视频链接:https://www.bilibili.com/video/BV1YKTG6GEqj/?vd_source=5ba34935b7845cd15c65ef62c64ba82f
仓库链接:https://github.com/LitchiCheng/mujoco-learning
之前几期进行过《Mujoco 开源机械臂 RL 强化学习避障、绕障》、《MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)》的分享,对于前两个对于任务还属于较为简单且单一,对于强化学习的奖励函数等会比较容易设计。
而pick and place这个类型的任务中会分为多个阶段(到达目标pick点、夹住cube、抬起来、放下去),如何让 RL 学会这种"分阶段"的任务,奖励函数会涉及很多考虑,在分享该实验前还是修改了N版奖励函数才让RL学会这个长程任务。其中经历过几种训练后的真实状态:
- 学会到位,但夹取姿态不对,推着cube走
- 到位夹着cube但无法抬起,反复扭曲
- 夹取抬起来后开始扭曲
- 夹取后抬起来放下来
- 夹取后无法靠近目标点
下面分享下奖励函数以及几个关键修改,奖励函数如下:
def _calc_reward(self, action: np.ndarray) -> tuple[float, bool, bool, bool]:
"""阶梯式奖励: stage_base + 阶段内稠密[0,1]"""
ee_pos = self.data.body(self.end_effector_id).xpos.copy()
cube_pos = self.data.body(self.cube_id).xpos.copy()
gripper_width = self.data.qpos[7:9].mean()
dist_ee2cube = np.linalg.norm(ee_pos - cube_pos)
dist_cube2target = np.linalg.norm(cube_pos - self.target_place_pos)
lateral_to_target = np.linalg.norm(cube_pos[:2] - self.target_place_pos[:2])
cube_z = cube_pos[2]
reward = 0.0
lateral_dist = np.linalg.norm(ee_pos[:2] - cube_pos[:2])
vertical_offset = ee_pos[2] - cube_pos[2] - 0.025
vertical_gap = ee_pos[2] - cube_pos[2]
# 末端姿态朝下
ee_rot = self.data.body(self.end_effector_id).xmat.reshape(3, 3)
alignment = np.dot(ee_rot[:, 2], np.array([0.0, 0.0, -1.0]))
# 计算Y轴水平方向投影
finger_axis_xy = (-ee_rot[:, 1])[:2]
finger_axis_xy_norm = np.linalg.norm(finger_axis_xy)
if finger_axis_xy_norm > 1e-6:
finger_axis_xy = finger_axis_xy / finger_axis_xy_norm
# 只关心和方块的一个边平行即可,不是斜着就可以
yaw_align = max(abs(finger_axis_xy[0]), abs(finger_axis_xy[1]))
