核心结论速览
- 作者用一个"只改路由器能看到什么信息、不动其架构"的消融,证明了 LLM 路由器的真正瓶颈是信息缺失 而非推理能力 :把"各模型在各维度的实测分数"这种数字喂进零样本路由器,AvgPerf 从 41.41 直接跳到 47.74(相对 +15.3%),且超过了编码了同样维度先验的启发式基线 DimensionBest(47.50)。
- 据此把路由形式化为 Context → Action → Feedback(C-A-F)循环 ,对应到上下文老虎机 ,并把评测指标从"单次准确率"换成累积遗憾(cumulative regret);C-A-F 同时充当一个能把所有现存路由方法归位的统一分类框架。
- 落地系统 ACRouter (Orchestrator + Verifier + Memory 三件套)在自建的 CodeRouterBench(约 1.01 万任务、10 维度)上,ID 测试拿到路由器最高 AvgPerf(49.98%)、最低累积遗憾;在 agentic 编程的 OOD 测试上(62.50%)显著超过所有静态学习器(普遍低于随机)、在线老虎机与"永远选 Opus"。
一、研究背景与动机
故事要从一个很具体的用户处境讲起。今天一个稍微重度的开发者,手里同时握着 Claude、GPT、还有本地跑的若干开源模型;而在代码这件事上,没有任何一个模型在所有维度上碾压其余所有模型。论文把这个落差讲成一个"立场分歧":
- 现有的 coding agent(Claude Code、Codex 之类)都是 provider-centric(厂商中心)------固定一个自家模型打天下。对厂商而言这是最优解:用自家模型、成本可预测、闭源可控。
- 但用户要的是 user-centric(用户中心)------我不在乎是谁家的模型,我只关心这道题用哪个模型质量最高、最划算。
这两种立场的冲突,把问题逼到了一个朴素的形式:一道任务进来,到底该路由给哪个模型? 这不是新问题(RouterBench、LLMRouterBench 等一系列工作都在做),但本文的切入点不一样------它没有去卷"怎么训一个更强的路由器",而是先停下来问:路由器到底卡在哪?是脑子不够,还是信息不够?
支撑动机的,是作者对 8 个前沿代码模型的实测(Opus 4.6、Sonnet 4.6、GPT-5.4、Qwen3-Max、Qwen3.5-Plus、GLM-5、Kimi-K2.5、MiniMax-M2.7)。结论有两条硬数据:
- 能力互补是真实存在的。 Opus 平均分最高(42.9%),但算法设计被 GLM-5 反超(47.2% vs 25.4%,相对 +86%)、测试生成被 Qwen3-Max 反超(82.7% vs 39.2%,+111%)、数据科学被 Kimi-K2.5 反超。9 个维度里有 5 个不同模型当过"维度冠军"。
- 强模型普遍更贵。 Opus 的总花费约为 Kimi 的 12 倍。
互补 + 价差,意味着"既提质又省钱"在原理上成立------这就是整篇论文的立论地基。
二、相关工作与定位
把前人路线放进一个坐标系,本文的位置就清楚了。作者后文用 C-A-F 框架(见第四节)顺手做了一张"现存方法归位表",这里先按思想谱系梳理:
| 路线 | 代表 | 信息状态 | 核心局限 |
|---|---|---|---|
| 单模型 | 任一固定后端 | 无 | 放弃了一切互补性 |
| 静态启发式 | DimensionBest、kNN | 冻结的先验 | 决策时不产生新信息,跨任务不累积 |
| 静态训练策略 | LogReg、RouteLLM、微调 Qwen | 训练时一次性写死 | 训练分布外(OOD)即崩 |
| 在线老虎机 | LinUCB、LinTS | 流式更新的参数化记忆 | 每臂线性模型,缺乏 context-aware 推理 |
| 本文(ACRouter) | C-A-F 三件套 | 执行落地反馈 + 跨任务累积的细粒度记忆 | (见第九节) |
本文相对于这些工作的"补缺"在于一句诊断:上述方法要么不在决策时产生新信息(前三类),要么产生的信息被线性模型的表达力卡死(在线老虎机) 。RouterBench / LLMRouterBench 这类工作把基准建在"单次准确率"上,无法刻画"信息随任务流累积"的过程;本文则主张评测必须是流式的、按累积遗憾计的,并为此自建了带"每题 × 每模型"结果矩阵的 CodeRouterBench。
一句话定位:别人在优化路由器,本文在重新定义路由问题------从"选模型的一次性分类"变成"在任务流上不断产生并累积信息的序贯决策"。
三、研究问题与核心贡献
形式化问题定义
