****论文题目:****MIXLINEAR: EXTREME LOW RESOURCE MULTIVARIATE TIME SERIES FORECASTING WITH 0.1K PARAMETERS(0.1K参数极低资源多元时间序列预测)
会议:ICLR 2026
摘要: 最近,人们对长期时间序列预测(LTSF)越来越感兴趣,它涉及到通过分析大量历史时间序列数据来确定模式和趋势来预测长期未来值。由于其复杂的时间依赖性和高的计算要求,LTSF面临着巨大的挑战。尽管基于Transformer的模型提供了很高的预测精度,但它们通常计算密集型,无法部署在具有硬件限制的设备上。在本文中,我们提出了MixLine,它将基于分段的时间域趋势提取和频域自适应低阶谱滤波协同结合起来。我们的方法利用了时间序列的互补结构稀疏性:通过数学上的线性变换分离段内和段间的相关性来有效地捕获局部时间模式,而通过可学习的秩受限滤波器将全局趋势压缩到超低维的频率潜在空间。通过将下采样的n长度输入/输出单层线性模型的参数范围从O(
)降低到O(N),MixLine在不牺牲精度的情况下实现了高效的计算。广泛的评估表明,MixLine以显著更少的参数(0.1K)实现了与现有模型相当的预测性能,这使得它非常适合在计算能力有限的设备上部署。
MixLinear:用 0.1K 参数实现长时序预测,向"参数爆炸"宣战
引言:一个关于效率的终极追问
如果有人告诉你,一个只有 176 个参数 的模型,可以在长时间序列预测任务上与拥有 630 万参数的 PatchTST 相媲美,你会相信吗?
这正是 ICLR 2026 论文 MixLinear 所展示的成果。当深度学习领域普遍沉浸在"更大即更好"的氛围中,MixLinear 选择了一条截然不同的路:用极致的参数效率,挑战时间序列预测的计算边界。
这不仅是一个工程上的压缩技巧,背后有一套清晰的理论洞察。本文将带你深入理解 MixLinear 究竟发现了什么问题,又是如何以 0.1K 参数解决它的。
一、问题的根源:为什么现有模型如此"臃肿"?
1.1 主流模型的参数爆炸
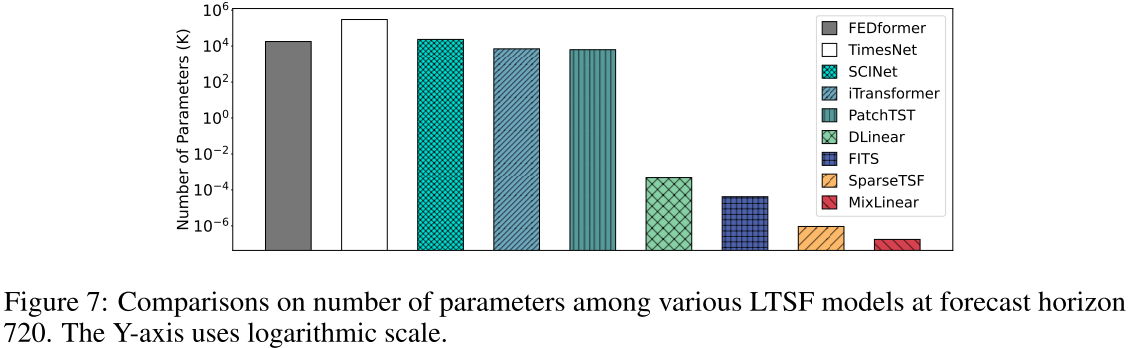
📊 配图位置:Figure 7 ------ 各模型参数量对数坐标对比图