else:
yaw_align = 0.0
is_physically_grasped = self._is_grasped_by_contact()
# 是否抓着标志位消抖
if self.grasped:
if is_physically_grasped and gripper_width < 0.035:
self.lost_contact_steps = 0
else:
self.lost_contact_steps += 1
if self.lost_contact_steps >= 4:
self.grasped = False
# 每步只落在一个 stage
if not self.grasped:
if self.grasp_phase == 0:
# stage0 接近:base 0 + reach∈[0,1]
reach = 0.5 * (1.0 - np.tanh(6.0 * lateral_dist)) \
+ 0.5 * (1.0 - np.tanh(6.0 * abs(vertical_offset)))
reward += reach # ≤1
if (lateral_dist < 0.018 and 0.01 < vertical_gap < 0.038):
pose = 0.5 * alignment + 0.5 * yaw_align
reward += pose
# 里程碑: 到达抓取位姿
if (lateral_dist < 0.018 and 0.008 < vertical_gap < 0.038
and alignment > 0.965 and yaw_align > 0.93):
reward += 1.0
self.grasp_phase = 1
self.close_steps = 0
# 记录到 tensorboard 中
self.alignment = alignment
self.ee_yaw = yaw_align
else:
# stage1 闭合:base 1.0 + 0.5
reward += 1.0
if is_physically_grasped:
reward += 0.5
cube_velocity = np.linalg.norm(
self.data.qvel[self.cube_qpos_start:self.cube_qpos_start+3]
)
# 两个夹抓贴着一边推着走的情况
if cube_velocity < 0.05:
reward += 1.0
self.grasped = True
self.lost_contact_steps = 0
else:
# 防止拿起来放下去
if (self.lifted and cube_z < self.lift_threshold - 0.02 and lateral_to_target > 0.06):
self.lifted = False
if not self.lifted:
# stage2 抬升中:base 1.0 + 2*lift∈[0,2]
reward += 1.0
lift_norm = np.clip((cube_z - self.cube_init_z) / self.lift_threshold, 0.0, 1.0)
reward += 2.0 * lift_norm # ≤2
if cube_z > self.lift_threshold:
reward += 1.0
self.lifted = True
else:
# stage3 搬运放置:base 3.0 + 4*place_xy + 0.5*place_z
reward += 3.0
