度。
- 使用圆形模板,将邻域像素与**核(中心像素)**比较灰度值,统计灰度相近的像素数量,得到 USAN 区域面积。
- 判定逻辑 :
- 平坦区:USAN 面积最大。
- 边缘点:USAN 面积约等于模板最大面积的一半(< 50% 设定阈值)。
- 角点:USAN 面积最小。因此通过设置 USAN 面积阈值(通常取最大值的 50%),即可将边缘点区分出来。
10. 视觉表达不变性和区分性(15)不变性和区分性定义,LBP HOG 灰度直方图 的不变性,提高灰度直方图区分性的一种方法,SIFT特征反色后变化
1. 视觉特征的不变性和区分性定义(约4分)
- 不变性(Invariance) :以不变应万变:图像在像素空间发生了亮度变换或几何变换,但是在特征空间没有变化,或变化很小。
局部视觉特征对视觉内容有良好的区分性和表达力
◼ 区分性:可辨别类间差异
◼ 表达力:可包容类内差异
◼ 相似视觉内容的视觉特征向量距离小,不同视觉内容的视觉特征向
量距离大
2. LBP、HOG、灰度直方图的不变性(约6分)
- 灰度直方图 :对平移和旋转具有天然不变性(因为丢失了空间位置信息)。但对光照和缩放敏感。
- LBP :对光照的单调灰度变化完全不变(因为仅比较邻域与中心像素的相对大小,不等号方向不会随线性变换改变)。标准的LBP对旋转敏感,需进行循环移位取最小值的处理才能获得旋转不变性。
- HOG :对光照的线性变化具有不变性(因为特征提取最后会进行 (L_2) 归一化,抵消了整体乘性系数)。HOG对微小平移和小形变具有鲁棒性,但标准的HOG对旋转敏感,需基于局部主方向对齐来获得旋转不变性。
3. 提高灰度直方图区分性的一种方法(约2分)
分块直方图(局部空间直方图)。
- 做法:将图像划分为互不重叠或重叠的多个局部网格(Block/Cell)。分别计算每个网格的灰度直方图,然后将所有网格的直方图按空间顺序首尾拼接形成长向量。
- 原因:传统灰度直方图丢失了空间分布信息,导致区分性很弱。分块直方图将"空间位置"显式编码进特征向量中,极大地提升了特征的区分性。
4. SIFT特征反色后的变化(约3分)
- 特征数量、关键点位置、特征尺度:不变。
- 主方向:相差180°。
- 128D描述子:16个格子中每个格子对应的8维梯度方向直方图内容不变,但16个格子的排列顺序发生了颠倒。
11. 第一问,问(a)(b)是什么算子。(拉普拉斯算子以及中心差分算子)第二问,问(c)(d)是怎么从(b)拓展的(原理); 图(d)为什么比图©的效果好?

第一问:识别图(a)和(b)是什么算子
- 图 (a) 是 4-邻域拉普拉斯算子。所有系数之和为0,用于检测图像灰度突变(边缘)或用于图像锐化。
- 图 (b) 是垂直方向的一阶中心差分算子。它纯粹计算垂直方向(Y方向)的灰度变化率,求的是梯度 (G_y)。
第二问:图(c)和图(d)是怎么从(b)拓展的?(推导原理)
这考察的是**"先平滑、后差分"**的拓展思想。模板(b)是纯粹的微分算子,对噪声极其敏感。图(c)和(d)通过在垂直差分的基础上,增加了水平方向的"平滑滤波",从而提高了算子的抗噪能力。
其原理可以通过**"外积(向量相乘)"**完美解释:
-
模板 (b) 的本质是垂直差分列向量 : Dy=−101D_y = \begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix}Dy= −101
-
图 © 的推导(Prewitt 算子):
- 在水平方向上引入均值(平均)平滑 行向量 HPrewitt=111H_{Prewitt} = \begin{bmatrix} 1 & 1 & 1 \end{bmatrix}HPrewitt=111
- 计算外积:−101×111=−1−1−1000111\begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix} \times \begin{bmatrix} 1 & 1 & 1 \end{bmatrix} = \begin{bmatrix} -1 & -1 & -1 \\ 0 & 0 & 0 \\ 1 & 1 & 1 \end{bmatrix} −101 ×111= −101−101−101
- 原理:这就是图©的算子。Prewitt 算子本质上就是**"中心差分 + 邻域均值平滑"**,以牺牲一点边缘定位精度来换取抗噪能力。
-
图 (d) 的推导(Sobel 算子):
- 在水平方向上引入高斯加权平滑 行向量 HSobel=121H_{Sobel} = \begin{bmatrix} 1 & 2 & 1 \end{bmatrix}HSobel=121(这也是高斯函数的离散一阶近似)
- 计算外积:−101×121=−1−2−1000121\begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix} \times \begin{bmatrix} 1 & 2 & 1 \end{bmatrix} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix} −101 ×121= −101−202−101
- 原理 :这就是图(d)的算子。相比于 Prewitt 的均值平滑,Sobel 的加权平滑让离中心越近的像素权值越大,在抗噪的同时更好保留了边缘的局部特征,因此是实际工程中最常用的梯度算子。
第三问:图(d)为什么比图©的效果好?
虽然图©的Prewitt和图(d)的Sobel都实现了"差分+平滑"的抗噪目的,但图(d)的 Sobel 算子效果更好 ,核心原因在于平滑权重的分配:
- Prewitt 算子(图c)的局限 :采用
[1, 1, 1]均值平滑,对水平邻域内的三个像素一视同仁 ,权重完全相同。这虽然能抑制噪声,但也会导致图像边缘的等比例模糊,降低了边缘定位的精确度。 - Sobel 算子(图d)的优势 :采用
[1, 2, 1]的高斯加权 平滑。这组系数本质上是高斯滤波的一维离散近似 。它的特点是离中心像素越近,权重越大(为2);离中心越远,权重越小(为1)。 - 结论 :图(d)的Sobel算子既有效地抑制了邻域内的高频噪声,又因为强调了中心像素的权重,使得边缘的锐度得到了更好的保持,定位精度更高。因此,Sobel 是实际数字图像处理中最常用的梯度算子。
12. CANNY 与 SUSAN算子,第一问,CANNY和SUSAN算子是如何检测边缘点的 第二问,SUSAN算子检测边缘的步骤
第一问:Canny 和 SUSAN 算子是如何检测边缘点的?
1. Canny 算子(基于一阶微分的优化组合)
Canny 是多阶段组合的边缘检测算子,它通过以下机制检测边缘点:
- 高斯平滑:首先对图像进行高斯滤波去噪。
- 梯度计算:利用一阶偏导(通常用 Sobel 算子)计算每个像素的梯度幅值和方向。
- 非极大值抑制(NMS) :在梯度方向上进行局部极大值判断,剔除非边缘像素,实现边缘细化(得到单像素宽边缘)。
- 双阈值与滞后连接 :设定高阈值 (T_H) 和低阈值 (T_L)。凡是梯度大于 (T_H) 的必定为强边缘;介于两者之间的弱边缘,只有当它与强边缘在空间上连接时才被保留。此机制极大消除了噪声引起的假边缘,并能闭合断点。
2. SUSAN 算子(基于局部灰度相似性的非微分模板)
SUSAN 算子完全不依赖导数 ,而是通过圆形模板的统计比较来检测边缘:
- 在图像上放置一个圆形模板(如含 37 个像素)。
- 将模板内所有像素的灰度值与**中心像素(核)**进行比较。灰度差值小于阈值 (t) 的像素,称为 USAN(核值相似区) 像素。
- 当中心点处于平坦区域 时,USAN 面积最大;当中心点处于边缘 时,USAN 面积大约为最大值的一半;当处于角点时,USAN 面积最小。
- 检测判定 :通过计算 USAN 区域的面积大小,并与预设的几何阈值 (g)(通常取最大 USAN 面积的一半)比较,若 USAN 面积小于 (g),则该中心像素被认定为边缘点(或角点)。
第二问:SUSAN 算子检测边缘的详细步骤
结合课件和 SUSAN 算子的经典算法流程,步骤可以严格总结为以下 5 步:
-
初始化圆形掩膜
将半径为 (R) 的圆形模板(在经典 SUSAN 算法中,通常使用包含 37 个像素的近似圆)放置在图像上,遍历整幅图像的每一个像素。
-
相似度比较与 USAN 计算
以当前像素点(核,记为 (P_0))为中心,逐一比较圆形模板内其余像素点 (P_i) 的灰度值与核的灰度值,判定它们是否属于同一区域(USAN)。
比较函数通常定义为:
C(P0,Pi)={1,if ∣I(Pi)−I(P0)∣≤t0,if ∣I(Pi)−I(P0)∣>tC(P_0, P_i) = \begin{cases} 1, & \text{if } |I(P_i) - I(P_0)| \le t \\ 0, & \text{if } |I(P_i) - I(P_0)| > t \end{cases}C(P0,Pi)={1,0,if ∣I(Pi)−I(P0)∣≤tif ∣I(Pi)−I(P0)∣>t
(其中 (t) 为设定的灰度相似性阈值,决定对噪声的鲁棒程度)。
随后,统计模板中满足条件的像素个数,得到当前核的 USAN 面积 (n(x,y))。
-
初始边缘判定
将计算出的 USAN 面积 (n(x,y)) 与几何阈值 (g)(通常定义为最大 USAN 面积的一半,即圆形模板包含总像素数的一半)进行比较:
R(x,y)={g−n(x,y),n(x,y)<g0,otherwiseR(x,y) = \begin{cases} g - n(x,y), & n(x,y) < g \\ 0, & \text{otherwise} \end{cases}R(x,y)={g−n(x,y),0,n(x,y)<gotherwise
如果 (n(x,y) < g),则该像素被认为是初步的边缘候选点;如果 (n(x,y)) 接近于模板像素总数,说明中心点位于平坦区域,响应为 0。
-
非极大值抑制(细化边缘)
由于 SUSAN 算子给出的初始边缘往往具有一定的宽度(对应同一边缘会连续触发多个相邻像素点满足条件),因此需要执行非极大值抑制。保留 USAN 面积局部最小对应的中心点,剔除邻域内响应较弱的点,最终获得单像素宽的边缘。
-
输出二值边缘图像
经过上述步骤和细化处理后,得到最终的边缘检测结果(二值图像,边缘点标记为 1,其余为 0)。
💡 考场速记与对比总结(必背):
- Canny :求导求梯度,依赖 NMS + 双阈值,适合高精度的标准边缘提取。
- SUSAN :不求导,靠局部灰度统计(USAN面积) ,对噪声更鲁棒,同时具备角点和边缘检测能力。SUSAN 的 5 步法经常被直接考察为 6~8 分的简答题,务必熟记。
13. SIFT与几何校验
第一问,SIFT的四个不变性解释。(平移,尺度,旋转,亮度)
第二问,SIFT反色之后的变化(主方向变化与128-D描述子的变化)
第三问,基于空间编码的几何校验的过程原理步骤。
补充:对于视觉特征不变性的理解
对"视觉特征不变性"的理解
视觉特征的不变性(invariance)
◼
以不变应万变:图像在像素空间发生了亮度变换或几何变换,但是在特征空间没有变化,或变化很小
◼
常见的不变性
✓
亮度不变性,平移不变性,旋转不变性,尺度(缩放)不变性
第一问:SIFT特征的四个不变性解释
1. 平移不变性
SIFT 在尺度空间(DoG 金字塔)中检测局部极值点。由于边缘像素即使发生微小平移,其邻域内的局部极值结构依然会保留,因此关键点的定位本身对平移具有天然鲁棒性。
2. 尺度不变性
SIFT 构建了高斯差分(DoG)金字塔 ,通过在不同尺度(由 (\sigma) 决定)下检测极值点,得到关键点的特征尺度 。在生成 128 维描述子前,会将关键点邻域的像素区域统一缩放至固定窗口大小,从而消除了目标尺寸变化带来的影响。
3. 旋转不变性
在每个关键点的局部区域内,计算像素的梯度幅值和方向,构建 36 个 Bin 的梯度方向直方图,将直方图的峰值方向 定义为该关键点的主方向 。在后续生成 128 维描述子时,会将邻域图像块根据主方向进行旋转对齐,从而实现旋转不变性。
4. 亮度不变性(线性光照)
SIFT 是基于**梯度(一阶差分)**进行描述的。因为图像的常数项亮度偏移在求导时会变为 0,梯度幅值和方向不受线性平移的影响。此外,生成的 128 维向量会进行 L2 范数归一化,从而有效消除线性缩放(等比例放大/缩小图像亮度)带来的影响。
第二问:SIFT 反色之后的变化
1. 主方向的变化
图像发生反色变换((f(I) = 255 - I))后,所有像素的梯度向量会发生反向,即 (\nabla f_{\text{反色}} = -\nabla f_{\text{原图}})。因此,每个 SIFT 特征的主方向会发生 180 度的翻转(与原主方向相差 180°)。
2. 128维描述子的变化
- 16个格子的空间布局(不变) :反色属于光度(灰度)变换,不改变图像的空间几何结构,因此描述子中 16 个格子((4 \times 4))的空间排列顺序不变。
- 每个格子的8维梯度直方图(发生循环移位) :由于所有梯度方向整体翻转了 180 度,对应到每个格子内的 8 维梯度直方图(通常 0-360 度,每 45 度为一个 bin)中,前 4 个 bin 的值会与后 4 个 bin 的值发生位置互换(循环移位)。
第三问:基于空间编码(Spatial Coding)的几何校验原理与步骤
1. 核心原理(动机)
纯词袋模型(BoW)匹配丢失了特征点的空间位置信息,容易产生大量空间布局错误的假匹配。空间编码通过提取和对比匹配特征点对之间的相对空间位置关系,剔除几何不一致的误匹配点对。
2. 实现步骤
- Step 1:构建相对空间编码矩阵(Xmap, Ymap)
假设两幅图中得到了 (N) 对匹配点。对每一幅图,分别构建大小为 (N \times N) 的二进制空间矩阵。对于任意两个匹配特征点 (i, j):- Xmap:记录水平相对关系。若 (x_j > x_i)(点 (j) 在 (i) 右边),记为 1;否则记为 0。
- Ymap:记录垂直相对关系。若 (y_j > y_i)(点 (j) 在 (i) 下方),记为 1;否则记为 0。
- Step 2:多角度编码(可选,应对旋转)
为了适应图像间的旋转,可将空间坐标系旋转多个不同角度(如 (0, \pi/4, \dots)),生成多组 Xmap 和 Ymap 候选。 - Step 3:异或(XOR)对比与误差度量
将查询图的空间矩阵 (G_q) 与待匹配图的空间矩阵 (G_m) 进行异或(XOR)运算 :V=Gq⊕GmV = G_q \oplus G_mV=Gq⊕Gm。- 如果某对点 ((i,j)) 的空间布局一致,异或结果为 0。
- 如果空间布局矛盾,异或结果为 1。
- Step 4:迭代剔除不一致匹配(寻找并去除 Outlier)
计算每个匹配点 (i) 对应的行向量中所有异或值的累加和(误差得分)。误差得分越高,说明该匹配点与其他点的相对空间关系冲突越多。 - Step 5:收敛与输出
将误差得分最高的匹配点对视为错误匹配(Outlier) ,将其剔除。剔除该点后,更新 (N),重复 Step 1 ~ Step 4,直到剩下的所有点对的异或结果全部为 0(即空间布局完全一致),剩余的匹配点对即为通过几何验证的正确匹配对。
💡 考场对比补充:
- RANSAC:基于随机采样拟合仿射/单应矩阵,模型准确但计算复杂度高((O(N^3)))。
- 空间编码 :基于点对的相对空间位置关系(上下左右),利用 XOR(异或)位运算 进行校验,速度快,特别适合大规模图像检索的快速几何过滤。
14. 给了两个模板,求相应的连续算子是什么(其中一个是拉普拉斯算子)(考点:离散空域滤波模板与线性算子对应关系);sobel算子拓展原理,以及拓展后的优势
结合中科大《数字图像分析》的空间域滤波考点,这道题考察的是离散差分模板的数学本质 以及可分离滤波器的设计原理。以下是标准的考试答案,可直接用于背诵作答。
第一问:离散空域滤波模板与连续线性算子的对应关系
核心答案 :离散空域滤波模板,本质上就是连续微分算子(或平滑算子)在离散网格上的"差分近似"。
-
对应关系的本质 :
连续图像处理中的数学算子(如一阶微分、二阶微分、高斯平滑)通过泰勒级数展开,可用离散的差分方程来逼近。
- 一阶微分 ∂f∂x\frac{\partial f}{\partial x}∂x∂f 近似为差分 f(x+1)−f(x)f(x+1) - f(x)f(x+1)−f(x)。
- 二阶微分 ∂2f∂x2\frac{\partial^2 f}{\partial x^2}∂x2∂2f 近似为 f(x+1)+f(x−1)−2f(x)f(x+1) + f(x-1) - 2f(x)f(x+1)+f(x−1)−2f(x)。
-
典型例题(拉普拉斯算子) :
连续域的 拉普拉斯算子(Laplacian) 定义为 ∇2f=∂2f∂x2+∂2f∂y2\nabla^2 f = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2}∇2f=∂x2∂2f+∂y2∂2f。
利用二阶差分的离散近似(累加水平方向和垂直方向的二阶差分),即可得到考试给出的 4-邻域拉普拉斯模板:
0−10−14−10−10\begin{bmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \end{bmatrix} 0−10−14−10−10
(注:其标准特征是模板系数之和为0,代表它在平坦区域(一阶导数为0,二阶导数也为0)的响应为0。)
第二问:Sobel 算子的拓展原理(推导过程)
Sobel 算子的拓展,是基于**"差分 + 平滑"的可分离卷积核思想。它由 一维中心差分核与 一维高斯加权核的外积**(Outer Product)所生成。
标准推导步骤(以垂直方向 (G_y) 模板为例):
- 取基础差分向量 :提取纯粹的垂直中心差分算子作为列向量
Dy=−101D_y = \begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix}Dy= −101 。 - 取平滑加权向量 :引入水平方向的一维高斯加权平滑行向量
H=121H = \begin{bmatrix} 1 & 2 & 1 \end{bmatrix}H=121(这是 1 维离散高斯分布的近似)。 - 求外积 :将列向量与行向量做矩阵外积运算:
Dy×H=−101⋅121=−1−2−1000121D_y \times H = \begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix} \cdot \begin{bmatrix} 1 & 2 & 1 \end{bmatrix} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}Dy×H= −101 ⋅121= −101−202−101
(得到的结果正是考试题目中通常给出的 Sobel 算子模板)。
(横向水平梯度 (G_x) 模板可通过 (D_x = -1, 0, 1) 与垂直平滑向量 (1, 2, 1^T) 的外积得到。)
第三问:拓展后的优势(为什么比 Prewitt 效果好)
Sobel 算子在拓展时,选择了 [1, 2, 1] 的权重,而非 Prewitt 算子采用的 [1, 1, 1] 均值平滑。其核心优势在于:
- 抗噪与保边的平衡更好 :
[1, 2, 1]是一个高斯平滑核的离散近似 。它遵循"离中心越近的像素,对中心影响越大"的原则。这既能有效抑制局部高频噪声,又能将更多的计算权重给到当前关注像素的边缘,不会像 Prewitt 那样等比例模糊边缘。 - 边缘定位精度更高:由于赋予了中心位置更大的权重,Sobel 算子在计算梯度时对边缘位置的敏感度更高,定位更精准。
- 工业界更受青睐 :因为其兼具一定的抗噪能力 和较好的边缘保持能力,Sobel 算子是目前图像处理中最常用的梯度近似算子。
💡 考场防混淆提示:
- 如果考题问"拓展后的优势",标准踩分点就是**"高斯加权平滑比均值平滑能更好地保边"**。
- Prewitt 是**"均值平滑(
[1,1,1])",Sobel 是 "高斯加权平滑([1,2,1])"**,只要记住这两个对应的平滑核就能答对。
15. sift描述子的维数如何定义及各维数的含义,shape context描述子的维数如何定义及各维数的含义
以下是针对 SIFT 和 Shape Context 描述子的考点级精简解答:
- SIFT (尺度不变特征变换) 描述子
-
维数定义 :标准 SIFT 描述子为 128 维。
-
计算划分 :以关键点为中心,将其周围的局部邻域划分为 4×44 \times 44×4 的网格(共 16 个子区域)。在每个子区域内,统计 8 个方向的梯度方向直方图。
-
计算公式 :16 (子区域)×8 (方向)=128 维16 \text{ (子区域)} \times 8 \text{ (方向)} = 128 \text{ 维}16 (子区域)×8 (方向)=128 维。
-
各维数的含义 :128 维中的每一个维度,代表在关键点邻域的某一个特定空间子块(1/16)内,属于某一个特定量化方向(1/8)的梯度幅值累加和(该累加和已叠加高斯权重并经过光照归一化)。本质上,它量化了局部区域内纹理和边缘的方向分布。
- Shape Context (形状上下文) 描述子
-
维数定义 :标准 Shape Context 描述子通常为 60 维(该维数由人为设定的极坐标网格参数决定)。
-
计算划分 :以形状边界上的某一参考点为圆心,建立对数极坐标系。通常将对数距离(径向)划分为 5 个区间,将角度(角向)划分为 12 个区间,构成 5×125 \times 125×12 的极坐标网格。
-
计算公式 :5 (对数距离区间)×12 (角度区间)=60 维5 \text{ (对数距离区间)} \times 12 \text{ (角度区间)} = 60 \text{ 维}5 (对数距离区间)×12 (角度区间)=60 维。
-
各维数的含义 :60 维中的每一个维度,代表该形状的其余所有边界点中,落入参考点特定相对距离区间(1/5)和特定相对角度区间(1/12)内的点的数量(频数)。本质上,它是一个相对空间位置的二维直方图,描述了整个形状相对于该局部参考点的全局轮廓分布特征。
16. sift描述子如何实现平移,旋转不变性,尺度不变性,亮度不变性;如何进行坐标变换实现平移、旋转、尺度不变性
第一问:SIFT 特征的四个不变性分别是如何实现的?