当前长时序预测(LTSF)领域,主流模型的参数规模已经失控:FEDformer、TimesNet、SCINet、iTransformer 的参数量在数千万乃至数亿级别,PatchTST 也有 630 万参数。这些模型在高性能服务器上或许游刃有余,但对于边缘传感器、嵌入式设备、物联网终端而言,根本无法部署。
即便是被誉为"轻量化"的代表模型,也存在明显问题:
- FITS(2024):10K 参数,相对轻量,但随预测长度增加参数量急剧膨胀
- SparseTSF(2024):1K 参数,业界最轻,但仍有较大压缩空间
- DLinear(2023):参数量达 485K,MACs(乘加运算量)随预测长度增长迅速
而 MixLinear 在最长配置(预测步长 720)下仅需 176 个参数,比 SparseTSF 少 81%,比 FITS 少约 98%。
1.2 深层病因:"单一表示策略"的结构性低效
参数爆炸并非不可避免,它是一种结构性低效的症状。论文指出,现有模型普遍采用"单一表示策略"------用同一套机制同时处理性质截然不同的两类时序模式:
局部高频特征(短期波动、局部形态):
- 本质特征是时域的局部性
- 最适合用时域的线性变换来高效捕捉
全局低频趋势(长期趋势、季节性):
- 在频域中天然稀疏,能量集中在少数主频分量上
- 最适合用频域的低秩压缩来表示
强行用统一架构建模这两类特征,就像用锤子拧螺丝------不是做不到,而是浪费。这种错配直接导致参数冗余和计算浪费。
1.3 已有方案的局限
- FITS:纯频域方法。用全局频率分量表示局部瞬态变化,天然需要大量系数才能描述尖锐的局部特征,反而削弱了频域压缩的效率优势。
- DeepGate 类方法:虽然对时序做了分解,但分解后仍使用参数量大的复杂模块,未能真正实现轻量化。
因此,核心挑战是:为局部模式和全局模式各找到最自然的处理域,并在同一框架中高效融合。
二、MixLinear 的解法:让每类模式在最自然的域中被处理
MixLinear 提出了一个核心理论原则------谱-时分解原则(Spectral-Temporal Decomposition Principle):
局部动态天然适合时域的分段线性分解;全局趋势在频域天然稀疏,适合低秩压缩。
基于此,MixLinear 采用双路径架构,两条路径并行处理后相加输出:
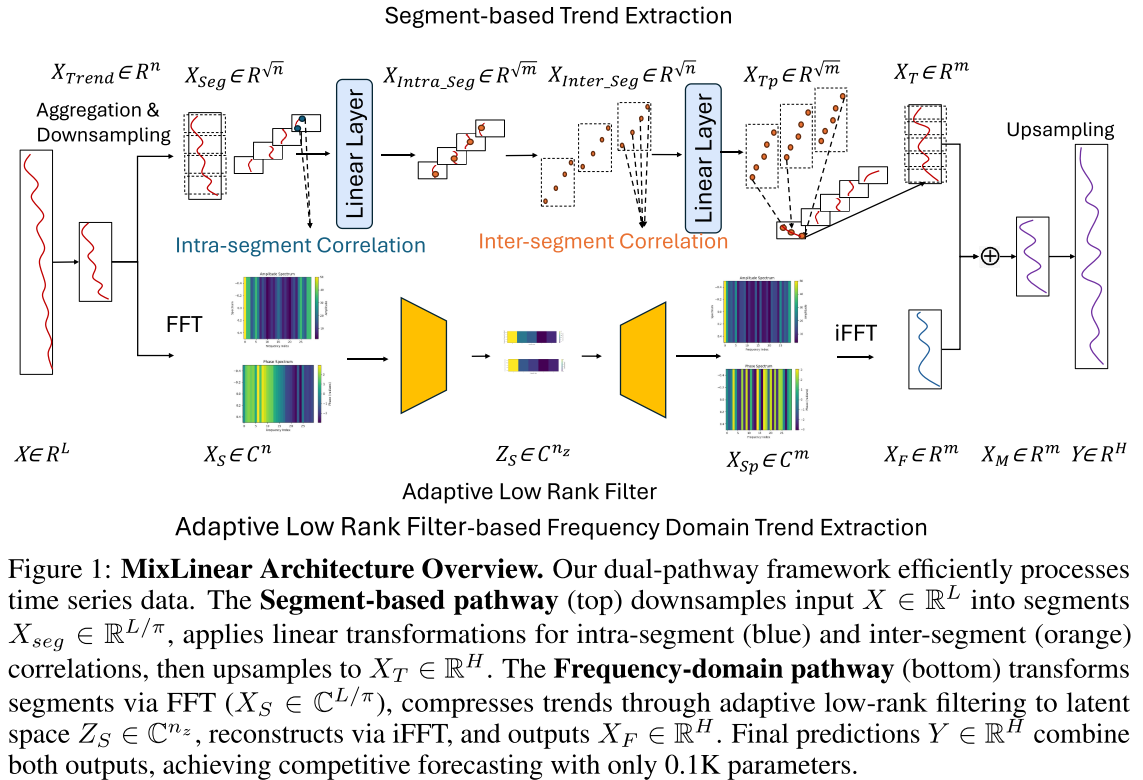
📊 配图位置:Figure 1 ------ MixLinear 整体架构图(双路径示意)
这种加法融合(而非乘法融合)在保持两条路径表示独立性的同时,避免了梯度不稳定问题,并支持端到端联合优化。
2.1 时域路径:基于分段的局部趋势提取
核心思想 :把时间序列切成小段,分别建模"段内"和"段间"的相关性,用两个小线性层替代一个大线性层,将复杂度从 压缩到 O(n)。
具体流程:
第一步:下采样与分段
对长度为 L 的输入 先以因子
做下采样,得到
长的序列,再划分为 M 个不重叠的段,每段长度
:
下采样本身起到低通滤波作用,衰减高频噪声,保留趋势信息。
第二步:段内相关建模(Intra-Segment)
对每个段 应用一个线性层,将 r 个时间步压缩为 d 维摘要向量:
这一步捕捉局部斜率、短周期、波形形态等段内局部特征。
第三步:段间相关建模(Inter-Segment)
将所有段的摘要向量堆叠为 ,再用第二个线性层建模跨段依赖:
这一步捕捉慢漂移、段级周期性、跨段相关性等全局时域结构。
该双线性分解等价于矩阵的"行变换 + 列变换"分解,将参数复杂度从单层线性的 降至 O(dr + dM),即 O(n),同时通过两层非平凡变换保持了足够的表达能力。
2.2 频域路径:自适应低秩谱滤波
核心思想:真实时序的全局趋势在频域极度稀疏(能量集中在极少数主频分量),因此可以用极低秩的矩阵分解来近似完整的频域变换,实现惊人的参数压缩。
具体流程:
第一步:FFT 变换
对下采样序列做快速傅里叶变换,得到复数频谱张量:
第二步:低秩谱滤波
用秩为 的矩阵分解替代全尺寸滤波矩阵:
其中 ,
,秩
(极致压缩)。
这一步将每段频谱投影到一个共享的低维潜空间,然后通过自适应基 U 重建滤波后的频谱。秩约束 迫使模型只关注最主导的频率模式,恰好对应时序数据频域低秩的自然属性。
第三步:iFFT 重建
频域路径仅需 个实参数,实现极致压缩的同时保留全局谱信息。
2.3 复杂度分析
| 维度 | MixLinear | 自注意力(Transformer) |
|---|---|---|
| 时间复杂度 | ||
| 空间复杂度 | ||
| 参数量 | 0.1K(45~176个) | 数百万至数亿 |
