2026 年 1 月,Anthropic 做了一件事:封禁第三方工具调用 Claude Code 服务。
消息传开的那一周,OpenCode 的 GitHub Star 数开始疯长。前五个月攒了 5 万颗星,1 月之后短短几周又多了 3 万。到今天,这个数字已经超过 17 万。
很多人说 OpenCode 是"Claude Code 被封禁的最大受益者"。
但事情没那么简单。
一个开源项目用不到一年时间做到 800 万月活,如果只是因为竞争对手封禁了入口,撑不起这个量级。真正让开发者留下来的,是它背后那套经得起推敲的架构设计。
目录
一、发生了什么
二、本质上是供应商锁定的反弹
三、核心机制拆解:主 Agent 与子 Agent 的分层架构
四、一个真实的对比:同样改代码,差别在哪里
五、工程落地启示
六、最后问一个问题
一、发生了什么
OpenCode 的起点很小。2025 年 6 月在 GitHub 发布,创始团队最开始只有几个人。
真正的转折点在 2026 年 1 月。Anthropic 开始封禁第三方工具通过 Claude Pro / Claude Max 订阅账号调用 Claude 模型的行为。OpenCode 之前支持用户用 Claude 订阅直接登录,原理是伪装成 Claude Code 的客户端身份,发送相同的 OAuth 请求头。
Anthropic 的反应分三步:技术封锁、账号封禁、法律行动。
OpenCode 的回应也很干脆------直接移除了对 Claude Pro/Max 订阅和 Claude API key 的支持。
但社区的反应比这两边都快。开发者开始大量涌入。到 2026 年 3 月,OpenCode 的 GitHub Star 数达到 12.8 万,贡献者超过 800 人。月活跃开发者从 65 万飙到 650 万。
安全博主 Daniel Miessler 做了一个直接对比实验:用 OpenCode 从零写一个完整博客。他的结论是------"OpenCode 和 Claude Code 一样好,至少在这个任务上。"
他原本以为 Claude Code 的优势在于某种"秘密酱汁"------上下文管理、记忆维护、多文件多步骤的编排能力。但实际用下来发现,OpenCode 做得同样好。
他的判断是:Claude Code 并不秘密。可能就是围绕上下文窗口和记忆管理的优秀工程实践。一旦其他工具实现了类似的编排策略,差距就会迅速缩小。
二、本质上是供应商锁定的反弹
这件事的本质不是"Claude 不让用了"。
本质是开发者对"供应商锁定"的集体反弹。
过去两年,AI 编程工具市场被几个巨头瓜分。Cursor 每月 20 美元,绑定了自己的模型套餐。Claude Code 按 Token 计费,只能用 Anthropic 的模型。GitHub Copilot 每月 10 美元,只能用 OpenAI。
每个工具都在努力把用户圈在自己的生态里。
OpenCode 走了一条完全相反的路:模型无关。
它支持 75 种以上的模型提供商------Anthropic、OpenAI、Google Gemini、DeepSeek、本地部署的 Ollama 和 llama.cpp。你用谁的 API Key,就连谁的模型。工具本身不抽成、不锁定、不干预。
一个 Reddit 高赞评论说得更直接:「Anthropic 正在激励用户留在自己的产品生态里,而不是在 API 之上构建外部工具。」