-
平移不变性
SIFT 在高斯差分(DoG)金字塔 中检测局部极值点。由于图像发生微小平移时,其周围的局部极值结构依然存在,因此关键点的定位本身对平移天然具有鲁棒性。此外,在生成描述子时采用相对坐标计算,也消除了绝对位置的影响。
-
旋转不变性
在每个关键点的局部邻域内,计算所有像素的梯度幅值和方向,构建 36 个 Bin 的梯度方向直方图,将直方图的峰值方向 定义为该关键点的主方向 。在后续生成 128 维描述子时,将邻域图像块根据主方向进行旋转对齐。
-
尺度不变性
SIFT 构建多尺度高斯金字塔 ,在不同尺度(由 (\sigma) 决定)的图像下检测极值点,得到关键点的特征尺度 (\sigma) 。在生成描述子前,会将关键点邻域的像素区域统一缩放至固定窗口尺寸(如 (16 \times 16) 网格),从而消除了目标尺寸变化带来的影响。
-
亮度(光照)不变性
- 针对线性光照平移:亮度增加/减少一个常数项 (b)(即 (I' = I + b)),在计算一阶导数(梯度)时,常数项被微分运算抵消。
- 针对线性光照缩放 :亮度等比例放大 (a) 倍(即 (I' = aI)),所有梯度幅值也会等比例放大 (a) 倍。但在生成 128 维描述子后,会执行 (L_2) 范数归一化,该缩放系数 (a) 会在归一化步骤中被完美约去。
第二问:如何通过坐标变换实现平移、旋转、尺度不变性?
在 SIFT 实际的工程代码实现中,是在描述子生成阶段 ,通过一套严密的局部图像块坐标变换流程来实现上述三种几何不变性的。
整个坐标变换步骤流程如下(设特征点绝对坐标为 ((x_c, y_c)),特征尺度为 (\sigma),主方向为 (\theta)):
1. 平移不变性的坐标变换(局部居中)
将原图中以该特征点为中心截取的局部图像块内的每一个像素点绝对坐标 ((x, y)),转换为相对于特征点中心 的局部坐标:
Xlocal=x−xc X_{\text{local}} = x - x_c Xlocal=x−xc
Ylocal=y−yc Y_{\text{local}} = y - y_c Ylocal=y−yc
物理意义:无论该特征点在图像左上角还是右下角,变换后它都作为局部坐标的原点 ((0,0)) 来处理。
2. 旋转不变性的坐标变换(主方向对齐)
根据步骤1算出的局部坐标,利用二维旋转变换矩阵 ,将局部图像块绕原点反向旋转角度 (-\theta),使其沿着主方向对齐。
(注:反向旋转 (-\theta),等价于将特征点的主方向 (\theta) 校正为水平 0 度方向。)
X′=Xlocal⋅cos(−θ)−Ylocal⋅sin(−θ) X' = X_{\text{local}} \cdot \cos(-\theta) - Y_{\text{local}} \cdot \sin(-\theta) X′=Xlocal⋅cos(−θ)−Ylocal⋅sin(−θ)
Y′=Xlocal⋅sin(−θ)+Ylocal⋅cos(−θ) Y' = X_{\text{local}} \cdot \sin(-\theta) + Y_{\text{local}} \cdot \cos(-\theta) Y′=Xlocal⋅sin(−θ)+Ylocal⋅cos(−θ)
物理意义:无论原图像如何旋转,经过此步变换后,局部图像块的梯度方向分布相对于新坐标系来说都是固定的。
3. 尺度不变性的坐标变换(归一化缩放)
将上一步旋转对齐后的坐标 ((X', Y')),统一除以该特征点所处的特征尺度 (\sigma):
Xfinal=X′σ X_{\text{final}} = \frac{X'}{\sigma} Xfinal=σX′
Yfinal=Y′σ Y_{\text{final}} = \frac{Y'}{\sigma} Yfinal=σY′
实际工程操作 :在底层代码中,并不是只做除法,而是以特征点为中心,框出边长为 (16\sigma) 的局部图像区域,然后利用双线性插值(Bilinear Interpolation),将其重采样(缩放)为一个固定的 (16 \times 16) 像素大小的标准网格 。
物理意义 :无论目标在图像中距离远近(对应的特征尺度 (\sigma) 不同),经过缩放插值后,最终送给描述子提取的特征图大小绝对一致,从而实现尺度不变。
💡 考场必备总结(区分于亮度):
平移、旋转、尺度 这三种几何不变性的实现,完全依赖于局部坐标变换 + 双线性插值重采样 。
而亮度不变性****不依赖任何坐标变换 ,它是基于梯度的数学性质(微分抵消常数,(L_2) 归一化抵消系数)来实现的。这一点在标准答案中务必区分开。
第六章 图像分割
传统分割方法
一、 阈值分割 (Thresholding)
1. 基本原理
基于图像的灰度直方图 ,选定一个或多个灰度阈值,将图像像素划分为目标(1)和背景(0)两类。它假设图像由具有单峰测度分布的目标和背景组成。
2. 核心公式(Otsu 大津法)
Otsu 法通过最大化类间方差(或最小化类内方差)自动选择最优阈值。给定直方图 (P(i)),选择阈值 (t) 将像素分为两类:
- 类概率 : q1(t)=∑i=1tP(i),q2(t)=∑i=t+1TP(i)q_1(t) = \sum_{i=1}^{t} P(i), q_2(t) = \sum_{i=t+1}^{T} P(i)q1(t)=∑i=1tP(i),q2(t)=∑i=t+1TP(i)
- 类均值 : μ1(t)=∑i=1tiP(i)q1(t),μ2(t)=∑i=t+1TiP(i)q2(t)\mu_1(t) = \sum_{i=1}^{t} \frac{i P(i)}{q_1(t)}, \mu_2(t) = \sum_{i=t+1}^{T} \frac{i P(i)}{q_2(t)}μ1(t)=∑i=1tq1(t)iP(i),μ2(t)=∑i=t+1Tq2(t)iP(i)
- 最优阈值 :穷举所有 (t),使得 加权类内方差 σw2(t)=q1(t)σ12(t)+q2(t)σ22(t)\sigma_w^2(t) = q_1(t)\sigma_1^2(t) + q_2(t)\sigma_2^2(t)σw2(t)=q1(t)σ12(t)+q2(t)σ22(t) 最小(或类间方差最大)。
3. 优缺点
- 优点:计算简单,速度极快,Otsu 法能自动确定阈值。
- 缺点 :对光照不均匀极敏感 ,全局阈值难以兼顾图像各处;完全忽略像素空间位置关系 。改进措施:采用依赖坐标的阈值选取(将图像分块,对每个子图像计算局部阈值,再插值得到阈值曲面)。
二、 区域生长法 (Region Growing)
1. 核心思想
将具有相似性质的像素集合 起来构成区域,本质是一种自底向上的合并策略。
2. 执行步骤
- 选择种子像素:基于聚类中心交互选取种子点。
- 确定生长准则:定义相邻像素被包含进来的规则(如"与种子像素的灰度差小于阈值 (T)")。
- 制定停止规则:根据图像边缘或区域大小确定生长何时终止。
3. 优缺点
- 优点 :能很好地保证区域的连通性。
- 缺点 :对种子点的选择非常敏感 ;对噪声敏感,容易导致过分割或欠分割。
三、 分裂合并法 (Split and Merge)
1. 核心思想
利用 四叉树(Quad-tree) 结构进行自顶向下 分裂和自底向上合并。
2. 执行步骤(课件第19-21页)
- 初始化 :将整幅图像 (R) 视为一个整体,设定一个均匀性测度逻辑谓词 (P)。
- 分裂 :如果当前区域 (R_i) 的均匀性测度 (P(R_i) = \text{FALSE})(即内部差异过大),则将其分裂成四个相等的正方形子区域。递归进行,直到所有子区域均匀性测度为真。
- 合并:对相邻的两个区域 (R_i) 和 (R_j),如果它们的并集满足均匀性测度 (P(R_i \cup R_j) = \text{TRUE}),则合并它们。
- 结束:当无法再进行分裂或合并时,算法终止。
3. 优缺点
- 优点:能同时处理区域内部差异和区域间相似性问题。
- 缺点 :分裂可能产生不自然的方块状边界;均匀性测度的定义(如基于方差)对噪声敏感。
四、 分水岭分割算法 (Watershed)
1. 基本思想
将图像梯度图 视为3D地形。图像梯度幅值大(边缘)对应"山脊",梯度幅值小(区域内部)对应"盆地/谷底"。
2. 执行步骤(课件第26-29页)
- 计算梯度图:对原图求梯度得到 (g(x,y))。
- 寻找极小值:找到梯度图中的局部极小值点 (M_1, M_2, \dots),它们是注水的"种子"。
- 模拟注水:设定阈值 (n) 逐渐升高(模拟水面上升)。每个极小值 (M_i) 对应的积水盆地 (C_n(M_i)) 开始扩张。
- 构筑水坝:当来自不同极小值的水域即将在阈值 (n) 处相遇时,在相遇处构筑"分水岭(水坝)",防止水体合并。
- 终止 :当阈值 (n) 升到最大值,所有极小值区域扩张完毕,分水岭线即为图像的边界。
3. 核心缺陷与改进
- 缺陷 :过分割(Over-segmentation)。由于梯度图存在大量局部极小值噪声,会导致产生无数碎片化区域(课件第31页)。
- 改进 :标记控制分割(Marker-controlled watershed) 。预先在图像中定义内部标记 (对应目标)和外部标记(对应背景),强制修改梯度图,仅从这些标记点开始注水,从而极大消除过分割。
五、 聚类分割算法 (Clustering Segmentation)
1. 基本思想
将图像的每个像素视作特征空间(灰度、颜色、坐标等)中的一个样本点 ,利用K-means 聚类算法将样本点划分到 (K) 个簇中,实现像素分组。
2. 核心数学形式化
给定 (N) 个样本(像素),目标是将它们划分为 (K) 个簇,最小化类内平方误差和 :
J=∑n=1N∑k=1Krnk∥xn−μk∥2J = \sum_{n=1}^{N} \sum_{k=1}^{K} r_{nk} \|x_n - \mu_k\|^2J=∑n=1N∑k=1Krnk∥xn−μk∥2
其中 (r_{nk}) 为指示变量(若样本 (n) 属于簇 (k) 则为1,否则为0),(\mu_k) 为簇 (k) 的中心。
3. 优缺点
- 优点:算法简单,收敛快。
- 缺点 :
- 需要预先指定 (K) 值(分割的类别数)。
- 对初始聚类中心的选择敏感,容易陷入局部最优。
- 仅用颜色特征 会忽略像素的位置信息,导致分割出的区域在空间上不连续。实际应用中会将空间坐标 + 颜色值一起作为特征向量进行聚类。
#💡 考试快速对比总结表
| 分割方法 | 核心策略 | 适用场景与特点 |
|---|---|---|
| 阈值分割 | 基于直方图,像素级分类 | 速度极快,依赖全局统计,光照不均时需分块。 |
| 区域生长 | 基于种子,像素向邻域扩张 | 保证连通性,依赖种子点选择,对噪声敏感。 |
| 分裂合并 | 基于四叉树,递归拆分与合并 | 能捕捉全局结构,但分块边界呈方块状,不自然。 |
| 分水岭 | 基于拓扑,模拟梯度图注水 | 能生成闭合边界,但易过分割 ,需结合标记控制。 |
| 聚类分割 | 基于高维特征空间,K-means | 结合 空间+颜色 特征效果好,但需预设 (K) 和初始中心。 |
水平集分割
一、 基本思想与优势
1. 基本思想
水平集(Level Set)方法的核心思想是**"升维"。它不直接追踪二维平面上的演化曲线 (C(p,t)),而是将这条曲线"嵌入"到一个随时间 (t) 变化的二维标量函数 (\phi(x,y,t)) 中,使得动态曲线始终是该函数的"零水平集"**(即满足 (\phi=0) 的位置)。
- 曲线内部:(\phi > 0)。
- 曲线外部:(\phi < 0)。
2. 核心优势
- 天然支持拓扑变化 :与参数化主动轮廓(Snake)不同,水平集通过更新整个二维矩阵 (\phi) 来间接更新曲线。当曲线需要**分裂(1变2)或合并(2变1)**时,在矩阵 (\phi) 层面仅仅是正负区域的合并或断裂,无需任何额外的算法逻辑来处理拓扑结构,计算机自动适应。
- 便于数值计算:(\phi(x,y)) 定义在固定网格上,可以方便地使用标准的偏微分方程(PDE)数值解法(如有限差分法)。
- 易于融合图像信息:速度函数 (F) 可以自然地包含图像的梯度信息、区域统计信息和形状先验信息。
二、 从曲线演化到水平集演化的推导(标准推导)
1. 已知曲线演化方程
设动态曲线为 (C(p,t)),其演化速度取决于法向量 (\mathbf{N}) 和速度函数 (F):
∂C∂t=F⋅N\frac{\partial C}{\partial t} = F \cdot \mathbf{N}∂t∂C=F⋅N
2. 嵌入到水平集函数
将曲线 (C) 嵌入到水平集函数 (\phi(x,y,t)) 中,使得曲线上的点始终满足恒等式:
ϕ(C(p,t),t)=0\phi(C(p,t), t) = 0ϕ(C(p,t),t)=0
3. 链式法则求全微分
对等式两边同时对时间 (t) 求偏导(应用全微分公式):
∂ϕ∂t+∇ϕ⋅∂C∂t=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot \frac{\partial C}{\partial t} = 0∂t∂ϕ+∇ϕ⋅∂t∂C=0
4. 代入曲线演化方程
将 ∂C∂t=F⋅N\frac{\partial C}{\partial t} = F \cdot \mathbf{N}∂t∂C=F⋅N 代入上式:
∂ϕ∂t+∇ϕ⋅(FN)=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot (F \mathbf{N}) = 0∂t∂ϕ+∇ϕ⋅(FN)=0
5. 引入法向量与梯度的几何关系
在水平集理论中,零水平集的单位法向量 (\mathbf{N}) 与 (\phi) 的梯度方向共线。标准定义为:
N=−∇ϕ∣∇ϕ∣\mathbf{N} = -\frac{\nabla \phi}{|\nabla \phi|}N=−∣∇ϕ∣∇ϕ
(注:课件推导有时会取负号,代表指向内侧/外侧的区别,代入后的最终结果是一致的。)
6. 向量运算化简
将 (\mathbf{N}) 代入等式:
∂ϕ∂t−∇ϕ⋅(F∇ϕ∣∇ϕ∣)=0\frac{\partial \phi}{\partial t} - \nabla \phi \cdot \left( F \frac{\nabla \phi}{|\nabla \phi|} \right) = 0∂t∂ϕ−∇ϕ⋅(F∣∇ϕ∣∇ϕ)=0
利用 ∇ϕ⋅∇ϕ=∣∇ϕ∣2\nabla \phi \cdot \nabla \phi = |\nabla \phi|^2∇ϕ⋅∇ϕ=∣∇ϕ∣2 进行化简:
∂ϕ∂t−F∣∇ϕ∣2∣∇ϕ∣=0\frac{\partial \phi}{\partial t} - F \frac{|\nabla \phi|^2}{|\nabla \phi|} = 0∂t∂ϕ−F∣∇ϕ∣∣∇ϕ∣2=0
7. 得证
移项得到最终的水平集演化方程:
∂ϕ∂t=F∣∇ϕ∣\boxed{\frac{\partial \phi}{\partial t} = F |\nabla \phi|}∂t∂ϕ=F∣∇ϕ∣
三、 利用变分法和梯度下降法推导演化方程
变分法的核心思想是:寻找一个函数 (\phi(x,y)),使得能量泛函 (E(\phi)) 达到极小值。 对应的数学工具类似于普通函数求极值时的"导数为0",但在泛函中,使用的是Euler-Lagrange 方程(变分导数)。
我们以课件第69页简化版的标准能量泛函 (E(\phi)) 为例进行推导(仅保留核心的正则化项,方便展示微积分过程)。
1. 定义能量泛函 (E(\phi))
假设我们希望水平集函数 (\phi) 始终保持为符号距离函数 (即 (|\nabla \phi| = 1)),可以定义一个惩罚能量:
E(ϕ)=∫Ω12(∣∇ϕ∣2−2∣∇ϕ∣+1)dxdyE(\phi) = \int_{\Omega} \frac{1}{2} \left( |\nabla \phi|^2 - 2|\nabla \phi| + 1 \right) dxdyE(ϕ)=∫Ω21(∣∇ϕ∣2−2∣∇ϕ∣+1)dxdy
(注:课件第70页以此公式为案例推导。当 (E(\phi)) 最小时,(|\nabla \phi| \to 1),即满足符号距离函数的要求。)
2. 引入微小扰动 (\delta h)(变分变量)
为了寻找使 (E(\phi)) 极小化的 (\phi),我们给 (\phi) 施加一个极小的扰动函数 (h(x,y)),即 (\phi + \delta h)(其中 (\delta) 是一个极小的标量,且扰动函数 (h) 在图像边界处满足 (h|_{\partial \Omega} = 0))。我们计算带扰动后的能量:
E(ϕ+δh)=∫Ω12(∣∇(ϕ+δh)∣2−2∣∇(ϕ+δh)∣+1)dxdyE(\phi + \delta h) = \int_{\Omega} \frac{1}{2} \left( |\nabla (\phi + \delta h)|^2 - 2|\nabla (\phi + \delta h)| + 1 \right) dxdyE(ϕ+δh)=∫Ω21(∣∇(ϕ+δh)∣2−2∣∇(ϕ+δh)∣+1)dxdy
3. 对 (\delta) 求导并令 (\delta \to 0)
将上述式子展开,并对微小变量 (\delta) 求偏导 ,然后再令 (\delta \to 0)。
(这一过程涉及展开平方项、利用链式法则求梯度等操作,课件第71-73页有完整微积分细节,此处省略冗长展开,直接给出化简后的核心项):
∂E(ϕ+δh)∂δ∣δ→0=∫Ω(∇h⋅∇ϕ−∇h⋅∇ϕ(ϕx2+ϕy2))dxdy\left. \frac{\partial E(\phi + \delta h)}{\partial \delta} \right|{\delta \to 0} = \int{\Omega} \left( \nabla h \cdot \nabla \phi - \frac{\nabla h \cdot \nabla \phi}{\sqrt{(\phi_x^2 + \phi_y^2)}} \right) dxdy∂δ∂E(ϕ+δh) δ→0=∫Ω(∇h⋅∇ϕ−(ϕx2+ϕy2) ∇h⋅∇ϕ)dxdy
4. 分部积分与格林公式(消除 (\nabla h))
这一步是变分法的核心降维操作 。利用格林公式(分部积分) ,将导数算子从 (h) 身上转移给 (\phi)。
∫Ω∇h⋅∇ϕ dxdy=∮∂Ωh(ϕxdy−ϕydx)−∫ΩhΔϕ dxdy\int_{\Omega} \nabla h \cdot \nabla \phi \, dxdy = \oint_{\partial \Omega} h (\phi_x dy - \phi_y dx) - \int_{\Omega} h \Delta \phi \, dxdy∫Ω∇h⋅∇ϕdxdy=∮∂Ωh(ϕxdy−ϕydx)−∫ΩhΔϕdxdy
由于边界处 (h=0),边界积分项消失。同理处理第二项,最终化简为:
∂E(ϕ+δh)∂δ∣δ→0=∫Ωh(−Δϕ+∇⋅∇ϕ∣∇ϕ∣)dxdy\left. \frac{\partial E(\phi + \delta h)}{\partial \delta} \right|{\delta \to 0} = \int{\Omega} h \left( - \Delta \phi + \nabla \cdot \left \\frac{\\nabla \\phi}{\|\\nabla \\phi\|} \\right \right) dxdy∂δ∂E(ϕ+δh) δ→0=∫Ωh(−Δϕ+∇⋅∣∇ϕ∣∇ϕ)dxdy