时域路径 O(n),频域路径 (FFT)+
(低秩滤波),整体由 FFT 主导,为
,优于自注意力的
。
三、实验结果
3.1 主实验:以极少参数实现竞争性预测精度
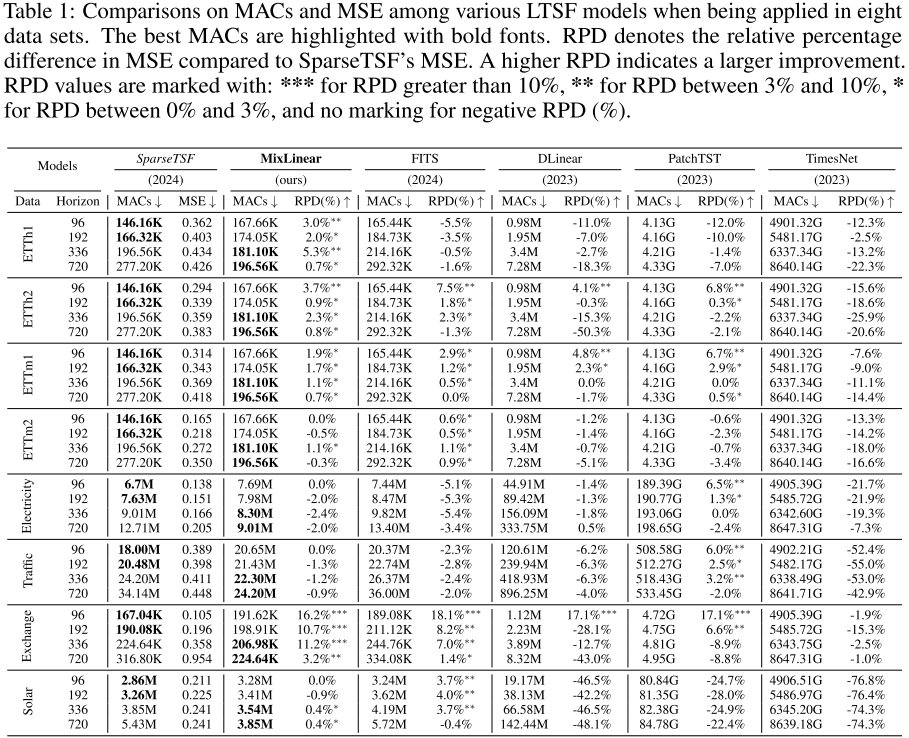
📊 配图位置:Table 1 ------ 八个数据集上各模型 MACs 和 MSE 对比(含 RPD)
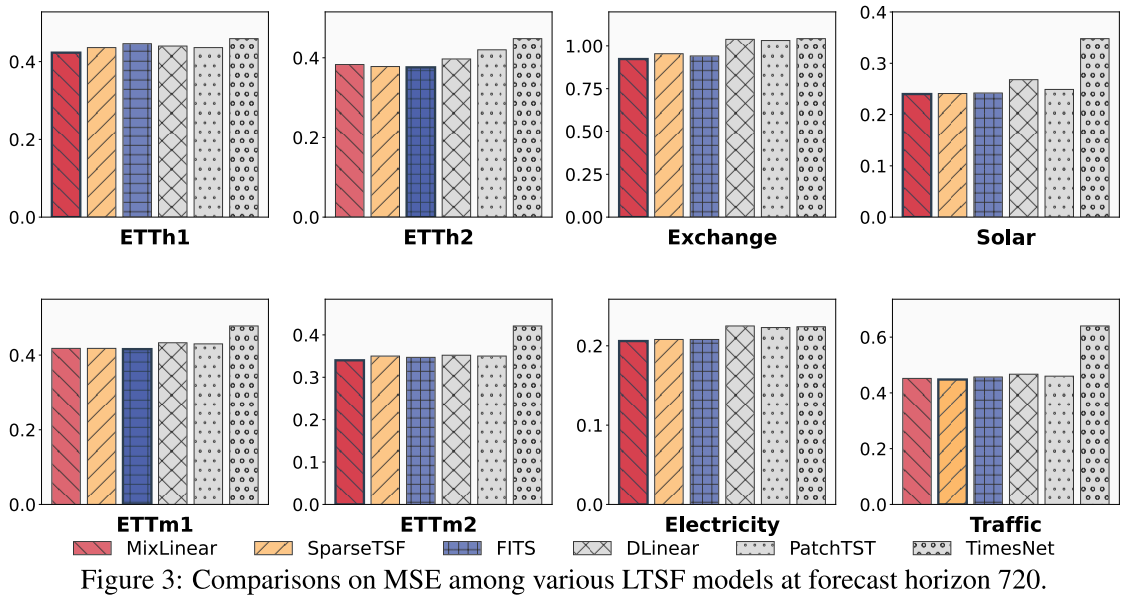
📊 配图位置:Figure 3 ------ 预测步长 720 时各模型 MSE 柱状图对比
实验在 ETTh1、ETTh2、ETTm1、ETTm2、Exchange、Solar、Electricity、Traffic 八个标准数据集上进行,回看窗口固定为 720,预测步长为 96/192/336/720。
参数效率(81% 参数削减):
MixLinear 仅需 0.1K 参数,在最长预测步长 720 下:
- 比 SparseTSF(1K)少 81% 参数
- 比 FITS(约 10K)少 94~98% 参数
- 比 PatchTST(6.31M)少约 99.997% 参数
在 Electricity 数据集上,当预测步长从 96 增至 720 时,MixLinear 参数量仅从 45 增至 176,而 FITS 从 1,056 增至 10,512,SparseTSF 增长同样更陡。
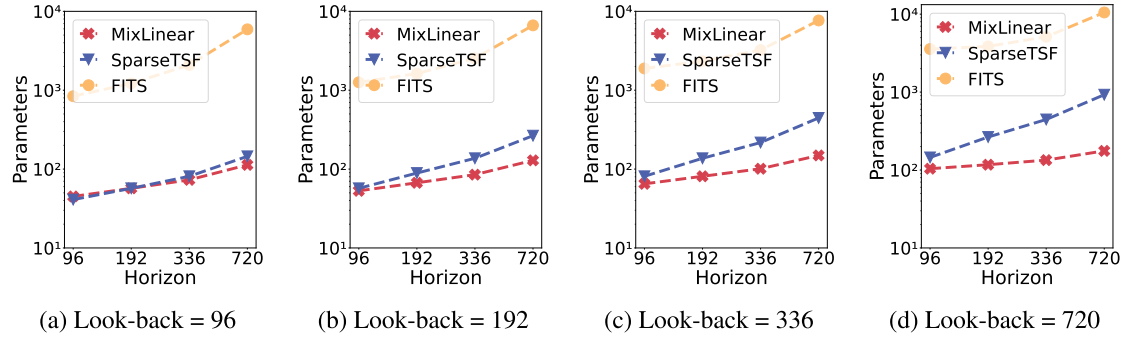
📊 配图位置:Figure 2 ------ Electricity 数据集不同 look-back 窗口下三个模型参数量随预测步长增长的对比(对数坐标)
预测精度:
- Exchange 数据集 :MixLinear 相比 SparseTSF 取得高达 16.2% 的 MSE 改善(96步:MSE 0.088 vs 0.105);192步时改善 10.7% ,336步时改善 11.2%
- ETTh1 数据集 :336步时 MSE 0.411,优于 SparseTSF(0.434)、FITS(0.436)、DLinear(0.446)
- ETTh2 数据集 :96步时 MSE 0.283 ,比 SparseTSF(0.294)提升 3.7%