给定一条任务流 {pi}i=1N\{p_i\}_{i=1}^N{pi}i=1N(pip_ipi 为第 iii 道编程任务的 prompt)与一个候选模型池 M={m1,...,mK}\mathcal{M}=\{m_1,\dots,m_K\}M={m1,...,mK}(本文 K=8K=8K=8)。路由策略 π\piπ 在每一步观测上下文 cic_ici 后选择一个动作(模型)ai∈Ma_i\in\mathcal{M}ai∈M,执行后获得反馈 fif_ifi。目标不是最大化单次准确率,而是最小化相对于逐题最优 oracle 的累积遗憾(定义见第五节)。
逐条贡献与新颖性分级
- 【思想创新 ★★★】把路由瓶颈从"推理"重新诊断为"信息"。 这是全文的命门,由 Table 1 的"纯信息消融"支撑(第七节详述)。它把"该不该做路由"和"路由该怎么做"两个问题都重新接地了。
- 【框架创新 ★★☆】C-A-F 循环 + 上下文老虎机视角 + 累积遗憾指标。 三者绑定:循环给出"信息如何流动",老虎机给出"为什么该用累积遗憾",累积遗憾给出"评测应该量什么"。C-A-F 同时是一张能把所有现存方法归位的分类表(Table 4),让消融天然成立。
- 【基准贡献 ★★★】CodeRouterBench。 约 1.01 万任务、10 维度、含一个专门留作 OOD 的 agentic 维度,并预采集了"每题 × 每模型"的结果矩阵------这是能在流上算累积遗憾的前提,现有路由基准不具备。
- 【系统贡献 ★★☆】ACRouter。 Orchestrator / Verifier / Memory 三件套,分别对应"整合信息 / 产生信息 / 累积信息"三条设计要求。
- 【实证发现 ★★☆】三个反直觉副发现。 "最强 coder 是最差 router"、"微调是门槛、规模不是"、"维度只能解释约 27% 的路由信号"。
四、方法详解(重点章节)
4.1 符号体系与 C-A-F 建模
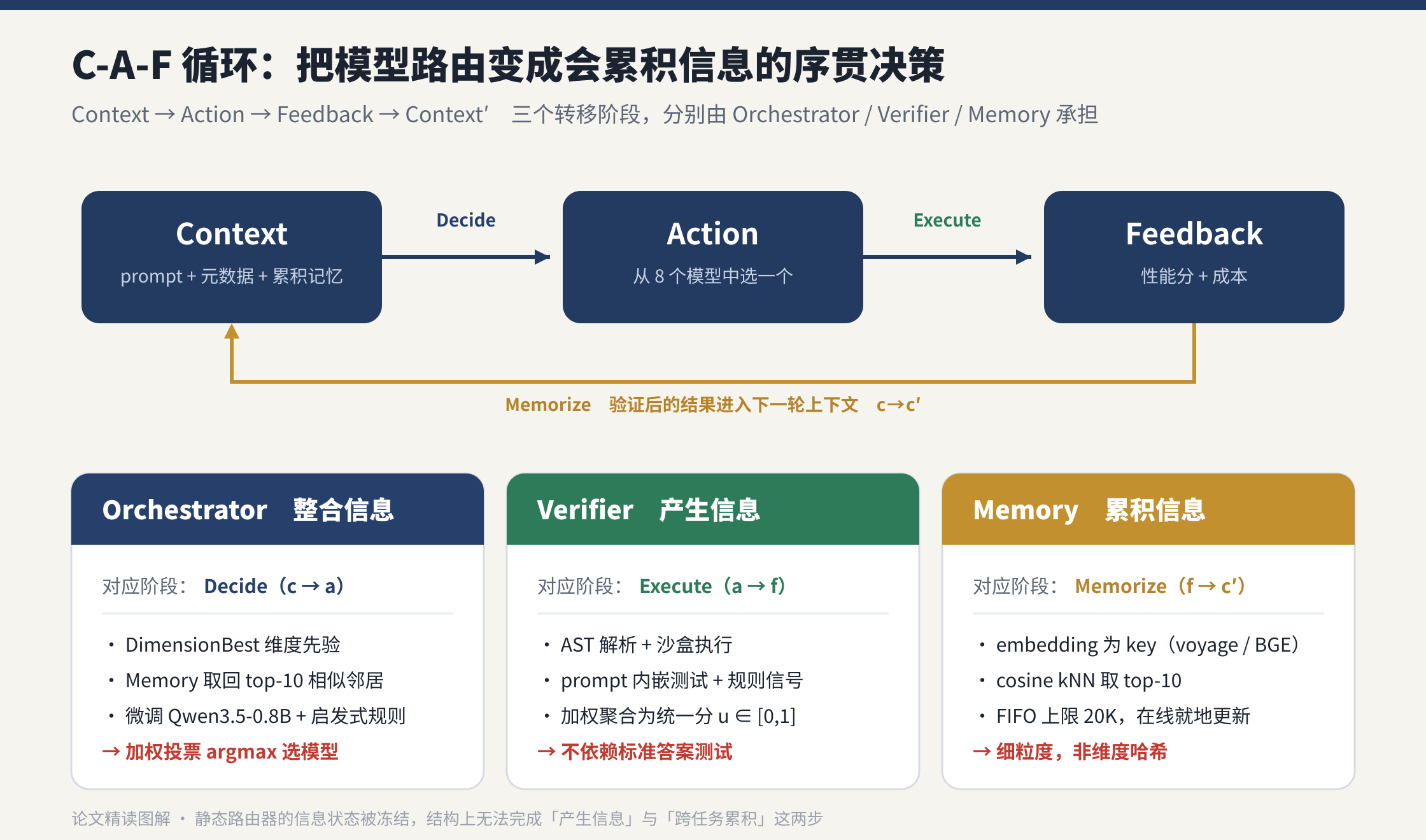
定义一个状态随任务流演化的循环:
ci→ Decide ai→ Execute fi→ Memorize ci+1 c_i \xrightarrow{\ \text{Decide}\ } a_i \xrightarrow{\ \text{Execute}\ } f_i \xrightarrow{\ \text{Memorize}\ } c_{i+1} ci Decide ai Execute fi Memorize ci+1
- Context ci=(pi, di, H<i)c_i=(p_i,\,d_i,\,\mathcal{H}{<i})ci=(pi,di,H<i):当前 prompt pip_ipi、任务元数据 did_idi(维度标签等)、以及累积记忆 H<i\mathcal{H}{<i}H<i(前 i−1i-1i−1 步验证后的轨迹)。
人话:决策前路由器手上掌握的全部信息------这道题长什么样、它属于哪一类、以及过去做过的题攒下的经验。 - Action ai∈Ma_i\in\mathcal{M}ai∈M:选择哪个模型。M\mathcal{M}M 就是那 8 个候选模型的集合,∈\in∈ 读作"属于",即 aia_iai 是这 8 个里的某一个。
- Feedback fi=(s^i, κ^i)f_i=(\hat s_i,\,\hat\kappa_i)fi=(s^i,κ^i):验证器给出的性能分 s^i\hat s_is^i 与成本 κ^i\hat\kappa_iκ^i。
人话:这次选择的"成绩单"------做得好不好、花了多少。字母头上的帽子 ^\hat{\ } ^ 表示这是验证器"估"出来的分,不是上帝视角的真值。
关键在 H<i\mathcal{H}{<i}H<i 这一项:每跑完一圈,验证后的结果进入下一圈的上下文,所以"下一次决策更知情"。静态路由器结构上做不到这件事 ------它的信息状态是冻结的,ci+1c{i+1}ci+1 与 cic_ici 共享同一份死先验。
由诊断(第七节)引出的两条设计要求:
- (i) 产生信息:每次决策要落地执行、真把输出跑进验证器,而非靠静态先验或模型自评;
- (ii) 累积信息:把这些信息跨任务流累积,让后续决策能 condition 在过去结果上。
4.2 C-A-F 作为统一分类框架(Table 4)

把三件套------Orchestrator(决策)、Verifier(产信息)、Memory(累信息)------分别删掉或冻结,就能把所有现存方法归位:
- 单模型 = 三者皆无;
- 静态启发式(DimensionBest、kNN)= 冻结记忆、无策略、无验证;
- 静态训练策略(LogReg、RouteLLM、微调 Qwen)= 仅有训练好的 Orchestrator;
- 在线老虎机(LinUCB / LinTS)= 参数化记忆 + argmax 策略 + 只看 reward 的验证。
这张表的妙处在于:它让"消融实验"和"与基线对比"成了同一件事------每个基线就是 ACRouter 抽掉某些组件后的特例。
4.3 ACRouter 三模块拆解