5. 得证 Euler-Lagrange 方程(泛函梯度)
当能量达到极小值时,上式对任意扰动 (h) 都必须等于0。因此括号内的内容必须为0,这就得到了能量泛函的梯度(Euler-Lagrange 方程) :
∂E(ϕ)∂ϕ=−Δϕ−∇⋅(∇ϕ∣∇ϕ∣)\boxed{ \frac{\partial E(\phi)}{\partial \phi} = -\left \\Delta \\phi - \\nabla \\cdot \\left( \\frac{\\nabla \\phi}{\|\\nabla \\phi\|} \\right) \\right }∂ϕ∂E(ϕ)=−Δϕ−∇⋅(∣∇ϕ∣∇ϕ)
(注:课件第74页最终推导出的 (E(\phi)) 梯度正是此式。)
二、 梯度下降法(构建演化方程)
得到了能量 (E(\phi)) 的泛函梯度 (\frac{\partial E(\phi)}{\partial \phi}) 之后,我们要让 (\phi) 随时间演化,向着能量最小的方向移动。
1. 梯度下降流的核心公式
在数学优化中,梯度下降的方向是梯度的反方向 。将水平集函数 (\phi) 视为随时间 (t) 变化的函数,我们直接构建**偏微分方程(PDE)**如下:
∂ϕ∂t=−∂E(ϕ)∂ϕ\frac{\partial \phi}{\partial t} = - \frac{\partial E(\phi)}{\partial \phi}∂t∂ϕ=−∂ϕ∂E(ϕ)
2. 代入变分法求出的梯度
将第一步得到的梯度代入上式:
∂ϕ∂t=−(−Δϕ−∇⋅(∇ϕ∣∇ϕ∣))\frac{\partial \phi}{\partial t} = -\left( -\left \\Delta \\phi - \\nabla \\cdot \\left( \\frac{\\nabla \\phi}{\|\\nabla \\phi\|} \\right) \\right \right)∂t∂ϕ=−(−Δϕ−∇⋅(∣∇ϕ∣∇ϕ))
化简得:
∂ϕ∂t=Δϕ−∇⋅(∇ϕ∣∇ϕ∣)\boxed{ \frac{\partial \phi}{\partial t} = \Delta \phi - \nabla \cdot \left( \frac{\nabla \phi}{|\nabla \phi|} \right) }∂t∂ϕ=Δϕ−∇⋅(∣∇ϕ∣∇ϕ)
这个方程被称为水平集的重初始化流(Reinitialization flow) 。它虽然复杂,但在代码中只需要用有限差分法(离散化)去迭代求解。其物理含义是:只要用这个方程不断更新 (\phi),最终矩阵 (\phi) 的梯度模长 (|\nabla \phi|) 会自动逼近1,从而不需要手动去做"重初始化"操作。
四、 如何基于演化实现图像分割(工程步骤)
结合已推导的方程,计算机完整实现水平集图像分割的流程如下:
1. 初始化(生成符号距离函数)
在图像上放置一个初始闭合轮廓(如一个圆)。计算每个像素点到轮廓的距离,构建符号距离函数矩阵 (\phi_0):内部为 (+) 距离,外部为 (-) 距离。保证 (|\nabla \phi_0| \approx 1)。
2. 构建图像速度场
利用原始图像 (I) 计算边缘停止函数 (g(x,y) = \frac{1}{1+|\nabla I|^2})。在物体边缘处 (g \to 0),使得曲线演化在此处停驻。
3. 迭代演化(更新矩阵 (\phi))
在一个极小的离散时间步长 (\Delta t) 下,按照上一步推导的梯度下降流方程,对矩阵 (\phi) 中的每一个像素值做数值更新(利用中心差分法计算 (\nabla \phi) 和 (\text{div}))。
- 计算机无需关注曲线的具体位置,只负责按照 PDE 更新整个矩阵。
4. 重初始化(Re-initialization)
经过多次迭代后,矩阵 (\phi) 的梯度模长会偏离 (1),导致数值计算不稳定。工程代码中每隔若干次迭代 (如 20 步),会强制对当前矩阵 (\phi) 执行一次符号距离变换,将其严格修正为 SDF。
5. 判定收敛与最终结果输出
计算矩阵 (\phi) 在两次迭代间的变化量总和。当变化量极小(小于设定阈值)时,停止迭代。最终分割结果并非画线,而是直接对最终矩阵 (\phi_{final}) 进行符号判断:
- 若 ϕfinal(x,y)≥0\phi_{final}(x,y) \ge 0ϕfinal(x,y)≥0,判定为前景(目标区域)。
- 若 ϕfinal(x,y)<0\phi_{final}(x,y) < 0ϕfinal(x,y)<0,判定为背景。
- 生成的二值掩膜(Mask)即最终的图像分割结果。
Graph Cut & Meanshift
一、 Graph Cut 图割法分割原理
Graph Cut 将图像分割问题转化为图的最小割(Min Cut)问题,通过构建带权无向图并最小化能量函数,实现目标与背景的分离。
1. 图的构建(图形化定义)
计算机将图像映射为一个带权的无向图 (G = (V, E)),包含两类顶点和两种边:
- 普通顶点:图像中的每一个像素对应图中的一个节点。
- 终端顶点 :两个特殊的节点,**S(源点/Source,代表前景目标)**和 T(汇点/Sink,代表背景)。
- n-links(邻域边) :普通顶点之间的边(通常连接4邻域或8邻域像素)。对应图像分割中的 平滑项(Smooth项),表示像素间的空间连贯性约束。
- t-links(终端边) :每个普通顶点与源点 S 和汇点 T 之间的连接边。对应图像分割中的 数据项(Data项),表示该像素属于前景或背景的先验概率。
2. 能量函数的形式化表达
图割的目标是找到图像分割的标签 (x),使得如下能量函数 最小化(课件第77页):
Ex=Edata(x)+λEsmooth(x)E_x = E_{data}(x) + \lambda E_{smooth}(x)Ex=Edata(x)+λEsmooth(x)
-
Data项(属于某类的代价) :
定义普通顶点到源点 S 和汇点 T 的边权值。通常基于像素灰度的先验概率 (P) 计算:
Edata(xi)∝−lnPr(Ii∣Ai)E_{data}(x_i) \propto -\ln \Pr(I_i \mid A_i)Edata(xi)∝−lnPr(Ii∣Ai)
其中 (A_i \in {s, t}) 表示像素 (x_i) 属于前景还是背景。条件概率越高,能量(代价)越低。
-
Smooth项(相邻像素不一致的惩罚) :
定义连接普通顶点的边权值,用于约束相邻像素的标记一致性。
Esmooth(xi,xj)=exp(−(Ii−Ij)22σ2)⋅δ(Ai,Aj)E_{smooth}(x_i, x_j) = \exp\left(-\frac{(I_i - I_j)^2}{2\sigma^2}\right) \cdot \delta(A_i, A_j)Esmooth(xi,xj)=exp(−2σ2(Ii−Ij)2)⋅δ(Ai,Aj)
其中 (\delta(A_i, A_j)) 为指示函数,当相邻像素标签不同时为1,相同时为0。物理意义:两个像素越相似,强行把它们切分成不同区域的代价(能量)就越高。
3. 最小割与最大流定理(求解 )
图像的最终分割对应于寻找一个边集合的割(Cut) ,使得所有边的权值之和最小。
- 根据最大流最小割定理(课件第81页),一个网络流中从源点 S 到汇点 T 的最大流量,等价于该网络能中断流通的最小割的容量和。
- 算法步骤 :
- 构建带权图,根据 Data 项和 Smooth 项设定边权。
- 利用(如 Ford-Fulkerson 算法)寻找从 S 到 T 的最大流。
- 网络达到最大流时,所有满流弧构成了一个最小割。
- 该最小割将图的顶点划分为两个不相交的子集 S 和 T,分别对应图像的前景(目标)和背景,完成分割。
4. 优缺点
- 优点:能得到全局最优解(因为图割算法是凸优化),能自然地结合区域统计信息和边界平滑约束。
- 缺点 :需人为交互提供背景和前景的先验种子点;属于二值分割,多目标分割需扩展为多标签图割。
二、 Mean Shift 均值漂移分割原理
Mean Shift 是一种基于非参数核密度估计的聚类算法。它不依赖于先验知识(如 K-means 需要指定 K 值),通过寻找特征空间中的**概率密度峰值(模值点)**来分割图像。
- 核心思想与特征空间
- 将图像中的每一个像素看作特征空间中的一个样本点。
- 联合特征空间 :为了同时保证颜色的相似性和空间的连续性,通常使用空间位置 + 颜色特征 的组合(课件第98页,特征 (=) 空间位置 ((x,y)) + 颜色 ((L,u,v)))。即 (K(\mathbf{x}) = C \cdot k_s(|\frac{\mathbf{x}s}{h_s}|2) \cdot k_r(|\frac{\mathbf{x}r}{h_r}|2))。
- 在高维特征空间中,目标区域对应一个密度较高的簇(点群)。
Mean Shift 向量定义
对于空间中的任意点 (x),其 Mean Shift 向量的初始形式定义为落入以 (x) 为中心、半径为 (h) 的球域内样本点的平均偏移向量 :
Mh(x)=1k∑xi∈Sh(xi−x)M_h(x) = \frac{1}{k} \sum_{x_i \in S_h} (x_i - x)Mh(x)=k1∑xi∈Sh(xi−x)
引入核函数(如高斯核)和权值 后,最终的 Mean Shift 向量为:
m(x)=∑i=1nxig(∥x−xih∥2)ω(xi)∑i=1ng(∥x−xih∥2)ω(xi)−xm(x) = \frac{\sum_{i=1}^{n} x_i g\left(\left\| \frac{x - x_i}{h} \right\|^2\right) \omega(x_i)}{\sum_{i=1}^{n} g\left(\left\| \frac{x - x_i}{h} \right\|^2\right) \omega(x_i)} - xm(x)=∑i=1ng(∥hx−xi∥2)ω(xi)∑i=1nxig(∥hx−xi∥2)ω(xi)−x
重要结论(课件第96-97页) :这个向量 (m(x)) 的方向与样本点概率密度函数的梯度方向一致,始终指向密度增大的最快方向。
Mean Shift 迭代算法流程(课件第96页)
-
在当前窗口中心 (x) 处,计算 Mean Shift 向量 (m(x))。
-
将当前窗口移动到 (m(x)) 所在的新位置(即把窗口中心平移到新的质心)。
-
重复步骤1、2,直到 (m(x)) 趋近于 0 (即窗口中心到达密度的局部极大值点)。
由于 Mean Shift 向量总是指向密度最大的方向,迭代算法必然收敛。
-
图像分割的实现步骤(课件第102页)
-
特征映射与漂移 :将图像每一个像素特征映射到联合空间,执行上述 Mean Shift 迭代,使每一个像素点都收敛到某个局部密度峰值(模值点)。
-
聚类模值点:将收敛到同一个模值点的所有像素归为一类。
-
区域合并(剔除非主要区域):
- 如果两个模值点之间的距离小于空间带宽半径 (h_s) ,且颜色差值小于颜色带宽半径 (h_r),则将它们合并。
- 除去包含像素数目少于 (M) 的极小区域(平滑处理)。
优缺点
- 优点:无需预设聚类数目 (K),能自动发现任意形状的簇;对参数(带宽 (h))的鲁棒性较好。
- 缺点:计算量极大(每个像素都要迭代漂移);带宽 (h)(核函数窗口大小)需要人为指定且难以自适应调整。
💡 考试快速对比总结表
| 对比维度 | Graph Cut 图割法 | Mean Shift 均值漂移 |
|---|---|---|
| 数学本质 | 能量最小化(组合优化) | 密度聚类(梯度上升) |
| 预处理要求 | 需要用户交互标注前景/背景种子 | 完全无监督,不需指定 K 值 |
| 是否保证全局最优 | 是(最大流最小割定理保证) | 否(依赖初始点和带宽,会陷入局部密度极大值) |
| 适用场景 | 交互式分割,医学图像分割,二值分割 | 视频跟踪,图像平滑/分割(无监督) |
| 核心优势 | 能纳入硬约束(用户划线) | 能处理任意形状的簇,空间+颜色联合特征 |
💡 考场踩分点提示:
如果考Graph Cut 简答,务必写出能量函数 (E_x = E_{data} + \lambda E_{smooth}) 并解释物理意义。
如果考Mean Shift 简答,务必写明**"Mean Shift 向量的方向与概率密度函数的梯度方向一致",以及"特征提取、漂移收敛、聚类合并"**三步法。这两点是判定是否掌握算法本质的核心踩分点。
1. 请解释基于水平集演化的图像分割的基本思想是什么?

第一问:基于水平集演化的图像分割的基本思想
(对应图中 b、c 两点)
- 嵌入(升维) :将动态的二维闭合曲线 (C(p,t)) 视为一个随时间变化的二维标量函数 (\phi(x,y,t)) 的零水平集(即满足 (\phi(x,y,t)=0) 的点的集合)。
- 间接演化 :不直接操作曲线 (C) 上的点,而是通过控制函数 ϕ(x,y,t)\phi(x,y,t)ϕ(x,y,t) 的演化方程,来间接实现 (C) 的形变。
- 停驻 :将图像梯度信息(边缘强度)编码进速度函数 (F) 中。让 (F) 在无纹理平坦区域速度较大,在目标边缘处速度趋近于 0,最终零水平集精准停在物体边缘,完成分割。
第二问:曲线演化方程到水平集演化方程的推导证明
1. 已知曲线演化方程
设曲线为 (C(p,t)),其曲线演化的标准方程为:
∂C∂t=F⋅N\frac{\partial C}{\partial t} = F \cdot \mathbf{N}∂t∂C=F⋅N
其中 (F) 是法向速度函数(由图像梯度和曲率决定),(\mathbf{N}) 是曲线的单位法向量。
2. 嵌入到水平集函数
将曲线 (C) 嵌入到水平集函数 (\phi(x,y,t)) 中,使得曲线上的点始终满足:
ϕ(C(p,t),t)=0\phi(C(p,t), t) = 0ϕ(C(p,t),t)=0
3. 对时间 (t) 求全微分(链式法则)
对上述等式两边同时对时间 (t) 求偏导(使用隐函数求导的链式法则):
∂ϕ∂t+∇ϕ⋅∂C∂t=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot \frac{\partial C}{\partial t} = 0∂t∂ϕ+∇ϕ⋅∂t∂C=0
其中 ∇ϕ=(∂ϕ∂x,∂ϕ∂y)\nabla \phi = \left( \frac{\partial \phi}{\partial x}, \frac{\partial \phi}{\partial y} \right)∇ϕ=(∂x∂ϕ,∂y∂ϕ) 是 ϕ\phiϕ 的空间梯度向量。
4. 代入曲线演化方程
将第 1 步中的 ∂C∂t=F⋅N\frac{\partial C}{\partial t} = F \cdot \mathbf{N}∂t∂C=F⋅N 代入上式:
∂ϕ∂t+∇ϕ⋅(FN)=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot (F \mathbf{N}) = 0∂t∂ϕ+∇ϕ⋅(FN)=0
5. 引入水平集的法向量关系
水平集函数有一个极其重要的几何性质:零水平集的单位法向量与 (\phi) 的梯度方向是共线的 。
根据定义(假设指向曲线外侧),法向量可表示为:
N=∇ϕ∣∇ϕ∣\mathbf{N} = \frac{\nabla \phi}{|\nabla \phi|}N=∣∇ϕ∣∇ϕ
(注:根据题目图片中手写的推导过程,使用的是指向内侧的法向量,即 N=−∇ϕ∣∇ϕ∣\mathbf{N} = - \frac{\nabla \phi}{|\nabla \phi|}N=−∣∇ϕ∣∇ϕ。带入符号最后的正负号会相反,但最终方程形式一致。这里按课件标准代入进行化简)
将法向量表达式代入第 4 步的等式:
∂ϕ∂t+∇ϕ⋅(−F∇ϕ∣∇ϕ∣)=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot \left( -F \frac{\nabla \phi}{|\nabla \phi|} \right) = 0∂t∂ϕ+∇ϕ⋅(−F∣∇ϕ∣∇ϕ)=0
6. 向量运算化简
利用向量点乘的性质:梯度向量与自身的点乘等于模长的平方,即 (\nabla \phi \cdot \nabla \phi = |\nabla \phi|^2)。
带入上式:
∂ϕ∂t−F∇ϕ⋅∇ϕ∣∇ϕ∣=∂ϕ∂t−F∣∇ϕ∣2∣∇ϕ∣=0\frac{\partial \phi}{\partial t} - F \frac{\nabla \phi \cdot \nabla \phi}{|\nabla \phi|} = \frac{\partial \phi}{\partial t} - F \frac{|\nabla \phi|^2}{|\nabla \phi|} = 0∂t∂ϕ−F∣∇ϕ∣∇ϕ⋅∇ϕ=∂t∂ϕ−F∣∇ϕ∣∣∇ϕ∣2=0
7. 得证
消去一个 ∣∇ϕ∣|\nabla \phi|∣∇ϕ∣,移项后即得到最终的水平集演化方程:
∂ϕ∂t=F∣∇ϕ∣\boxed{\frac{\partial \phi}{\partial t} = F |\nabla \phi|}∂t∂ϕ=F∣∇ϕ∣
2. 图像分割的定义、阈值分割方法(10),给定两个正态分布,分别为背景图和物品的分布,平均值为u1,u2。方差为m1,m2,且u1>u2+m2*3(大概是这个),使用二值分割,问阈值是多少。

结合你提供的《数字图像分析》第六章课件,以及这道典型的10分考题,我将从图像分割的严格定义 、阈值分割原理 ,以及这道题的具体数学推导三个层面来详细解答。
1. 图像分割的数学定义(结合课件第2页)
在严谨的数字图像分析中,图像分割可以用集合论严格定义。
设集合 (R) 代表整幅图像区域,对 (R) 的分割可以被看作是将 (R) 分成若干个非空子集(子区域) (R_1, R_2, \dots, R_n),并需满足以下四个条件:
- 完备性:(\bigcup_{i=1}^n R_i = R)(所有子区域拼起来刚好是整幅图);
- 互斥性:对于任意 (i \neq j),有 (R_i \cap R_j = \varnothing)(各个区域之间没有重叠);
- 连通性:每个子区域 (R_i) 内部必须是联通的;
- 均匀性/一致性 :对于每个子区域,均匀性测度 (P(\cdot)) 为真 (比如内部灰度分布均匀);但对于任意两个相邻子区域之并,(P) 为假(即相邻区域必须有明显差异,避免"过度分割")。
2. 阈值分割方法的核心思想(结合课件第4-6、9页)
阈值分割是最传统、计算量最小的图像分割方法。
- 基本原理 :基于图像中目标与背景的灰度差异。如果目标与背景的灰度分别集中在不同的区间,我们可以在直方图中找到一个阈值 (T),将图像像素分为两类(如 (>T) 为目标,(\le T) 为背景)。
- 实现步骤 :单阈值分割公式为 g(x,y)={1f(x,y)>T0f(x,y)≤Tg(x,y) = \begin{cases} 1 & f(x,y) > T \\ 0 & f(x,y) \le T \end{cases}g(x,y)={10f(x,y)>Tf(x,y)≤T。
- 如何求取最优阈值?