值得一提的是,在更完整的 9 模型对比(Table 5)中,MixLinear 在 ETTh1 多个步长上超越了所有基线,包括 PatchTST(6.31M参数)和 iTransformer(7.04M参数)。
MACs 效率:
- 低维数据集(ETTh1,7通道),预测步长 720:MixLinear 196.56K MACs,低于 SparseTSF(277.20K,多 41.3%)和 FITS(292.32K,多 48.98%)
- 高维数据集(Traffic,862通道),预测步长 720:MixLinear 24.2M MACs,低于 SparseTSF(34.14M,多 41.7%)和 FITS(36.00M,多 48.8%)
3.2 推理速度:低维快 3.2×,高维快 2.58×
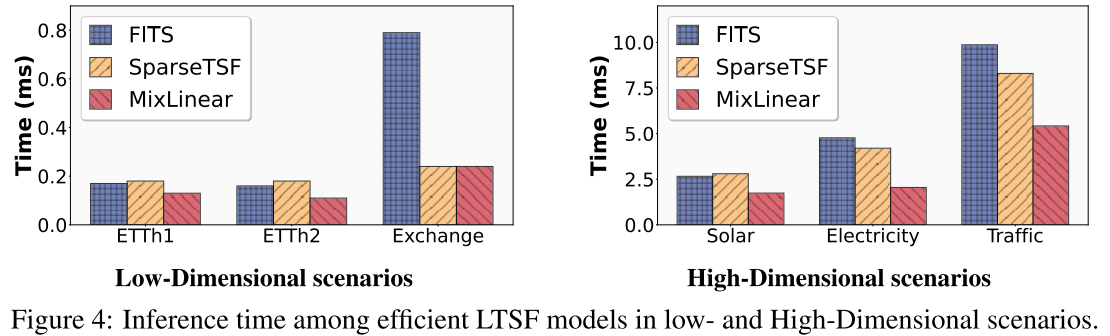
📊 配图位置:Figure 4 ------ 低维和高维场景下三个模型推理时间对比柱状图
除参数量和 MACs 外,实际推理时间同样验证了 MixLinear 的效率优势:
低维场景(ETTh1/ETTh2/Exchange):
- Exchange 数据集:MixLinear 0.25ms ,SparseTSF 0.80ms ,FITS 0.43ms
- MixLinear 比 SparseTSF 快 3.2× ,比 FITS 快 1.72×
高维场景(Solar/Electricity/Traffic):
- Electricity 数据集:MixLinear 2.05ms ,SparseTSF 4.20ms ,FITS 4.77ms
- MixLinear 比 SparseTSF 快 2.12× ,比 FITS 快 2.58×
3.3 消融实验:两条路径各司其职,缺一不可

📊 配图位置:Table 2 ------ 消融实验结果(w/o Filtering、w/o Segment、完整 MixLinear 对比)
论文对两条路径分别进行了消融,得到以下规律:
低维数据集(ETTh1/ETTh2)上:
- 去掉频域路径(w/o Filtering)的 MSE 为 0.425,优于去掉时域路径(w/o Segment)的 0.474
- 说明在通道数少、跨通道相关有限时,时域分段路径贡献更大