① Orchestrator(整合信息 → 对应"决策")。 决策中枢。综合三路信号:DimensionBest 先验、从 Memory 用 cosine kNN 取回的 top-10 历史邻居、任务元数据;核心策略是一个微调过的 Qwen3.5-0.8B 叠加启发式规则,用加权投票出最终选择。
Fig. 2 的例子很直观:一道运行时报错的 bug 修复任务,四个投票者(api_llm→MiniMax、logreg→GLM-5、memory_KNN→Kimi、dim_best→Kimi)加权后 Kimi-K2.5 得 1.47 分胜出,argmax 选 Kimi 去修。
② Verifier(产生信息 → 对应"执行/反馈")。 沙盒原生的打分器,把 AST 解析、沙盒执行、prompt 内嵌测试、规则信号等多路信号按类型加权,聚合成统一分 ui∈0,1u_i\in0,1ui∈0,1(见第五节 Eq. 8)。关键是它不依赖 ground-truth oracle 测试------尤其在 OOD 上没有标准答案测试时,全靠这些代理信号自算置信度。
③ Memory(累积信息 → 对应"记忆")。 在线向量库。以任务 embedding(voyage-code-3 / BGE-large)为 key,value 存"选了哪个模型 / 性能 / 成本 / 验证轨迹";检索用 cosine kNN 取 top-10;FIFO 上限 20K 条,每跑完一圈就地更新。强调这是基于 embedding 的细粒度记忆,而非 DimensionBest 那种粗粒度的"维度哈希"------所以"某候选模型在相似任务上最近的成功/失败"都能对 Orchestrator 可见。
4.4 路由主循环(伪代码)
text
Input: 任务流 {p_1..p_N}, 模型池 M, 探测集预热的 Memory H, 微调策略 θ
for i = 1 .. N:
d_i ← extract_metadata(p_i) # 维度等元数据
N_i ← Memory.knn(embed(p_i), k=10) # 取相似历史邻居
votes ← {
dim_best : DimensionBest(d_i),
logreg : LogReg(p_i),
api_llm : Qwen3.5-0.8B_θ(p_i, d_i, N_i),
mem_knn : majority_model(N_i)
}
a_i ← argmax_m Σ_v w_v · 1[votes[v] = m] # 加权投票
y_i ← a_i.run(p_i) # 执行
u_i, κ_i ← Verifier(y_i, p_i) # 产生信息: 统一分 + 成本
Memory.insert(embed(p_i) → {a_i, u_i, κ_i, trace}) # 累积信息 (FIFO 20K)
Output: 路由轨迹 {a_i}, 累积遗憾 CumReg_N五、关键公式与理论推导(数学重点章节)
这是一篇以实证与系统为主的论文,数学体量不大,但有四个核心形式对象值得逐一讲透。下面每个公式我都会先逐符号翻译成人话 ,再讲它为什么这么设 ,能上手算的地方配一个小例子。
5.0 读公式前:一张符号小抄
如果下面这些记号让你打怵,先记住这 7 条,后面就都能跟下来:
- 下标 iii :表示"第 iii 道任务"。xix_ixi 就是"第 iii 题的那个 xxx"。
- 求和号 ∑i=1N\sum_{i=1}^{N}∑i=1N :把 iii 从 1 到 NNN 的东西全部加起来。
- maxj\max_jmaxj :在所有候选 jjj 里取最大的那个数值。
- argmaxj\arg\max_jargmaxj :取到最大值的那个 jjj 本身 (要的是"哪个选项",不是"最高分多少")。路由器干的就是 argmax\arg\maxargmax------它要的是"选哪个模型"。
- ∈\in∈ :属于。ai∈Ma_i\in\mathcal{M}ai∈M = aia_iai 是集合 M\mathcal{M}M 里的一员。
- 0,10,10,1:闭区间,取值在 0 到 1 之间(含两端),常用来表示"归一化后的分数 / 概率"。
- 帽子 x^\hat{x}x^:估计值,不是真值(比如验证器估出来的分)。
5.1 奖励函数:把"质量"与"成本"压成单一标量
ri(ai)=ϵ1 si(ai)+ϵ2 κi(ai),ϵ1=1, ϵ2=−0.1 r_i(a_i)=\epsilon_1\, s_i(a_i)+\epsilon_2\,\kappa_i(a_i),\qquad \epsilon_1=1,\ \epsilon_2=-0.1 ri(ai)=ϵ1si(ai)+ϵ2κi(ai),ϵ1=1, ϵ2=−0.1
逐符号翻译(人话):
- aia_iai:这道题你选的那个模型。
- si(ai)s_i(a_i)si(ai):这个模型在这题上的性能分(越高越好,可理解成"做得多对")。
- κi(ai)\kappa_i(a_i)κi(ai):这个模型在这题上的成本(钱 / 算力,越高越费)。