place_xy = 1.0 - np.tanh(2.5 * lateral_to_target)
reward += 4.0 * place_xy # ≤4
target_blend = 1.0 - np.tanh(8.0 * lateral_to_target) # lat=0→1, lat=0.15→0
# lat 大 → desired_z ≈ carry_height(托住,防脱手)
# lat 小 → desired_z ≈ target_z(鼓励下放)
desired_z = (self.carry_height * (1.0 - target_blend)
+ self.target_place_pos[2] * target_blend)
z_err = abs(cube_z - desired_z)
reward += 0.5 * (1.0 - np.tanh(8.0 * z_err)) # ≤0.5
is_success = self.grasped and self.lifted and dist_cube2target < self.place_threshold
if is_success:
reward += 1.0
# 姿态保持
if not self.lifted:
reward += 0.3 * (alignment - 1.0)
reward += 0.2 * (yaw_align - 1.0)
# 惩罚项 ≤0.1
cube_velocity = np.linalg.norm(self.data.qvel[self.cube_qpos_start:self.cube_qpos_start+3])
if not self.grasped and dist_ee2cube < 0.05 and cube_velocity > 0.05:
reward -= 0.3
q = self.data.qpos[:7].copy()
dq = self.data.qvel[:7].copy()
q_home = self.home_joint_pos[:7]
joint_ranges = self.model.jnt_range[:7]
range_width = joint_ranges[:, 1] - joint_ranges[:, 0]
posture_error = (q - q_home) / range_width
posture_penalty = np.sum(self.posture_weights * np.square(posture_error))
reward -= 0.05 * posture_penalty
lower_margin = q - joint_ranges[:, 0]
upper_margin = joint_ranges[:, 1] - q
limit_violation = np.maximum(0.0, self.joint_margin - np.minimum(lower_margin, upper_margin))
reward -= 0.5 * np.sum(np.square(limit_violation / self.joint_margin))
reward -= 0.003 * np.linalg.norm(dq)
reward -= 0.01 * np.linalg.norm(action - self.last_action)
reward += -0.02 # 时间惩罚
is_drop = cube_z < -0.02
if is_drop:
reward -= 5.0
terminated = is_drop