- 最简单的是直方图双峰法(取双峰之间的谷底)。
- 大津法(Otsu) (课件重点):通过最大化类间方差 (或最小化类内方差)来自动寻找全局最优阈值,属于无监督的自适应阈值分割。
3. 针对本题的推导与标准答案(给定两个高斯分布)
题目已知条件:
- 背景分布:均值 (\mu_1),方差 (\sigma_1^2)(对应题目中的 (m_1))。
- 物品分布:均值 (\mu_2),方差 (\sigma_2^2)(对应题目中的 (m_2))。
- 约束条件:(\mu_1 > \mu_2 + 3\sigma_2)(即背景均值比物品均值大了超过 3 倍物品分布的标准差)。
问:使用二值分割,最佳阈值是多少?
严谨的数学推导与结论:
- 两类的概率密度函数均为高斯分布,它们在灰度上的重叠区域可以忽略不计(因为 (\mu_1) 远远大于 (\mu_2),差值为 (3\sigma_2) 以上)。
- 在这个条件下,最小错误率贝叶斯分类准则的解,就是求方程 (p(\text{背景}) \cdot P(x|\text{背景}) = p(\text{物品}) \cdot P(x|\text{物品})) 的根。
- 考试最标准、最直接的答案 :
当两个分布完全分离开来,或者说重叠极少时,最优分割阈值直接取为 两个分布均值的中点 。
T=μ1+μ22\boxed{T = \frac{\mu_1 + \mu_2}{2}}T=2μ1+μ2
3.从集合角度分析图像分割原理,参数化主动轮廓模型的图像分割以及level set的好处
1. 集合角度分析图像分割原理(第2页)
设整个图像区域为集合 (R),分割是将 (R) 划分为非空子集 (R_i),满足:
① 完备性:⋃i=1nRi=R\bigcup_{i=1}^n R_i = R⋃i=1nRi=R;
② 互斥性:Ri∩Rj=∅,i≠jR_i \cap R_j = \varnothing, i\neq jRi∩Rj=∅,i=j;
③ 连通性:每个子区域 (R_i) 连通;
④ 均匀性:满足逻辑谓词 P(Ri)=TRUEP(R_i)=\text{TRUE}P(Ri)=TRUE,且相邻子区域之并满足 P(Ri∪Rj)=FALSEP(R_i \cup R_j)=\text{FALSE}P(Ri∪Rj)=FALSE。
2. 参数化主动轮廓(Snakes)分割原理(第50-51、60页)
定义能量泛函:Esnake=∫(Eint+Eext)dsE_{\text{snake}} = \int (E_{\text{int}} + E_{\text{ext}}) dsEsnake=∫(Eint+Eext)ds。
内部能量 EintE_{\text{int}}Eint(由一阶、二阶导数组成)约束曲线的平滑性;外部能量 EextE_{\text{ext}}Eext(依赖图像梯度)将曲线拉向目标边缘。通过梯度下降法迭代极小化能量(求解欧拉-拉格朗日方程)实现曲线演化。
致命缺点 :由于曲线由离散控制点显式表示,无法自适应处理拓扑变化(不能分裂或合并)。
3. Level Set(水平集)的好处(第60-62、65页)
- 天然支持拓扑变化 :将动态曲线嵌入高维函数 (\phi(x,t)) 的零水平集 ((\phi=0))。曲线分裂或合并时,对应矩阵 (\phi) 正负号自动变化,无需额外编程处理拓扑。
- 统一数学推导:由链式法则推导得到水平集演化方程 (\frac{\partial \phi}{\partial t} = F|\nabla \phi|),将问题转化为固定网格上的偏微分方程数值求解。
- 数值稳定性 :初始化为符号距离函数(SDF) (即满足 (|\nabla \phi| = 1)),在迭代过程中通过重初始化(Re-initialization)维持稳定,保证曲率等几何量计算的准确性。
4. 图像分割的集合定义, 水平集变分推导
一、 图像分割的集合定义(约4分,对应PPT第2页)
设图像区域为集合 (R),分割是将 (R) 划分为 (n) 个非空子集 (R_1, R_2, \dots, R_n),并满足:
- 完备性:(\bigcup_{i=1}^n R_i = R);
- 互斥性:对于任意 (i \neq j),(R_i \cap R_j = \varnothing);
- 连通性:每个子区域 (R_i) 必须是连通的;
- 均匀性:区域内满足 (P(R_i)=\text{TRUE}),相邻区域的并满足 (P(R_i \cup R_j)=\text{FALSE})(避免过度分割)。
二、 水平集的变分推导(约8分,严格对应PPT第69页、70-74页)
1. 构造变分能量泛函(对照PPT第69页)
引入一个包含惩罚项和边缘项的能量泛函 E(ϕ)\mathcal{E}(\phi)E(ϕ):
E(ϕ)=μP(ϕ)+λLg(ϕ)+νAg(ϕ)\mathcal{E}(\phi) = \mu \mathcal{P}(\phi) + \lambda \mathcal{L}_g(\phi) + \nu \mathcal{A}_g(\phi)E(ϕ)=μP(ϕ)+λLg(ϕ)+νAg(ϕ)
其中,P(ϕ)=∫Ω12(∣∇ϕ∣−1)2dxdy\mathcal{P}(\phi) = \int_{\Omega} \frac{1}{2} (|\nabla \phi| - 1)^2 dxdyP(ϕ)=∫Ω21(∣∇ϕ∣−1)2dxdy 是重初始化惩罚项;
Lg(ϕ)=∫Ωgδ(ϕ)∣∇ϕ∣dxdy\mathcal{L}g(\phi) = \int{\Omega} g\delta(\phi)|\nabla \phi|dxdyLg(ϕ)=∫Ωgδ(ϕ)∣∇ϕ∣dxdy 是边缘长度项;
Ag(ϕ)=∫ΩgH(−ϕ)dxdy\mathcal{A}g(\phi) = \int{\Omega} gH(-\phi)dxdyAg(ϕ)=∫ΩgH(−ϕ)dxdy 是面积项(速度项)。
边缘指示函数 g=11+∣∇Gσ∗I∣2g = \frac{1}{1 + |\nabla G_\sigma * I|^2}g=1+∣∇Gσ∗I∣21。
2. 变分法求导(对照PPT第70-74页推导本质)
引入微小的扰动 ϵη\epsilon \etaϵη(满足边界 (\eta|{\partial \Omega}=0)),令 ϕϵ=ϕ+ϵη\phi{\epsilon} = \phi + \epsilon \etaϕϵ=ϕ+ϵη。求能量泛函关于 ϵ\epsilonϵ 的极值,即令一阶变分导数为0:
dE(ϕ+ϵη)dϵ∣ϵ=0=0\left. \frac{d \mathcal{E}(\phi + \epsilon \eta)}{d\epsilon} \right|_{\epsilon=0} = 0dϵdE(ϕ+ϵη) ϵ=0=0
通过分部积分 (利用格林公式将梯度算子转移),并利用边界条件消去边界积分项,得到对应能量泛函的欧拉-拉格朗日方程。
3. 导出最终的演化方程(对照PPT第69页最下方公式)
根据最陡梯度下降法,令 (\phi) 随时间变化的方向为能量函数负梯度的方向,最终得到的水平集演化方程 为(PPT原式):
∂ϕ∂t=μΔϕ−div(∇ϕ∣∇ϕ∣)+λδ(ϕ)div(g∇ϕ∣∇ϕ∣)+νgδ(ϕ)\boxed{\frac{\partial \phi}{\partial t} = \mu \left \\Delta \\phi - \\text{div} \\left( \\frac{\\nabla \\phi}{\|\\nabla \\phi\|} \\right) \\right + \lambda \delta(\phi) \text{div} \left( g \frac{\nabla \phi}{|\nabla \phi|} \right) + \nu g \delta(\phi) }∂t∂ϕ=μΔϕ−div(∣∇ϕ∣∇ϕ)+λδ(ϕ)div(g∣∇ϕ∣∇ϕ)+νgδ(ϕ)
5. 图像分割的定义, 水平集的基本思想, 水平集的推导(只考了PPT上的部分)
第一问:图像分割的定义
设集合 (R) 代表整个图像区域,对 (R) 的分割可看作将 (R) 分成若干个满足下述条件的非空子集(子区域)(R_1, R_2, \dots, R_n):
- 完备性 :⋃i=1nRi=R\bigcup_{i=1}^n R_i = R⋃i=1nRi=R (所有子区域的并集必须等于原图像)。
- 互斥性 :对 ∀i≠j\forall i \neq j∀i=j,有 Ri∩Rj=∅R_i \cap R_j = \emptysetRi∩Rj=∅ (不同子区域之间没有重叠)。
- 连通性:每个子区域 (R_i) 必须是连通的。
- 均匀性 :对于各个子区域,均匀性测度 P(⋅)P(\cdot)P(⋅) 为真;但对其任意两个相邻子区域之并,其均匀性测度 (P) 为假(避免过度分割,即 P(Ri)=TRUEP(R_i) = \text{TRUE}P(Ri)=TRUE,且 P(Ri∪Rj)=FALSEP(R_i \cup R_j) = \text{FALSE}P(Ri∪Rj)=FALSE)。
第二问:水平集(Level Set)的基本思想
- 升维嵌入 :将动态的二维闭合曲线 (C(p,t)) 嵌入到一个随时间 (t) 变化的二维函数 (\phi(x,y,t)) 中,使得该动态曲线对应函数中高度为 0 的等值面(即零水平集:(\phi(C(p,t), t) = 0))。
- 间接演化 :不直接在图像空间修改轮廓曲线的坐标点 ,而是通过在整张图像上演化动态曲面 (\phi(x,y,t)),利用偏微分方程(PDE)不断更新矩阵中的每个像素值,从而间接实现底层零水平集(轮廓曲线)的形变。
- 自适应停驻 :通过设计由图像梯度 决定的速度函数 (F),使得演化在图像平坦区域速度快,在物体边缘处速度趋近于 0。当零水平集停驻在物体边缘处时,即完成图像分割。
(注:天然支持拓扑变化,即曲线在演进中可以自动分裂或合并,是水平集相对于 Snake 模型的突出优势,考试如有余力可补充)。
第三问:水平集的推导(梯度下降法推导)
Step 1:已知曲线演化方程
给定一条随时间变化的动态闭合曲线 (C(p,t)),其标准的曲线演化方程为:
∂C∂t=F⋅N\frac{\partial C}{\partial t} = F \cdot \mathbf{N}∂t∂C=F⋅N
其中,(F) 是沿法线方向的速度函数 (由图像梯度和曲率决定),(\mathbf{N}) 是曲线的单位法向量。
Step 2:嵌入到水平集函数
将曲线 (C) 嵌入到水平集函数 (\phi(x,y,t)) 中,使曲线始终是该函数的零水平集,即有恒等式:
ϕ(C(p,t),t)=0\phi(C(p,t), t) = 0ϕ(C(p,t),t)=0
Step 3:对时间 (t) 求全微分(链式法则)
对上述等式两边同时对时间 (t) 求偏导,应用多变量微积分的链式法则:
∂ϕ∂t+∇ϕ⋅∂C∂t=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot \frac{\partial C}{\partial t} = 0∂t∂ϕ+∇ϕ⋅∂t∂C=0
其中,∇ϕ=(∂ϕ∂x,∂ϕ∂y)\nabla \phi = \left( \frac{\partial \phi}{\partial x}, \frac{\partial \phi}{\partial y} \right)∇ϕ=(∂x∂ϕ,∂y∂ϕ) 是水平集函数 (\phi) 的空间梯度向量。
Step 4:代入曲线演化方程
将 Step 1 中的 (\frac{\partial C}{\partial t} = F \cdot \mathbf{N}) 代入 Step 3 的等式中:
∂ϕ∂t+∇ϕ⋅(FN)=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot (F \mathbf{N}) = 0∂t∂ϕ+∇ϕ⋅(FN)=0
Step 5:引入水平集的法向量关系
根据水平集函数的几何性质,零水平集的单位法向量 (\mathbf{N}) 与 (\phi) 的梯度方向共线。根据推导方向选择符号(通常定义指向外侧的法向量为 (\mathbf{N} = \frac{\nabla \phi}{|\nabla \phi|}),或者根据课件手写笔迹指向内侧为 (\mathbf{N} = -\frac{\nabla \phi}{|\nabla \phi|}),将其代入 Step 4 的等式进行化简。
这里以课件常见推导代入(设 (\mathbf{N} = -\frac{\nabla \phi}{|\nabla \phi|})):
∂ϕ∂t+∇ϕ⋅(−F∇ϕ∣∇ϕ∣)=0\frac{\partial \phi}{\partial t} + \nabla \phi \cdot \left( -F \frac{\nabla \phi}{|\nabla \phi|} \right) = 0∂t∂ϕ+∇ϕ⋅(−F∣∇ϕ∣∇ϕ)=0
Step 6:向量运算化简
利用向量点乘性质:(\nabla \phi \cdot \nabla \phi = |\nabla \phi|^2),化简上式:
∂ϕ∂t−F∣∇ϕ∣2∣∇ϕ∣=0\frac{\partial \phi}{\partial t} - F \frac{|\nabla \phi|^2}{|\nabla \phi|} = 0∂t∂ϕ−F∣∇ϕ∣∣∇ϕ∣2=0
化简得到:
∂ϕ∂t−F∣∇ϕ∣=0\frac{\partial \phi}{\partial t} - F |\nabla \phi| = 0∂t∂ϕ−F∣∇ϕ∣=0
Step 7:得证(水平集演化方程)
移项后,得到最终的水平集演化方程:
∂ϕ∂t=F∣∇ϕ∣\boxed{\frac{\partial \phi}{\partial t} = F |\nabla \phi|}∂t∂ϕ=F∣∇ϕ∣
6. 聚类分析和kmeans方法计算
一、 聚类分析(图像分割中的原理)
在图像分割中,聚类分割是把图像的每个像素看作特征空间中的一个样本点。
- 特征表达 :样本点的特征可以是像素的灰度值、RGB颜色值、空间坐标位置、纹理特征等。
- 分割目标:根据特征空间中样本的分布,将像素划分为 (K) 个簇,使得同一个簇内的像素特征高度相似(类内方差最小),不同簇的特征差异显著。
二、 K-Means 聚类算法的标准计算步骤(必背)
K-Means 是一种基于迭代优化 的硬聚类算法。以下是考试必须掌握的数学公式和步骤:
1. 初始化
随机或根据先验知识选取 (K) 个初始聚类中心 ({\mu_1, \dots, \mu_K})。在图像分割中,K 通常代表图像中的"前景/背景"或目标数量。
2. 分配样本(基于最小欧氏距离)
对于特征空间中的每一个样本点 (x_n),计算它到每一个聚类中心 (\mu_i) 的距离。将其分配到距离最小的那个簇。
数学形式为:
rnk={1,若 ∥xn−μk∥2≤∥xn−μj∥2(∀j≠k)0,其他 r_{nk} = \begin{cases} 1, & \text{若 } \|x_n - \mu_k\|^2 \le \|x_n - \mu_j\|^2 \quad (\forall j \neq k) \\ 0, & \text{其他} \end{cases} rnk={1,0,若 ∥xn−μk∥2≤∥xn−μj∥2(∀j=k)其他
(r_{nk}=1) 表示样本 (n) 被分配到第 (k) 个簇。
3. 更新聚类中心
根据第 2 步分配的结果,重新计算每个簇的质心(新的聚类中心) 。
数学公式为:
μk=1Nk∑n=1Nrnk⋅xn \mu_k = \frac{1}{N_k} \sum_{n=1}^{N} r_{nk} \cdot x_n μk=Nk1n=1∑Nrnk⋅xn
((N_k) 表示第 (k) 个簇中包含的样本总数,即求和分配到该簇的所有样本并取平均)。
4. 判断是否收敛
重复步骤 2 和步骤 3,直到聚类中心的位置不再发生变化 (即目标函数 (J) 收敛)。
目标函数(加权类内方差和)为:
J=∑n=1N∑k=1Krnk∥xn−μk∥2 J = \sum_{n=1}^{N} \sum_{k=1}^{K} r_{nk} \|x_n - \mu_k\|^2 J=n=1∑Nk=1∑Krnk∥xn−μk∥2
在计算机代码中,通常会设定最大迭代次数,达到后强制停止。
第七章 图像识别
几何验证(剔除错误匹配)
使用词袋模型(BoW)得到的匹配,虽然候选集缩小了,但"我只和你共享了相同单词,并不代表我在空间上和你长得像"。因此必须进行空间几何验证。
1. RANSAC(随机采样一致性)
- 核心思想 :从一堆包含错误匹配点对(Outliers)的原始数据中,通过随机采样,迭代找出能正确拟合模型的一组"内点"(Inliers),从而剔除Outliers。
- 算法步骤(对应课件幻灯片41) :
- 随机采样:随机选取最少点对(如仿射变换至少需要3对匹配点),假设它们是Inliers。
- 估计模型 :利用这3对点计算出一个仿射变换模型 (\begin{pmatrix} x \ y \end{pmatrix} = \begin{pmatrix} m_1 & m_2 \ m_3 & m_4 \end{pmatrix} \begin{pmatrix} u \ v \end{pmatrix} + \begin{pmatrix} t_1 \ t_2 \end{pmatrix})。
- 验证内点:将其他所有匹配点代入该模型,如果误差小于阈值,则视为内点,记录内点数量。
- 迭代输出 :重复上述步骤多次(通常几十次到几百次),最后选取内点数量最多的那个模型,并用这些内点重新估计最终的仿射变换。
- 优缺点:准确度高,但计算量大(复杂度为 (O(N^3))),在大规模图像检索的在线阶段较耗时。
2. 空间编码(Spatial Coding)
- (这就是为了弥补 RANSAC 耗时问题而被提出的)。
- 核心思想 :不求解复杂的矩阵变换,而是通过构建简单的相对空间位置矩阵来判断两幅图像是否一致。
- 算法步骤 :
- 构建相对位置矩阵:对于一幅图中的一组匹配点,以其中第 (i) 个点作为原点,判断第 (j) 个点在它的左/右(Xmap)以及上/下(Ymap)。
- 异或(XOR)对比:假设查询图 (I_q) 和匹配图 (I_m) 中,它们各自的Xmap和Ymap矩阵应该一致。将两张图的Xmap做异或运算((Vx = Xmap_q \oplus Xmap_m))。
- 迭代剔除 :异或结果为1的位置,表示两者空间位置关系冲突。遍历矩阵,找出不一致行(点)最多的那个匹配点对(认为它是Outlier),将它剔除掉。重复迭代,直到所有剩余点的空间布局完全一致(异或结果全为0)。
- 优点:在课件中重点强调,它能以极快的速度在大规模图像检索中实现几何验证,且不需要像RANSAC那样做复杂的随机迭代。
二值哈希的三种方法
在大规模数据集(如1000万张图)下,用512维的浮点向量做欧氏距离检索,无论是存储(20GB)还是算力都扛不住。二值哈希 的本质,是将高维浮点向量映射为几十位到一百多位 的二进制编码(比如128位bit),最终用极快的异或(XOR)和查表来替代慢速的浮点相乘。
方法1:局部敏感哈希(LSH - Locality Sensitive Hashing)
- (这是最原始的哈希法,属于"概率近似"方法)。
- 基本思想:如果在原始特征空间中两个点距离很近,那么经过随机的哈希函数映射后,它们落到同一个"桶"(桶内哈希值相同)的概率应该极高;反之,距离远的点落到同一个桶的概率极低。
- 具体做法 :在特征空间中随机生成多个超平面或抽取位。为了弥补单个哈希函数的偶然性,通常会构建L个哈希表(课件57页)。
- 检索过程 :查询时,去L个哈希表中找同一个桶里的点作为候选。因为是多表并行,能极大保证即便漏掉一次,还有机会在别的表里被找到。
方法2:迭代量化(ITQ - Iterative Quantization)
- (课件58页重点介绍,ITQ是目前工业界最常用、效果极好的一种线性哈希)。
- 核心痛点 :如果我们直接把PCA降维后的数据,通过取符号(大于0为1,小于0为0)变成0/1,这叫作硬量化,量化误差非常大。
- 基本思想 :在不改变原始数据相对位置的前提下,对PCA降维后的坐标轴进行旋转,让数据尽量贴合"超立方体(如三维空间中的正方体)"的顶点。
- 核心步骤 :
- 第一步(PCA降维):将高维特征降至c维( (V = XW) )。
- 第二步(迭代求解) :
- 固定旋转矩阵 (R),求最佳的二值编码 (B)(基于当前距离,取 (\text{sgn}(VR)))。
- 固定二值编码 (B),求最佳的旋转矩阵 (R)(此处用到了矩阵的SVD分解来算出新的 (R))。
- 第三步(交替循环) :不断重复上面的两步,逐步最小化量化误差(即最小化 (|B - VR|_F^2)),直到收敛。最终得到的 (B),就是一组误差最小的哈希码。
方法3:球面哈希(Spherical Hashing)
- (课件60-62页介绍的另一种思路)。
- 基本思想 :传统的哈希是用超平面 (如 (ax+by+c=0))来划分空间。而球面哈希改用超球面来划分空间。
- 核心优势:超球面在局部敏感性上比超平面更佳(只需一个超球面就能包围一个局部子空间,而超平面需要 D+1 个才能围成封闭空间)。
- 构建哈希函数:(h_k(x) = 1) 代表点落入该超球面内,否则为 (-1)。
- 关键约束条件 :为了让学习的哈希码具有区分度,球面哈希需要满足两个条件:
- 平衡性:落入球内和球外的样本各占一半( (o_i \approx n/2) )。
- 独立性 :任意两个超球面的交集部分(即两个球覆盖重叠的区域)面积应该为总样本的四分之一( (o_{i,j} \approx n/4) )。如果不满足,会计算一个排斥力(课件62页的 (f_i)),将球心推开。通过迭代使球心位置满足上述条件,即可得到哈希函数。
💡 考场提炼思路 :
这部分内容很多,考试如果出简答题,你需要抓住**【功能定位】**来答:
- 几何验证 :解决BoW匹配中**"空间位置错位"**的误匹配。RANSAC 计算精确但耗时,适合数量较少的精细匹配;空间编码通过快速位运算做绝对位置判断,适合大规模图像检索的快速几何过滤。
- 二值哈希 :解决大规模检索时**"存储大、浮点距离计算慢"的痛点。把高维浮点向量转为紧凑的二进制码,用 汉明距离(异或查表)**代替欧氏距离。LSH 是概率哈希(多表),ITQ 采用坐标旋转最小化量化误差(最常用),球面哈希则用超球面替代超平面来分割特征空间。
1,霍夫变换,说明如果灰度图像空间下有很多条直线,如何检测?写下思路
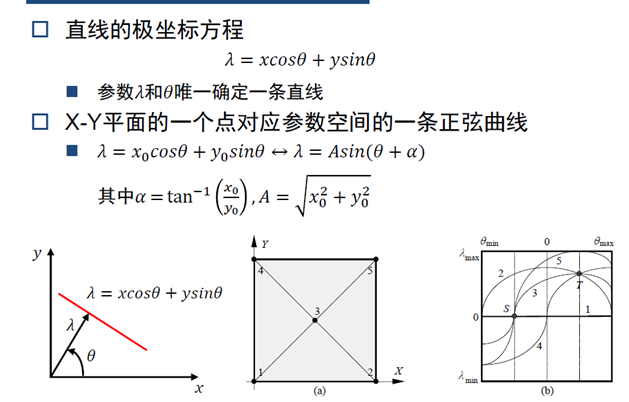
核心思想(点-线对偶性)
基于直线极坐标方程 (\lambda = x\cos\theta + y\sin\theta),将图像空间中的每一个点映射为参数空间(霍夫空间)中的一条正弦曲线。利用对偶性,将图像中"检测共线点"的问题转化为参数空间中"寻找曲线交点(峰值)"的问题。
检测思路与步骤:
- 边缘检测:首先对灰度图像进行边缘提取(如Canny算子),得到二值化的边缘点集合。
- 参数空间量化:构建以 ((\theta, \lambda)) 为坐标的二维累加器阵列(霍夫表),根据图像尺寸设置 (\theta) 和 (\lambda) 的取值范围。
- 投票累加 :遍历所有边缘点 ((x_i, y_i)),代入极坐标方程 λ=xicosθ+yisinθ\lambda = x_i\cos\theta + y_i\sin\thetaλ=xicosθ+yisinθ,遍历所有可能的 (\theta) 值,计算对应的 (\lambda),并在累加器相应位置进行"投票"加一。
- 寻找峰值 :扫描累加器阵列,找到局部极大值(峰值)。通过设置合适的阈值过滤掉伪直线,并对局部峰值进行非极大值抑制。
- 提取与绘制:累加器中的峰值点 ((\theta, \lambda)) 即对应图像空间中检测出的直线的参数,根据这些参数在原图上绘制出多条直线。
2. 图像检索常采用倒排表对数据库进行素引。解释倒排索引是如何实现高效的存储和快速检索索查询计算?
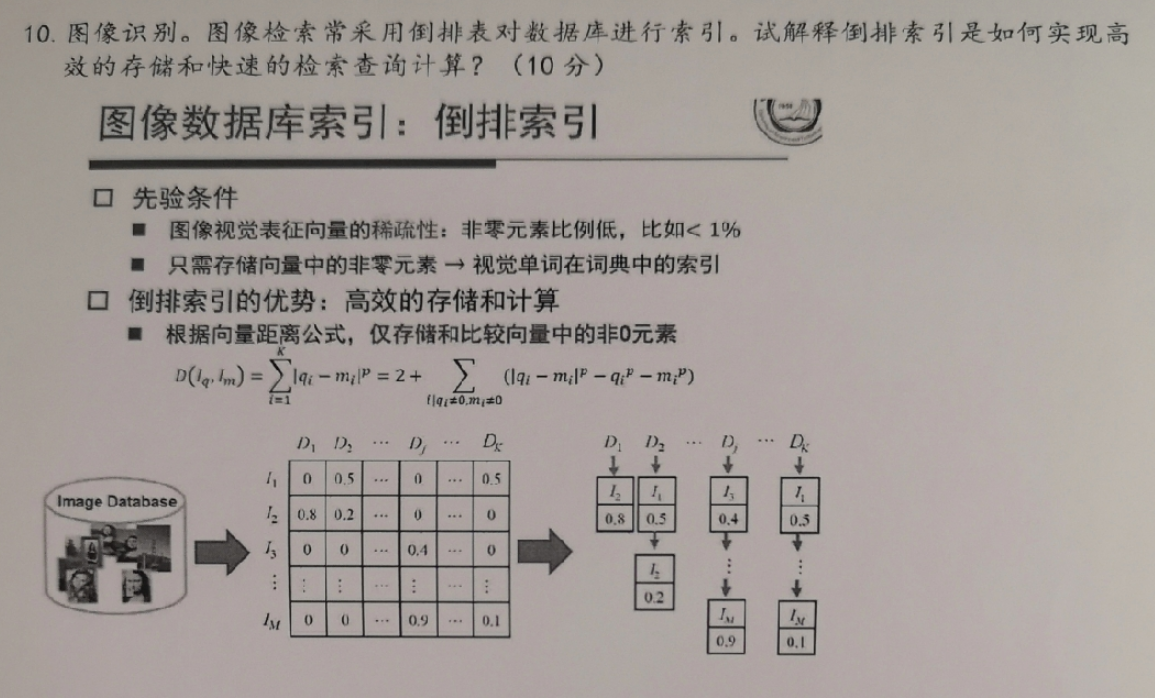
倒排索引能高效存储和快速检索,基于以下三点:
1. 基于稀疏性实现高效存储
图像的特征向量具有高度稀疏性(非零元素极低)。倒排表不记录全量向量,而是建立**"视觉单词ID → (包含该词的图像ID, 权值)"的倒排链表**,仅存储非零元素,极大节省空间。
2. 基于倒排表实现快速剪枝
检索时,只需提取查询图的非零单词 ,去倒排表中"捞"对应的链表。这直接跳过了数以百万计的无关图像,将待计算距离的候选集从全库缩小到极小范围。
3. 基于距离公式化简实现快速计算
利用L1归一化特性(向量各维度权重和为1),可将常规L1距离展开为倒排索引专用的交集公式 :
D(Iq,Im)=2+∑i∣qi≠0,mi≠0(∣qi−mi∣−qi−mi)\boxed{D(I_q, I_m) = 2 + \sum_{i|q_i \neq 0, m_i \neq 0} (|q_i - m_i| - q_i - m_i)}D(Iq,Im)=2+i∣qi=0,mi=0∑(∣qi−mi∣−qi−mi)
该公式表明:我们只需计算查询图和候选图"同时非零(交集)"的那几个维度,其余未重合的维度统一为常数2。这使计算复杂度从 (O(全库 \times 全维度)) 降至 (O(候选集 \times 交集维度))。
3.第一问,考椭圆经过霍夫变换后的形状。即以(x1,y1)(x_1,y_1)(x1,y1)为一个焦点坐标的所有椭圆,经过霍夫变换后(x2,y2,C)(x_2,y_2,C)(x2,y2,C)((x2,y2)(x_2,y_2)(x2,y2)是另一焦点坐标,C是焦距)的几何形状是什么?(此问版本答案为 圆台 )
第二问,一个圆盘,加上噪声,如何通过霍夫变换检测圆。图就是下面这个,步骤可按照底下标注来写(梯度取阈值后霍夫变换累加器,最后叠加显示)

第一问:给定一个椭圆焦点,经过霍夫变换后参数空间的形状
标准答案:
一个图像空间中的边缘点 ((x, y)),在给定椭圆一个焦点 (F_1(x_1, y_1)),且以另一焦点 ((x_2, y_2)) 和焦距相关参数(半长轴 (a) 或常数 (2a))为参数空间的霍夫变换中,会形成一个圆锥面(或圆台)。
简要推导理由:
设图像空间边缘点为 (P(x, y)),固定焦点为 (F_1(x_1, y_1))。根据椭圆定义,(P) 到两焦点的距离之和为常数 (2a),即:
∣PF1∣+∣PF2∣=2a⇒∣PF2∣=2a−∣PF1∣|PF_1| + |PF_2| = 2a \quad \Rightarrow \quad |PF_2| = 2a - |PF_1|∣PF1∣+∣PF2∣=2a⇒∣PF2∣=2a−∣PF1∣
其中 (|PF_1|) 为已知常数。因此,在以 ((x_2, y_2)) 和 (2a) 为轴的参数空间中,点 (P) 对应的轨迹正是以 ((x_1, y_1)) 为圆心、半径为 (2a - |PF_1|) 的圆 。随着参数 (2a) 的变化,这些圆在三维空间中拓展,形成圆锥面(受限于 (2a > |PF_1|) 的约束及图像空间范围,通常为截断的圆台)。
第二问:带噪声圆盘图像,如何通过霍夫变换检测圆(结合图a-d)
标准作答步骤(结合图片标注):
-
输入与预处理(图a):获取 256×256 灰度图像,图像中叠加了较强的随机噪声。这是霍夫变换面对的原始目标。
-
边缘检测与梯度计算(图b):
- 首先,利用Sobel算子对原图求一阶偏导,计算图像的梯度幅值 (G) 和梯度方向 (\theta)。
- 设定阈值,将梯度幅值较小的点滤除,得到二值化的边缘图像(图b)。虽然边缘可能断裂,且夹杂零星噪声,但真实圆周上的大部分点得以保留。
-
霍夫投票,生成累加器图(图c,核心降维步骤):
- 利用圆的一个重要几何性质:圆上任意点的梯度方向必定过圆心。
- 对图(b)中的每一个边缘像素点 ((x, y)),结合其梯度方向 (\theta),沿梯度方向(及反方向,以应对明暗圆差异)进行"投票"。
- 若已知半径 (R),则直接在二维累加器数组 ((a, b)) 中投下候选圆心票。若半径未知,则需在三维参数空间 ((a, b, R)) 中投出圆锥面。
- 遍历完所有边缘像素后,真实圆心位置会获得大量重叠的投票,在累加器图(图c)中形成高亮的白斑(峰值),而噪声点贡献的票数极低,仅形成杂散暗点。
-
峰值提取与过滤(图c至图d的桥梁):
- 在二维或三维累加器中,设置一个投票数最低阈值,去除虚假噪声产生的峰值。
- 利用非极大值抑制(NMS) ,在局部区域内寻找得票数最多的坐标,精准定位出真正的圆心 ((a, b)) 及对应的半径 (R)。
-
最终结果输出与叠加(图d):
- 根据定位到的圆心和半径,在**原始带噪图像(图a)**上叠加绘制出检测到的完整圆周。
- 得到图(d)。由于霍夫变换是全局投票机制,它天然具备极强的鲁棒性,能够有效克服图(a)中的强噪声干扰,成功检测出圆盘边界。
4.基于y=kx+b如何实现霍夫变换检测出来直线,有何缺点,以及替换霍夫变换的方法
1. 基于 (y = kx + b) 实现霍夫变换检测直线的基本原理
在图像空间((x-y) 平面)中,直线方程可写为 (y = kx + b)。
- 点-线对偶性:图像空间中的一个像素点 ((x_0, y_0)),对应到由参数 (k) 和 (b) 构成的**参数空间(霍夫空间)**中,是一条直线 (b = -x_0k + y_0)。
- 投票机制:遍历图像中的所有边缘点,每一条参数空间中的直线都会经过一个公共交点。通过构建一个二维累加器数组 (A(k,b)) 来统计交点的票数。
- 峰值检测:累加器数组 (A(k,b)) 中的**极大值(峰值)**所对应的 ((k, b)),就是原图像中检测出的那条直线的斜率与截距。
2. 该方法存在的严重缺点