- ϵ1=1, ϵ2=−0.1\epsilon_1=1,\ \epsilon_2=-0.1ϵ1=1, ϵ2=−0.1:两个权重。性能权重是 111,成本权重是 −0.1-0.1−0.1。
- rir_iri:综合奖励------给这次选择打的总分。
一句话:做得好加分,花得多扣分,把两件事压成一个数。
为什么成本权重是负的? 因为花钱是"坏事",要从总分里扣掉,所以前面带负号。
为什么是 −0.1-0.1−0.1 而不是 −1-1−1? 这等于宣布"质量比成本重要 10 倍 "。它真正的作用是个裁判(tie-breaker):只有当两个模型质量几乎打平时,成本才有资格决定胜负;只要质量差出一截,再贵也照选贵的。
上手算一遍(两个模型二选一):
| 模型 | 性能 sss | 成本 κ\kappaκ | r=s−0.1κr=s-0.1\kappar=s−0.1κ |
|---|---|---|---|
| A(强但贵) | 0.90 | 2.0 | 0.90−0.20=0.700.90-0.20=\mathbf{0.70}0.90−0.20=0.70 |
| B(弱但便宜) | 0.60 | 0.5 | 0.60−0.05=0.550.60-0.05=\mathbf{0.55}0.60−0.05=0.55 |
奖励选 A(0.70>0.550.70>0.550.70>0.55)------A 贵了 4 倍,但质量优势仍压过成本。
若把权重换成 ϵ2=−1\epsilon_2=-1ϵ2=−1 再算:rA=0.90−2.0=−1.10r_A=0.90-2.0=-1.10rA=0.90−2.0=−1.10,rB=0.60−0.5=0.10r_B=0.60-0.5=0.10rB=0.60−0.5=0.10,这次反而选 B。可见 −0.1-0.1−0.1 这个小数字本身,就决定了天平往"质量"还是"成本"那边倒。
坑 :sss 和 κ\kappaκ 必须先各自归一化到可比尺度,否则系数没意义。而且论文自己说 provider 端缓存命中率看不到、成本测不准,所以在 ID 上这一项基本只是"软裁判",奖励近似退化成 ri≈sir_i\approx s_iri≈si(详见第九节)。
5.2 累积遗憾:评测指标的重新定义
CumRegN(π)=∑i=1N(maxjRij−Ri,ai) \mathrm{CumReg}N(\pi)=\sum{i=1}^{N}\Big(\max_{j}R_{ij}-R_{i,a_i}\Big) CumRegN(π)=i=1∑N(jmaxRij−Ri,ai)
先说什么是"遗憾(regret)" :事后回看,"要是这题当时选了最好的那个模型,我本可以多拿多少分"。你实际拿到的,减去理论上最该拿到的,那个差距就是遗憾。 你永远不可能超过最优,所以遗憾总是 ≥0\ge 0≥0,越小越好,000 就是步步最优。
逐符号翻译:
- RijR_{ij}Rij:第 iii 题、用第 jjj 个模型,拿到的回报(就是上面那个含成本的 rrr)。
- maxjRij\max_j R_{ij}maxjRij:第 iii 题里把 8 个模型都试一遍,回报最高的那个值------这题"开了天眼"最该拿的分。
- Ri,aiR_{i,a_i}Ri,ai:你的策略实际选的模型 aia_iai 拿到的分。
- maxjRij−Ri,ai\max_j R_{ij}-R_{i,a_i}maxjRij−Ri,ai:第 iii 题的单题遗憾 (≥0\ge 0≥0)。
- ∑i=1N(⋯ )\sum_{i=1}^N(\cdots)∑i=1N(⋯):把 NNN 道题的遗憾全部累加------这就是累积遗憾。
一句话:累积遗憾 = 在整条任务流上,你和"每题都开天眼选最优"之间的总差距。
为什么要换掉"单次准确率"这把旧尺子? 因为准确率只看"平均做对多少",看不到"信息有没有越攒越多、后面有没有比前面更准"。遗憾是流式的,能体现"前面踩的坑有没有让后面少踩"------而这正是 C-A-F 想量的能力。
下面是全文最该讲透的一步推导:「逐题 oracle」远远强于「最优单模型」,这就是路由值得做的数学理由。
先把两种"理想策略"分清楚:
- 逐题 oracle :每道题各自挑当题最优 → 总分 ∑imaxjRij\sum_i \max_j R_{ij}∑imaxjRij。
- 最优单模型 :先选定一个模型,全程只用它 → 总分 maxj∑iRij\max_j \sum_i R_{ij}maxj∑iRij。
它们之间有一个恒成立的不等式:
∑imaxjRij ≥ maxj∑iRij \sum_i \max_j R_{ij}\ \ \ge\ \ \max_j \sum_i R_{ij} i∑jmaxRij ≥ jmaxi∑Rij