return reward, terminated, is_success, is_drop 其中要注意:
- 长程任务需要分阶段进行奖励,让RL慢慢理解每个阶段的奖励区别,递进式奖励带来的梯度变化正确的引导下一步动作逐渐靠近目标;
- 每个阶段分为base和稠密奖励,让RL理解阶段内的动作应该怎么推进;
- 另外还要注意阶段之间的相互影响,比如抬起来、放下去就是冲突,需要设定相应的阈值进行切换,不然就是反反复复;
- 中间也要加一些工程方式,如夹取姿态的限定、夹取成功的判断,夹爪的开合由脚本完成,这些让RL学习不是不可能,而是不划算;
- 增加一些过程记录,方便看到是否是因为阈值设定的问题;
- 通过传统的方式验证下,首先要确保本身就可行,比如机械臂是否可达等
判断是否夹住的函数,通过contact和开合程度
def _is_grasped_by_contact(self) -> bool:
left_contact = False
right_contact = False
for i in range(self.data.ncon):
contact = self.data.contact[i]
body1 = contact.geom1
body2 = contact.geom2
body1_id = self.model.geom_bodyid[body1]
body2_id = self.model.geom_bodyid[body2]
bodies = {body1_id, body2_id}
if self.cube_id in bodies and self.left_finger_id in bodies:
left_contact = True
if self.cube_id in bodies and self.right_finger_id in bodies:
right_contact = True
gripper_width = self.data.qpos[7:9].mean()
return left_contact and right_contact and gripper_width < 0.035增加中间辅助的动作,按比例让动作按一定预期和网络学会的一起输出
if not self.grasped or self.lifted:
self._assist_on = False
elif cube_z_now < self.carry_height - 0.03:
self._assist_on = True
elif cube_z_now >= self.carry_height:
self._assist_on = False
commanded_action = action.copy()
if self._assist_on:
current_q = self.data.qpos[:7]
home_action = np.clip(
(self.home_joint_pos[:7] - current_q) / self.max_delta_q, -1.0, 1.0
)
# 保证从桌面可靠抬起;lifted 后此分支已不再进入
blend = 0.5
commanded_action = np.clip(blend * home_action + (1-blend) * action, -1.0, 1.0)下面是Tensorboard记录
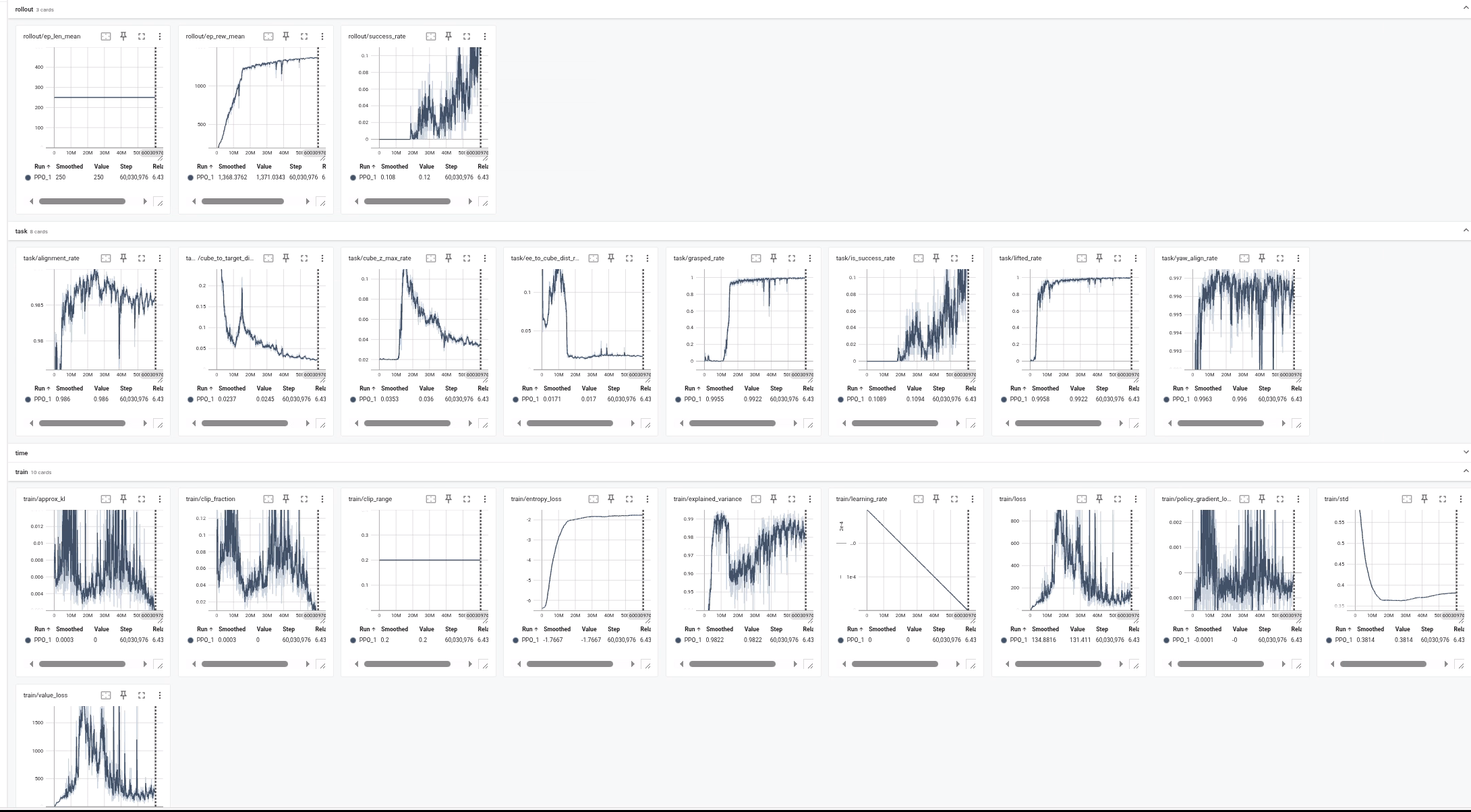
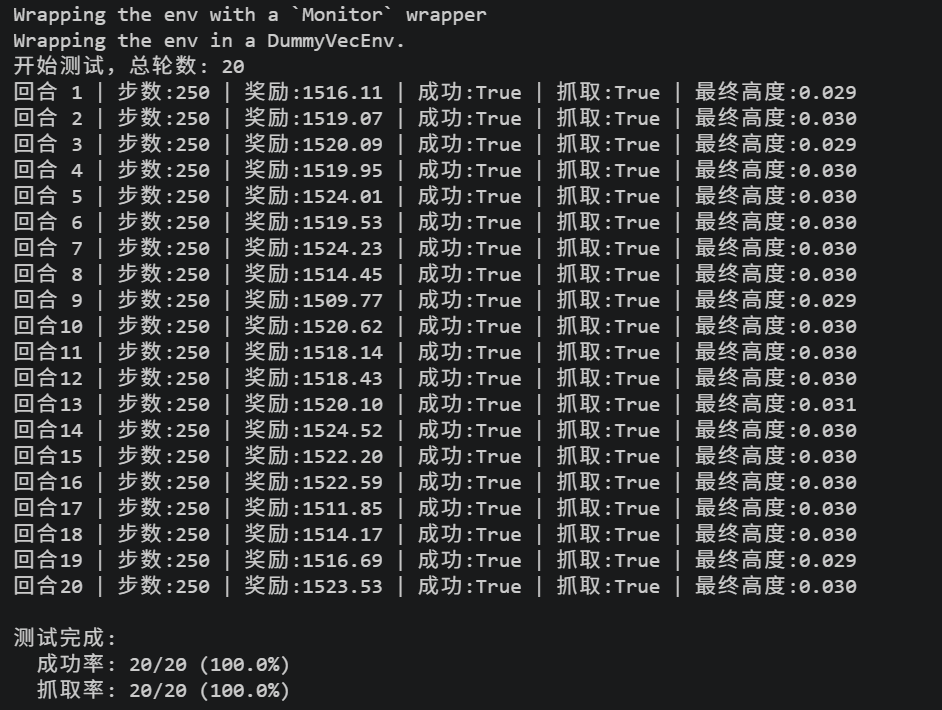
下面是60M steps训练后,进行test的结果