- 无法检测垂直线:当原图中的直线垂直于 X 轴时,其斜率 (k) 将趋于无穷大(即 (k \to \infty)),无法用有限的数值表示。
- 参数空间无界:斜率 (k) 和截距 (b) 的取值范围都是无限的((-\\infty, +\\infty)),无法在计算机中预先构建一个具有明确上下界的有限累加器数组来进行投票统计。
3. 替换霍夫变换的方法
为了克服上述缺点,实际应用中通常替换为直线的极坐标方程(极坐标霍夫变换) :
λ=xcosθ+ysinθ\lambda = x \cos\theta + y \sin\thetaλ=xcosθ+ysinθ
- 为什么能替代:参数 (\theta) 代表直线的法线角度(取值范围限制在 (0 \sim 180^\circ)),参数 (\lambda) 代表原点到直线的垂直距离(取值范围限制在 (0 \sim) 图像对角线长度)。
- 优势 :此方法将参数空间限制在完全有限的范围内,且无论直线是水平、倾斜还是垂直,参数 (\theta) 和 (\lambda) 都能完美表示,彻底解决了 (y=kx+b) 无法表示垂直直线的缺陷。
5.目标检测(15)倒角距离变换检测给定形状(定义和复杂度;距离变换图;指定位置的chamfer distance计算), VJ人脸检测中利用了积分图提高效率,写出积分图基本思想
一、 倒角距离变换检测给定形状(约8分)
1. 定义与距离变换图
倒角距离变换(Chamfer Distance Transform)是一种将二值边缘图像转换为灰度图像 的过程。在该变换中,图像中每个像素点的值被赋为其到最近边缘点(特征点)的距离 。
生成的灰度图称为距离变换图(Distance Map)。
2. 计算复杂度
传统暴力计算复杂度极高(若模板点数为 (M),图像总点数为 (P),复杂度为 (O(MP)))。利用两遍扫描(前向扫描+后向扫描) 的倒角距离算法,可以将其计算复杂度显著降低至 (O(M \times N))(即与图像总像素数呈线性关系)。
3. 指定位置的倒角距离(Chamfer Distance)计算
设模板形状(点集)为 (T),待匹配的边缘图像的距离变换图为 (DT)。
在图像位置 (x) 处放置模板中心,模板与边缘图像的**匹配代价(倒角距离)**计算公式为(对应课件第26页):
Dchamfer(x)=1∣T∣∑t∈TDT(t+x)D_{\text{chamfer}}(x) = \frac{1}{|T|} \sum_{t \in T} DT(t + x)Dchamfer(x)=∣T∣1∑t∈TDT(t+x)
- 物理意义 :将模板中心置于位置 (x),将模板中的每一个点 (t) 映射到距离变换图中,取出对应的距离值 DT(t+x)DT(t+x)DT(t+x),将所有距离值求和并除以模板点数 (|T|) 做归一化。
- 匹配判定 :计算出的 Dchamfer(x)D_{\text{chamfer}}(x)Dchamfer(x) 越小,表明模板与当前位置的边缘越吻合。
二、 VJ人脸检测中积分图的基本思想(约7分)
VJ人脸检测算法需要计算大量的 Haar-like 矩形特征,如果用传统方法逐像素累加极其缓慢。积分图(Integral Image)是 VJ 算法实现实时人脸检测的核心加速机制。
1. 积分图的基本定义
设原始图像为 (I(x,y)),积分图 (ii(x,y)) 定义为:从图像左上角 ((0,0)) 到当前位置 ((x,y)) 所形成的矩形区域内,所有像素值的总和 。
其递推计算(构建)公式为:
ii(x,y)=i(x,y)+ii(x−1,y)+ii(x,y−1)−ii(x−1,y−1)ii(x,y) = i(x,y) + ii(x-1,y) + ii(x,y-1) - ii(x-1,y-1)ii(x,y)=i(x,y)+ii(x−1,y)+ii(x,y−1)−ii(x−1,y−1)
2. 如何实现快速矩形区域求和(核心思想)
通过积分图,任意一个矩形区域内的像素和仅需一次加法和两次减法(共 3 次运算)即可在 (O(1)) 的常数时间内求出 ,与矩形区域的大小无关 。
设图中左上角坐标为 ((x_1, y_1)),右下角坐标为 ((x_2, y_2)) 的矩形,其内部像素和 (S) 的计算公式为:
S=ii(x2,y2)−ii(x1−1,y2)−ii(x2,y1−1)+ii(x1−1,y1−1)S = ii(x_2, y_2) - ii(x_1 - 1, y_2) - ii(x_2, y_1 - 1) + ii(x_1 - 1, y_1 - 1)S=ii(x2,y2)−ii(x1−1,y2)−ii(x2,y1−1)+ii(x1−1,y1−1)
3. 效率提升的总结
在 VJ 算法中,需要在一个检测窗口内穷举数千甚至上万个不同大小、不同位置的 Haar 特征。积分图将这些需要大量循环累加的特征计算,全部转变为了常数时间 (O(1)) 的查表和简单四则运算。这保证了 VJ 算法能够在当时的硬件条件下实现实时人脸检测(每秒处理数十帧)。
6. Chamfer distance 第一问,给出如下类似左图的一张图,让你在图上的白格子上直接计算距离,即弄成右图的形式。
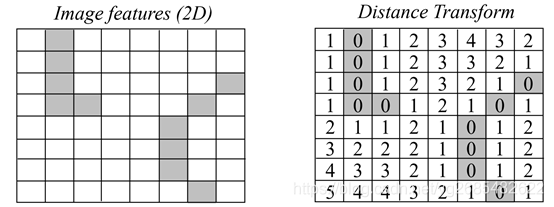
第二问,给出一个下面的模板(下左图),并告诉你模板中心在图中的什么位置(如下右图 五角星处),然后计算此时的chamfer distance。
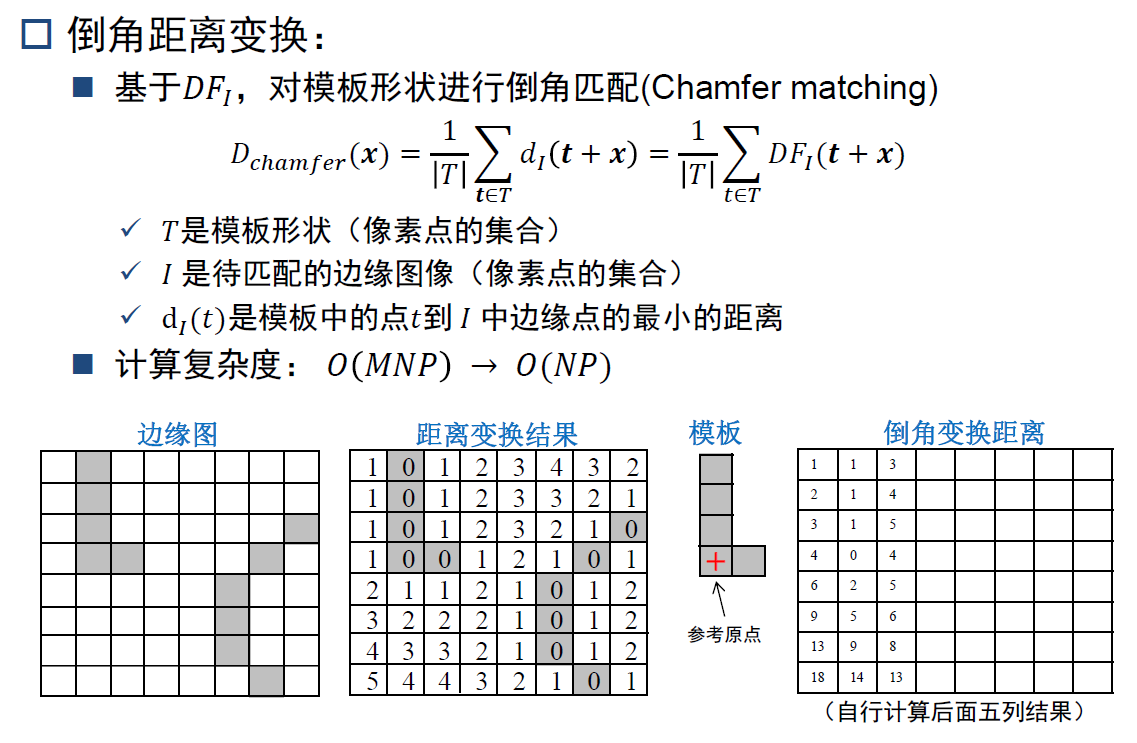
倒角距离变换就是把模板放进去,然后再距离变换结果里面查表,然后把模板各个各自的值求和,就表示为这个参考原点所在位置的倒角变换距离
7. 求共生矩阵以及chanmfer distanc
第一部分:灰度共生矩阵(GLCM)
考题类型 :给你一个 (3\times3) 或 (4\times4) 的小灰度图像矩阵,再指定一个偏移量(如 ((1,0)) 或 ((1,1))) ,让你计算其灰度共生矩阵,并可能要求计算某种纹理特征。
-
什么是灰度共生矩阵?
它通过统计图像中特定空间关系 (偏移量)下,两个灰度级共同出现的频数,来反映图像纹理的粗糙度、方向性等信息。举个例子:如果图像左右相邻像素的灰度值通常相同,那么共生矩阵对角线上的数值就会很大。
-
具体手工计算步骤(考试标准流程)
第一步:确定灰度级 (L)(极其关键!)
如果原图有 256 个灰度级,计算出来的矩阵将是 (256\times256),极其庞大。考卷上通常会指定灰度级量化(Bin) 。如果没有指定,一般需要将灰度级压缩到 8 级(0~7)或 4 级(0~3)。
- 例如 :原图灰度值范围是 0~15,考卷压缩为 4 级(0~3)。那么原图灰度值为
0,1,2,3映射为0;4,5,6,7映射为1,以此类推。
第二步:确定偏移量 (d = (dx, dy))
题目会指定统计方向。例如:
(1,0):统计水平向右邻居的关系。(0,1):统计垂直向下邻居的关系。(1,1):统计右下对角线邻居的关系。
第三步:遍历像素,填表(矩阵大小固定为 (L \times L))
假设压缩后灰度级为 4,那么共生矩阵是一个 (4\times4) 的空表格(初始为0)。
遍历量化后的图像中的每一个像素。对于当前坐标 ((x,y)) 的灰度值 (i),查看坐标为 ((x+dx, y+dy)) 的邻居像素的灰度值 (j)。
- 如果像素和邻居在图片范围内,则在表格的第 (i) 行,第 (j) 列的位置加 1。
第四步:处理归一化或对称性问题
- 非对称性:从 ((x,y)) 到 ((x+dx,y+dy))。
- 对称性 :很多时候为了减少计算量,不仅看 (i\to j),还要看 (j\to i),视为整体。不过考试通常只考单向遍历,直接累加即可。
第二部分:倒角距离(Chamfer Distance)
考题类型 :给你一张二值边缘图(左图),让你计算其距离变换图(右图);再给你一个目标形状模板(方向、锚点),让你计算该模板放在某个位置时,匹配的倒角距离得分。
- 核心计算步骤(考试直接套公式)
第一层:计算距离变换图(Distance Transform Map)
- 考试题会像你之前提供的PPT图片那样,给出二值边缘图像(带灰色格子)。
- 手工直接算 :对于图上每一个空白格子,找到离它最近的灰色格子(棋盘距离 (D_8)),数它们之间的行差和列差,取最大值作为该格子的数值填进去。
- (注:计算机通过两次扫描实现,考试手算直接找最近点即可,无需模拟前后扫描。)
第二层:利用模板匹配,计算倒角距离得分(Chamfer Matching)
拿到第一层算好的距离变换图后:
- 确定模板锚点 :看题目给的模板小图,确定红色十字/参考原点的位置。
- 列出相对偏移量 :写出模板中所有黑色像素相对于锚点的坐标偏移量(行偏移,列偏移)。
- 定位绝对坐标 :将锚点移到考题要求的目标位置(如"五角星"处),把模板上每一个黑色像素的相对偏移量 与锚点的绝对坐标相加,得到在实际距离变换图中的绝对坐标。
- 查表与求平均(或求和) :去第一层算好的距离变换图中,查找这几个绝对坐标对应的数值,全部加起来,并除以模板黑色像素的总个数。
- 得最终结果 :得出的结果就是该位置模板与边缘的倒角匹配距离。分数越小,说明匹配越好(完美匹配时距离为0)。
第八章 概率图模型
概率有向图模型和概率无向图模型
一、 概率有向图模型(贝叶斯网络)
有向图使用有向边(箭头)表示随机变量之间的因果关系。
- 因子分解(Factorization)
概率有向图表示联合概率分布可以分解为图中每个节点在其父节点给定时的条件分布的乘积 (课件第8页)。
p(x)=∏i=1Np(xi∣pai)p(x) = \prod_{i=1}^{N} p(x_i | \text{pa}_i)p(x)=∏i=1Np(xi∣pai)
- 其中 pai\text{pa}_ipai 为结点 (x_i) 的父结点集合。
- 物理意义:这种分解极大地降低了参数数量。例如在马尔可夫链(课件第9页)中,联合分布由 (K^N) 级参数降为 (K^2) 级。
- 注意:有向图必须是有向无环图(DAG)。
- 条件独立性(D-separation,有向分离)
在有向图中,我们可以通过三种典型连接结构快速判定独立性(课件第12-14页):
- tail-to-tail(共父结构) a←c→ba \leftarrow c \rightarrow ba←c→b:若观测到 (c),则 (a) 和 (b) 独立。
- head-to-tail(链式结构) a→c→ba \rightarrow c \rightarrow ba→c→b:若观测到 (c),则 (a) 和 (b) 独立。
- head-to-head(V型结构) a→c←ba \rightarrow c \leftarrow ba→c←b :这是考试最大的坑 。若未观测到 (c)(及其任何后代),则 (a) 和 (b) 是独立 的;一旦观测到 (c) 或其任何一个后代,原本独立的 (a) 和 (b) 就会变得依赖。
- D-separation 通用规则(课件第13页) :如果两个节点之间的所有路径都被集合 (C) 阻隔(阻隔条件分别为上述三种结构),则它们满足 A ⊥ B | C。
- 有向图的马尔可夫毯(Markov Blanket)
一个结点的马尔可夫毯是使该结点与图中所有其他结点独立 所需要观测到的最小结点集合(课件第15页)。
- 构成 :在有向图中,节点 (x_i) 的马尔可夫毯包含:父结点、子结点、以及子结点的其他所有父结点(即共同父结点/Co-parents)。
- (解释为什么需要共同父节点:因为存在 V 型结构。即使看住了父节点和子节点,如果子节点的共同父节点未观测到,它们依然会通过 V 型结构产生依赖。)
二、 概率无向图模型(马尔可夫随机场 - MRF)
无向图使用无向边 表示变量间的相互作用与约束关系(常用于图像去噪、分割等没有明确因果关系的场景)。
- 因子分解(Factorization)
无向图不能像有向图那样直接用条件概率归一化。利用 Hammersley-Clifford 定理 ,联合概率分布可分解为最大团上的势函数的乘积。
- 团(Clique):图中任意两个结点均有边连接的结点子集(课件第17页)。
- 最大团(Maximal Clique):无法再加入任何一个结点仍保持团性质的团。
- 数学表达 (课件第18页):
P(Y)=1Z∏CψC(YC)P(Y) = \frac{1}{Z} \prod_{C} \psi_C(Y_C)P(Y)=Z1∏CψC(YC)
其中:- (\psi_C(Y_C)) 是势函数,通常取指数形式 (\psi_C(Y_C) = \exp{-E(Y_C)})(课件第19页),即玻尔兹曼分布。
- (Z) 是划分函数(归一化因子) ,用于保证概率和为1。(注意:划分函数 (Z) 的计算复杂度是指数级的,是无向图学习和推断最大的难点所在!)
- 条件独立性(图分离)
无向图的条件独立性非常直观,利用**"图物理切断(分离)"**判定(课件第20-21页)。
- 成对马尔可夫性 :给定其他所有变量,任意两个没有边连接的结点 (u, v) 条件独立。
- 局部马尔可夫性 :给定结点 (v) 的所有直接邻居 (W),结点 (v) 与图中所有其他节点 (O) 条件独立。
- 全局马尔可夫性 :若结点集合 (A, B) 被结点集合 (C) 物理分开,则给定 (C) 时,(A) 和 (B) 条件独立。即只要通过切断节点集合 (C) 就能阻断 (A) 到 (B) 的所有通路。
- 无向图的马尔可夫毯
- 构成 :在无向图模型中,结点 (v) 的马尔可夫毯就是所有与 (v) 有边相连的邻居集合。(非常简单粗暴,远亲不如近邻)。
💡 考试必背对比总结表(精准区分两者)
| 对比维度 | 有向图模型(贝叶斯网络) | 无向图模型(马尔可夫随机场) |
|---|---|---|
| 边含义 | 因果关系(箭头表示条件概率) | 相互作用/约束(无箭头表示势能约束) |
| 联合概率(因子分解) | (P(x) = \prod P(x_i \mid \text{pa}_i)) (节点父条件概率直接相乘) | (P(Y) = \frac{1}{Z} \prod_{C} \psi_C(Y_C)) (最大团的势函数指数相乘,归一化) |
| 条件独立判定 | D-separation (三种连接结构); 注意 V 型(head-to-head)结构的"反直觉"激活 | 图分离(物理切割) ; 集合 A、B 被集合 C 分隔开即可 |
| 马尔可夫毯 | 父结点 + 子结点 + 共同父结点 (复杂,需堵住 V 型依赖关系) | 所有直接相邻的邻居结点 (非常简单) |
| 推理计算复杂度 | 局部条件概率,计算相对容易 | 划分函数 (Z) 的计算是指数级的,极为困难 |
💡 考场答题小贴士:
- 如果考卷问"马尔可夫毯 "并把两种图混在一起考,请务必分图作答。有向图写"父+子+共同父",无向图写"所有邻居"。
- 看到 D-separation 题目,立刻在草稿纸上画图判断三种结构。谨记 V型结构(两个箭头指向同一个节点) 的特殊性:不观测中间节点时独立,观测了反而不独立!