- 完整 MixLinear 进一步将 MSE 降至 0.423,体现了频域路径的补充价值
高维数据集(Electricity/Traffic)上:
- 去掉时域路径(w/o Segment)的 MSE 为 0.478,优于去掉频域路径(w/o Filtering)的 0.528(Traffic数据集)
- 说明在高维场景中,频域低秩滤波更擅长压缩全局动态
- 完整 MixLinear 在 Traffic 和 Electricity 上均取得最优,MSE 分别为 0.452 和 0.209
从 MACs 角度看,完整 MixLinear 相比 w/o Filtering 仅增加少量开销(Exchange 数据集:224.64K vs 207.36K,来自 FFT/iFFT 操作),但精度提升显著。
3.4 超参数分析:鲁棒到几乎不需要调参
分段长度的影响:
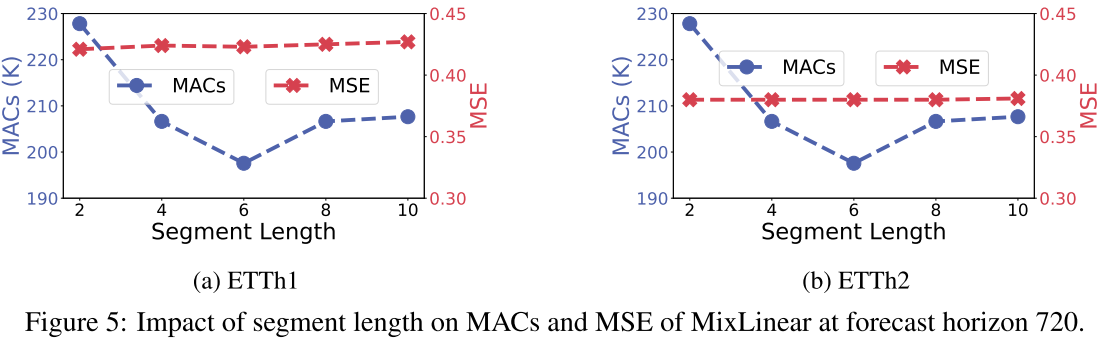
📊 配图位置:Figure 5 ------ 分段长度对 ETTh1/ETTh2 上 MACs 和 MSE 的影响
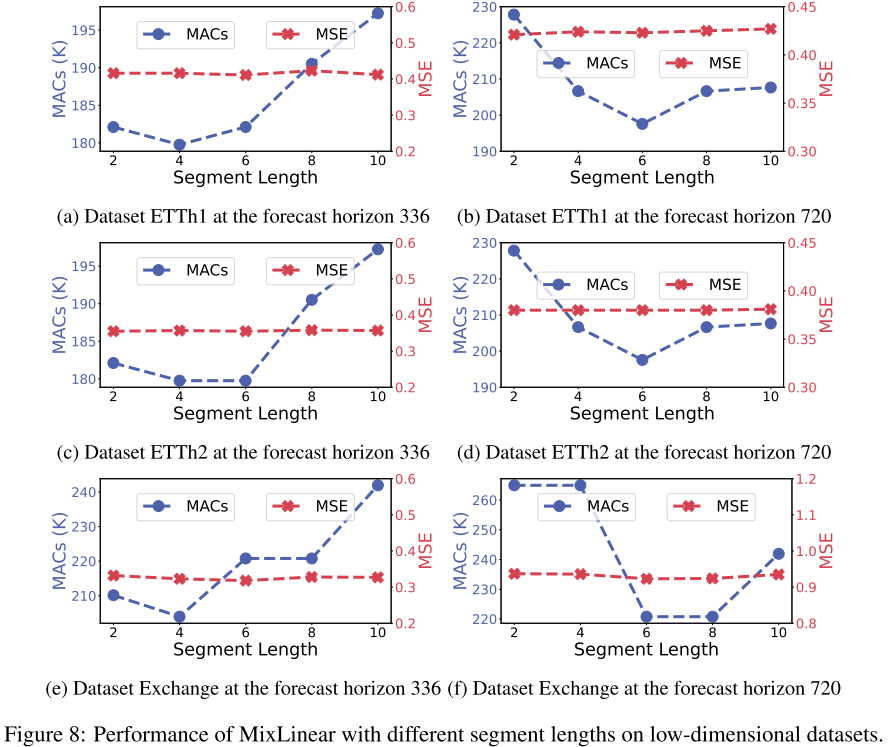
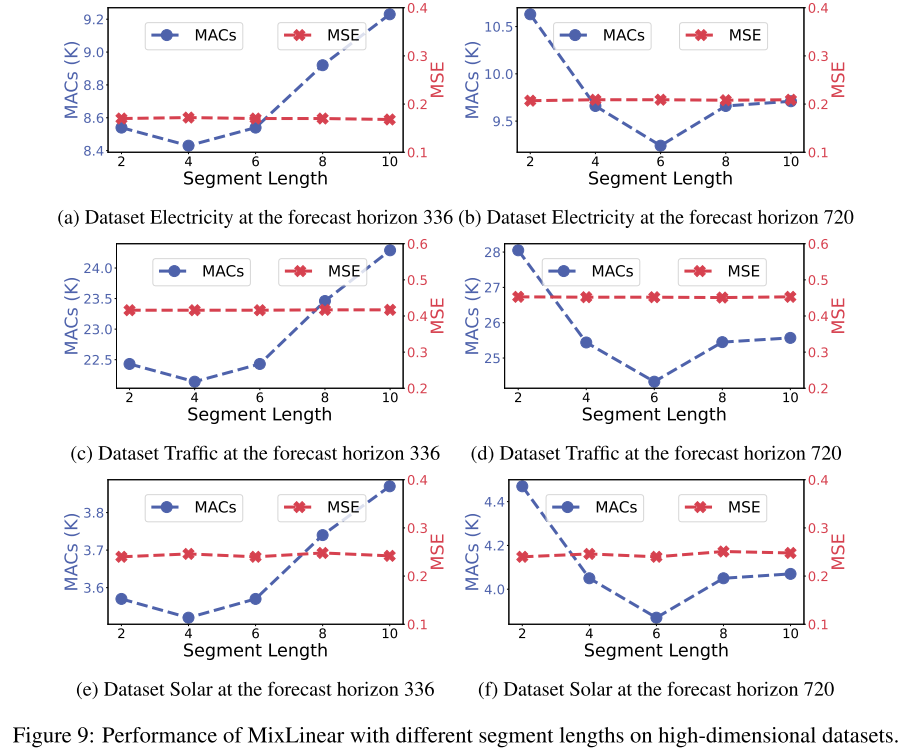
📊 配图位置:Figure 8/9 ------ 低维/高维数据集上不同分段长度的详细分析
在 ETTh1 上,分段长度从 2 变化到 16,MSE 仅在 0.42~0.43 之间微幅波动;而 MACs 从约 290K 降至 220K,说明更长的分段既能保持精度又能降低计算量。高维数据集(Traffic)上表现更为稳健,MSE 曲线几乎完全平坦。
谱秩的影响:
📊 配图位置:Figure 6 ------ 谱秩对 ETTh1/ETTh2 上 MACs 和 MSE 的影响
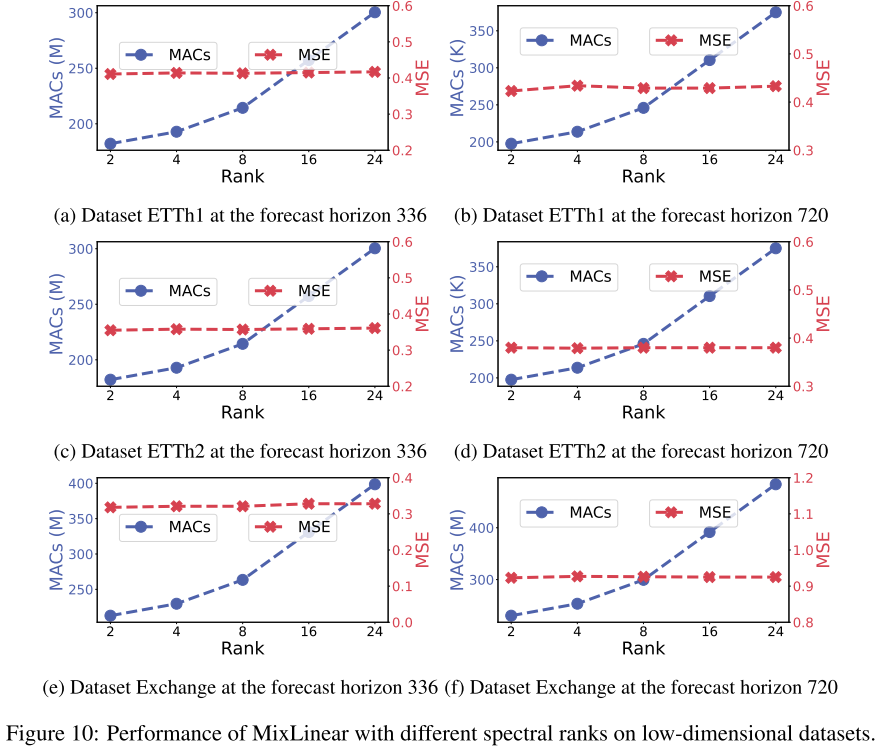
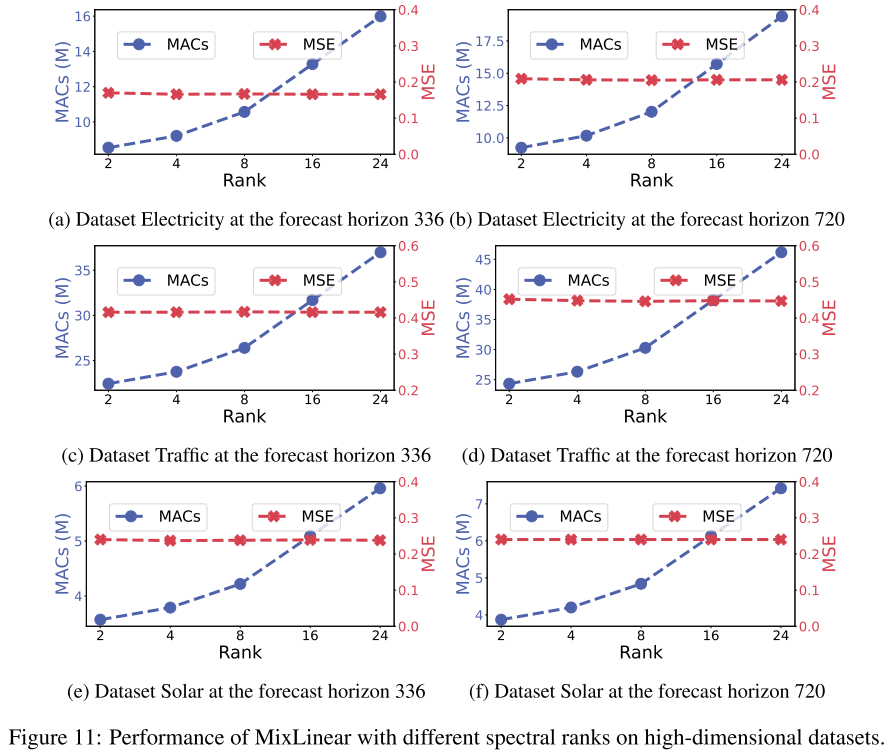
📊 配图位置:Figure 10/11 ------ 低维/高维数据集上不同谱秩的详细分析
在 ETTh1 上,谱秩 从 2 增至 24,MSE 改善仅约 0.005 ,而 MACs 从 275K 增至 350K。ETTh2 在