为什么?一句话证明: 对任何一个固定的模型 j0j_0j0,每一题都有 maxjRij≥Ri,j0\max_j R_{ij}\ge R_{i,j_0}maxjRij≥Ri,j0(一堆数里取最大,当然不小于其中任意一个)。把所有题加起来:∑imaxjRij≥∑iRi,j0\sum_i \max_j R_{ij}\ge \sum_i R_{i,j_0}∑imaxjRij≥∑iRi,j0。这对每一个 j0j_0j0 都成立,所以对"那个让右边最大的 j0j_0j0"也成立------于是左边 ≥\ge≥ 右边。证毕。
用具体数字感受这个差距(2 题 × 2 模型,格子里是回报):
| 模型 A | 模型 B | |
|---|---|---|
| 题 1 | 0.9 | 0.3 |
| 题 2 | 0.2 | 0.8 |
- 最优单模型 :A 的总分 0.9+0.2=1.10.9+0.2=1.10.9+0.2=1.1,B 的总分 0.3+0.8=1.10.3+0.8=1.10.3+0.8=1.1,取较大者 =1.1=\mathbf{1.1}=1.1。
- 逐题 oracle :max(0.9,0.3)+max(0.2,0.8)=0.9+0.8=1.7\max(0.9,0.3)+\max(0.2,0.8)=0.9+0.8=\mathbf{1.7}max(0.9,0.3)+max(0.2,0.8)=0.9+0.8=1.7。
- 差距 =1.7−1.1=0.6=1.7-1.1=\mathbf{0.6}=1.7−1.1=0.6。
这 0.60.60.6 是任何单模型策略都吃不到的红利 ------哪怕你永远选最强的那个,也只能逼近 1.11.11.1,碰不到 1.71.71.7。只有"每题换最合适的模型"(也就是路由)才能把这 0.60.60.6 捞回来。
把它对回论文:CodeRouterBench 上逐题 Oracle =57.00=\mathbf{57.00}=57.00,而最强单模型 Opus 平均才 42.942.942.9------这之间十几个点的鸿沟,就是上面那个 0.60.60.6 的放大版,是 ACRouter 存在的全部意义。也正因如此,累积遗憾里的 oracle 不是"最强模型",而是"每题开天眼",这是一把高得多、也诚实得多的标尺。
前提 :累积遗憾能算出来,靠的是一张预采集好的"每题 × 每模型"回报矩阵 R∈RN×KR\in\mathbb{R}^{N\times K}R∈RN×K(NNN 道题、KKK 个模型,每格都先把结果跑出来存好)。这正是 CodeRouterBench 必须自建、区别于"只测单次准确率"旧基准的地方。
5.3 统一验证分:把多路异质信号聚成置信度(Eq. 8 概形)
ui=∑t∈Twt ϕt(yi,pi)∑t∈Twt ∈0,1 u_i=\frac{\sum_{t\in\mathcal{T}} w_t\, \phi_t(y_i,p_i)}{\sum_{t\in\mathcal{T}} w_t}\ \in0,1 ui=∑t∈Twt∑t∈Twtϕt(yi,pi) ∈0,1
逐符号翻译:
- ttt:一种检查信号。比如:代码能不能被 AST 解析(语法对不对)、丢进沙盒能不能跑通、prompt 自带的测试过不过、有没有违反某些规则。
- ϕt(yi,pi)∈0,1\phi_t(y_i,p_i)\in0,1ϕt(yi,pi)∈0,1:第 ttt 种检查打的分(111 = 完全通过,000 = 完全不过,中间值 = 部分通过)。
- wtw_twt:这种检查的可信权重。"沙盒真的跑通了"比"语法没报错"更能说明问题,所以前者权重更高。
- 分子 ∑twtϕt\sum_t w_t\phi_t∑twtϕt:把各项检查分按可信度加权求和。
- 分母 ∑twt\sum_t w_t∑twt:所有权重之和,作用是归一化 ------把结果压回 0,10,10,1。
一句话 :这就是一个加权平均 。把好几个"局部体检指标"按可信度平均成一个 0 ∼ 10\!\sim\!10∼1 的"健康分" uiu_iui,当作"没有标准答案时,这段代码大概率对不对"的估计。
为什么一定要除以 ∑twt\sum_t w_t∑twt(归一化)? 不除的话,检查项越多、分子越大,不同任务之间没法比;除完之后无论用了几个信号,uiu_iui 都稳稳落在 0 ∼ 10\!\sim\!10∼1,可以直接当性能分 sis_isi 喂进上面的奖励函数。
上手算一遍:
| 检查项 | 得分 ϕ\phiϕ | 权重 www | wϕw\phiwϕ |
|---|---|---|---|
| AST 可解析 | 1.0 | 1 | 1.0 |
| 沙盒跑通 | 1.0 | 3 | 3.0 |
| 内嵌测试过一半 | 0.5 | 2 | 1.0 |
u=1.0+3.0+1.01+3+2=56≈0.83u=\dfrac{1.0+3.0+1.0}{1+3+2}=\dfrac{5}{6}\approx 0.83u=1+3+21.0+3.0+1.0=65≈0.83。