- 在描述无向图的势函数时,写出 (\psi_C(Y_C) = \exp{-E(Y_C)}) 及 划分函数 (Z) 的指数运算特性,往往能拿到额外的推导分。
1,条件随机场,基于维特比算法,计算最大的输出序列。跟ppt如下图的上的例子差不多,改了随机矩阵的数字。


2. 概率图模型,马尔科夫毯和条件独立的推断(10),给一个图,有向无环图,然后给你一个节点,让你求与它相关的马尔科夫毯节点,然后问其余的节点如何保存独立性(证明),
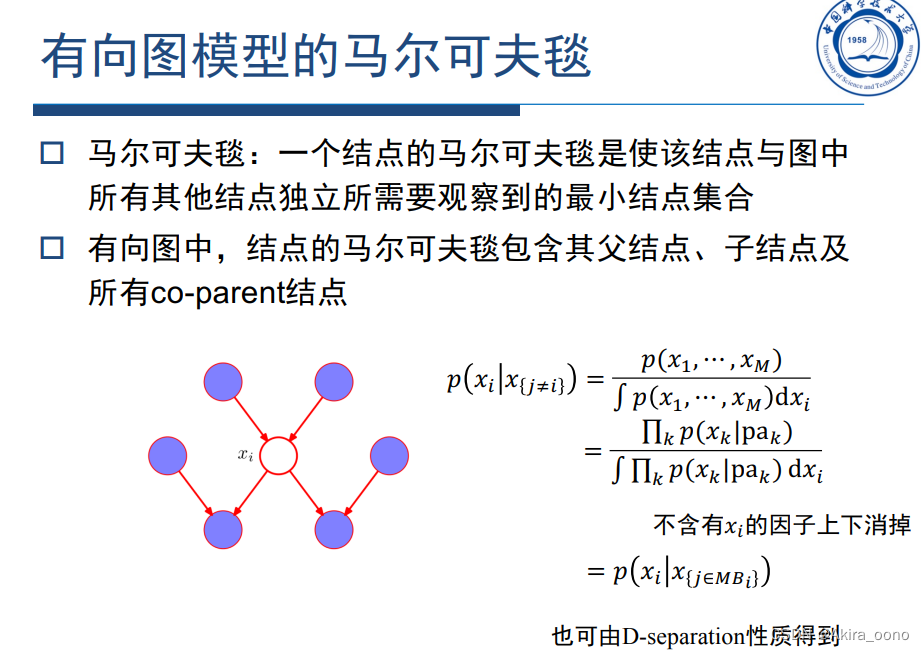
问题:给定一个有向无环图,求节点 (X) 的马尔可夫毯节点,并证明其余节点保持独立性。
(1)求马尔可夫毯节点(3分):
根据有向图马尔可夫毯的定义,节点 (X) 的马尔可夫毯 (MB(X)) 需要包含三类节点:
- (X) 的所有父节点(箭头指向 (X) 的节点);
- (X) 的所有子节点(箭头从 (X) 出发的节点);
- (X) 的所有配偶节点(与 (X) 共同指向同一个子节点的节点)。
- (直接在图上画出,写出集合即可) (MB(X) = { \dots })。
(2)证明条件独立性(7分): (暂时就还是记忆PPT那个公式)证明过程如下:
- 根据有向图模型的全局因子分解性质,联合概率可写为:
p(X1,...,XN)=∏i=1Np(Xi∣pai) p(X_1, \dots, X_N) = \prod_{i=1}^{N} p(X_i \mid \text{pa}_i) p(X1,...,XN)=i=1∏Np(Xi∣pai)- 考虑节点 (X) 在给定所有其他节点时的条件概率:
p(X∣其余)∝∏i=1Np(Xi∣pai) p(X \mid \text{其余}) \propto \prod_{i=1}^{N} p(X_i \mid \text{pa}_i) p(X∣其余)∝i=1∏Np(Xi∣pai)- 在连乘中,只有包含 (X) 的项才会影响推导结果。包含 (X) 的项正好只有两类:(X) 自身的条件概率 (p(X \mid \text{pa}(X))),以及 (X) 的所有子节点的条件概率 (\prod p(Y \mid \text{pa}(Y)))。
- 因此,化简可得:
p(X∣其余)∝p(X∣pa(X))∏Y∈Child(X)p(Y∣pa(Y)) p(X \mid \text{其余}) \propto p(X \mid \text{pa}(X)) \prod_{Y \in \text{Child}(X)} p(Y \mid \text{pa}(Y)) p(X∣其余)∝p(X∣pa(X))Y∈Child(X)∏p(Y∣pa(Y))- 观察等式右边的变量集合,正好等同于第一步求出的马尔可夫毯 (MB(X))。
- 所以有 (p(X \mid \text{其余}) = p(X \mid MB(X))),即当给定马尔可夫毯后,其余节点与 (X) 条件独立,证明成立。
第九章 运动分析
穷举块匹配和层级块匹配
🎯 穷举块匹配算法 (MBMA / FSBM)
MBMA,通常更被称为全搜索块匹配 (Full Search Block Matching, FSBM) 。它的核心思想非常简单直接:在预先设定的搜索窗口内,遍历所有可能的候选位置,逐一计算匹配代价,并从中选出代价最小的一个作为最终的运动矢量。
-
优点:
- 理论上最佳 :因为是全局搜索,所以能找到搜索窗口内的全局最优解,运动估计的精度最高。
- 结构规整:数据存取和计算流程规则,非常适合并行处理和硬件实现。
-
缺点:
- 计算量巨大 :这是它最主要的缺陷。假设搜索范围为
[-p, p],则每个块需要比较(2p+1)²个位置,计算量随搜索范围呈平方级增长,极其耗时。这一瓶颈也催生了众多旨在降低计算复杂度的快速算法。
- 计算量巨大 :这是它最主要的缺陷。假设搜索范围为
🪜 层级块匹配算法 (HBMA)
HBMA的核心思想是"由粗到细,逐级精炼",通过构建图像金字塔来大幅减少计算量。
其基本步骤如下:
- 构建金字塔:对当前帧和参考帧分别进行下采样,构建多级分辨率逐渐降低的图像金字塔。最顶层图像最小,底层是原始图像。
- 顶层粗搜索:从金字塔最顶层开始,在小图像上进行块匹配。由于图像小,搜索范围也随之减小,可快速得到一个粗略的运动矢量。
- 逐级细化 :将上一级得到的运动矢量作为下一级搜索的初始值 。在下一级(分辨率更高)中,只在这个初始值附近的一个小范围内进行精细搜索,不断修正运动矢量。
- 到达底层:重复上述过程,直到最底层(原始分辨率),得到最终精确的运动矢量。
-
优点:
- 计算效率高:通过由粗到细的策略,避免了在原始图像上进行大范围的穷举搜索,显著降低了计算量。
- 能估计大运动:在低分辨率的顶层,小运动在缩小的图像上会被"放大",使得算法能有效地估计出较大的运动矢量。
- 多分辨率也能估计小运动
-
缺点:
- 可能陷入局部最优:如果顶层估计的初始运动矢量不准确,后续的细化过程可能会在错误的路径上寻找,最终得到的是局部最优解而非全局最优解。
- 实现更复杂:需要构建图像金字塔,并管理不同层级间的数据传递,实现复杂度高于全搜索。
⚖️ 核心差异速览
| 特征 | 穷举块匹配算法 (MBMA/FSBM) | 层级块匹配算法 (HBMA) |
|---|---|---|
| 搜索策略 | 全局穷举搜索 | 由粗到细的层级搜索 |
| 计算复杂度 | 极高,随搜索范围平方增长 | 较低,大幅减少计算量 |
| 运动矢量精度 | 高,全局最优 | 较高,但可能陷入局部最优 |
| 实现复杂度 | 低,结构规整 | 较高,需构建图像金字塔 |
1,推到光流方程,并说明二义性:
即假设在恒定亮度条件下,泰勒展开;


结合课件内容及考试简答题的规范,答案整理如下:
一、光流方程的推导
- 基础假设 :基于恒定亮度假设,即同一像素点在不同时刻的亮度保持不变,表示为:(\psi(x+d_x, y+d_y, t+d_t) = \psi(x, y, t))。
- 泰勒展开 :将左侧函数在位置 ((x, y, t)) 处进行一阶泰勒级数展开,得到:
(\psi(x+d_x, y+d_y, t+d_t) = \psi(x, y, t) + \frac{\partial \psi}{\partial x}d_x + \frac{\partial \psi}{\partial y}d_y + \frac{\partial \psi}{\partial t}d_t) - 对比与化简 :将展开式代入恒定亮度假设等式,两边消去 (\psi(x, y, t)),并除以时间变化量 (d_t),得到:
(\frac{\partial \psi}{\partial x} \frac{d_x}{d_t} + \frac{\partial \psi}{\partial y} \frac{d_y}{d_t} + \frac{\partial \psi}{\partial t} = 0) - 向量表达 :令图像空间梯度 (\nabla \psi = \\frac{\\partial \\psi}{\\partial x}, \\frac{\\partial \\psi}{\\partial y}^T),像素运动速度 (v = v_x, v_y^T),则最终光流方程为:
∇ψTv+∂ψ∂t=0\nabla \psi^T v + \frac{\partial \psi}{\partial t} = 0∇ψTv+∂t∂ψ=0
二、光流估计的二义性
- 根本原因(方程欠定) :光流方程为一个方程,包含 (v_x) 和 (v_y) 两个未知数,是欠定方程组。仅凭此方程无法求出唯一的速度矢量((v_x, v_y))。
- 几何解释(孔径问题) :将速度矢量分解为沿梯度方向的法向分量 (v_n) 和垂直于梯度的切向分量 (v_t)(即 (v = v_n e_n + v_t e_t))。光流方程只包含沿梯度 (v_n) 方向的流向量 ,而切线方向 (v_t) 的流向量在数学上是未定义的(无法被方程解出)。
- 特殊区域失效 :在平坦纹理区域 ,由于图像局部灰度不发生显著变化,空间梯度 (\nabla \psi = 0)。此时光流方程为 (\frac{\partial \psi}{\partial t} = 0),光流是完全不确定的。
- 结论 :在平坦区域,运动估计不可靠;而在靠近边缘的区域(梯度 (\nabla \psi) 较大),光流估计更可靠,但仍只能准确计算出垂直于边缘的速度分量。
2. 运动分析一相机运动建模。考虑一个摄像机顺序地进行跟、吊、摇、倾、变焦、旋转运动,并低设成像模型为小孔我像模型,请网答最少需要多少个参数可以描述上述运动?
《请给出详细证明过程)(13分)

题目答案:最少需要 4个参数 来描述上述相机运动。
1. 基础模型:针孔相机透视投影
由课件第5页可知,在针孔相机模型下,三维空间点 ((X,Y,Z)) 投影到图像平面 ((x,y)) 的关系为:
x=FXZ,y=FYZx = F\frac{X}{Z},\quad y = F\frac{Y}{Z}x=FZX,y=FZY
2. 分析六种相机运动的二维映射
课件第13-15页给出了独立相机运动的二维位移场模型(假设运动较小且场景深度 (Z) 近似恒定):
- 跟(Track)与吊(Boom):相机沿X、Y轴平移。产生全局平移量 ((t_x, t_y)),其中 (t_x = \frac{FT_x}{Z}, t_y = \frac{FT_y}{Z})。
- 摇(Pan)与倾(Tilt):相机绕Y、X轴旋转。结合一阶近似(小角度),其在图像平面上引入的近似平移量为 ((\theta_y F, -\theta_x F))。
- 变焦(Zoom) :焦距 (F) 改变,对应图像平面的各向同性缩放,缩放系数设为 (\rho)(即 (\rho = F'/F))。
- 滚(Roll) :相机绕Z轴旋转,对应图像平面绕原点的平面旋转变换,角度为 (\theta_z)。
3. 合并推导出4参数模型(课件第17页核心)
当一个摄像机顺序 进行了上述全部运动后,在图像平面上的坐标映射 ( (x, y) \to (x', y') ) 可以表示为:
x′y′\]=ρ\[cosθz−sinθzsinθzcosθz\]\[x+θyF+txy−θxF+ty\]\\begin{bmatrix} x' \\\\ y' \\end{bmatrix} = \\rho \\begin{bmatrix} \\cos\\theta_z \& -\\sin\\theta_z \\\\ \\sin\\theta_z \& \\cos\\theta_z \\end{bmatrix} \\begin{bmatrix} x + \\theta_y F + t_x \\\\ y - \\theta_x F + t_y \\end{bmatrix}\[x′y′\]=ρ\[cosθzsinθz−sinθzcosθz\]\[x+θyF+txy−θxF+ty
将上述参数代回,即可得到一个极其紧凑的4参数线性映射关系 (这正是PPT第17页的最终公式):
x′y′\]=\[c1−c2c2c1\]\[xy\]+\[c3c4\]\\begin{bmatrix} x' \\\\ y' \\end{bmatrix} = \\begin{bmatrix} c_1 \& -c_2 \\\\ c_2 \& c_1 \\end{bmatrix} \\begin{bmatrix} x \\\\ y \\end{bmatrix} + \\begin{bmatrix} c_3 \\\\ c_4 \\end{bmatrix}\[x′y′\]=\[c1c2−c2c1\]\[xy\]+\[c3c4
3. 穷举块匹配法的缺点(至少四点)


穷举块匹配法(Exhaustive Block Matching Algorithm,EBMA)是视频编码和运动估计中最基础、最直观的方法。其核心思想是:在当前帧的某个搜索窗口内,逐个像素位置地计算候选块与参考块之间的匹配误差(如SAD、SSD),选择误差最小的位置作为最佳运动矢量。
尽管原理简单、易于实现,但穷举块匹配法在实际应用中存在以下四个主要缺点:
1. 计算复杂度极高,实时性差
- 问题本质:假设搜索窗口大小为 (-p, p)(即水平和垂直方向各搜索 (2p+1) 个位置),对于一个 (N \times N) 的宏块,需要计算 ((2p+1)^2) 次匹配运算。每次匹配运算需要对 (N^2) 个像素进行差值计算。总计算量为 (O(N^2 \times (2p+1)^2))。
- 案例说明:在H.264/AVC标准中,一个16x16的宏块,若搜索范围为±32像素,则需计算 ((2*32+1)^2 = 4225) 次16x16块的SAD运算。对于高清(1920x1080)视频,一帧就有8100个宏块,计算量巨大,难以满足实时编码需求。
2. 易陷入局部最优,对复杂运动模式捕捉能力弱
- 问题本质 :该方法假设块内所有像素做纯平移运动。对于旋转、缩放、仿射变换等非平移运动,以及存在遮挡、形变的区域,穷举法找到的"最小误差点"可能只是一个局部最优解,而非真实的全局运动。
- 案例说明:当物体同时存在平移和旋转时(如车轮滚动),穷举法找到的最佳匹配块可能与参考块在像素级别上差异最小,但该运动矢量并不能反映真实的旋转分量,导致重建帧出现模糊或块效应。
3. 对搜索范围敏感,大范围运动估计性能下降
- 问题本质:搜索范围 (p) 需要预先设定。若 (p) 设置过小,无法捕捉快速或大位移运动;若 (p) 设置过大,计算量呈平方增长,且噪声干扰会更明显。
- 案例说明:在体育视频(如足球比赛)中,摄像机快速摇移会导致场景整体发生大位移。若搜索范围不足,则无法找到正确的匹配块,运动矢量会错误地指向搜索窗口内的某个局部相似区域,造成预测残差增大,压缩效率降低。
4. 对噪声和光照变化敏感
- 问题本质:匹配准则(如SAD、SSD)直接基于像素灰度值的绝对差异。当视频存在椒盐噪声、高斯噪声,或发生全局/局部光照变化时,像素值会发生非运动引起的改变,导致匹配误差计算失真。
- 案例说明:在监控视频中,若某区域突然变亮(如车灯照射),即使物体静止,该区域的像素值也会剧烈变化。穷举法会误认为找不到好的匹配块,从而产生错误的运动矢量或较大的残差,影响编码质量和后续运动分析。
改进方向:为了克服上述缺点,后续发展出了多种快速块匹配算法(如三步搜索TSS、菱形搜索DS、自适应运动搜索)和更先进的运动估计技术(如可变块大小运动估计、亚像素精度运动估计、基于仿射/透视模型的运动估计),在保证估计精度的同时,大幅降低了计算复杂度。
4. 运动分析的四大准则,以及四大准则之间的联系
一、 运动分析的四大准则
在运动估计中,通常采用以下四种优化准则来求解运动参数:
1. 基于位移帧差准则(DFD Criterion)
使锚帧与目标帧之间对应像素的亮度差值最小化。
目标函数: EDFD=∑x∣ψ2(x+d)−ψ1(x)∣p→minE_{\text{DFD}} = \sum_{x} |\psi_2(\mathbf{x} + \mathbf{d}) - \psi_1(\mathbf{x})|^p \to \minEDFD=∑x∣ψ2(x+d)−ψ1(x)∣p→min。(当 (p=1) 时对应平均绝对差 MAD,当 (p=2) 时对应均方误差 MSE)。
2. 基于光流方程准则(OF Criterion)
利用泰勒级数展开,假设相邻帧间运动较小,用图像的空间梯度与运动矢量的点积来近似帧差。
目标函数:Eflow=∑x∣∇ψ1(x)Td+ψ2(x)−ψ1(x)∣p→minE_{\text{flow}} = \sum_{x} | \nabla \psi_1(\mathbf{x})^T \mathbf{d} + \psi_2(\mathbf{x}) - \psi_1(\mathbf{x}) |^p \to \minEflow=∑x∣∇ψ1(x)Td+ψ2(x)−ψ1(x)∣p→min。
3. 正则化准则(平滑约束准则)
引入额外的平滑项约束,防止运动场产生局部剧烈突变(如噪声导致的错误匹配)。
目标函数:( E_s = \sum_{x} \sum_{y \in N_x} |\mathbf{d}(\mathbf{x}) - \mathbf{d}(\mathbf{y})|^2 ),最终目标常表示为加权求和: ( w_{\text{DFD}} E_{\text{DFD}} + w_s E_s \to \min )。
4. 贝叶斯准则(Bayesian Criterion)
将运动估计视为概率推理问题,即最大化运动矢量的后验概率 (P(D = \mathbf{d}|\Psi = \psi_2; \psi_1))。通过最大化后验概率(MAP)来求解最优运动矢量。
二、 四大准则之间的联系
四大准则并非孤立,它们在数学和应用上存在紧密的内在联系:
-
光流(OF)与位移帧差(DFD)的关系:
- OF准则基于小运动假设 ,它是泰勒展开的一阶线性近似,适用于运动较小的情况。
- 当运动较大 时,线性近似失效,必须应用DFD准则进行直接匹配。
-
正则化准则与DFD/OF准则的联系:
- DFD 或 OF 准则单独使用时,通常会因局部纹理单一(孔径问题)或噪声干扰导致运动场错乱。
- 引入**平滑约束(正则化)**后,可以在保持数据保真度(DFD/OF误差最小)的同时,强制邻域运动矢量趋于一致。
-
贝叶斯准则与DFD+正则化准则的等效关系(核心考点):
- 课件第34页明确指出:基于贝叶斯准则的运动估计,可以被简化为具有适当平滑约束的基于DFD的估计。
- 数学本质 :最大化后验概率 (P(D|\psi)) 等价于最小化 (-\log P(D|\psi))。其中,似然项 (P(\psi|D)) 取负对数后等价于DFD或OF误差项 ;先验项 (P(D)) 取负对数后等价于正则化(平滑)约束项。
- 结论:贝叶斯框架在理论上统一了"数据保真(DFD/OF)"与"平滑约束(正则化)"。
5.基于灰度不变假设,推导二维光流方程; 光流方程在什么情况下不能确定(二义性的部分)
第一问:基于灰度不变假设,推导二维光流方程
标准作答步骤:
-
恒定亮度假设(Constant Intensity Assumption)
设图像中某像素点在 (t) 时刻的亮度为 (\psi(x, y, t))。假设该像素点在 (t+dt) 时刻运动到 ((x+d_x, y+d_y)),其亮度保持不变。数学表达为:
ψ(x+dx,y+dy,t+dt)=ψ(x,y,t)\psi(x+d_x, y+d_y, t+d_t) = \psi(x, y, t)ψ(x+dx,y+dy,t+dt)=ψ(x,y,t)
-
一阶泰勒展开
将等式左边的函数在 ((x,y,t)) 处进行一阶泰勒级数展开:
ψ(x+dx,y+dy,t+dt)=ψ(x,y,t)+∂ψ∂xdx+∂ψ∂ydy+∂ψ∂tdt+ϵ\psi(x+d_x, y+d_y, t+d_t) = \psi(x, y, t) + \frac{\partial \psi}{\partial x} d_x + \frac{\partial \psi}{\partial y} d_y + \frac{\partial \psi}{\partial t} d_t + \epsilonψ(x+dx,y+dy,t+dt)=ψ(x,y,t)+∂x∂ψdx+∂y∂ψdy+∂t∂ψdt+ϵ
(其中 (\epsilon) 为高阶无穷小,忽略不计)。
-
对比并化简
将展开式代入恒定亮度假设等式中,等式两边消去 (\psi(x,y,t)),得到:
∂ψ∂xdx+∂ψ∂ydy+∂ψ∂tdt=0\frac{\partial \psi}{\partial x} d_x + \frac{\partial \psi}{\partial y} d_y + \frac{\partial \psi}{\partial t} d_t = 0∂x∂ψdx+∂y∂ψdy+∂t∂ψdt=0
-
推导光流方程
等式两边同时除以时间变化量 (d_t),并令 (v_x = \frac{d_x}{d_t}), (v_y = \frac{d_y}{d_t}) 分别表示像素在 X 方向和 Y 方向的速度分量,得到:
∂ψ∂xvx+∂ψ∂yvy+∂ψ∂t=0\frac{\partial \psi}{\partial x} v_x + \frac{\partial \psi}{\partial y} v_y + \frac{\partial \psi}{\partial t} = 0∂x∂ψvx+∂y∂ψvy+∂t∂ψ=0
-
向量形式表示
将梯度记为 ∇ψ=∂ψ∂x,∂ψ∂yT\nabla \psi = \left \\frac{\\partial \\psi}{\\partial x}, \\frac{\\partial \\psi}{\\partial y} \\right^T∇ψ=∂x∂ψ,∂y∂ψT,速度矢量记为 v=vx,vyT\mathbf{v} = v_x, v_y^Tv=vx,vyT。则二维光流方程可写成紧凑的向量内积形式:
∇ψTv+∂ψ∂t=0\boxed{\nabla \psi^T \mathbf{v} + \frac{\partial \psi}{\partial t} = 0}∇ψTv+∂t∂ψ=0
第二问:光流方程在什么情况下不能确定(二义性的部分)
标准答案:
光流方程中出现"二义性"(孔径问题,Aperture Problem),主要是因为一个方程包含两个未知数((v_x, v_y)),属于欠定方程组。
具体来说,光流不确定性的情况体现在以下两个方面:
-
切线方向分量的未定义(孔径问题)
- 将真实运动速度向量 (\mathbf{v}) 分解为沿梯度方向的法向分量 (v_n) 和 垂直于梯度的切线分量 (v_t) ,即 v=vnen+vtet\mathbf{v} = v_n \mathbf{e}_n + v_t \mathbf{e}_tv=vnen+vtet。
- 将速度分解代入光流方程,由于切线方向与梯度方向互相垂直,内积为零(∇ψ⋅et=0\nabla \psi \cdot \mathbf{e}_t = 0∇ψ⋅et=0)。
- 因此,光流方程只能解出沿梯度方向的分量 (v_n)(满足 vn∥∇ψ∥+∂ψ∂t=0v_n \|\nabla \psi\| + \frac{\partial \psi}{\partial t} = 0vn∥∇ψ∥+∂t∂ψ=0),而平行于边缘的切线速度分量 (v_t) 在数学上是未定义的,无法确定。
-
平坦(恒定亮度)区域的完全失效
- 在图像中灰度分布均匀、没有纹理的平坦区域 ,图像的空间梯度 ∇ψ=0\nabla \psi = 0∇ψ=0。
- 代入光流方程,得到 ∂ψ∂t=0\frac{\partial \psi}{\partial t} = 0∂t∂ψ=0。
- 这意味着无论目标运动速度如何,该区域的亮度都不会产生任何变化。因此,在平坦区域光流是完全不确定的,运动估计不可靠。
-
结论
光流估计更可靠的是靠近图像边缘的区域 (梯度 (\nabla \psi) 较大)。在平坦区域及边缘切向方向,由于光流方程固有的孔径问题 ,无法得到唯一的二维运动矢量。必须在光流方程的基础上,引入空间平滑约束(如 Lucas-Kanade 方法或 Horn-Schunck 方法)才能求得唯一解。
第十章 目标跟踪
贝叶斯,卡尔曼。粒子滤波
结合中科大《数字图像分析》课程的要求,这三个概念构成了目标跟踪从**"宏观概率框架"到 "最优线性解析解",再到"非线性数值近似解"**的完整理论体系。
下面我结合严谨的数学公式,为您详细展开讲解。
一、 贝叶斯跟踪框架(宏观概率框架)
贝叶斯跟踪是单目标跟踪的基石 。它将目标跟踪问题建模为一个状态估计问题 :根据直到当前时刻的所有观测值(图像帧),去估计目标在当前时刻的最优状态(如位置、速度、大小)。
1. 核心假设:
- 马尔可夫假设 :当前状态 (x_t) 仅依赖于上一时刻状态 (x_{t-1}),与更早的历史状态独立:p(xt∣x1:t−1)=p(xt∣xt−1)p(x_t | x_{1:t-1}) = p(x_t | x_{t-1})p(xt∣x1:t−1)=p(xt∣xt−1)。
- 观测独立性 :当前观测值 (z_t) 仅依赖于当前状态 (x_t),即 p(zt∣x1:t,z1:t−1)=p(zt∣xt)p(z_t | x_{1:t}, z_{1:t-1}) = p(z_t | x_t)p(zt∣x1:t,z1:t−1)=p(zt∣xt)。
2. 核心公式(递归贝叶斯估计):
跟踪的过程是一个**"预测(先验)"与"更新(后验)"**的交替循环。
-
第一步:预测(Predict)
根据上一时刻的后验概率 (p(x_{t-1} | z_{1:t-1})) 和状态转移模型(目标怎么动),计算当前时刻的先验概率 p(xt∣z1:t−1)p(x_t | z_{1:t-1})p(xt∣z1:t−1)。
p(xt∣z1:t−1)=∫p(xt∣xt−1)⋅p(xt−1∣z1:t−1) dxt−1p(x_t | z_{1:t-1}) = \int p(x_t | x_{t-1}) \cdot p(x_{t-1} | z_{1:t-1}) \, dx_{t-1}p(xt∣z1:t−1)=∫p(xt∣xt−1)⋅p(xt−1∣z1:t−1)dxt−1
-
第二步:更新(Update)
当得到当前时刻的观测值 (z_t)(即当前帧的图像内容)后,利用贝叶斯定理,将先验概率修正为后验概率 p(xt∣z1:t)p(x_t | z_{1:t})p(xt∣z1:t)。
p(xt∣z1:t)=p(zt∣xt)⋅p(xt∣z1:t−1)p(zt∣z1:t−1)p(x_t | z_{1:t}) = \frac{p(z_t | x_t) \cdot p(x_t | z_{1:t-1})}{p(z_t | z_{1:t-1})}p(xt∣z1:t)=p(zt∣z1:t−1)p(zt∣xt)⋅p(xt∣z1:t−1)
(注:分母 p(zt∣z1:t−1)p(z_t | z_{1:t-1})p(zt∣z1:t−1) 是归一化常数,确保概率积分为1。分子的第一项 (p(z_t | x_t)) 是似然概率 ,表示当前状态与观测值的匹配程度;第二项是先验概率)。
二、 卡尔曼滤波跟踪基本原理(最优线性解析解)
适用场景 :要求系统线性 (目标做匀速/匀加速运动),且过程噪声与观测噪声均为高斯分布 。在这种前提下,卡尔曼滤波能给出贝叶斯框架的最优闭合解析解(直接算出的精确解,不需迭代或近似)。
1. 建立状态空间方程:
- 状态转移方程 :xk=Fxk−1+Buk+wkx_k = F x_{k-1} + B u_k + w_kxk=Fxk−1+Buk+wk
(F):状态转移矩阵(控制目标运动规律); wk∼N(0,Q)w_k \sim N(0, Q)wk∼N(0,Q):过程噪声(高斯分布,协方差 (Q))。 - 观测方程 :zk=Hxk+vkz_k = H x_k + v_kzk=Hxk+vk
(H):观测矩阵; vk∼N(0,R)v_k \sim N(0, R)vk∼N(0,R):观测噪声(高斯分布,协方差 (R))。
2. 卡尔曼滤波五大核心公式(必须掌握):
卡尔曼滤波分为两阶段,共5个方程。
-
第一阶段:预测(时间更新)
- 状态预测 :x^k∣k−1=Fx^k−1∣k−1\hat{x}{k|k-1} = F \hat{x}{k-1|k-1}x^k∣k−1=Fx^k−1∣k−1
- 协方差预测 :Pk∣k−1=FPk−1∣k−1FT+QP_{k|k-1} = F P_{k-1|k-1} F^T + QPk∣k−1=FPk−1∣k−1FT+Q
-
第二阶段:校正(状态更新 / 融合观测)
- 计算卡尔曼增益 :Kk=Pk∣k−1HT(HPk∣k−1HT+R)−1K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1}Kk=Pk∣k−1HT(HPk∣k−1HT+R)−1
(增益 (K) 代表对"预测"和"观测"的信任权重。若观测噪声 (R) 极小,(K) 会变大,系统更相信测量值;若过程噪声 (Q) 极小,系统更相信预测值) 。
-
更新状态估计 :x^k∣k=x^k∣k−1+Kk(zk−Hx^k∣k−1)\hat{x}{k|k} = \hat{x}{k|k-1} + K_k (z_k - H \hat{x}_{k|k-1})x^k∣k=x^k∣k−1+Kk(zk−Hx^k∣k−1)
-
更新误差协方差 :Pk∣k=(I−KkH)Pk∣k−1P_{k|k} = (I - K_k H) P_{k|k-1}Pk∣k=(I−KkH)Pk∣k−1
三、 粒子滤波跟踪基本原理(非线性/非高斯蒙特卡洛近似)
为什么需要粒子滤波?
实际跟踪中,目标经常会突然转向、加速、或者光照发生突变(非高斯分布),此时卡尔曼滤波会立刻失效。粒子滤波通过**"蒙特卡洛模拟",用大量的随机样本(粒子)**来近似概率分布,从而解决复杂的非线性/非高斯问题。
1. 核心思想:
用 (N) 个带权重的随机粒子 {xt(i),wt(i)}i=1N\{x_t^{(i)}, w_t^{(i)}\}{i=1}^{N}{xt(i),wt(i)}i=1N 来近似后验概率密度 p(xt∣z1:t)p(x_t | z{1:t})p(xt∣z1:t)。粒子越多的区域,目标存在的概率越大。
2. 粒子滤波的标准流程(SIR 采样重要性重采样):
- 步骤 1:初始化((t=0))
在状态空间内随机撒下 (N) 个粒子,权重均等,为 w0(i)=1Nw_0^{(i)} = \frac{1}{N}w0(i)=N1。 - 步骤 2:预测(传播)
根据状态转移模型 p(xt∣xt−1)p(x_t | x_{t-1})p(xt∣xt−1),将上一时刻的粒子进行扩散和移动:xt(i)∼p(xt∣xt−1(i))x_t^{(i)} \sim p(x_t | x_{t-1}^{(i)})xt(i)∼p(xt∣xt−1(i))。(即按目标运动规律让粒子集体走一步)。 - 步骤 3:更新(计算权重)
根据当前帧观测到的图像特征(如颜色直方图),计算每个粒子的观测似然 p(zt∣xt(i))p(z_t | x_t^{(i)})p(zt∣xt(i))。
更新权重:wt(i)=p(zt∣xt(i))w_t^{(i)} = p(z_t | x_t^{(i)})wt(i)=p(zt∣xt(i))。
归一化权重:w~t(i)=wt(i)∑j=1Nwt(j)\tilde{w}t^{(i)} = \frac{w_t^{(i)}}{\sum{j=1}^{N} w_t^{(j)}}w~t(i)=∑j=1Nwt(j)wt(i)。
(物理意义:长得越像目标的粒子,权重越大)。 - 步骤 4:重采样(Resampling)------【非常重要】
复制权重大的粒子,剔除权重极小的粒子。
使粒子总数保持在 (N),且权重重置为均等:(w_t^{(i)} = \frac{1}{N})。
(物理意义:精力集中在"靠谱"的区域,避免在背景区域浪费计算资源)。 - 步骤 5:状态估计输出
目标在当前时刻的最终状态,通常取所有粒子的加权平均值 :
x^t=∑i=1Nwt(i)xt(i)\hat{x}t = \sum{i=1}^{N} w_t^{(i)} x_t^{(i)}x^t=∑i=1Nwt(i)xt(i)
(也可以取权重最大粒子作为状态输出)。 - 步骤 6:返回步骤 2 循环迭代。
1. 请从原理上解释为何卡尔爱滤泼跟踪在实际应用中效果不好?(2)请从原理上解释粒子滤波是如何帮决该问题的?

2.卡尔曼滤波与粒子滤波的原理。卡尔曼滤波的两个重要假设


第十一章 3D 图像分析
一、 成像变换与相机标定 (Camera Calibration)
这一部分解决的是**"3D空间中的点是如何投影到2D图像平面上的",以及"如何求解相机的数学参数"**。
1. 坐标系与针孔成像模型
图像的形成涉及世界坐标系、相机坐标系、图像坐标系、像素坐标系 的多次转换。使用齐次坐标 可以将其统一为线性矩阵运算(课件第8页)。
完整的投影方程为:
p=KR∣−RTPW\mathbf{p} = \mathbf{K}\\mathbf{R} \\mid -\\mathbf{R}\\mathbf{T}\mathbf{P}_Wp=KR∣−RTPW
其中:
- PW\mathbf{P}_WPW:世界坐标系下的3D点 (X,Y,Z,1)T(X, Y, Z, 1)^T(X,Y,Z,1)T。
- M=R∣−RT\mathbf{M} = \\mathbf{R} \\mid -\\mathbf{R}\\mathbf{T}M=R∣−RT:外参矩阵 ,表示相机在世界坐标系中的旋转R\mathbf{R}R 和位移 T\mathbf{T}T。(考试常考:RT表示外参,决定相机是"拍哪、怎么摆")。
- (\mathbf{K}):内参矩阵 ,将相机坐标系投影到像素坐标系。一般形式为:
K=a0cx0bcy001\mathbf{K} = \begin{bmatrix} a & 0 & c_x \\ 0 & b & c_y \\ 0 & 0 & 1 \end{bmatrix}K= a000b0cxcy1
其中 (a, b) 包含焦距和像素尺度因子,((c_x, c_y)) 是光心在像素坐标系下的主点坐标。(内参决定相机的"焦距、分辨率")。
2. 相机标定原理
相机标定就是求内参矩阵 (\mathbf{K}) 和外参矩阵 (\\mathbf{R}\|\\mathbf{T}) 的过程。
- DLT(直接线性变换)算法 (课件第9页):
通过已知的 (N) 对 2D 像素点 (\mathbf{p}_i) 和对应的 3D 世界坐标点 (\mathbf{P}_i),构建线性方程组求解投影矩阵 (\mathbf{M})。
pi=MPi⇒−Pi⊤0xiPi⊤0−Pi⊤yiPi⊤m0m1m2=0\mathbf{p}_i = \mathbf{M}\mathbf{P}_i \quad \Rightarrow \quad \begin{bmatrix} -\mathbf{P}_i^\top & 0 & x_i \mathbf{P}_i^\top \\ 0 & -\mathbf{P}_i^\top & y_i \mathbf{P}_i^\top \end{bmatrix} \begin{bmatrix} \mathbf{m}_0 \\ \mathbf{m}_1 \\ \mathbf{m}_2 \end{bmatrix} = \mathbf{0}pi=MPi⇒−Pi⊤00−Pi⊤xiPi⊤yiPi⊤ m0m1m2 =0 - 最小重投影误差法(优化后处理) (课件第11页):
DLT对噪声敏感,通常用作初值。之后用非线性优化(如光束平差法 Bundle Adjustment )最小化实际投影点 (\mathbf{p}_i) 与估计投影点 (\mathbf{p}'_i) 之间的欧氏距离 :
∑i=1N∥pi−π(KR∣−RTPi)∥2\sum_{i=1}^{N} \| \mathbf{p}_i - \pi (\mathbf{K}\\mathbf{R} \| -\\mathbf{R}\\mathbf{T}\mathbf{P}_i) \|^2∑i=1N∥pi−π(KR∣−RTPi)∥2
二、 立体视觉与对极几何 (Stereo Vision & Epipolar Geometry)
立体视觉通过**两个已知位置的相机(双眼)来模拟人类的双目深度感知,解决"物体离我有多远"**的问题。
1. 立体视觉深度公式(视差)
在理想情况(两相机平行、内参相同)下(课件第13页):
Z=f⋅TxR−xL=f⋅TdZ = \frac{f \cdot T}{x_R - x_L} = \frac{f \cdot T}{d}Z=xR−xLf⋅T=df⋅T
- (Z):目标到相机的深度。
- (f):焦距。
- (T):两个相机光心之间的水平基线距离(Baseline)。
- (d = x_R - x_L):视差(Disparity),即同一个空间点在左右视图中的像素水平位置差。
- 结论 :视差 (d) 越大,距离 (Z) 越近;视差 (d) 越小,距离 (Z) 越远。深度与视差成反比。
2. 立体匹配
想要得到视差图(深度图),必须先找出左右视图中的对应像素点(课件第14-16页)。常用的匹配方法有:
- 基于亮度/灰度的区域匹配。
- 基于**局部特征(如Harris、SIFT)**的稀疏匹配(常用于视觉SLAM)。
- 基于深度学习的端到端匹配(如PSMNet,构建Cost Volume代价体)。
3. 对极几何(Epipolar Geometry)
它是立体视觉中约束搜索范围的极强工具(课件第18-21页)。
- 核心概念 :
- 极平面(Epipolar Plane):由两个相机的光心 (O_1, O_2) 和空间点 (\mathbf{P}) 共同决定的平面。
- 极线(Epipolar Line):极平面与图像平面的交线。
- 极点(Epipole):连接两个相机光心的直线与图像平面的交点(即另一个相机光心在该图像上的投影)。
- 极线约束(关键考点) :
已知左图像上的点 (\mathbf{p}_1),其在右图像上的对应点 (\mathbf{p}_2) 不可能全图搜索,一定在某个特定的极线上 。这大大缩小了匹配搜索范围,从二维搜索变成了一维搜索。
4. 图像矫正(Rectification)
由于实际双目相机很难做到完美的平行放置,为了进一步简化匹配,我们可以通过旋转相机、缩放图像 (单应性变换),将双目图像矫正(Rectify) ,使得两张图像处于同一个水平面上 。
矫正后,对应点必定位于同一水平扫描线上,直接进行水平一维搜索即可。
三、 单应性(Homography)
单应性描述了同一个平面在不同相机视角下的投影变换关系,是图像拼接(全景图)、平面标定等任务的核心技术。
1. 单应矩阵定义与特性
两个平面之间的透视变换可以用一个 (3\times3) 的单应矩阵 (\mathbf{H}) 表示(课件第24页):
p′=Hp\mathbf{p}' = \mathbf{H}\mathbf{p}p′=Hp
- 特性 :(\mathbf{H}) 矩阵具有 8个自由度((\mathbf{H}) 可以缩放一个尺度因子,因此令最后一个元素为1,剩下8个未知数)。
- 保共线性质:单应变换会将直线映射为直线。
2. 单应矩阵的应用场景与推导(考频极高)
-
场景一:相机仅发生旋转(纯旋转 (T=0)) (课件第25-26页):
当相机绕光心仅转动时,不同视角的图像之间存在单应性,变换关系为:
λx′y′1=KRK−1xy1⇒H=KRK−1\lambda \begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} = \mathbf{K}\mathbf{R}\mathbf{K}^{-1} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} \quad \Rightarrow \quad \mathbf{H} = \mathbf{K}\mathbf{R}\mathbf{K}^{-1}λ x′y′1 =KRK−1 xy1 ⇒H=KRK−1
(这个推导非常经典,常用于全景图拼接的数学解释)
-
场景二:拍摄的是一块平面的物体(或地面) (课件第27页):
当观察的是世界坐标系下 (Z=0) 的平面时,透视投影退化为单应变换。
λxy1=Kr1,r2,tXY1=HXY1\lambda \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} = \mathbf{K}\\mathbf{r}_1, \\mathbf{r}_2, \\mathbf{t} \begin{bmatrix} X \\ Y \\ 1 \end{bmatrix} = \mathbf{H} \begin{bmatrix} X \\ Y \\ 1 \end{bmatrix}λ xy1 =Kr1,r2,t XY1 =H XY1
3. 如何求解单应矩阵?
- DLT算法:由4对以上的匹配特征点,构建 (\mathbf{A}\mathbf{h} = \mathbf{0}) 矩阵求解 (\mathbf{H})(课件第29页)。
- RANSAC算法 :因为特征匹配中会有大量误匹配(外点 Outlier) ,在计算 (\mathbf{H}) 时必须结合 RANSAC 算法进行随机采样剔除错误匹配,多次迭代后得到最准确的 (\mathbf{H})。
- 应用实例:全景图拼接(全景照片的生成)。
💡 考试快速对比表
| 概念 | 核心输入 | 核心输出 | 核心数学工具 | 主要应用场景 |
|---|---|---|---|---|
| 相机标定 | 2D像素点 + 对应的3D世界点 | 内参 K, 外参 R,T | DLT(线性求解)+ 光束平差法(非线性优化) | 机器人导航、AR/VR |
| 立体视觉 | 双目图像对 | 视差图/深度图 | (Z=fT/d),极线约束,匹配算法 | 自动驾驶测距、3D重建 |
| 单应性 | 两张图像的特征匹配点 | 透视变换矩阵 H | (\mathbf{H} = \mathbf{K}\mathbf{R}\mathbf{K}^{-1}),DLT,RANSAC | 全景图像拼接、图像矫正 |
💡 考场踩分点提示:
- 如果考简答题"相机标定的目的是什么? ",答案务必包含:"求解相机的内参矩阵和外参矩阵,建立3D世界坐标到2D像素坐标的精确映射关系。"
- 如果考推导题"证明单应矩阵 (\mathbf{H}) 在相机纯旋转时成立 ",必须写出 p2=KRK−1p1p_2 = \mathbf{K}\mathbf{R}\mathbf{K}^{-1} p_1p2=KRK−1p1 这个关系式。
- 如果考"如何找到立体匹配的同名点? ",答案一定要提到**"极线约束"(将二维搜索降为一维搜索)和"图像矫正"**。