后即趋于饱和,为频域稀疏性假设提供了强有力的实证支撑------时序的全局趋势确实集中在极低维的频率子空间中 。秩-2 近似比秩-16 参数减少约 6×,但精度基本持平。
下采样因子的影响:
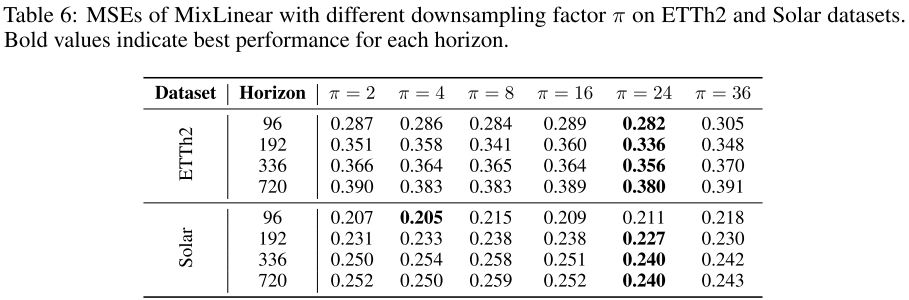
📊 配图位置:Table 6 ------ 不同下采样因子 π 在 ETTh2 和 Solar 数据集上的 MSE 对比
实验显示 在大多数配置下取得最优,但不同
值之间的 MSE 差异通常在 2~3% 以内,说明 MixLinear 对下采样因子的选择也具有良好的鲁棒性。
3.5 MACs 随预测步长的可扩展性
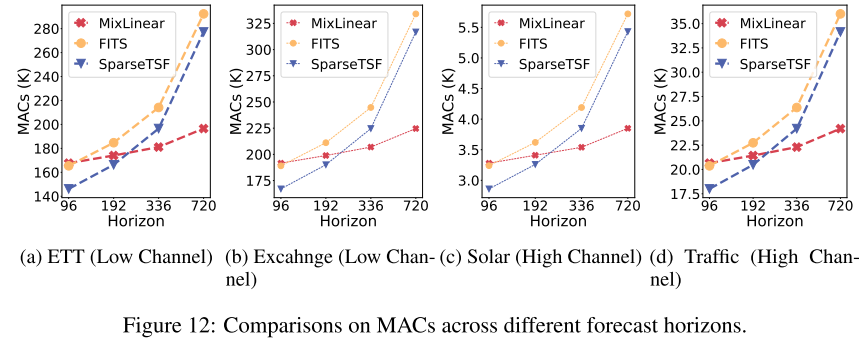
📊 配图位置:Figure 12 ------ 不同预测步长下三个模型的 MACs 增长曲线
Figure 12 直观展示了 MixLinear 的可扩展性优势:随着预测步长从 96 增至 720,MixLinear 的 MACs 增长曲线始终最为平缓,对应其 的理论复杂度。这与 SparseTSF 和 FITS 的更陡增长曲线形成鲜明对比,在 H = 336 和 H = 720 的高难度场景下,MixLinear 相比 SparseTSF 的 MACs 优势高达 40%。
四、与更多基线的全面对比
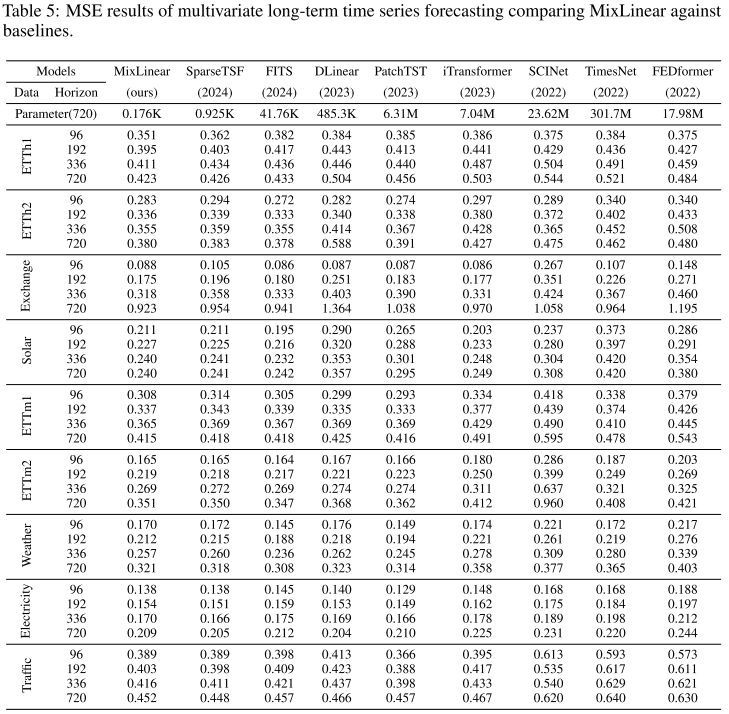
📊 配图位置:Table 5 ------ 九个模型在九个数据集上的完整 MSE 对比(包含 iTransformer、SCINet、FEDformer)
在与 9 种基线的全面对比中(Table 5),MixLinear 仅用 0.176K 参数(horizon=720),实现了以下表现:
- ETTh1:在 96、192、336 步均取得最低 MSE(如 96步 MSE=0.351,优于 SparseTSF 的 0.362、PatchTST 的 0.385、FEDformer 的 0.375)
- ETTh2:96步 MSE=0.283,仅次于 FITS(0.272),优于其余所有基线
- Exchange:96步 MSE=0.088,与 DLinear(0.087)、iTransformer(0.086)、FITS(0.086)相近,显著优于 SparseTSF(0.105)和 SCINet(0.267)