坑(我作为读者的) :这套打分全靠"代理信号和真实正确率正相关"这个假设 。论文没给 uiu_iui 对真值的校准曲线------万一这些"体检指标"本身不准,Memory 累积下来的就是被污染的反馈,而后面所有决策都建在这堆反馈上。这是地基性的隐患(第九节展开)。
5.4 路由信号的可解释上界:互信息只有约 27%
附录 D.3 给出一个信息论量级估计:oracle 选择 yty_tyt 与任务维度 dtd_tdt 之间的互信息,仅占 yty_tyt 熵的约 27%:
I(yt; dt)H(yt)≈0.27 \frac{I(y_t;\,d_t)}{H(y_t)}\approx 0.27 H(yt)I(yt;dt)≈0.27
附录 D.3 给了一个信息论量级估计:oracle 的选择 yty_tyt(该选哪个模型)与任务维度 dtd_tdt 之间的互信息,只占 yty_tyt 总不确定性的约 27%:
I(yt; dt)H(yt)≈0.27 \frac{I(y_t;\,d_t)}{H(y_t)}\approx 0.27 H(yt)I(yt;dt)≈0.27
先把三个吓人的词翻译成人话:
- 熵 H(y)H(y)H(y):"该选哪个模型"这件事本身有多难猜。如果 8 个模型常常各擅一摊、谁都可能是答案,那就很难猜,熵就大。可以想成"要猜中该选谁,平均得问多少个是 / 否问题"。
- 条件熵 H(y∣d)H(y\mid d)H(y∣d) :已经知道任务维度 ddd 之后,"该选谁"还剩多少没猜准。
- 互信息 I(y;d)=H(y)−H(y∣d)I(y;d)=H(y)-H(y\mid d)I(y;d)=H(y)−H(y∣d) :知道维度后,难度下降了多少------也就是"维度"这条线索到底含多少金。
所以 I(y;d)H(y)≈0.27\dfrac{I(y;d)}{H(y)}\approx 0.27H(y)I(y;d)≈0.27 在说:"维度"这条线索,只能消除约 27% 的"该选谁"的不确定性;剩下约 73% 藏在每道题的具体长相里(用了什么算法、调了什么 API、怎么处理边界)。
打个比方 :你要猜一个人爱看什么电影(yyy)。只知道他的"年龄段"(ddd=维度)能帮你猜对一部分,但更准的线索其实是他"上周具体看了哪几部"(题目的具体内容)。维度是粗线条,具体内容才是细线索。
这个 27% 一下把全文串起来了:
- 它是 DimensionBest 的天花板 ------只吃维度先验,最多到 0.4750.4750.475,永远够不到 oracle 的 0.5700.5700.570,因为它只抓住了那 27%。
- 它也是 ACRouter 用 embedding 记忆的理由------剩下那 73% 的信号在题目内容里,只能靠"按具体题目长相去检索相似历史"才能捞到,维度标签捞不着。
一句话:27% 既是粗粒度路由的上限,也是细粒度记忆存在的全部依据。
六、实验设置
模型池(8 个前沿代码模型):Opus 4.6、Sonnet 4.6、GPT-5.4、Qwen3-Max、Qwen3.5-Plus、GLM-5、Kimi-K2.5、MiniMax-M2.7。
基准 CodeRouterBench:
- 从 15+ 个公开 benchmark 重整出约 10,111 道任务,分 10 个维度;
- 9 个单轮维度(代码生成 / 算法设计 / bug 修复 / 代码补全 / 重构 / 数据科学 / 多语言 / 代码理解 / 测试生成),各约 1,111 题;
- 第 10 个 agentic programming 维度专门留作 OOD(176 题,来自 SWE-bench Verified、LongCLI-Bench、FeatureBench、SWE-CI)。
数据切分 :探测集 7,080 (用于 profile 模型、训练分类器、暖启动 Memory)、ID 测试 2,919 、OOD 测试 176。
评价指标 :AvgPerf(路由后平均性能)、累积遗憾(相对逐题 oracle)、Perf/$(成本效率)、Pareto 前沿。7 个维度用执行式打分(沙盒 pass@1),3 个维度用代理指标 + LLM-as-Judge。
baseline 谱系:单模型(含"永远选 Opus")、静态启发式(DimensionBest、kNN)、静态学习器(LogReg、RouteLLM、TF-IDF+MLP、微调 Qwen 0.8B--27B)、在线老虎机(LinUCB、LinTS)。
实现细节 :Orchestrator 用微调 Qwen3.5-0.8B;Memory 用 voyage-code-3 / BGE-large 做 embedding,FIFO 上限 20K;OOD 的 agentic 评测把标准 250 步砍到 40 步(作者称"相对排名不受影响")。
七、实验结果与深度分析
7.1 命门实验:纯信息消融(Table 1)
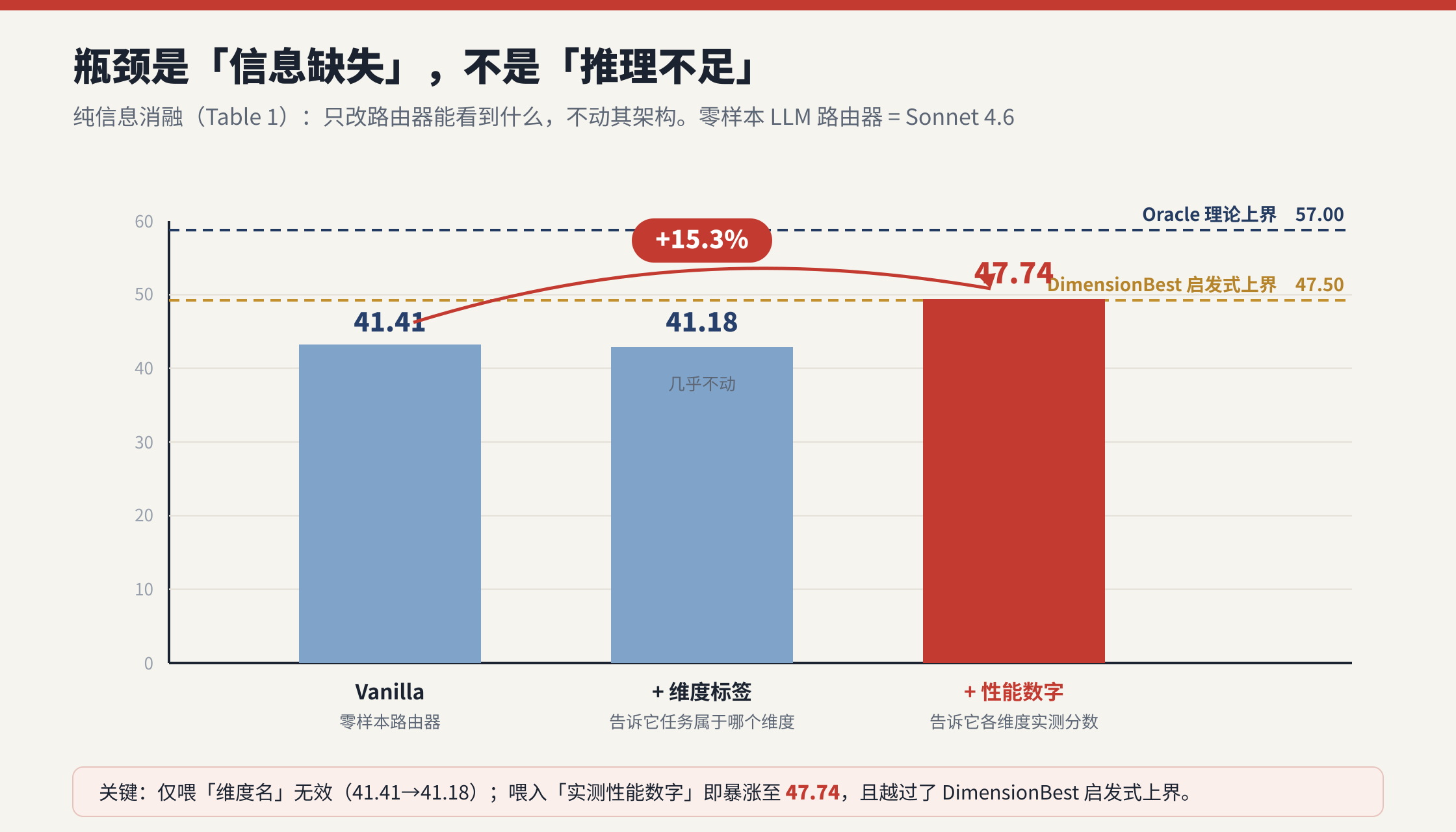
只改"路由器能拿到什么信息"、不动架构:
| 设置 | AvgPerf | 解读 |
|---|---|---|