开发者用脚投票的结果是:OpenCode 成了 GitHub 上星标最高的开源编程 Agent。
但模型无关只是"为什么用"的理由。真正让开发者"留下来"的,是它内部那套主 Agent 与子 Agent 的分层架构。
三、核心机制拆解:主 Agent 与子 Agent 的分层架构
OpenCode 采用客户端-服务器架构,基于 TypeScript 和 Bun 运行时构建。整体分为四层:客户端层、核心服务层、扩展层、模型适配层。
但最值得关注的设计,是核心服务层里的 Agent 系统。
OpenCode 的核心设计理念,是以"代理模式工作流"为核心,将复杂编程任务拆分为"主代理 + 子代理"的协作模式。
3.1 主 Agent 与子 Agent 的定位差异
主 Agent 出现在 OpenCode 的 Agent 切换器中,是用户直接交互的对象。子 Agent 通过 Task 工具被主 Agent 生成,不能直接被用户选中。
本质上是这样分工的:
主 Agent 负责理解用户的整体目标、规划执行步骤、统筹全局。子 Agent 负责拆出去干具体的小任务------查文档、改某个模块、写测试、跑命令、整理结果。
你可以把子 Agent 理解成主 Agent 派出去的专项助手。主 Agent 负责整体目标和主线判断,子 Agent 负责一个更明确的小任务。
3.2 为什么需要分层
单个 Agent 处理复杂任务时会遇到三个典型问题:
第一,上下文窗口不够用。一个 Agent 既要理解项目全貌,又要处理具体文件的修改细节,上下文很快就会撑爆。
第二,任务无法并行。主 Agent 处理任务是排队的------先做 A、再做 B、再做 C。但很多任务其实可以并行------审查代码和写测试完全可以同时进行。
第三,职责混杂。同一个 Agent 既要做规划,又要写代码,还要做审查。角色不清晰,决策质量就会下降。
分层的核心价值就在于解决这三个问题。
3.3 四层架构中的 Agent 系统
OpenCode 的四层架构从下到上分别是:

用户交互层提供 CLI、TUI、Web 三种接入方式。AI 引擎层通过统一的模型抽象层实现模型热插拔和智能路由。核心能力层是 Agent 系统的所在地。工具集成层通过标准化接口与外部系统交互。
Agent 系统在核心能力层中包含三个关键组件:
决策中枢:基于 ReAct 框架的思维链推理引擎
记忆管理:短期工作记忆与长期知识库的分层存储
行动规划:动态生成可执行步骤序列的规划器
3.4 主从协作的完整流程
下面这张图展示了主 Agent 与子 Agent 协作的典型流程:
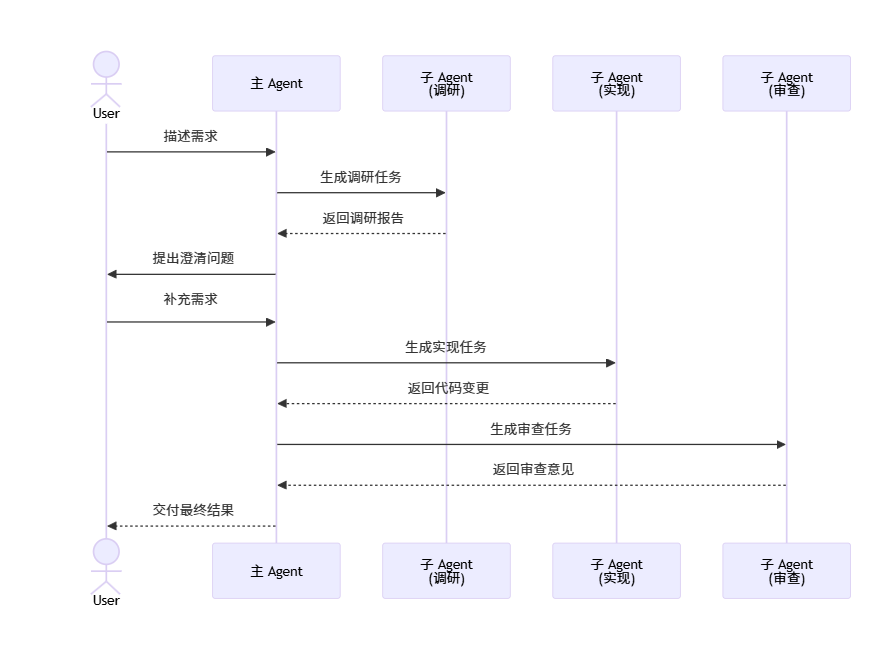
以一个实际的开源插件 Blueprint 为例,它实现了五个专门化的 Agent:
Agent
类型
职责
Planner
主 Agent
调研代码库、访谈用户、生成结构化实施计划
Orchestrator
主 Agent
执行计划、创建 git worktree、委派任务、验证结果
Investigator
子 Agent
深度代码库调研------目录结构、代码模式、依赖关系
Reviewer
子 Agent
审查计划和代码,发现遗漏和范围蔓延
Worker
子 Agent
在隔离的 git worktree 中实现单个原子任务