- ETTm1/ETTm2:全面领先或持平,且只用极少参数
- Electricity、Traffic:处于前两名,与参数量大 3~4 个数量级的 PatchTST 相当
五、预测可视化
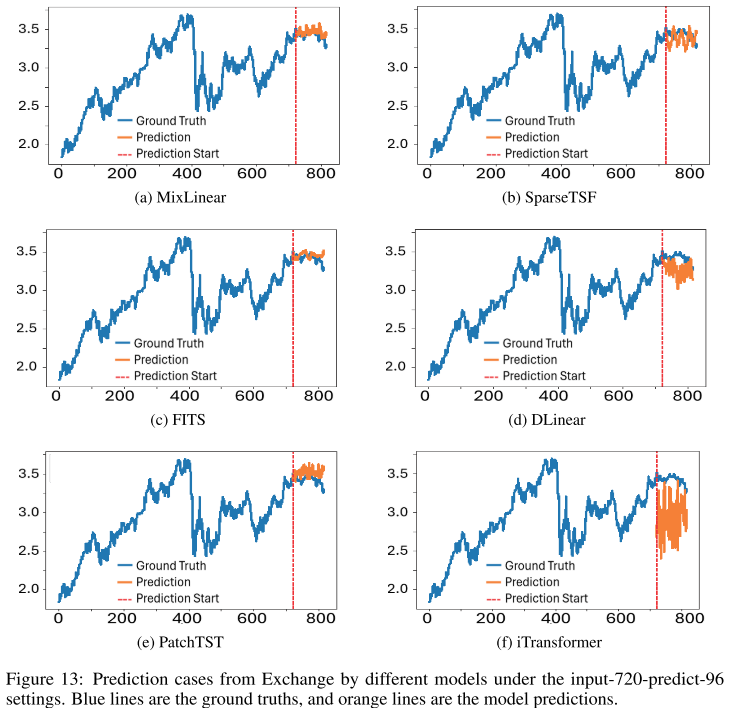
📊 配图位置:Figure 13 ------ Exchange 数据集 input-720-predict-96 下各模型预测曲线对比
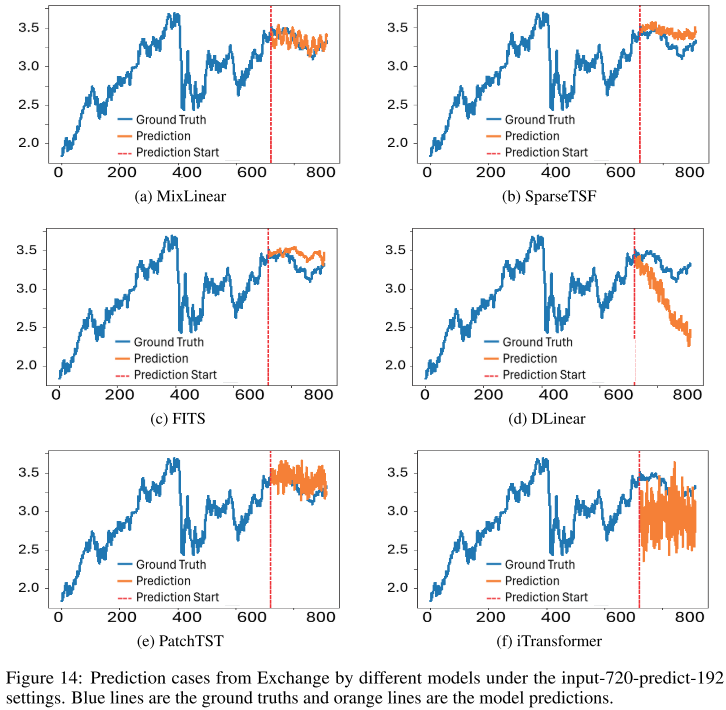
📊 配图位置:Figure 14 ------ Exchange 数据集 input-720-predict-192 下各模型预测曲线对比
在 Exchange 数据集的可视化对比中,MixLinear 的预测曲线与真实值高度吻合,无论是 96 步还是 192 步预测,走势跟踪都明显优于 DLinear 和 iTransformer(后两者出现较大偏差和不稳定现象)。
六、应用前景
MixLinear 的极致轻量化,为以下场景打开了新的可能:
边缘计算与物联网:176 个参数的模型可以直接运行在微控制器上,实现本地实时推理,无需将数据上传云端。对于洪水预警传感器、环境健康监测站、交通控制系统这类对实时性和功耗都有严格要求的场景,MixLinear 具有直接的实用价值。
大模型效率启示:论文在结论中指出,谱-时分解的底层思想同样适用于大型语言模型和基础模型的效率优化,为未来更轻量的 LLM 设计提供了方向性参考。
七、总结
MixLinear 的价值不仅在于"参数少"这一工程成就,更在于它揭示了一个被长期忽视的设计原则:不同统计属性的信号,应在各自最自然的表示域中被处理。 强行用统一架构建模性质迥异的局部和全局特征,是现有时序模型参数爆炸的根本原因。
通过将时域分段线性分解(处理局部)与频域低秩谱滤波(处理全局)在双路径框架中有机结合,MixLinear 以 的时间复杂度、O(n) 的空间复杂度、最低 45 个参数,实现了与百万参数模型相当的预测精度,并在 Exchange 等数据集上取得了显著超越。
这是一篇值得反复品读的工作------它不仅给出了一个实用的轻量化方案,更重新定义了时序预测中"效率"与"表达力"之间的可能边界。