| Oracle(逐题最优,理论上界) | 57.00 | 路由红利的天花板 |
| DimensionBest(按先验给每维配最优模型) | 47.50 | 静态启发式上界 |
| Vanilla(零样本 LLM 路由器,Sonnet 4.6) | 41.41 | 起点 |
| +Dimension(额外告知任务属于哪个维度) | 41.18 | 几乎没动,甚至略降 |
| +Perf stats(告知各维度实测性能数字) | 47.74 | 暴涨,且 > DimensionBest |
两个信号极其干净:
- 光告诉模型"这是个 bug fixing 任务"(维度名字)没用 (41.41→41.18);但把"各模型在各维度的实测分数"这种数字 喂进去,直接 41.41→47.74,相对涨 15.3%。
- 这个 47.74 甚至超过了编码了同样维度先验的启发式路由器 DimensionBest(47.50)。
附录 D.4 再补一刀:Vanilla 路由器的模型选择分布几乎是均匀的,根本没利用维度结构;只要把性能先验喂进去,它不改任何架构就追平甚至超过 DimensionBest。
这张表是全文的逻辑支点:LLM 路由器的瓶颈是信息缺失,不是推理能力。后面所有设计(C-A-F、三件套)都是这条诊断的工程兑现。
7.2 主结果(Table 3)
In-Distribution(n=2,919) :ACRouter 拿到路由器里最高的 AvgPerf(49.98% )和最低的累积遗憾(205.5 ),比握着完整维度先验的 DimensionBest 还高 2.48 个点。所有轻量分类器(LogReg、RouteLLM、TF-IDF+MLP、微调 Qwen)挤在 46--47 区间,在线老虎机也是 46--47。
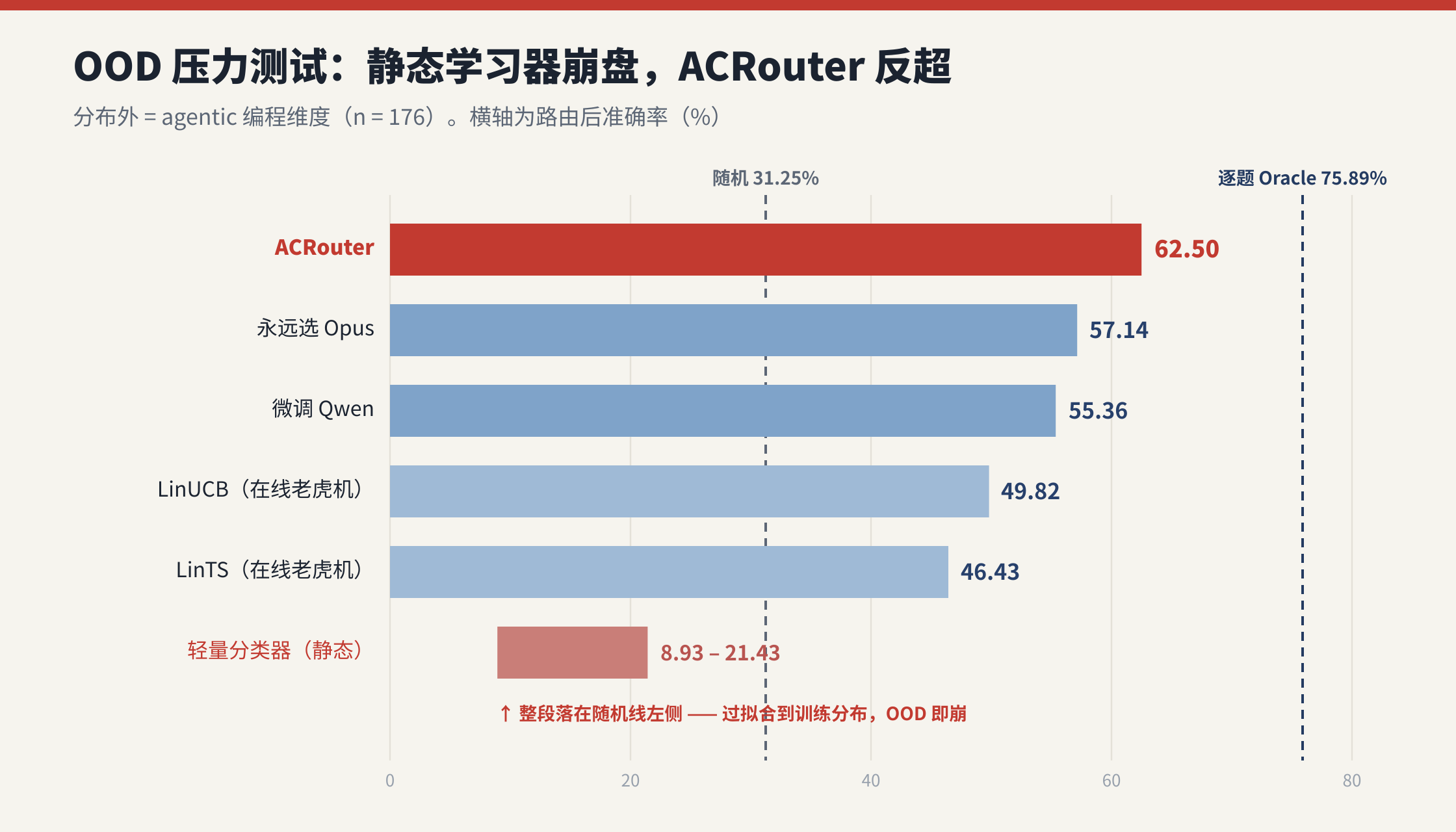
OOD(n=176,分水岭):
- 静态学习器全线崩盘 :轻量分类器 OOD 掉到 8.93%--21.43% ,比随机(31.25%)还低------典型的过拟合到训练分布。
- 在线老虎机活得好一些(LinUCB 49.82% / LinTS 46.43%),因为在流上持续更新,但受限于每臂线性模型,缺乏 context-aware 推理。
- ACRouter 拿到 62.50% ,领先在线老虎机、领先"永远选 Opus"(57.14%)、也领先微调 Qwen(55.36%),累积遗憾 17.0 全表第一。
累积遗憾曲线(Fig. 5):ID 上静态方法增长更快,OOD 上直接塌掉,只有 ACRouter 随 Memory 累积验证经验把信息缺口补上。Pareto 前沿(Fig. 6)上 ACRouter 把前沿往上顶,且成本低于"永远选 Opus"。
7.3 三个反直觉副发现
- "会写代码"≠"会做路由"(App C.1) :让 8 个模型分别当路由器,Opus 4.6 在 0-shot 和 3-shot 里都垫底,尽管它本身是最强 coder。路由是另一种能力。
- 微调是门槛,规模不是(App C.2):Qwen 从 0.8B 扫到 27B(约 30 倍参数),AvgPerf 只动 0.5 个点(46.21→46.74);但不微调的话,基座模型直接吐出格式错误的路由 token、退化到默认单模型。这解释了主表为何用 0.8B。
- 维度只能解释约 27% 的路由信号(App D.3):见 5.4 节。这是"细粒度记忆 > 维度哈希"的定量依据。
7.4 必须正视的一处反转:GPT-5.4 的"房间里的大象"(App D.7 / Table 14)
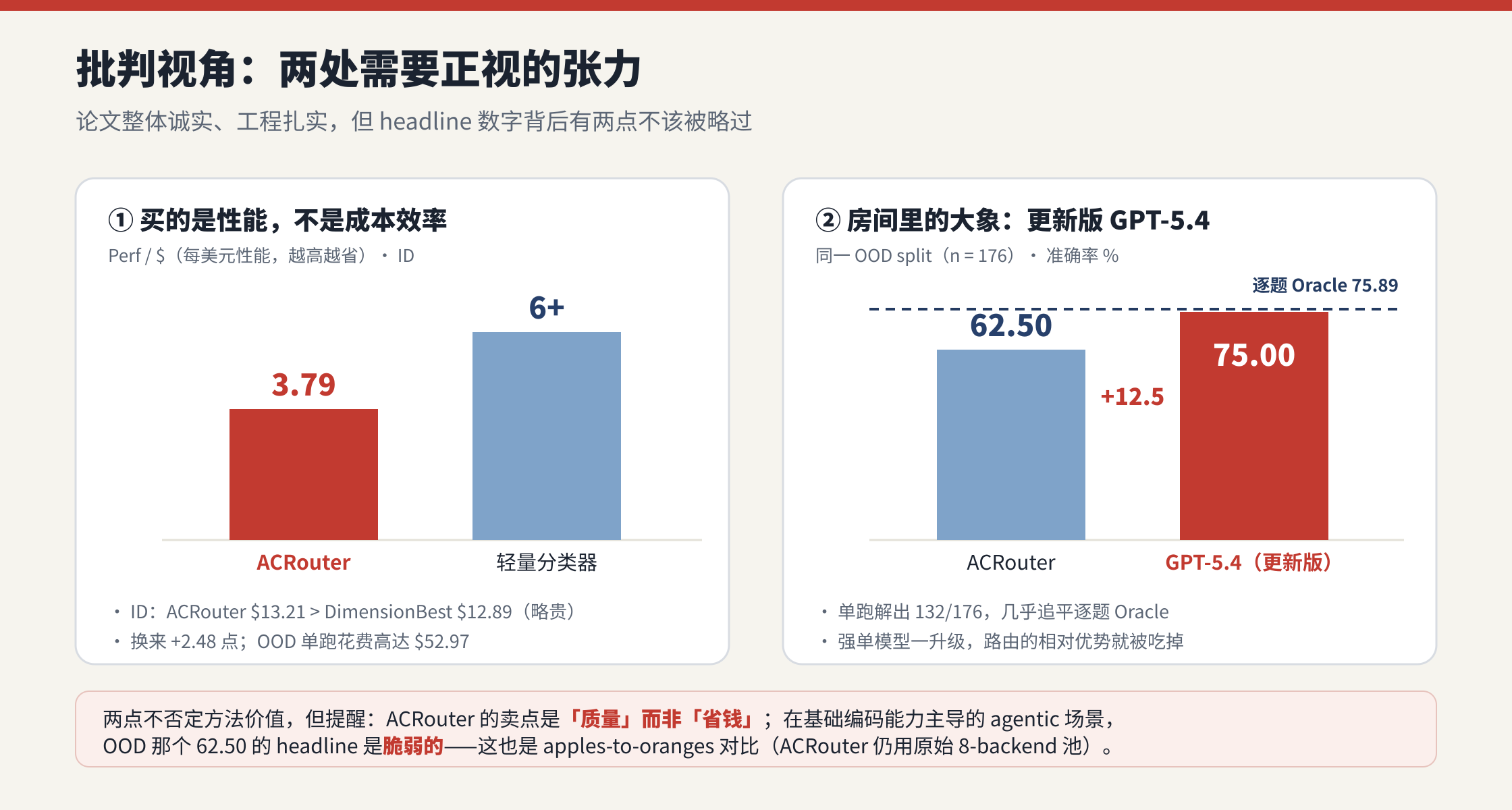
作者老实交代:一次更新后的单跑 GPT-5.4 在同一 OOD split 上解出了 75.00%(132/176) ,几乎追平逐题 oracle 的 75.89%,把 ACRouter 的 62.50% 甩开 12.5 个点。这是个 apples-to-oranges 的对比(ACRouter 用的是原始 8-backend bundle,没把升级版 GPT-5.4 纳入候选池),但它说明一件事:在 agentic 这种"基础编码能力主导"的场景里,一个更新的强单模型直接吊打了路由器,OOD 那个 headline 数字是脆弱的。 诚实可贵,但确实削弱了 OOD 叙事(第九节展开)。
八、创新点与亮点
真正的方法论贡献(思想层):
- 诊断的重定向------把路由瓶颈从"推理"挪到"信息"。这不是又一个路由器,而是把整个问题的因变量换了。Table 1 那个"喂数字就涨 15.3%、还超过启发式上界"的结果,是全篇最有说服力的一击。
- C-A-F 的双重身份------它既是 ACRouter 的设计蓝图,又是一张能把单模型 / 启发式 / 静态学习器 / 在线老虎机全部归位的分类表,让"消融"与"对比基线"合二为一。配上"累积遗憾"这个被老虎机视角正当化的新指标,评测范式被换掉了。