这里有一个关键的设计约束:只有 Worker Agent 可以写源代码。Planner、Orchestrator、Investigator、Reviewer 被限制为只能在 .blueprint/ 目录内写入文件。
这个约束解决了一个很实际的问题:职责边界清晰。做规划的就做规划,写代码的就写代码,审查的就审查。不会出现一个 Agent 既当运动员又当裁判员的情况。
3.5 Self-Healing 自愈机制
OpenCode 还有一个不太常被提及但很重要的设计:Self-Healing 自愈机制。
核心思想是:任务中断后可以从断点继续。
实际运行中,LLM 的调用可能超时、网络可能闪断、上下文可能溢出。如果没有自愈机制,整个任务就要从头开始。有了断点续传,损失就被控制在了局部。
四、一个真实的对比:同样改代码,差别在哪里
假设你要给一个项目添加用户认证功能,涉及三个文件的修改和一个新文件的创建。
没有分层架构的 Agent:
一个 Agent 从头干到尾。它要先理解项目结构,然后写代码,然后自己审查。过程中它的上下文会越来越臃肿------既要记住项目全局,又要关注每个文件的细节。改到第三个文件的时候,前面两个文件的上下文可能已经被挤出去了。结果就是顾此失彼。
有分层架构的 OpenCode:
主 Agent 先派一个 Investigator 子 Agent 去调研项目结构------目录怎么组织的、用了什么框架、现有的认证方式是什么。调研结果写回主 Agent 的记忆里。
然后主 Agent 基于调研结果生成实施计划,派 Worker 子 Agent 去改代码。每个 Worker 只负责一个原子任务,在隔离的 git worktree 里工作。改完了派 Reviewer 子 Agent 去审查。
每个子 Agent 的上下文是干净的------它只关注自己那一亩三分地。主 Agent 的上下文也是干净的------它只关注整体目标和状态协调。
分层的本质不是"多几个 Agent",而是让每个 Agent 的上下文窗口只装它该装的东西。
五、工程落地启示
说了这么多 OpenCode 的设计,对我们自己有什么启发?
第一,上下文隔离是 Agent 系统稳定运行的前提。
一个 Agent 的上下文窗口再大也是有限的。把任务拆细、把职责拆清,让每个子 Agent 只关注一件事,比训练一个"万能 Agent"要靠谱得多。
第二,主 Agent 不要做具体的事。
主 Agent 的核心职责是规划、调度、决策。具体执行交给子 Agent。如果主 Agent 既要做规划又要写代码,它的决策质量一定会下降。
第三,工具级别的权限控制比提示词约束更可靠。
Blueprint 的做法是在工具层面通过 tool.execute.before 钩子强制执行权限控制,而不是靠提示词告诉 Agent"你不要写源代码"。工程上能用代码保证的事,不要依赖提示词。
第四,自愈机制不是可选项。
在生产环境中,LLM 调用失败是常态,不是异常。设计系统时要假设每一步都可能失败,并且有办法从失败中恢复。
六、最后问一个问题
你的系统里,Agent 的上下文是共享的还是隔离的?
如果是共享的------所有 Agent 共用一个巨大的上下文窗口------那当任务变复杂的时候,上下文污染几乎是必然的。
如果是隔离的------每个子 Agent 有自己的上下文,主 Agent 只负责协调------那你就已经在用分层架构的思路了。
想清楚这个问题,比学会用 OpenCode 本身更重要。
因为工具会变,但架构思想不会。