- CodeRouterBench------预采集"每题 × 每模型"结果矩阵 + 专设 agentic OOD 维度,是流式路由研究的可复用底座。
扎实但属工程优化的部分:
- ACRouter 的三件套本身。Orchestrator 是"DimensionBest 投票者 + LogReg 投票者 + 微调小模型 + kNN 记忆"的加权集成;Verifier 是多信号沙盒打分;Memory 是 FIFO 向量库。每一块都合理、好用,但都不是新原理------它的强,来自它比任何被比较的基线都掌握更多信息。这一点要和"思想创新"分开记账。
九、局限性与潜在问题
论文自陈的不足:成本因缓存不可观测而仅作次要指标;OOD 评测把 250 步砍到 40 步;GLM-5 有约 14.5% 任务缺失按 0 计;结果绑定特定模型版本,需靠 V2/V3 roadmap 持续更新。
我作为读者发现的隐患:
- OOD 叙事被 GPT-5.4 反转削弱(见 7.4)。"一个更新的单模型就能反超路由器"这件事,对"路由在 OOD 上更有价值"的核心主张是结构性的威胁,而非边角料。
- ACRouter 买的是性能,不是效率。 别被"比永远选 Opus 便宜"误导------Opus 是池子里最贵的,这是个很低的标尺。Perf/:ACRouter 是 3.79(ID),而轻量分类器普遍 6+。ID 上 ACRouter(13.21)甚至比 DimensionBest(12.89)还略贵,换来 2.48 个点;OOD 上花 52.97。它的价值主张是"质量",成本效率反而不占优。
- "成本感知"框架在虚晃。 ϵ2=−0.1\epsilon_2=-0.1ϵ2=−0.1 在 ID 上"基本只是软性 tie-breaker",reward 近乎退化为 ri≈sir_i\approx s_iri≈si。那么以"成本感知 reward"算出来的累积遗憾,所承载的信息量比表面看上去少。
- "超过 DimensionBest"没那么惊喜。 DimensionBest 本来就是 ACRouter 的一个投票者,再叠加 Memory-kNN 与微调策略------它严格地比被比较的基线掌握更多信息。在这个设定下超过 DimensionBest,与其说是架构胜利,不如说是把"信息缺失"论点又复述了一遍。
- 验证器的可靠性未被严格检验。 整套"执行落地反馈"的前提是 Verifier 打分靠谱,尤其 OOD 上它在没有 ground-truth 测试时聚合代理信号。论文没给 uiu_iui 相对真值的独立校准------若验证器有噪声,Memory 累积的就是噪声反馈,这是地基性的一环。
- 老虎机更多是 framing 而非工具。 它用 contextual bandit 正当化"累积遗憾"这个指标,但 ACRouter 本身是个 LLM + kNN 的启发式集成,没有任何 regret bound。这个老虎机联系是描述性的,不是规定性的。
- OOD 统计基底薄:仅 176 题、单一维度、还砍了步数;"相对排名不受影响"是断言不是证明。GLM-5 的缺失值按 0 计,还会同时压低它的均分、并可能影响 oracle 与维度冠军的认定。
十、个人评述与启发
价值判断。 这篇最有价值的不是 ACRouter 这个系统(它本质是"把更多信息塞进一个集成投票器"),而是那个诊断------把路由瓶颈从"推理"重新定位到"信息",并配上 C-A-F 这个统一视角和 CodeRouterBench 这个能算累积遗憾的流式评测台。诊断 + 基准是会被后人反复引用的东西;具体系统则会随模型版本快速过时。
可复现性评估。 中等偏上。基准与"每题 × 每模型"矩阵若如承诺开源,复现性会很好;但 ACRouter 的复现依赖于微调小策略、embedding 后端、验证器权重等一串工程细节,且全部结果绑定 2026 年的特定模型快照------半年后模型一升级,绝对数字大概率全变,需靠基准自身的滚动更新维持有效性。
可拓展方向。 论文在 §E.3 点了更大的野心:C-A-F 这套"观察上下文→行动→拿反馈→更新记忆"的范式不止用于模型路由,还能推广到工具选择、prompt 策略选择、思考预算分配------把路由当成 agent 决策的一个最小实例。这个推广方向比 ACRouter 本身更有想象空间:任何"在动作集上序贯决策、且能拿到执行反馈"的 agent 子问题,原则上都能套这个壳。
对相关研究者的借鉴。
- 做路由/调度的:先量一下你的瓶颈是信息还是推理,再决定要不要去卷更大的策略模型------Table 1 的方法论(纯信息消融)本身就值得复用。
- 做基准的:单次准确率不足以刻画序贯系统,预采集结果矩阵 + 累积遗憾是个干净的范式。
- 做 agent 的:把 C-A-F 当成一张检查表------你的系统在每步产生新信息 了吗?这些信息跨步累积了吗?很多 agent 之所以"记不住教训",就是缺了这两条里的某一条。